


最近、AI 企業がインターネット上のすべてのデータを「許可」の有無に関係なく吸い上げることの危険性について、多くの議論がなされています。「許可」については後ほど触れますが、あえて引用符をつけた理由があります。しかし、オープンウェブが完全に採掘され、コンテンツ提供者が扉を閉ざし、新しいデータをスクレイピングするのがほとんど不可能になった時、LLM にとってそれは何を意味するのでしょうか?
tagAI スクレイピングの危険性
AI 企業はインターネットを食べ放題のデータビュッフェのように扱い、マナーなど気にしていません。Runway が YouTube の利用規約に違反してモデルトレーニング用に動画を収集していること、Anthropic が iFixit に1日100万回もアクセスしていること、そしてNew York Times が著作権のある作品の使用について OpenAI と Microsoft を訴えていることを見てください。
robots.txtや利用規約でスクレイパーをブロックしようとしても、実際には全く役に立ちません。ルールを無視するスクレイパーは構わずスクレイピングを続け、より良心的なものはブロックされます。スクレイパーが良い行動をとるインセンティブは全くありません。これは Data Provenance Initiative の最近の論文でも明らかです:
これは抽象的な問題ではありません - iFixit は金銭的損失を被り、DevOps リソースが枯渇しています。ReadTheDocs は悪質なクローラーにより、たった1ヶ月で5,000ドル以上の帯域幅料金が発生し、1日だけで10 TB近くのトラフィックを記録しました。ウェブサイトを運営していて、ルールを守らないクローラーに攻撃された場合?それはサービス停止につながりかねません。
では、ウェブサイトは何をすべきでしょうか?AI 企業がルールを守らないのであれば、ペイウォールが増え、自由にアクセスできるコンテンツは減少するでしょう。フリーなウェブは もはや存在しません。残されているのは有料のみです。
tagスクレイピングは合法なのか?
スクレイピングは問題があるのでしょうか?はい。合法なのでしょうか?これもはい。ウェブスクレイピングは米国、EU、日本、韓国、カナダで合法です。この行為を特に規制する法律を持つ国はないようですが、誰でも閲覧できるウェブサイトを自動化して訪問し、そのコンテンツの個人的なコピーを作成することは合法だと、世界中の裁判所は一般的に同意しています。
ウェブページやrobots.txtファイルに通知を掲載することで、スクレイピングやその他の合法的な利用を禁止できると考える人もいます。しかしこれは実際には機能しません。そのような通知に法的な意味はなく、robots.txtはIETF の規約であり法的な強制力はありません。少なくとも「利用規約に同意します」というボタンをクリックするなどの確認行為がなければ、ウェブサイトの訪問者に条件を課すことはできません。そしてそれでさえも多くの場合、法的に執行不可能です。
 Joshua J. Kaufman
Joshua J. Kaufmanただし、スクレイピングは合法ですが、いくつかの制限があります:
- ウェブスクレイパーで頻繁すぎるアクセスや高速なアクセスを行い、他のユーザーのウェブサイト利用を妨げるような行為は、極端な場合、民事上または刑事上の結果を招く可能性があります。
- 多くの国では、不正なコンピュータアクセスを犯罪とする法律があります。一般公開されていないことが明らかなウェブサイトの部分をスクレイピングすることは違法となる可能性があります。
- 多くの国では、コピー防止技術を回避することを違法とする法律があります。ウェブサイトがコンテンツのダウンロードを防止する措置を講じている場合、それをスクレイピングすると法律違反となる可能性があります。
- 明示的な利用規約があり、その受諾を確認する必要があるウェブサイトは、スクレイピングを禁止し、それを行った場合に提訴することができますが、結果はまちまちです。
米国では、スクレイピングに関する明示的な法律はありませんが、1986年のComputer Fraud and Abuse Actを使ってこれを禁止しようとする試みは失敗しており、最近では2019年の第9巡回区裁判所のhiQ Labs v. LinkedIn事件でも失敗しています。米国の法律は複雑で、裁判所が作り出した多くの区別や、州と連邦巡回区の管轄システムがあり、最高裁判所が判断を下さない限り、必ずしも最終的なものとはなりません(そして時には最高裁判所の判断でさえも最終的ではありません)。
