




多言語モデルにおける主要な課題の1つは、「言語ギャップ」です。これは、異なる言語で同じ意味を持つフレーズが、本来あるべき程度には近接してクラスタリングされない現象を指します。理想的には、ある言語のテキストと、その他の言語での等価表現は類似した表現(つまり、非常に近い埋め込み)を持つべきであり、これにより異なる言語のテキストに対して同じように機能するクロス言語アプリケーションが可能になります。しかし、モデルは微妙にテキストの言語を表現してしまい、クロス言語パフォーマンスの低下につながる「言語ギャップ」を生み出します。
この記事では、この言語ギャップと、それがテキスト埋め込みモデルのパフォーマンスにどのような影響を与えるかを探ります。私たちは、jina-xlm-robertaモデルと最新のjina-embeddings-v3を使用して、同じ言語内のパラフレーズや異なる言語ペア間の翻訳の意味的整列を評価する実験を行いました。これらの実験により、異なるトレーニング条件下で、類似または同一の意味を持つフレーズがどの程度うまくクラスタリングされるかが明らかになりました。

私たちはまた、クロス言語の意味的整列を改善するためのトレーニング手法、特に対照学習におけるパラレル多言語データの導入についても実験を行いました。この記事では、その洞察と結果を共有します。
tag多言語モデルトレーニングは言語ギャップを作り出し、そして縮小する
テキスト埋め込みモデルのトレーニングは、通常2つの主要な部分からなる多段階プロセスを含みます:
- マスク言語モデリング(MLM):事前学習は通常、一部のトークンがランダムにマスクされた大量のテキストを使用します。モデルはこれらのマスクされたトークンを予測するようトレーニングされます。この手順により、モデルは構文、語彙的意味論、実世界の制約から生じる可能性のあるトークン間の選択依存関係を含む、トレーニングデータの言語パターンを学習します。
- 対照学習:事前学習後、モデルは意味的に類似したテキストの埋め込みをより近づけ、(任意で)類似していないものをより遠ざけるために、キュレーションされた、または半キュレーションされたデータでさらにトレーニングされます。このトレーニングでは、意味的類似性が既に知られているか、少なくとも信頼性高く推定されているテキストのペア、トリプレット、あるいはグループを使用することができます。これには複数のサブステージがある場合があり、このプロセスの部分に対して様々なトレーニング戦略が存在します。新しい研究が頻繁に発表されており、最適なアプローチについての明確なコンセンサスはありません。
言語ギャップがどのように生じ、どのように解消できるかを理解するには、両段階の役割を見る必要があります。
tagマスク言語事前学習
テキスト埋め込みモデルのクロス言語能力の一部は、事前学習中に獲得されます。
