


AI モデルを理解する上では多くの壁があり、その中には非常に大きな壁もあり、AI プロセスの実装を妨げることがあります。しかし、多くの人が最初に直面するのは、トークンについて話すときの意味を理解することです。

AI 言語モデルを選択する際の最も重要な実用的なパラメータの一つは、コンテキストウィンドウのサイズ(最大入力テキストサイズ)です。これは単語や文字、その他の自動認識可能な単位ではなく、トークンで表されます。
さらに、埋め込みサービスは通常「トークンごと」に計算されるため、トークンは請求書を理解する上で重要です。
トークンが何であるかを明確に理解していない場合、これは非常に混乱する可能性があります。
しかし、現代の AI の中で混乱する側面の中で、トークンはおそらく最も単純なものです。この記事では、トークン化とは何か、何をするものか、なぜそのような方法を採用しているのかを明確にしていきます。
tag要約
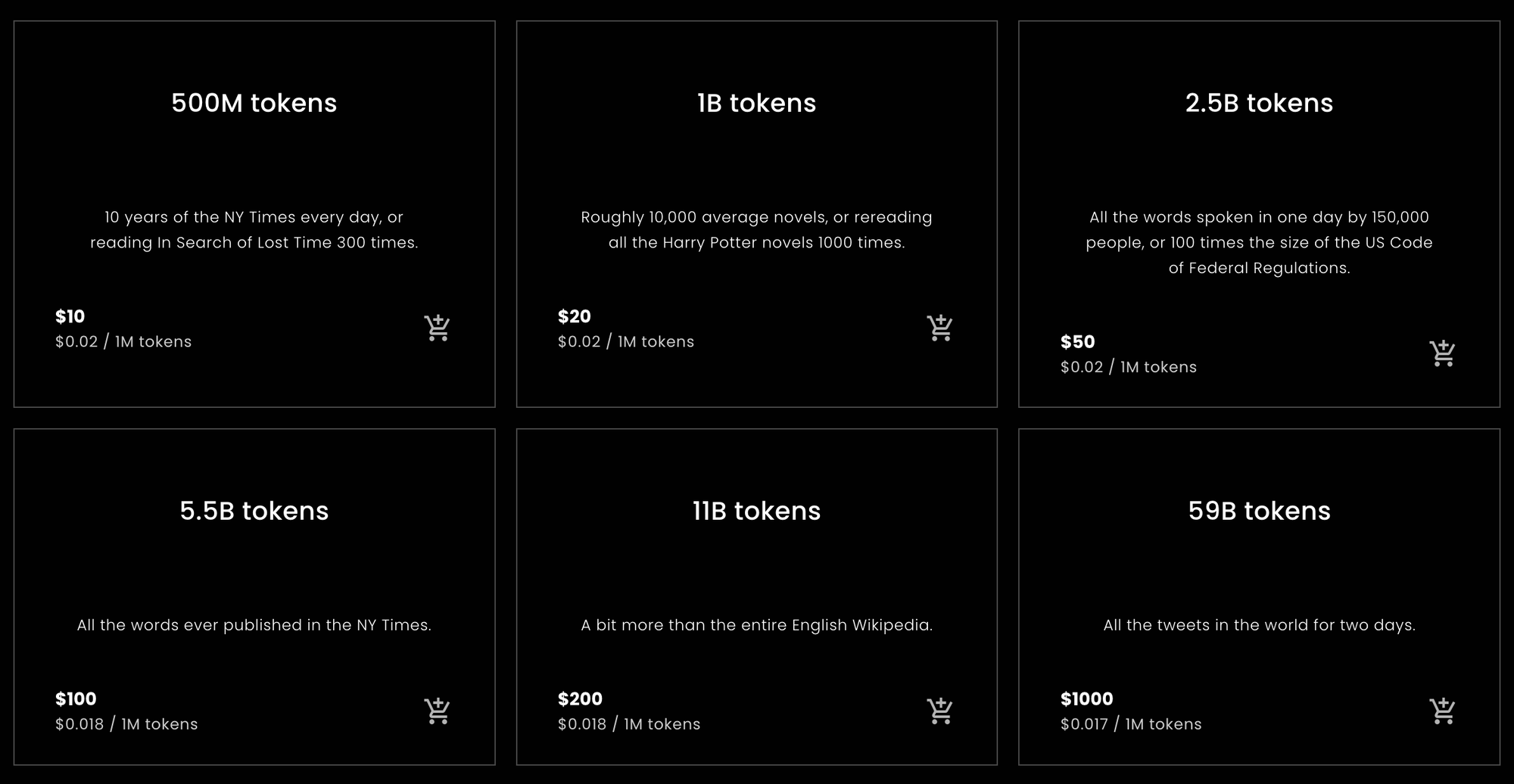
Jina Embeddings から購入するトークン数を素早く把握したい方、または必要なトークン数の見積もりを知りたい方のために、以下の統計情報を提供します。
tag英語の単語あたりのトークン数
この記事の後半で説明する実証テストでは、Jina Embeddings の英語専用モデルを使用して、さまざまな英語テキストをトークン化したところ、単語数に対してトークン数が約10%多くなるという結果が得られました。この結果はかなり安定していました。
Jina Embeddings v2 モデルのコンテキストウィンドウは 8192 トークンです。これは、Jina モデルに 7,400 語を超える英語テキストを渡すと、切り捨てられる可能性が高いことを意味します。
tag中国語の文字あたりのトークン数
中国語の場合、結果はより変動的です。テキストの種類によって、中国語の文字(漢字)1字あたり0.6から0.75トークンの比率で変動しました。中国語用 Jina Embeddings v2 に英語テキストを入力した場合は、英語用 Jina Embeddings v2 とほぼ同じ結果となり、単語数に対して約10%多いトークン数となります。
tagドイツ語の単語あたりのトークン数
