



大規模言語モデル(LLM)と検索拡張生成(RAG)の登場により、企業がデータを活用する多くの機会が生まれましたが、同時に異なるソースを単一のコミュニケーションインターフェースに接続するという課題も生まれました。HR テクノロジー分野のイノベーター Springworks は、Jina AI との深い協力のもと、この課題の解決に取り組んでいます。
この事例研究では、Springworks のワークプレイス生産性ツールである Albus が、Jina Embeddings と Reranker を使用して、異なるアプリからのデータとコミュニケーションを可能にする方法を探ります。




tagすべてのアプリを単一のツールに接続
今日のデジタル化により、職場のコラボレーションツールが急増し、情報が複数の孤立したプラットフォームに散在する環境が生まれています。従業員は、過去のブレインストーミングの結果や前週のスプリントプランニングの議事録など、どこかで読んだ覚えはあるものの、再び見つけることができない情報を延々と探さなければならないことがよくあります。この情報の断片化は、生産性を低下させ、フラストレーションを増加させる障壁を生み出しています。生成 AI は、この問題に対処することを約束し、複数のソースからのデータにアクセスできる質問応答システムを作成することで、従業員が単一の情報源を持てるようにします。これを実現するには、これらすべての情報サイロにアクセスし、統合できる AI アプリケーションが必要です。
tagSpringworks Albus による解決策
Albus は、CRM、チケットシステム、人事管理システム、ナレッジ管理ツールを含む、100 以上の一般的なワークプレイスアプリケーションと統合されています。Jina AI の最先端の Embedding モデルと Reranker モデルを LLM と組み合わせることで、Albus は接続されたすべてのソースを分析し、最も関連性の高い最新の情報を使用して、従業員の質問に回答します。従業員は複数のアプリを検索したり、特定のファイル名や場所を覚えたりする必要がなくなります。
「当社の独自の社内ベンチマークで、ほぼすべての最先端の embeddings モデルと reranker モデルを評価しましたが、Jina のモデルは真に際立っています。彼らの技術は期待に応えるだけでなく、それを超えています。」
— Kartik Mandaville、Springworks の 創業者 兼 CEO
