

コードとドキュメントを正確に検索することは、これまで以上に重要になっています。私たちは、コーディングの分野における最新の埋め込みモデル:jina-embeddings-v2-base-code を発表できることを大変嬉しく思います。この新しいオープンソースのプログラミング言語埋め込みモデルは、開発者のコードとドキュメントとのやり取りを改善するために設計されています。英語と30の主要なプログラミング言語をサポートし、最大8,192の入力トークンを処理できる唯一のオープンソースモデルとして際立っています。jina-embeddings-v2-base-code は現在、Apache 2.0ライセンスの下で HuggingFace で公開されており、私たちの Embedding API を通じて自由にアクセスできます。
Embedding API にアクセスし、ドロップダウンリストから jina-embeddings-v2-base-code を選択してください。100万トークンを無料でお試しいただけます。
tagなぜコード用の埋め込みモデルを開発するのか?
開発者は多くの場合、エラーを探すためではなく、特定の機能を見つけたり、特定のプロセスがどのように実装されているかを理解したりするために、膨大なコードベースを探索する必要があります。この作業は時間がかかり、時には干し草の山から針を探すようなものです。統合開発環境(IDE)は、情報検索を自動化するツールや機能を提供することで、このプロセスを大幅に改善してきました。しかし、さらなる改善の可能性が存在し、ここで私たちの埋め込みモデルが活躍します。
tagjina-embeddings-v2-base-code のユースケース
AI を活用した検索機能を統合することで、IDE 内の既存の機能を強化するだけでなく、開発者がコードベースとやり取りする方法を変革しています。この技術は単純なテキスト検索を超え、クエリの意図を理解する意味的な理解を提供し、コードレビュー、単体テスト、および全体的な品質管理に必要な時間と労力を大幅に削減します。
強化されたコードナビゲーション
- クエリ形式:探している機能やコードスニペットの自然言語による説明。
- 取得結果形式:説明された機能が実装されている関連コードファイルまたはスニペット、およびコードの特定の部分を指し示す注釈やハイライト。
効率的なコードレビュー
- クエリ形式:コードベース全体で確認したいプログラミングの概念やパターンの説明。
- 取得結果形式:説明された概念、パターン、またはベストプラクティスに一致するコードスニペットやプルリクエストのリスト。レビュアーが改善が必要な重要な領域に集中できるようになります。
自動化されたドキュメント支援
- クエリ形式:ドキュメントまたは説明が必要なコードスニペット。
- 取得結果形式:コードの機能、パラメータ、戻り値の型を説明する推奨 docstring またはドキュメントエントリ。これにより、最新かつ包括的なドキュメントの維持が容易になります。
これらの具体的なユースケースに対応することで、jina-embeddings-v2-base-code は開発体験を向上させるだけでなく、より協力的で効率的なコーディング環境を促進します。
