
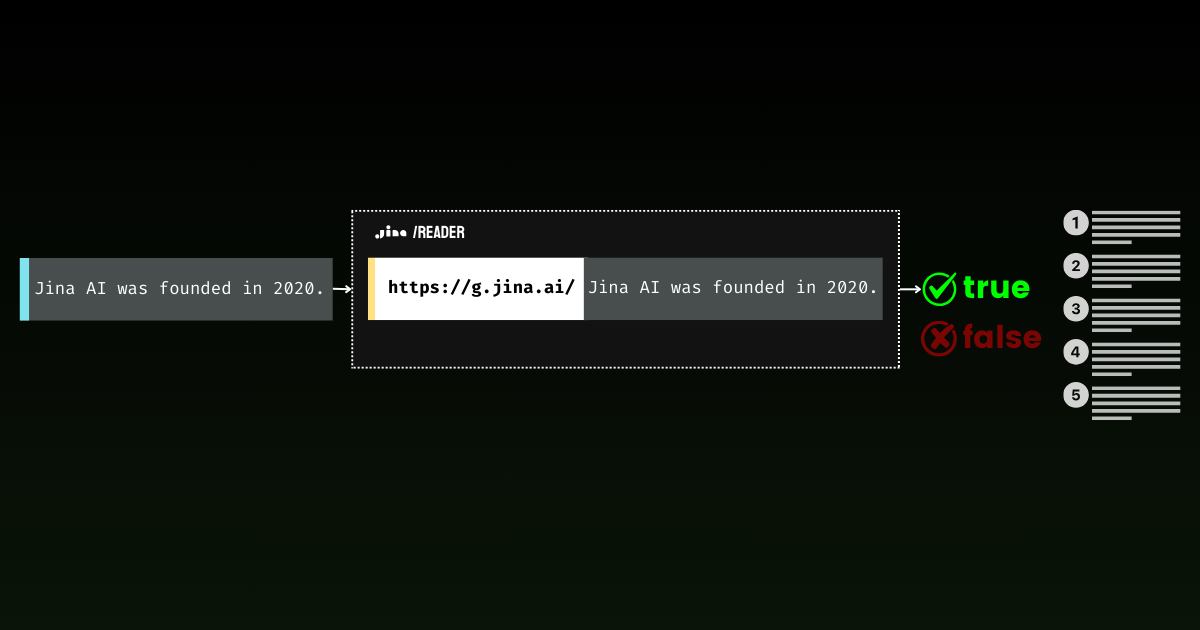

GenAI アプリケーションにとって、グラウンディングは絶対に必要不可欠です。
グラウンディングがないと、LLM は幻覚を起こしやすく、特にトレーニングデータに最新の情報や特定の知識が欠けている場合、不正確な情報を生成しやすくなります。LLM の推論能力がいかに優れていても、その知識のカットオフ日以降に導入された情報については、正しい回答を提供することはできません。
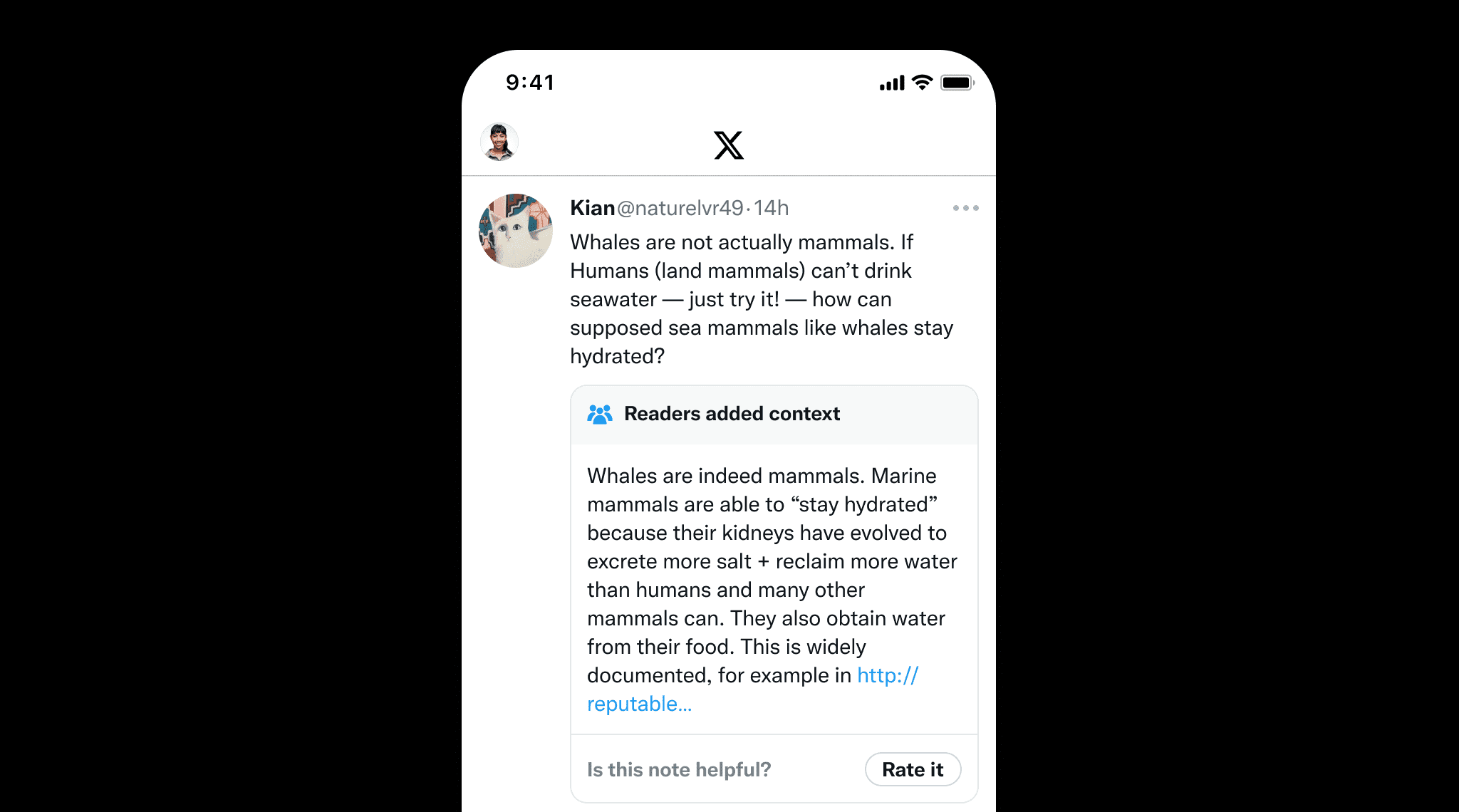
グラウンディングは LLM だけでなく、誤情報を防ぐために人が作成したコンテンツにとっても重要です。良い例がX の Community Notes で、ユーザーが協力して誤解を招く可能性のある投稿にコンテキストを追加します。これは、Community Notes が情報の整合性を維持するのに役立つように、明確なソースと参照を提供することで事実の正確性を確保するグラウンディングの価値を強調しています。
Jina Reader では、使いやすいグラウンディングソリューションを積極的に開発しています。例えば、r.jina.ai は Web ページを LLM フレンドリーな markdown に変換し、s.jina.ai は与えられたクエリに基づいて検索結果を統一された markdown 形式に集約します。

本日、このスイートに新しいエンドポイント g.jina.ai を導入することを発表できることを嬉しく思います。この新しい API は、与えられた文章をリアルタイムの Web 検索結果を使用してグラウンディングし、事実性スコアと使用された正確な参照を返します。実験によると、この API は GPT-4、o1-mini、Gemini 1.5 Flash & Pro with search grounding などのモデルと比較して、ファクトチェックにおいてより高い F1 スコアを達成しています。

g.jina.ai が Gemini の Search Grounding と異なる点は、各結果に最大 30 個の URL(通常は少なくとも 10 個)が含まれ、それぞれに結論に寄与する直接の引用が付随することです。以下は、"The latest model released by Jina AI is jina-embeddings-v3," という文章を g.jina.ai を使用してグラウンディングした例です(2024 年 10 月 14 日現在)。完全な機能を探るにはAPI プレイグラウンドをご覧ください。なお、制限事項が適用されます:
curl -X POST https://g.jina.ai \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $YOUR_JINA_TOKEN" \
-d '{
"statement":"the last model released by Jina AI is jina-embeddings-v3"
}'YOUR_JINA_TOKEN は Jina AI の API キーです。ホームページから 100 万トークンを無料で取得でき、これで 3〜4 回の無料試用が可能です。現在の API 価格は 100 万トークンあたり 0.02USD で、1 回のグラウンディングリクエストのコストは約 0.006USD です。
{
"code": 200,
"status": 20000,
"data": {
"factuality": 0.95,
"result": true,
