



本日、5.7 億パラメータを持つ最先端のテキストエンベディングモデル jina-embeddings-v3 の発表を嬉しくお知らせします。**多言語**データと**長文脈**検索タスクで最高性能を達成し、最大 8192 トークンの入力長をサポートします。このモデルは、タスク特化型の Low-Rank Adaptation (LoRA) アダプターを備え、**クエリ文書検索**、**クラスタリング**、**分類**、**テキストマッチング**など様々なタスクで高品質なエンベディングを生成することができます。
MTEB English、Multilingual、LongEmbed での評価において、jina-embeddings-v3 は英語タスクで OpenAI と Cohere の最新の独自エンベディングを上回り、すべての多言語タスクで multilingual-e5-large-instruct を凌駕しています。デフォルトの出力次元は 1024 ですが、Matryoshka 表現学習(MRL)の統合により、性能を損なうことなく任意に 32 次元まで切り捨てることができます。


jina-embeddings-v2-(zh/es/de) は当社の二言語モデルスイートを指し、中国語、スペイン語、ドイツ語の単一言語および言語横断タスクのみでテストされ、他の言語は除外されています。また、openai-text-embedding-3-large と cohere-embed-multilingual-v3.0 のスコアは、これらのモデルが多言語および言語横断的な MTEB タスク全体で評価されていないため、報告していません。
baai-bge-m3 が使用する固定位置エンベディングと jina-embeddings-v2 が使用する ALiBi ベースのアプローチの両方を上回っています。2024 年 9 月 18 日のリリース時点で、jina-embeddings-v3 は**最高**の多言語モデルであり、10 億パラメータ未満のモデルの中で MTEB 英語リーダーボードで**2 位**にランクされています。v3 は合計 89 言語をサポートし、そのうち 30 言語で最高の性能を発揮します:アラビア語、ベンガル語、中国語、デンマーク語、オランダ語、英語、フィンランド語、フランス語、グルジア語、ドイツ語、ギリシャ語、ヒンディー語、インドネシア語、イタリア語、日本語、韓国語、ラトビア語、ノルウェー語、ポーランド語、ポルトガル語、ルーマニア語、ロシア語、スロバキア語、スペイン語、スウェーデン語、タイ語、トルコ語、ウクライナ語、ウルドゥー語、ベトナム語。