同源語や借用語により、モデルは大量のテキストデータから言語間の意味的整列の一部を学習することが可能になります。例えば、英語の banana とフランス語の banane(およびドイツ語の Banane)は、頻出し、綴りも十分似ているため、埋め込みモデルは"banan-"のような形の単語が言語間で類似した分布パターンを持つことを学習できます。この情報を活用して、言語間で見た目が異なる他の単語も同様の意味を持つことをある程度学習し、文法構造がどのように翻訳されるかさえも理解できます。
しかし、これは明示的なトレーニングなしに起こります。
jina-embeddings-v3の事前学習済みバックボーンであるjina-xlm-robertaモデルを使用して、マスク言語事前学習から言語間の等価性をどの程度学習したかをテストしました。英語の文章をドイツ語、オランダ語、簡体字中国語、日本語に翻訳したセットの2次元UMAP 文章表現をプロットしました。結果は以下の図の通りです:
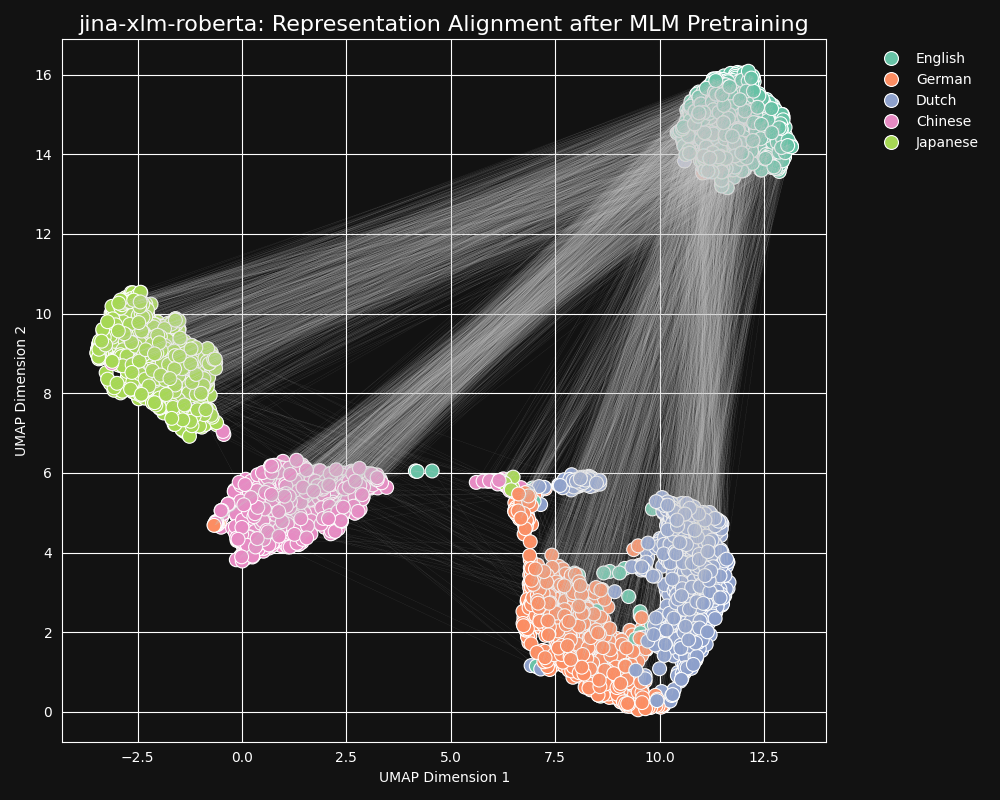
これらの文章は
jina-xlm-roberta の埋め込み空間で、強く言語固有のクラスターを形成する傾向があります。ただし、この投影では2次元への投影の副作用かもしれない外れ値がいくつか見られます。事前学習が同じ言語の文章の埋め込みを非常に強くクラスタリングしていることがわかります。これはより高次元の空間での分布を2次元に投影したものなので、例えば、英語の文章の良いドイツ語訳が、その英語元文の埋め込みに最も近いドイツ語文の埋め込みである可能性はまだあります。しかし、英語の文章の埋め込みは、意味的に同一または非常に近いドイツ語文よりも、別の英語文に近い可能性が高いことを示しています。
また、ドイツ語とオランダ語が他の言語ペアよりもはるかに近いクラスターを形成していることにも注目してください。これは、比較的近い関係にある2つの言語としては驚くべきことではありません。ドイツ語とオランダ語は、時に部分的に相互理解が可能なほど似ています。
日本語と中国語も他の言語よりも近いように見えます。両者は同じような関係ではありませんが、書き言葉の日本語は通常漢字(漢字)、中国語ではhànzìを使用します。日本語はこれらの文字の大部分を中国語と共有しており、両言語は一つまたは複数の漢字/hànzì で書かれる多くの単語を共有しています。MLM の観点からは、これはドイツ語とオランダ語の間にある視覚的な類似性と同じ種類のものです。
この「言語ギャップ」は、2つの言語それぞれ2文ずつを見るだけでもより単純な形で確認できます:

MLM は自然にテキストを言語でクラスタリングする傾向があるため、"my dog is blue" と "my cat is red" は、それらのドイツ語の対応訳から遠く離れて一緒にクラスタリングされています。以前のブログ記事で議論された「モダリティギャップ」とは異なり、これは言語間の表面的な類似点と相違点から生じると考えられます:類似した綴り、印刷における同じ文字列の使用、そして可能性として形態論と構文構造の類似性(共通の語順や単語の構築方法)です。
要するに、モデルが MLM 事前学習で言語間の等価性を学習している程度は、言語によるテキストのクラスタリングへの強いバイアスを克服するには十分ではありません。大きな言語ギャップが残ります。
tag対照学習
理想的には、埋め込みモデルは言語に無関心で、その埋め込みに一般的な意味のみをエンコードすることが望ましいです。そのようなモデルでは、言語によるクラスタリングは見られず、言語ギャップも存在しないはずです。ある言語の文章は、良い翻訳に非常に近く、たとえ同じ言語であっても、別の意味を持つ他の文章からは遠く離れているべきです。以下の図のようになります:

MLM 事前学習だけではそれを達成できないため、埋め込みにおけるテキストの意味的表現を改善するために追加の対照学習技術を使用します。
対照学習では、意味的に類似または相違があることが分かっているテキストのペアや、一方のペアがもう一方よりも類似していることが分かっているトリプレットを使用します。トレーニング中に、これらのテキストペアとトリプレット間の既知の関係を反映するように重みが調整されます。
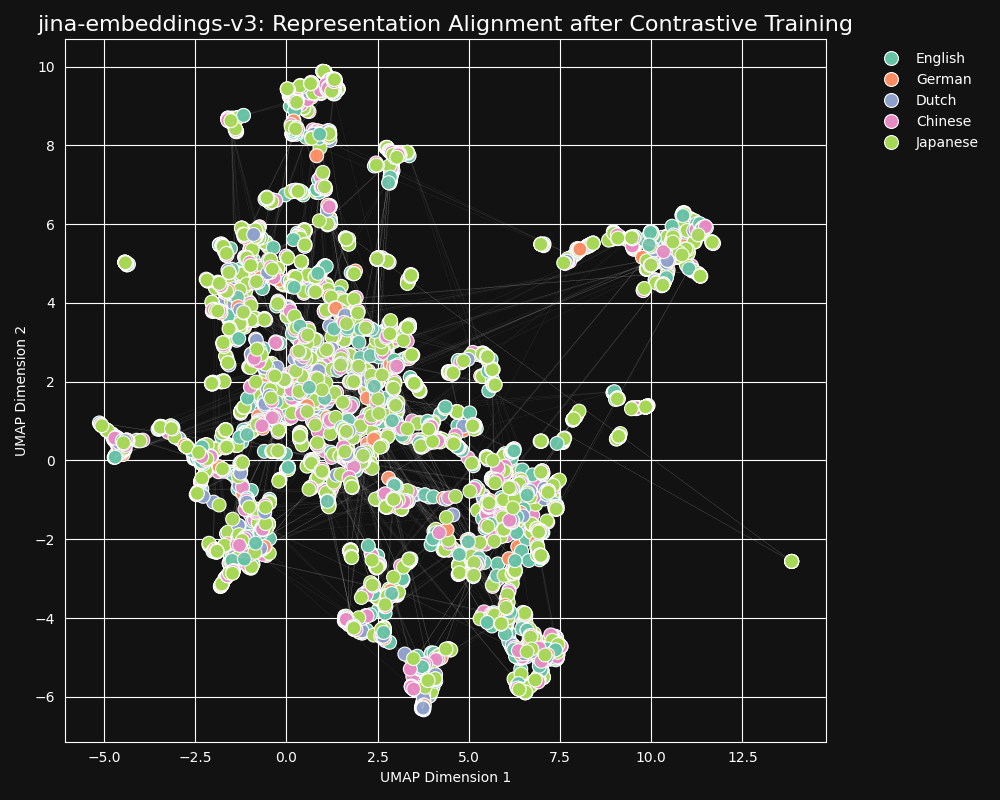
私たちの対照学習データセットには30の言語が含まれていますが、ペアとトリプレットの97%は単一言語内のものであり、クロス言語のペアやトリプレットは3%にすぎません。しかし、この3%だけでも劇的な結果を生み出しています:jina-embeddings-v3からの埋め込みの UMAP 投影が示すように、埋め込みはほとんど言語クラスタリングを示さず、意味的に類似したテキストは言語に関係なく近い埋め込みを生成します。
これを確認するため、STS17 データセットにおいて jina-xlm-roberta と jina-embeddings-v3 が生成した表現の Spearman 相関を測定しました。
以下の表は、翻訳されたテキストの異なる言語間での意味的類似性ランキングの Spearman 相関を示しています。英語の文のセットを取り、それらの埋め込みと特定の参照文の埋め込みとの類似性を測定し、最も類似性が高いものから低いものへと順序付けます。その後、それらの文を別の言語に翻訳してランキングプロセスを繰り返します。理想的な言語横断的な埋め込みモデルでは、2つの順序付けられたリストは同じになり、Spearman 相関は 1.0 となります。
