


テキストと画像を シームレスな検索体験に統合したマルチモーダル検索は、OpenAI の CLIP のようなモデルのおかげで勢いを増しています。これらのモデルは、視覚データとテキストデータの間のギャップを効果的に埋め、画像と関連するテキストを相互に結びつけることを可能にします。
CLIP や同様のモデルは強力ですが、特に長いテキストの処理や複雑なテキストの関係性の扱いに関して、顕著な制限があります。ここで jina-clip-v1 が登場します。
これらの課題に対処するために設計された jina-clip-v1 は、堅牢なテキストと画像のマッチング機能を維持しながら、テキスト理解を改善しています。両モダリティを使用するアプリケーションにより合理化されたソリューションを提供し、検索プロセスを簡素化し、テキストと画像に別々のモデルを使用する必要性をなくしています。
この投稿では、jina-clip-v1 がマルチモーダル検索アプリケーションにもたらすものを探り、統合されたテキストと画像の埋め込みを通じて精度と結果の多様性をどのように向上させるかを実験を通じて紹介します。
tagCLIP とは何か
CLIP(Contrastive Language–Image Pretraining)は、OpenAI が開発した AI モデルアーキテクチャで、共同表現を学習することでテキストと画像を結びつけます。CLIP は本質的に、テキストモデルと画像モデルを融合させたものであり、両方の入力を共有埋め込み空間に変換し、類似したテキストと画像が近い位置に配置されます。CLIP は膨大な画像とテキストのペアデータセットで訓練され、視覚的内容とテキスト内容の関係を理解することができます。これにより、キャプション生成や画像検索などのゼロショット学習シナリオで高い効果を発揮できます。
CLIP のリリース以降、SigLiP、LiT、EvaCLIP などのモデルがその基盤を拡張し、トレーニング効率、スケーリング、マルチモーダル理解などの側面を向上させています。これらのモデルは、より大規模なデータセット、改良されたアーキテクチャ、より洗練されたトレーニング技術を活用して、画像と言語のモデルの分野をさらに発展させています。
CLIP はテキストのみでも機能することはできますが、重要な制限があります。まず、短いテキストキャプションでのみトレーニングされ、最大で約 77 単語しか処理できません。次に、CLIP はテキストと画像の接続には優れていますが、a crimson fruit と a red apple が同じものを指す可能性があるといったテキスト同士の比較では苦戦します。ここで jina-embeddings-v3 のような専門的なテキストモデルが輝きを放ちます。
