Lettore
Converti un URL in un input compatibile con LLM, semplicemente aggiungendo
r.jina.ai davanti.API del lettore
Converti un URL in un input compatibile con LLM, semplicemente aggiungendo
r.jina.ai davanti.chevron_leftchevron_right
globe_book
Utilizzare
r.jina.ai per leggere un URL e recuperarne il contenutotravel_explore
Usa
s.jina.ai per cercare sul web e ottenere SERP
Aggiungi
mcp.jina.ai come server MCP per accedere alla nostra API in LLMupload
Richiesta
GET
curl "https://r.jina.ai/https://www.example.com"
Jina VLM: Piccolo modello linguistico di visione multilingue
Un modello di linguaggio visivo con parametri 2.4B che consente di ottenere risposte visive multilingue all'avanguardia tra VLM aperti su scala 2B.

ReaderLM v2: piccolo modello linguistico per HTML in Markdown e JSON
ReaderLM-v2 è un modello di linguaggio con parametri da 1,5 miliardi specializzato nella conversione da HTML a Markdown e nell'estrazione da HTML a JSON. Supporta documenti fino a 512K token in 29 lingue e offre una precisione superiore del 20% rispetto al suo predecessore.


L'inserimento delle informazioni web nei LLM è un passo importante per radicarsi, ma può essere impegnativo. Il metodo più semplice è raschiare la pagina web e alimentare l'HTML grezzo. Tuttavia, lo scraping può essere complesso e spesso bloccato e l'HTML grezzo è ingombro di elementi estranei come markup e script. L'API Reader risolve questi problemi estraendo il contenuto principale da un URL e convertendolo in testo pulito e compatibile con LLM, garantendo input di alta qualità per il tuo agente e i sistemi RAG.
HTML grezzo
Uscita del lettore

Reader può essere utilizzato come API SERP. Ti consente di alimentare il tuo LLM con il contenuto dietro la pagina del motore di ricerca. Aggiungi semplicemente
https://s.jina.ai/?q= alla tua query e Reader cercherà sul web e restituirà i primi cinque risultati con i loro URL e contenuti, ciascuno in un testo pulito e adatto a LLM. In questo modo, puoi sempre mantenere il tuo LLM aggiornato, migliorarne la fattualità e ridurre le allucinazioni.info Tieni presente che, a differenza della demo mostrata sopra, in pratica non cerchi la domanda originale sul web per il grounding. Ciò che le persone fanno spesso è riscrivere la domanda originale o utilizzare domande multi-hop. Leggono i risultati recuperati e quindi generano ulteriori query per raccogliere più informazioni necessarie prima di arrivare a una risposta finale.

