





本日、私たちは Jina Reranker v2(jina-reranker-v2-base-multilingual)を公開します。これは、検索基盤ファミリーにおける最新かつ最高性能のニューラルリランカーモデルです。Jina Reranker v2 により、RAG/検索システムの開発者は以下の機能を利用できます:
- 多言語対応: 100 言語以上でより関連性の高い検索結果を提供し、
bge-reranker-v2-m3を上回る性能を実現 - エージェント対応: エージェント型 RAG 向けの最先端の関数呼び出しと text-to-SQL 対応のドキュメントリランキング
- コード検索: コード検索タスクにおける最高性能
- 超高速:
bge-reranker-v2-m3の15 倍、jina-reranker-v1-base-en の 6 倍のドキュメントスループット
新規ユーザー全員に 100 万トークンを無料で提供する Reranker API を通じて、Jina Reranker v2 の利用を開始できます。

この記事では、Jina Reranker v2 でサポートされるこれらの新機能について詳しく説明し、他の最先端モデル(Jina Reranker v1 を含む)と比較したリランカーモデルの性能を示し、Jina Reranker v2 がタスクの精度とドキュメントスループットで最高性能を達成するに至った訓練プロセスについて説明します。
tag復習:なぜリランカーが必要なのか
埋め込みモデルは 検索基盤において最も広く使用され理解されているコンポーネントですが、検索の速度と引き換えに精度を犠牲にすることがよくあります。埋め込みベースの検索モデルは通常、バイエンコーダーモデルであり、各ドキュメントが埋め込まれて保存され、クエリも埋め込まれて、クエリの埋め込みとドキュメントの埋め込みの類似性に基づいて検索が行われます。このモデルでは、ユーザーのクエリとマッチしたドキュメント間のトークンレベルの相互作用の多くの微妙なニュアンスが失われます。なぜなら、元のクエリとドキュメントは互いに「見る」ことができず、埋め込みだけが見えるからです。これは検索精度を犠牲にする可能性があります - これはクロスエンコーダーリランカーモデルが優れている領域です。

リランカーは、クエリとドキュメントのペアを一緒にエンコードして埋め込みではなく関連性スコアを生成するクロスエンコーダーアーキテクチャを採用することで、この詳細な意味の欠如に対処します。研究によると、ほとんどの RAG システムにおいて、リランカーモデルの使用は意味的な根拠付けを改善し、幻覚を減少させることが示されています。
tagJina Reranker v2 による多言語サポート
かつて、Jina Reranker v1 は 4 つの主要な英語ベンチマークで最先端の性能を達成することで他と差別化を図りました。今日、私たちは Jina Reranker v2 のリランキング機能を 100 言語以上の多言語サポートと言語横断タスクで大幅に拡張しています!
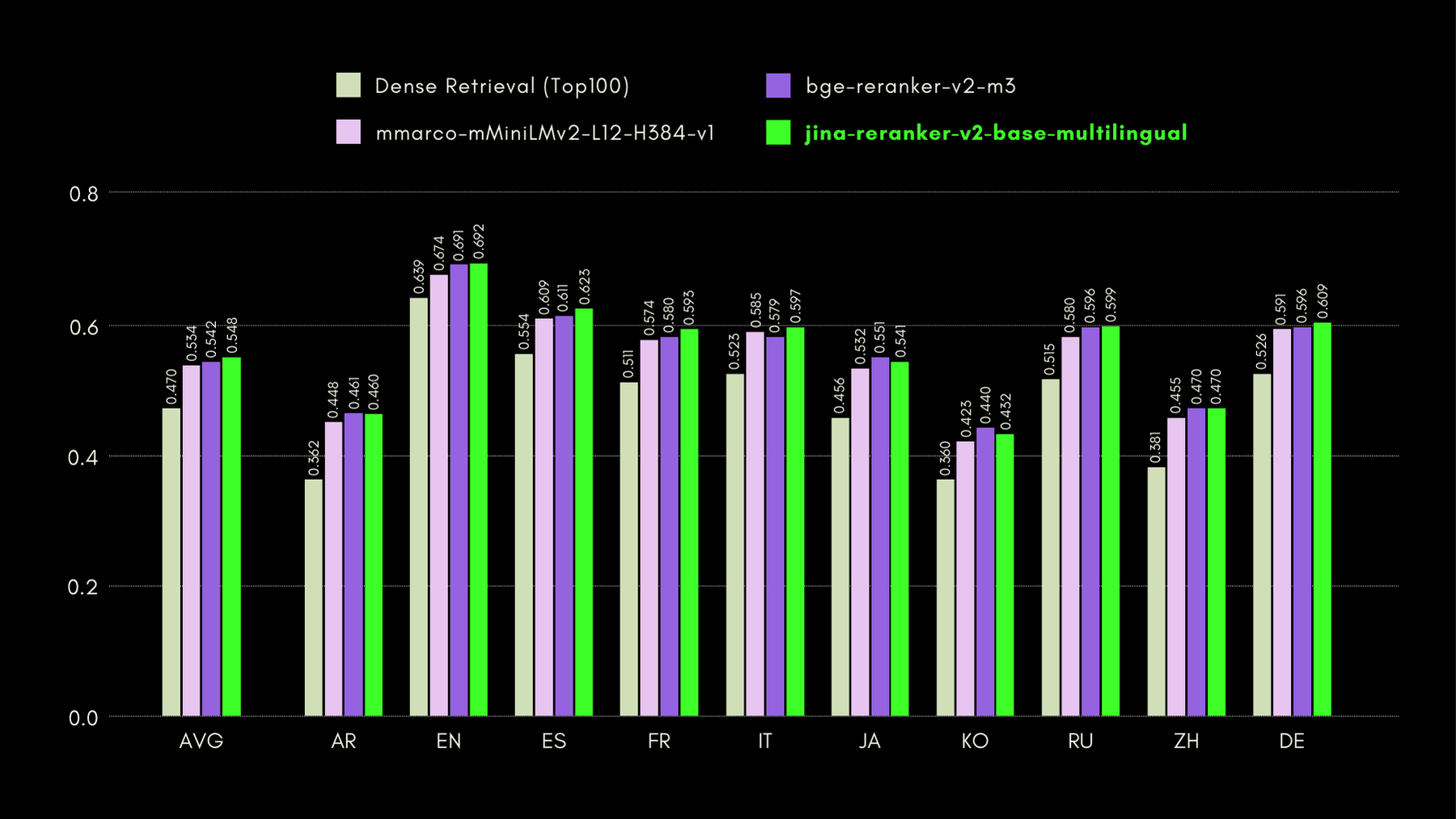
Jina Reranker v2 の言語横断および英語の性能を評価するために、以下の 3 つのベンチマークで同様のリランカーモデルと性能を比較しました:
MKQA:多言語知識質問応答
このデータセットは、実世界の知識ベースから派生した 26 言語の質問と回答で構成されており、質問応答システムの言語横断性能を評価するように設計されています。MKQA は英語のクエリとそれらの非英語言語への手動翻訳、および英語を含む複数の言語での回答で構成されています。
以下のグラフでは、従来の埋め込みベース検索を実行する「dense retriever」をベースラインとして含む、各リランカーの recall@10 スコアを報告しています:
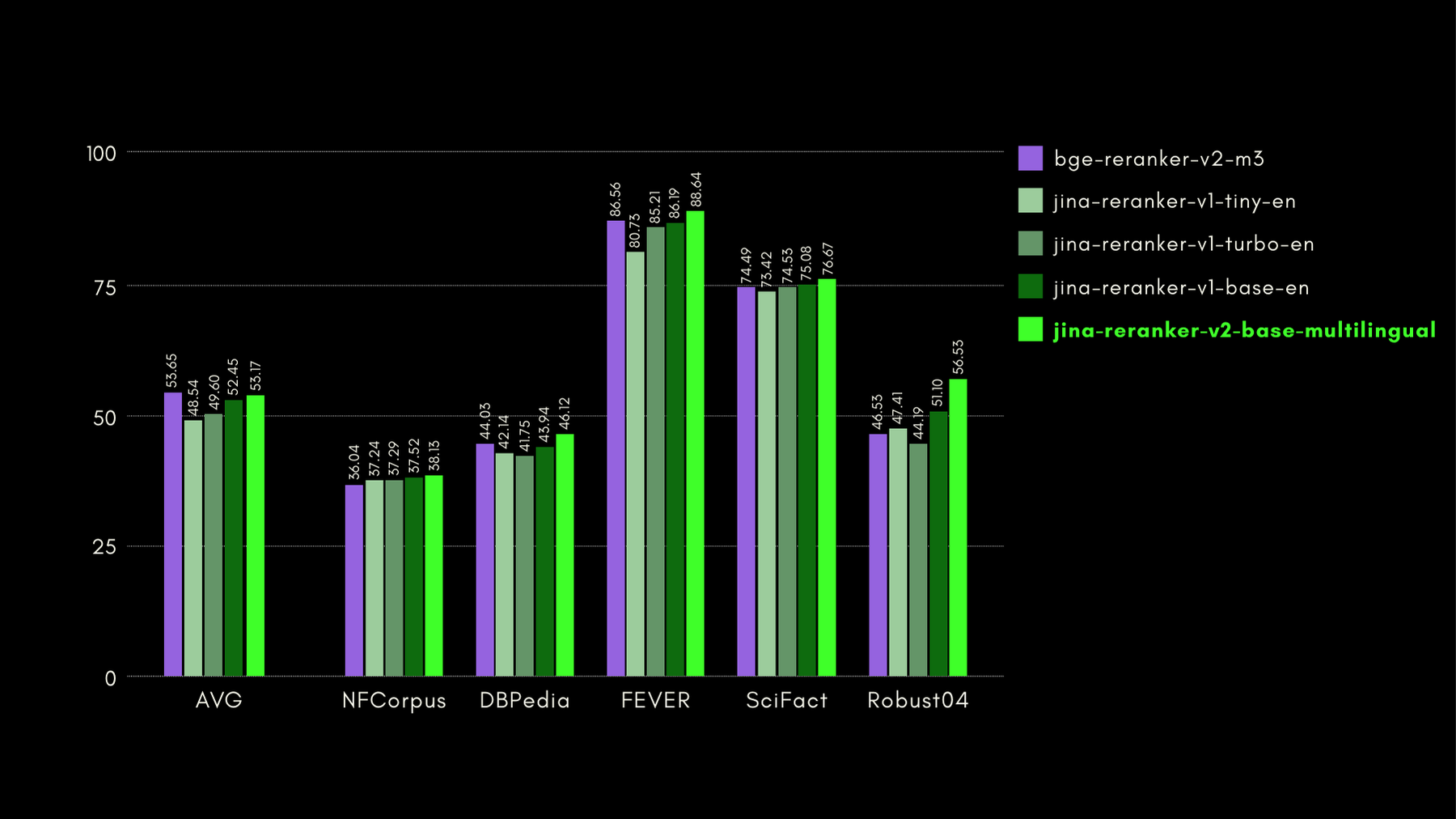
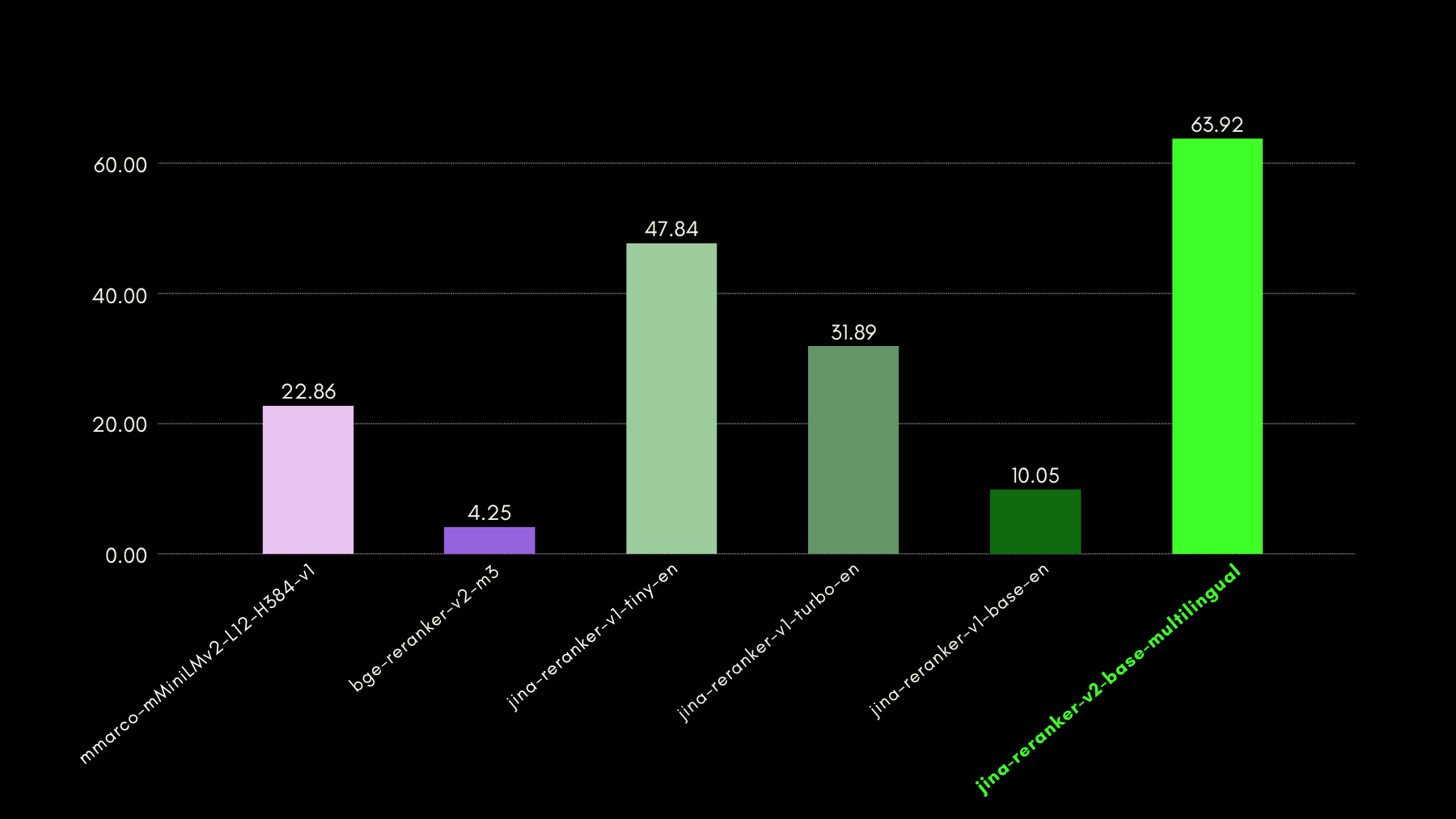
BEIR:多様な IR タスクの異種ベンチマーク
このオープンソースリポジトリには多くの言語の検索ベンチマークが含まれていますが、私たちは英語タスクのみに焦点を当てています。これらは訓練データのない 17 のデータセットで構成されており、これらのデータセットの焦点はニューラルまたは語彙的検索システムの検索精度の評価にあります。