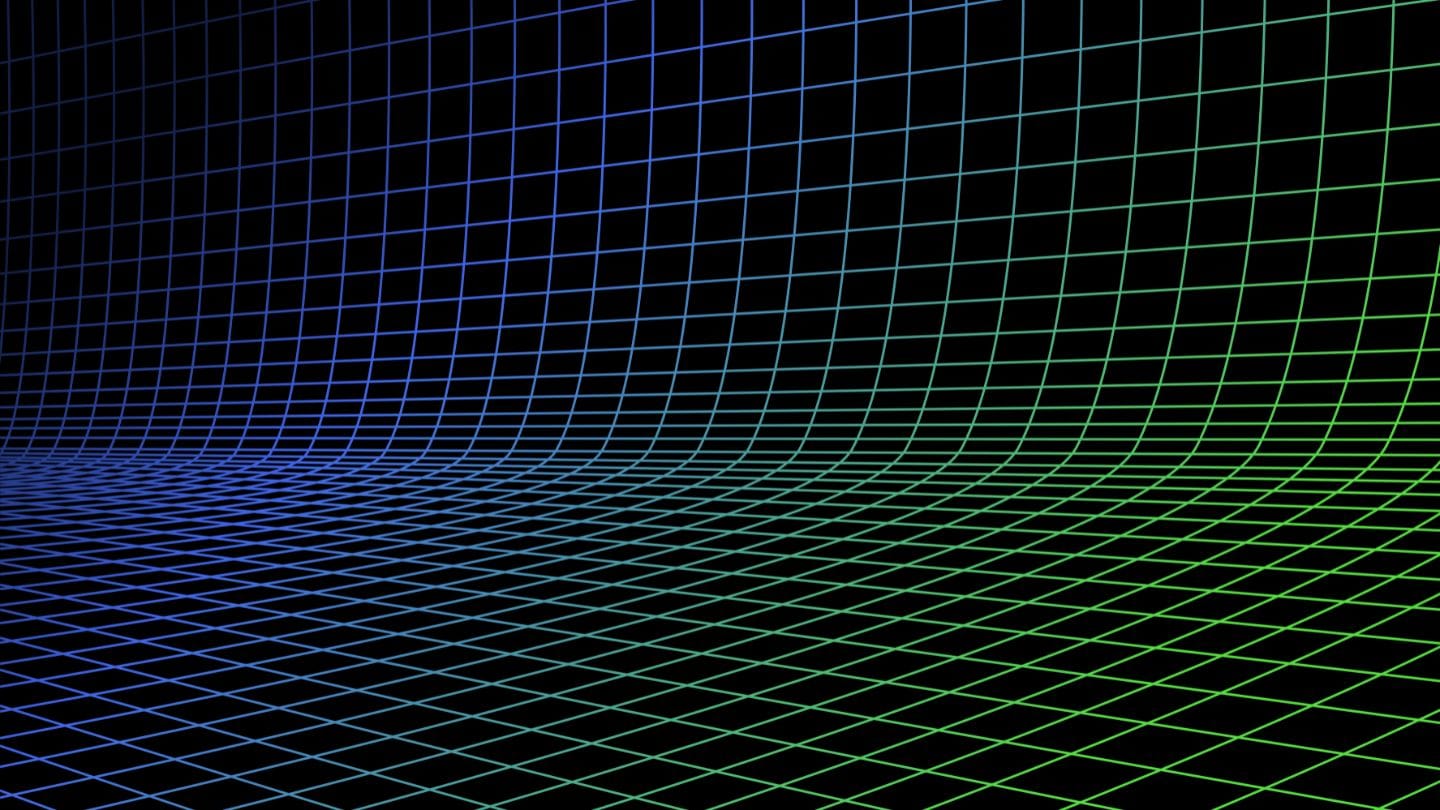
これらの制限は、テキストと画像の両方を含む検索タスクを複雑にします。例えば、ユーザーがテキスト文字列や画像を使ってファッション製品を検索できる「ルックを探す」オンラインストアの場合です。製品をインデックス化する際、各製品を複数回処理する必要があります - 画像用に1回、テキスト用に1回、さらにテキスト専用モデル用に1回です。同様に、ユーザーが製品を検索する際、システムはテキストと画像の両方のターゲットを見つけるために少なくとも2回検索する必要があります:
tag『jina-clip-v1』は CLIP の短所をどのように解決するか
CLIP の制限を克服するため、私たちは jina-clip-v1 を作成し、より長いテキストを理解し、テキストクエリをテキストと画像の両方により効果的にマッチングできるようにしました。jina-clip-v1 が特別な理由は何でしょうか?まず第一に、より賢いテキスト理解モデル(JinaBERT)を使用し、短いキャプション(製品名など)だけでなく、より長く複雑なテキスト(製品説明など)を理解できます。第二に、jina-clip-v1 は、テキストと画像のマッチングと、テキスト同士のマッチングの両方を同時に行えるように訓練されています。
OpenAI CLIP の場合は異なります:インデックス作成とクエリの両方で、2つのモデル(画像とキャプションなどの短いテキスト用の CLIP、説明文などの長いテキスト用の別のテキスト埋め込み)を呼び出す必要があります。これはオーバーヘッドを増やすだけでなく、本来は非常に高速であるべき検索操作を遅くします。jina-clip-v1 は、速度を犠牲にすることなく、1つのモデルでこれらすべてを実現します:

この統合されたアプローチにより、以前のモデルでは困難だった新しい可能性が開かれ、検索へのアプローチ方法が変わる可能性があります。この記事では、2つの実験を行いました:
- テキスト検索と画像検索を組み合わせて検索結果を改善する:jina-clip-v1 がテキストから理解することと画像から理解することを組み合わせることができるでしょうか?これら2つの理解を融合させるとどうなるでしょうか?視覚情報を追加すると検索結果はどう変わるでしょうか?端的に言えば、テキストと画像を同時に使用して検索することでより良い結果が得られるでしょうか?
