



Jina CLIP v1(jina-clip-v1)は、OpenAI のオリジナル CLIP モデルの機能を拡張した新しいマルチモーダル埋め込みモデルです。この新しいモデルにより、テキストのみとテキスト・画像のクロスモーダル検索の両方で最先端の性能を提供する単一の埋め込みモデルを利用できます。Jina AI は、OpenAI CLIP の性能をテキストのみの検索で 165%、画像から画像への検索で 12%向上させ、テキストから画像および画像からテキストのタスクでは同等またはわずかに優れた性能を実現しました。この強化された性能により、Jina CLIP v1 はマルチモーダル入力を扱う上で不可欠なものとなっています。
本記事では、まず元の CLIP モデルの欠点と、独自の共同学習手法でそれらをどのように解決したかについて説明します。次に、様々な検索ベンチマークにおける我々のモデルの有効性を実証します。最後に、Embeddings API と Hugging Face を通じて Jina CLIP v1 を使い始める方法について詳しく説明します。
tagマルチモーダル AI のための CLIP アーキテクチャ
2021 年 1 月、OpenAI はCLIP(対照的言語-画像事前学習)モデルをリリースしました。CLIP は単純ながら巧妙なアーキテクチャを持っています:テキスト用と画像用の 2 つの埋め込みモデルを、単一の出力埋め込み空間を持つ単一のモデルに組み合わせています。そのテキストと画像の埋め込みは直接比較可能で、テキスト埋め込みと画像埋め込みの距離は、そのテキストがその画像をどれだけ適切に説明しているか(またはその逆)に比例します。
これは、マルチモーダル情報検索とゼロショット画像分類において非常に有用であることが証明されています。特別な追加学習なしに、CLIP は自然言語ラベルを使用して画像をカテゴリーに分類することができました。

オリジナルの CLIP のテキスト埋め込みモデルは、わずか 6300 万パラメータのカスタムニューラルネットワークでした。画像側では、OpenAI はResNet とViT モデルの選択肢と共に CLIP をリリースしました。各モデルは個々のモダリティに対して事前学習され、その後キャプション付き画像を使用して学習され、用意された画像-テキストペアに対して類似の埋め込みを生成するようになりました。
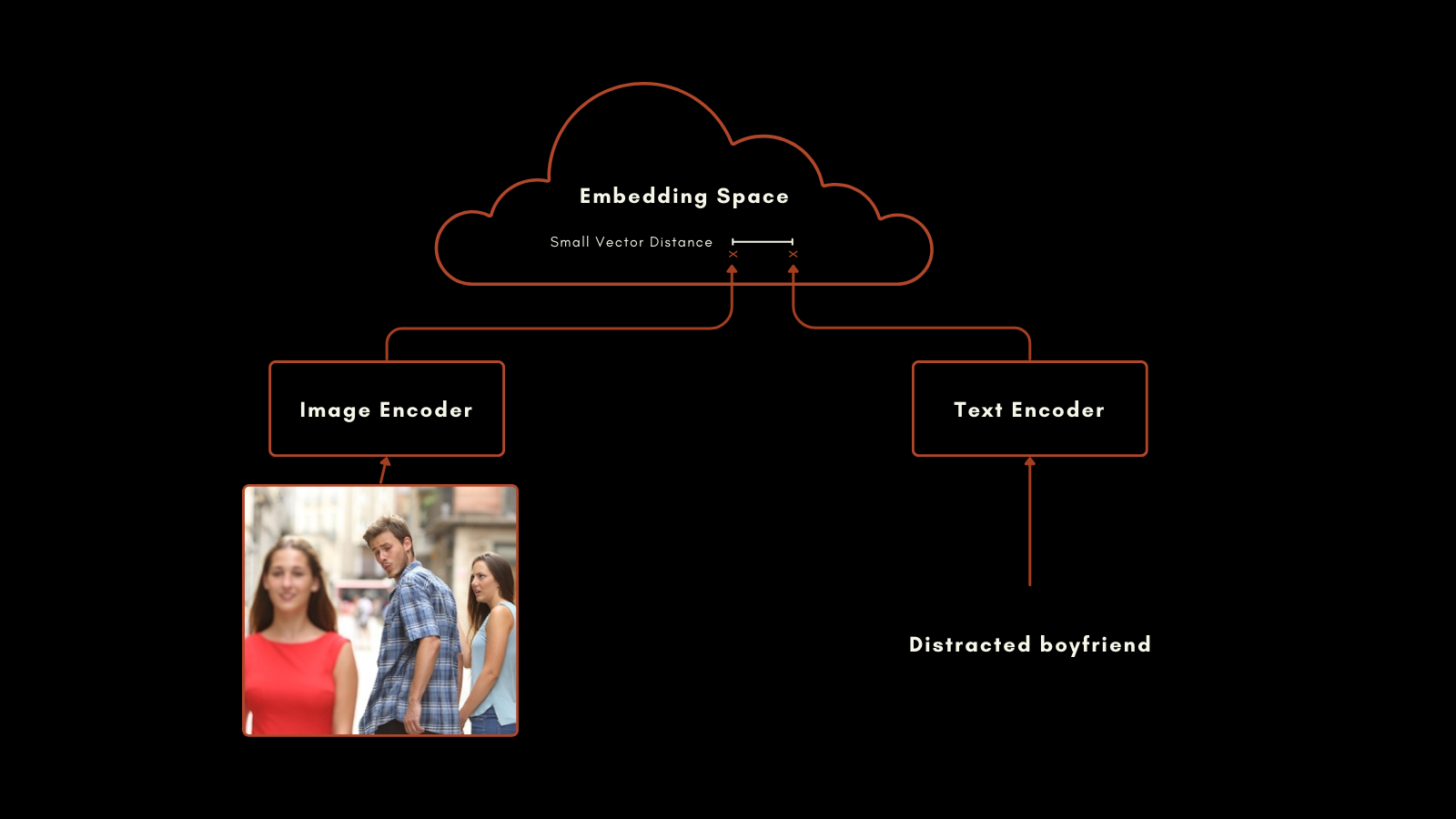
このアプローチは印象的な結果を生み出しました。特に注目すべきはそのゼロショット分類性能です。例えば、学習データに宇宙飛行士のラベル付き画像が含まれていなかったにもかかわらず、CLIP はテキストと画像における関連概念の理解に基づいて宇宙飛行士の写真を正しく識別することができました。
しかし、OpenAI の CLIP には 2 つの重要な欠点があります:
- 1 つ目は、テキスト入力容量が非常に限られていることです。最大 77 トークンの入力を受け付けますが、実証的分析によると、実際には埋め込みを生成するために 20 トークン以上は使用していません。これは CLIP が画像のキャプションから学習されており、キャプションは通常非常に短いためです。これは数千トークンをサポートする現在のテキスト埋め込みモデルとは対照的です。
- 2 つ目は、テキストのみの検索シナリオにおけるテキスト埋め込みの性能が非常に低いことです。画像キャプションは非常に限られた種類のテキストであり、テキスト埋め込みモデルに期待される広範なユースケースを反映していません。
ほとんどの実際のユースケースでは、テキストのみと画像-テキストの検索が組み合わされているか、少なくとも両方のタスクが利用可能です。テキストのみのタスク用に 2 つ目の埋め込みモデルを維持することは、AI フレームワークのサイズと複雑さを実質的に 2 倍にします。
Jina AI の新しいモデルはこれらの問題に直接対処し、jina-clip-v1 は過去数年間の進歩を活用して、テキストと画像のモダリティのあらゆる組み合わせを含むタスクに最先端の性能をもたらします。
tagJina CLIP v1 の紹介
Jina CLIP v1 は、OpenAI のオリジナル CLIP のスキーマを維持しています:同じ埋め込み空間で出力を生成するように共同学習された 2 つのモデルです。
テキストエンコーディングには、Jina Embeddings v2 モデルで使用されているJina BERT v2 アーキテクチャを適応させました。このアーキテクチャは最先端の 8k トークン入力ウィンドウをサポートし、768 次元のベクトルを出力し、より長いテキストからより正確な埋め込みを生成します。これはオリジナルの CLIP モデルでサポートされている 77 トークン入力の 100 倍以上です。
画像埋め込みには、北京人工知能研究院の最新モデル:EVA-02 モデルを使用しています。我々は多数の画像 AI モデルを実証的に比較し、同様の事前学習でクロスモーダルコンテキストでテストしましたが、EVA-02 は他のモデルを明確に上回りました。また、モデルサイズが Jina BERT アーキテクチャと同等であり、画像とテキストの処理タスクの計算負荷がほぼ同じになっています。
これらの選択は、ユーザーに重要な利点をもたらします:
- すべてのベンチマークとすべてのモーダルの組み合わせでより良い性能を発揮し、特にテキストのみの埋め込み性能が大幅に向上。
EVA-02の画像-テキストおよび画像のみのタスクにおける実証的に優れた性能に加え、Jina AI の追加学習による画像のみの性能向上という利点。- より長いテキスト入力のサポート。Jina Embeddings の 8k トークン入力サポートにより、詳細なテキスト情報を処理し、画像と相関付けることが可能。
- このマルチモーダルモデルは非マルチモーダルシナリオでも高性能であるため、スペース、計算、コード保守、複雑さの大幅な節約が可能。
tag学習
