


前回のEmbeddings V2の目覚ましい成功に続き、最新の中国語/英語バイリンガルテキスト埋め込みモデル:jina-embeddings-v2-base-zhのリリースを発表できることを大変嬉しく思います。この新しいモデルは、Jina Embeddings V2の卓越した8Kトークン長を継承しつつ、中国語と英語の両言語に対する堅牢なサポートを実現しています。
jina-embeddings-v2-base-zhは、高品質なバイリンガルデータを用いた厳密でバランスの取れた事前学習により、優れた品質とパフォーマンスを実現しています。このアプローチにより、不均衡な多言語データで学習されたモデルでよく見られるバイアスが大幅に軽減されています。
tag主な特徴
- バイリンガルモデル: このモデルは英語と中国語の両方のテキストをエンコードし、クエリまたはターゲット文書としてどちらの言語も使用できます。これらの言語で同等の意味を持つテキストは同じ埋め込み空間にマッピングされ、多くの多言語アプリケーションの基礎となります。
- 拡張された8Kトークン長: 私たちのモデルは、大量のテキスト処理が可能で、この機能は他のほとんどのオープンソースモデルの能力を超えています。
- コンパクトで効率的: 322MB(1億6100万パラメータ)のサイズと768の出力次元を持ち、GPUなしの標準的なコンピュータハードウェアでの高性能を実現するよう設計されており、アクセシビリティが向上しています。
tagC-MTEBでの優れたパフォーマンス
Chinese MTEBリーダーボードにおいて、中国語と英語の両方をサポートする私たちのJina Embeddings v2は、0.5GB未満のモデルの中でトップクラスのモデルとして際立っています。特に注目すべきは、このカテゴリーで唯一の8Kトークン長対応という特徴です。
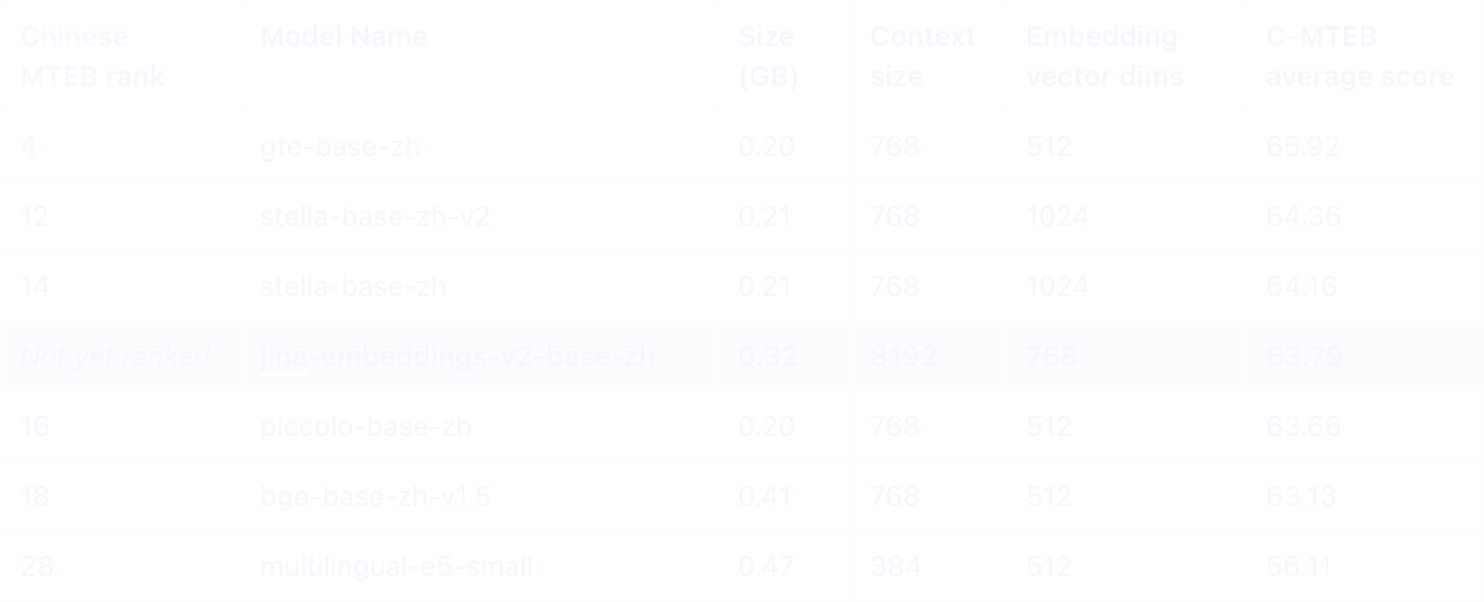
同様のサイズの中国語モデルの中で、E5 Multilingualモデルと私たちのjina-embeddings-v2-base-zhのみが英語をサポートし、効果的なクロス言語アプリケーションを実現しています。特筆すべきは、Jinaが中国語に関わるすべてのカテゴリーで著しく優れたパフォーマンスを示していることです。

