


深夜、警官が街灯の下で手と膝をついて這いまわっている酔っ払いを見つけました。酔っ払いは財布を探していると警官に告げます。警官が本当にここで財布を落としたのか確認すると、男は道路の向こう側で落としたと思うと答えます。困惑した警官が、ではなぜここを探しているのかと尋ねると、酔っ払いは「ここの方が明るいからです」と説明しました。
David H. Friedman, Why Scientific Studies Are So Often Wrong: The Streetlight Effect, Discover magazine, Dec. 2010
ベンチマークは現代の機械学習の実践における重要な要素として長く存在してきましたが、深刻な問題があります:私たちのベンチマークが実際に有用なものを測定しているのかどうかがわからないのです。
これは大きな問題であり、この記事ではその解決策の一部として AIR-Bench を紹介します。Beijing Academy of Artificial Intelligence との共同プロジェクトであるこれは、ベンチマークの質と有用性を向上させることを目的とした AI 評価の新しいアプローチです。


tag街灯効果
科学的および運用研究では測定に大きな重点が置かれていますが、測定は単純なものではありません。健康に関する研究では、ある薬物や治療が受けた人の健康を改善したか、寿命を延ばしたか、またはその状態を何らかの形で改善したかを知りたいと思うでしょう。しかし、健康や生活の質の向上を直接測定することは難しく、治療が誰かの寿命を延ばしたかどうかを知るには何十年もかかる可能性があります。
そこで研究者は代理指標を使用します。健康研究では、それは体力や痛みの軽減、血圧の低下など、簡単に測定できる変数かもしれません。健康研究における問題の1つは、その代理指標が、薬物や治療に期待する健康上の改善を本当に示しているかどうかわからないことです。
測定とは、あなたにとって重要な有用なものの代理指標です。その物事そのものは測定できないかもしれないので、代わりに測定可能な別のもの、つまり本当に気にかけている有用なものと相関関係があると信じられる何かを測定するのです。
測定に焦点を当てることは20世紀の運用研究の主要な発展であり、深遠かつ肯定的な影響をもたらしました。1980年代の日本の経済的優位性の確立に貢献したとされる Total Quality Management は、ほぼ完全に代理変数の継続的な測定とそれに基づく実践の最適化に関するものです。
しかし、測定に焦点を当てることには、いくつかの既知の大きな問題があります:
- 測定に基づいて意思決定を行うと、その測定が良い代理指標でなくなる可能性があります。
- 何も改善しないのに測定値を膨らませる方法が存在することがあり、不正の可能性や、役に立たないことをしているのに進歩していると信じてしまう可能性があります。
この問題が原因で、医学研究の大部分が間違っている可能性があると考える人もいます。測定可能なものと実際の目標との間の乖離は、ベトナム戦争におけるアメリカの惨事の理由として挙げられる要因の1つです。
これは時に「街灯効果」と呼ばれ、この記事の冒頭の話のように、酔っ払いが物を落とした場所ではなく、明るい場所で探すという話に由来します。代理測定とは、見たいものを照らす光がないため、光のある場所を探すようなものです。
より専門的な文献では、「街灯効果」は通常、グッドハートの法則と結びついています。これはイギリスの経済学者 Charles Goodhart による、繁栄の代理指標を重視したサッチャー政権への批判に由来します。グッドハートの法則にはいくつかの定式化がありますが、以下が最も広く引用されているものです:
目標となる測定は、すべて悪い測定になる[...]
Keith Hoskins, 1996 The 'awful idea of accountability': inscribing people into the measurement of objects.
AI における有名な例として、機械翻訳研究で使用される BLEU メトリックがあります。2001年に IBM で開発された BLEU は、機械翻訳システムの評価を自動化する方法で、2000年代の機械翻訳ブームの重要な要因となりました。システムにスコアを付けることが容易になると、それを改善することができるようになりました。そして BLEU スコアは着実に向上しました。2010年までには、他のシステムが上手く扱えない特定の問題をどれだけ革新的に扱えるかに関係なく、最先端の BLEU スコアを上回らない限り、機械翻訳に関する研究論文をジャーナルや学会で発表することはほぼ不可能になっていました。
学会で発表する最も簡単な方法は、モデルのパラメータを少し調整して Google Translate よりわずかに高い BLEU スコアを得て、それを提出することでした。これらの結果は本質的に無意味でした。新しいテキストで翻訳させてみると、最先端のシステムよりも優れていることはほとんどなく、むしろ劣っていることが多かったのです。
BLEU を機械翻訳の進歩を評価するために使用する代わりに、より良い BLEU スコアを得ることが目標になってしまいました。そうなった時点で、進歩を評価する有用な方法ではなくなったのです。
tag私たちの AI ベンチマークは良い代理指標なのか?