jina-embeddings-v2 に対して超線形的な改善を示しています。このグラフは、MTEB リーダーボードからトップ 100 のエンベディングモデルを選択し、サイズ情報のないもの(通常はクローズドソースまたは独自モデル)を除外して作成されました。明らかなトロールと判断された投稿も除外されています。さらに、最近注目を集めている LLM ベースのエンベディング(例:e5-mistral-7b-instruct)と比較すると、パラメータサイズが 71 億(12 倍大きい)で出力次元が 4096(4 倍大きい)にもかかわらず、MTEB 英語タスクでの改善がわずか 1% であるのに対し、jina-embeddings-v3 はより費用対効果の高いソリューションであり、本番環境やエッジコンピューティングにより適しています。
tagモデルアーキテクチャ
| 機能 | 説明 |
|---|---|
| Base | jina-XLM-RoBERTa |
| 基本パラメータ数 | 559M |
| LoRA使用時のパラメータ数 | 572M |
| 最大入力トークン数 | 8192 |
| 最大出力次元数 | 1024 |
| レイヤー数 | 24 |
| 語彙数 | 250K |
| 対応言語数 | 89 |
| アテンション | FlashAttention2、非使用時も動作可能 |
| プーリング | Mean pooling |
jina-embeddings-v3 のアーキテクチャは以下の図に示されています。バックボーンアーキテクチャを実装するために、XLM-RoBERTa モデルに以下の重要な修正を加えました:(1) 長文テキストシーケンスの効果的なエンコーディングの実現、(2) タスク固有のエンベッディングエンコーディングの許可、(3) 最新の技術による全体的なモデル効率の改善。元の XLM-RoBERTa トークナイザーは引き続き使用しています。jina-embeddings-v3 は 570 ミリオンのパラメータを持ち、137 ミリオンの jina-embeddings-v2 よりも大きいものの、LLM からファインチューニングされたエンベッディングモデルと比べるとはるかに小さいものとなっています。

jina-XLM-RoBERTa モデルをベースとし、4 つの異なるタスクに対して 5 つの LoRA アダプターを使用しています。jina-embeddings-v3 の主要な革新点は LoRA アダプターの使用です。4 つのタスクに対して 5 つのタスク固有の LoRA アダプターが導入されています。モデルの入力は、テキスト(埋め込む長文書)とタスクの 2 つの部分で構成されています。jina-embeddings-v3 は 4 つのタスクをサポートし、5 つのアダプターを実装しています:非対称検索タスクにおけるクエリと文書のエンベッディングのための retrieval.query と retrieval.passage、クラスタリングタスクのための separation、分類タスクのための classification、そして STS や対称検索などの意味的類似性を含むタスクのための text-matching です。LoRA アダプターは全パラメータの 3% 未満を占めるだけで、計算に対する負荷は最小限に抑えられています。