両モデルとも8Kトークンのコンテキストサイズを持ちますが、jina-embeddings-v2-base-zhは、OpenAIのtext-embedding-ada-002を特に中国語を含むタスクで大きく上回っています。

tag中国企業のグローバル展開を支援
私たちの中国語-英語埋め込みモデルは、「出海」を目指す中国企業にとって強力なツールです。中国語テキストをシームレスに処理し、主要なベクトルデータベース、検索システム、RAGアプリケーションと容易に統合できる高品質な埋め込みを提供します。
jina-embeddings-v2-base-zhは、特に国際展開を図る企業にとって重要な中国語-英語のコンテキストに特化したAIアプリケーションの開発に有益です。具体的なユースケースは以下の通りです:
- 文書分析と管理:国際的な法務やビジネス取引において、幅広い文書の分析と管理が可能です。
- AI検索アプリケーション:多言語環境での検索機能を強化し、グローバルユーザーが中国語と英語で関連情報を見つけやすくします。
- 検索拡張チャットボットと質疑応答:効率的なバイリンガルカスタマーサービスボットを構築し、世界中の顧客とのやり取りを改善します。
- 自然言語処理アプリケーション:グローバル市場トレンドを理解するためのセンチメント分析、国際マーケティング戦略のためのトピックモデリング、グローバルコミュニケーション管理のためのテキスト分類などが含まれます。
- レコメンドシステム:中国語と英語のデータから得られた洞察を使用して、多様なグローバル視聴者向けに製品やコンテンツのレコメンドをカスタマイズします。
このモデルを活用することで、中国企業はAIアプリケーションにおける言語の壁を効果的に橋渡しし、グローバルな競争力と市場展開を強化できます。
tagAPIを通じてjina-embeddings-v2-base-zhを始める
Embeddings APIを通じて、すぐにモデルをワークフローに統合できます。Embeddings ポータルにアクセスし、無料のアクセスキーを取得するか既存のキーをチャージし、ドロップダウンメニューからjina-embeddings-v2-base-zhを選択するだけです。始めるのはこんなに簡単です!