高性能なマルチモーダル AI を実現するための我々のレシピの一部は、学習データと手順にあります。画像キャプションで使用されるテキストの長さが非常に短いことが、CLIP スタイルのモデルでテキストのみの性能が低い主な原因であることに気付き、我々の学習はこれを明示的に改善するように設計されています。
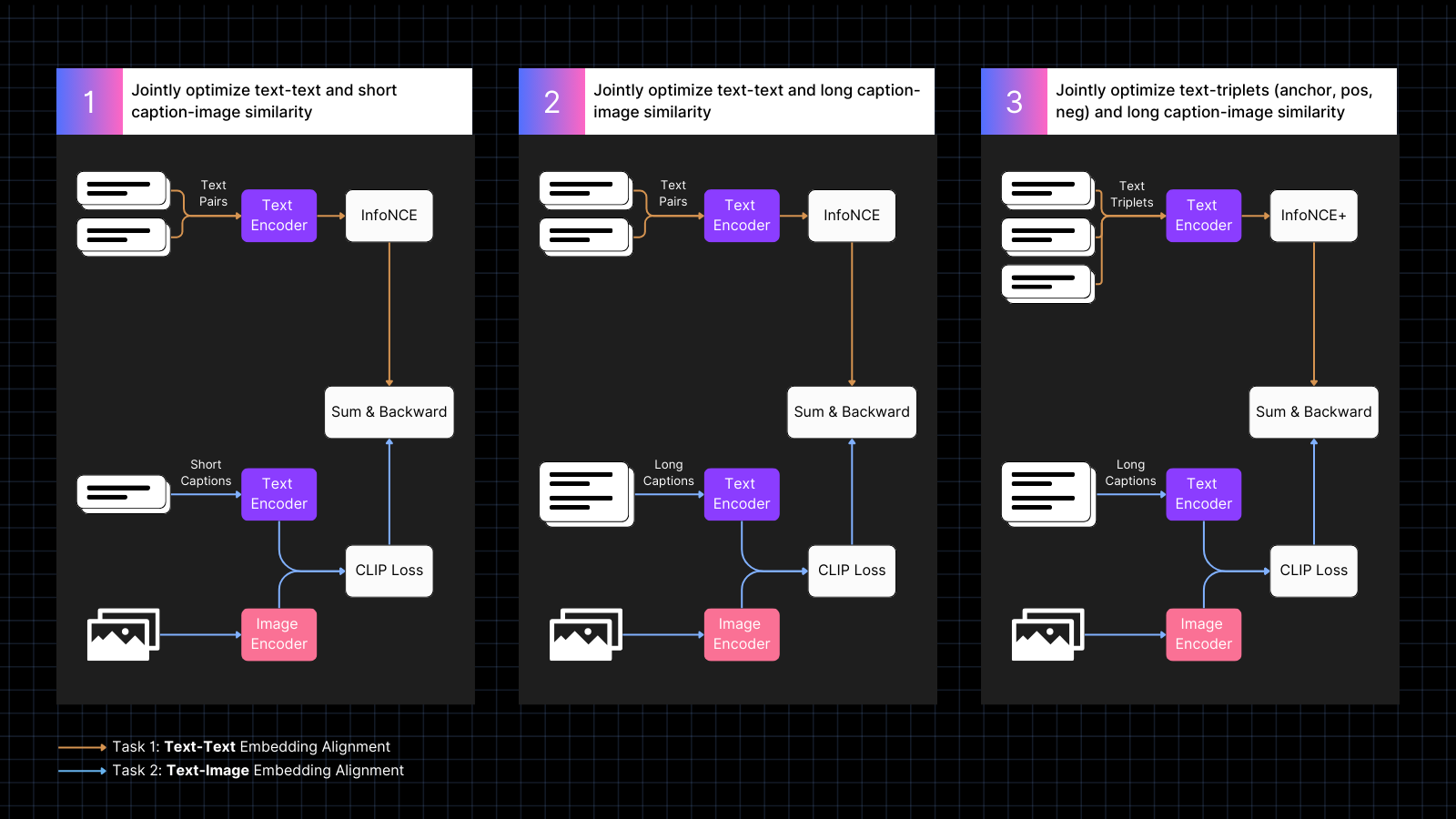
学習は 3 つのステップで行われます:
- キャプション付き画像データを使用して画像とテキストの埋め込みを整列させることを学習し、同時に類似の意味を持つテキストペアを組み合わせます。この共同学習は、2 種類のタスクを同時に最適化します。この段階でモデルのテキストのみの性能は低下しますが、画像-テキストペアのみで学習した場合ほどは低下しません。
- AI モデルによって生成された、画像をより詳細に説明する大きなテキストと画像を整列させる合成データを使用して学習します。同時にテキストのみのペアでの学習も継続します。この段階で、モデルは画像と組み合わせてより大きなテキストに注目することを学習します。
- ハードネガティブを持つテキストトリプレットを使用して、より細かい意味的区別を学習することでテキストのみの性能をさらに改善します。同時に、画像と長いテキストの合成ペアを使用した学習を継続します。この段階で、モデルは画像-テキストの能力を失うことなく、テキストのみの性能が劇的に向上します。
学習とモデルアーキテクチャの詳細については、我々の最新論文をお読みください:
tagマルチモーダル埋め込みにおける最新の成果
私たちは Jina CLIP v1 の性能を、テキストのみ、画像のみ、およびその両方の入力モダリティを含むクロスモーダルタスクにわたって評価しました。テキストのみの性能評価には MTEB 検索ベンチマーク を使用しました。画像のみのタスクには CIFAR-100 ベンチマークを使用しました。クロスモーダルタスクでは、CLIP Benchmark に含まれる Flickr8k、Flickr30K、および MSCOCO Captions で評価を行いました。
結果は以下の表にまとめられています:
| Model | Text-Text | Text-to-Image | Image-to-Text | Image-Image |
|---|---|---|---|---|
| jina-clip-v1 | 0.429 | 0.899 | 0.803 | 0.916 |
| openai-clip-vit-b16 | 0.162 | 0.881 | 0.756 | 0.816 |
| % increase vs OpenAI CLIP |
165% | 2% | 6% | 12% |
これらの結果から、jina-clip-v1 は OpenAI の元の CLIP をすべてのカテゴリーで上回り、特にテキストのみと画像のみの検索で大幅に優れていることがわかります。全カテゴリーの平均で、性能が 46% 向上しています。