Le immagini sulla pagina Web vengono automaticamente sottotitolate utilizzando un modello di linguaggio visivo nel lettore e formattate come tag alt dell'immagine nell'output. Ciò fornisce al tuo LLM a valle suggerimenti sufficienti per incorporare tali immagini nei suoi processi di ragionamento e riepilogo. Ciò significa che puoi porre domande sulle immagini, selezionarne di specifiche o persino inoltrare i loro URL a un VLM più potente per un'analisi più approfondita!
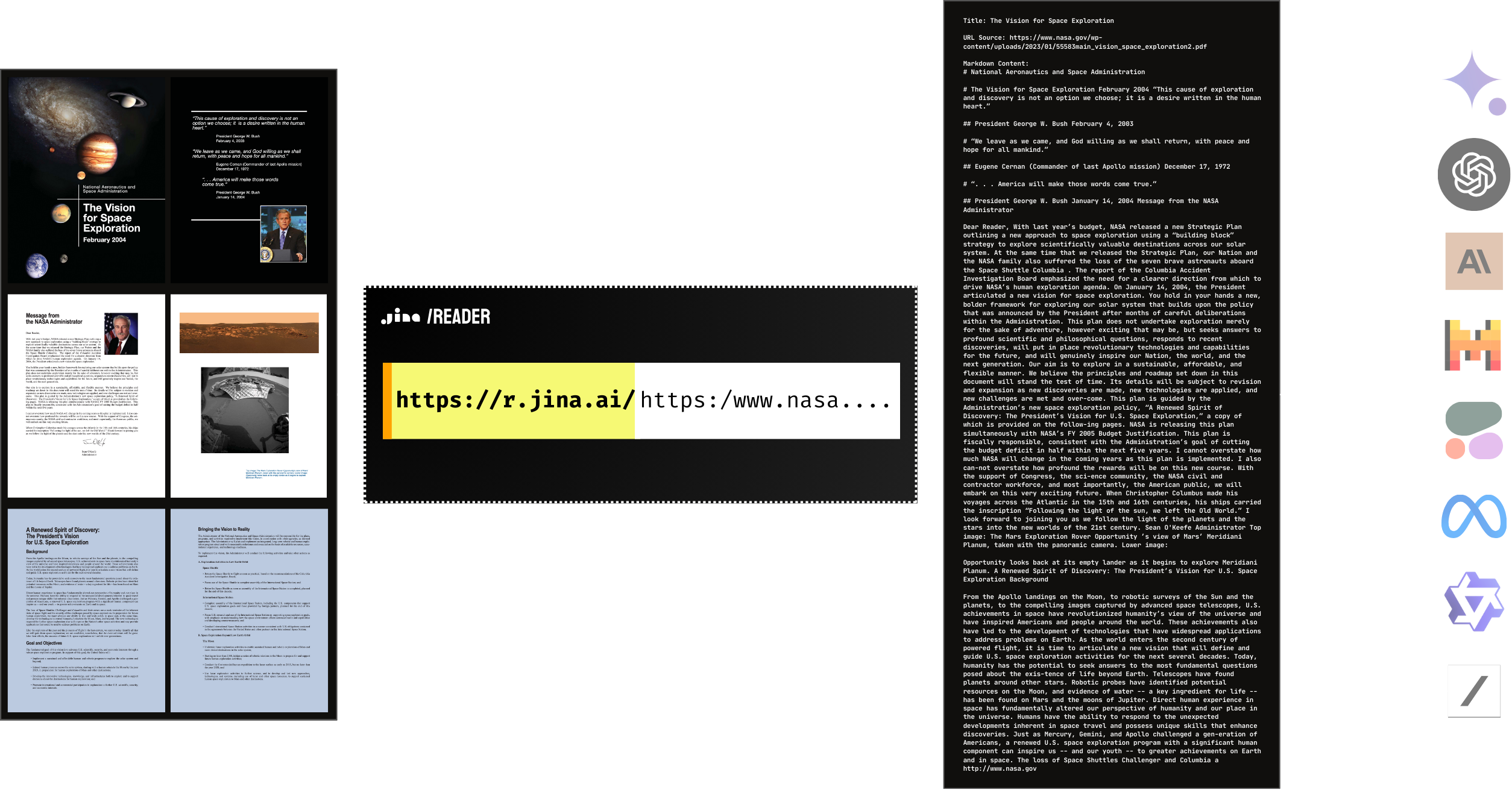
Sì, Reader supporta nativamente la lettura di PDF. È compatibile con la maggior parte dei PDF, compresi quelli con molte immagini, ed è velocissimo! In combinazione con un LLM, puoi facilmente creare un ChatPDF o un'intelligenza artificiale per l'analisi dei documenti in pochissimo tempo.
La parte migliore? È gratis!
L'API Reader è disponibile gratuitamente e offre limiti di tariffa e prezzi flessibili. Costruito su un'infrastruttura scalabile, offre elevata accessibilità, concorrenza e affidabilità. Ci sforziamo di essere la soluzione di messa a terra preferita per i tuoi LLM.
Limite di velocità
I limiti di velocità vengono monitorati in tre modi: RPM (richieste al minuto) e TPM (token al minuto). I limiti vengono applicati per IP/chiave API e vengono attivati al raggiungimento della soglia RPM o TPM. Quando si fornisce una chiave API nell'intestazione della richiesta, i limiti di velocità vengono monitorati per chiave anziché per indirizzo IP.
| Prodotto | Punto finale API | Descrizionearrow_upward | senza chiave APIkey_off | con chiave API gratuitakey | con chiave API a pagamentokey | con chiave API Premiumkey | Latenza media | Conteggio dell'utilizzo del token | Richiesta consentita | |
|---|---|---|---|---|---|---|---|---|---|---|
| API del lettore | https://r.jina.ai | Convertire l'URL in testo compatibile con LLM | 20 RPM | 500 RPM | 500 RPM | trending_up5000 RPM | 7.9s | Contare il numero di token nella risposta di output. | GET/POST | |
| API del lettore | https://s.jina.ai | Cerca sul web e converti i risultati in testo compatibile con LLM | block | 100 RPM | 100 RPM | trending_up1000 RPM | 2.5s | Ogni richiesta costa un numero fisso di token, a partire da 10000 token | GET/POST | |
