


埋め込み(Embeddings)は、様々な AI や自然言語処理アプリケーションの基盤となり、テキストの意味を高次元ベクトルとして表現する方法を提供しています。しかし、モデルのサイズが大きくなり、AI モデルが処理するデータ量が増加するにつれて、従来の埋め込みの計算とストレージの要件は急激に増加しています。バイナリ埋め込みは、高性能を維持しながらリソース要件を大幅に削減する、コンパクトで効率的な代替手段として導入されました。
バイナリ埋め込みは、埋め込みベクトルのサイズを最大 96%(Jina Embeddings の場合は 96.875%)削減することで、これらのリソース要件を軽減する一つの方法です。ユーザーは、精度をほとんど損なうことなく、コンパクトなバイナリ埋め込みの力を AI アプリケーションで活用できます。
tagバイナリ埋め込みとは?
バイナリ埋め込みは、従来の高次元浮動小数点ベクトルをバイナリベクトルに変換する特殊なデータ表現形式です。これは埋め込みを圧縮するだけでなく、ベクトルの完全性と有用性をほぼ完全に保持します。この技術の本質は、変換後もデータポイント間の意味論的関係と距離を維持できることにあります。
バイナリ埋め込みの魔法は量子化にあります。これは高精度の数値を低精度の数値に変換する方法です。AI モデリングでは、通常、埋め込みの 32 ビット浮動小数点数を 8 ビット整数などの少ないビット数の表現に変換することを意味します。

バイナリ埋め込みは、これを究極まで推し進め、各値を 0 または 1 に縮小します。32 ビット浮動小数点数をバイナリ桁に変換することで、埋め込みベクトルのサイズを 32 分の 1、つまり 96.875% 削減します。結果として、得られる埋め込みのベクトル演算が大幅に高速化されます。一部のマイクロチップで利用可能なハードウェアの高速化を使用すると、ベクトルが 2 値化された場合、ベクトル比較の速度は 32 倍以上に向上する可能性があります。
このプロセスでは必然的に一部の情報が失われますが、モデルの性能が非常に高い場合、この損失は最小限に抑えられます。非量子化された埋め込みが異なるものの間で最大限に異なる場合、2 値化はその違いをうまく保持する可能性が高くなります。そうでない場合、埋め込みを正しく解釈することが困難になる可能性があります。
Jina Embeddings のモデルは、まさにそのような頑健性を持つように訓練されており、2 値化に適しています。
このようなコンパクトな埋め込みにより、特にモバイルや時間に敏感な用途など、リソースに制約のある環境で新しい AI アプリケーションが可能になります。
以下のグラフが示すように、これらのコストと計算時間の利点は、比較的小さな性能コストで得られます。

jina-embeddings-v2-base-enでは、バイナリ量子化により検索精度が 47.13% から 42.05% に低下し、約 10% の損失となります。jina-embeddings-v2-base-deでは、この損失は 44.39% から 42.65% とわずか 4% です。
Jina Embeddings のモデルがバイナリベクトルの生成で優れた性能を発揮するのは、より均一な埋め込みの分布を作成するように訓練されているためです。これは、2 つの異なる埋め込みが、他のモデルの埋め込みよりも多くの次元でより離れている可能性が高いことを意味します。この特性により、それらの距離がバイナリ形式でより適切に表現されることが保証されます。
tagバイナリ埋め込みはどのように機能するのか?