tag今後の展開:言語サポートの拡大とAWS Sagemaker統合
jina-embeddings-v2-base-zhは近日中にAWS SagemakerとHugging Faceで利用可能になります。



Jina AIでは、グローバルな利用者向けの手頃な価格でアクセスしやすい埋め込み技術のリーダーであり続けることへの取り組みは揺るぎません。主要なヨーロッパ言語やその他の国際言語に焦点を当てた追加の多言語対応を積極的に開発しており、私たちの提供範囲を拡大しています。AWS SageMakerとの統合を含む、これらのエキサイティングなアップデートにご期待ください。
tagアーリーテスターへの特別な感謝
プレビューバージョン(jina-embeddings-v2-base-zh-preview)をテストしてくださった中国のユーザーコミュニティの選ばれたメンバーの皆様に深く感謝いたします。彼らの洞察に満ちたフィードバックは、この正式リリースのパフォーマンス向上に不可欠でした。私たちのモデルの品質に関する観察や提案がございましたら、ぜひDiscordサーバーにご参加いただき、ご意見をお聞かせください。皆様のご意見は、私たちの継続的な改善の旅において非常に貴重です。


スコア分布の改善 vs. jina-embeddings-v2-base-zh-preview
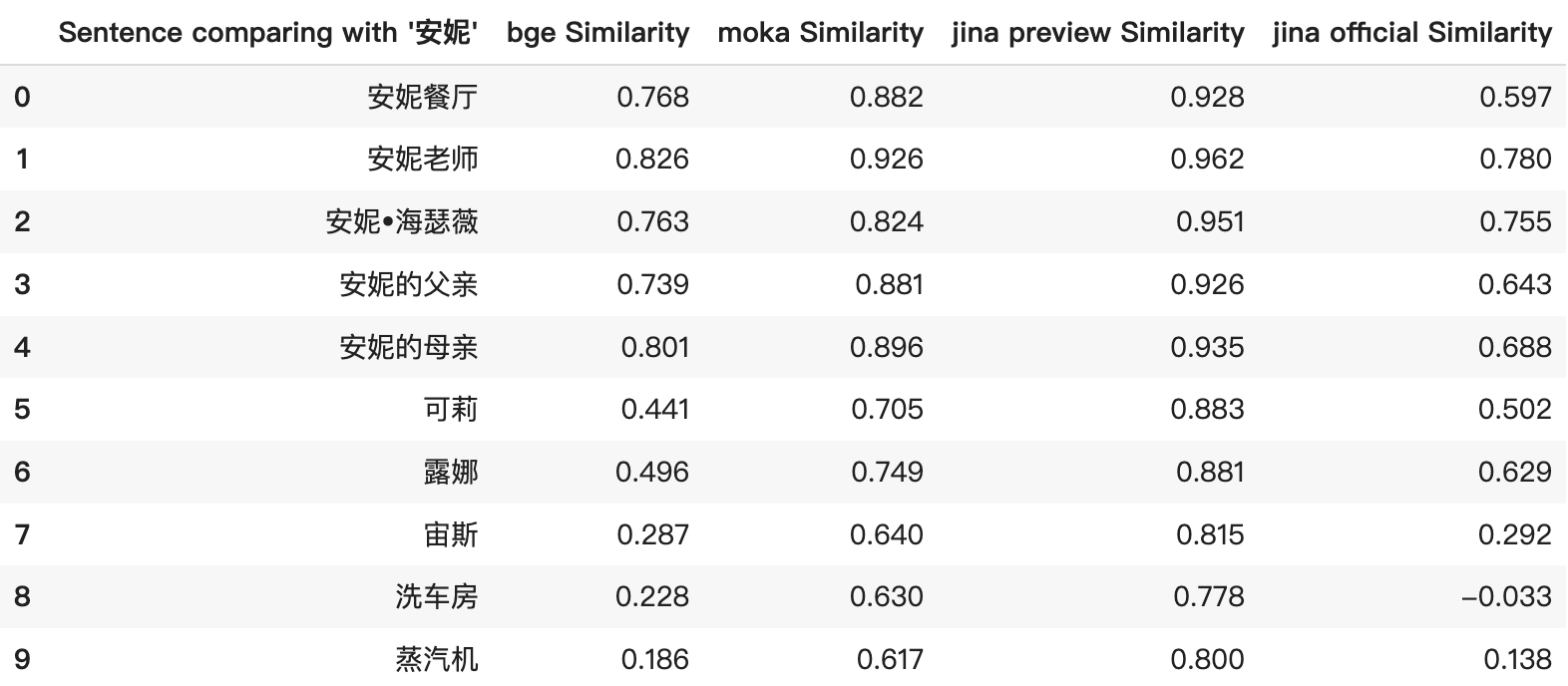
jina-embeddings-v2-base-zh-previewでは、類似度スコアが過度に高くなり、関連のないアイテム間でも高いコサイン類似度を示す問題がありました。これは以下のスクリーンショットのトップ5の結果で特に顕著でした。類似度スコアは一貫して高く、アイテム間の真の関係を正確に反映していませんでした。例えば、「安妮」と「蒸気機関」の比較で誤解を招くほど高い類似度スコアが出ていました。
正式リリースでは、モデルを微調整してより明確で論理的な類似度スコアを生成し、アイテム間の関係をより正確に表現できるようになりました。例えば、改訂されたスコアリングはより広い範囲を示し、アイテム間の相対的な類似性をより明確に理解できるようになっています。
さらに、Jina Embeddings は現在、8192トークンをサポートするオープンソースの埋め込みモデルとして唯一のものとなっています。この機能により、長文書から短いフレーズ、あるいは「安妮」対「露娜」のような個々の単語/名前まで、幅広いデータタイプを処理する能力が強調されています。
tag中英二言語対応8Kベクトル大規模モデルが新登場、グローバル展開企業に必携!
Embeddings V2が各界から好評を博して以来、本日、私たちは新しい中英二言語テキストベクトル大規模モデル:jina-embeddings-v2-base-zhをリリースしました。このモデルはV2の全ての利点を継承し、8000トークンまでのテキストを処理できるだけでなく、中国語と英語の二言語コンテンツにも流暢に対応し、言語間アプリケーションに新たな可能性をもたらします。
