

最近、Stanford NLP グループが開発した言語モデル(LM)プロンプトをアルゴリズム的に最適化することを目的とした最先端のフレームワーク DSPy について調査しました。この3日間で、DSPy に関する初期の印象といくつかの貴重な洞察を得ました。なお、私の観察は DSPy の公式ドキュメントに取って代わるものではありません。実際、この投稿に入る前に彼らのドキュメントとREADMEを少なくとも一度は読むことを強くお勧めします。ここでの議論は、DSPy の機能を数日間探求して得た予備的な理解を反映しています。DSPy Assertions、Typed Predictor、LM weights tuning などの高度な機能については、まだ十分に調査していません。
 stanfordnlp
stanfordnlpJina AI での検索基盤に焦点を当てたバックグラウンドがありますが、DSPy への私の関心は Retrieval-Augmented Generation(RAG)での潜在的な可能性に直接起因するものではありません。代わりに、いくつかの生成タスクに対処するために DSPy を自動プロンプトチューニングに活用できる可能性に興味を持ちました。
DSPy を初めて使用する方で、アクセスしやすいエントリーポイントを探している方、またはフレームワークに慣れているものの公式ドキュメントが混乱したり圧倒的だと感じる方向けに、この記事を書きました。また、初心者には難しく感じるかもしれない DSPy の慣用句に厳密に従うことは避けています。それでは、より深く掘り下げていきましょう。
tagDSPy の好きなところ
tagDSPy によるプロンプトエンジニアリングのループの閉じ込め
DSPy で最も興奮するのは、プロンプトエンジニアリングのサイクルのループを閉じるアプローチで、手動で手作業のプロセスを、構造化された、明確に定義された機械学習ワークフロー(データセットの準備、モデルの定義、トレーニング、評価、テスト)に変換することです。これが DSPy の最も革新的な側面だと私は考えています。
ベイエリアを旅行し、LLM 評価に焦点を当てた多くのスタートアップ創業者と話をする中で、メトリクス、ハルシネーション、観測可能性、コンプライアンスについての議論をよく耳にしました。しかし、これらの会話は重要な次のステップまで進むことがありません:これらすべてのメトリクスを手に入れた後、次に何をするのか?プロンプトの言い回しを調整し、特定の魔法の言葉(例:「私の祖母が死にかけています」)がメトリクスを向上させることを期待するのは、戦略的なアプローチと言えるでしょうか?この質問は多くの LLM 評価スタートアップによって未解決のままでした。そして、DSPy を発見するまで、私も答えることができませんでした。DSPy は、特定のメトリクスに基づいてプロンプトを最適化する、あるいはプロンプトと LLM の重みの両方を含む LLM パイプライン全体を最適化する、明確でプログラム的な方法を導入します。