以下のグラフでは、各リランカーを含む BEIR の NDCG@10 を報告しています。BEIR の結果は、新たに導入された jina-reranker-v2-base-multilingual の多言語機能が英語検索機能を損なわないことを明確に示しています。さらに、jina-reranker-v1-base-en と比較して大幅に改善されています。
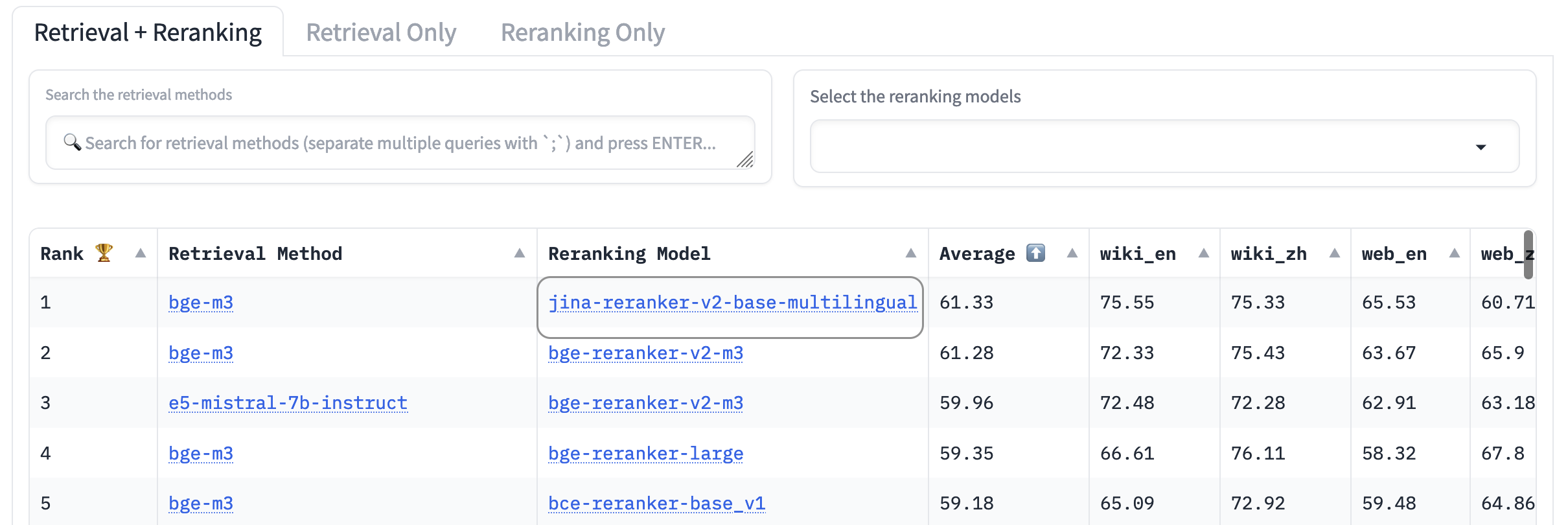
AirBench:自動異種 IR ベンチマーク
私たちは BAAI と共同で、RAG システム向けの AirBench ベンチマークを 共同作成 して公開しました。このベンチマークは、カスタムドメインとタスク向けに自動生成された合成データを使用し、ベンチマーク対象のモデルがデータセットに過適合する機会がないよう、ground truth を公開しないようにしています。
本稿執筆時点では、jina-reranker-v2-base-multilingual が他のすべての reranker モデルを上回り、リーダーボード で首位を獲得しています。
tagTooling-Agents の復習:LLM にツールの使用を教える
数年前に AI ブームが始まって以来、AI モデルがコンピュータが得意なはずの作業で十分な性能を発揮できていないことが指摘されてきました。例えば、Mistral-7b-Instruct-v0.1 との次のような会話を見てみましょう:

一見正しく見えるかもしれませんが、実際には 203 × 7724 は 1,567,972 です。
なぜ LLM は 10 倍以上の誤差を出してしまうのでしょうか?それは、LLM が数学やその他の推論を行うようには訓練されておらず、内部的な再帰性がないため、複雑な数学的問題を解くことができないからです。LLM は文章を生成したり、本質的に正確さを必要としない他のタスクを実行したりするように訓練されています。
しかし、LLM は答えを捏造することをためらいません。LLM の視点からすると、15,824,772 は 204 × 7,724 のもっともらしい答えに見えます。ただし、完全に間違っているのです。
Agentic RAG は、生成型 LLM の役割を、彼らが不得意な「思考」や「知識」から、得意な「読解力」と「情報の自然言語への統合」へと変更します。単に答えを生成するのではなく、RAG はあなたのリクエストに関連する情報を利用可能なデータソースから見つけ、言語モデルに提示します。その仕事は答えを作り出すことではなく、別のシステムが見つけた答えを自然で応答的な形で提示することです。
Jina Reranker v2 を SQL データベーススキーマとファンクションコーリングに敏感になるよう訓練しました。これには従来のテキスト検索とは異なる種類のセマンティクスが必要です。タスクとコードを認識できる必要があり、私たちの reranker はこの機能のために特別に訓練されています。
tag構造化データクエリにおける Jina Reranker v2
embedding モデルと reranker モデルは非構造化データを第一級市民として扱っていますが、ほとんどのモデルでは構造化された表形式データのサポートがまだ不十分です。
Jina Reranker v2 は、MySQL や MongoDB などの構造化データベースにクエリを実行するというダウンストリームの意図を理解し、入力クエリに対して構造化テーブルスキーマに適切な関連性スコアを割り当てます。
以下に示すように、reranker は自然言語クエリから SQL クエリを生成する前に、最も関連性の高いテーブルを取得します:
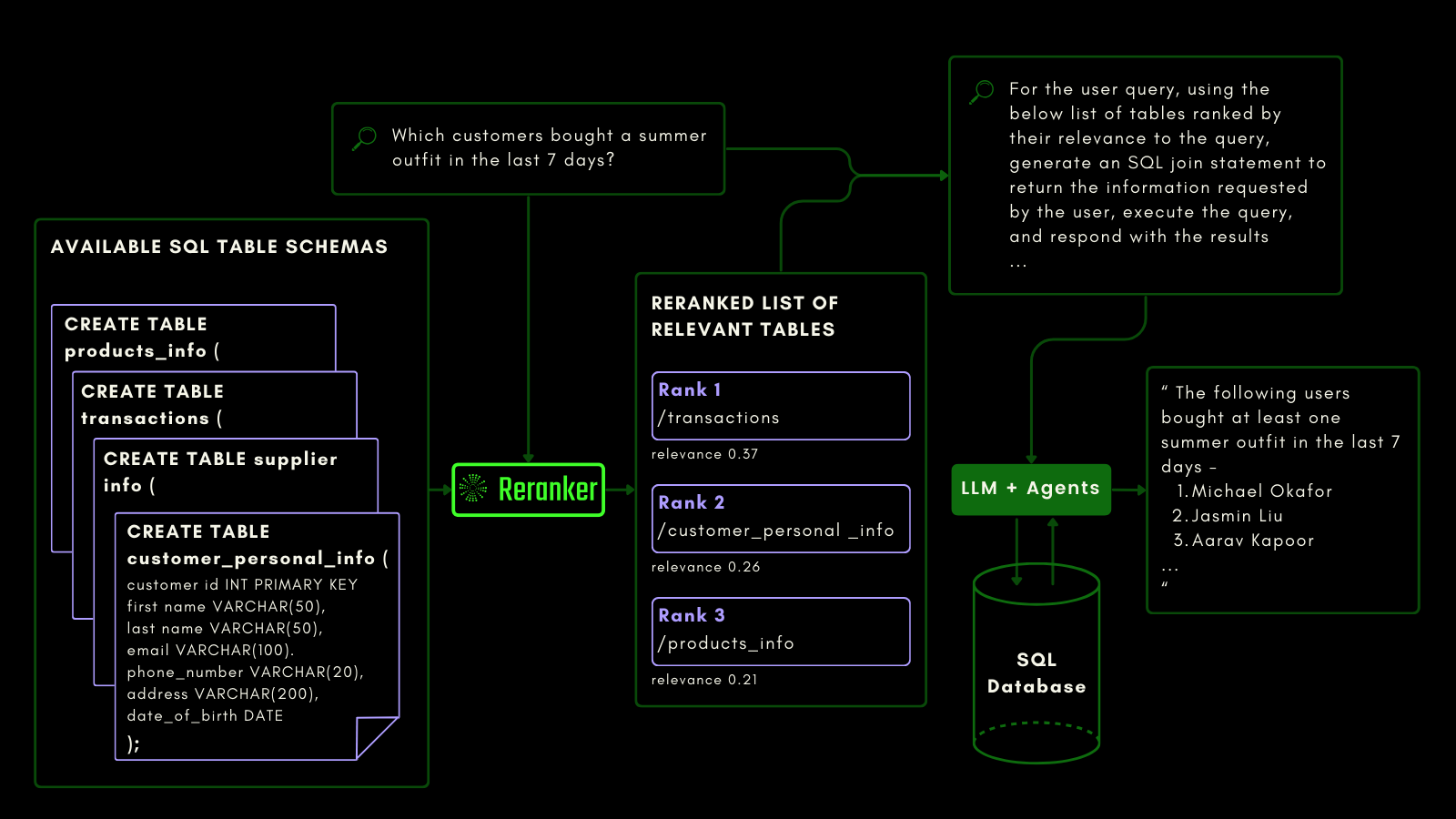
クエリ対応機能の評価には、NSText2SQL データセットベンチマークを使用しました。元のデータセットの "instruction" カラムから、自然言語で書かれた指示と対応するテーブルスキーマを抽出しています。
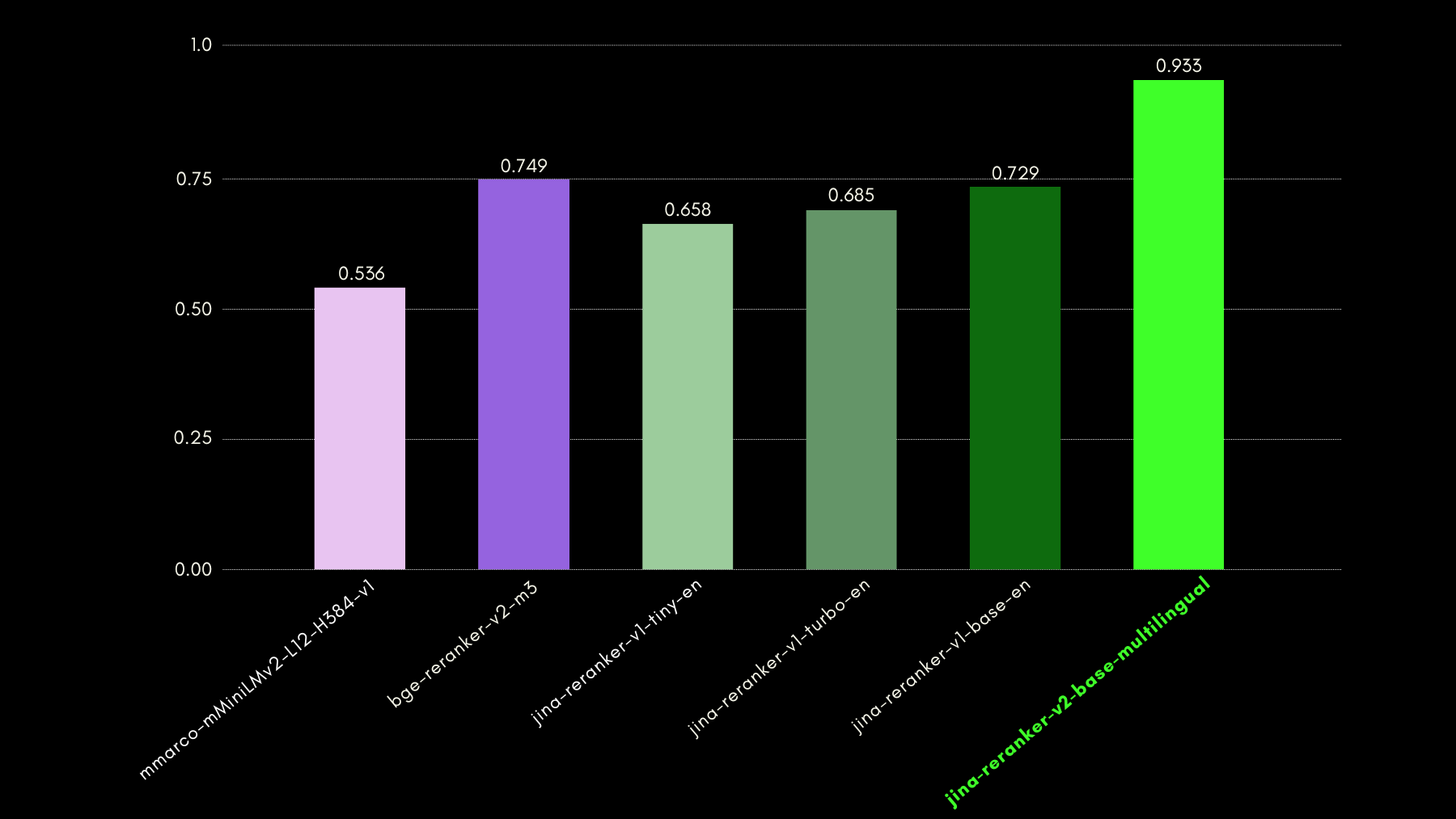
以下のグラフは、recall@3 を使用して、自然言語クエリに対応する正しいテーブルスキーマのランク付けに reranker モデルがどの程度成功しているかを比較しています。