さらなるパフォーマンス向上とメモリ消費の削減のために、FlashAttention 2 の統合、アクティベーションチェックポイントのサポート、効率的な分散トレーニングのための DeepSpeed フレームワークの使用を行っています。
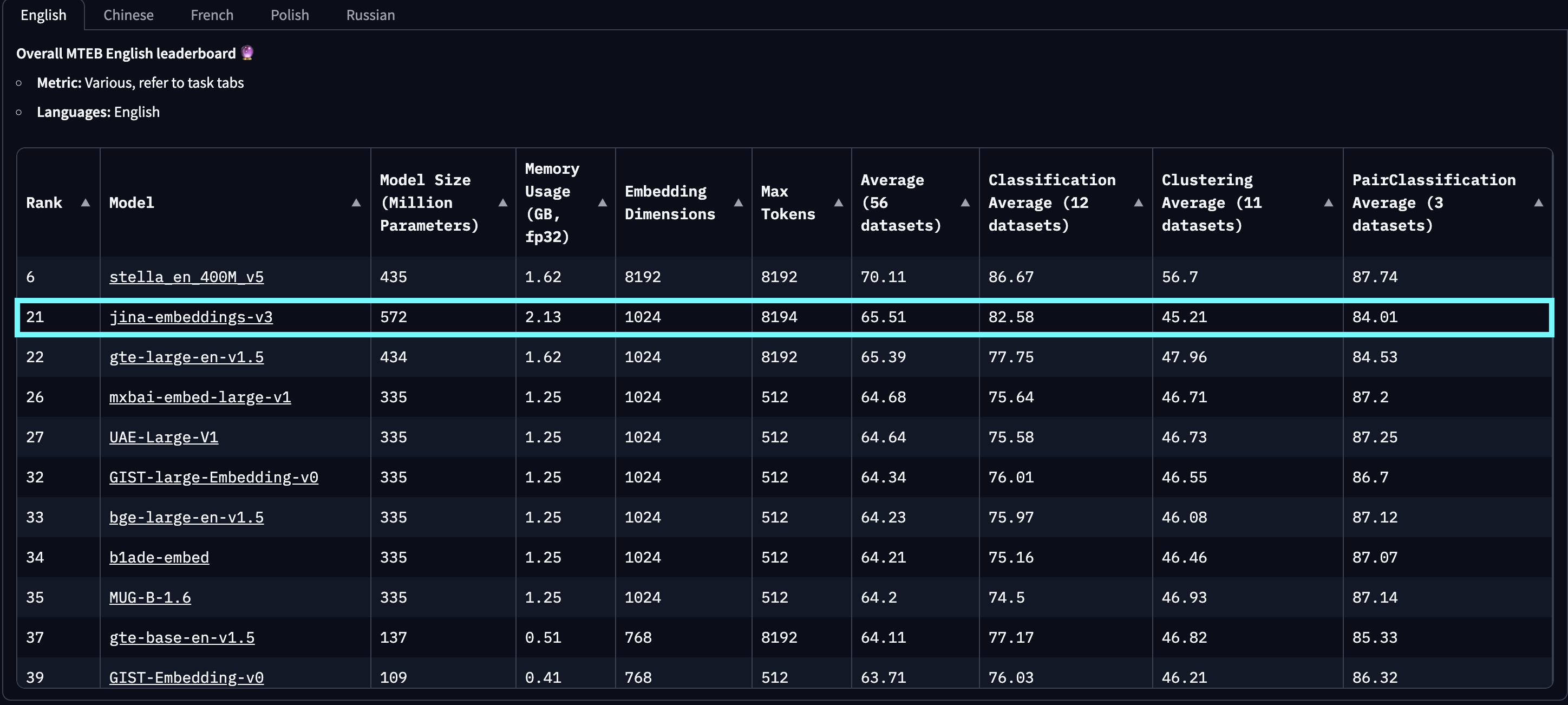
tag使用開始
tagJina AI Search Foundation API 経由
jina-embeddings-v3 を使用する最も簡単な方法は、Jina AI ホームページにアクセスし、Search Foundation API セクションに移動することです。本日より、このモデルは新規ユーザー全員のデフォルトとして設定されています。異なるパラメータや機能をそこから直接探索することができます。
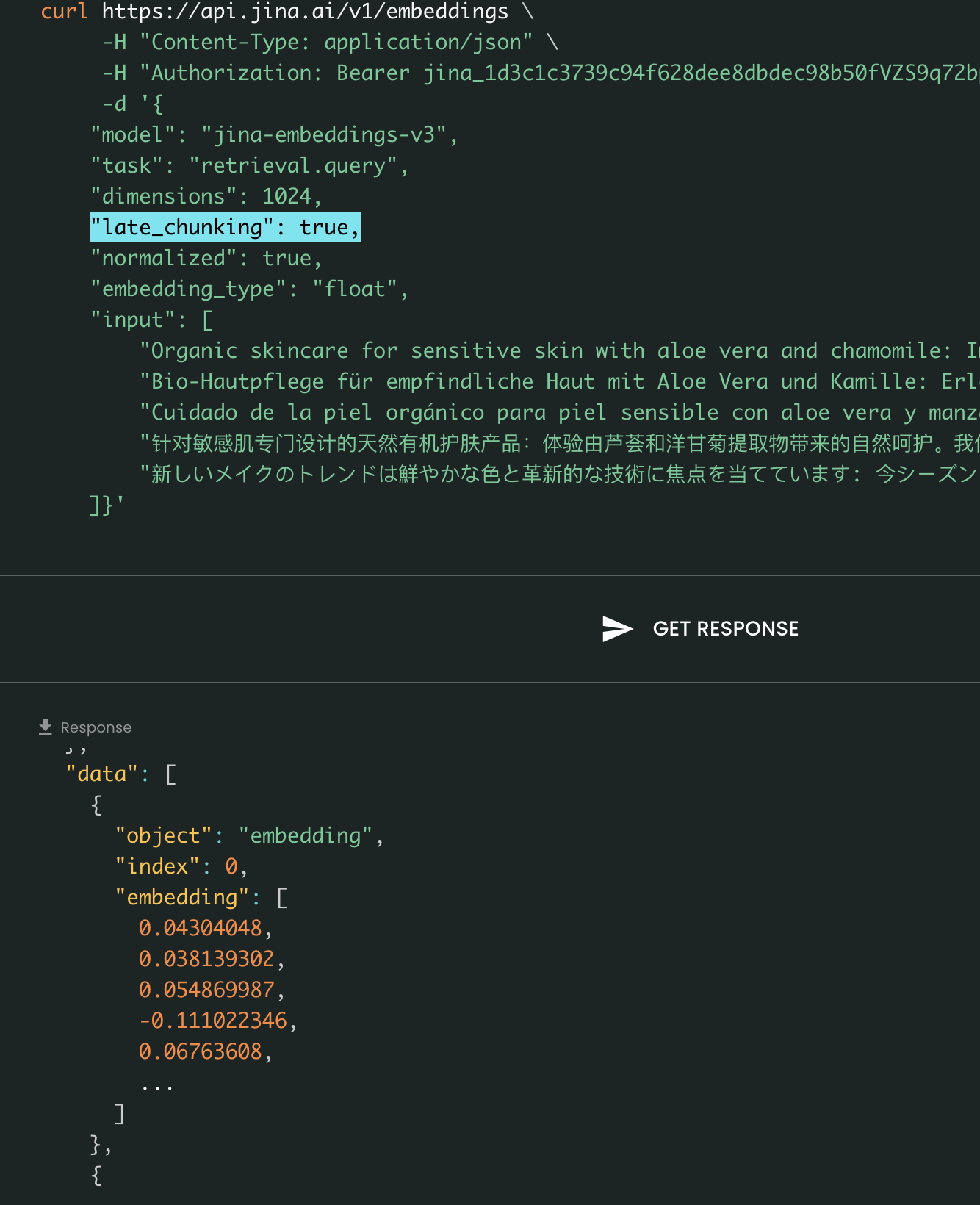
curl https://api.jina.ai/v1/embeddings \
-H "Content-Type: application/json" \
-H "Authorization: Bearer jina_387ced4ff3f04305ac001d5d6577e184hKPgRPGo4yMp_3NIxVsW6XTZZWNL" \
-d '{
"model": "jina-embeddings-v3",
"task": "text-matching",
"dimensions": 1024,
"late_chunking": true,
"input": [
"Organic skincare for sensitive skin with aloe vera and chamomile: ...",
"Bio-Hautpflege für empfindliche Haut mit Aloe Vera und Kamille: Erleben Sie die wohltuende Wirkung...",
"Cuidado de la piel orgánico para piel sensible con aloe vera y manzanilla: Descubre el poder ...",
"针对敏感肌专门设计的天然有机护肤产品:体验由芦荟和洋甘菊提取物带来的自然呵护。我们的护肤产品特别为敏感肌设计,...",
"新しいメイクのトレンドは鮮やかな色と革新的な技術に焦点を当てています: 今シーズンのメイクアップトレンドは、大胆な色彩と革新的な技術に注目しています。..."