"reason": "The majority of the references explicitly support the statement that the last model released by Jina AI is jina-embeddings-v3. Multiple sources, such as the arXiv paper, Jina AI's news, and various model documentation pages, confirm this assertion. Although there are a few references to the jina-embeddings-v2 model, they do not provide evidence contradicting the release of a subsequent version (jina-embeddings-v3). Therefore, the statement that 'the last model released by Jina AI is jina-embeddings-v3' is well-supported by the provided documentation.",
"references": [
{
"url": "https://arxiv.org/abs/2409.10173",
"keyQuote": "arXiv September 18, 2024 jina-embeddings-v3: Multilingual Embeddings With Task LoRA",
"isSupportive": true
},
{
"url": "https://arxiv.org/abs/2409.10173",
"keyQuote": "We introduce jina-embeddings-v3, a novel text embedding model with 570 million parameters, achieves state-of-the-art performance on multilingual data and long-context retrieval tasks, supporting context lengths of up to 8192 tokens.",
"isSupportive": true
},
{
"url": "https://azuremarketplace.microsoft.com/en-us/marketplace/apps/jinaai.jina-embeddings-v3?tab=Overview",
"keyQuote": "jina-embeddings-v3 is a multilingual multi-task text embedding model designed for a variety of NLP applications.",
"isSupportive": true
},
{
"url": "https://docs.pinecone.io/models/jina-embeddings-v3",
"keyQuote": "Jina Embeddings v3 is the latest iteration in the Jina AI's text embedding model series, building upon Jina Embedding v2.",
"isSupportive": true
},
{
"url": "https://haystack.deepset.ai/integrations/jina",
"keyQuote": "Recommended Model: jina-embeddings-v3 : We recommend jina-embeddings-v3 as the latest and most performant embedding model from Jina AI.",
"isSupportive": true
},
{
"url": "https://huggingface.co/jinaai/jina-embeddings-v2-base-en",
"keyQuote": "The embedding model was trained using 512 sequence length, but extrapolates to 8k sequence length (or even longer) thanks to ALiBi.",
"isSupportive": false