tagファンクションコーリングにおける Jina Reranker v2
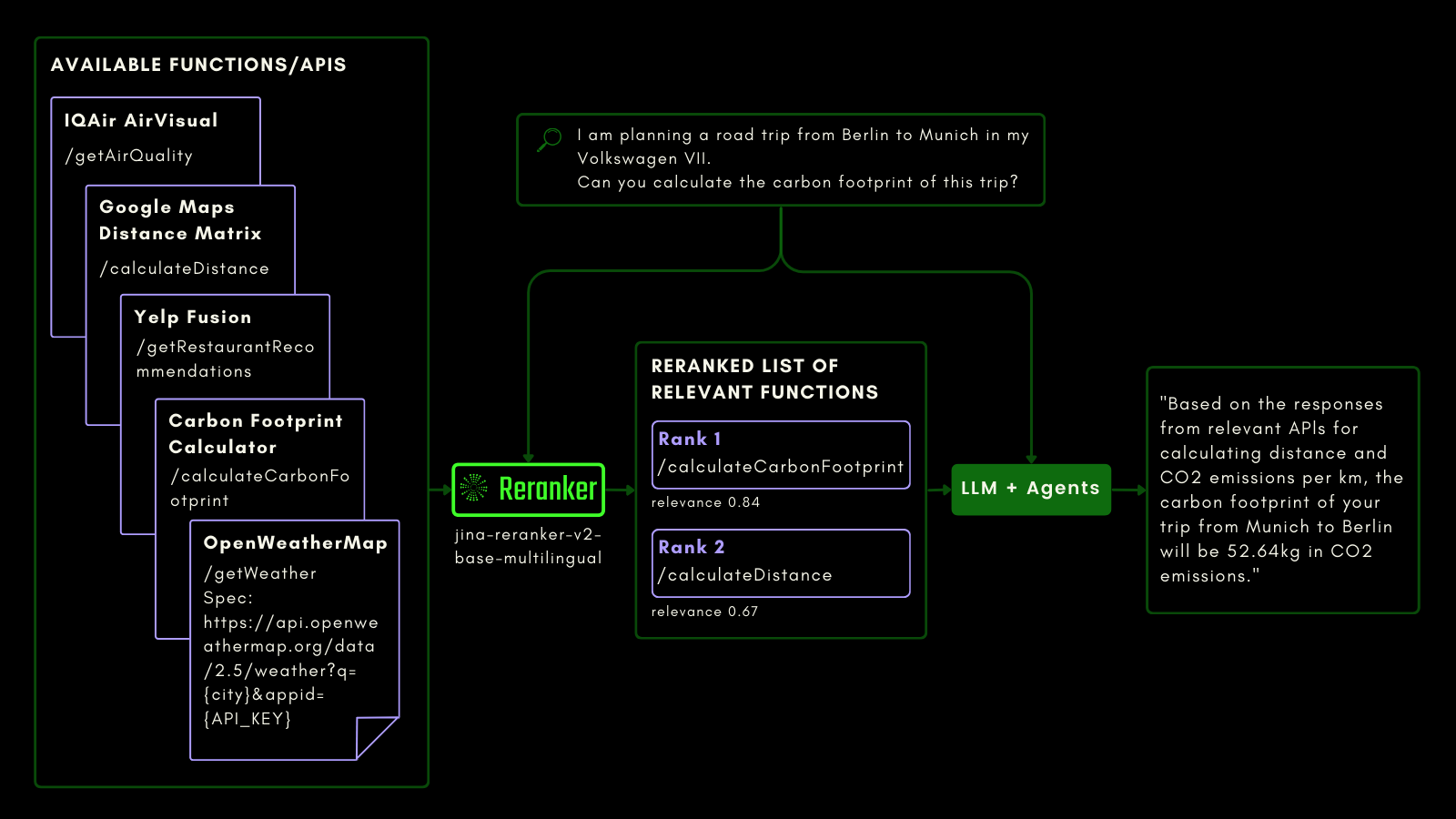
SQL テーブルへのクエリと同様に、agentic RAG を使用して外部ツールを呼び出すことができます。これを念頭に、Jina Reranker v2 にファンクションコーリングを統合し、外部関数への意図を理解し、関数仕様に対して適切な関連性スコアを割り当てることができるようにしました。
以下の概略図は(例を用いて)、LLM が Reranker を使用してファンクションコーリング機能を改善し、最終的に agentic AI のユーザーエクスペリエンスを向上させる方法を説明しています。
関数対応機能の評価には、ToolBench ベンチマークを使用しました。このベンチマークは、16,000 以上のパブリック API と、シングル API およびマルチ API 設定でそれらを使用するための合成生成された指示を収集しています。
以下が他の reranker モデルと比較した結果(recall@3 メトリック)です:
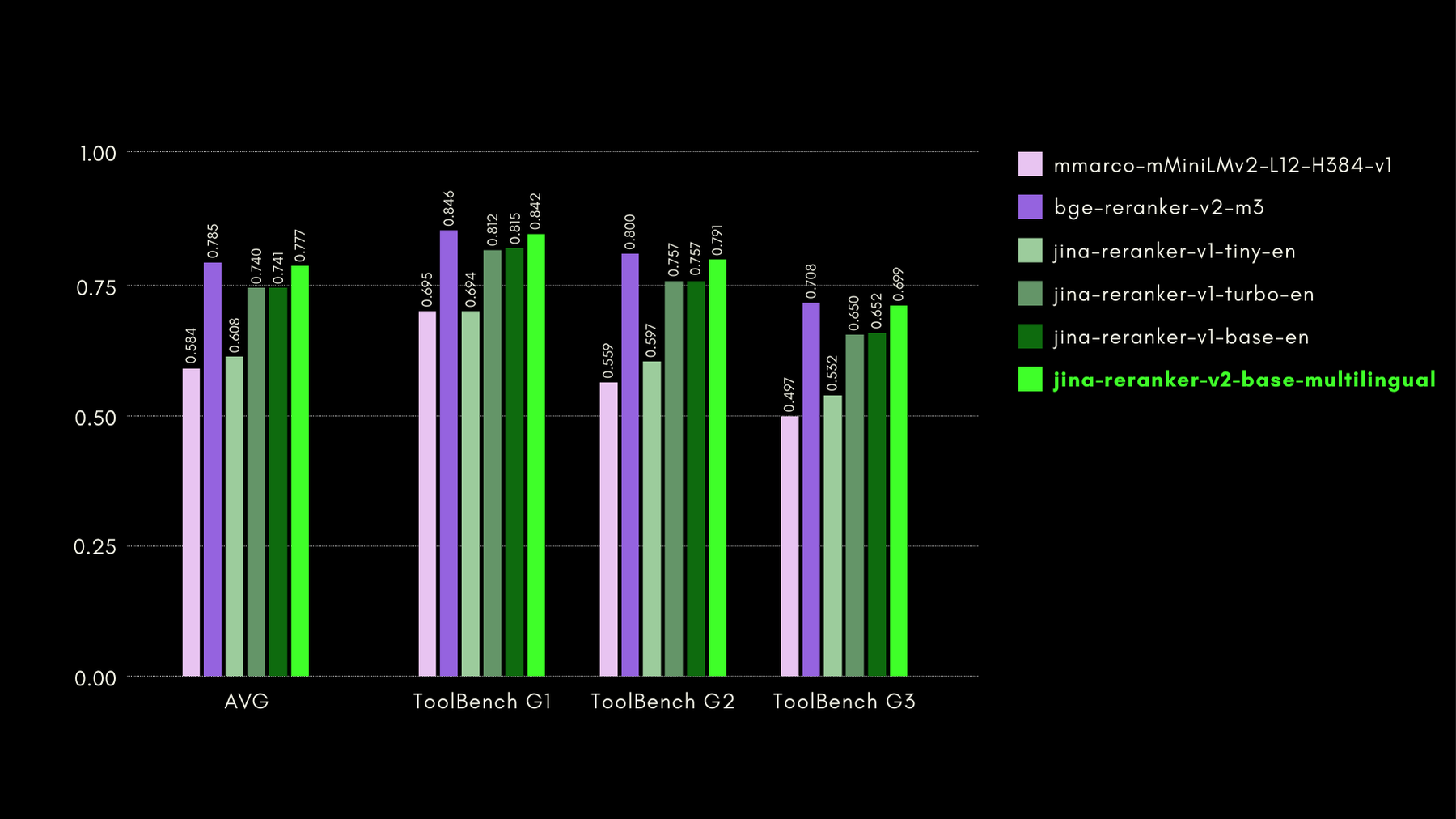
後のセクションでも示すように、jina-reranker-v2-base-multilingualは、bge-reranker-v2-m3の半分のサイズで、約15倍速いという利点を持ちながら、ほぼ最先端の性能を発揮します。
tagコード検索における Jina Reranker v2
Jina Reranker v2 は、関数呼び出しと構造化データのクエリに対して訓練されているだけでなく、同サイズの競合モデルと比較してコード検索も改善されています。コード検索能力の評価にはCodeSearchNetベンチマークを使用しました。このベンチマークは、docstring形式と自然言語形式のクエリを組み合わせたもので、クエリに関連するコードセグメントにラベル付けされています。
以下は、他のリランカーモデルと比較した MRR@10 の結果です:
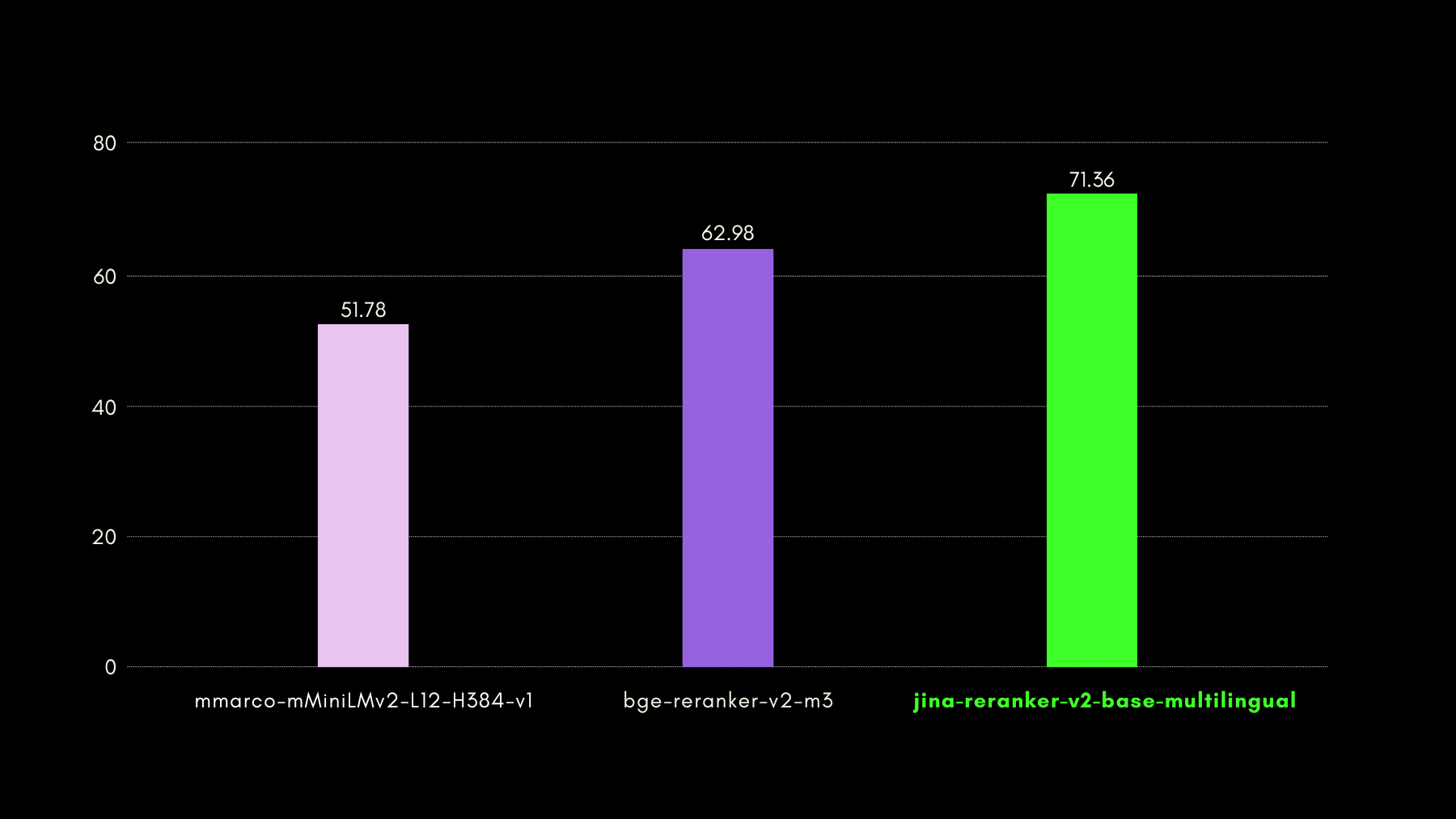
tagJina Reranker v2 による超高速推論
クロスエンコーダー型のニューラルリランカーは検索されたドキュメントの関連性予測に優れていますが、埋め込みモデルと比べて推論が遅いという特徴があります。つまり、クエリを n 個のドキュメントと一つずつ比較することは、ほとんどのベクトルデータベースにおける HNSW や他の高速検索手法と比べてはるかに遅くなります。私たちは Jina Reranker v2 でこの遅さを解決しました。
- 独自の訓練手法(後述)により、わずか 278M パラメータで最先端の精度を達成しました。
bge-reranker-v2-m3の 567M パラメータと比較すると、Jina Reranker v2 は半分のサイズです。これがスループット(50ms あたりの処理ドキュメント数)向上の第一の理由です。 - 同等のモデルサイズでも、Jina Reranker v2 は英語向けの前世代モデル Jina Reranker v1 と比べて 6 倍のスループットを誇ります。これは、トランスフォーマーベースのモデルのアテンション層にメモリと計算の最適化を導入するFlash Attention 2を実装したためです。
以上の施策の結果として、Jina Reranker v2 のスループット性能をご覧ください:
tagJina Reranker v2 の訓練方法
jina-reranker-v2-base-multilingualは 4 段階で訓練しました:
- 英語データによる準備:ペア(対照学習)またはトリプレット(クエリ、正解レスポンス、不正解レスポンス)、クエリ・関数スキーマペア、クエリ・テーブルスキーマペアを含む英語のみのデータでバックボーンモデルを訓練し、最初のバージョンを準備しました。
- クロスリンガルデータの追加:次の段階では、バックボーンモデルの多言語検索タスクにおける能力を具体的に向上させるため、クロスリンガルなペアとトリプレットのデータセットを追加しました。
- すべての多言語データの追加:この段階では、モデルができるだけ多くのデータを学習することに重点を置きました。第 2 段階のモデルチェックポイントを、100 以上の低リソース言語と高リソース言語からのすべてのペアとトリプレットデータセットでファインチューニングしました。