ドイツ語の単語とトークンの比率は、英語よりも変動が大きいですが、中国語ほどではありません。テキストのジャンルによって、平均して単語数に対して20%から30%多いトークン数となりました。ドイツ語・英語用 Jina Embeddings v2 に英語テキストを入力した場合は、英語専用モデルや中国語/英語モデルよりもやや多くのトークンを使用し、単語数に対して12%から15%多いトークン数となります。
tag注意事項
これらは簡単な計算ですが、ほとんどの自然言語テキストとユーザーにとって、おおよそ正確なはずです。最終的に、トークン数は常にテキストの文字数に2を加えた数を超えないことのみを保証できます。実際にはそれよりもはるかに少なくなりますが、事前に特定のカウントを約束することはできません。
これらは統計的に単純な計算に基づく推定値です。特定のリクエストに必要なトークン数は保証できません。
Jina Embeddings のトークン購入に関するアドバイスだけが必要な場合は、ここで読み終えることができます。Jina AI 以外の企業の他の埋め込みモデルは、Jina モデルと同じトークンと単語、トークンと中国語文字の比率ではないかもしれませんが、全体的に大きな違いはないでしょう。
その理由を理解したい場合は、この記事の残りの部分で言語モデルのトークン化についてより深く掘り下げていきます。
tag単語、トークン、数字
トークン化は、現代の AI モデルが存在する以前から自然言語処理の一部でした。
コンピュータ上のすべてが単なる数字だというのはありふれた言い方かもしれませんが、それはほぼ事実です。しかし、言語は自然には単なる数字の集まりではありません。音波で構成される音声かもしれませんし、紙の上の記号かもしれません。あるいは印刷されたテキストの画像や手話を使用している人のビデオかもしれません。しかし、コンピュータで自然言語を処理する場合、ほとんどの場合、文字(a、b、c など)、数字(0、1、2...)、句読点、スペースで構成される文字列のことを指します。これらは異なる言語やテキストエンコーディングで表現されます。
コンピュータエンジニアはこれらを「文字列」と呼びます。
AI 言語モデルは入力として数字の列を受け取ります。例えば、次のような文を書いたとします:
What is today's weather in Berlin?
