

ベルリン、ドイツ - 2023年1月15日 – JFK の象徴的な「私もベルリン市民である」という言葉にならい、Jina AI では独自の方法で言語の架け橋を築くことを喜びとしています。本日、私たちは最新のイノベーション:jina-embeddings-v2-base-de、ドイツ語/英語の埋め込みモデルを発表できることを誇りに思います。この最先端のバイリンガルモデルは言語表現において大きな前進を遂げ、8,192トークンのコンテキスト長を誇ります。特筆すべきは、同等のモデルと比べてサイズが1/7にすぎないにもかかわらず、トップクラスのパフォーマンスを達成していることです。
埋め込みは、米国市場への進出を目指すドイツ企業にとって重要です。German American Business Outlook (GABO) 2022によると、ドイツ企業の約3分の1が世界の売上と利益の20%以上を米国で生み出しており、93%が米国での売上増加を見込んでいます。この傾向は続いており、93%が今後3年間で米国への投資を拡大する計画を立てており、85%が純売上高の成長を期待し、デジタルトランスフォーメーションに重点を置いています。優れた埋め込みは、顧客の嗜好をより深く理解し、より効果的なコミュニケーションを可能にし、文化的に共鳴する製品を位置づけることで、この拡大に重要な役割を果たすことができます。
私たちのブレークスルーは、英語圏でバイリンガルアプリケーションを実装しようとするドイツ企業にとって特に有益です。jina-embeddings-v2-base-deにより、ドイツ企業がますます連携が進む世界でどのようにイノベーションを起こし、成長していくのかを見るのが楽しみです。
tagモデルのハイライト
- 最先端のパフォーマンス:jina-embeddings-v2-base-deは、関連するベンチマークで常にトップにランクされ、同様のサイズのオープンソースモデルの中でもリードしています。
- バイリンガルモデル: このモデルはドイツ語と英語の両方のテキストをエンコードし、検索アプリケーションでいずれの言語もクエリまたは対象ドキュメントとして使用できます。両言語で同等の意味を持つテキストは同じ埋め込み空間にマッピングされ、多言語アプリケーションの基礎となります。
- 拡張されたコンテキスト:8192トークンの長さにより、jina-embeddings-v2-base-deは数百トークンしかサポートしないモデルをはるかに超えて、より長いテキストやドキュメントフラグメントをサポートできます。
- コンパクトなサイズ:jina-embeddings-v2-base-deは標準的なコンピュータハードウェアで高性能を発揮するように設計されています。パラメータ数はわずか1億6,100万で、モデル全体は322MBで一般的なコンピュータのメモリに収まります。埋め込み自体は768次元で、多くのモデルと比較して比較的小さなベクトルサイズであり、アプリケーションのスペースと実行時間を節約します。
- バイアスの最小化:最近の研究によると、特定の言語トレーニングを受けていない多言語モデルは、埋め込みにおいて英語の文法構造に強いバイアスを示すことが判明しています。埋め込みモデルは意味を捉えることに重点を置くべきであり、表面的に類似しているだけの文ペアを優遇すべきではありません。
- シームレスな統合:Jina Embeddings v2モデルは、MongoDB、Qdrant、Weaviateなどの主要なベクターデータベース、およびHaystackやLlamaIndexなどのRAGとLLMフレームワークとネイティブに統合されています。
tagドイツ語NLPにおける優れたパフォーマンス
私たちはjina-embeddings-v2-base-deを、ドイツ語と英語の両方をサポートする4つの著名なベースラインと比較テストを行いました。これらには以下が含まれます:
- MicrosoftのMultilingual-E5-largeおよびMultilingual-E5-base