- 画像を使用して検索結果を多様化する:ほとんどの検索エンジンはテキストマッチングを最大化します。しかし、jina-clip-v1 の画像理解を「ビジュアルシャッフル」として使用できるでしょうか?最も関連性の高い結果だけを表示する代わりに、視覚的に多様な結果を含めることができます。これは関連する結果をより多く見つけることではなく、関連性が低くても、より広い視点を示すことです。これにより、それまで考えていなかったトピックの側面を発見できるかもしれません。例えば、ファッション検索の文脈で、ユーザーが「マルチカラーのカクテルドレス」を検索する場合、上位の検索結果がすべて同じように見える(つまり、非常に近いマッチング)ことを望むのか、それとも(ビジュアルシャッフルを通じて)より幅広い選択肢を望むのでしょうか?
これらのアプローチは、e コマース、メディア、アート&デザイン、医療画像など、ユーザーがテキストまたは画像で検索する可能性のあるさまざまなユースケースで有用です。
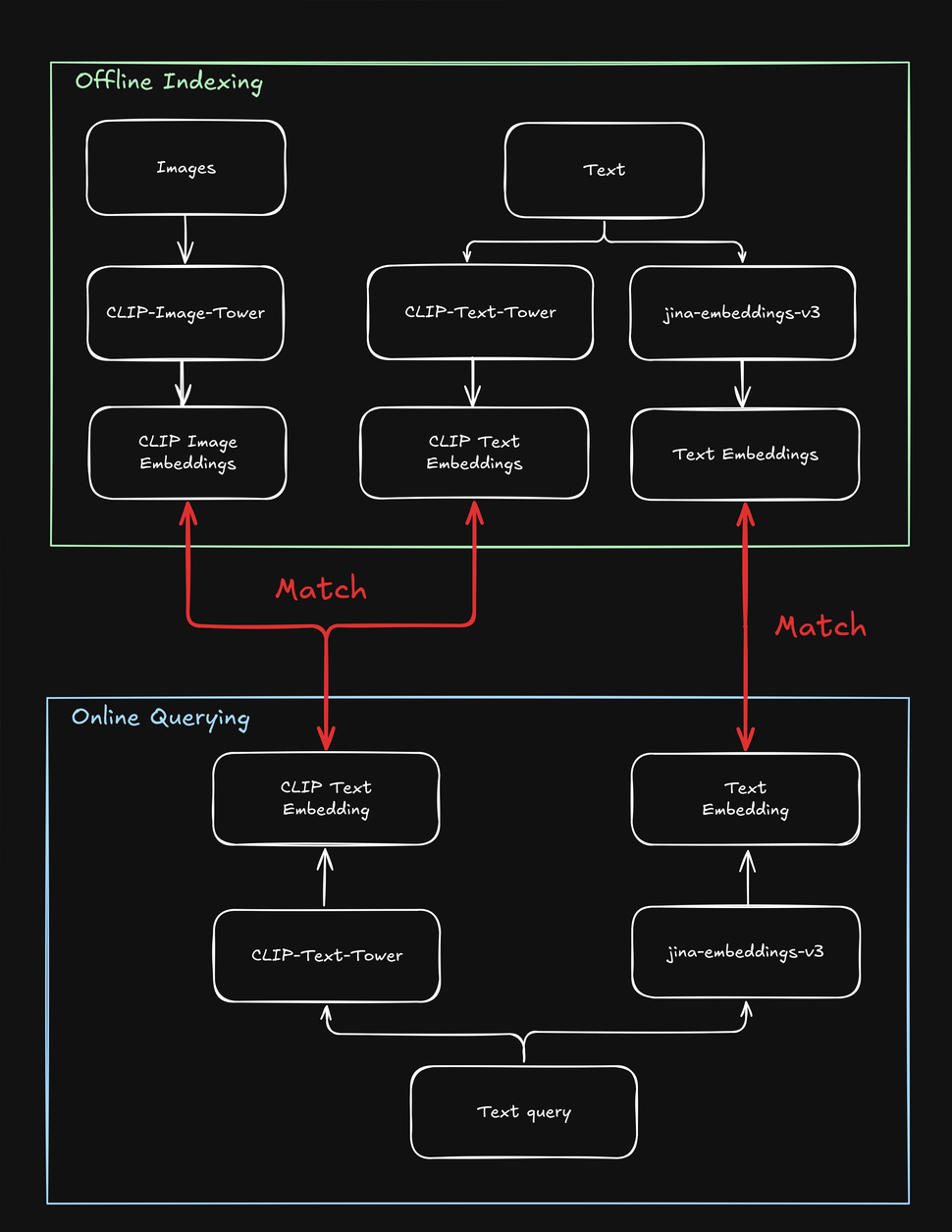
tag平均以上のパフォーマンスを実現するテキストと画像の埋め込みの平均化
ユーザーがクエリ(通常はテキスト文字列)を送信すると、jina-clip-v1 のテキストタワーを使用してクエリをテキスト埋め込みにエンコードできます。jina-clip-v1 の強みは、同じ意味空間でテキスト対テキストとテキスト対画像の信号を整列させることで、テキストと画像の両方を理解できることにあります。
各商品の事前にインデックス化されたテキストと画像の埋め込みを平均化することで、検索結果を改善できるでしょうか?
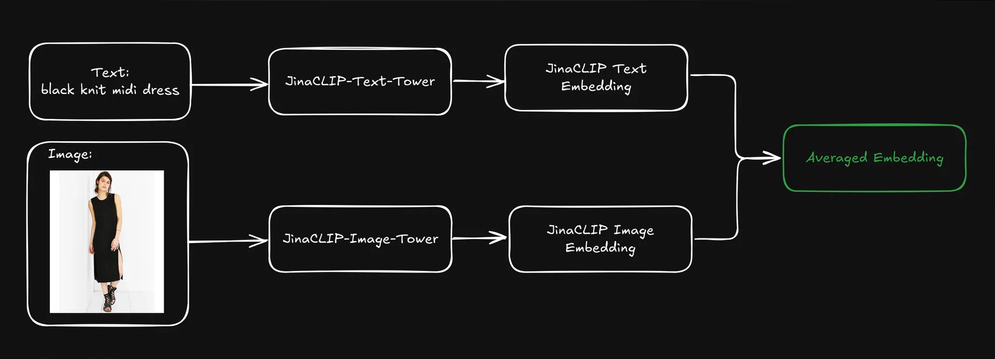
これにより、テキスト情報(商品説明など)と視覚情報(商品画像など)の両方を含む単一の表現が作成されます。その後、このブレンドされた表現を検索するためにテキストクエリの埋め込みを使用できます。これは検索結果にどのような影響を与えるでしょうか?
