



開発者やオペレーションエンジニアは、簡単にセットアップでき、迅速に起動でき、後で追加の手間なく効率的にスケールした本番環境にデプロイできるインフラストラクチャを重視しています。そのため、パートナーである Milvus が提供する最新の軽量ベクトルデータベース Milvus Lite は、特に高品質で使いやすい検索基盤モデルと組み合わせた場合に、Python 開発者が検索アプリケーションを迅速に開発するための重要なツールとなっています。
本記事では、架空の企業の社内公開チャンネルのチャットを基に構築した Retrieval Augmented Generation (RAG) アプリケーションの例を用いて、Milvus Lite が Jina Embeddings v2 と Jina Reranker v1 をどのように統合し、従業員が組織に関する質問に正確で有用な回答を得られるようにするかを説明します。
tagMilvus Lite、Jina Embeddings、Jina Reranker の概要
Milvus Lite は、主要なベクトルデータベースである Milvus の新しい軽量バージョンで、Python ライブラリとしても提供されています。Milvus Lite は、Docker や Kubernetes にデプロイされた Milvus と同じ API を共有していますが、サーバーをセットアップすることなく、1 行の pip コマンドで簡単にインストールできます。
Milvus の Python SDK である pymilvus に Jina Embeddings v2 と Jina Reranker v1 を統合することで、Milvus Lite を含む Milvus のあらゆるデプロイメントモードで、同じ Python クライアントを使用してドキュメントを直接埋め込むことができるようになりました。Jina Embeddings と Reranker の統合の詳細については、pymilvus の ドキュメントページをご覧ください。
8k トークンのコンテキストウィンドウと多言語対応機能を備えた Jina Embeddings v2 は、テキストの幅広い意味を符号化し、正確な検索を保証します。パイプラインに Jina Reranker v1 を追加することで、より深いコンテキスト理解のために検索結果をクエリと直接クロスエンコードして、結果をさらに精緻化することができます。
tagMilvus と Jina AI モデルの実践
このチュートリアルでは、実践的なユースケースに焦点を当てます:過去の会話に基づいて、企業の Slack チャット履歴から幅広い質問に答えることです。
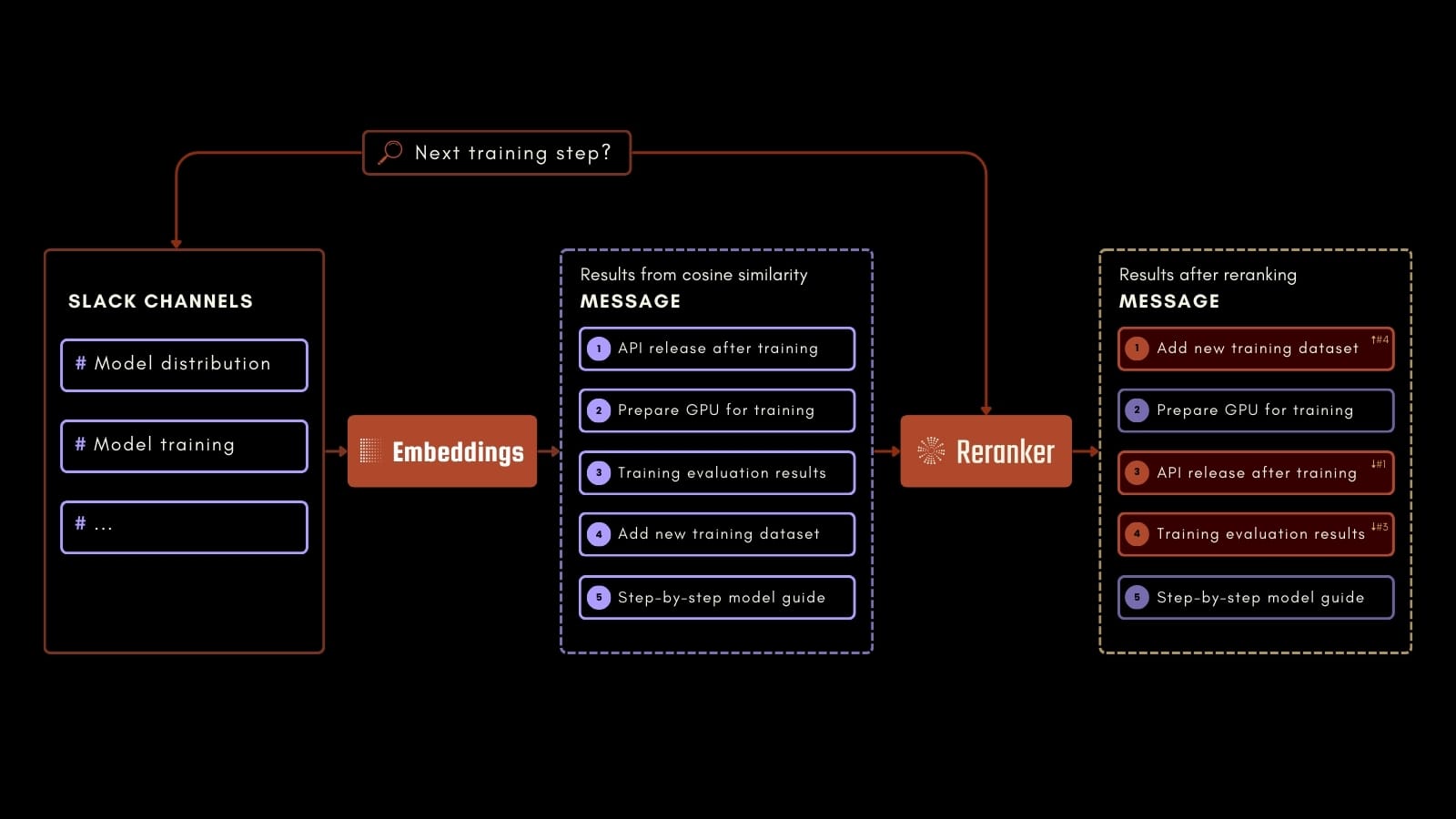
例えば、上記のプロセス図のように、従業員が AI トレーニングプロセスの次のステップについて質問することができます。Jina Embeddings、Jina Reranker、Milvus を使用することで、記録された Slack メッセージから関連情報を正確に特定できます。このアプリケーションは、過去のコミュニケーションから価値ある情報へのアクセスを容易にすることで、職場の生産性を向上させることができます。
回答を生成するために、Langchain の HuggingFace 統合を通じて Mixtral 7B Instruct を使用します。モデルを使用するには、こちらの説明に従って生成できる HuggingFace アクセストークンが必要です。
Colab で、またはノートブックをダウンロードして実践できます。


tagデータセットについて
このチュートリアルで使用されるデータセットは GPT-4 を使用して生成され、Blueprint AI の Slack チャンネルのチャット履歴を再現することを目的としています。Blueprint は独自の基盤モデルを開発している架空の AI スタートアップです。データセットはこちらからダウンロードできます。
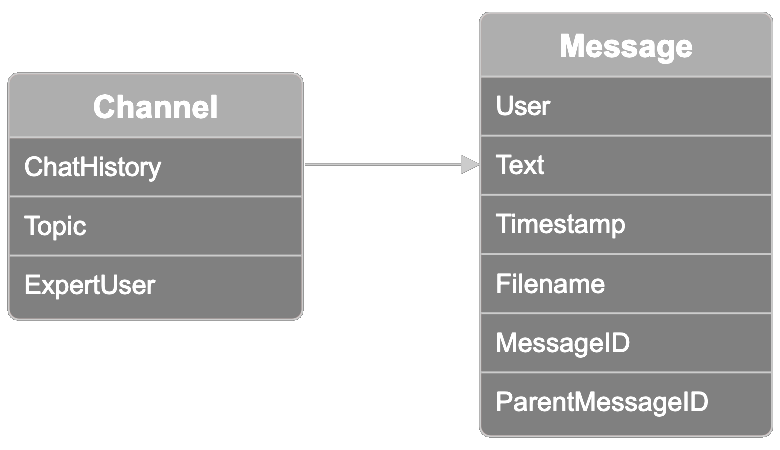