LangChain の CEO の Harrison と、OpenAI の元 Developer Relations 責任者の Logan は、Unsupervised Learning Podcast で、2024年が LLM 評価の重要な年になると述べています。このため、DSPy がパズルの重要な欠落部分を提供しているので、現在よりもっと注目に値すると私は考えています。
tagDSPy によるロジックとテキスト表現の分離
DSPy の印象的なもう一つの側面は、プロンプトエンジニアリングを再現可能で LLM に依存しないモジュールに定式化することです。これを達成するために、プロンプトからロジックを抽出し、ロジックとテキスト表現の間に明確な関心の分離を作成します。以下に示す通りです。
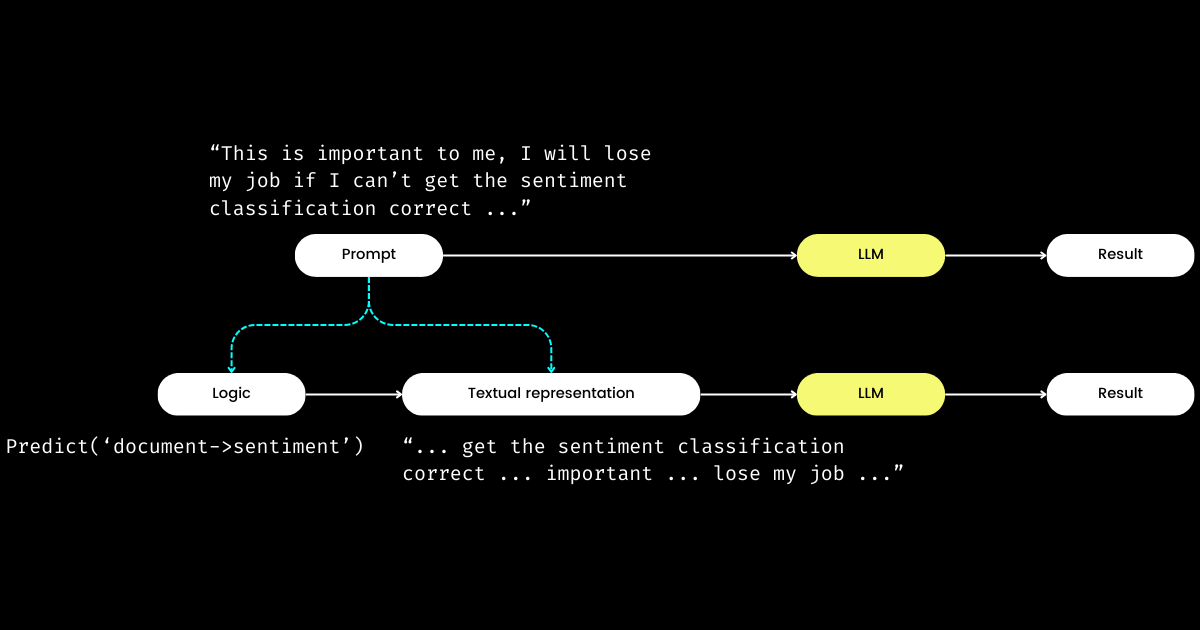
dspy.Module)とそのテキスト表現で構成されます。ロジックは不変で、再現可能、テスト可能、そして LLM に依存しません。テキスト表現はロジックの結果に過ぎません。DSPy のロジックを不変、テスト可能、LLM に依存しない「原因」とし、テキスト表現をその「結果」とする概念は、最初は理解が難しいかもしれません。特に「プログラミング言語の未来は自然言語である」という広く信じられている考えの中では、そうです。「プロンプトエンジニアリングが未来である」という考えを受け入れると、DSPy の設計哲学に出会った時に混乱を感じるかもしれません。単純化するという期待に反して、DSPy は一連のモジュールとシグネチャ構文を導入し、自然言語プロンプティングを C プログラミングの複雑さに逆行させているように見えます!
しかし、なぜこのようなアプローチを取るのでしょうか?私の理解では、プロンプトプログラミングの中核にはロジックがあり、コミュニケーションはその効果を増幅させる増幅器として機能するということです。"Do sentiment classification" という指示は中核的なロジックを表し、"Follow these demonstrations or I will fire you" のような表現はそれを伝える一つの方法です。実生活でのやり取りと同様に、物事がうまくいかない原因は、多くの場合ロジックの欠陥ではなく、コミュニケーションの問題にあります。これは、特に非ネイティブスピーカーが、なぜプロンプトエンジニアリングを難しいと感じるのかを説明しています。私の会社では、優秀なソフトウェアエンジニアがプロンプトエンジニアリングに苦労しているのを見てきましたが、それはロジックの欠如ではなく、「雰囲気を話せない」ためです。ロジックをプロンプトから分離することで、DSPy は dspy.Module を介して決定論的なロジックのプログラミングを可能にし、開発者は使用する LLM に関係なく、従来のエンジニアリングと同じようにロジックに焦点を当てることができます。
では、開発者がロジックに焦点を当てる一方で、誰がテキスト表現を管理するのでしょうか?DSPy がこの役割を担い、あなたのデータと評価メトリクスを使用してテキスト表現を洗練させます—物語の焦点を決定することからヒントの最適化、良いデモンストレーションの選択まで、すべてを行います。驚くべきことに、DSPy は評価メトリクスを使用して LLM の重みを微調整することさえできます!