しかし、トークン化後、AI モデルは以下のような入力を受け取ります:
[101, 2054, 2003, 2651, 1005, 1055, 4633, 1999, 4068, 1029, 102]
トークン化とは、入力文字列を AI モデルが理解できる特定の数字の列に変換するプロセスです。
トークンごとに課金するウェブ API を通じて AI モデルを使用する場合、各リクエストは上記のような数字の列に変換されます。リクエストのトークン数は、その数字の列の長さです。したがって、英語用 Jina Embeddings v2 に「What is today's weather in Berlin?」の埋め込みを要求すると、11 トークンの料金がかかります。これは、その文を AI モデルに渡す前に 11 個の数字の列に変換したためです。
Transformer アーキテクチャに基づく AI モデルは、トークンで測定される固定サイズのコンテキストウィンドウを持っています。これは「入力ウィンドウ」「コンテキストサイズ」、または「シーケンス長」(特にHugging Face MTEB リーダーボードでは)とも呼ばれます。これはモデルが一度に処理できる最大テキストサイズを意味します。
したがって、埋め込みモデルを使用する場合、これが許可される最大入力サイズとなります。
Jina Embeddings v2 モデルはすべて 8,192 トークンのコンテキストウィンドウを持っています。他のモデルは異なる(通常はより小さい)コンテキストウィンドウを持つでしょう。これは、入力するテキストの量に関係なく、その Jina Embeddings モデルに関連付けられたトークナイザーは、8,192 トークン以下に変換する必要があることを意味します。
tag言語から数字へのマッピング
トークンのロジックを説明する最もシンプルな方法は以下の通りです:
自然言語モデルの場合、トークンが表す文字列の部分は、単語、単語の一部、または句読点です。スペースは一般的にトークナイザーの出力で明示的な表現を与えられません。
トークン化は、自然言語処理におけるテキスト分割と呼ばれる技術群の一部であり、トークン化を実行するモジュールは、非常に論理的にトークナイザーと呼ばれます。
トークン化の仕組みを示すために、最小の英語用 Jina Embeddings v2 モデル:jina-embeddings-v2-small-enを使用していくつかの文をトークン化してみましょう。Jina Embeddings の他の英語専用モデル — jina-embeddings-v2-base-en — は同じトークナイザーを使用するため、この記事で使用しない AI モデルの追加メガバイトをダウンロードする必要はありません。
まず、Python 環境またはノートブックにtransformersモジュールをインストールします。使用する-U フラグを使用して最新バージョンにアップグレードしてください。古いバージョンではこのモデルは動作しません:
pip install -U transformers
次に、AutoModel.from_pretrained を使用して jina-embeddings-v2-small-en をダウンロードします:
from transformers import AutoModel
model = AutoModel.from_pretrained('jinaai/jina-embeddings-v2-small-en', trust_remote_code=True)
文字列をトークン化するには、モデルの tokenizer メンバーオブジェクトの encode メソッドを使用します:
model.tokenizer.encode("What is today's weather in Berlin?")