以下のグラフと表は、jina-xlm-roberta と jina-embeddings-v3 の両方を使用して、STS17 ベンチマークにおける英語と他の6言語との比較結果を示しています。
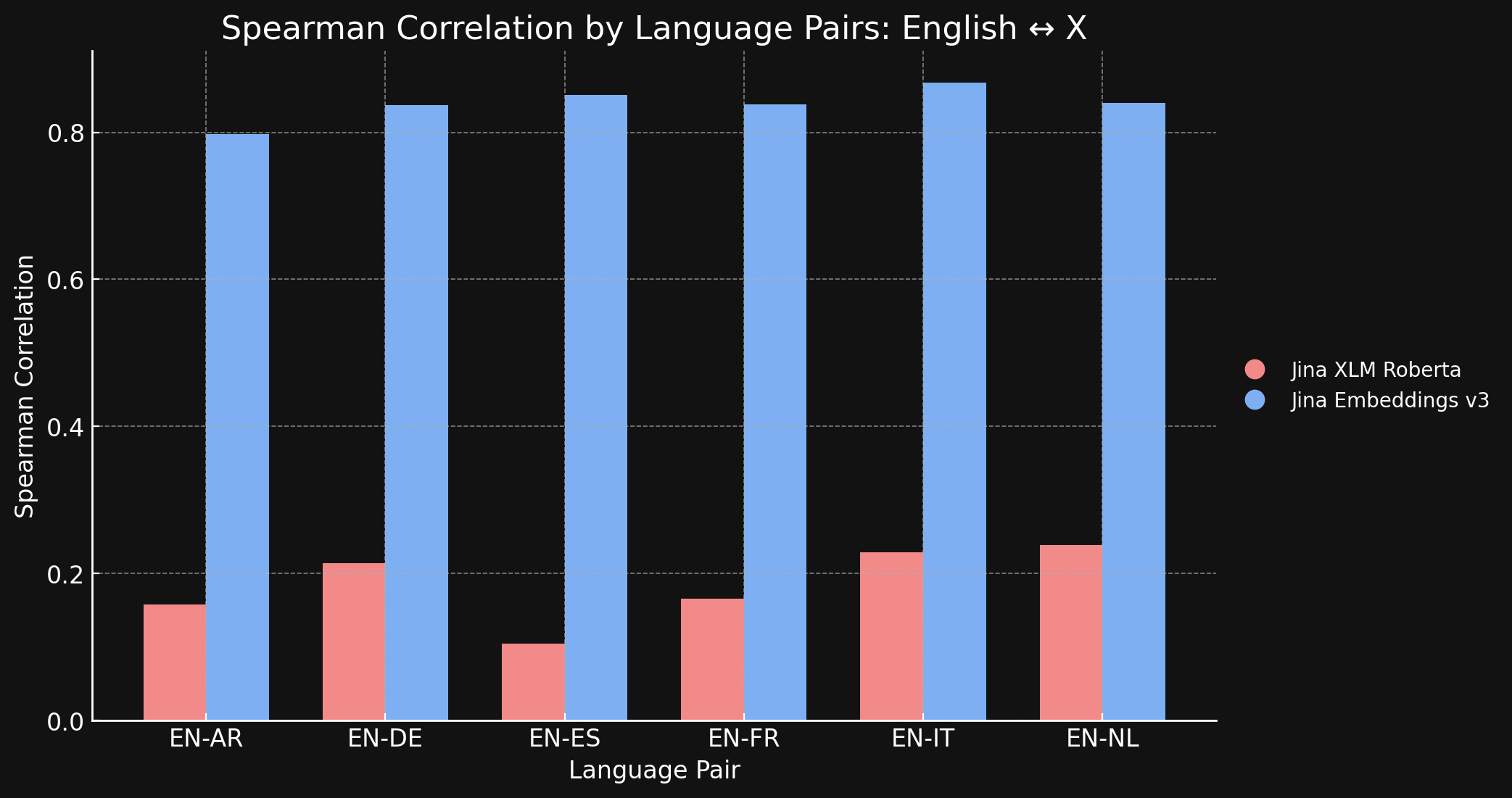
| Task | jina-xlm-roberta |
jina-embeddings-v3 |
|---|---|---|
| English ↔ Arabic | 0.1581 | 0.7977 |
| English ↔ German | 0.2136 | 0.8366 |
| English ↔ Spanish | 0.1049 | 0.8509 |
| English ↔ French | 0.1659 | 0.8378 |
| English ↔ Italian | 0.2293 | 0.8674 |
| English ↔ Dutch | 0.2387 | 0.8398 |
事前学習と比較して、対照学習が生む大きな違いがここに示されています。学習データの中で言語横断的なデータはわずか3%しかありませんが、jina-embeddings-v3 モデルは事前学習で獲得した言語間のギャップをほぼ解消するのに十分な言語横断的な意味論を学習しています。
tag英語対世界:他の言語は整列性を保てるか?
私たちは jina-embeddings-v3 を89の言語で学習させ、特に広く使用されている30の書き言葉に焦点を当てました。大規模な多言語学習コーパスを構築する努力にもかかわらず、対照学習で使用したデータの約半分は依然として英語が占めています。英語のデータの膨大さに比べると、豊富なテキスト資料が入手可能な広く使用されているグローバル言語を含む他の言語は、依然として比較的少ない割合となっています。
この英語の優位性を考えると、英語の表現は他の言語よりも整列性が高いのでしょうか?これを探るために、フォローアップ実験を実施しました。
私たちは parallel-sentences というデータセットを構築しました。これは1,000組の英語テキストペアで構成され、「アンカー」と「ポジティブ」から成り、ポジティブテキストはアンカーテキストから論理的に導き出されるものです。

例えば、以下の表の最初の行を見てください。これらの文は意味的に完全に同一ではありませんが、互換性のある意味を持っています。同じ状況を情報豊かに説明しています。
私たちはこれらのペアを GPT-4 を使用してドイツ語、オランダ語、中国語(簡体字)、中国語(繁体字)、日本語の5言語に翻訳し、品質を確保するために手動で検査を行いました。
| Language | Anchor | Positive |
|---|---|---|