埋め込みモデルで最も広く使用されているベンチマークは MTEB テストセットで、56の特定のテストで構成されています。これらはカテゴリごとに平均化され、全体でクラス固有のスコアを生成します。執筆時点での MTEB リーダーボードのトップは次のようになっています:
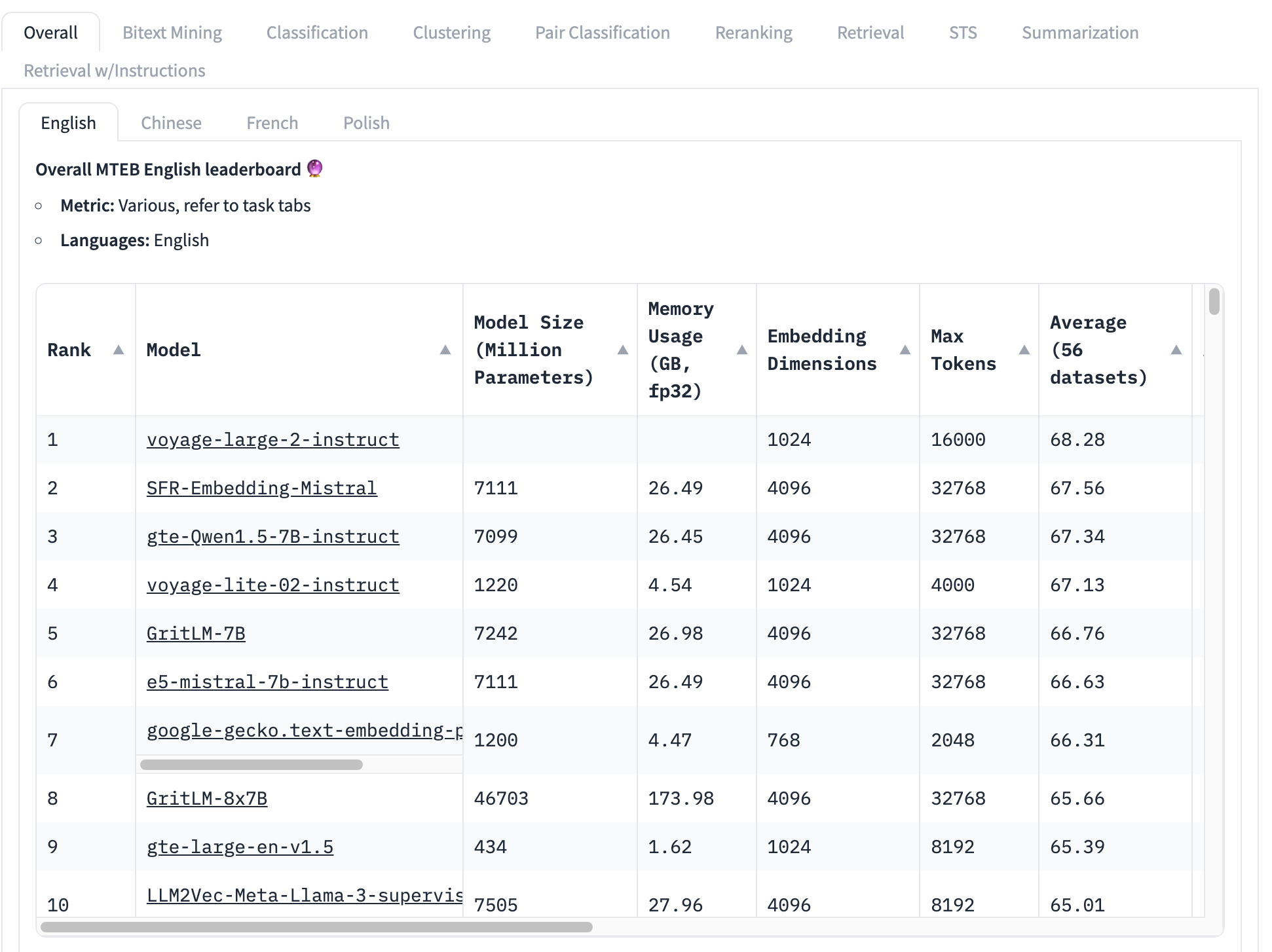
トップランクの埋め込みモデルの総合平均スコアは 68.28、次に高いのは 67.56 です。この表を見ただけでは、それが大きな差なのかどうかを知ることは非常に難しいです。もしそれが小さな差であれば、最高スコアを持つモデル以外の要因がより重要かもしれません:
- モデルサイズ: モデルにはサイズの違いがあり、それは計算リソースの要求の違いを反映しています。小さなモデルは速く実行でき、メモリ使用量が少なく、より安価なハードウェアで済みます。このトップ10リストでは、4億3400万パラメータから460億以上まで - 100倍もの差があります!