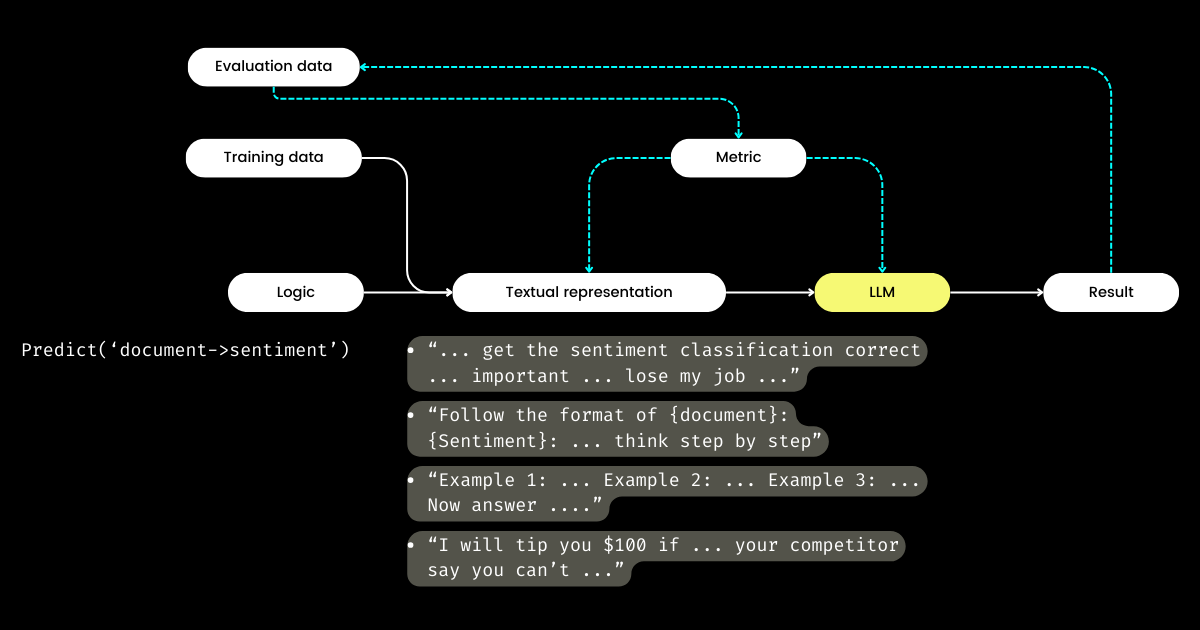
私にとって、DSPy の主要な貢献—プロンプトエンジニアリングにおけるトレーニングと評価のループを閉じること、そしてロジックをテキスト表現から分離すること—は、LLM/エージェントシステムに対する潜在的な重要性を強調しています。確かに野心的なビジョンですが、間違いなく必要なものです!
tagDSPy が改善できると思う点
まず、DSPy は慣用句のため、初心者にとって学習曲線が急です。signature、module、program、teleprompter、optimization、compile などの用語は圧倒的です。プロンプトエンジニアリングに熟練している人でさえ、DSPy 内でこれらの概念を把握することは難しい迷路となり得ます。
この複雑さは、私の Jina 1.0 での経験と似ています。当時私たちは、chunk、document、driver、executor、pea、pod、querylang、flow といった多くのイディオムを導入しました(ユーザーが覚えやすいように可愛いステッカーまでデザインしました!)。






これらの初期のコンセプトのほとんどは、後の Jina のリファクタリングで削除されました。今日では、「大粛清」から生き残ったのは Executor、Document、そして Flow だけです。Jina 3.0 では新しいコンセプトとして Deployment を追加しました。バランスは取れていますね。🤷
この問題は DSPy や Jina に固有のものではありません。TensorFlow のバージョン 0.x から 1.x の間に導入された無数のコンセプトと抽象化を思い出してください。これは、ソフトウェアフレームワークの初期段階でよく見られる問題だと考えています。その段階では、最大限の正確性と再現性を確保するために、アカデミックな表記法をコードベースに直接反映させようとする傾向があります。しかし、すべてのユーザーがそのような細かい抽象化を重視するわけではなく、シンプルなワンライナーを求める人から、より大きな柔軟性を求める人まで、さまざまな好みがあります。ソフトウェアフレームワークにおける抽象化についてのこのトピックについては、2020 年のブログ記事で詳しく議論しました。興味のある読者は参考になるかもしれません。


第二に、DSPy のドキュメントは一貫性の面で時々不足しています。module と program、teleprompter と optimizer、あるいは optimize と compile(時には training や bootstrapping と呼ばれる)といった用語が互換的に使用され、混乱を招いています。その結果、私は DSPy を使い始めた最初の数時間を、何を optimizes するのか、bootstrapping のプロセスが何を意味するのかを理解することに費やしました。
これらの障壁にもかかわらず、DSPy をより深く掘り下げ、ドキュメントを再確認すると、すべてが腑に落ちる瞬間が訪れ、その独自の用語と PyTorch のような馴染みのある構造との関連性が明らかになるでしょう。しかし、DSPy は将来のバージョンで改善の余地があることは間違いありません。特に、PyTorch のバックグラウンドを持たないプロンプトエンジニアにとって、フレームワークをよりアクセスしやすくする点で改善が必要です。
tagDSPy 初心者のよくつまずくポイント
以下のセクションでは、私が DSPy で最初につまずいた質問のリストをまとめました。これらの洞察を共有することで、同様の課題に直面する他の学習者の助けになればと思います。
tagteleprompter、optimization、compile とは何か?DSPy で具体的に何が最適化されるのか?