},
{
"url": "https://huggingface.co/jinaai/jina-embeddings-v2-base-en",
"keyQuote": "With a standard size of 137 million parameters, the model enables fast inference while delivering better performance than our small model.",
"isSupportive": false
},
{
"url": "https://huggingface.co/jinaai/jina-embeddings-v2-base-en",
"keyQuote": "We offer an `encode` function to deal with this.",
"isSupportive": false
},
{
"url": "https://huggingface.co/jinaai/jina-embeddings-v3",
"keyQuote": "jinaai/jina-embeddings-v3 Feature Extraction • Updated 3 days ago • 278k • 375",
"isSupportive": true
},
{
"url": "https://huggingface.co/jinaai/jina-embeddings-v3",
"keyQuote": "the latest version (3.1.0) of [SentenceTransformers] also supports jina-embeddings-v3",
"isSupportive": true
},
{
"url": "https://huggingface.co/jinaai/jina-embeddings-v3",
"keyQuote": "jina-embeddings-v3: Multilingual Embeddings With Task LoRA",
"isSupportive": true
},
{
"url": "https://jina.ai/embeddings/",
"keyQuote": "v3: Frontier Multilingual Embeddings is a frontier multilingual text embedding model with 570M parameters and 8192 token-length, outperforming the latest proprietary embeddings from OpenAI and Cohere on MTEB.",
"isSupportive": true
},
{
"url": "https://jina.ai/news/jina-embeddings-v3-a-frontier-multilingual-embedding-model",
"keyQuote": "Jina Embeddings v3: A Frontier Multilingual Embedding Model jina-embeddings-v3 is a frontier multilingual text embedding model with 570M parameters and 8192 token-length, outperforming the latest proprietary embeddings from OpenAI and Cohere on MTEB.",
"isSupportive": true
},
{
"url": "https://jina.ai/news/jina-embeddings-v3-a-frontier-multilingual-embedding-model/",
"keyQuote": "As of its release on September 18, 2024, jina-embeddings-v3 is the best multilingual model ...",