tagSpringworks ソリューションの中核
Springworks は、Jina AI と協力して、Albus の高度な RAG システムを開発し、反復的に改善しています。Albus は構造化データと非構造化データの両方を取得します。AI クラシファイアーがユーザーのリクエストをリレーショナルデータベースへのクエリで解決するべきか、jina-colbert-v1-en を使用して非構造化データをベクターデータベースで検索するべきかを判断します。ソースに関係なく、取得された結果は jina-reranker-v1-base-en を使用して再ランク付けされ、あらゆるユーザーの質問に答えるための最も関連性の高い情報を見つけ出します。
「Jina AI のカスタマーサクセスチームは、これらのモデルの最適化に重要な役割を果たしています。迅速な対応と詳細な説明により、実装プロセスが簡素化され、結果が大幅に改善されました。」
— Kartik Mandaville、Springworks の 創業者 兼 CEO
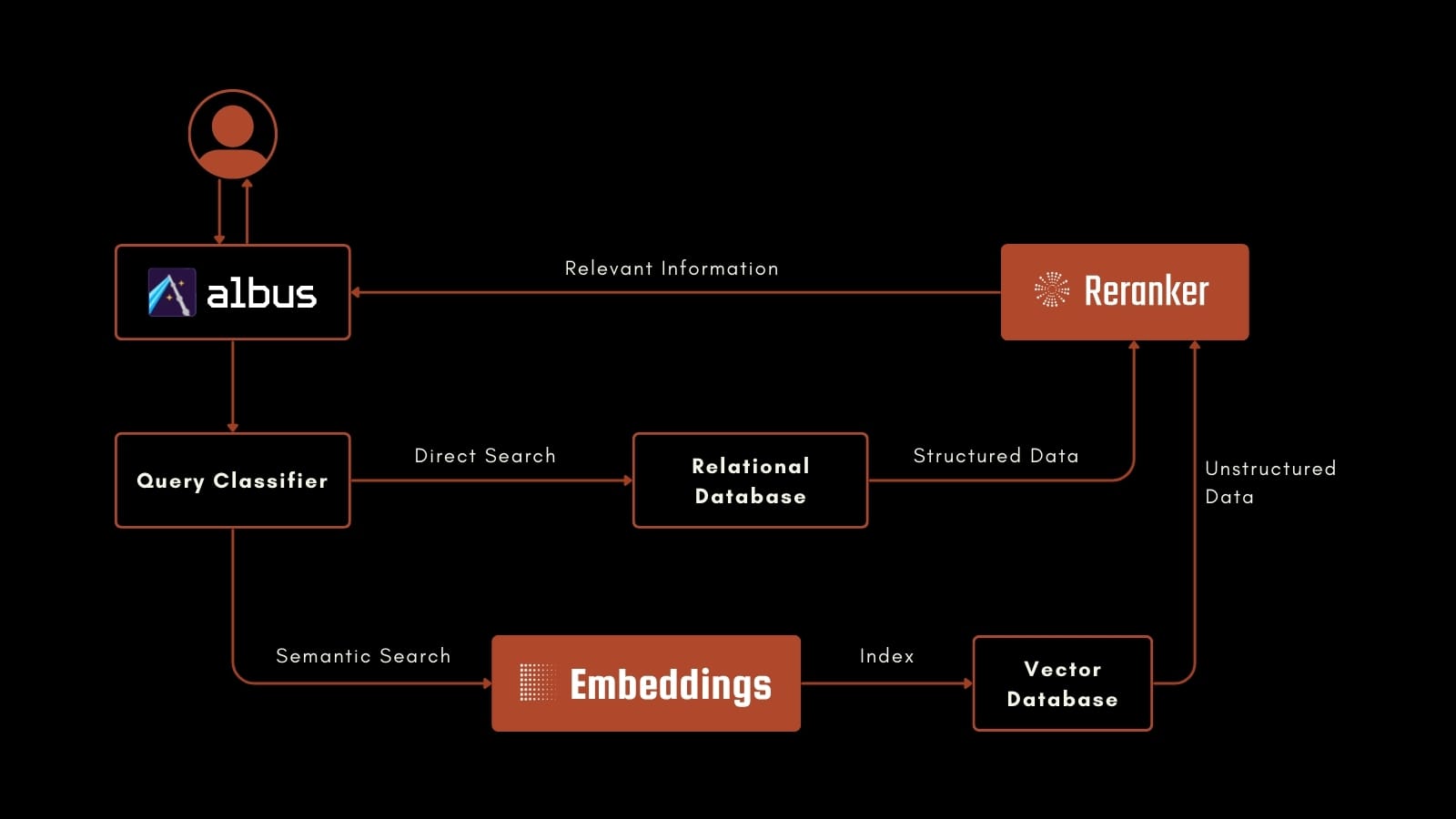
