



新しい情報検索技術に対応することは重要ですが、すでに実績があり、ビジネス価値を実証済みのコンポーネントを壊さないことも同様に重要です。
AI 駆動のベクトル検索が成長しているにもかかわらず、実際には多くの企業が従来の検索技術に依存しており、多くの場合 BM25 アルゴリズムの変種を使用しています。これは信頼性が高く、実績のある技術です。完全に新しいシステムへの移行は大きなステップであるだけでなく、多くの場合、相当なリソースと運用の全面的な見直しを必要とするため、実用的ではありません。さらに、BM25 は Elasticsearch や Solr などの広く普及している検索エンジンプラットフォームで一般的に使用される字句検索エンジンの基礎となっています。多くのユースケースですでに強力な結果を提供しています。
そのため、AI ベースの検索がユーザー満足度と結果の品質を大幅に向上させるという説得力のある証拠があるにもかかわらず、多くの企業はニューラル検索への完全な移行をためらっています。
tag検索方式に依存しないニューラルリランキング
Reranker は検索システムの画期的な追加機能です。Elasticsearch などの既存の検索エンジンを強化するように設計されており、提供される検索品質を改善するアドオンのように機能する追加レイヤーとして機能します。接続されている検索技術の種類を知る必要はなく、単にマッチのリストを受け取り、より良い順序に並べ替えます。
Jina Reranker は従来の検索技術にさらに深い理解を加えます。BM25 のようなアルゴリズムは用語の頻度に基づいてドキュメントを検索する点では優れていますが、ユーザーの意図に照らして検索したテキストの意味を評価することは苦手です。これは AI が得意とする分野です:Reranker はユーザーが探しているものにより合致した結果を生み出すのに役立ちます。
したがって、AI モデルの強力な利点を検索フレームワークにもたらしたい企業にとって、Jina Reranker を追加することは賢明な選択であり、既存の検索インフラを置き換える負担を伴いません。これは検索結果を単に許容可能なものではなく、より関連性が高く正確な、優れたものにする改善です。
tagなぜ Jina Reranker なのか?
リランカーモデルの中で、Jina Reranker モデルは最先端として、パフォーマンスベンチマークでトップクラスのスコアを記録しています。

この記事では、e コマースプラットフォーム向けのレコメンデーションシステムの実装方法をご紹介します。まず、BM25 リトリーバー単体のパフォーマンスを分析します。次に、検索パイプラインに Jina Reranker を追加し、結果がより関連性が高く効果的になる様子を見ていきます。
tag既存のワークフローに Jina Reranker を追加する:
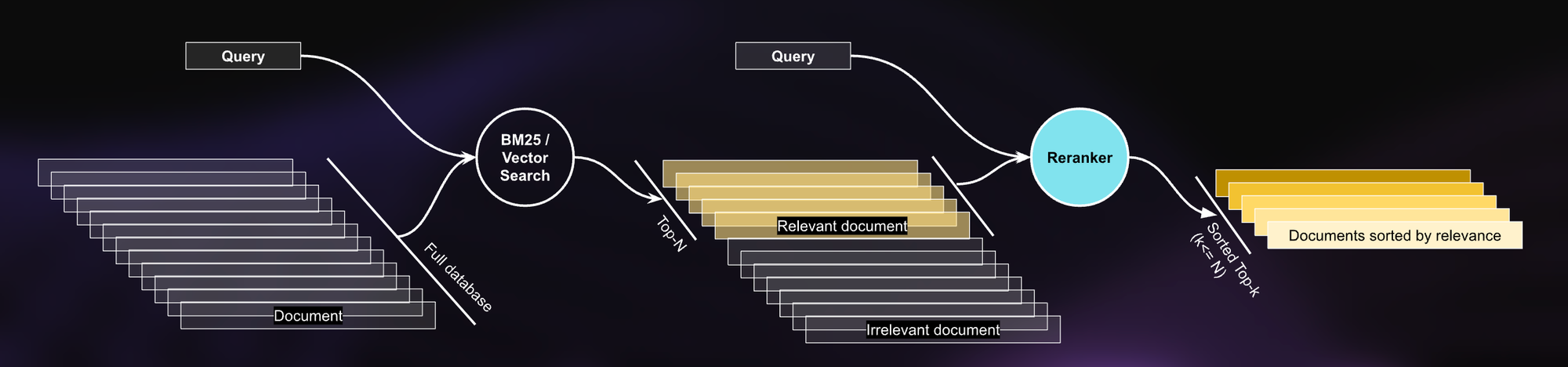
Jina Reranker を統合した更新されたワークフローの内訳は以下の通りです:
- 初期検索:クエリが入力されると、BM25 検索エンジンはクエリ用語とドキュメントのマッチングに基づいて関連ドキュメントを検索します。
- リランキング:jina-reranker-v1-base-en はこれらの初期結果を受け取り、最先端の AI を使用してユーザーのクエリに照らして各検索ドキュメントの関連性を評価します。
- 結果の返却:Jina Reranker は検索結果を並べ替え、最も関連性の高いドキュメントが上位に表示されるようにします。
私たちの使いやすい API と包括的なドキュメントが、システムへの最小限の変更だけで、プロセス全体をガイドします。