| English | Two young girls are playing outside in a non-urban environment. | Two girls are playing outside. |
| German | Zwei junge Mädchen spielen draußen in einer nicht urbanen Umgebung. | Zwei Mädchen spielen draußen. |
| Dutch | Twee jonge meisjes spelen buiten in een niet-stedelijke omgeving. | Twee meisjes spelen buiten. |
| Chinese (Simplified) | 两个年轻女孩在非城市环境中玩耍。 | 两个女孩在外面玩。 |
| Chinese (Traditional) | 兩個年輕女孩在非城市環境中玩耍。 | 兩個女孩在外面玩。 |
| Japanese | 2人の若い女の子が都市環境ではない場所で遊んでいます。 | 二人の少女が外で遊んでいます。 |
その後、jina-embeddings-v3 を使用して各テキストペアをエンコードし、それらの間のコサイン類似度を計算しました。以下の図と表は、各言語のコサイン類似度スコアの分布と平均類似度を示しています:
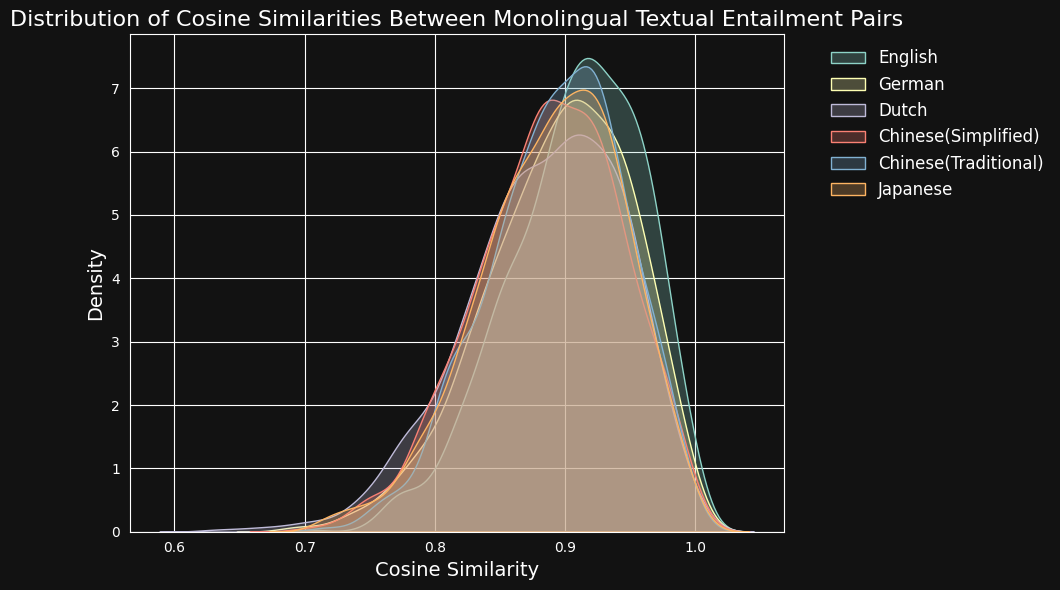
| Language | Average Cosine Similarity |
|---|---|
| English | 0.9078 |
| German | 0.8949 |
| Dutch | 0.8844 |
| Chinese (Simplified) | 0.8876 |
| Chinese (Traditional) | 0.8933 |
| Japanese | 0.8895 |
学習データにおける英語の優位性にもかかわらず、jina-embeddings-v3 は英語と同程度に、ドイツ語、オランダ語、日本語、そして両形式の中国語における意味的類似性を認識することができます。
tag言語の壁を破る:英語を超えた言語横断的整列
クロス言語の表現整合性の研究は、通常、英語を含む言語ペアを対象としています。理論的には、この偏りによって実際に起きていることが見えにくくなる可能性があります。モデルは、他の言語ペアが適切にサポートされているかどうかを検証せずに、すべてを英語の等価物にできるだけ近づけるように最適化しているかもしれません。
これを調べるため、私たちは parallel-sentences データセットを使用して、英語のバイリンガルペアだけでなく、クロスリンガルな整合性に関する実験を行いました。
