


本日、ウィーンの ICML カンファレンスで私に投げかけられた質問です。
コーヒーブレイク中、ある Jina ユーザーが LLM コミュニティでの最近の議論から生まれた質問をしてきました。彼は、多くの LLM が逆の結果を出す中で、私たちの埋め込みモデルが 9.11 は 9.9 より小さいと判断できるかどうかを尋ねました。
「正直なところ、分かりません」と私は答えました。彼がこの機能が自身のアプリケーションにとって重要であることを説明し、トークン化が問題の根本かもしれないと提案したとき、私は頷きながら - すでに答えを見つけるための実験のアイデアが頭の中を駆け巡っていました。
この記事では、私たちの埋め込みモデル jina-embeddings-v2-base-en(2023年10月リリース)と Reranker の jina-reranker-v2-multilingual(2024年6月リリース)が数値を正確に比較できるかテストしたいと思います。9.11 と 9.9 の単純な比較を超えて、小さな整数、大きな数値、浮動小数点数、負の数、通貨、日付、時刻など、さまざまな種類の数値を含む実験セットを設計しました。目的は、異なる数値フォーマットを扱う際の私たちのモデルの効果を評価することです。
tag実験セットアップ
完全な実装は以下の Colab で見ることができます:


実験のデザインはとてもシンプルです。例えば、埋め込みモデルが [1, 100] の間の数値を理解できるかをチェックするために、以下のステップを実行します:
- ドキュメントの構築:
1から100までの各数値に対して「文字列リテラル」ドキュメントを生成します。 - Embedding API に送信:Embedding API を使用して各ドキュメントの埋め込みを取得します。
- コサイン類似度の計算:すべての2つのドキュメントのペアごとにコサイン類似度を計算し、類似度行列を作成します。
- 散布図の作成:結果を散布図で可視化します。類似度行列の各要素 は以下のポイントにマッピングされます:X軸:、Y軸: の類似度値
デルタ がゼロ、つまり の場合、意味的類似度は最高になるはずです。デルタ が大きくなるにつれて、類似度は減少するはずです。理想的には、類似度はデルタ値に比例して直線的に変化するはずです。もしこのような直線性が観察されない場合、モデルは数値を理解できておらず、9.11 が 9.9 より大きいといったエラーを生む可能性があります。
Reranker モデルも同様の手順に従います。主な違いは、構築されたドキュメントを反復処理する際に、プロンプト "what is the closest item to..." を先頭に追加して各ドキュメントを query として設定し、他のすべてを documents としてランク付けする点です。Reranker API から返される関連性スコアを直接意味的類似度の尺度として使用します。コアの実装は以下のようになります。
def rerank_documents(documents):
reranker_url = "https://api.jina.ai/v1/rerank"
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {token}"
}
# Initialize similarity matrix
similarity_matrix = np.zeros((len(documents), len(documents)))
for idx, d in enumerate(documents):
payload = {
"model": "jina-reranker-v2-base-multilingual",
"query": f"what is the closest item to {d}?",
"top_n": len(documents),
"documents": documents
}
...tagモデルは [1, 2, 3, ..., 100] の間の数値を比較できるか?