"isSupportive": true
}
],
"usage": {
"tokens": 112073
}
}
}"The latest model released by Jina AI is jina-embeddings-v3" という文章を g.jina.ai でグラウンディングした結果(2024 年 10 月 14 日現在)。
tag仕組みについて
中核として、g.jina.ai は s.jina.ai と r.jina.ai をラップし、Chain of Thought(CoT)を通じてマルチホップ推論を追加しています。このアプローチにより、グラウンディングされた各文章がオンライン検索とドキュメント読み取りの助けを借りて徹底的に分析されることを保証します。

s.jina.ai と r.jina.ai の上に構築されたラッパーで、プランニングと推論のための Chain of Thought を追加しています。tagステップバイステップの説明
g.jina.ai が入力から最終出力までの Grounding をどのように処理するかを詳しく見ていきましょう:
- 入力ステートメント:
プロセスは、ユーザーが検証したい文を提供することから始まります。例えば、「Jina AI が最新でリリースしたモデルは jina-embeddings-v3 です」というような文です。事実確認の指示を文の前に追加する必要はありません。 - 検索クエリの生成:
LLM を使用して、そのステートメントに関連する一意の検索クエリのリストを生成します。これらのクエリは、ステートメントのさまざまな事実要素を包括的にカバーすることを目的としています。 - 各クエリに対して
s.jina.aiを呼び出し:
生成された各クエリに対して、g.jina.aiはs.jina.aiを使用してウェブ検索を実行します。検索結果は、クエリに関連するウェブサイトやドキュメントの集合です。舞台裏では、s.jina.aiがr.jina.aiを呼び出してページコンテンツを取得します。 - 検索結果からの参照の抽出:
検索で取得した各ドキュメントから、LLM が重要な参照を抽出します。これらの参照には以下が含まれます:url:ソースのウェブアドレスkeyQuote:ドキュメントからの直接引用または抜粋isSupportive:参照が元のステートメントを支持するか反論するかを示すブール値
- 参照の集約とトリミング:
取得したドキュメントからのすべての参照が1つのリストにまとめられます。参照の総数が30を超える場合、システムはランダムに30の参照を選択して管理可能な出力を維持します。 - ステートメントの評価:
評価プロセスでは、LLM を使用して収集した参照(最大30)に基づいてステートメントを評価します。これらの外部参照に加えて、モデルの内部知識も評価に役立ちます。最終結果には以下が含まれます:factuality:ステートメントの事実的正確性を0から1の間でスコア化result:ステートメントが真か偽かを示すブール値reason:支持または反論するソースを参照しながら、なぜそのステートメントが正しいまたは間違っていると判断されたかの詳細な説明
- 結果の出力:
ステートメントの評価が完了すると、出力が生成されます。これには、事実性スコア、ステートメントの判定、詳細な根拠、そして引用とURLを含む参照リストが含まれます。参照は引用、URL、およびステートメントを支持するかどうかに限定され、出力を明確で簡潔に保ちます。
tagベンチマーク
私たちは手作業で100のステートメントを収集し、それぞれに true(62ステートメント)または false(38ステートメント)の真偽ラベルを付け、さまざまな手法で事実確認が可能かどうかを判定しました。このプロセスは本質的にタスクを二値分類問題に変換し、最終的なパフォーマンスは精度、再現率、F1スコアで測定されます—値が高いほど良いとされます。
ステートメントの完全なリストはこちらでご覧いただけます。
| Model | Precision | Recall | F1 Score |
|---|---|---|---|