- マイニングされたハードネガティブによるファインチューニング:第 3 段階のリランキング性能を観察した後、既存のクエリに対するハードネガティブの例(クエリに表面的には関連しているように見えるが、実際には間違っているレスポンス)をより多く含むトリプレットデータを追加してモデルをファインチューニングしました。
この 4 段階の訓練アプローチは、訓練プロセスの早い段階で関数とテーブルのスキーマを含めることで、モデルがこれらのユースケースを特に意識し、言語構造よりも候補ドキュメントの意味論に焦点を当てることを学習できるという洞察に基づいています。
tagJina Reranker v2 の実践
tagReranker API を通じて
Jina Reranker v2 を始める最も速く簡単な方法は、Jina Reranker の APIを使用することです。
このページの API セクションに移動して、お好みのプログラミング言語で jina-reranker-v2-base-multilingual を統合してください。
例 1:関数呼び出しのランキング
最も関連性の高い外部関数/ツールのランキングを行うには、以下のようにクエリとドキュメント(関数スキーマ)をフォーマットします:
curl -X 'POST' \
'https://api.jina.ai/v1/rerank' \
-H 'accept: application/json' \
-H 'Authorization: Bearer <YOUR JINA AI TOKEN HERE>' \
-H 'Content-Type: application/json' \
-d '{
"model": "jina-reranker-v2-base-multilingual",
"query": "I am planning a road trip from Berlin to Munich in my Volkswagen VII. Can you calculate the carbon footprint of this trip?",
"documents": [
"{'\''Name'\'': '\''getWeather'\'', '\''Specification'\'': '\''Provides current weather information for a specified city'\'', '\''spec'\'': '\''https://api.openweathermap.org/data/2.5/weather?q={city}&appid={API_KEY}'\'', '\''example'\'': '\''https://api.openweathermap.org/data/2.5/weather?q=Berlin&appid=YOUR_API_KEY'\''}",
"{'\''Name'\'': '\''calculateDistance'\'', '\''Specification'\'': '\''Calculates the driving distance and time between multiple locations'\'', '\''spec'\'': '\''https://maps.googleapis.com/maps/api/distancematrix/json?origins={startCity}&destinations={endCity}&key={API_KEY}'\'', '\''example'\'': '\''https://maps.googleapis.com/maps/api/distancematrix/json?origins=Berlin&destinations=Munich&key=YOUR_API_KEY'\''}",
"{'\''Name'\'': '\''calculateCarbonFootprint'\'', '\''Specification'\'': '\''Estimates the carbon footprint for various activities, including transportation'\'', '\''spec'\'': '\''https://www.carboninterface.com/api/v1/estimates'\'', '\''example'\'': '\''{type: vehicle, distance: distance, vehicle_model_id: car}'\''}"