]}'
v2 と比較して、v3 では API に task、dimensions、late_chunking という 3 つの新しいパラメータが導入されました。
パラメータ task
task パラメータは重要で、下流タスクに応じて設定する必要があります。生成されるエンベッディングはそのタスクに対して最適化されます。詳細については以下のリストを参照してください。
task の値 |
タスクの説明 |
|---|---|
retrieval.passage |
クエリ文書検索タスクにおける文書のエンベッディング |
retrieval.query |
クエリ文書検索タスクにおけるクエリのエンベッディング |
separation |
文書のクラスタリング、コーパスの可視化 |
classification |
テキスト分類 |
text-matching |
(デフォルト) 意味的テキスト類似性、一般的な対称検索、レコメンデーション、類似アイテムの検索、重複排除 |
API は汎用的なメタエンベッディングを生成してから追加のファインチューニング済み MLP で適応させるのではなく、タスク固有の LoRA アダプターを各トランスフォーマーレイヤー(合計 24 レイヤー)に挿入し、一度でエンコーディングを実行することに注意してください。詳細についてはarXiv の論文をご覧ください。
パラメータ dimensions
dimensions パラメータを使用すると、最小のコストでスペース効率とパフォーマンスのトレードオフを選択できます。jina-embeddings-v3 で使用される MRL 技術のおかげで、エンベッディングの次元を好きなだけ(1 次元まで!)削減できます。小さなエンベッディングはベクトルデータベースのストレージに優しく、そのパフォーマンスコストは以下の図から推定できます。

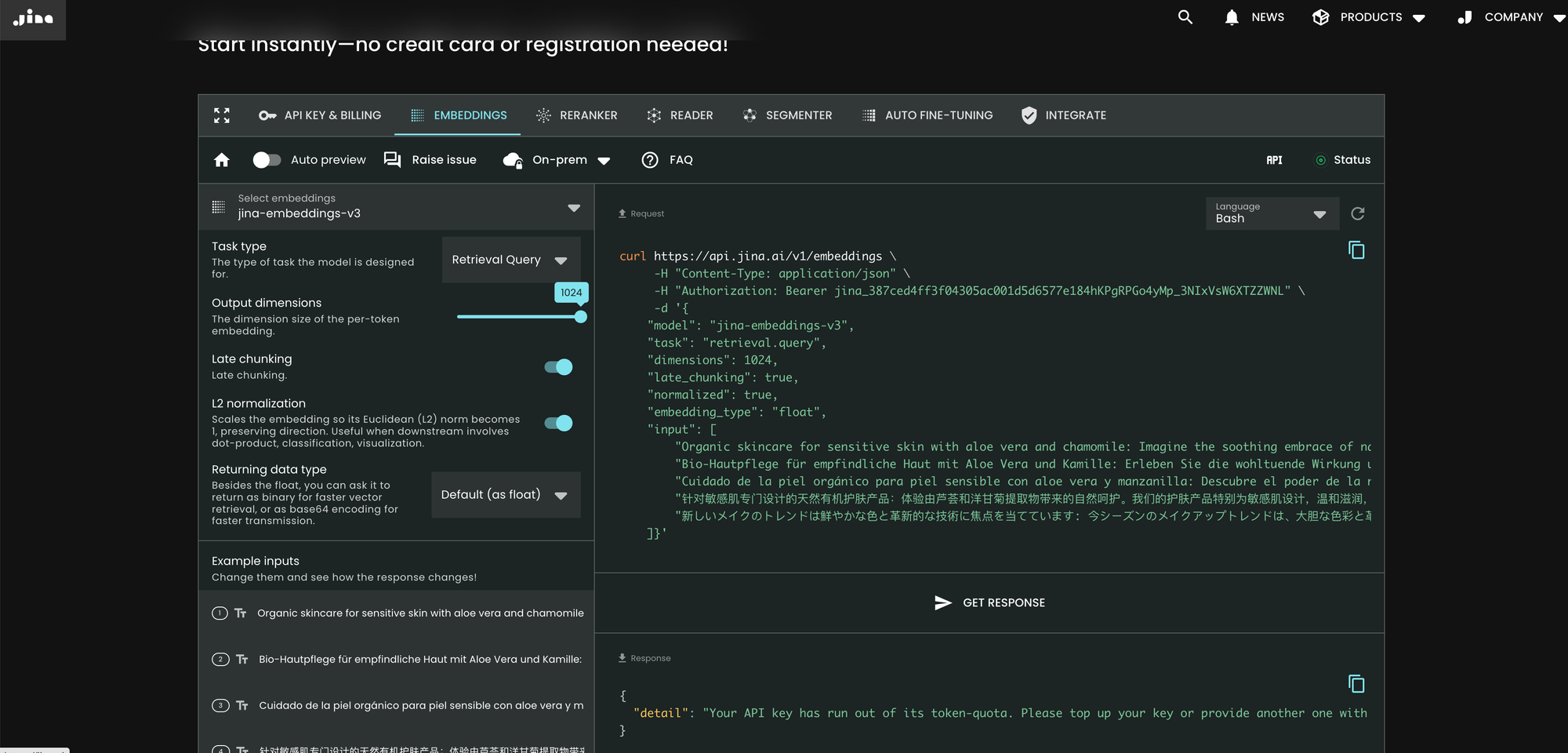
パラメータ late_chunking
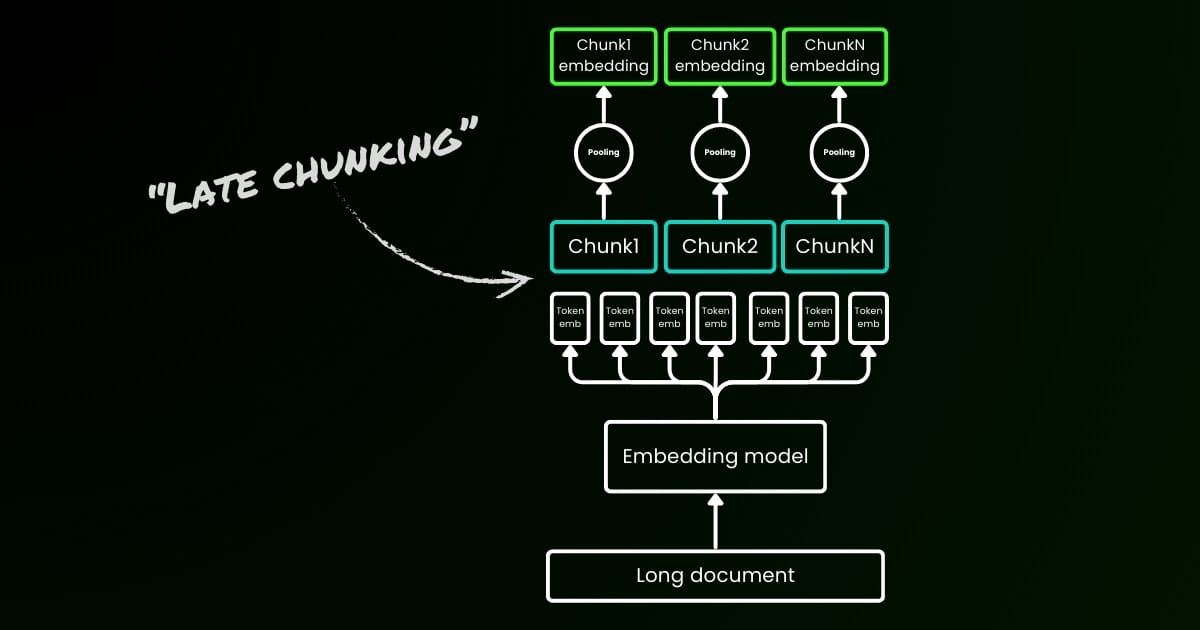