- T-SystemsのCross English & German RoBERTa for Sentence Embeddings
- Sentence-BERT(
distiluse-base-multilingual-cased-v2)
私たちのベンチマークには英語のMTEBタスクと独自のカスタムベンチマークが含まれています。ドイツ語埋め込みの包括的なベンチマークスイートが不足していたため、MTEBにインスパイアされた独自のベンチマークを開発する取り組みを行いました。ここでその発見とブレークスルーを共有できることを誇りに思います。
 jina-ai
jina-ai
tagコンパクトなサイズ、優れた結果
jina-embeddings-v2-base-deは、特にドイツ語タスクで卓越したパフォーマンスを示しています。サイズが3分の1以下でありながら、E5ベースモデルを凌駕しています。さらに、7倍の大きさを持つE5ラージモデルと互角の性能を示し、その効率性とパワーを実証しています。この効率性は、他の一般的な二言語・多言語埋め込みモデルと比較して、jina-embeddings-v2-base-deを画期的なものにしています。
tagドイツ語-英語のクロス言語検索での優れた性能
私たちのモデルはサイズと効率性だけでなく、英独クロス言語検索タスクでもトップパフォーマーです。これは以下の主要なベンチマークでの性能に表れています:
- 英語からドイツ語への検索のためのWikiCLIR
- 英語からドイツ語への検索のためのMTEB評価の一部であるSTS17
- ドイツ語から英語への検索のための、同じくMTEBの一部であるSTS22
- ドイツ語から英語への検索のための、MTEBに含まれるBUCC
これらのベンチマーク、特にMTEB評価テスト(WikiCLIRを除く)でのパフォーマンスは、jina-embeddings-v2-base-deが複雑なバイリンガルタスクを効果的に処理できることを示しています。
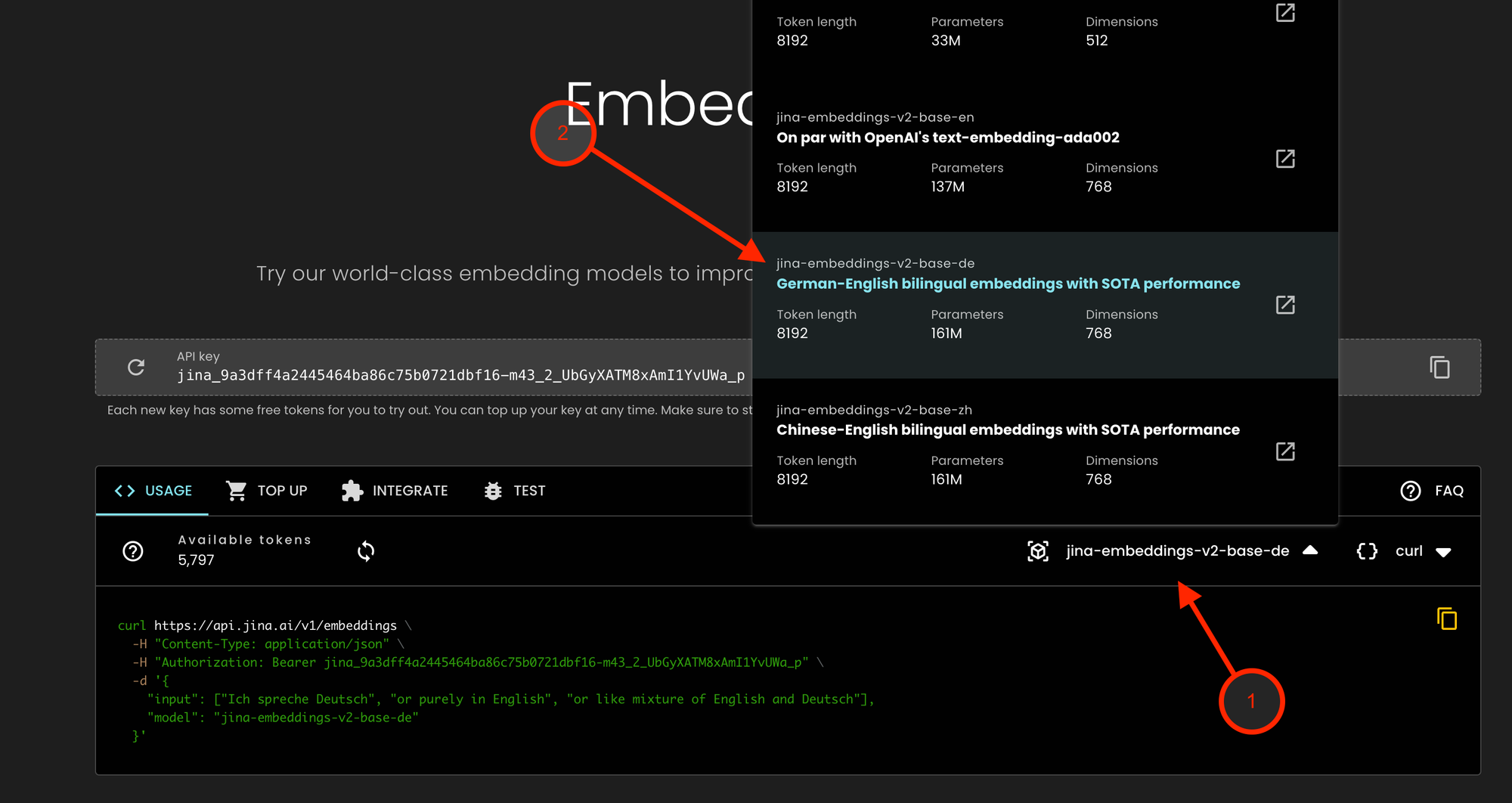
tagAPIアクセスの取得
プライバシーとデータコンプライアンスを重視するエンタープライズユーザー向けの提供物(jina-embeddings-v2-base-deを含む)は、Jina Embeddings APIを通じてアクセスできます:
- Jina Embeddings API にアクセスし、モデルのドロップダウンをクリックします
- jina-embeddings-v2-base-de を選択します

このモデルは近日中に、Amazon クラウドユーザー向けの AWS Sagemaker マーケットプレイスと、HuggingFace でのダウンロードで利用可能になる予定です。
tagJina 8K Embeddings:多様な AI アプリケーションの基盤
Embedding は、情報検索、データ品質管理、分類、推奨など、幅広い AI アプリケーションに不可欠です。これらは多くの AI タスクを強化する基礎となっています。
Jina AI は、プライバシーとデータコンプライアンスを重視するあらゆる種類と規模の企業に対して、中核的な AI コンポーネントを透明で、アクセスしやすく、手頃な価格に保ちながら、Embedding 技術の最先端を推進することに取り組んでいます。jina-embeddings-v2-base-de に加えて、Jina AI は中国語向けの最先端の Embedding モデルと、高性能な英語単一言語モデルをリリースしています。これは、AI 技術をよりインクルーシブで世界的に適用可能にするという私たちのミッションの一環です。
皆様のフィードバックを大切にしています。コミュニティチャンネルに参加して、フィードバックを提供し、私たちの進歩について最新情報を得てください。共に、より強固でインクルーシブな AI の未来を形作っていきましょう。