以下の表は、異なる言語ペア間で等価なテキスト(共通の英語ソースの翻訳)におけるコサイン類似度の分布を示しています。理想的には、すべてのペアでコサイン類似度が1(つまり、意味的な埋め込みが同一)となるはずです。実際にはそれは不可能ですが、優れたモデルであれば翻訳ペアで非常に高いコサイン値を示すことが期待されます。
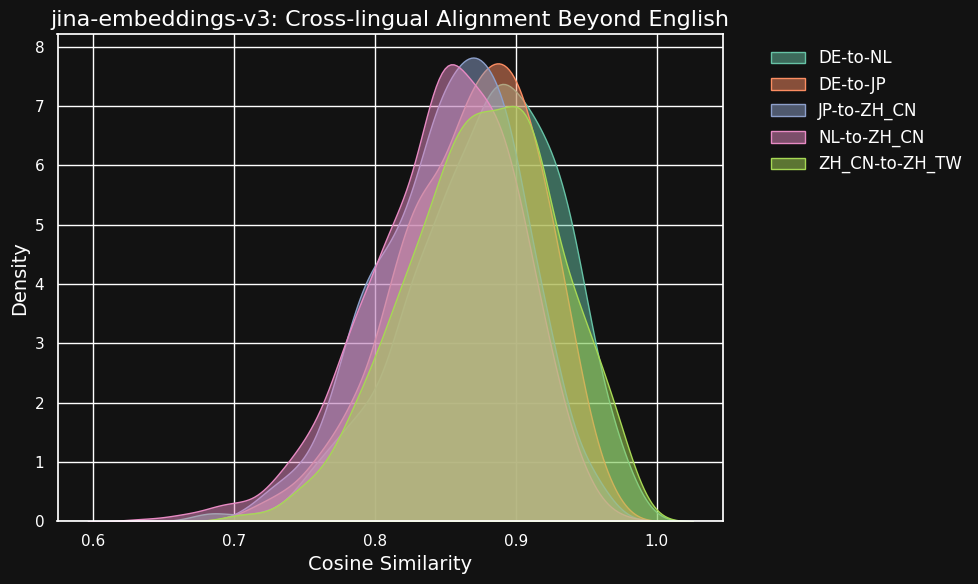
| Language Pair | Average Cosine Similarity |
|---|---|
| German ↔ Dutch | 0.8779 |
| German ↔ Japanese | 0.8664 |
| Chinese (Simplified) ↔ Japanese | 0.8534 |
| Dutch ↔ Chinese (Simplified) | 0.8479 |
| Chinese (Simplified) ↔ Chinese (Traditional) | 0.8758 |
異なる言語間の類似度スコアは同じ言語内の互換性のあるテキスト間と比べてやや低いものの、依然として非常に高い値を示しています。オランダ語とドイツ語の翻訳間のコサイン類似度は、ドイツ語内の互換性のあるテキスト間とほぼ同じ高さです。
これは、ドイツ語とオランダ語が非常に似ている言語であることを考えると、驚くことではないかもしれません。同様に、ここでテストした2種類の中国語は実際には2つの異なる言語ではなく、同じ言語の文体的に少し異なる形態にすぎません。しかし、オランダ語と中国語、あるいはドイツ語と日本語のような非常に異なる言語ペアでも、意味的に等価なテキスト間で非常に強い類似性を示していることがわかります。
これらの非常に高い類似度の値が、翻訳者として ChatGPT を使用したことの副作用である可能性を考慮しました。これを検証するため、TED Talks の人手による英語とドイツ語の翻訳原稿をダウンロードし、整合された翻訳文が同様の高い相関を示すかどうかを確認しました。
結果は、以下の図からわかるように、機械翻訳データよりもさらに強い相関を示しました。
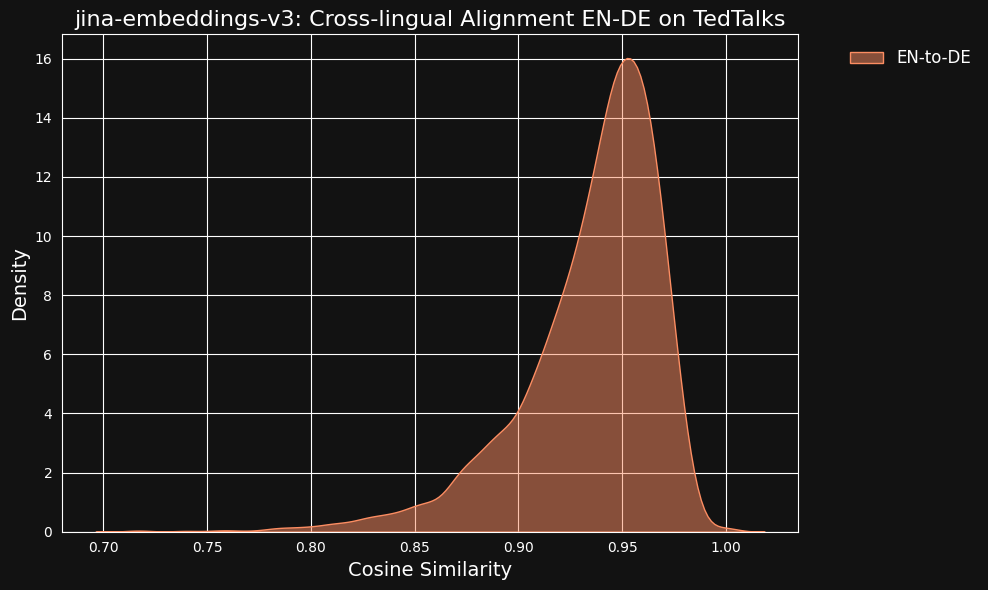
tagクロス言語データはクロス言語整合性にどの程度寄与しているか?
言語間の差異の消失と高いクロス言語パフォーマンスは、明示的にクロス言語であるトレーニングデータの割合(わずか3%)と比較して不釣り合いに見えます。
そこで、クロス言語が実際に寄与しているかどうかをテストしました。
クロス言語データなしで jina-embeddings-v3 を完全に再トレーニングするのは小規模な実験としては費用がかかりすぎるため、Hugging Face から xlm-roberta-base モデルをダウンロードし、jina-embeddings-v3 のトレーニングに使用したデータのサブセットを使用して対照学習でさらにトレーニングを行いました。特に、クロス言語データの量を調整して2つのケースをテストしました:クロス言語データなしのケースと、ペアの20%がクロス言語のケースです。トレーニングのメタパラメータは以下の表のとおりです:
| Backbone | % Cross-Language | Learning Rate | Loss Function | Temperature |
xlm-roberta-base without X-language data | 0% | 5e-4 | InfoNCE | 0.05 |
xlm-roberta-base with X-language data | 20% | 5e-4 | InfoNCE | 0.05 |
その後、MTEB の STS17 および STS22 ベンチマークとスピアマン相関を使用して、両モデルのクロスリンガルパフォーマンスを評価しました。結果は以下の通りです:
tagSTS17
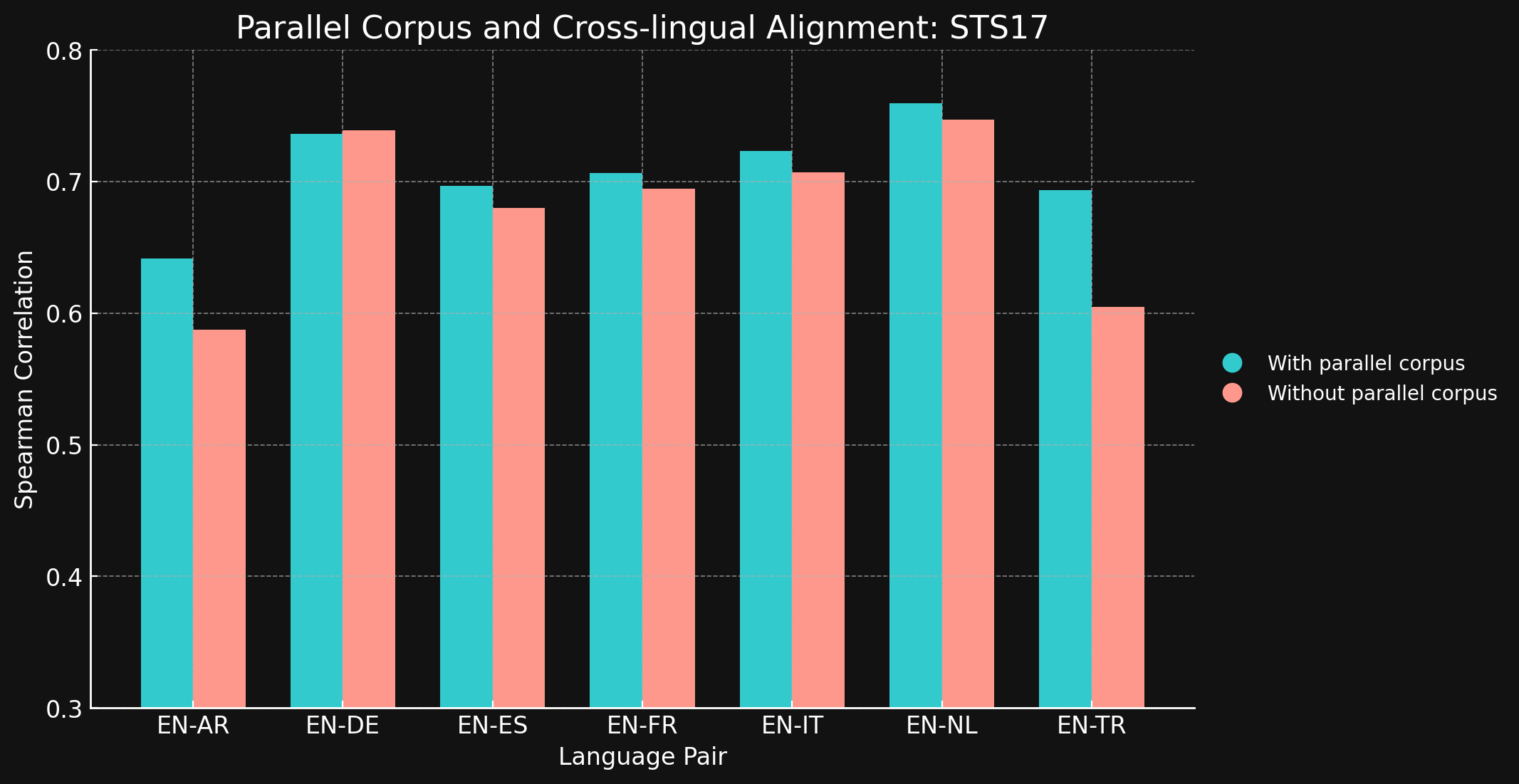
| Language Pair | With parallel corpora | Without parallel corpora |
| English ↔ Arabic | 0.6418 | 0.5875 |
| English ↔ German | 0.7364 | 0.7390 |
| English ↔ Spanish | 0.6968 | 0.6799 |
| English ↔ French | 0.7066 | 0.6944 |
| English ↔ Italian | 0.7232 | 0.7070 |
| English ↔ Dutch | 0.7597 | 0.7468 |
| English ↔ Turkish | 0.6933 | 0.6050 |
tagSTS22
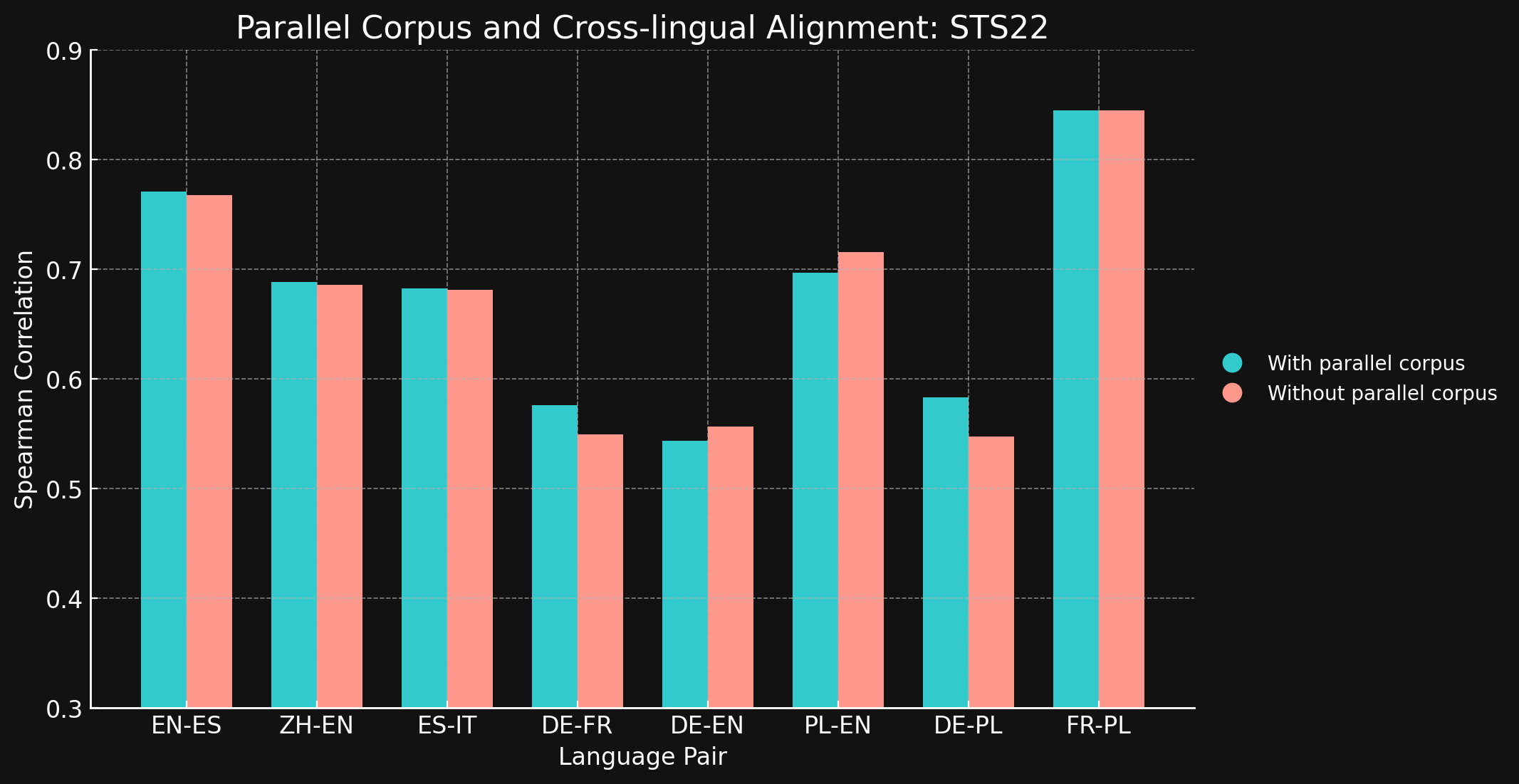
| 言語ペア | パラレルコーパスあり | パラレルコーパスなし |
| English ↔ Spanish | 0.7710 | 0.7675 |
| Simplified Chinese ↔ English | 0.6885 | 0.6860 |
| Spanish ↔ Italian | 0.6829 | 0.6814 |
| German ↔ French | 0.5763 | 0.5496 |
| German ↔ English | 0.5439 | 0.5566 |
| Polish ↔ English | 0.6966 | 0.7156 |
| German ↔ English | 0.5832 | 0.5478 |
| French ↔ Polish | 0.8451 | 0.8451 |