最後に、late_chunking パラメータは、先月導入した文の一括エンコーディングのための新しいチャンク分割方法を使用するかどうかを制御します。true に設定すると、API は input フィールド内のすべての文を連結し、単一の文字列としてモデルに送ります。つまり、入力内の文は同じセクション、段落、または文書から来たかのように扱われます。内部的には、モデルはこの長い連結文字列を埋め込み、その後で後処理チャンク分割を行い、入力リストのサイズに一致する埋め込みのリストを返します。したがって、リスト内の各埋め込みは前の埋め込みの影響を受けています。
ユーザーの観点からは、late_chunking の設定は入力や出力のフォーマットを変更しません。埋め込み値が、個別ではなく前のコンテキスト全体に基づいて計算されるという変化だけが見られます。使用時に知っておくべき重要なことはlate_chunking=True の場合、リクエストごとの(input のすべてのトークンを合計した)トークン総数は 8192 に制限されます。これは jina-embeddings-v3 で許可される最大コンテキスト長です。late_chunking=False の場合、そのような制限はありません。トークン総数は Embedding API のレート制限のみの対象となります。
Late Chunking のオンとオフ:入力と出力のフォーマットは同じままで、埋め込み値のみが異なります。late_chunking が有効な場合、埋め込みは input の前のコンテキスト全体の影響を受けますが、無効な場合は埋め込みは独立して計算されます。
tagAzure と AWS 経由
jina-embeddings-v3 は現在、AWS SageMaker と Azure Marketplace で利用可能です。


これらのプラットフォーム以外や、社内のオンプレミスで使用する必要がある場合は、モデルが CC BY-NC 4.0 ライセンスの下で提供されていることにご注意ください。商用利用については、お気軽にお問い合わせください。
tagベクトルデータベースとパートナー経由
私たちは Pinecone、Qdrant、Milvus などのベクトルデータベースプロバイダーや、LlamaIndex、Haystack、Dify などの LLM オーケストレーションフレームワークと密接に協力しています。リリース時点で、Pinecone、Qdrant、Milvus、Haystack が既に jina-embeddings-v3 のサポートを統合しており、task、dimensions、late_chunking という 3 つの新しいパラメータもサポートしていることをお知らせできることを嬉しく思います。