結果は数値のリストです:
[101, 2054, 2003, 2651, 1005, 1055, 4633, 1999, 4068, 1029, 102]
これらの数値を文字列形式に戻すには、tokenizer オブジェクトの convert_ids_to_tokens メソッドを使用します:
model.tokenizer.convert_ids_to_tokens([101, 2054, 2003, 2651, 1005, 1055, 4633, 1999, 4068, 1029, 102])
結果は文字列のリストです:
['[CLS]', 'what', 'is', 'today', "'", 's', 'weather', 'in',
'berlin', '?', '[SEP]']
モデルのトークナイザーには以下の特徴があります:
- 先頭に
[CLS]、末尾に[SEP]を追加します。これは技術的な理由で必要であり、テキストが必要とするトークン数に加えて、埋め込みのリクエストごとに 2 つの追加トークンが必要になることを意味します。 - 句読点を単語から分離し、"Berlin?" を
berlinと?に、"today's" をtoday、'、sに分割します。 - すべてを小文字にします。すべてのモデルがこれを行うわけではありませんが、英語を使用する場合のトレーニングに役立ちます。大文字小文字の意味が異なる言語では、あまり有用ではないかもしれません。
異なるプログラムの異なる単語カウントアルゴリズムは、この文の単語数を異なる方法でカウントする可能性があります。OpenOffice では 6 単語としてカウントされます。Unicode テキストセグメンテーションアルゴリズム(Unicode Standard Annex #29)では 7 単語としてカウントされます。他のソフトウェアでは、句読点や "'s" のような接尾辞の扱い方によって、異なる数になる可能性があります。
このモデルのトークナイザーは、6~7 単語に対して 9 個のトークンを生成し、さらにすべてのリクエストに必要な 2 つの追加トークンを加えます。
では、ベルリンよりもあまり一般的ではない地名で試してみましょう:
token_ids = model.tokenizer.encode("I live in Kinshasa.")
tokens = model.tokenizer.convert_ids_to_tokens(token_ids)
print(tokens)
結果:
['[CLS]', 'i', 'live', 'in', 'kin', '##sha', '##sa', '.', '[SEP]']
"Kinshasa" という名前は 3 つのトークンに分解されています:kin、##sha、##sa。## はこのトークンが単語の先頭ではないことを示しています。
完全に未知の単語をトークナイザーに与えると、単語数に対するトークン数の比率はさらに増加します:
token_ids = model.tokenizer.encode("Klaatu barada nikto")
tokens = model.tokenizer.convert_ids_to_tokens(token_ids)
print(tokens)
['[CLS]', 'k', '##la', '##at', '##u', 'bar', '##ada', 'nik', '##to', '[SEP]']
3 つの単語が 8 つのトークンになり、さらに [CLS] と [SEP] トークンが追加されます。
ドイツ語のトークン化も同様です。Jina Embeddings v2 for German モデルを使用して、"What is today's weather in Berlin?" のドイツ語訳を英語モデルと同じ方法でトークン化できます。
german_model = AutoModel.from_pretrained('jinaai/jina-embeddings-v2-base-de', trust_remote_code=True)
token_ids = german_model.tokenizer.encode("Wie wird das Wetter heute in Berlin?")
tokens = german_model.tokenizer.convert_ids_to_tokens(token_ids)
print(tokens)
結果:
['<s>', 'Wie', 'wird', 'das', 'Wetter', 'heute', 'in', 'Berlin', '?', '</s>']
このトークナイザーは英語のものとは少し異なり、[CLS] と [SEP] の代わりに <s> と </s> を使用しますが、同じ機能を果たします。また、ドイツ語では英語とは異なる形で大文字小文字が意味を持つため、テキストの大文字小文字は正規化されません。
(この説明を簡単にするため、単語の始まりを示す特殊文字は省略しています。)
次に、新聞記事からより複雑な文を試してみましょう:
Ein Großteil der milliardenschweren Bauern-Subventionen bleibt liegen – zu genervt sind die Landwirte von bürokratischen Gängelungen und Regelwahn.
sentence = """
Ein Großteil der milliardenschweren Bauern-Subventionen
bleibt liegen – zu genervt sind die Landwirte von
bürokratischen Gängelungen und Regelwahn.