- 埋め込みサイズ: 埋め込みの次元数は様々です。次元数が小さいほど、埋め込みベクトルのメモリと保存容量が少なくなり、ベクトルの比較(埋め込みの主要な用途)がはるかに速くなります。このリストでは、768から4096までの埋め込み次元が見られます - 5倍の差ですが、商用アプリケーションを構築する際には依然として重要です。
- コンテキスト入力ウィンドウサイズ: コンテキストウィンドウは、2048トークンから32768トークンまでサイズと品質が異なります。さらに、モデルによって位置エンコーディングと入力管理のアプローチが異なり、入力の特定の部分に対するバイアスを生む可能性があります。
つまり、総合平均は、どの埋め込みモデルが最適かを判断するには非常に不完全な方法なのです。
以下の検索タスクに特化したスコアを見ても、同じ問題に直面します。このテストセットでモデルがどんなスコアを得ても、あなたの特定の固有のユースケースに対してどのモデルが最も良いパフォーマンスを発揮するかを知る方法はありません。
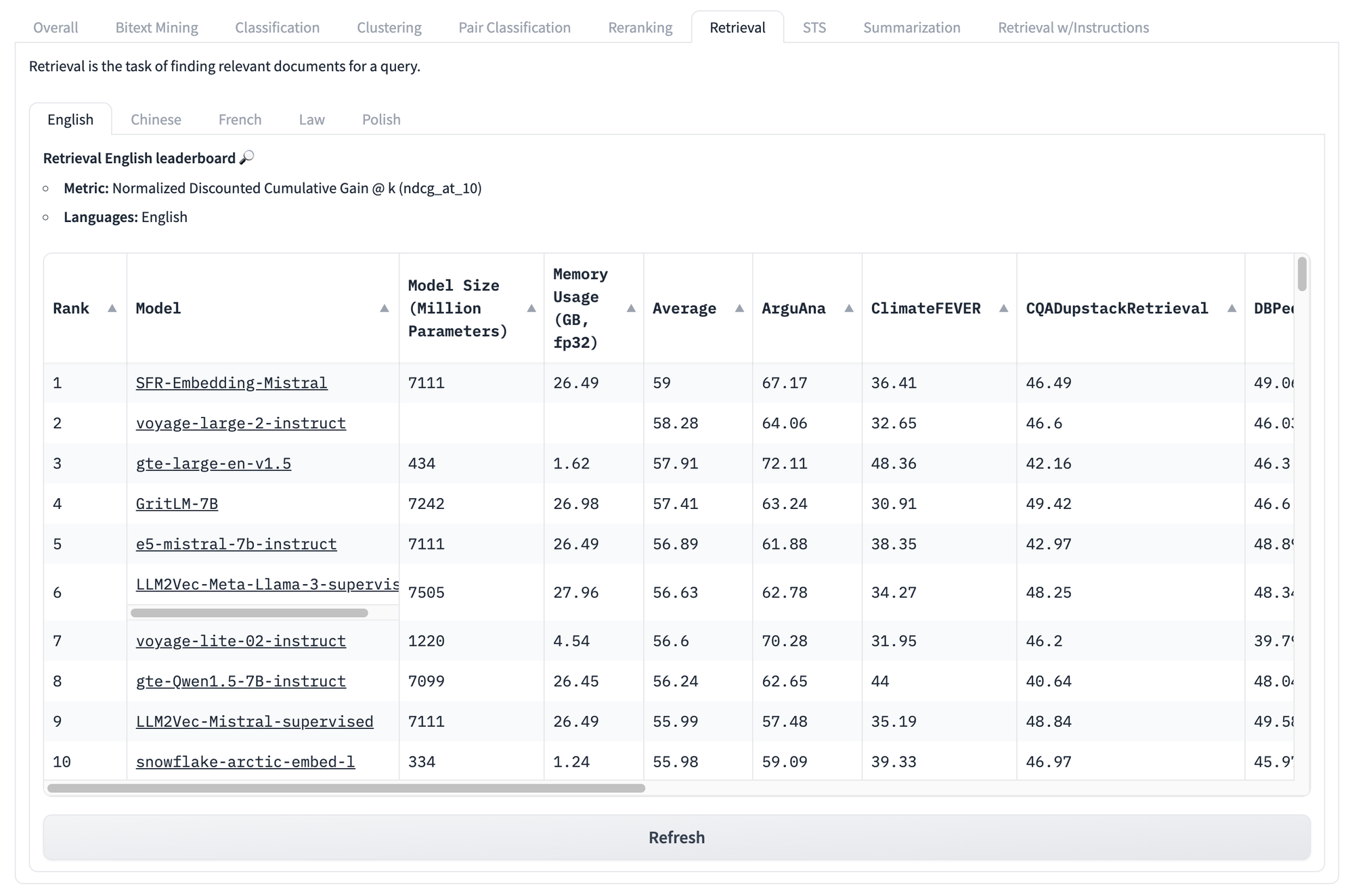
しかし、このような種類のベンチマークの問題はそれだけではありません。
グッドハートの法則の主な洞察は、意図的でなくても指標は常に操作される可能性があるということです。例えば、MTEB ベンチマークは、トレーニングデータに含まれている可能性が高い公開ソースからのデータで構成されています。ベンチマークデータをトレーニングから除外するよう特別に取り組まない限り、ベンチマークスコアは統計的に不適切なものとなります。
単純で包括的な解決策はありません。ベンチマークは代用指標であり、私たちが知りたいけれど直接測定できないことを本当に反映しているかどうかを確実に知ることはできません。
