


新着!パート II:境界キューと誤解に関する詳細な解説。
約1年前の2023年10月、私たちは 世界初の8Kコンテキスト長を持つオープンソースの埋め込みモデルである jina-embeddings-v2-base-en をリリースしました。それ以来、埋め込みモデルにおける長文コンテキストの有用性について多くの議論がありました。多くのアプリケーションにおいて、数千語に及ぶ文書を単一の埋め込み表現にエンコードすることは理想的ではありません。多くのユースケースではテキストの小さな部分を取り出す必要があり、密ベクトルベースの検索システムは通常、より小さなテキストセグメントの方が、埋め込みベクトルに意味が「過度に圧縮」される可能性が低いため、より良いパフォーマンスを発揮します。
Retrieval-Augmented Generation(RAG)は、文書を小さなテキストチャンク(例えば512トークン以内)に分割する必要がある最もよく知られたアプリケーションの1つです。これらのチャンクは通常、テキスト埋め込みモデルによって生成されたベクトル表現とともにベクターデータベースに保存されます。実行時には、同じ埋め込みモデルがクエリをベクトル表現にエンコードし、それを使用して関連する保存済みテキストチャンクを特定します。これらのチャンクはその後、大規模言語モデル(LLM)に渡され、LLMは取得したテキストに基づいてクエリに対する応答を生成します。

要するに、より小さなチャンクの埋め込みの方が好ましいように見えます。これは下流のLLMの入力サイズが限られているためだけでなく、長いコンテキストの重要な文脈情報が単一のベクトルに圧縮されると希薄化する可能性があるという懸念もあるためです。
しかし、業界が必要とするのが512コンテキスト長の埋め込みモデルだけなら、8192コンテキスト長のモデルを訓練する意味は何なのでしょうか?
この記事では、RAGにおける素朴なチャンク分割-埋め込みパイプラインの限界を探ることで、この重要ではあるが不快な質問を再検討します。私たちは「Late Chunking」と呼ばれる新しいアプローチを紹介します。これは、8192長の埋め込みモデルが提供する豊富な文脈情報を活用して、より効果的にチャンクを埋め込む方法です。
tag文脈の消失問題
チャンク分割-埋め込み-検索-生成という単純なRAGパイプラインには課題がありません。具体的には、このプロセスは長距離の文脈依存関係を破壊する可能性があります。言い換えれば、関連する情報が複数のチャンクに分散している場合、テキストセグメントを文脈から切り離すと効果が失われる可能性があり、このアプローチは特に問題となります。
下の画像では、Wikipediaの記事が文単位でチャンクに分割されています。「its」や「the city」といったフレーズが、最初の文でのみ言及されている「Berlin」を参照していることがわかります。これにより、埋め込みモデルがこれらの参照を正しいエンティティにリンクすることが難しくなり、結果としてベクトル表現の品質が低下します。