"""
token_ids = german_model.tokenizer.encode(sentence)
tokens = german_model.tokenizer.convert_ids_to_tokens(token_ids)
print(tokens)トークン化の結果:
['<s>', 'Ein', 'Großteil', 'der', 'mill', 'iarden', 'schwer',
'en', 'Bauern', '-', 'Sub', 'ventionen', 'bleibt', 'liegen',
'–', 'zu', 'gen', 'ervt', 'sind', 'die', 'Landwirte', 'von',
'büro', 'krat', 'ischen', 'Gän', 'gel', 'ungen', 'und', 'Regel',
'wahn', '.', '</s>']
ここでは、多くのドイツ語の単語がより小さな部分に分割されており、必ずしもドイツ語文法で認められた分割方法に従っているわけではありません。結果として、単語カウンターでは 1 単語としてカウントされる長いドイツ語の単語が、Jina の AI モデルでは任意の数のトークンになる可能性があります。
次に、中国語で "What is today's weather in Berlin?" を翻訳してみましょう:
柏林今天的天气怎么样?
chinese_model = AutoModel.from_pretrained('jinaai/jina-embeddings-v2-base-zh', trust_remote_code=True)
token_ids = chinese_model.tokenizer.encode("柏林今天的天气怎么样?")
tokens = chinese_model.tokenizer.convert_ids_to_tokens(token_ids)
print(tokens)
トークン化の結果:
['<s>', '柏林', '今天的', '天气', '怎么样', '?', '</s>']
中国語では通常、書き言葉に単語の区切りはありませんが、Jina Embeddings のトークナイザーは複数の漢字をまとめることが多くあります:
| Token string | Pinyin | Meaning |
|---|---|---|
| 柏林 | Bólín | Berlin |
| 今天的 | jīntiān de | today's |
| 天气 | tiānqì | weather |
| 怎么样 | zěnmeyàng | how |
香港の新聞からより複雑な文を試してみましょう:
sentence = """
新規定執行首日,記者在下班高峰前的下午5時來到廣州地鐵3號線,
從繁忙的珠江新城站啟程,向機場北方向出發。
"""
token_ids = chinese_model.tokenizer.encode(sentence)
tokens = chinese_model.tokenizer.convert_ids_to_tokens(token_ids)
print(tokens)
(訳:『新しい規制が施行された初日の午後5時、記者は広州地下鉄3号線の珠江新城駅から空港方面に向かう電車に乗り込みました。ラッシュアワーの最中でした。』)
結果:
['<s>', '新', '規定', '執行', '首', '日', ',', '記者', '在下', '班',
'高峰', '前的', '下午', '5', '時', '來到', '廣州', '地', '鐵', '3',
'號', '線', ',', '從', '繁忙', '的', '珠江', '新城', '站', '啟',
'程', ',', '向', '機場', '北', '方向', '出發', '。', '</s>']
これらのトークンは中国語の特定の辞書(词典)にマッピングされているわけではありません。例えば、"啟程"(出発する、旅立つ)は通常一つの単語として分類されますが、ここでは2つの構成文字に分割されています。同様に、"在下班"は通常2つの単語として認識され、"在"(~において)と"下班"(退勤時間)の間で分割されるはずですが、トークナイザーは"在下"と"班"の間で分割しています。
3つの言語すべてにおいて、トークナイザーがテキストを分割する場所は、人間の読者が論理的に分割する場所とは直接関係ありません。
これは Jina Embeddings モデルに特有の機能ではありません。このトークン化アプローチは AI モデル開発においてほぼ普遍的です。2つの異なる AI モデルが同一のトークナイザーを持つとは限りませんが、現在の開発状況では、実質的にすべてのモデルがこのような動作をするトークナイザーを使用しています。
次のセクションでは、トークン化に使用される具体的なアルゴリズムとその背後にある論理について説明します。
tagなぜトークン化するのか?そしてなぜこの方法なのか?