EU にもスクレイピングを特に対象とする法律はありませんが、長年にわたって一般的な慣行として異議を唱えられることなく行われてきました。2019年の EU 著作権指令のテキストおよびデータマイニング条項は、スクレイピングが一般的に合法であることを強く示唆しています。
最大の法的問題は、スクレイピング行為自体ではなく、スクレイピング後に何が起こるかです。ウェブからスクレイピングしたデータには依然として著作権が適用されます。個人的なコピーは保持できますが、法的問題の可能性なしに再配布や再販売することはできません。
大規模なウェブスクレイピングを行うことは、ほぼ常に様々なデータ保護・プライバシー法で定義される「個人データ」のコピーを作成することを意味します。欧州の GDPR(General Data Protection Regulation)は「個人データ」を次のように定義しています:
識別された、または識別可能な自然人(「データ主体」)に関する情報。識別可能な自然人とは、特に名前、識別番号、位置データ、オンライン識別子、またはその自然人の身体的、生理的、遺伝的、精神的、経済的、文化的もしくは社会的アイデンティティに特有の一つまたは複数の要素を参照することによって、直接的または間接的に識別できる者をいう。
[GDPR, Art. 4.1]
EU に居住する人物または EU 内で行われる活動に関する個人データを保有している場合、GDPR の下で法的責任を負います。その範囲は非常に広いため、大規模なデータ収集の場合はそれが該当すると想定すべきです。データを収集したのがあなたか他人かは関係なく、現在それを保有している場合、あなたにその責任があります。GDPR の義務を果たさない場合、あなたが住んでいる国やデータが保管・処理される場所に関係なく、EU はあなたを処罰することができます。
カナダの PIPEDA(Personal Information Protection and Electronic Documents Act)は GDPR に似ています。日本の APPI(個人情報の保護に関する法律)も同様の範囲をカバーしています。英国は EU 離脱時に GDPR のほとんどの要素を国内法に組み込み、後に改正されない限り、それらは依然として有効です。
米国には連邦レベルで比較可能なデータ保護法はありませんが、CCPA(California Consumer Privacy Act)は GDPR に似た条項を持ち、カリフォルニア州の人々や活動に関するデータを持っている場合に適用されます。
ほとんどの先進国には、ウェブからの大規模なデータ収集の利用を少なくとも一部の面で制限するデータ保護法があります。世界中でスクレイピングに関連する法的手続きのほとんどは、データの収集方法ではなく、その使用方法に関するものでした。
したがって、ウェブスクレイピングはほぼ常に合法です。問題となるのは、その後に何が起こるかです。
tagスクレイピングからの AI トレーニングは合法なのか?
おそらく合法です。
ウェブスクレイピングは、現実的なケースのほぼすべてで著作権で保護されたコンテンツを含むことになります。本当の問題は:所有者の許可なく著作権で保護されたコンテンツを AI のトレーニングに使用できるかということです。
完全には解決されていない法的な論点が多くありますが:
- 欧州では、2019年のEU著作権指令第4条により、いくつかの条件付きで合法とされています。
- 日本では、著作権法第30条第4項(2018年改正)により、許可なく著作物をAIの学習に使用することが認められると解釈されています。
- 米国では、この状況を具体的に規定する法律はありませんが、著作物の統計的分析は、商業製品の場合でも長年合法とされてきました。Authors Guild, Inc. v. Google, Inc.およびAuthors Guild, Inc. v. HathiTrustの訴訟は、AIに特化したものではありませんが、米国法における「フェアユース」の範囲を大幅に拡大し、AIの学習が違法となる可能性は低いと考えられます。アメリカの法制度は明確な回答を提供しておらず、この結論を検証するいくつかの訴訟が現在も進行中です。
他の小規模な法域でも合法と判断されており、私の知る限り、これまでに違法とされた例はありません。
欧州の著作権法では、著作権所有者が「適切な方法で」AIの学習利用を制限できると定めていますが、現時点でその方法に関する具体的な指針はありません。
日本の著作権法は、「著作権者の利益を不当に害する」場合に著作物の使用を制限しています。これは通常、著作権者が特定のAIモデルによって作品の経済的価値が低下することを証明する必要があることを示唆しています。