v2 API との統合を既に完了している他のパートナーも、モデル名を jina-embeddings-v3 に変更するだけで v3 をサポートできるはずです。ただし、v3 で導入された新しいパラメータはまだサポートされていない可能性があります。
Pinecone 経由

Qdrant 経由

Milvus 経由

Haystack 経由

tagまとめ
2023 年 10 月、私たちは jina-embeddings-v2-base-en を公開し、世界初の 8K コンテキスト長をサポートするオープンソース埋め込みモデルとなりました。これは長いコンテキストをサポートし、OpenAI の text-embedding-ada-002 に匹敵する唯一のテキスト埋め込みモデルでした。そして今日、1 年間の学習、実験、貴重な教訓を経て、私たちは誇りを持って jina-embeddings-v3 をリリースします—これはテキスト埋め込みモデルの新しいフロンティアであり、当社の大きなマイルストーンです。
このリリースでは、私たちが得意とする長いコンテキストの埋め込みで引き続き優れた成果を上げながら、業界とコミュニティの両方から最も要望の多かった機能である多言語埋め込みにも対応しました。同時に、パフォーマンスも新たな高みへと押し上げています。タスク特化型 LoRA、MRL、late chunking など新機能により、jina-embeddings-v3 は RAG、エージェントなどのさまざまなアプリケーションの基盤となる埋め込みモデルとして真に機能すると考えています。NV-embed-v1/v2 のような最近の LLM ベースの埋め込みと比較して、私たちのモデルは非常にパラメータ効率が高く、本番環境やエッジデバイスにより適しています。
今後は、リソースの少ない言語での jina-embeddings-v3 のパフォーマンスの評価と改善、およびデータの可用性の制限によって引き起こされる体系的な失敗の分析に焦点を当てる予定です。さらに、jina-embeddings-v3 のモデルの重み、その革新的な機能、そして新しい知見は、jina-clip-v2 を含む今後のモデルの基盤として機能します。jina-reranker-v3、および reader-lm-v2。