AI 言語モデルは、テキストシーケンスを表す数値のシーケンスを入力として受け取りますが、基礎となるニューラルネットワークを実行し埋め込みを作成する前に、もう少し処理が行われます。小さなテキストシーケンスを表す数値のリストが与えられると、モデルは各数値に対して内部辞書で一意のベクトルを検索します。それらを組み合わせてニューラルネットワークへの入力とします。
これは、トークナイザーが与えられたあらゆる入力テキストを、モデルのトークンベクトル辞書に存在するトークンに変換しなければならないことを意味します。従来の辞書からトークンを取得した場合、スペルミスや珍しい固有名詞、外国語に初めて遭遇した時点でモデル全体が停止してしまいます。その入力を処理できなくなってしまいます。
自然言語処理では、これは語彙外(OOV)問題と呼ばれ、あらゆるテキストタイプとあらゆる言語で広く見られます。OOV 問題に対処するには、いくつかの戦略があります:
- 無視する。辞書にないものはすべて「不明」トークンに置き換える。
- 回避する。テキストシーケンスをベクトルにマッピングする辞書の代わりに、個々の文字をベクトルにマッピングする辞書を使用する。英語は主に26文字しか使用しないため、これは任意の辞書よりも小さく、OOV 問題に対してより堅牢でなければならない。
- テキスト内の頻出する部分シーケンスを見つけて辞書に入れ、残りの部分には文字(単一文字トークン)を使用する。
最初の戦略では、多くの重要な情報が失われます。辞書にない形式のデータについて、モデルは学習すらできません。通常のテキストには、最大の辞書でさえ含まれていないものが多くあります。
2番目の戦略は可能で、研究者も調査しています。しかし、モデルがより多くの入力を受け入れ、より多くを学習しなければならないことを意味します。これは3番目の戦略よりも良い結果が得られなかった上に、はるかに大きなモデルとより多くのトレーニングデータが必要になります。
AI 言語モデルは、ほぼすべてが何らかの形で3番目の戦略を実装しています。ほとんどは Wordpiece アルゴリズム [Schuster and Nakajima 2012] のバリエーションか、Byte-Pair Encoding(BPE)と呼ばれる同様の技術を使用しています。[Gage 1994、Senrich et al. 2016] これらのアルゴリズムは言語に依存しません。つまり、可能な文字の包括的なリスト以外の知識なしに、すべての書き言葉に対して同じように機能します。Google の BERT のような多言語モデル向けに設計されており、インターネットからスクレイピングした入力(何百もの言語やコンピュータプログラムのような人間の言語以外のテキスト)を、複雑な言語学的処理なしにトレーニングできるようになっています。
より言語特有で言語を認識するトークナイザーを使用することで、大幅な改善が見られるという研究もあります。[Rust et al. 2021] しかし、そのようなトークナイザーの構築には時間、お金、専門知識が必要です。BPE や Wordpiece のような普遍的な戦略を実装する方が、はるかに安価で容易です。
しかし結果として、特定のテキストが何個のトークンを表すかを知る方法は、トークナイザーを実行してから出力されたトークンの数を数える以外にありません。テキストの最小の部分シーケンスは1文字なので、トークンの数は文字数(スペースを除く)に2を加えた数を超えることはないと確信できます。
良い推定値を得るには、多くのテキストをトークナイザーに投入し、入力した単語数や文字数と比較して、平均して何個のトークンが得られるかを経験的に計算する必要があります。次のセクションでは、現在利用可能なすべての Jina Embeddings v2 モデルについて、あまり体系的ではない経験的な測定を行います。
tagトークン出力サイズの経験的推定
英語とドイツ語については、Unicode テキストセグメンテーションアルゴリズム(Unicode Standard Annex #29)を使用して単語数を取得しました。このアルゴリズムは、ダブルクリックで何かを選択する際のテキスト断片の選択に広く使用されています。これが利用可能な普遍的で客観的な単語カウンターに最も近いものです。
Python で polyglot ライブラリをインストールしました。このライブラリはこのテキストセグメンターを実装しています:
pip install -U polyglot
テキストの単語数を取得するには、このようなコードスニペットを使用できます:
from polyglot.text import Text
txt = "What is today's weather in Berlin?"