しかし、AI ベンチマークには私たちが軽減できる3つの主要な問題があります:
- ベンチマークは本質的に固定的:同じタスクで同じテキストを使用
- ベンチマークは汎用的:実際のシナリオについてはあまり有用な情報を提供しない
- ベンチマークは柔軟性に欠ける:多様なユースケースに対応できない
AI はこのような問題を引き起こしますが、時には解決策も生み出します。少なくとも AI ベンチマークに影響を与えるこれらの問題に対して、AI モデルを使用して対処できると私たちは考えています。
tagAI でAI をベンチマークする:AIR-Bench
AIR-Bench はオープンソースで、MIT ライセンスの下で利用可能です。GitHub のリポジトリからコードを閲覧またはダウンロードできます。
 AIR-Bench
AIR-Benchtag何をするのか?
AIR-Bench は AI ベンチマークに重要な機能をもたらします:
- 検索と RAG アプリケーションに特化
このベンチマークは、現実的な情報検索アプリケーションと検索拡張生成パイプラインに向けて設計されています。 - ドメインと言語の柔軟性
AIR を使用すると、ドメイン固有のデータや他の言語、さらには独自のタスク固有のデータからベンチマークを作成することがはるかに容易になります。 - 自動データ生成
AIR-Bench はテストデータを生成し、データセットは定期的に更新され、データ漏洩のリスクを軽減します。
tagHuggingFace の AIR-Bench リーダーボード
私たちは、MTEB のリーダーボードと同様に、現在リリースされている AIR-Bench 生成タスク用のリーダーボードを運営しています。ベンチマークを定期的に再生成し、新しいものを追加し、より多くの AI モデルへのカバレッジを拡大していく予定です。

tagどのように機能するのか?