つまり、上の例のように長い記事を文単位のチャンクに分割した場合、RAGシステムは「ベルリンの人口は?」といったクエリに答えるのが困難になる可能性があります。都市名と人口が単一のチャンク内に一緒に現れることがなく、より大きな文書の文脈がないため、LLMはこれらのチャンクの1つを提示されても、「it」や「the city」といった照応参照を解決することができません。
この問題を緩和するためのヒューリスティックがいくつかあります。スライディングウィンドウによる再サンプリング、複数のコンテキストウィンドウ長の使用、文書の複数回スキャンなどです。しかし、すべてのヒューリスティックと同様に、これらのアプローチは当たり外れがあります。場合によっては機能するかもしれませんが、その効果に理論的な保証はありません。
tag解決策:Late Chunking
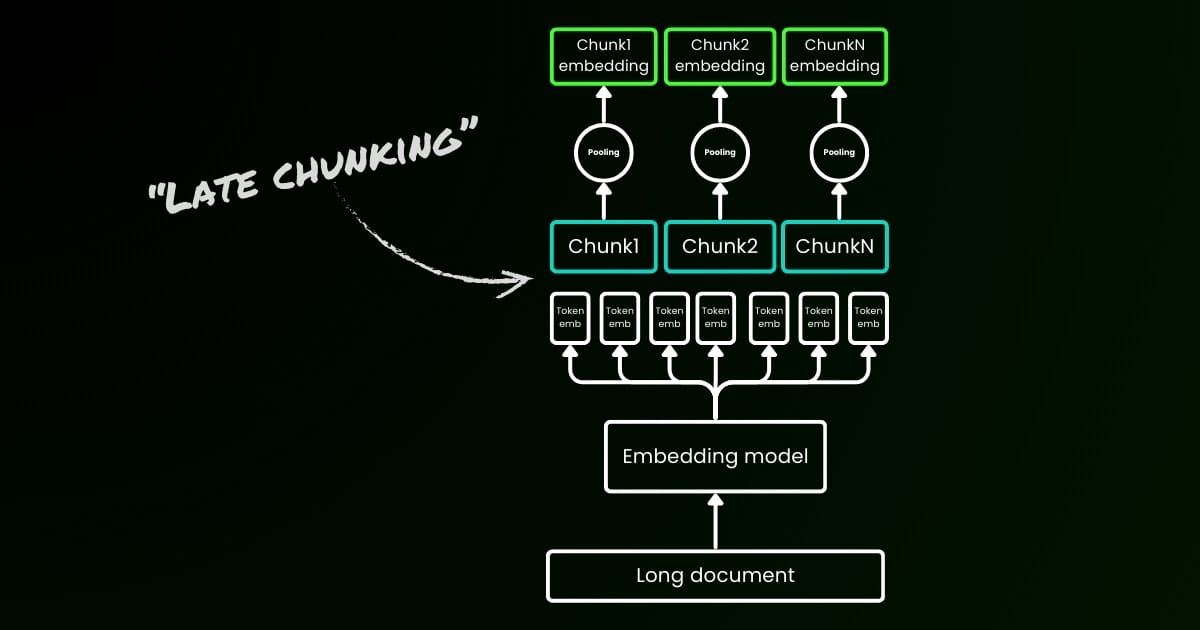
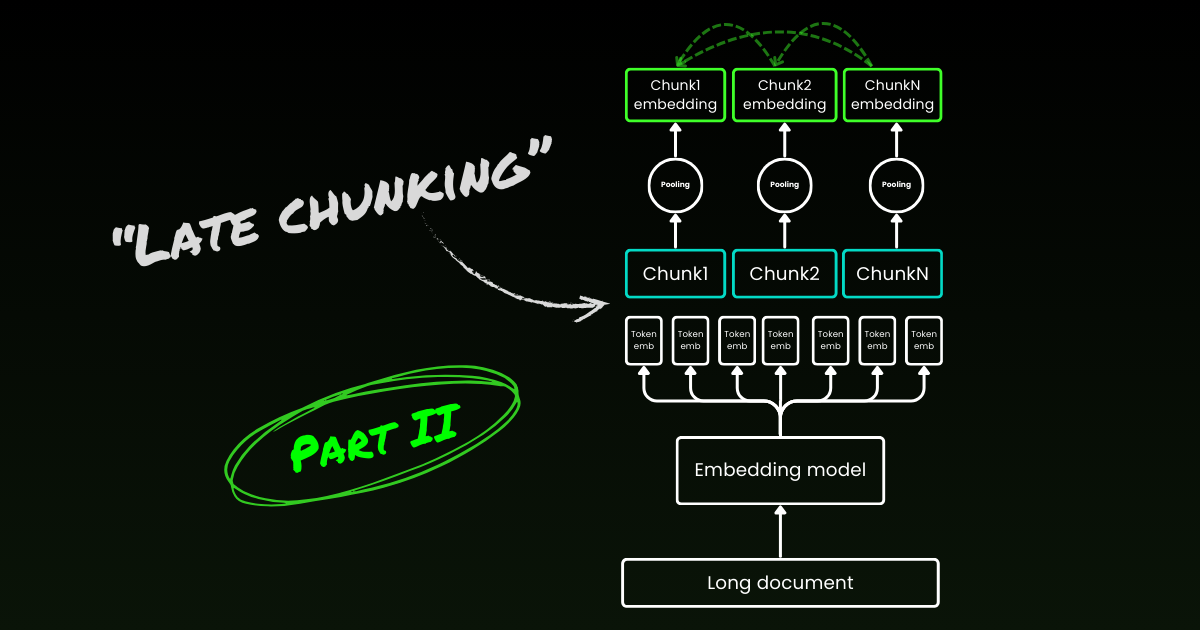
素朴なエンコーディングアプローチ(下の画像の左側)では、文、段落、または最大長の制限を使用して事前にテキストを分割します。その後、埋め込みモデルがこれらの結果として得られたチャンクに繰り返し適用されます。各チャンクの単一の埋め込みを生成するために、多くの埋め込みモデルはこれらのトークンレベルの埋め込みに平均プーリングを使用して、単一の埋め込みベクトルを出力します。