これを調べるために、Fashion200k データセットを使用しました。これはファッション画像検索とクロスモーダル理解に関連するタスク向けに特別に作成された大規模なデータセットです。衣類、靴、アクセサリーなど、200,000以上のファッションアイテムの画像と、それに対応する商品説明やメタデータで構成されています。
 xthan
xthanさらに、各アイテムを大まかなカテゴリー(例えば dress)と詳細なカテゴリー(knit midi dress など)に分類しました。
tag3つの検索手法の分析
テキストと画像の埋め込みを平均化することでより良い検索結果が得られるかを確認するため、テキスト文字列(例:red dress)をクエリとして使用する3つのタイプの検索実験を行いました:
- テキスト埋め込みを使用したクエリから説明文への検索: テキスト埋め込みに基づく商品説明文の検索。
- クロスモーダル検索によるクエリから画像への検索: 画像埋め込みに基づく商品画像の検索。
- クエリから平均埋め込みへの検索: 商品説明文と商品画像の両方の平均化された埋め込みの検索。
まず、データセット全体をインデックス化し、その後パフォーマンスを評価するために1,000のクエリをランダムに生成しました。各クエリをテキスト埋め込みにエンコードし、上記の手法に基づいて個別にマッチングを行いました。精度は、返された商品のカテゴリがクエリにどれだけ一致しているかで測定しました。
multicolor henley t-shirt dressというクエリを使用した場合、クエリから説明文への検索がトップ5の精度で最も高い結果を示しましたが、上位3位以降のドレスは視覚的に同一でした。効果的な検索では、ユーザーの関心をより良く捉えるために、関連性と多様性のバランスを取る必要があるため、これは理想的とは言えません。

クエリから画像へのクロスモーダル検索では、同じクエリを使用し、まったく異なるアプローチで非常に多様なドレスのコレクションを提示しました。広いカテゴリでは5つ中2つが一致しましたが、細かいカテゴリでは一致するものはありませんでした。

テキストと画像の埋め込みを平均化した検索が最も良い結果を示しました:5つの結果すべてが広いカテゴリと一致し、5つ中2つが細かいカテゴリと一致しました。さらに、視覚的に重複するアイテムが排除され、より多様な選択肢が提供されました。テキスト埋め込みを使用して平均化されたテキストと画像の埋め込みを検索することで、検索品質を維持しながら視覚的な手がかりを取り入れ、より多様で総合的な結果が得られることがわかりました。

tagスケールアップ:より多くのクエリでの評価
より大規模なスケールでもこれが機能するかを確認するため、広いカテゴリと細かいカテゴリの両方で実験を継続しました。異なる数の結果("k値")を取得して、複数回の反復実験を行いました。
広いカテゴリと細かいカテゴリの両方において、クエリから平均埋め込みへの検索は、すべての k値(10、20、50、100)で一貫して最も高い精度を達成しました。これは、テキストと画像の埋め込みを組み合わせることで、カテゴリが広いか具体的かに関わらず、関連アイテムを検索する上で最も正確な結果が得られることを示しています:

| k | Search Type | Broad Category Precision (cosine similarity) | Fine-grained Category Precision (cosine similarity) |
|---|---|---|---|
| 10 | Query to Description | 0.9026 | 0.2314 |
| 10 | Query to Image | 0.7614 | 0.2037 |
| 10 | Query to Avg Embedding | 0.9230 | 0.2711 |