]
}'<YOUR JINA AI TOKEN HERE> を個人の Reranker API トークンに置き換えることを忘れないでください
結果として以下が得られるはずです:
{
"model": "jina-reranker-v2-base-multilingual",
"usage": {
"total_tokens": 383,
"prompt_tokens": 383
},
"results": [
{
"index": 2,
"document": {
"text": "{'Name': 'calculateCarbonFootprint', 'Specification': 'Estimates the carbon footprint for various activities, including transportation', 'spec': 'https://www.carboninterface.com/api/v1/estimates', 'example': '{type: vehicle, distance: distance, vehicle_model_id: car}'}"
},
"relevance_score": 0.5422876477241516
},
{
"index": 1,
"document": {
"text": "{'Name': 'calculateDistance', 'Specification': 'Calculates the driving distance and time between multiple locations', 'spec': 'https://maps.googleapis.com/maps/api/distancematrix/json?origins={startCity}&destinations={endCity}&key={API_KEY}', 'example': 'https://maps.googleapis.com/maps/api/distancematrix/json?origins=Berlin&destinations=Munich&key=YOUR_API_KEY'}"
},
"relevance_score": 0.23283305764198303
},
{
"index": 0,
"document": {
"text": "{'Name': 'getWeather', 'Specification': 'Provides current weather information for a specified city', 'spec': 'https://api.openweathermap.org/data/2.5/weather?q={city}&appid={API_KEY}', 'example': 'https://api.openweathermap.org/data/2.5/weather?q=Berlin&appid=YOUR_API_KEY'}"
},
"relevance_score": 0.05033063143491745
}
]
}例 2:SQL クエリのランク付け
同様に、クエリに対する構造化テーブルスキーマの関連スコアを取得するには、以下のような API 呼び出しの例を使用できます:
curl -X 'POST' \
'https://api.jina.ai/v1/rerank' \
-H 'accept: application/json' \
-H 'Authorization: Bearer <YOUR JINA AI TOKEN HERE>' \
-H 'Content-Type: application/json' \
-d '{
"model": "jina-reranker-v2-base-multilingual",
"query": "which customers bought a summer outfit in the past 7 days?",
"documents": [