DSPy では、"Teleprompters" がオプティマイザーです(@lateinteraction がドキュメントとコードを改訂して明確にしているようです)。compile 関数はこのオプティマイザーの中心として機能し、optimizer.optimize() を呼び出すのに似ています。これを DSPy における学習と考えてください。この compile() プロセスは以下を調整することを目的としています:
- few-shot のデモ
- 指示
- LLM の重み
ただし、DSPy の初心者向けチュートリアルのほとんどは重みと指示の調整には深入りしないため、次の質問につながります。
tagDSPy の bootstrap とは何か?
Bootstrap は、few-shot の文脈内学習のための自己生成デモの作成を指し、compile() プロセス(つまり、上述の最適化/学習)の重要な部分です。これらの few-shot デモは、ユーザーが提供したラベル付きデータから生成されます。1 つのデモは通常、入力、出力、根拠(例:思考の連鎖)、および中間の入力と出力(マルチステージのプロンプト用)で構成されます。もちろん、質の高い few-shot デモは出力の優秀性に不可欠です。そのために、DSPy ではユーザー定義のメトリック関数を使用して、特定の基準を満たすデモのみが選択されるようにすることができます。これは次の質問につながります。
tagDSPy のメトリック関数とは?
DSPy を実践的に使用した経験から、メトリック関数は現在のドキュメントで説明されているよりもはるかに重要な強調が必要だと考えるようになりました。DSPy のメトリック関数は、その暗黙の性質(trace=None によって制御される)のおかげで、評価フェーズと学習フェーズの両方で重要な役割を果たし、「損失」関数としても機能します:
def keywords_match_jaccard_metric(example, pred, trace=None):
# Jaccard similarity between example keywords and predicted keywords
A = set(normalize_text(example.keywords).split())
B = set(normalize_text(pred.keywords).split())
j = len(A & B) / len(A | B)
if trace is not None:
# act as a "loss" function
return j
return j > 0.8 # act as evaluationこのアプローチは従来の機械学習とは大きく異なります。従来の機械学習では、損失関数は通常連続的で微分可能(例:ヒンジ損失/MSE)である一方、評価メトリックは全く異なり離散的(例:NDCG)である場合があります。DSPy では、評価と損失関数はメトリック関数に統合されており、離散的で、ほとんどの場合ブール値を返します。メトリック関数は LLM を統合することもできます!以下の例では、LLM を使用したファジーマッチを実装して、予測値と正解の答えが magnitude の面で類似しているかどうかを判断します。例えば、「100 万ドル」と「$1M」は true を返します。
class Assess(dspy.Signature):
"""Assess the if the prediction is in the same magnitude to the gold answer."""