テストした言語ペアのほとんどにおいて、クロスリンガル学習データがほとんどまたはまったく改善をもたらさなかったことに驚きました。より大きなデータセットを使用して完全に学習されたモデルでもこの結果が維持されるかどうかを確信することは難しいですが、明示的なクロス言語学習があまり効果を持たないという証拠を確かに示しています。
ただし、STS17 には English/Arabic と English/Turkish のペアも含まれていることに注目してください。これらは両方とも、私たちの学習データであまり表現されていない言語です。使用した XML-RoBERTa モデルは、アラビア語が 2.25%、トルコ語が 2.32% の事前学習データで、これは他のテストした言語よりもはるかに少ない割合です。この実験で使用した小規模な対照学習データセットでは、アラビア語は 1.7%、トルコ語は 1.8% しかありませんでした。
これらの2つの言語ペアは、クロス言語データでの学習が明確な違いをもたらした唯一のテストケースです。学習データにあまり表現されていない言語の場合、明示的なクロス言語データがより効果的だと考えていますが、結論を出す前にこの分野をさらに探求する必要があります。対照学習におけるクロス言語データの役割と効果は、Jina AI が積極的に研究を行っている分野です。
tag結論
Masked Language Modeling のような従来の言語事前学習手法では、「言語ギャップ」が残ります。これは、異なる言語の意味的に類似したテキストが、本来あるべき程度には近接しないという問題です。Jina Embeddings の対照学習レジメンは、このギャップを減少または解消するのに非常に効果的であることを示しました。
なぜこれが機能するのかは完全には明確ではありません。対照学習では明示的にクロス言語テキストペアを使用していますが、その量はごくわずかで、高品質なクロス言語結果を確保する上で実際にどの程度の役割を果たしているのかは不明確です。より制御された条件で明確な効果を示そうとする試みは、明確な結果を生み出しませんでした。
しかし、jina-embeddings-v3 が事前学習の言語ギャップを克服し、多言語アプリケーションのための強力なツールとなっていることは明らかです。複数の言語にわたって同等の強力なパフォーマンスを必要とするあらゆるタスクに使用する準備ができています。
jina-embeddings-v3 は、私たちの Embeddings API(100万トークンまで無料)、または AWS や Azure を通じて使用できます。これらのプラットフォーム以外や社内で使用する場合は、CC BY-NC 4.0 ライセンスの下でライセンスされていることにご注意ください。商用利用にご興味がある場合は、お問い合わせください。