これがどのように機能するかを理解するために、3 つの埋め込み:A、B、C を考えてみましょう。これらはすべて完全な浮動小数点ベクトルで、2 値化されたものではありません。ここで、A から B までの距離が B から C までの距離よりも大きいとします。埋め込みでは、通常コサイン距離を使用します:
A、B、C を 2 値化すると、ハミング距離でより効率的に距離を測定できます。
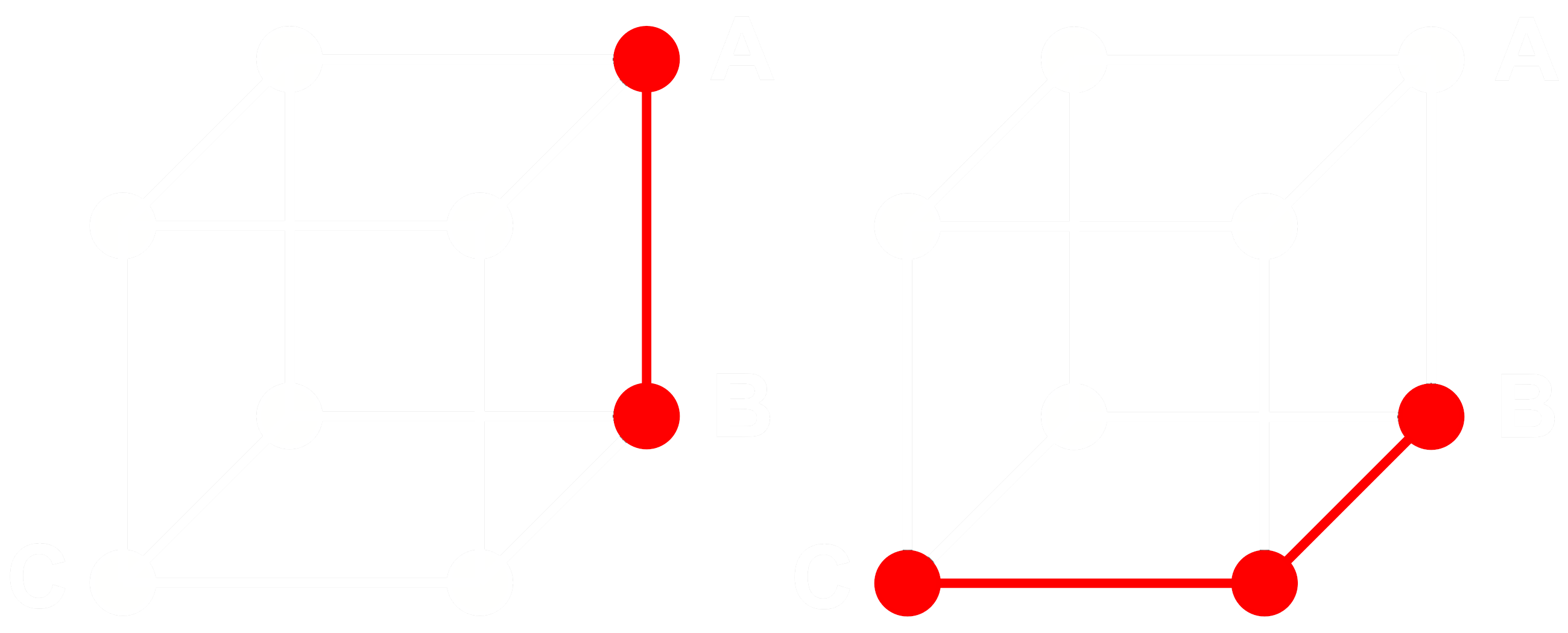
A、B、C の 2 値化されたバージョンをそれぞれ Abin、Bbin、Cbin と呼びましょう。
バイナリベクトルの場合、Abin と Bbin 間のコサイン距離が Bbin と Cbin 間よりも大きい場合、Abin と Bbin 間のハミング距離は Bbin と Cbin 間のハミング距離以上になります。
したがって:
の場合、ハミング距離については:
理想的には、埋め込みを 2 値化する際、完全な埋め込みと同じ関係が 2 値化された埋め込みでも成り立つことが望ましいです。つまり、浮動小数点コサインで一方の距離が他方より大きい場合、それらの 2 値化された等価物間のハミング距離でも同様になるべきです:
すべての埋め込みの三つ組についてこれを真にすることはできませんが、ほとんどの場合について真にすることは可能です。