データは関連する Slack スレッドのコレクションを表す「チャンネル」で整理されています。各チャンネルには、10 のトピックオプションのいずれかのトピックラベルがあります:「model distribution」、「model training」、「model fine-tuning」、「ethics and bias mitigation」、「user feedback」、「sales」、「marketing」、「model onboarding」、「creative design」、「product management」。あるユーザーは「expert user」として知られています。この情報を使用して、以下で説明するようにトピックの最も専門的なユーザーを検索した結果を検証できます。
各チャンネルには、チャンネルごとに最大 100 メッセージの会話スレッドを含むチャット履歴もあります。データセットの各メッセージには以下の情報が含まれています:
- メッセージを送信したユーザー
- ユーザーが送信したメッセージテキスト
- メッセージのタイムスタンプ
- ユーザーがメッセージに添付した可能性のあるファイル名
- メッセージ ID
- メッセージが別のメッセージから始まったスレッド内にある場合の親メッセージ ID
tag環境のセットアップ
まず、必要なコンポーネントをすべてインストールします:
pip install -U pymilvus
pip install -U "pymilvus[model]"
pip install langchain
pip install langchain-community
データセットをダウンロードします:
import os
if not os.path.exists("chat_history.json"):
!wget https://raw.githubusercontent.com/jina-ai/workshops/main/notebooks/embeddings/milvus/chat_history.json環境変数に Jina AI API キーを設定します。こちらで生成できます。
import os
import getpass
os.environ["JINAAI_API_KEY"] = getpass.getpass(prompt="Jina AI API Key: ")同様に Hugging Face トークンも設定します。生成方法はこちらでご確認いただけます。Hugging Face Hub にアクセスするために READ に設定されていることを確認してください。
os.environ["HUGGINGFACEHUB_API_TOKEN"] = getpass.getpass(prompt="Hugging Face Token: ")tagMilvus コレクションの作成
データをインデックスするために Milvus コレクションを作成します:
from pymilvus import MilvusClient, DataType
# Specify a local file name as uri parameter of MilvusClient to use Milvus Lite
client = MilvusClient("milvus_jina.db")
schema = MilvusClient.create_schema(
auto_id=True,
enable_dynamic_field=True,
)
schema.add_field(field_name="id", datatype=DataType.INT64, description="The Primary Key", is_primary=True)
schema.add_field(field_name="embedding", datatype=DataType.FLOAT_VECTOR, description="The Embedding Vector", dim=768)
index_params = client.prepare_index_params()
index_params.add_index(field_name="embedding", metric_type="COSINE", index_type="AUTOINDEX")
client.create_collection(collection_name="milvus_jina", schema=schema, index_params=index_params)tagデータの準備