より詳細な評価については、私たちの最新の論文をご覧ください。
tagEmbeddings API を使い始める
Jina Embeddings API を使用して、Jina CLIP v1 を簡単にアプリケーションに統合できます。
以下のコードは、Python の requests パッケージを使用して API を呼び出し、テキストと画像の埋め込みを取得する方法を示しています。テキスト文字列と画像の URL を Jina AI サーバーに渡し、両方のエンコーディングを返します。
<YOUR_JINA_AI_API_KEY> を有効な Jina API キーに置き換えることを忘れないでください。Jina Embeddings ウェブページから 100 万トークンの無料トライアルキーを取得できます。import requests
import numpy as np
from numpy.linalg import norm
cos_sim = lambda a,b: (a @ b.T) / (norm(a)*norm(b))
url = 'https://api.jina.ai/v1/embeddings'
headers = {
'Content-Type': 'application/json',
'Authorization': 'Bearer <YOUR_JINA_AI_API_KEY>'
}
data = {
'input': [
{"text": "Bridge close-shot"},
{"url": "https://fastly.picsum.photos/id/84/1280/848.jpg?hmac=YFRYDI4UsfbeTzI8ZakNOR98wVU7a-9a2tGF542539s"}],
'model': 'jina-clip-v1',
'encoding_type': 'float'
}
response = requests.post(url, headers=headers, json=data)
sim = cos_sim(np.array(response.json()['data'][0]['embedding']), np.array(response.json()['data'][1]['embedding']))
print(f"Cosine text<->image: {sim}")
tag主要な LLM フレームワークとの統合
Jina CLIP v1 は既に LlamaIndex と LangChain で利用可能です:
- LlamaIndex:
MultimodalEmbeddingベースクラスでJinaEmbeddingを使用し、get_image_embeddingsまたはget_text_embeddingsを呼び出します。 - LangChain:
JinaEmbeddingsを使用し、embed_imagesまたはembed_documentsを呼び出します。
tag価格設定