print(len(Text(txt).words))
結果は 7 になるはずです。
トークン数を取得するために、テキストの各セグメントを以下に説明する様々な Jina Embeddings モデルのトークナイザーに渡し、その都度、返されたトークン数から2を引きました。
tag英語
(jina-embeddings-v2-small-en および jina-embeddings-v2-base-en)
平均値を計算するために、Wortschatz Leipzigから2つの英語テキストコーパスをダウンロードしました。これはライプツィヒ大学がホストする、多数の言語と設定で自由にダウンロード可能なコーパスのコレクションです:
- 2020年の英語ニュースデータから100万文のコーパス(
eng_news_2020_1M) - 2016年の英語Wikipediaデータから100万文のコーパス(
eng_wikipedia_2016_1M)
どちらも英語のダウンロードページで見つけることができます。
多様性のために、Project Gutenberg からHapgood によるビクトル・ユーゴーの『レ・ミゼラブル』の翻訳と、1611年に英語に翻訳された欽定訳聖書のコピーもダウンロードしました。
4つのテキストすべてについて、polyglotで実装された Unicode セグメンターを使用して単語数を数え、次に jina-embeddings-v2-small-en で作成されたトークンを数え、各トークン化リクエストから2つのトークンを引きました。結果は以下の通りです:
| テキスト | 単語数 (Unicode セグメンター) | トークン数 (Jina Embeddings v2 英語用) | トークン数/単語数の比率 (小数点以下3桁) |
|---|---|---|---|
eng_news_2020_1M | 22,825,712 | 25,270,581 | 1.107 |
eng_wikipedia_2016_1M | 24,243,607 | 26,813,877 | 1.106 |
les_miserables_en | 688,911 | 764,121 | 1.109 |
kjv_bible | 1,007,651 | 1,099,335 | 1.091 |
正確な数値を使用していることは、これが正確な結果であることを意味するわけではありません。このように異なるジャンルの文書がすべて単語数よりもトークン数が 9% から 11% 多いということは、Unicode セグメンターで計測した場合、単語数よりもトークン数が約 10% 多くなると予想できることを示しています。ワードプロセッサは多くの場合句読点をカウントしませんが、Unicode セグメンターはカウントするため、オフィスソフトウェアの単語数とは必ずしも一致しないと考えられます。
tagドイツ語
(jina-embeddings-v2-base-de)
ドイツ語については、Wortschatz Leipzig のドイツ語ページから 3 つのコーパスをダウンロードしました:
deu_mixed-typical_2011_1M— 2011 年時点の異なるジャンルのテキストをバランスよく混合した 100 万文。deu_newscrawl-public_2019_1M— 2019 年のニューステキスト 100 万文。deu_wikipedia_2021_1M— 2021 年のドイツ語版 Wikipedia から抽出した 100 万文。
さらに多様性を持たせるため、Deutsches Textarchivからカール・マルクスの『資本論』全 3 巻もダウンロードしました。
そして英語と同じ手順で処理を行いました:
| テキスト | 単語数 (Unicode セグメンター) | トークン数 (Jina Embeddings v2 ドイツ語および英語用) | トークン数/単語数の比率 (小数点以下 3 桁) |
|---|---|---|---|
deu_mixed-typical_2011_1M | 7,924,024 | 9,772,652 | 1.234 |
deu_newscrawl-public_2019_1M | 17,949,120 | 21,711,555 | 1.210 |
deu_wikipedia_2021_1M | 17,999,482 | 22,654,901 | 1.259 |
marx_kapital | 784,336 | 1,011,377 | 1.289 |
これらの結果は英語専用モデルよりもばらつきが大きいものの、ドイツ語のテキストは平均して単語数よりもトークン数が 20% から 30% 多くなることを示唆しています。
英語のテキストは、ドイツ語・英語トークナイザーを使用すると、英語専用のものよりも多くのトークンが生成されます:
| テキスト | 単語数 (Unicode セグメンター) | トークン数 (Jina Embeddings v2 ドイツ語および英語用) | トークン数/単語数の比率 (小数点以下 3 桁) |
|---|---|---|---|
eng_news_2020_1M | 24243607 | 27758535 | 1.145 |
eng_wikipedia_2016_1M | 22825712 | 25566921 | 1.120 |
バイリンガルのドイツ語/英語で英語のテキストを埋め込む場合、英語専用のものと比べてトークン数が 12% から 15% 多くなると予想されます。
tag中国語
(jina-embeddings-v2-base-zh)
中国語は通常スペースなしで書かれ、20 世紀以前は「単語」という概念が伝統的にありませんでした。そのため、中国語のテキストの長さは通常、文字数(字数)で測られます。そこで、Unicode セグメンターを使用する代わりに、すべてのスペースを削除してから文字数を取得して中国語のテキストの長さを測定しました。
Wortschatz Leipzig の中国語コーパスページから 3 つのコーパスをダウンロードしました:
zho_wikipedia_2018_1M— 2018 年に抽出された中国語版 Wikipedia からの 100 万文。zho_news_2007-2009_1M— 2007 年から 2009 年にかけて収集された中国語ニュースソースからの 100 万文。zho-trad_newscrawl_2011_1M— 繁体字(繁體字)のみを使用するニュースソースからの 100 万文。
さらに多様性を持たせるため、魯迅(魯迅)による 1920 年代初頭の中編小説『阿 Q 正伝』(阿Q正傳)も使用しました。Project Gutenberg から繁体字版をダウンロードしました。
| テキスト | 文字数 (字数) | トークン数 (Jina Embeddings v2 中国語および英語用) | トークン数/文字数の比率 (小数点以下 3 桁) |
|---|---|---|---|
zho_wikipedia_2018_1M | 45,116,182 | 29,193,028 | 0.647 |
zho_news_2007-2009_1M | 44,295,314 | 28,108,090 | 0.635 |
zho-trad_newscrawl_2011_1M | 54,585,819 | 40,290,982 | 0.738 |
Ah_Q | 41,268 | 25,346 | 0.614 |
トークンと文字の比率のこのようなばらつきは予想外であり、特に繁体字コーパスにおける外れ値についてはさらなる調査が必要です。それでも、中国語の場合、テキストの文字数よりも少ないトークンで済むと結論付けることができます。コンテンツによっては、25%から40%少なくて済むと予想できます。
Jina Embeddings v2 の中国語と英語モデルにおける英語テキストは、英語のみのモデルとほぼ同じ数のトークンを生成しました:
| Text | Word count (Unicode Segmenter) | Token count (Jina Embeddings v2 for Chinese and English) | Ratio of tokens to words (to 3 decimal places) |
|---|---|---|---|
eng_news_2020_1M | 24,243,607 | 26,890,176 | 1.109 |
eng_wikipedia_2016_1M | 22,825,712 | 25,060,352 | 1.097 |
tagトークンを真剣に考える
トークンは AI 言語モデルにとって重要な足場であり、この分野では研究が進行中です。
AI モデルが革新的だと証明された点の1つは、ノイズの多いデータに対して非常に頑健であることです。特定のモデルが最適なトークン化戦略を使用していない場合でも、ネットワークが十分に大きく、十分なデータがあり、適切に訓練されていれば、不完全な入力から正しい処理を学習することができます。
その結果、他の分野と比べてトークン化の改善にはあまり労力が費やされていませんが、これは変わる可能性があります。
埋め込みのユーザーとして、Jina Embeddings のような API を通じて購入する場合、特定のタスクに必要なトークン数を正確に知ることはできず、確実な数字を得るために独自のテストが必要になる場合があります。しかし、ここで提供された見積もり — 英語の場合は単語数の約110%、ドイツ語の場合は単語数の約125%、中国語の場合は文字数の約70% — は、基本的な予算計画には十分なはずです。