"CREATE TABLE customer_personal_info (customer_id INT PRIMARY KEY, first_name VARCHAR(50), last_name VARCHAR(50));",
"CREATE TABLE supplier_company_info (supplier_id INT PRIMARY KEY, company_name VARCHAR(100), contact_name VARCHAR(50));",
"CREATE TABLE transactions (transaction_id INT PRIMARY KEY, customer_id INT, purchase_date DATE, FOREIGN KEY (customer_id) REFERENCES customer_personal_info(customer_id), product_id INT, FOREIGN KEY (product_id) REFERENCES products(product_id));",
"CREATE TABLE products (product_id INT PRIMARY KEY, product_name VARCHAR(100), season VARCHAR(50), supplier_id INT, FOREIGN KEY (supplier_id) REFERENCES supplier_company_info(supplier_id));"
]
}'予想される応答は:
{
"model": "jina-reranker-v2-base-multilingual",
"usage": {
"total_tokens": 253,
"prompt_tokens": 253
},
"results": [
{
"index": 2,
"document": {
"text": "CREATE TABLE transactions (transaction_id INT PRIMARY KEY, customer_id INT, purchase_date DATE, FOREIGN KEY (customer_id) REFERENCES customer_personal_info(customer_id), product_id INT, FOREIGN KEY (product_id) REFERENCES products(product_id));"
},
"relevance_score": 0.2789437472820282
},
{
"index": 0,
"document": {
"text": "CREATE TABLE customer_personal_info (customer_id INT PRIMARY KEY, first_name VARCHAR(50), last_name VARCHAR(50));"
},
"relevance_score": 0.06477169692516327
},
{
"index": 3,
"document": {
"text": "CREATE TABLE products (product_id INT PRIMARY KEY, product_name VARCHAR(100), season VARCHAR(50), supplier_id INT, FOREIGN KEY (supplier_id) REFERENCES supplier_company_info(supplier_id));"
},
"relevance_score": 0.027742892503738403
},
{
"index": 1,
"document": {
"text": "CREATE TABLE supplier_company_info (supplier_id INT PRIMARY KEY, company_name VARCHAR(100), contact_name VARCHAR(50));"
},
"relevance_score": 0.025516605004668236
}
]
}tagRAG/LLM フレームワーク経由