テキストと画像の入力は、トークン消費量に応じて課金されます。
英語のテキストについて、実験的に計算した結果、平均して 1 単語あたり 1.1 トークンが必要となります。
画像については、224x224 ピクセルのタイルで画像を覆うのに必要なタイル数をカウントします。一部のタイルは部分的に空白かもしれませんが、同じようにカウントされます。各タイルの処理には 1,000 トークンが必要です。
例
750x500 ピクセルの画像の場合:
- 画像は 224x224 ピクセルのタイルに分割されます。
- タイル数を計算するには、ピクセル幅を 224 で割り、最も近い整数に切り上げます。
750/224 ≈ 3.35 → 4 - 高さについても同様に計算します:
500/224 ≈ 2.23 → 3
- タイル数を計算するには、ピクセル幅を 224 で割り、最も近い整数に切り上げます。
- この例で必要な総タイル数は:
4(水平)x 3(垂直)= 12 タイル - コストは 12 x 1,000 = 12,000 トークンとなります
tagエンタープライズサポート
110 億トークンの Production Deployment プランを購入するユーザーに新しい特典を導入しています。これには以下が含まれます:
- 製品チームとエンジニアリングチームとの 3 時間のコンサルテーションで、お客様の特定のユースケースと要件について話し合います。
- お客様の RAG(Retrieval-Augmented Generation)またはベクトル検索のユースケースに合わせてカスタマイズされた Python ノートブックで、Jina AI のモデルをアプリケーションに統合する方法を示します。
- アカウントエグゼクティブの割り当てと優先メールサポートにより、お客様のニーズに迅速かつ効率的に対応します。
tagHugging Face 上のオープンソース Jina CLIP v1
Jina AI はオープンソースの検索基盤にコミットしており、このモデルを Apache 2.0 ライセンスの下で無料で Hugging Face で提供しています。
このモデルをダウンロードして自身のシステムやクラウドインストールで実行するためのサンプルコードは、jina-clip-v1 の Hugging Face モデルページで見つけることができます。

tagまとめ
Jina AI の最新モデル — jina-clip-v1 — は、マルチモーダル埋め込みモデルにおける重要な進歩を表し、OpenAI の CLIP を大きく上回る性能向上を提供します。テキストのみおよび画像のみの検索タスクにおける顕著な改善と、テキストから画像および画像からテキストのタスクにおける競争力のある性能により、複雑な埋め込みのユースケースに対する有望なソリューションとなっています。
現在のところリソースの制約により、このモデルは英語のテキストのみをサポートしています。より多くの言語に対応できるよう機能拡張を進めています。