gold_answer = dspy.InputField(desc='number, could be in natural language')
prediction = dspy.InputField(desc='number, could be in natural language')
assessment = dspy.OutputField(desc='yes or no, focus on the number magnitude, not the unit or exact value or wording')
def same_magnitude_correct(example, pred, trace=None):
return dspy.Predict(Assess)(gold_answer=example.answer, prediction=pred.answer).assessment.lower() == 'yes'強力な機能ではありますが、メトリック関数は、最終的な品質評価を決定するだけでなく、最適化の結果にも影響を与えることから、DSPy のユーザー体験に大きく影響を与えます。適切に設計されたメトリック関数は最適化されたプロンプトにつながりますが、設計の悪いメトリック関数は最適化の失敗を招く可能性があります。DSPy で新しい問題に取り組む際、ロジック(すなわち DSPy.Module)の設計と同じくらいの時間をメトリック関数の設計に費やすことになるかもしれません。このロジックとメトリックの両方に注力する必要性は、初心者にとって負担となる可能性があります。
tag"Bootstrapped 0 full traces after 20 examples in round 0" とはどういう意味でしょうか?
この compile() 中に静かに表示されるメッセージは、最大限の注意を払うべきものです。これは本質的に最適化/コンパイルが失敗し、得られるプロンプトは単純な few-shot よりも優れていないことを意味します。何が問題なのでしょうか?このようなメッセージに遭遇した際の DSPy プログラムのデバッグに役立つヒントをまとめました:
メトリック関数が正しくない
BootstrapFewShot(metric=your_metric) で使用される関数 your_metric は正しく実装されていますか?単体テストを実施してください。your_metric が True を返すことはありますか?それとも常に False を返しているでしょうか?True を返すことが重要です。なぜなら、それが DSPy がブートストラップされた例を「成功」とみなす基準だからです。すべての評価で True を返すと、すべての例がブートストラップで「成功」とみなされます!これは理想的ではありませんが、メトリック関数の厳密さを調整して "Bootstrapped 0 full traces" の結果を変更する方法です。なお、DSPy のドキュメントではメトリクスがスカラー値を返すことも可能と記載されていますが、基底のコードを見た限り、初心者にはお勧めしません。
ロジック(DSPy.Module)が正しくない
メトリック関数が正しい場合、ロジック dspy.Module が正しく実装されているかを確認する必要があります。まず、各ステップに DSPy signature が正しく割り当てられているかを確認します。dspy.Predict('question->answer') のようなインライン signatures は使いやすいですが、品質のために クラスベースの signatures での実装を強く推奨します。具体的には、クラスに説明的な docstrings を追加し、InputField と OutputField の desc フィールドを記入します。これらはすべて LM に各フィールドについてのヒントを提供します。以下に、フェルミ問題を解くための 2 つの多段階 DSPy.Module を実装しました。1 つはインライン signature を使用し、もう 1 つはクラスベースの signature を使用しています。
class FermiSolver(dspy.Module):
def __init__(self):
super().__init__()
self.step1 = dspy.Predict('question -> initial_guess')
self.step2 = dspy.Predict('question, initial_guess -> calculated_estimation')
self.step3 = dspy.Predict('question, initial_guess, calculated_estimation -> variables_and_formulae')
self.step4 = dspy.ReAct('question, initial_guess, calculated_estimation, variables_and_formulae -> gathering_data')
self.step5 = dspy.Predict('question, initial_guess, calculated_estimation, variables_and_formulae, gathering_data -> answer')
def forward(self, q):
step1 = self.step1(question=q)
step2 = self.step2(question=q, initial_guess=step1.initial_guess)
step3 = self.step3(question=q, initial_guess=step1.initial_guess, calculated_estimation=step2.calculated_estimation)
step4 = self.step4(question=q, initial_guess=step1.initial_guess, calculated_estimation=step2.calculated_estimation, variables_and_formulae=step3.variables_and_formulae)
step5 = self.step5(question=q, initial_guess=step1.initial_guess, calculated_estimation=step2.calculated_estimation, variables_and_formulae=step3.variables_and_formulae, gathering_data=step4.gathering_data)
return step5インライン signature のみを使用したフェルミ問題ソルバー
class FermiStep1(dspy.Signature):
question = dspy.InputField(desc='Fermi problems involve the use of estimation and reasoning')
initial_guess = dspy.OutputField(desc='Have a guess – don't do any calculations yet')