各デルタの平均と分散を示す散布図。左:jina-embeddings-v2-base-en、右:jina-reranker-v2-multilingual。documents = [str(i) for i in range(1, 101)]
tagこれらのプロットの読み方
さらなる実験に進む前に、まずこれらのプロットの適切な読み方を説明させてください。最初に、上記の2つのプロットから私が観察したのは、埋め込みモデルはうまく機能していますが、reranker モデルはあまり良い結果を示していないということです。では、私たちは何を見ており、なぜそうなのでしょうか?
X軸は、ドキュメントセットから均一にサンプリングされた と のインデックス のデルタ、つまり を表します。このデルタは の範囲です。ドキュメントセットは構築上ソートされているため、 が小さいほど、 と は意味的に近く、 と の距離が遠いほど、 と の類似度は低くなります。そのため、Y軸で表される類似度は でスパイクを示し、左右に移動するにつれて直線的に低下します。
理想的には、これは鋭いピークまたは「上向き矢印」の形状 ^ を作るはずです。しかし、必ずしもそうはなりません。X軸を特定の点、例えば に固定して、Y軸に沿って見ると、類似度の値が0.80から0.95の範囲で変動していることがわかります。つまり、デルタが同じ25であっても、 は0.81、 は0.91というように異なる値を示す可能性があります。
シアン色のトレンドラインは、各X値における平均類似度と標準偏差を示しています。また、ドキュメントセットが均等に間隔を置いて配置されているため、連続するドキュメント間の間隔が等しくなり、類似度は直線的に低下するはずであることにも注意してください。
埋め込みプロットは常に対称的で、 で最大のY値1.0を示すことに注意してください。これは、 と のコサイン類似度が対称的で、 であるためです。
一方、reranker プロットは、reranker モデルにおけるクエリとドキュメントの役割が異なるため、常に非対称です。最大値は必ずしも1.0ではありません。なぜなら、 は "what is the closest item to 4" と "4" の関連性スコアを計算することを意味するからです。考えてみれば、 が最大のY値をもたらすという保証はありません。
tagモデルは負の数 [-100, -99, -98, ..., -1] を比較できるか?


各デルタの平均と分散を示す散布図。左:jina-embeddings-v2-base-en、右:jina-reranker-v2-multilingual。ここではモデルが負の空間での意味的類似度を判断できるかテストしたいと思います。documents = [str(-i) for i in range(1, 101)]
tagモデルはより大きな間隔の数値 [1000, 2000, 3000, ..., 100000] を比較できるか?


ここでは、1000 間隔で数値を比較した場合のセマンティック類似性をモデルが判断できるかテストしたいと考えています。documents = [str(i*1000) for i in range(1, 101)] デルタごとの平均と分散を示す散布図。左:jina-embeddings-v2-base-en、右:jina-reranker-v2-multilingual。
tagモデルは任意の範囲の数値を比較できるか?例:[376, 377, 378, ..., 476]


ここでは、任意の範囲の数値を比較する際のセマンティック類似性をモデルが判断できるかテストするため、ランダムな範囲に数値を移動させました。documents = [str(i+375) for i in range(1, 101)]デルタごとの平均と分散を示す散布図。左:jina-embeddings-v2-base-en、右:jina-reranker-v2-multilingual。
tagモデルは大きな数値を比較できるか?[4294967296, 4294967297, 4294967298, ..., 4294967396]


ここでは、非常に大きな数値を比較する際のセマンティック類似性をモデルが判断できるかテストしたいと考えています。前回の実験と同様の考え方で、範囲をさらに大きな数値に移動させました。documents = [str(i+4294967296) for i in range(1, 101)]デルタごとの平均と分散を示す散布図。左:jina-embeddings-v2-base-en、右:jina-reranker-v2-multilingual。
tagモデルは小数を比較できるか?[0.0001, 0.0002, 0.0003, ...,0.1](固定桁数なし)


ここでは、小数を比較する際のセマンティック類似性をモデルが判断できるかテストしたいと考えています。documents = [str(i/1000) for i in range(1, 101)]デルタごとの平均と分散を示す散布図。左:jina-embeddings-v2-base-en、右:jina-reranker-v2-multilingual。
tagモデルは通貨の数値を比較できるか?[2, 100]


ここでは、通貨形式の数値を比較する際のセマンティック類似性をモデルが判断できるかテストしたいと考えています。documents = ['$'+str(i) for i in range(1, 101)]デルタごとの平均と分散を示す散布図。左:jina-embeddings-v2-base-en、右:jina-reranker-v2-multilingual。
tagモデルは日付を比較できるか?[2024-07-24, 2024-07-25, 2024-07-26, ..., 2024-10-31]


ここでは、YYYY-MM-DD形式の日付を比較する際のセマンティック類似性をモデルが判断できるかテストしたいと考えています。today = datetime.today(); documents = [(today + timedelta(days=i)).strftime('%Y-%m-%d') for i in range(100)]デルタごとの平均と分散を示す散布図。左:jina-embeddings-v2-base-en、右:jina-reranker-v2-multilingual。
tagモデルは時刻を比較できるか?[19:00:07, 19:00:08, 19:00:09,..., 20:39:07]