注目すべきは、Google、Microsoft、OpenAI、Adobe、Shutterstockが、生成AIプロダクトのユーザーが著作権に関する法的問題に直面した場合の補償を提供することを表明していることです。これは、彼らの法務チームが米国法の下でその行為が合法だと考えている強い証左となっています。
tag大規模スクレイピングがAIに与える影響
AIによるスクレイピングの急増により、ウェブはデジタル版の無法地帯と化しています。これらのスクレイパーはrobots.txtを無視し、iFixitのようなウェブサイトに際限のないリクエストを送り続けています。これは単なる迷惑行為ではなく、オープンなインターネットの仕組みを根本から見直さざるを得ない、潜在的にウェブを破壊しかねない問題です。経済的・社会的な観点から見ても、多くの変化が予想されます:
信頼の崩壊:このAIによるデータ収集の熱狂は、ウェブ全体での信頼関係を大きく損なう可能性があります。コンテンツを閲覧する前に人間であることを証明する必要がある未来を想像してください。より多くのCAPTCHA、ログインの壁、「交通信号をすべてクリックしてください」といったテストが待ち受けることになるでしょう。まるで密造酒場に入るように、秘密の合言葉ではなく、自分が賢い機械ではないことを証明しなければならないのです。
人間が生成するコンテンツの制限:コンテンツクリエイターは、自分の作品が盗用されることを警戒し、防衛態勢を強めています。有料化、会員限定コンテンツ、コンテンツロックの増加が予想されます。自由にブラウジングして学べる時代は、ダイヤルアップモデムの音やAIMのステータスメッセージのように、懐かしい思い出となるかもしれません。一般の人々がアクセスできないなら、不正なスクレイパーはなおさらアクセスが困難になります。
法的問題:AIに関する法的問題の解決には、何年、あるいは数十年かかる可能性があります。インターネットは約30年の歴史がありますが、その法的問題の一部は今日でも未解決のままです。正しい立場にあるかどうかに関わらず、何が許可されるかを法廷で何年もかけて確認する余裕がない場合は、懸念材料となります。
小規模サイトの破綻と大手の独占:このスクレイピングの急増は単なる迷惑以上のものです。ウェブインフラに実質的な負荷をかけています。AIによるトラフィック増に対応するためにより強力なサーバーへのアップグレードが必要となり、それは安価ではありません。小規模サイトや情熱的なプロジェクトが市場から淘汰され、この嵐を耐え抜けるだけの規模を持つか、AIカンパニーとライセンス契約を結べる企業だけが残るウェブ(およびLLMの学習データ)となる可能性があります。これは「富める者が生き残る」シナリオであり、インターネット(およびLLMの知識)の多様性と興味深さを損なう可能性があります。自由にアクセス可能なデータへの扉を閉ざすことで、AI企業に入場料を課したり、最高額の入札者にのみライセンスを供与したりすることができます。資金がない?ドアマンが出口を示すでしょう。
tagAIが生成するデータは救世主となるか?
このデータ収集の急増は、ウェブサイトに影響を与えるだけでなく、潜在的なAIの知識不足を引き起こす可能性があります。オープンウェブが門戸を閉ざすにつれ、AIモデルは新鮮で質の高いデータに飢えることになるでしょう。
このデータ不足は、AIのトンネルビジョンという厄介な状況を引き起こす可能性があります。新しい情報の定期的な流入がなければ、AIモデルは古い知識のエコーチェンバーとなるリスクがあります。AIに時事問題について尋ねると、まるで去年の答え、あるいはもっと悪いことに、事実が休暇を取ったパラレルワールドからの答えが返ってくるような状況を想像してください。
人間が生成したデータがロックされている場合でも、企業は学習データをどこかから入手する必要があります。その一例が合成データです:他のLLMを学習させるためにLLMが作成したデータです。これには、モデル蒸留やバイアスを補正するための学習データ生成など、広く使用されている技術が含まれます。

合成データを使用することで、人間が生成したデータのライセンス取得という困難な手続きを回避できます。また、インターネット上のデータは必ずしも現実世界の多様性を反映していないため、合成データの生成はモデルをより現実に即したものにする助けとなります(時にはそうではない場合も)。さらに、医療や法的用途では、合成データにより個人を特定できる情報を削除するためのデータサニタイズが不要になります。