Jina Reranker の既存の LLM および RAG オーケストレーションフレームワークとの統合は、モデル名 jina-reranker-v2-base-multilingual を使用することで、すでに動作するはずです。それぞれのドキュメントページを参照して、アプリケーションで Jina Reranker v2 を統合する方法について詳しく学んでください。
- Haystack by deepset:Jina Reranker v2 は、Haystack の JinaRanker クラスで使用できます:
from haystack import Document
from haystack_integrations.components.rankers.jina import JinaRanker
docs = [Document(content="Paris"), Document(content="Berlin")]
ranker = JinaRanker(model="jina-reranker-v2-base-multilingual", api_key="<YOUR JINA AI API KEY HERE>")
ranker.run(query="City in France", documents=docs, top_k=1)
- LlamaIndex:Jina Reranker v2 は JinaRerank node postprocessor モジュールとして以下のように初期化して使用できます:
import os
from llama_index.postprocessor.jinaai_rerank import JinaRerank
jina_rerank = JinaRerank(model="jina-reranker-v2-base-multilingual", api_key="<YOUR JINA AI API KEY HERE>", top_n=1)
- Langchain:既存のアプリケーションで Jina Reranker 2 を使用するために Jina Rerank 統合を利用できます。JinaRerank モジュールは適切なモデル名で初期化する必要があります:
from langchain_community.document_compressors import JinaRerank
reranker = JinaRerank(model="jina-reranker-v2-base-multilingual", jina_api_key="<YOUR JINA AI API KEY HERE>")
tagHuggingFace 経由
研究および評価目的で、jina-reranker-v2-base-multilingual モデルを Hugging Face で(CC-BY-NC-4.0 ライセンスの下で)公開しています。

Hugging Face からモデルをダウンロードして実行するには、transformers と einops ライブラリをインストールしてください:
pip install transformers einops
pip install ninja
pip install flash-attn --no-build-isolation
Hugging Face アクセストークンを使用して、Hugging Face CLI ログインを通じて Hugging Face アカウントにログインします:
huggingface-cli login --token <"HF-Access-Token">
事前学習済みモデルをダウンロードします:
from transformers import AutoModelForSequenceClassification
model = AutoModelForSequenceClassification.from_pretrained(
'jinaai/jina-reranker-v2-base-multilingual',
torch_dtype="auto",
trust_remote_code=True,
)
model.to('cuda') # GPU が利用できない場合は 'cpu' を使用
model.eval()
クエリと再ランク付けする文書を定義します:
query = "Organic skincare products for sensitive skin"
documents = [
"Organic skincare for sensitive skin with aloe vera and chamomile.",