AIR アプローチの核心的な洞察は、大規模言語モデル(LLM)を使用して、トレーニングセットに含まれ得ない新しいテキストと新しいタスクを生成できるということです。
AIR-Bench は、LLM の創造的能力を活用してシナリオを展開します。ユーザーはドキュメントのコレクション(一部のモデルのトレーニングデータに含まれている可能性のある実際のもの)を選択し、定義された役割を持つユーザーと、そのドキュメントコーパスを使用する必要がある状況を想定します。

その後、ユーザーはコーパスからドキュメントを選択し、ユーザープロファイルと状況の説明とともに LLM に渡します。LLM は、そのユーザーと状況に適切で、そのドキュメントを見つけるべきクエリを作成するようプロンプトされます。
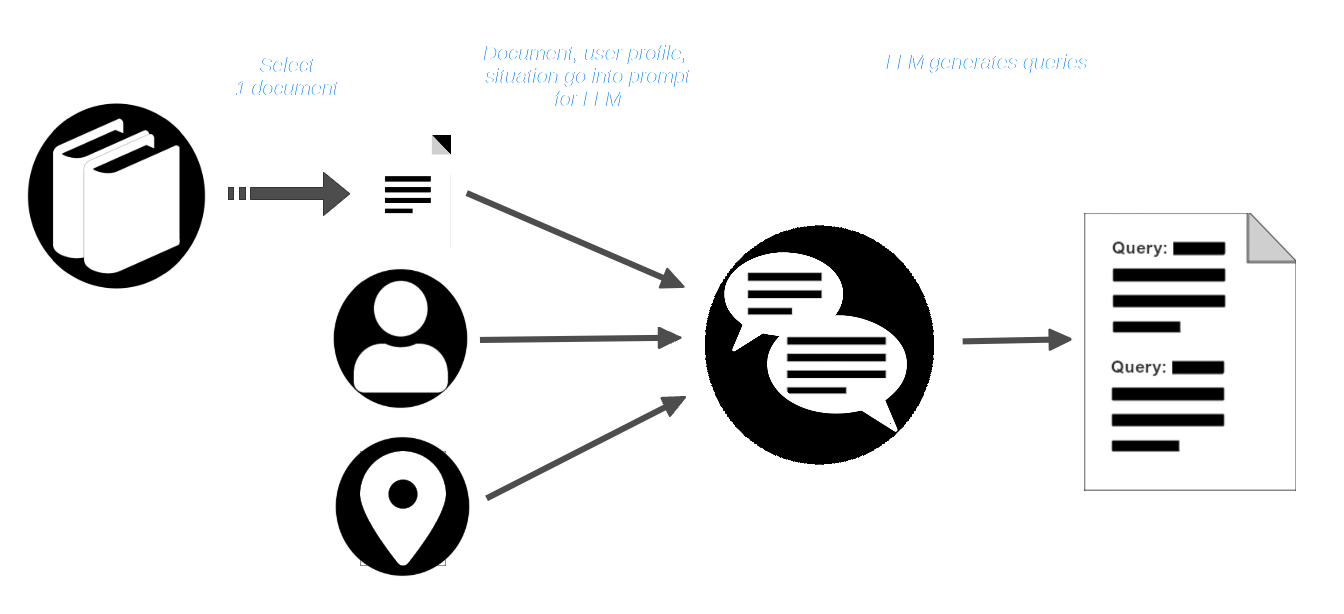
AIR-Bench パイプラインは、ドキュメントとクエリで LLM にプロンプトを与え、提供されたものと類似しているが、クエリにマッチすべきではない合成ドキュメントを作成します。
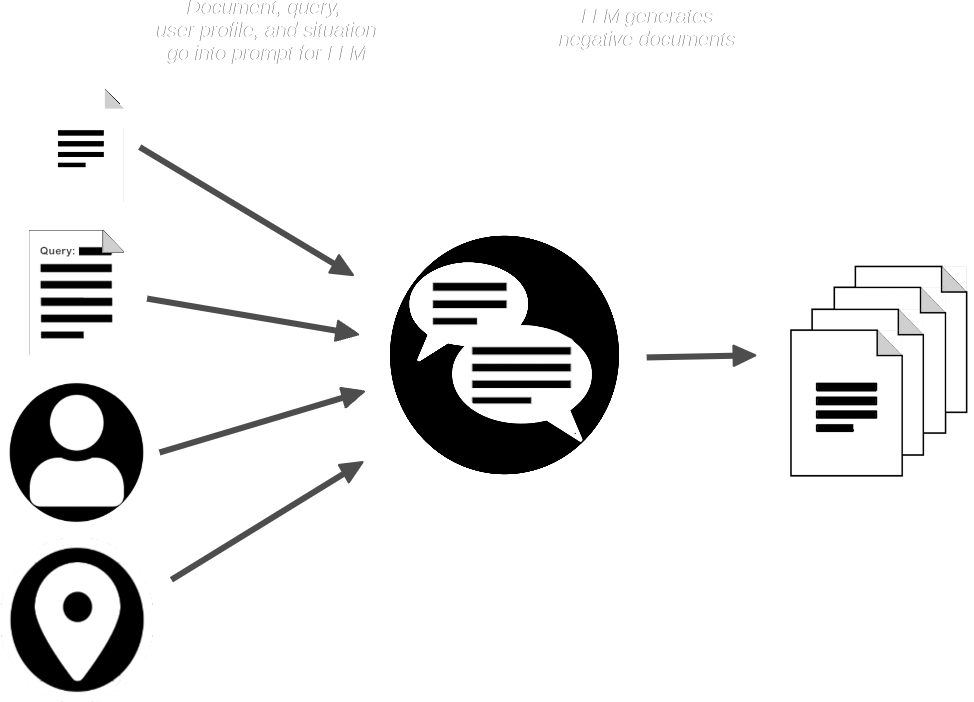
これで以下のものが得られます:
- クエリのコレクション
- 各クエリに対応する実際のドキュメント
- マッチしないと予想される合成ドキュメントの小さなコレクション
AIR-Bench は合成ドキュメントを実際のドキュメントのコレクションとマージし、1つまたは複数の埋め込みモデルとリランカーモデルを使用して、クエリが一致するドキュメントを検索できるはずであることを検証します。また、LLM を使用して、各クエリが検索すべきドキュメントに関連していることを検証します。
この AI 中心の生成と品質管理プロセスの詳細については、GitHub の AIR-Bench リポジトリにあるデータ生成ドキュメントをお読みください。
AIR-Benchその結果、高品質なクエリとマッチのペア、およびそれらを実行するための半合成データセットが生成されます。元の実際のドキュメントコレクションが学習の一部を形成していたとしても、追加された合成ドキュメントとクエリ自体は、以前に学習できなかった新しいデータとなります。
tagドメイン固有のベンチマークと現実に基づくテスト
クエリとドキュメントを合成することで、ベンチマークデータが学習に漏れることを防ぐだけでなく、汎用的なベンチマークの問題にも大きく対処できます。