しかし、その反面、将来のモデルは本当に学習させたくないAI生成データでも学習することになります。すなわち「Slop」と呼ばれる低品質なAI生成データです。例えば、かつて愛されていたテックブログが、元スタッフの名前で低品質なAI生成記事を公開しているケースや、クロックポットモヒートやブラートヴルストアイスクリームといった不自然なAI生成レシピ、あるいはFacebookを席巻するShrimp Jesusなどがあります。
これは従来の手作りコンテンツよりもはるかに安価で簡単に作成できるため、急速にインターネットを席巻しています。
現在の状況から見ると、AI生成コンテンツは利用可能な人間生成コンテンツを上回りつつあります。GPT-5は(部分的に)GPT-4が生成したデータで学習されることになるでしょう。さらにGPT-6は、GPT-5が生成したデータで学習されることになります。そしてこれは続いていきます。
tagモデル崩壊とその回避方法
自身の出力を入力として使用することは、人間とLLMの両方にとって悪影響があります。合成データの使用量や種類を慎重に選別したとしても、モデルの品質低下を防ぐことは保証できません。
生成AIモデル全般において、出力の質と多様性の低下は実験的に測定可能で、かなり急速に発生します。画像生成モデルは数世代で異常を示し始め、ある研究では、Wikipediaのデータで学習された大規模言語モデルが、プロンプトに対して首尾一貫した正確な応答を示していたのが、自身の出力での学習を9世代繰り返した後には、「tailed jackrabbits」という言葉を繰り返すだけになってしまいました。
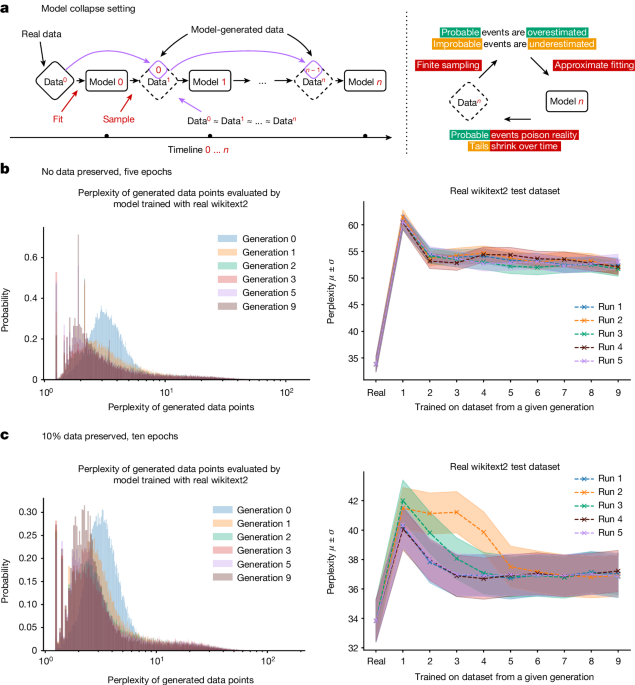
これは簡単に説明できます:AI モデルは学習データの近似です。AI モデルの出力で訓練された AI モデルは、近似の近似となります。訓練サイクルが進むごとに、近似と「実際の」現実世界のデータとの差は大きくなっていきます。
これを「モデル崩壊」と呼びます。
AI 生成データがますます普及するにつれ、インターネットからスクレイピングしたデータで新しいモデルを訓練することは、モデルのパフォーマンスを低下させるリスクがあります。私たちには、次のように考える理由があります:実際の人間が作成したデータの量が減少しない限り、モデルはそれほど悪化しませんが、改善もしません。しかし、AI 作成のデータと人間が作成したデータを分離できない場合、訓練にはより多くの時間がかかるでしょう。新しいモデルは改善することなく、作成コストが高くなります。
ここには深い皮肉があります。AI の貪欲なデータへの欲求が、データの飢饉につながる可能性があるのです。Model Autophagy Disorder(モデル自食障害)は、AI にとっての狂牛病のようなものです:牛の廃棄物を牛に与えることが新種の寄生性脳疾患を引き起こしたように、増加する AI 出力で AI を訓練すると、深刻な精神病理が引き起こされます。
良いニュースは、AI は私たちのデータを必要としているため、人類を置き換えることができないということです。悪いニュースは、データソースを破壊することで自身の成長を妨げる可能性があるということです。
この予測可能な AI の知識飢饉を避けるために、AI モデルの訓練と使用方法を再考する必要があります。私たちは既に、Retrieval-Augmented Generationのような解決策を目にしています。これは AI モデルを事実情報の源として使用することを避け、代わりに外部情報源を評価し再構成するデバイスとして見なすものです。もう一つの前進の道は専門化を通じてで、特定のタスククラスを実行するようにモデルを適応させ、狭い領域に焦点を当てた選別された訓練データを使用します。ChatGPT のような汎用モデルを、LawLLM、MedLLM、MyLittlePonyLLM などの専門家 AI に置き換えることができます。
他の可能性もあり、研究者がどのような新しい技術を発見するかを予測するのは難しいです。より良い合成データを生成する方法や、より少ないデータからより良いモデルを得る方法があるかもしれません。しかし、より多くの研究がこの問題を解決するという保証はありません。
最終的に、この課題は AI コミュニティに創造性を強いるかもしれません。結局のところ、必要は発明の母であり、データに飢えた AI の景観は真に革新的な解決策を生み出す可能性があります。誰が知っているでしょうか?AI における次の大きなブレークスルーは、より多くのデータからではなく、より少ないデータでより多くのことを行う方法を見つけることから来るかもしれません。
tag巨大企業だけがスクレイピングを行える場合はどうなるのか?