対照的に、この記事で提案する「Late Chunking」アプローチでは、まず埋め込みモデルのトランスフォーマー層をテキスト全体、あるいは可能な限り多くのテキストに適用します。これにより、テキスト全体からの情報を含む各トークンのベクトル表現のシーケンスが生成されます。その後、このトークンベクトルのシーケンスの各チャンクに平均プーリングを適用し、テキスト全体の文脈を考慮した各チャンクの埋め込みを生成します。独立同分布(i.i.d.)のチャンク埋め込みを生成する素朴なエンコーディングアプローチとは異なり、Late Chunkingは前のチャンクに「条件付けられた」チャンク埋め込みのセットを作成し、それによって各チャンクにより多くの文脈情報をエンコードします。
明らかにLate Chunkingを効果的に適用するには、jina-embeddings-v2-base-enのような長文コンテキスト埋め込みモデルが必要です。このモデルは最大8192トークン(標準的な10ページ分のテキストに相当)をサポートします。このサイズのテキストセグメントでは、さらに長いコンテキストを必要とする文脈依存関係が存在する可能性は低くなります。
重要な点として、Late Chunkingでも境界キューは必要ですが、これらのキューはトークンレベルの埋め込みを取得した後にのみ使用されます—そのため名前に「Late」が付いています。
| 素朴なチャンク分割 | Late Chunking | |
|---|---|---|
| 境界キューの必要性 | あり | あり |
| 境界キューの使用 | 前処理で直接 | トランスフォーマー層からトークンレベルの埋め込みを取得した後 |
| 結果として得られるチャンク埋め込み | i.i.d. | 条件付き |
| 近隣チャンクの文脈情報 | 失われる。一部のヒューリスティック(オーバーラップサンプリングなど)で緩和 | 長文コンテキスト埋め込みモデルによって十分に保持 |
tag実装と定性的評価


Late Chunkingの実装は上のGoogle Colabで確認できます。ここでは、可能なすべての境界キューを活用して長い文書を意味のあるチャンクに分割する、Tokenizer APIの最新機能リリースを利用しています。この機能の背後にあるアルゴリズムについての詳しい議論はXで見つけることができます。