| Jina AI Grounding API (g.jina.ai) | 0.96 | 0.88 | 0.92 |
| Gemini-flash-1.5-002 w/ grounding | 1.00 | 0.73 | 0.84 |
| Gemini-pro-1.5-002 w/ grounding | 0.98 | 0.71 | 0.82 |
| gpt-o1-mini | 0.87 | 0.66 | 0.75 |
| gpt-4o | 0.95 | 0.58 | 0.72 |
| Gemini-pro-1.5-001 w/ grounding | 0.97 | 0.52 | 0.67 |
| Gemini-pro-1.5-001 | 0.95 | 0.32 | 0.48 |
なお、実際には一部の LLM は予測で第三のクラスである「分からない」を返すことがあります。評価では、これらのインスタンスはスコア計算から除外されます。このアプローチにより、不確実な回答に対して誤った回答と同程度のペナルティを課すことを避けています。モデルが不確実な予測をすることを防ぐため、推測するよりも不確実性を認めることが望ましいとされています。
tag制限事項
有望な結果にもかかわらず、現バージョンの Grounding API にはいくつかの制限があることを強調したいと思います:
- 高いレイテンシーとトークン消費:アクティブなウェブ検索、ページ読み込み、LLM による多段階推論のため、
g.jina.aiの1回の呼び出しには約30秒かかり、最大30万トークンを使用する可能性があります。100万トークンの無料 API キーでは、3〜4回程度しかテストできないことを意味します。有料ユーザーのサービス可用性を維持するため、g.jina.aiには保守的なレート制限も実装しています。現在の API 価格である100万トークンあたり0.02 USD では、1回の Grounding リクエストは約0.006 USD のコストがかかります。 - 適用の制約:すべてのステートメントが Grounding できる、またはすべきというわけではありません。「疲れている」といった個人の意見や経験は、Grounding に適していません。同様に、将来の出来事や仮説的なステートメントも適用できません。Grounding が無意味または的外れになる場合が多くあります。不必要な API 呼び出しを避けるため、ユーザーは実際に事実確認が必要な文や部分のみを選択的に提出することをお勧めします。サーバー側では、ステートメントが Grounding を拒否される可能性がある理由を説明する包括的なエラーコードを実装しています。
- ウェブデータの品質への依存:Grounding API の精度は、取得するソースの品質に依存します。検索結果に低品質または偏ったデータが含まれている場合、Grounding プロセスがそれを反映し、不正確または誤解を招く結論につながる可能性があります。この問題を防ぐため、ユーザーが手動で
referencesパラメータを指定し、システムが検索する URL を制限できるようにしています。これにより、ユーザーは Grounding に使用するソースをより詳細にコントロールでき、より的確で関連性の高い事実確認プロセスを確保できます。
tag結論
Grounding API は、エンドツーエンドのほぼリアルタイムな事実確認体験を提供します。研究者は、自身の仮説を支持または反証する参照を見つけることで、研究の信頼性を高めることができます。企業の会議では、仮定やデータを検証することで、正確で最新の情報に基づいた戦略構築を確保します。政治的議論では、主張を素早く検証し、議論により多くの説明責任をもたらします。
今後は、より詳細な事実確認のために、社内レポート、データベース、PDF などのプライベートデータソースを統合することで、API を強化する計画です。また、より深い評価のためにリクエストごとの確認ソース数を増やすことも目指しています。多段階質問応答を改善することで分析の深さを増し、繰り返しのリクエストでより信頼性の高い一貫した結果を生成できるよう、一貫性の向上を優先事項としています。