"New makeup trends focus on bold colors and innovative techniques",
"Bio-Hautpflege für empfindliche Haut mit Aloe Vera und Kamille",
"Neue Make-up-Trends setzen auf kräftige Farben und innovative Techniken",
"Cuidado de la piel orgánico para piel sensible con aloe vera y manzanilla",
"Las nuevas tendencias de maquillaje se centran en colores vivos y técnicas innovadoras",
"针对敏感肌专门设计的天然有机护肤产品",
"新的化妆趋势注重鲜艳的颜色和创新的技巧",
"敏感肌のために特別に設計された天然有機スキンケア製品",
"新しいメイクのトレンドは鮮やかな色と革新的な技術に焦点を当てています",
]
文章のペアを構築し、関連性スコアを計算します:
sentence_pairs = [[query, doc] for doc in documents]
scores = model.compute_score(sentence_pairs, max_length=1024)
スコアは浮動小数点数のリストとなり、各浮動小数点数はクエリに対する対応する文書の関連性スコアを表します。スコアが高いほど関連性が高いことを意味します。
または、rerank 関数を使用して、max_query_length に基づいてクエリと文書を自動的にチャンク分割することで、大きなテキストの再ランク付けを行うことができます。
max_length でそれぞれ指定します。各チャンクは個別にスコアリングされ、各チャンクのスコアが組み合わされて最終的な再ランキング結果が生成されます:results = model.rerank(
query,
documents,
max_query_length=512,
max_length=1024,
top_n=3
)
この関数は、各ドキュメントの関連性スコアだけでなく、そのコンテンツと元のドキュメントリストでの位置も返します。
tagプライベートクラウドデプロイメント経由
Jina Reranker v2 の AWS および Azure アカウント向けプライベートデプロイメント用の事前ビルドパッケージは、まもなくAWS Marketplace および Azure Marketplace の各販売者ページで公開される予定です。
tagJina Reranker v2 の主なポイント
Jina Reranker v2 は、検索基盤の機能を大幅に拡張します:
- クロスエンコーディングを使用した最先端の検索により、幅広い新しいアプリケーション領域が開かれます。
- 多言語および言語間機能が強化され、ユースケースの言語の壁がなくなります。
- ファンクションコーリングの最高レベルのサポートと構造化データクエリの認識により、エージェント RAG 機能の精度が向上します。
- コンピュータコードやコンピュータ形式のデータの検索が向上し、テキスト情報検索を超えた機能を提供します。
- ドキュメントのスループットが大幅に向上し、検索方法に関係なく、より多くの検索されたドキュメントをより高速に再ランク付けでき、きめ細かな関連性計算のほとんどを jina-reranker-v2-base-multilingual に任せることができます。
Reranker v2 により RAG システムの精度が大幅に向上し、既存の情報管理ソリューションがより多くの、より良いアクション可能な結果を生成できるようになります。言語間サポートにより、これらすべての機能が多国籍・多言語企業向けに直接利用可能となり、使いやすい API を手頃な価格で提供します。
実際のユースケースから導き出されたベンチマークでテストすることで、Jina Reranker v2 が実際のビジネスモデルに関連するタスクで最先端のパフォーマンスを維持していることを、1つの AI モデルで確認でき、コストを抑えながらテックスタックをよりシンプルに保つことができます。