tag実際の動作:Jina Reranker を使用した e コマース検索の強化
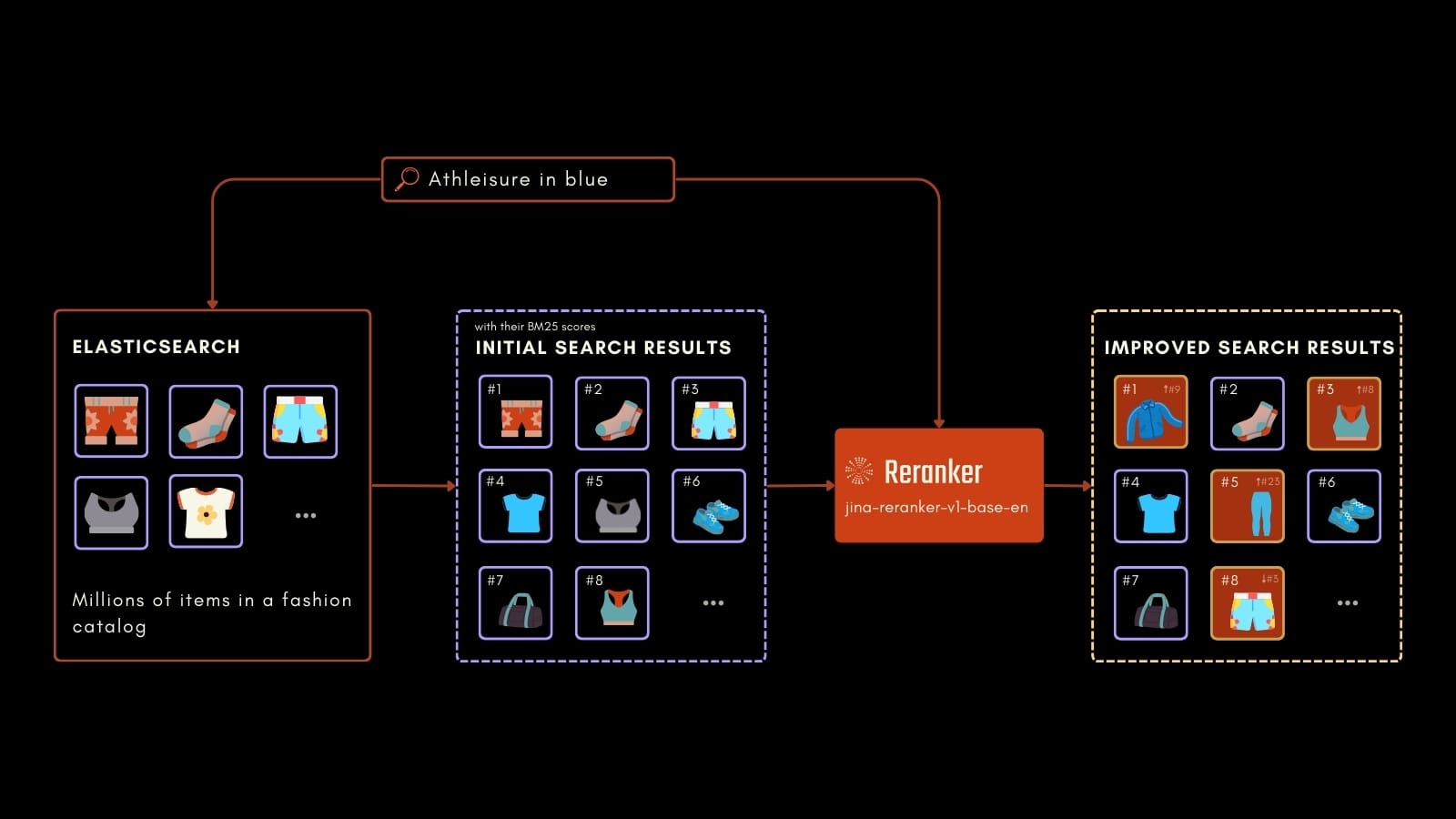
実際の応用例として、e コマースの例を通じて Jina Reranker の効果を実証してみましょう。ここでの目標は、ユーザーのクエリに基づいて商品リストを検索することです。
これを示すために、人気のある AI 検索・オーケストレーションフレームワークである Haystack by deepset を使用して 2 つの検索パイプラインを設定します。最初のパイプラインは BM25 単独で使用します。2 つ目は BM25 システムに jina-reranker-v1-base-en を統合します。既存の Elasticsearch クラスターがある場合は、Haystack の InMemoryDocumentStore コンポーネントを ElasticsearchDocumentStore に簡単に置き換えて同じ実験を行うことができます。
Kaggle のサンプルデータセットを使用します。CSV はここから直接ダウンロードできます。この比較は、検索ワークフローに Jina Reranker を組み込むことによる改善を示しています。
まず、必要なコンポーネントをすべてインストールします:
pip install --q haystack-ai jina-haystack
Jina API キーを環境変数として設定します。ここで生成できます。
import os
import getpass
os.environ["JINA_API_KEY"] = getpass.getpass()
商品名に基づいて商品を検索します。例:
short_query = "Nightwear for Women"
各 CSV の行を Document に変換します:
import csv
from haystack import Document
documents = []
with open("fashion_data.csv") as f:
data = csv.reader(f, delimiter=";")
for row in data:
row_text = ''.join(row)
row_doc = Document(content=row_text, meta={"prod_id": row[0], "prod_image": row[1]})
documents.append(row_doc)
tagパイプライン #1:BM25 のみ
from haystack import Pipeline
from haystack.document_stores.types import DuplicatePolicy
from haystack.document_stores.in_memory import InMemoryDocumentStore
from haystack.components.retrievers.in_memory import InMemoryBM25Retriever
document_store=InMemoryDocumentStore()
document_store.write_documents(documents=documents, policy=DuplicatePolicy.OVERWRITE)
retriever = InMemoryBM25Retriever(document_store=document_store)
rag_pipeline = Pipeline()
rag_pipeline.add_component("retriever", retriever)
result = rag_pipeline.run(
{
"retriever": {"query": query, "top_k": 50},
}
)
for doc in result["retriever"]["documents"]:
print("Product ID:", doc.meta["prod_id"])
print("Product Image:", doc.meta["prod_image"])
print("Score:", doc.score)
print("-"*100)
BM25 によって返された 50 件の結果のサムネイルです:

結果はナイトウェアに関連しており、クエリと部分的に一致していますが、最も関連性の高い一致(グリッド内の太字の画像)が BM25 によって取得された多数の製品の中に埋もれてしまっているようです。実際には、BM25 のみを使用すると、ユーザーはページの上部で主に関連性のない結果を受け取ることになります。
tagパイプライン #2:BM25 + Jina Reranker
以下のスクリプトは、このパイプラインを段階的に構築する方法を示しています:
from haystack_integrations.components.rankers.jina import JinaRanker
ranker_retriever = InMemoryBM25Retriever(document_store=document_store)
ranker = JinaRanker()
ranker_pipeline = Pipeline()
ranker_pipeline.add_component("ranker_retriever", ranker_retriever)
ranker_pipeline.add_component("ranker", ranker)
ranker_pipeline.connect("ranker_retriever.documents", "ranker.documents")
result = ranker_pipeline.run(
{
"ranker_retriever": {"query": query, "top_k": 50},
"ranker": {"query": query, "top_k": 10},
}
)
for doc in result["ranker"]["documents"]:
print("Product ID:", doc.meta["prod_id"])
print("Product Image:", doc.meta["prod_image"])
print("Score:", doc.score)
print("-"*100)
Jina Reranker が返した上位 10 件の結果です:

BM25 と比較して、Jina Reranker はより関連性の高い回答のコレクションを返します。私たちの e コマースの設定では、これはより良いユーザーエクスペリエンスと購入の可能性の向上につながります。
tagJina Reranker と BM25 の統合の影響
e コマース領域での事例研究を通じて、Jina Reranker と Elasticsearch などの従来の検索エンジンの統合が検索技術において大きな飛躍をもたらすことが明らかになりました。この統合が検索体験を改善する方法の概要は以下の通りです:
- ヒット率の向上:Jina Reranker と従来の検索の融合により、関連性のある結果の頻度が著しく向上しました。これにより、検索プロセスの精度が高まり、ユーザーのクエリにより密接に適合するようになりました。
- ユーザーエクスペリエンスの向上:検索結果の品質に明確な改善が見られます。これは、Jina Reranker と BM25 の組み合わせた機能が、ユーザーの特定のニーズにより適合し、全体的な検索体験を向上させていることを示しています。
- 複雑なクエリに対する高精度:難しい検索に関しては、この相乗効果によりクエリと関連コンテンツの両方をより詳細に理解できます。これにより、より鋭く正確な結果が得られます。
tag検索体験を向上させる準備はできていますか?
Jina Reranker は、検索結果の関連性を高めるための理想的なソリューションです。既存の検索システムとシームレスに統合でき、最小限のコーディングで迅速に実装できます。
ここまでお読みいただいて興味を持たれた方、Jina Reranker がどのような違いをもたらすか確認したい方は、ぜひお試しください。Jina AI の Search Foundation モデルの変革力を、ご自身の環境で体験してみてください。