jina-embeddings-v2-base-zhが卓越した性能を発揮できるのは、質の高い二言語データセットと、厳密かつバランスの取れた事前学習、一次微調整、二次微調整のおかげです。この3ステップの学習パラダイムは、モデルの二言語能力を一般化しただけでなく、モデルのバイアスを効果的に軽減し、多言語モデルがしばしば直面する「均一性の欠如」という問題を解決しました。
tagモデルの特徴概要
特徴1:二言語のシームレスな連携
jina-embeddings-v2-base-zhモデルは、中国語と英語のテキストを流暢に処理でき、検索クエリでもターゲット文書でも対応可能です。中英テキストの意味が近い内容は同じベクトル空間にマッピングされ、多言語アプリケーションの強固な基盤を築きます。
特徴2:8k Tokenの超長文テキストサポート
当モデルは8K Tokenまでのテキスト処理をサポートしており、これはオープンソースベクトルモデルの中で他に類を見ない特徴で、より長いテキスト段落の処理に大きな優位性を提供します。
特徴3:効率的でコンパクトなモデル構造
jina-embeddings-v2-base-zhモデルは322MBのコンパクトなサイズ(1.61億パラメータを含む)で、出力次元は768となっており、一般的なコンピューターハードウェアで効率的に実行でき、GPUに依存することなく、その実用性と利便性を大きく向上させています。
tagモデルの卓越した性能
CMTEBランキングの激しい競争の中で、私たちのJina Embeddings v2モデルは0.5GB以下のモデルカテゴリーで際立っています。このモデルは中国語と英語のテキストをサポートするだけでなく、8K Tokenまでのテキストを処理できる能力を持っており、これは同クラスのモデルでは稀有な特徴です。
同サイズの中国語対応モデルの中で、Multilingual E5と私たちのjina-embeddings-v2-base-zhは英語を処理できる唯二のモデルであり、これにより言語間アプリケーションが可能になります。
現在、世界的に見ても、OpenAIのクローズドソースモデルtext-embedding-ada-002とJina Embeddingsのみが8k Tokenの長文入力をサポートしています。中国語タスクの処理においては、Jina Embeddingsが顕著な性能優位性を示しています。
tag中国企業のグローバルビジネス展開を支援
私たちの中英二言語ベクトルモデルjina-embeddings-v2-base-zhは、中国企業の国際市場進出における強力なパートナーです。中国語と英語の二言語テキストをシームレスに処理し、高品質なテキストベクトル表現を提供するだけでなく、先進的なベクトルデータベース、検索システム、RAGアプリケーションへの容易な統合が可能です。
このモデルは特に中英二言語シナリオに適応したAIアプリケーションの構築に適しており、グローバル展開を目指す企業にとって、その価値は計り知れません。以下は実際のアプリケーション事例です:
- 文書分析と管理:大量の文書を分析・管理し、国際的な法務や商取引の円滑な進行を支援。
- AI駆動型検索アプリケーション:多言語環境における検索性能を向上させ、グローバルユーザーが中国語と英語の関連情報を容易に見つけられるようサポート。