AIR-Bench は、選択されたデータ、ユーザープロファイル、シナリオを LLM に提供することで、特定のユースケース向けのベンチマークを非常に簡単に構築できます。さらに、特定のユーザータイプと使用シナリオに合わせてクエリを構築することで、従来のベンチマークよりも実際の使用状況に近いテストクエリを生成できます。LLM の限られた創造性と想像力は実世界のシナリオと完全に一致しないかもしれませんが、研究者が利用できるデータから作られた静的なテストデータセットよりは適切です。
この柔軟性の副産物として、AIR-Bench は GPT-4 がサポートするすべての言語をサポートします。
さらに、AIR-Bench は、埋め込みモデルの最も広く使用されているアプリケーションである、現実的な AI ベースの情報検索に特化しています。クラスタリングや分類などの他の種類のタスクのスコアは提供しません。
tagAIR-Bench の配布
AIR-Bench は GitHub リポジトリからダウンロード、使用、修正が可能です。
AIR-BenchAIR-Bench は 2 種類のベンチマークをサポートしています:
- 特定のクエリに関連するドキュメントの正確な検索を評価する情報検索タスク。
- 検索拡張生成パイプラインの情報検索部分を模倣する「長文ドキュメント」タスク。
また、AIR-Bench の使用方法のライブ例として、英語と中国語の事前生成されたベンチマークセットを、生成スクリプトと共に提供しています。これらは容易に入手可能なデータセットを使用しています。
例えば、6,738,498 の英語 Wikipedia ページの選択に対して、4,260 のドキュメントにマッチする 1,727 のクエリと、追加で 7,882 の合成非マッチング(ただし類似)ドキュメントを生成しました。英語データセット 8 つと中国語データセット 6 つの従来の情報検索ベンチマークを提供しています。「長文ドキュメント」タスクについては、15 のベンチマークをすべて英語で提供しています。
完全なリストと詳細については、GitHub の AIR-Bench リポジトリにある利用可能なタスクページをご覧ください。
AIR-Benchtag参加しよう
AIR-Benchmark は、Search Foundations コミュニティのためのツールとして設計されており、ユーザーが自身のニーズにより適したベンチマークを作成できるようになっています。テストがユースケースについて有益な情報を提供する場合、私たちもそれを参考にして、より良い製品を構築することができます。