チャット履歴を解析してメタデータを抽出します:
import json
with open("chat_history.json", "r", encoding="utf-8") as file:
chat_data = json.load(file)
messages = []
metadatas = []
for channel in chat_data:
chat_history = channel["chat_history"]
chat_topic = channel["topic"]
chat_expert = channel["expert_user"]
for message in chat_history:
text = f"""{message["user"]}: {message["message"]}"""
messages.append(text)
meta = {
"time_stamp": message["time_stamp"],
"file_name": message["file_name"],
"parent_message_nr": message["parent_message_nr"],
"channel": chat_topic,
"expert": True if message["user"] == chat_expert else False
}
metadatas.append(meta)
tagチャットデータの埋め込み
関連するチャット情報を取得するために、Jina Embeddings v2 を使用して各メッセージの埋め込みを作成します:
from pymilvus.model.dense import JinaEmbeddingFunction
jina_ef = JinaEmbeddingFunction("jina-embeddings-v2-base-en")
embeddings = jina_ef.encode_documents(messages)tagチャットデータのインデックス作成
メッセージ、その埋め込み、および関連するメタデータのインデックスを作成します:
collection_data = [{
"message": message,
"embedding": embedding,
"metadata": metadata
} for message, embedding, metadata in zip(messages, embeddings, metadatas)]
data = client.insert(
collection_name="milvus_jina",
data=collection_data
)tagチャット履歴の検索
質問をしてみましょう:
query = "Who knows the most about encryption protocols in my team?"クエリを埋め込み、関連するメッセージを取得します。ここでは、最も関連性の高い 5 つのメッセージを取得し、Jina Reranker v1 を使用してそれらを再ランク付けします:
from pymilvus.model.reranker import JinaRerankFunction
query_vectors = jina_ef.encode_queries([query])
results = client.search(
collection_name="milvus_jina",
data=query_vectors,
limit=5,
)
results = results[0]
ids = [results[i]["id"] for i in range(len(results))]
results = client.get(
collection_name="milvus_jina",
ids=ids,
output_fields=["id", "message", "metadata"]
)
jina_rf = JinaRerankFunction("jina-reranker-v1-base-en")
documents = [results[i]["message"] for i in range(len(results))]
reranked_documents = jina_rf(query, documents)