ここでは、時刻形式の数値、つまりhh:mm:ssを比較する際の意味的類似性をモデルが判断できるかテストします。now = datetime.now(); documents = [(now + timedelta(minutes=i)).strftime('%H:%M:%S') for i in range(100)]各デルタの平均と分散を示す散布図。左:jina-embeddings-v2-base-en、右:jina-reranker-v2-multilingual。
tag観察結果
上記のプロットから以下の観察結果が得られました:
tagReranker モデル
- Reranker モデルは数値の比較に苦労しています。[1, 100]の間の数値を比較する最も単純なケースでも、パフォーマンスは十分とは言えません。
- Reranker の使用においては、
what is the closest item to xのような特別なプロンプト構成を使用していることに注意が必要です。これも結果に影響を与える可能性があります。
tagEmbedding モデル
- Embedding モデルは、[1, 100]の範囲内の小さな整数や[-100, 1]の範囲内の負の数の比較においては、比較的良好な性能を示します。しかし、この範囲を他の値にシフトしたり、間隔を増やしたり、より大きな、あるいは小さな浮動小数点数を扱ったりすると、性能は大幅に低下します。
- 通常10ステップごとに定期的なスパイクが観察されます。この挙動は、トークナイザーが文字列を処理する方法、つまり「10」または「1」と「0」にトークン化する可能性に関連している可能性があります。
tag日付と時刻の理解
- 興味深いことに、Embedding モデルは日付と時刻をよく理解しており、ほとんどの場合正しく比較できています。日付のプロットでは30/31ステップごとにスパイクが現れ、これは月の日数に対応しています。時刻のプロットでは60ステップごとにスパイクが現れ、これは1時間の分数に対応しています。
- Reranker モデルもある程度この理解を示しています。
tag「ゼロ」との類似性の可視化

もう1つの興味深い実験として、おそらくより直感的なのは、任意の数値とゼロ(つまり原点)との類似性または関連性スコアを直接可視化することです。ゼロの埋め込みを参照点として固定し、数値が大きくなるにつれて意味的類似性が線形的に減少するかどうかを確認したいと考えました。Reranker の場合、クエリを "0" または "What is the closest number to number zero?" に固定し、数値が増加するにつれて関連性スコアが減少するかどうかを確認するために、すべての数値をランク付けできます。結果は以下の通りです:


ここでは、「原点埋め込み」を「ゼロ」の埋め込みに固定し、任意の数値とゼロとの意味的類似性がその数値の値に比例するかどうかを確認します。具体的には、documents = [str(i) for i in range(2048)]を使用します。各デルタの平均と分散を示す散布図です。左:jina-embeddings-v2-base-en、右:jina-reranker-v2-multilingual。
tag結論
この記事では、現在の Embedding モデルと Reranker モデルが数値比較をどのように扱うかを示しています。比較的シンプルな実験設定にもかかわらず、現在のモデルにおける基本的な欠陥を露呈し、次世代の Embedding と Reranker の開発に向けて貴重な洞察を提供しています。
モデルが数値を正確に比較できるかどうかを決定する2つの重要な要因があります:
第一に、トークン化:語彙に0-9の数字のみが含まれている場合、11は別々のトークン1と1として、または単一のトークン11としてトークン化される可能性があります。この選択は、数値の理解に影響を与えます。
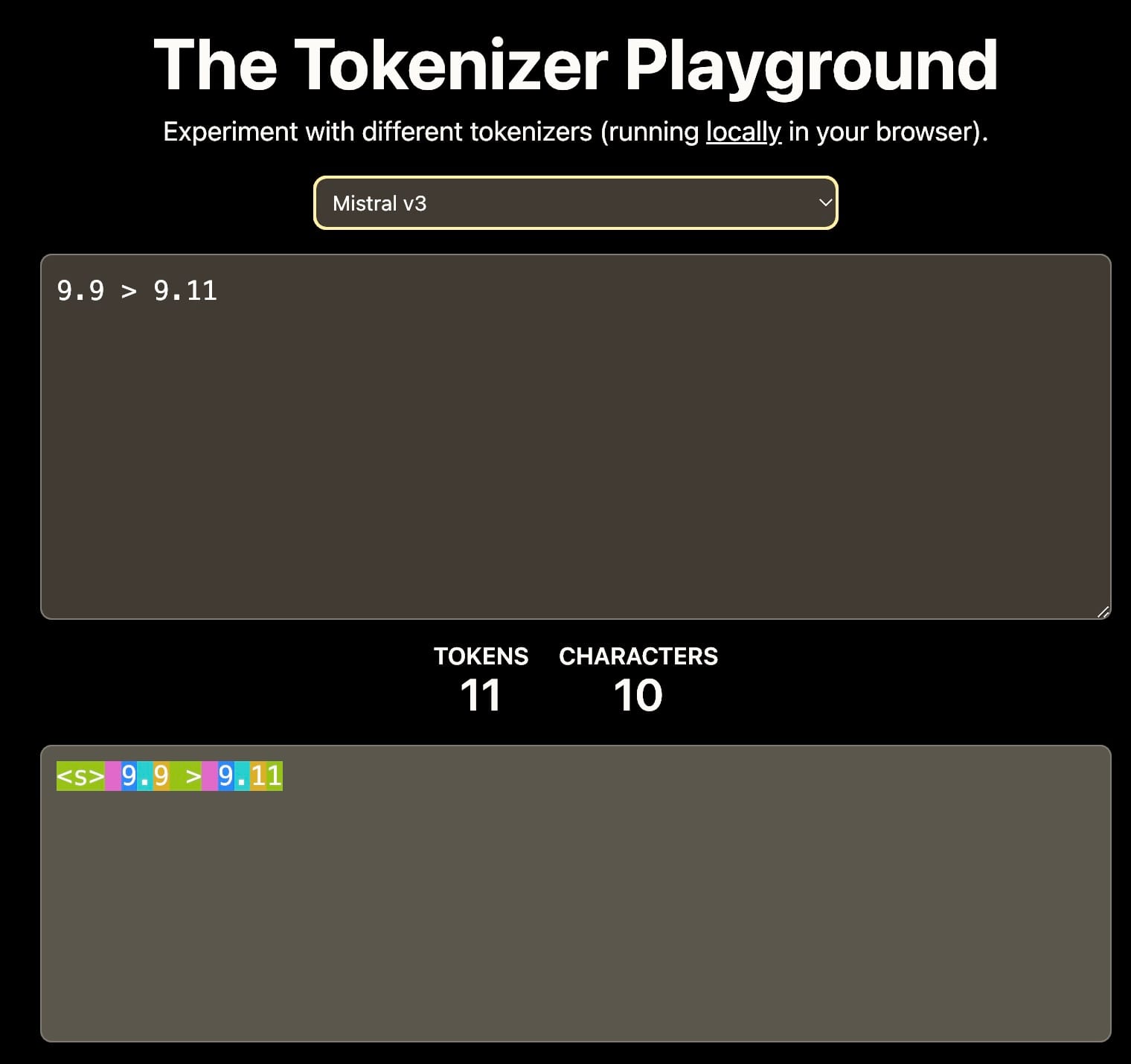
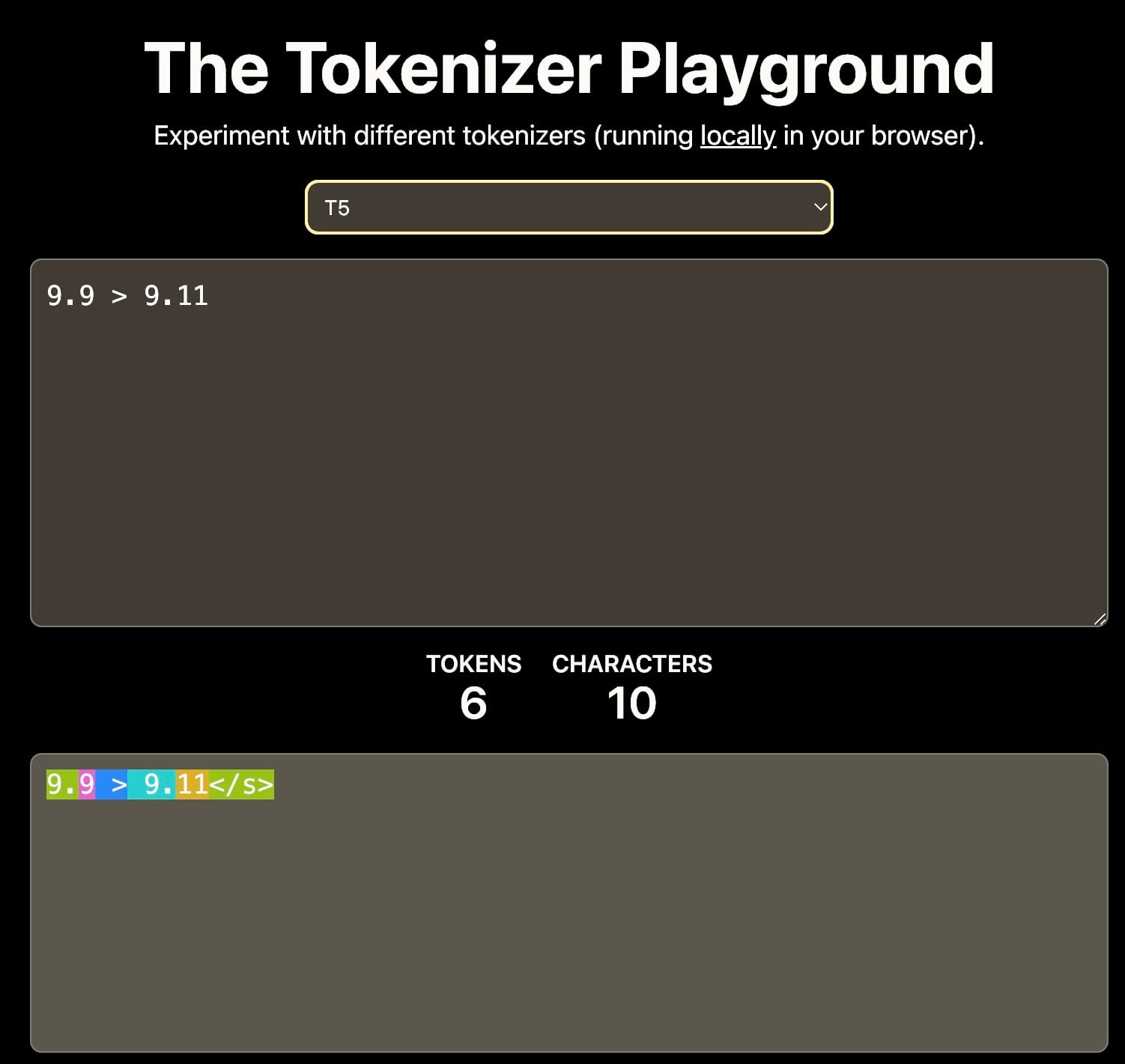
異なるトークナイザーは9.11を異なる方法で解釈します。これは文脈的学習に影響を与える可能性があります。出典:The Tokenizer Playground on HuggingFace。
第二に、学習データ:学習コーパスはモデルの数値推論能力に大きな影響を与えます。例えば、学習データが主にセマンティックバージョニングが一般的なソフトウェアドキュメントや GitHub リポジトリを含む場合、モデルは9.9の次のマイナーバージョンが9.11であるため、9.11が9.9より大きいと解釈する可能性があります。
Embedding や Reranker などの密な検索モデルの算術能力は、RAG や高度な検索・推論を含むタスクにとって重要です。強力な数値推論能力は、特に JSON のような構造化データを扱う際の検索品質を大幅に向上させることができます。