| 20 | Query to Description | 0.9150 | 0.2316 |
| 20 | Query to Image | 0.7523 | 0.1964 |
| 20 | Query to Avg Embedding | 0.9229 | 0.2631 |
| 50 | Query to Description | 0.9134 | 0.2254 |
| 50 | Query to Image | 0.7418 | 0.1750 |
| 50 | Query to Avg Embedding | 0.9226 | 0.2390 |
| 100 | Query to Description | 0.9092 | 0.2139 |
| 100 | Query to Image | 0.7258 | 0.1675 |
| 100 | Query to Avg Embedding | 0.9150 | 0.2286 |
- テキスト埋め込みを使用したクエリから説明への検索は、両方のカテゴリーで良好な性能を示しましたが、平均埋め込みアプローチよりもわずかに劣っていました。これは、テキストによる説明だけでも「ドレス」のような広いカテゴリーには特に有用な情報を提供しますが、細かい分類(例:異なるタイプのドレスの区別)に必要な微妙な違いを捉えるには不十分かもしれないことを示唆しています。
- クロスモーダル検索を使用したクエリから画像への検索は、両方のカテゴリーで一貫して最も低い精度を示しました。これは、視覚的な特徴が広いカテゴリーの識別には役立つものの、特定のファッションアイテムの細かい区別には効果が低いことを示唆しています。視覚的な違いが微妙で、テキストによる追加のコンテキストが必要な場合、純粋に視覚的な特徴から細かいカテゴリーを区別することの難しさが特に顕著です。
- 全体として、テキストと視覚情報を組み合わせる(平均埋め込みを通じて)ことで、広範囲および細かいファッション検索タスクの両方で高い精度を達成しました。テキストによる説明は特に広いカテゴリーの識別に重要な役割を果たす一方で、画像単独では両方のケースで効果が低くなっています。
全体として、広いカテゴリーの精度は細かいカテゴリーと比較してはるかに高くなりました。これは主に、広いカテゴリー(例:dress)のアイテムが、細かいカテゴリー(例:henley dress)よりもデータセットに多く含まれているためです。後者は前者のサブセットであるためです。本質的に、広いカテゴリーは細かいカテゴリーよりも一般化が容易です。ファッションの例を離れて考えると、一般的に何かが鳥であることを識別するのは簡単です。しかし、それがVogelkop Superb Bird of Paradiseであると識別するのははるかに難しいのです。
さらに注目すべき点は、テキストクエリの情報は、視覚的な特徴よりも他のテキスト(製品名や説明など)により簡単にマッチするということです。したがって、テキストを入力として使用する場合、画像よりもテキストが出力される可能性が高くなります。インデックスに画像とテキストの両方を組み合わせる(埋め込みの平均を取ることで)ことで、最良の結果を得ることができます。
tagテキストで結果を取得し、画像で多様化する
前のセクションでは、視覚的に重複する検索結果の問題に触れました。検索において、精度だけでは必ずしも十分ではありません。多くの場合、簡潔でありながら、高い関連性と多様性を持つランク付けされたリストを維持する方が効果的です。特にユーザーのクエリが曖昧な場合(例えば、ユーザーが black jacket を検索する場合 — ブラックのバイカージャケット、ボンバージャケット、ブレザー、それとも他の種類を意味するのでしょうか?)。