例として、ユーザーが Albus を使用して Jira チケットデータベースに次のようなクエリを行うとします:
Which tickets were created since March about updating the Dockerfile
to use the latest Ubuntu version?Query Classifier は、このクエリが構造化検索に最適であると判断し("since March" は従来のフィルタークエリを示唆)、Jira Query Language(Jira で使用される SQL 変種)で同等のクエリを生成します:
project = "BACKEND_API"
AND created >= "2023-03-01"
AND text ~ "dockerfile"
AND text ~ "Ubuntu"これにより一連のチケットが返され、それらのテキスト内容は元の自然言語クエリとともに jina-reranker-v1-base-en に送られます。Jina Reranker がそれらを再順序付けし、最上位のチケットのテキストはテンプレートと共に LLM のプロンプトにコンパイルされます。これによりユーザーに送信される自然言語のテキスト応答が作成されます。
次に、構造化検索にあまり適していないリクエストを想像してみましょう:
How does the company's ESOP policy differ between senior management
and associate-level employees?Query Classifier はこれを embeddings ベースのベクトル検索に適していると認識し、jina-colbert-v1-base-en を使用して embedding を生成し、ベクターデータベースがチケットとマッチングします。これらの結果は、構造化検索の場合と同様に、元のクエリとともに jina-reranker-v1-base-en に渡され、同じ手順で自然言語応答が生成されます。
tag即時デプロイメントとワンクリック統合
Albus は可能な限りユーザーフレンドリーになるよう設計されています。ワークアプリをワンクリックで統合できます:
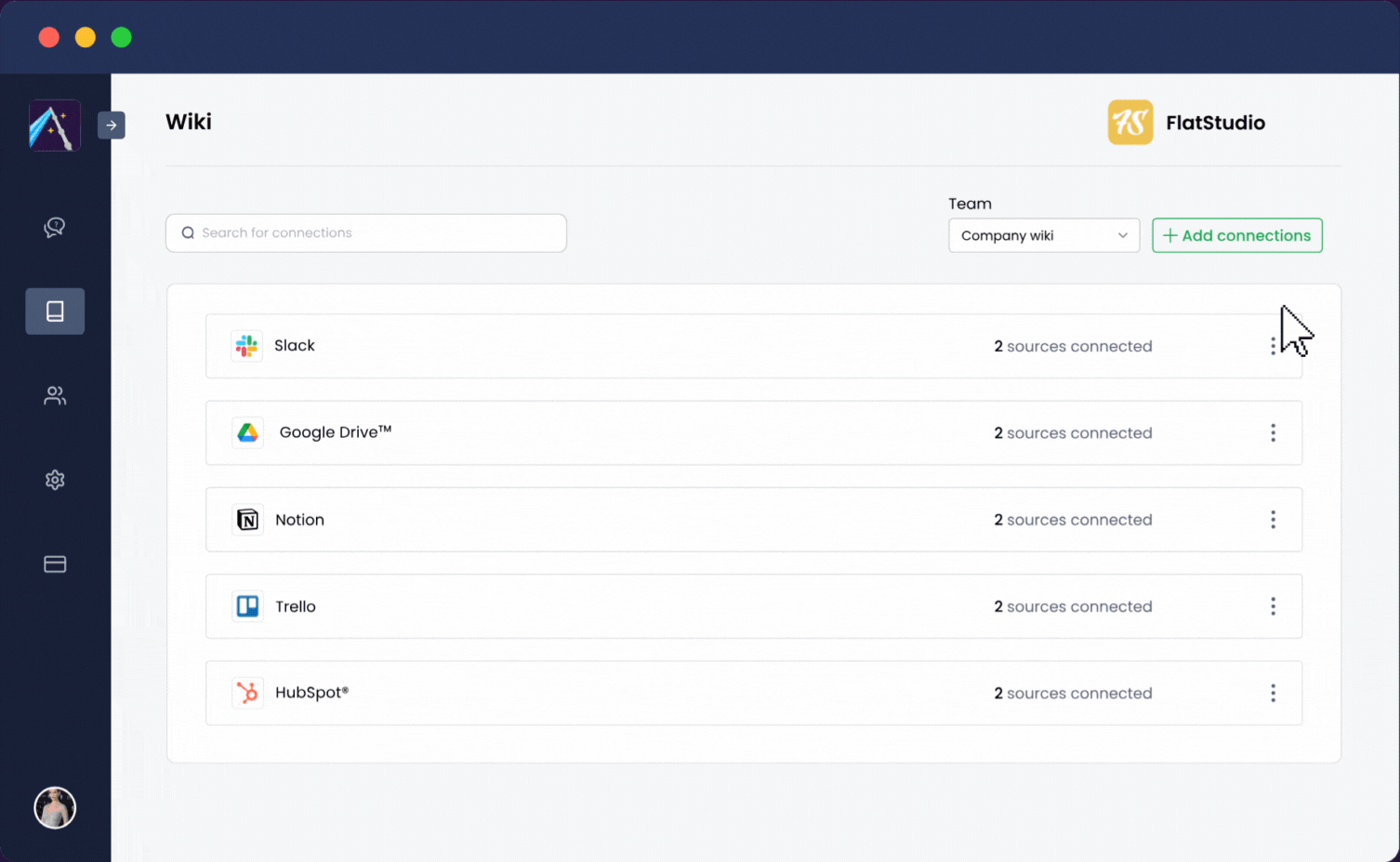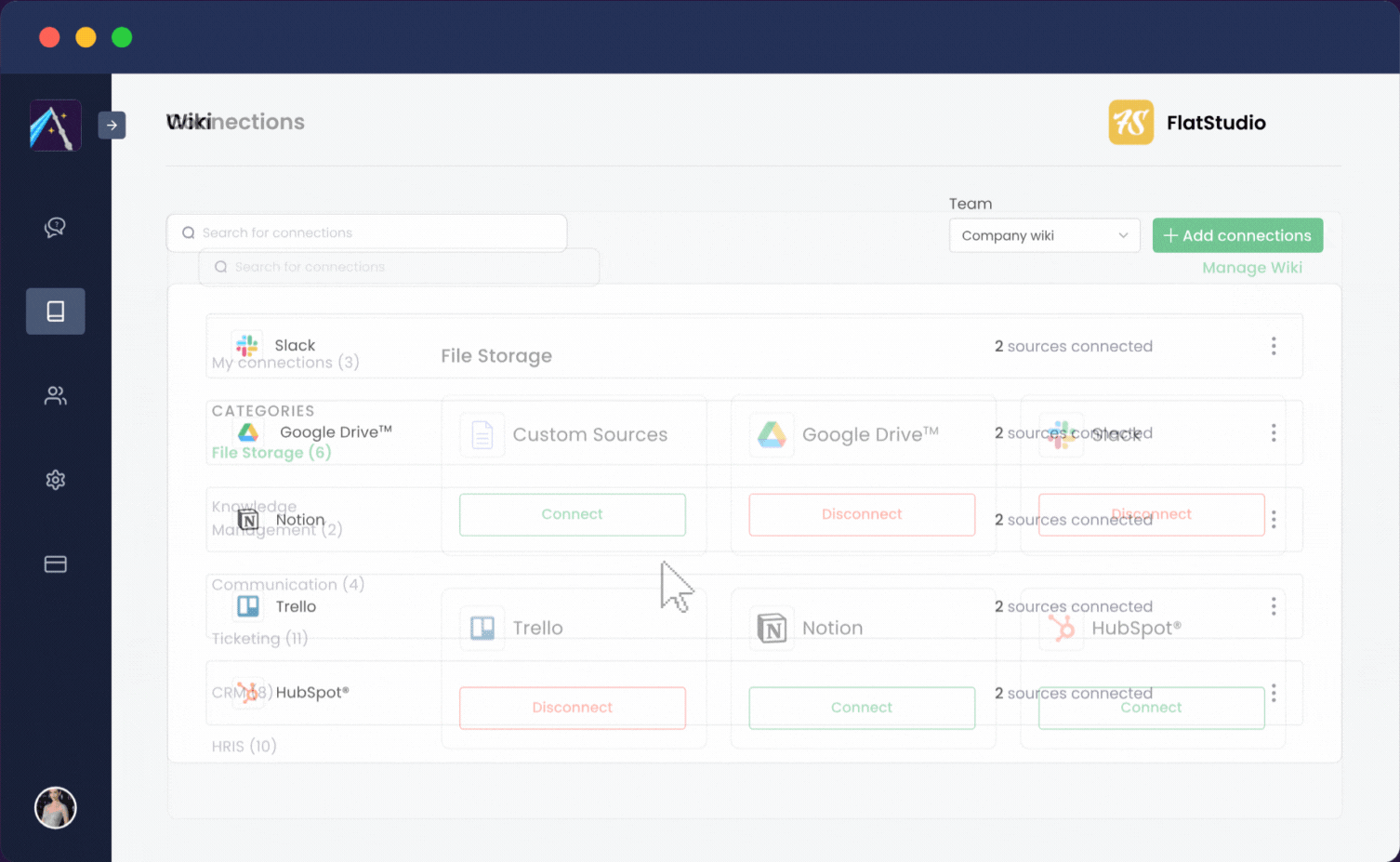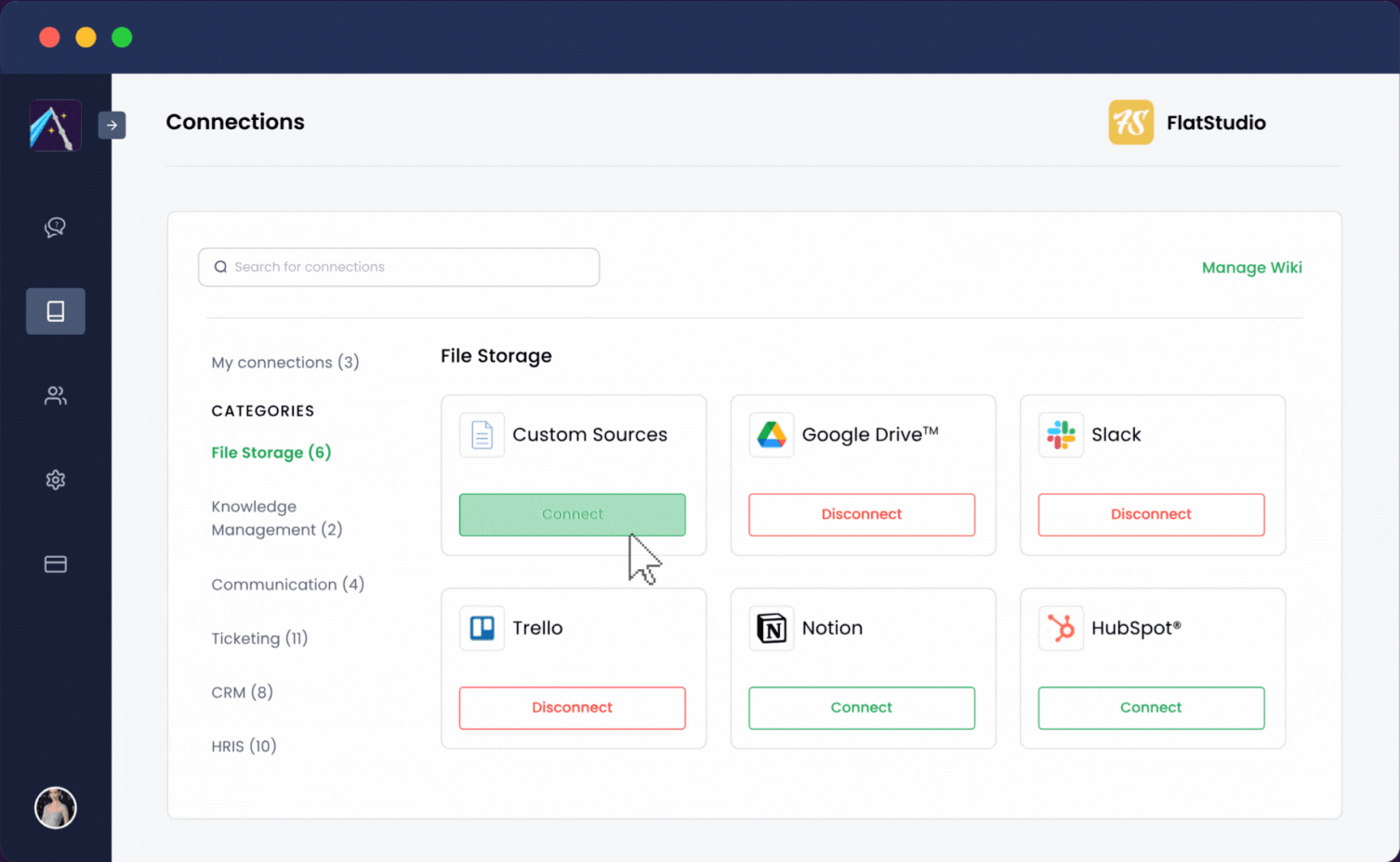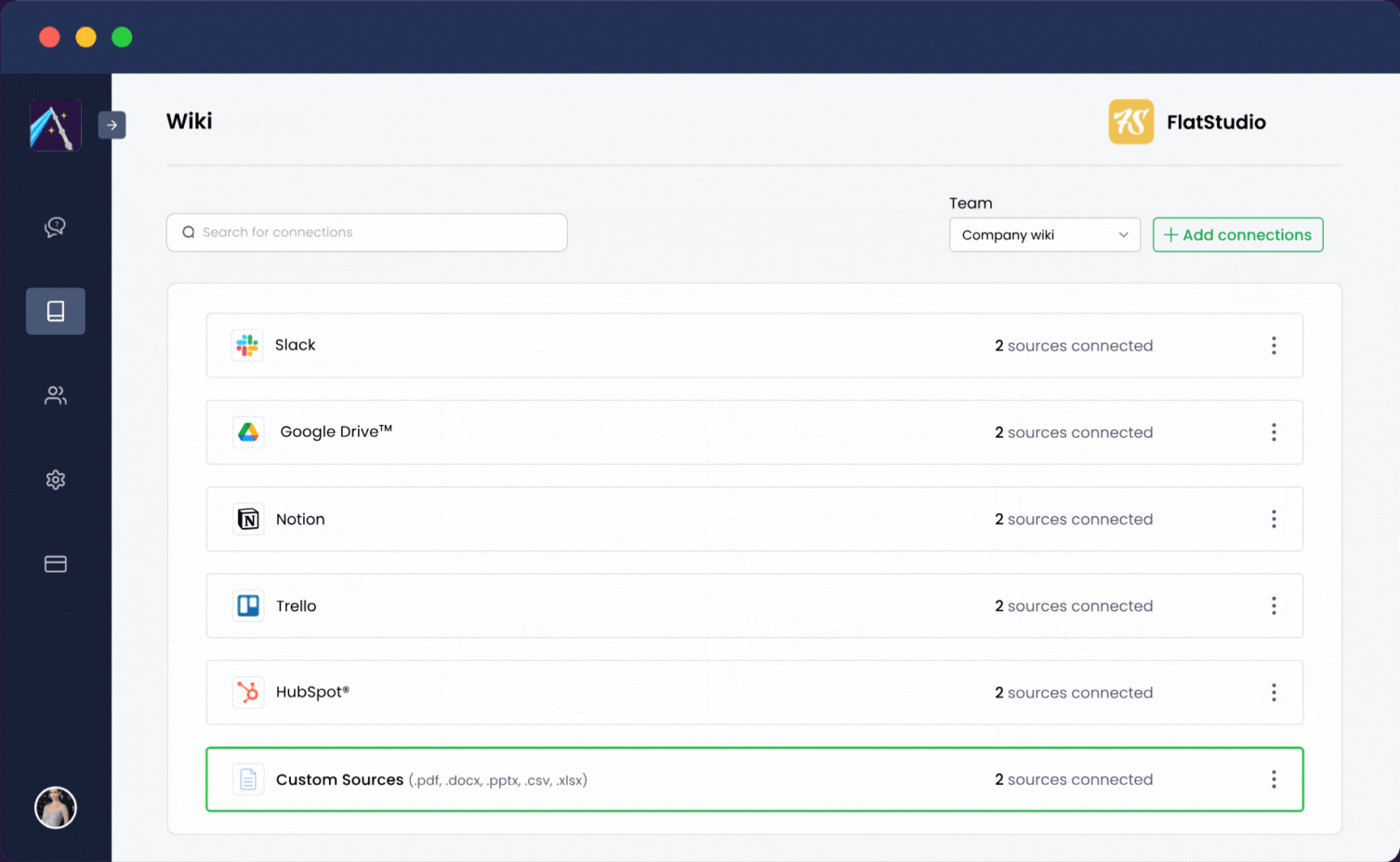
Albus は数分で稼働を開始し、チームが質問するだけで任意の情報を見つけることができる単一のチャット環境にワークプレイス全体を変換します。
tag知識共有の新境地
Springworks は企業がデータにアクセスする新しい方法を作り出し、信頼されるオフィスツールになることが期待されています。AI を活用した一元化された情報検索ソリューションを提供することで、Albus は従業員が必要な情報を探すために費やす時間と労力を削減します。Jina AI とツールの既存システムとの統合能力、および正確でコンテキストを意識した回答を提供する能力により、Albus は企業の知識をかつてないほどアクセスしやすいものにします。
Jina AI は、企業に最高品質のモデルを競争力のある価格で提供することに取り組んでいます。当社の実装の専門知識とエンタープライズ向けサービスの利用をご希望の場合は、ウェブサイトからお問い合わせください。フィードバックの共有や最新モデルの情報を得るには、Discord チャンネルで直接対話してください。私たちは日々製品の改善を重ねており、皆様からのご意見は開発プロセスにおいて非常に重要です。