- 検索機能を強化したチャットボットとQ&Aシステム:効率的なバイリンガルカスタマーサービスボットを構築し、グローバル顧客とのコミュニケーション体験を最適化。
- 自然言語処理アプリケーション:グローバル市場トレンド分析、国際マーケティング戦略のトピックモデリング、そしてグローバルコミュニケーション管理のテキスト分類をカバー。
- レコメンデーションシステム:中国語と英語のデータインサイトを活用し、グローバルな多様な視聴者向けにパーソナライズされた製品とコンテンツを推奨。
このモデルにより、中国企業はAIアプリケーション分野で言語の壁を越え、グローバル市場での競争において先手を打つことができます。
tagjina-embeddings-v2-base-zh を簡単に始める
私たちのバイリンガル埋め込みモデルをワークフローに素早く組み込みたいですか?簡単な手順で始められます:https://jina.ai/embeddings にアクセスし、無料の API キーを取得するか既存のキーを更新し、ドロップダウンメニューから jina-embeddings-v2-base-zh を選択すれば、モデルはすぐに使用可能になり、あなたの探索を待っています!
tag将来の展望:多言語サポートと AWS SageMaker との深い統合
jina-embeddings-v2-base-zh は間もなく AWS SageMaker と HuggingFace で利用可能になり、ユーザーにさらに便利なサービスを提供します。
私たちは多言語埋め込みモデル、特にヨーロッパおよびその他の国際言語のサポートを積極的に推進し、グローバルユーザーの多様なニーズに応えています。AWS SageMaker との深い統合を含む、これから登場する exciting なアップデートにご期待ください。私たちはサービスの範囲を継続的に深化・拡大していきます。
tag謝辞:アーリーテスターの貴重な貢献に感謝
jina-embeddings-v2-base-zh-preview のテストに参加してくださった中国のコミュニティの皆様に心より感謝申し上げます。皆様の貴重なフィードバックは、モデルの最適化に重要な役割を果たしました。使用中に提案やアイデアがございましたら、いつでもお知らせください。皆様からのフィードバック一つ一つが、私たちの継続的な進歩の原動力となっています。
正式版ではプレビュー版のスコア膨張問題が解決されました
以前のプレビュー版モデルと比較して、正式版モデルではより分散した合理的な類似度スコアを提供しています。プレビュー版のテストでは、モデルは類似度スコアのインフレーション現象を示していました。「アンナ」と「蒸気機関」のような完全に無関係な単語でも、高いコサイン類似度を示していました。正式版では、モデルを最適化し、類似度スコアがより合理的になり、コンテンツ間の関係をより正確に反映するようになりました。
さらに、Jina Embeddings は現在、最大 8192 Token のテキスト処理をサポートしており、長文も短文も、さらには単語や名前(「アンナ」と「ルナ」の比較など)でも、様々なタイプのデータを処理する強力な能力を発揮します。この改善により、モデルの精度が向上しただけでなく、多様なデータを処理する際の柔軟性と実用性も向上しました。