上記の Wikipedia の例に Late Chunking を適用すると、意味的類似性が即座に改善されることがわかります。例えば、Wikipedia 記事内の「the city」と「Berlin」の場合、「the city」を表すベクトルには「Berlin」の以前の言及とリンクする情報が含まれるため、その都市名に関するクエリにとってはるかに適切なマッチとなります。
| Query | Chunk | Sim. on naive chunking | Sim. on late chunking |
|---|---|---|---|
| Berlin | Berlin is the capital and largest city of Germany, both by area and by population. | 0.849 | 0.850 |
| Berlin | Its more than 3.85 million inhabitants make it the European Union's most populous city, as measured by population within city limits. | 0.708 | 0.825 |
| Berlin | The city is also one of the states of Germany, and is the third smallest state in the country in terms of area. | 0.753 | 0.850 |
上記の数値結果で、「Berlin」という用語の埋め込みと、コサイン類似度を使用した Berlin に関する記事からの様々な文との比較を確認できます。「Sim. on IID chunk embeddings」列は、事前チャンキングを使用した「Berlin」のクエリ埋め込みとの類似度値を示し、「Sim. under contextual chunk embedding」は Late Chunking 手法での結果を表しています。
tagBEIR での定量的評価
Late Chunking の有効性をトイ例以外で検証するため、BeIR の検索ベンチマークの一部を使用してテストしました。これらの検索タスクは、クエリセット、テキストドキュメントのコーパス、各クエリに関連するドキュメントの ID 情報を格納する QRels ファイルで構成されています。
クエリに関連するドキュメントを特定するために、ドキュメントはチャンク分割され、埋め込みインデックスにエンコードされ、k-最近傍(kNN)を使用して各クエリ埋め込みに最も類似したチャンクが決定されます。各チャンクはドキュメントに対応しているため、チャンクの kNN ランキングをドキュメントの kNN ランキングに変換できます(ランキングに複数回出現するドキュメントは最初の出現のみを保持)。この結果のランキングを Ground-truth の QRels ファイルが提供するランキングと比較し、nDCG@10 などの検索メトリクスを計算します。この手順は以下に示されており、評価スクリプトは再現性のためにこのリポジトリで見つけることができます。
 jina-ai
jina-ai私たちは様々な BeIR データセットでこの評価を実行し、ナイーブチャンキングと Late Chunking 手法を比較しました。境界手がかりを得るために、テキストを約 256 トークンの文字列に分割する正規表現を使用しました。ナイーブチャンキングと Late Chunking の両方の評価で、埋め込みモデルとして jina-embeddings-v2-small-en を使用しました。これは v2-base-en モデルの小型バージョンですが、8192 トークンまでの長さをサポートしています。結果は以下の表の通りです。
| Dataset | Avg. Document Length (characters) | Naive Chunking (nDCG@10) | Late Chunking (nDCG@10) | No Chunking (nDCG@10) |
|---|---|---|---|---|
| SciFact | 1498.4 | 64.20% | 66.10% | 63.89% |
| TRECCOVID | 1116.7 | 63.36% | 64.70% | 65.18% |
| FiQA2018 | 767.2 | 33.25% | 33.84% | 33.43% |
| NFCorpus | 1589.8 | 23.46% | 29.98% | 30.40% |
| Quora | 62.2 | 87.19% | 87.19% | 87.19% |
すべてのケースで、Late Chunking はナイーブなアプローチと比較してスコアを改善しました。いくつかの場合では、ドキュメント全体を単一の埋め込みにエンコードするよりも優れた性能を示しましたが、他のデータセットでは、チャンキングを全く行わない方が最良の結果を示しました(もちろん、チャンクのランキングが必要ない場合のみ、チャンキングなしが意味を持ちますが、これは実践ではまれです)。ナイーブなアプローチと Late Chunking の性能差をドキュメントの長さに対してプロットすると、ドキュメントの平均長が Late Chunking による nDCG スコアの改善度と相関していることが明らかになります。つまり、ドキュメントが長いほど、Late Chunking 戦略はより効果的になります。

tag結論
この記事では、長文脈埋め込みモデルの能力を活用して短いチャンクを埋め込む「Late Chunking」と呼ばれるシンプルなアプローチを紹介しました。従来の i.i.d. チャンク埋め込みが文脈情報を保持できず、最適ではない検索結果につながることを示し、Late Chunking が各チャンク内の文脈情報を維持し条件付けるためのシンプルかつ非常に効果的な解決策を提供することを示しました。Late Chunking の効果は長いドキュメントでより顕著になります—これは jina-embeddings-v2-base-en のような高度な長文脈埋め込みモデルによってのみ可能になった機能です。この研究が長文脈埋め込みモデルの重要性を実証するだけでなく、このトピックに関する更なる研究にも刺激を与えることを期待しています。
パート II に続く:境界手がかりと誤解についての詳細な分析。