| API di riclassificazione | https://api.jina.ai/v1/rerank | Classifica i documenti per query | block | 100 RPM & 100,000 TPM | 500 RPM & 2,000,000 TPM | trending_up5,000 RPM & 50,000,000 TPM | ssid_chart dipende dalla dimensione dell'input help | Conta il numero di token nella richiesta di input. | POST | |
| Incorporamento dell'API | https://api.jina.ai/v1/embeddings | Convertire testo/immagini in vettori di lunghezza fissa | block | 100 RPM & 100,000 TPM | 500 RPM & 2,000,000 TPM | trending_up5,000 RPM & 50,000,000 TPM | ssid_chart dipende dalla dimensione dell'input help | Conta il numero di token nella richiesta di input. | POST | |
| API del classificatore | https://api.jina.ai/v1/train | Addestrare un classificatore utilizzando esempi etichettati | block | 25 RPM & 25,000 TPM | 125 RPM & 500,000 TPM | 1,250 RPM & 12,000,000 TPM | ssid_chart dipende dalla dimensione dell'input | I token vengono conteggiati come: input_tokens × num_iters | POST | |
| API del classificatore (Colpo zero) | https://api.jina.ai/v1/classify | Classificare gli input utilizzando la classificazione zero-shot | block | 25 RPM & 25,000 TPM | 125 RPM & 500,000 TPM | 1,250 RPM & 12,000,000 TPM | ssid_chart dipende dalla dimensione dell'input | I token vengono conteggiati come: input_tokens + label_tokens | POST | |
| API del classificatore (Pochi colpi) | https://api.jina.ai/v1/classify | Classificare gli input utilizzando un classificatore addestrato a pochi scatti | block | 25 RPM & 25,000 TPM | 125 RPM & 500,000 TPM | 1,250 RPM & 12,000,000 TPM | ssid_chart dipende dalla dimensione dell'input | I token sono conteggiati come: input_tokens | POST | |
| API del segmentatore | https://api.jina.ai/v1/segment | Tokenizzare e segmentare il testo lungo | 20 RPM | 200 RPM | 200 RPM | 1,000 RPM | 0.3s | Il token non viene conteggiato come utilizzo. | GET/POST | |
| Ricerca profonda | https://deepsearch.jina.ai/v1/chat/completions | Ragiona, cerca e ripeti per trovare la risposta migliore | block | 50 RPM | 50 RPM | 500 RPM | 56.7s | Contare il numero totale di token nell'intero processo. | POST |