ここで、jina-clip-v1 のクロスモーダル機能を活用する代わりに、テキストタワーからのテキスト埋め込みを初期テキスト検索に使用し、その後、イメージタワーからの画像埋め込みを「視覚的リランカー」として適用して検索結果を多様化させましょう。これを以下の図で説明します:
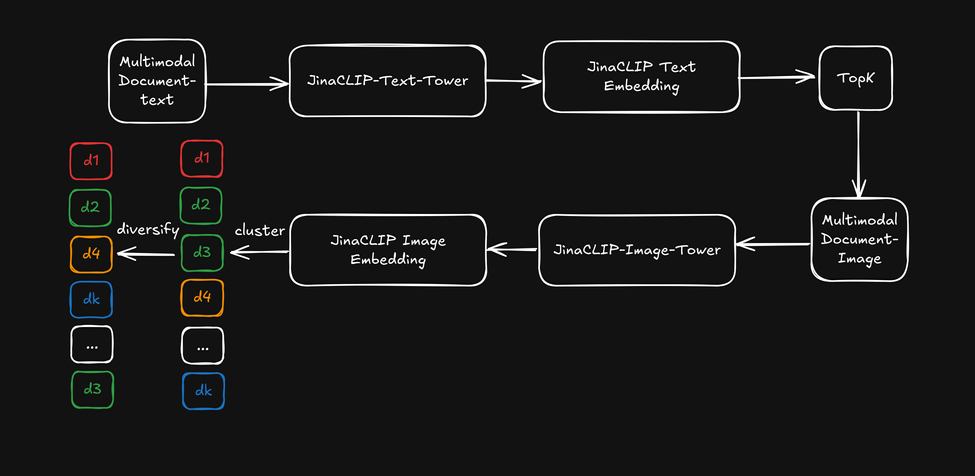
- まず、テキスト埋め込みに基づいて上位 k 件の検索結果を取得します。
- 各上位検索結果について、視覚的特徴を抽出し、画像埋め込みを使用してクラスタリングします。
- 各クラスターから 1 つのアイテムを選択して検索結果を並べ替え、多様化されたリストをユーザーに提示します。
上位 50 件の結果を取得した後、画像埋め込みに軽量な k-means クラスタリング(k=5)を適用し、各クラスターからアイテムを選択しました。カテゴリの精度は Query-to-Description のパフォーマンスと一貫性を保ちました。これは、クエリから製品カテゴリへの変換を測定指標として使用したためです。しかし、画像ベースの多様化により、ランク付けされた結果は、より多くの異なる側面(素材、カット、パターンなど)をカバーし始めました。参考までに、以前のマルチカラーのヘンリーネック T シャツドレスの例を示します:

テキスト埋め込み検索と、画像埋め込みを多様化リランカーとして組み合わせた場合に、多様化が検索結果にどのように影響するか見てみましょう:

ランク付けされた結果はテキストベースの検索から生成されますが、上位 5 件の例でより多様な「側面」をカバーし始めます。これは、実際に埋め込みを平均化することなく、埋め込みの平均化と同様の効果を達成します。
ただし、これにはコストがかかります:上位 k 件の結果を取得した後に追加のクラスタリングステップを適用する必要があり、初期ランキングのサイズによって数ミリ秒の追加時間がかかります。また、k-means クラスタリングの k 値の決定には、経験則に基づく推測が必要です。これが結果の多様化を改善するために支払う代価です!
tag結論
jina-clip-v1 は、単一の効率的なモデルで両方のモダリティを統合することで、テキストと画像検索の間のギャップを効果的に橋渡しします。私たちの実験では、画像とともにより長く複雑なテキスト入力を処理する能力が、従来の CLIP のようなモデルと比較して優れた検索性能を提供することが示されました。
私たちのテストでは、テキストと説明の照合、画像の照合、埋め込みの平均化など、様々な方法を網羅しました。結果は一貫して、テキストと画像の埋め込みを組み合わせることで最良の結果が得られ、精度と検索結果の多様性の両方が向上することを示しました。また、画像埋め込みを「視覚的リランカー」として使用することで、関連性を維持しながら結果の多様性が向上することも発見しました。
これらの進歩は、ユーザーがテキストの説明と画像の両方を使用して検索する実世界のアプリケーションにとって重要な意味を持ちます。jina-clip-v1 は両方のデータタイプを同時に理解することで検索プロセスを合理化し、より関連性の高い結果を提供し、より多様な製品推薦を可能にします。この統合された検索機能は e コマースを超えて、メディアアセット管理、デジタルライブラリ、視覚的コンテンツキュレーションにも利点をもたらし、異なるフォーマット間で関連コンテンツを発見しやすくします。
jina-clip-v1 は現在英語のみをサポートしていますが、現在 jina-clip-v2 の開発を進めています。jina-embeddings-v3 の足跡をたどり、
jina-colbert-v2、この新バージョンは 89 言語に対応した最先端の多言語マルチモーダル検索モデルとなります。このアップグレードにより、様々な市場や産業における検索・検索タスクの新たな可能性が開かれ、e コマース、メディアなどのグローバルアプリケーションにおいて、より強力な埋め込みモデルとなります。