今日、多くの人にとってインターネットとは、手に持つ黒いガラスの長方形を通して見る Facebook、Instagram、X です。それは均質化され、「安全」で、何を(そして誰を)見て何を見ないかを(ポリシーとアルゴリズムを通じて)決定するゲートキーパーによってコントロールされています。
それは常にこのようではありませんでした。ほんの数十年前には、ユーザー生成のブログ、独立したウェブサイト、そしてより多くのものがありました。80年代には、数十のオペレーティングシステムとハードウェア規格が競合していました。しかし2010年代までに、Apple と Microsoft が優位に立ち、均質化の傾向が始まりました。
Web ブラウザ、スマートフォン、ソーシャルメディアサイトでも同じことが見られます。多様性と新しいアイデアの爆発から始まり、大手プレイヤーがボールを独占し、他の誰もが参入することを困難にします。
とはいえ、これらのプレイヤーが独占状態にあったとしても、一部の小規模プレイヤーは潜り込んでいました(Linux や Firefox を例に挙げてみましょう)。しかし、LLM では「弱者の逆転」は起こりそうにありません。小規模プレイヤーが多様で最新の訓練データにアクセスする財務力を欠く場合、高品質なモデルを作成することができません。そしてそれなしには、どうやってビジネスを継続できるでしょうか?
巨大企業は、より広いウェブが縮小する中でも、AI モデルに新鮮な情報を継続的に供給する資源を持っています。一方、小規模プレイヤーやスタートアップは、データの底をこすり、古くなったパンくずでアルゴリズムを養おうと苦心しています。これは知識格差として雪だるま式に大きくなる可能性があります。データが豊富な企業が洞察力と能力で豊かになるにつれ、データが乏しい企業はさらに遅れをとり、彼らの AI は日々古くなり、競争力を失っていきます。これは単に誰が最も光り輝く AI のおもちゃを持っているかという問題ではありません - それは誰が技術、商業、そして情報へのアクセス方法の未来を形作るかという問題です。私たちは、一握りのテック巨人が最先端の AI 王国への鍵を握り、他の全ての人々がデジタルの暗黒時代から覗き込むしかない未来を見つめています。
ライセンス供与される魅力的なコンテンツが大量に存在する中で、Netflix の古い時代のように、一つの巨大企業がすべてをライセンス供与する可能性は低いでしょう。覚えていますか?一つのサービスに加入すれば、夢見た全ての番組を見ることができました。今日では、番組は Hulu、Netflix、Disney+、そして HBO Max(今週はどう呼ばれているのかわかりませんが)に分散しています。時には、あなたが愛する番組が突然エーテルの中に消えてしまうこともあります。これが LLM の未来かもしれません:Google は Reddit への優先アクセス権を持ち、一方でOpenAI は Financial Times へのアクセス権を得ています。iFixit?そのデータはもはや存在せず、ただ埃っぽい埋め込みとして保存され、更新されることはありません。一つのモデルがすべてを支配する代わりに、ライセンス権が AI ベンダー間でやり取りされる中で、断片化と変化する能力を目にすることになるかもしれません。
tag結論
好むと好まざるとにかかわらず、スクレイピングは今後も続いていくでしょう。すでにコンテンツプロバイダーは、アクセスを制限する壁を築き、ライセンスを購入できる余裕のある者にのみ門戸を開いています。これにより、個々の LLM が学習できるリソースは深刻に制限され、同時に、小規模な企業は収益性の高いコンテンツの入札戦から締め出され、残りの戦利品は巨大テック企業の LLM の間で分配されています。これは、知識の分野における Netflix 以降のストリーミング時代の再来です。
人間が生成したデータが減少する一方で、AI が生成した「質の低いコンテンツ」は急増しています。これらを使ってモデルを訓練すると、改善の遅延やモデルの崩壊さえ引き起こす可能性があります。これを解決する唯一の方法は、従来の発想にとらわれない思考です - イノベーションと破壊的創造の文化を持つスタートアップは、そのために理想的な存在です。しかし、大手企業のみにライセンスされているデータこそが、そうしたスタートアップが生き残るために必要不可欠な命綱なのです。
データへの公平なアクセスを制限することで、メガ企業は競争を抑制しているだけでなく、AI の未来そのものを窒息させ、この潜在的なデジタル暗黒時代を超えて私たちを前進させる可能性のあるイノベーションを抹殺しているのです。
AI 革命は未来の話ではなく、今すでに起きています。William Gibson の言葉を借りれば:「未来はすでにここにある、ただ均等に配分されていないだけだ」。そしてそれは、さらに不均等に配分される可能性が十分にあります。