Niente panico! Ogni nuova chiave API contiene dieci milioni di token gratuiti!
Prezzi dell'API
Il prezzo dell'API si basa sull'utilizzo del token. Una chiave API ti dà accesso a tutti i prodotti della fondazione di ricerca.

Con l'API Jina Search Foundation
Il modo più semplice per accedere a tutti i nostri prodotti. Ricarica i token man mano che procedi.
Ricarica questa chiave API con più token
Inserisci la chiave API corretta per ricaricare
Comprendere il limite di velocità
I limiti di velocità sono il numero massimo di richieste che possono essere effettuate a un'API entro un minuto per indirizzo IP/chiave API (RPM). Scopri di più sui limiti di velocità per ogni prodotto e livello di seguito.
keyboard_arrow_down

Quali sono i costi associati all'utilizzo dell'API Reader?
keyboard_arrow_down
Come funziona l'API Reader?
keyboard_arrow_down
L'API Reader è open source?
keyboard_arrow_down
Qual è la latenza tipica per l'API Reader?
keyboard_arrow_down
Perché dovrei utilizzare l'API Reader invece di raschiare la pagina da solo?
keyboard_arrow_down
L'API Reader supporta più lingue?
keyboard_arrow_down
Cosa devo fare se un sito web blocca l'API Reader?
keyboard_arrow_down
L'API Reader può estrarre il contenuto dai file PDF?
keyboard_arrow_down
L'API Reader può elaborare i contenuti multimediali dalle pagine Web?
keyboard_arrow_down
È possibile utilizzare l'API Reader su file HTML locali?
keyboard_arrow_down
L'API Reader memorizza nella cache il contenuto?
keyboard_arrow_down
Posso utilizzare l'API Reader per accedere ai contenuti dietro un login?
keyboard_arrow_down
Posso utilizzare l'API Reader per accedere ai PDF su arXiv?
keyboard_arrow_down
Come funziona la didascalia delle immagini in Reader?
keyboard_arrow_down
Qual è la scalabilità del Reader? Posso usarlo in produzione?
keyboard_arrow_down
Qual è il limite di velocità dell'API Reader?
keyboard_arrow_down
Che cos'è Reader-LM? Come posso utilizzarlo?
keyboard_arrow_down
Come posso estrarre dati strutturati dalle pagine web?
keyboard_arrow_down
Reader aggira attivamente la protezione anti-bot del sito web?
keyboard_arrow_down
Passare da una chiave API gratuita a una a pagamento mi darà accesso a più siti web?
keyboard_arrow_down
Limite di velocità
I limiti di velocità vengono monitorati in tre modi: RPM (richieste al minuto) e TPM (token al minuto). I limiti vengono applicati per IP/chiave API e vengono attivati al raggiungimento della soglia RPM o TPM. Quando si fornisce una chiave API nell'intestazione della richiesta, i limiti di velocità vengono monitorati per chiave anziché per indirizzo IP.
| Prodotto | Punto finale API | Descrizionearrow_upward | senza chiave APIkey_off | con chiave API gratuitakey | con chiave API a pagamentokey | con chiave API Premiumkey | Latenza media | Conteggio dell'utilizzo del token | Richiesta consentita | |
|---|---|---|---|---|---|---|---|---|---|---|
| API del lettore | https://r.jina.ai | Convertire l'URL in testo compatibile con LLM | 20 RPM | 500 RPM | 500 RPM | trending_up5000 RPM | 7.9s | Contare il numero di token nella risposta di output. | GET/POST | |
| API del lettore | https://s.jina.ai | Cerca sul web e converti i risultati in testo compatibile con LLM | block | 100 RPM | 100 RPM | trending_up1000 RPM | 2.5s | Ogni richiesta costa un numero fisso di token, a partire da 10000 token | GET/POST | |
| API di riclassificazione | https://api.jina.ai/v1/rerank | Classifica i documenti per query | block | 100 RPM & 100,000 TPM | 500 RPM & 2,000,000 TPM | trending_up5,000 RPM & 50,000,000 TPM | ssid_chart dipende dalla dimensione dell'input help | Conta il numero di token nella richiesta di input. | POST | |
| Incorporamento dell'API | https://api.jina.ai/v1/embeddings | Convertire testo/immagini in vettori di lunghezza fissa | block | 100 RPM & 100,000 TPM | 500 RPM & 2,000,000 TPM | trending_up5,000 RPM & 50,000,000 TPM | ssid_chart dipende dalla dimensione dell'input help | Conta il numero di token nella richiesta di input. | POST | |
| API del classificatore | https://api.jina.ai/v1/train | Addestrare un classificatore utilizzando esempi etichettati | block | 25 RPM & 25,000 TPM | 125 RPM & 500,000 TPM | 1,250 RPM & 12,000,000 TPM | ssid_chart dipende dalla dimensione dell'input | I token vengono conteggiati come: input_tokens × num_iters | POST | |
| API del classificatore (Colpo zero) | https://api.jina.ai/v1/classify | Classificare gli input utilizzando la classificazione zero-shot | block | 25 RPM & 25,000 TPM | 125 RPM & 500,000 TPM | 1,250 RPM & 12,000,000 TPM | ssid_chart dipende dalla dimensione dell'input | I token vengono conteggiati come: input_tokens + label_tokens | POST | |
| API del classificatore (Pochi colpi) | https://api.jina.ai/v1/classify | Classificare gli input utilizzando un classificatore addestrato a pochi scatti | block | 25 RPM & 25,000 TPM | 125 RPM & 500,000 TPM | 1,250 RPM & 12,000,000 TPM | ssid_chart dipende dalla dimensione dell'input | I token sono conteggiati come: input_tokens | POST | |
| API del segmentatore | https://api.jina.ai/v1/segment | Tokenizzare e segmentare il testo lungo | 20 RPM | 200 RPM | 200 RPM | 1,000 RPM | 0.3s | Il token non viene conteggiato come utilizzo. | GET/POST | |
| Ricerca profonda | https://deepsearch.jina.ai/v1/chat/completions | Ragiona, cerca e ripeti per trovare la risposta migliore | block | 50 RPM | 50 RPM | 500 RPM | 56.7s | Contare il numero totale di token nell'intero processo. | POST |
Domande comuni relative all'API
code
Posso usare la stessa chiave API per le API di lettura, incorporamento, riclassificazione, classificazione e messa a punto?
keyboard_arrow_down
code
Posso monitorare l'utilizzo del token della mia chiave API?
keyboard_arrow_down
code
Cosa devo fare se dimentico la mia chiave API?
keyboard_arrow_down
code
Le chiavi API scadono?
keyboard_arrow_down
code
Posso trasferire token tra chiavi API?
keyboard_arrow_down
code
Posso revocare la mia chiave API?
keyboard_arrow_down
code
Perché la prima richiesta per alcuni modelli è lenta?
keyboard_arrow_down
code
I miei dati API vengono utilizzati per addestrare i vostri modelli?
keyboard_arrow_down
code
Quali sono i limiti di velocità per le API Jina?
keyboard_arrow_down
code
Esistono limiti alle dimensioni dei batch per le API?
keyboard_arrow_down
Domande comuni relative alla fatturazione
attach_money
La fatturazione è basata sul numero di frasi o richieste?
keyboard_arrow_down
attach_money
È disponibile una prova gratuita per i nuovi utenti?
keyboard_arrow_down
attach_money
Vengono addebitati i token per le richieste non riuscite?
keyboard_arrow_down
attach_money
Quali metodi di pagamento sono accettati?
keyboard_arrow_down
attach_money
È disponibile la fatturazione per gli acquisti di token?
keyboard_arrow_down