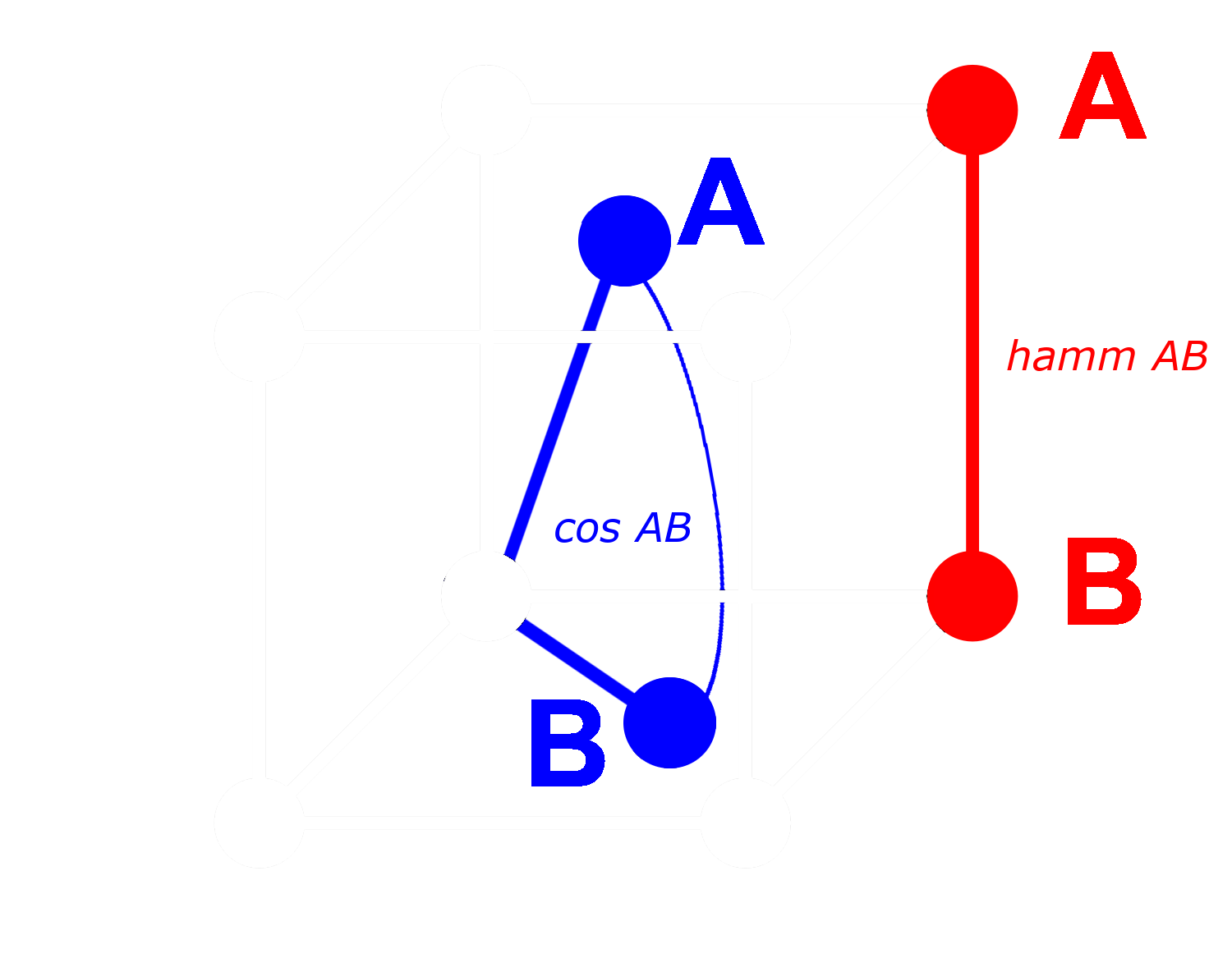
バイナリベクトルでは、各次元を存在する(1)か存在しない(0)かのいずれかとして扱うことができます。2 つのベクトルが非バイナリ形式で互いに離れているほど、任意の次元で一方が正の値を持ち、他方が負の値を持つ確率が高くなります。これは、バイナリ形式では、一方が 0 で他方が 1 である次元がより多くなる可能性が高いことを意味します。これによりハミング距離でより離れた位置にあることになります。
逆に、より近いベクトルについては:非バイナリベクトルが近いほど、任意の次元で両方とも 0 または両方とも 1 を持つ確率が高くなります。これによりハミング距離でより近い位置にあることになります。
Jina Embeddings のモデルが 2 値化に非常に適しているのは、ネガティブマイニングやその他の微調整の実践を使用して、特に異なるものの間の距離を増加させ、似ているものの間の距離を減少させるように訓練されているためです。これにより、埋め込みはより頑健になり、類似性と違いにより敏感になり、バイナリ埋め込み間のハミング距離が非バイナリ埋め込み間のコサイン距離により比例するようになります。
tagJina AI のバイナリ埋め込みでどれだけ節約できるか?