reranked_messages = []
for reranked_document in reranked_documents:
idx = reranked_document.index
reranked_messages.append(results[idx])最後に、Mixtral 7B Instruct と再ランク付けされたメッセージをコンテキストとして使用して、クエリへの回答を生成します:
from langchain.prompts import PromptTemplate
from langchain_community.llms import HuggingFaceEndpoint
llm = HuggingFaceEndpoint(repo_id="mistralai/Mixtral-8x7B-Instruct-v0.1")
prompt = """<s>[INST] Context information is below.\\n
It includes the five most relevant messages to the query, sorted based on their relevance to the query.\\n
---------------------\\n
{context_str}\\\\n
---------------------\\n
Given the context information and not prior knowledge,
answer the query. Please be brief, concise, and complete.\\n
If the context information does not contain an answer to the query,
respond with \\"No information\\".\\n
Query: {query_str}[/INST] </s>"""
prompt = PromptTemplate(template=prompt, input_variables=["query_str", "context_str"])
llm_chain = prompt | llm
answer = llm_chain.invoke({"query_str":query, "context_str":reranked_messages})
print(f"\n\nANSWER:\n\n{answer}")質問への回答は:
「コンテキスト情報に基づくと、User5 がチーム内で暗号化プロトコルについて最も知識があるようです。彼らは、新しいプロトコルがデータセキュリティを大幅に向上させると述べており、特にクラウドデプロイメントにおいてその効果が顕著であると言及しています。」
chat_history.json のメッセージを確認すれば、User5 が最も専門的なユーザーかどうか自分で検証できます。
tagまとめ
Milvus Lite のセットアップ方法、Jina Embeddings v2 を使用したチャットデータの埋め込み、そして Jina Reranker v1 を使用した検索結果の改善について、Slack チャット履歴の検索という実用的なユースケースを通じて見てきました。Milvus Lite は、複雑なサーバー設定を必要とせずに Python ベースのアプリケーション開発を簡素化します。Jina Embeddings と Reranker との統合により、職場での貴重な情報へのアクセスを容易にし、生産性を向上させることを目指しています。
tagJina AI Models と Milvus を今すぐ使用
統合された Jina Embeddings と Reranker を備えた Milvus Lite は、わずか数行のコードで使用できる完全な処理パイプラインを提供します。
皆様のユースケースについてお聞かせいただき、Jina AI Milvus エクステンションがビジネスニーズにどのように適合するかについて話し合えることを楽しみにしています。ウェブサイトまたはDiscord チャンネルからご連絡いただき、フィードバックを共有し、最新のモデルについての情報を入手してください。Milvus と Jina AI の統合に関する質問については、Milvus コミュニティにご参加ください。