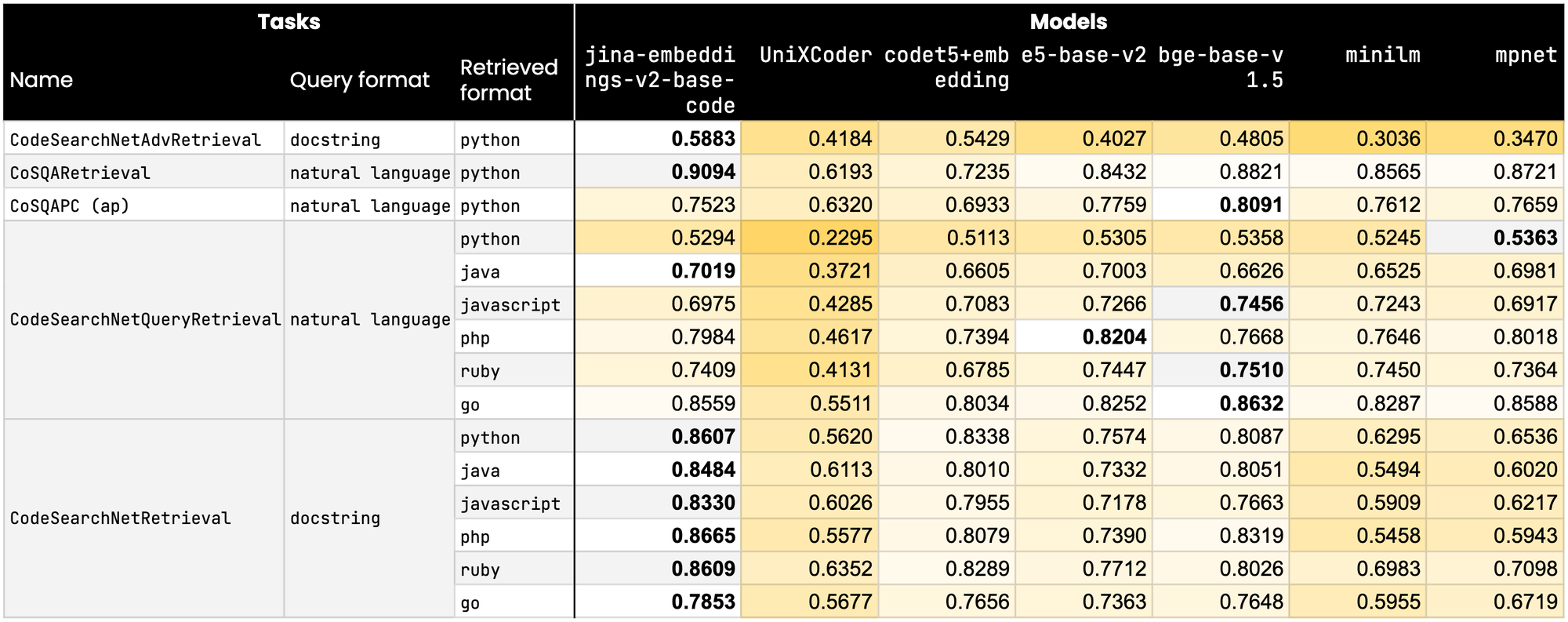
tagパフォーマンスのベンチマーク
精度と正確さが最も重要な分野で、jina-embeddings-v2-base-code は15の重要な CodeNetSearch ベンチマークのうち9つでライバルを上回り、トップの座に立っています。さらに、残りのベンチマークでも非常に競争力のあるスコアを維持しています。Microsoft や Salesforce などの技術大手を含む最も近い競合と比較して、jina-embeddings-v2-base-code はより高いランクを獲得しただけでなく、その優れた設計と機能を示しています。
tagモデルのハイライト
- 最先端のパフォーマンス:私たちの卓越性への取り組みは、他のオープンソースの製品を凌駕し、Microsoft や Salesforce のモデルさえも上回る Jina Embedding モデルのパフォーマンスに反映されています。
- コンパクトかつパワフル:AI の世界では効率性が鍵となります。1億6100万パラメータ(量子化なしで307MB)を持つ jina-embeddings-v2-base-code は、機能を損なうことなく、高速なパフォーマンスとコスト削減を提供するよう効率性を重視して設計されています。
- 拡張されたコンテキスト処理能力:最大8,192トークンを処理できる能力により、大きな関数や多数のオブジェクトファイルを扱うことができ、数百トークンしかサポートしていないモデルの限界を超える理解の深さとコンテキストを提供します。
- 多言語対応:汎用性を重視し、私たちのモデルは 30 種類のプログラミング言語とフレームワークを対象にトレーニングされており、最も人気のある 6 つの言語(Python、JavaScript、Java、PHP、Go、Ruby)に特に重点を置いています。この広範なカバレッジにより、jina-embeddings-v2-base-code はプログラミングコミュニティの多様なニーズに対応できます。
- シームレスなコード生成のための RAG 統合:モデルの RAG との互換性とコード生成モデルとの統合により、一般的な知識からのコード生成だけでなく、関連する API とドキュメントを読み取り、効率的で正確な自動コード統合を実現できます。
tagシームレスな API 統合
jina-embeddings-v2-base-code は、MongoDB、Qdrant、Weaviate などの主要なベクトルデータベース、および Haystack や LlamaIndex などのフレームワークをサポートし、容易な統合が可能なように設計されています。これにより、開発者は既存のシステムに私たちのモデルを簡単に組み込み、コード検索とドキュメンテーションプロセスを強化することができます。
jina-embeddings-v2-base-code についてのフィードバックを歓迎します。コミュニティチャンネルに参加して、フィードバックを提供し、私たちの進展について最新情報を得てください。共に、より強固で包括的な AI の未来を形作っていきましょう。