Jina AI のバイナリ埋め込みモデルを採用することで、時間に敏感なアプリケーションのレイテンシーを低減するだけでなく、以下の表が示すように、かなりのコスト削減効果も得られます:
| モデル | 2億5000万の 埋め込みあたりの メモリ |
検索 ベンチマーク 平均 |
AWS での推定価格 (x2gb インスタンスで 月額 $3.8/GB) |
|---|---|---|---|
| 32 ビット浮動小数点埋め込み | 715 GB | 47.13 | $35,021 |
| バイナリ埋め込み | 22.3 GB | 42.05 | $1,095 |
このような 95% 以上の削減は、検索精度の低下が約 10% に抑えられています。
これは、OpenAI の Ada 2 モデルやCohere の Embed v3 の 2 値化ベクトルを使用する場合よりもさらに大きな削減効果です。これらのモデルは 1024 次元以上の出力埋め込みを生成します。Jina AI の埋め込みは 768 次元しかなく、量子化する前の段階で同じ精度でも他のモデルよりもサイズが小さくなっています。
これらの節約は環境面でも効果があり、希少材料やエネルギーの使用を抑えることができます。
tagはじめに
Jina Embeddings API を使用して 2 値埋め込みを取得するには、API 呼び出しに encoding_type パラメータを追加し、符号付き整数としてエンコードされた 2 値化埋め込みを取得する場合は binary、符号なし整数の場合は ubinary を値として指定するだけです。
tagJina Embedding API に直接アクセス
curl を使用する場合:
curl https://api.jina.ai/v1/embeddings \
-H "Content-Type: application/json" \
-H "Authorization: Bearer <YOUR API KEY>" \
-d '{
"input": ["Your text string goes here", "You can send multiple texts"],
"model": "jina-embeddings-v2-base-en",
"encoding_type": "binary"
}'
または Python の requests API を使用する場合:
import requests
headers = {
"Content-Type": "application/json",
"Authorization": "Bearer <YOUR API KEY>"
}
data = {
"input": ["Your text string goes here", "You can send multiple texts"],
"model": "jina-embeddings-v2-base-en",
"encoding_type": "binary",
}
response = requests.post(
"https://api.jina.ai/v1/embeddings",
headers=headers,
json=data,
)
上記の Python request を使用すると、response.json() を確認することで以下のようなレスポンスが得られます:
{
"model": "jina-embeddings-v2-base-en",
"object": "list",
"usage": {
"total_tokens": 14,
"prompt_tokens": 14
},
"data": [
{
"object": "embedding",
"index": 0,
"embedding": [
-0.14528547,
-1.0152762,
...
]
},
{
"object": "embedding",
"index": 1,
"embedding": [
-0.109809875,
-0.76077706,
...
]
}
]
}
これらは 96 個の 8 ビット符号付き整数として保存された 2 つの 2 値埋め込みベクトルです。これらを 768 個の 0 と 1 に展開するには、numpy ライブラリを使用する必要があります:
import numpy as np
# assign the first vector to embedding0
embedding0 = response.json()['data'][0]['embedding']
# convert embedding0 to a numpy array of unsigned 8-bit ints
uint8_embedding = np.array(embedding0).astype(numpy.uint8)
# unpack to binary
np.unpackbits(uint8_embedding)
結果として、0 と 1 のみからなる 768 次元のベクトルが得られます:
array([0, 0, 1, 1, 0, 1, 1, 0, 1, 1, 0, 0, 0, 1, 0, 1, 1, 1, 1, 1, 0, 0,
0, 0, 1, 1, 1, 1, 1, 1, 0, 0, 1, 1, 0, 0, 0, 1, 1, 1, 0, 1, 0, 1,
0, 0, 0, 0, 0, 0, 1, 0, 1, 0, 0, 1, 1, 0, 0, 0, 0, 1, 0, 1, 1, 1,
0, 0, 0, 0, 1, 1, 1, 0, 0, 1, 0, 0, 0, 0, 1, 1, 1, 1, 0, 1, 0, 1,
1, 1, 0, 1, 1, 1, 1, 0, 0, 0, 1, 1, 1, 1, 1, 0, 1, 0, 1, 0, 0, 0,
0, 0, 1, 0, 0, 0, 1, 0, 1, 1, 0, 0, 1, 0, 1, 1, 1, 1, 0, 0, 1, 0,
1, 0, 0, 1, 1, 0, 0, 1, 0, 1, 1, 0, 0, 0, 0, 1, 0, 0, 1, 0, 0, 1,