class FermiStep2(FermiStep1):
initial_guess = dspy.InputField(desc='Have a guess – don't do any calculations yet')
calculated_estimation = dspy.OutputField(desc='List the information you'll need to solve the problem and make some estimations of the values')
class FermiStep3(FermiStep2):
calculated_estimation = dspy.InputField(desc='List the information you'll need to solve the problem and make some estimations of the values')
variables_and_formulae = dspy.OutputField(desc='Write a formula or procedure to solve your problem')
class FermiStep4(FermiStep3):
variables_and_formulae = dspy.InputField(desc='Write a formula or procedure to solve your problem')
gathering_data = dspy.OutputField(desc='Research, measure, collect data and use your formula. Find the smallest and greatest values possible')
class FermiStep5(FermiStep4):
gathering_data = dspy.InputField(desc='Research, measure, collect data and use your formula. Find the smallest and greatest values possible')
answer = dspy.OutputField(desc='the final answer, must be a numerical value')
class FermiSolver2(dspy.Module):
def __init__(self):
super().__init__()
self.step1 = dspy.Predict(FermiStep1)
self.step2 = dspy.Predict(FermiStep2)
self.step3 = dspy.Predict(FermiStep3)
self.step4 = dspy.Predict(FermiStep4)
self.step5 = dspy.Predict(FermiStep5)
def forward(self, q):
step1 = self.step1(question=q)
step2 = self.step2(question=q, initial_guess=step1.initial_guess)
step3 = self.step3(question=q, initial_guess=step1.initial_guess, calculated_estimation=step2.calculated_estimation)
step4 = self.step4(question=q, initial_guess=step1.initial_guess, calculated_estimation=step2.calculated_estimation, variables_and_formulae=step3.variables_and_formulae)
step5 = self.step5(question=q, initial_guess=step1.initial_guess, calculated_estimation=step2.calculated_estimation, variables_and_formulae=step3.variables_and_formulae, gathering_data=step4.gathering_data)
return step5各フィールドにより包括的な説明を付けたクラスベースの signature を使用したフェルミ問題ソルバー
また、def forward(self, ) の部分も確認してください。多段階の Module の場合、最後のステップからの出力(または FermiSolver のような全ての出力)が次のステップの入力として渡されていることを確認してください。
問題が単に難しすぎる
メトリックとモジュールの両方が正しいように見える場合、問題が単に難しすぎて、実装したロジックではそれを解決するのに十分でない可能性があります。そのため、DSPy はあなたのロジックとメトリック関数では、デモをブートストラップすることが不可能だと判断します。この段階で、以下のような選択肢を検討できます:
- より強力な LM を使用する。例えば、学習者の LM として
gpt-35-turbo-instructをgpt-4-turboに置き換えたり、より強力な LM を教師として使用したりします。これはしばしば非常に効果的です。結局のところ、より強力なモデルはプロンプトの理解力が高いということです。 - ロジックを改善する。
dspy.Moduleのステップを追加または置き換えて、より複雑なものにします。例えば、PredictをChainOfThoughtやProgramOfThoughtに置き換えたり、Retrievalステップを追加したりします。 - より多くのトレーニング例を追加する。20 例が不十分な場合、100 例を目指しましょう!そうすれば、1 つの例がメトリックチェックを通過し、
BootstrapFewShotによって選ばれることを期待できます。 - 問題を再構成する。しばしば、問題の定式化が間違っているために解決不可能になります。しかし、異なる角度から見ることで、物事がずっと簡単で明白になることがあります。
実践では、試行錯誤のプロセスが必要です。例えば、私は特に難しい問題に取り組みました:2~3 つのキーワードに基づいて Google Material Design アイコンに似た SVG アイコンを生成する問題です。最初の戦略は、dspy.ChainOfThought('keywords -> svg') を使用する単純な DSPy.Module を利用し、生成された SVG と正解の Material Design SVG との視覚的類似性を pHash アルゴリズムのように評価するメトリック関数を組み合わせることでした。20 のトレーニング例から始めましたが、最初のラウンド後に "Bootstrapped 0 full traces after 20 examples in round 0" となり、最適化が失敗したことを示しました。データセットを 100 例に増やし、モジュールを複数のステージを含むように改訂し、メトリック関数のしきい値を調整することで、最終的に 2 つのブートストラップされたデモンストレーションを実現し、いくつかの最適化されたプロンプトを得ることができました。