1, 0, 1, 0, 1, 1, 0, 0, 0, 1, 0, 1, 1, 1, 0, 0, 1, 1, 0, 0, 0, 1,
1, 1, 0, 1, 0, 1, 1, 1, 1, 0, 1, 0, 0, 1, 0, 0, 1, 0, 1, 0, 1, 1,
0, 0, 0, 1, 1, 1, 0, 0, 0, 0, 0, 0, 1, 1, 0, 1, 0, 0, 0, 1, 1, 1,
1, 0, 0, 1, 0, 0, 0, 1, 0, 1, 0, 0, 1, 0, 1, 0, 1, 0, 0, 1, 0, 0,
0, 0, 0, 0, 1, 0, 0, 0, 1, 1, 1, 0, 1, 1, 0, 1, 1, 0, 1, 0, 0, 0,
1, 0, 0, 1, 0, 0, 1, 0, 0, 0, 1, 1, 0, 1, 1, 0, 0, 0, 1, 0, 0, 1,
0, 0, 0, 0, 0, 1, 1, 0, 0, 1, 1, 1, 1, 0, 1, 0, 1, 0, 1, 1, 1, 1,
1, 0, 1, 0, 0, 0, 1, 0, 0, 1, 0, 1, 1, 1, 0, 1, 1, 1, 1, 1, 1, 0,
0, 0, 0, 0, 1, 0, 1, 1, 1, 0, 1, 1, 1, 1, 0, 0, 0, 0, 0, 1, 1, 1,
1, 1, 1, 1, 0, 1, 0, 0, 0, 0, 0, 0, 1, 0, 0, 1, 0, 1, 0, 1, 0, 1,
1, 0, 1, 1, 1, 0, 0, 1, 0, 1, 1, 0, 1, 0, 0, 1, 1, 0, 0, 0, 1, 1,
0, 0, 0, 1, 1, 1, 1, 1, 0, 1, 1, 0, 1, 0, 0, 0, 1, 1, 0, 1, 1, 0,
1, 0, 1, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 1, 1, 1, 1, 0, 1, 1, 1, 0,
0, 0, 0, 0, 0, 1, 1, 1, 1, 0, 1, 0, 1, 1, 0, 1, 0, 1, 1, 1, 0, 0,
0, 0, 1, 1, 1, 0, 1, 0, 1, 0, 0, 1, 0, 1, 0, 0, 0, 1, 1, 1, 0, 1,
0, 1, 1, 1, 0, 1, 1, 0, 1, 0, 1, 1, 1, 1, 1, 0, 1, 0, 0, 0, 1, 0,
0, 1, 1, 1, 0, 1, 1, 0, 0, 1, 1, 0, 1, 1, 0, 1, 1, 1, 0, 1, 1, 0,
1, 1, 0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 1, 1, 1, 1, 0, 1, 1, 0,
0, 1, 0, 0, 1, 1, 0, 1, 0, 0, 1, 0, 0, 1, 0, 1, 0, 1, 1, 1, 0, 0,
0, 0, 1, 1, 0, 1, 0, 0, 1, 1, 1, 1, 1, 0, 1, 0, 1, 1, 1, 1, 0, 1,
1, 0, 1, 1, 0, 1, 1, 0, 1, 0, 0, 1, 0, 0, 0, 1, 0, 1, 0, 1, 1, 0,
1, 1, 1, 0, 0, 0, 1, 0, 0, 1, 0, 0, 0, 1, 0, 0, 1, 0, 1, 1, 0, 0,
1, 0, 1, 1, 1, 1, 1, 1, 1, 0, 1, 0, 0, 0, 1, 0, 0, 1, 1, 1, 0, 1,
1, 1, 0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 1, 1, 0, 1, 1, 0, 0, 1, 1, 0,
1, 0, 1, 0, 0, 0, 0, 0, 0, 0, 1, 1, 0, 0, 0, 1, 0, 0, 1, 1, 0, 1,
1, 1, 1, 0, 0, 1, 1, 1, 0, 1, 0, 0, 1, 1, 0, 1, 1, 1, 1, 1, 1, 0,
1, 1, 1, 0, 0, 1, 1, 0, 0, 1, 0, 0, 1, 1, 0, 0, 0, 1, 0, 1, 1, 1,
0, 0, 1, 1, 0, 0, 1, 0, 1, 1, 1, 1, 1, 0, 1, 0, 0, 1, 0, 0],
dtype=uint8)
tagQdrant での 2 値量子化の使用
Qdrant の統合ライブラリを使用して、2 値埋め込みを Qdrant ベクトルストアに直接格納することもできます。Qdrant は内部的に BinaryQuantization を実装しているため、ベクトルコレクション全体のプリセット設定として使用でき、コードを変更することなく 2 値ベクトルの検索と保存が可能です。
使用方法は以下のコード例を参照してください:
import qdrant_client
import requests
from qdrant_client.models import Distance, VectorParams, Batch, BinaryQuantization, BinaryQuantizationConfig
# Jina API キーを提供し、利用可能なモデルの1つを選択します。
# 無料トライアルキーはこちらで取得できます:https://jina.ai/embeddings/
JINA_API_KEY = "jina_xxx"
MODEL = "jina-embeddings-v2-base-en" # または "jina-embeddings-v2-base-en"
EMBEDDING_SIZE = 768 # small バリアントの場合は 512
# API からエンベディングを取得
url = "https://api.jina.ai/v1/embeddings"
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {JINA_API_KEY}",
}
text_to_encode = ["Your text string goes here", "You can send multiple texts"]
data = {
"input": text_to_encode,
"model": MODEL,
}
response = requests.post(url, headers=headers, json=data)
embeddings = [d["embedding"] for d in response.json()["data"]]
# エンベディングを Qdrant にインデックス化
client = qdrant_client.QdrantClient(":memory:")
client.create_collection(
collection_name="MyCollection",
vectors_config=VectorParams(size=EMBEDDING_SIZE, distance=Distance.DOT, on_disk=True),
quantization_config=BinaryQuantization(binary=BinaryQuantizationConfig(always_ram=True)),
)
client.upload_collection(
collection_name="MyCollection",
ids=list(range(len(embeddings))),
vectors=embeddings,
payload=[
{"text": x} for x in text_to_encode
],
)検索を設定するには、oversampling と rescore パラメータを使用する必要があります:
from qdrant_client.models import SearchParams, QuantizationSearchParams
results = client.search(
collection_name="MyCollection",
query_vector=embeddings[0],
search_params=SearchParams(
quantization=QuantizationSearchParams(
ignore=False,
rescore=True,
oversampling=2.0,
)
)
)tagLlamaIndex を使用する
Jina バイナリエンベディングを LlamaIndex で使用するには、JinaEmbedding オブジェクトをインスタンス化する際に encoding_queries パラメータを binary に設定します:
from llama_index.embeddings.jinaai import JinaEmbedding
# 無料トライアルキーはこちらで取得できます:https://jina.ai/embeddings/
JINA_API_KEY = "<YOUR API KEY>"
jina_embedding_model = JinaEmbedding(
api_key=jina_ai_api_key,
model="jina-embeddings-v2-base-en",
encoding_queries='binary',
encoding_documents='float'
)
jina_embedding_model.get_query_embedding('Query text here')
jina_embedding_model.get_text_embedding_batch(['X', 'Y', 'Z'])
tagバイナリエンベディングをサポートする他のベクトルデータベース
以下のベクトルデータベースはバイナリベクトルをネイティブにサポートしています:
tag例
バイナリエンベディングの実際の動作を示すために、arXiv.org から選んだアブストラクトに対して、jina-embeddings-v2-base-en を使用して 32 ビット浮動小数点とバイナリベクトルの両方を取得しました。そして、サンプルクエリ「3D segmentation」に対するエンベディングと比較しました。
下の表から分かるように、上位3件は同じで、上位5件中4件が一致しています。バイナリベクトルを使用しても、ほぼ同じトップマッチが得られています。
| バイナリ | 32ビット浮動小数点 | |||
|---|---|---|---|---|
| ランク | ハミング 距離 |
マッチしたテキスト | コサイン | マッチしたテキスト |
| 1 | 0.1862 | SEGMENT3D: A Web-based Application for Collaboration... |
0.2340 | SEGMENT3D: A Web-based Application for Collaboration... |
| 2 | 0.2148 | Segmentation-by-Detection: A Cascade Network for... |
0.2857 | Segmentation-by-Detection: A Cascade Network for... |
| 3 | 0.2174 | Vox2Vox: 3D-GAN for Brain Tumour Segmentation... |
0.2973 | Vox2Vox: 3D-GAN for Brain Tumour Segmentation... |
| 4 | 0.2318 | DiNTS: Differentiable Neural Network Topology Search... |
0.2983 | Anisotropic Mesh Adaptation for Image Segmentation... |
| 5 | 0.2331 | Data-Driven Segmentation of Post-mortem Iris Image... |
0.3019 | DiNTS: Differentiable Neural Network Topology... |
