


Jina Embeddings と Jina Reranker が、AWS Marketplace から Amazon SageMaker で利用できるようになりました。セキュリティ、信頼性、クラウド運用の一貫性を重視する企業ユーザーにとって、これによりプライベートな AWS 環境で Jina AI の最先端 AI を利用でき、AWS の確立された安定したインフラのすべての利点を享受できます。
AWS Marketplace 上の完全な embedding モデルと reranking モデルのラインナップにより、SageMaker ユーザーは、競争力のある価格で 8k 入力コンテキストウィンドウと最高ランクの多言語 embeddings をオンデマンドで利用できます。モデルの AWS へのインポートやエクスポートに料金を支払う必要はなく、価格は透明で、請求は AWS アカウントと統合されています。
現在 Amazon SageMaker で利用可能なモデルには以下が含まれます:
- Jina Embeddings v2 Base - English
- Jina Embeddings v2 Small - English
- Jina Embeddings v2 バイリンガルモデル:
- Jina Embeddings v2 Base - Code
- Jina Reranker v1 Base - English
- Jina ColBERT v1 - English
- Jina ColBERT Reranker v1 - English
モデルの完全なリストは AWS Marketplace の Jina AI のベンダーページをご覧ください。7 日間の無料トライアルをご利用いただけます。


この記事では、Amazon SageMaker のコンポーネントのみを使用して検索拡張生成(RAG)アプリケーションを作成する方法を説明します。使用するモデルは、Jina Embeddings v2 - English、Jina Reranker v1、および Mistral-7B-Instruct 大規模言語モデルです。
Python Notebook でダウンロードするか、Google Colab で実行して、手順を追うこともできます。
tag検索拡張生成
検索拡張生成は、生成 AI における代替的なパラダイムです。大規模言語モデル(LLM)を使って学習したことを直接ユーザーのリクエストに応答するのではなく、流暢な言語生成能力を活用しながら、ロジックと情報検索を外部のより適した装置に移行します。
RAG システムは、LLM を呼び出す前に、外部のデータソースから関連情報を積極的に取得し、それをプロンプトの一部として LLM に送ります。LLM の役割は、外部情報を統合してユーザーのリクエストに対する一貫した応答を生成することであり、幻覚のリスクを最小限に抑え、結果の関連性と有用性を高めます。
RAG システムは概して少なくとも 4 つのコンポーネントを持ちます:
- データソース:通常は、AI 支援の情報検索に適したベクトルデータベース
- 情報検索システム:ユーザーのリクエストをクエリとして扱い、それに関連するデータを取得する
- システム:多くの場合、AI ベースの reranker を含み、取得したデータの一部を選択して LLM のプロンプトに処理する
- LLM:例えば GPT モデルや Mistral のようなオープンソース LLM で、ユーザーのリクエストと提供されたデータを取り、ユーザーへの応答を生成する
embedding モデルは情報検索に適しており、その目的で頻繁に使用されます。テキスト embedding モデルはテキストを入力として受け取り、embedding(高次元ベクトル)を出力します。このベクトルの空間的な関係は、意味的な類似性(つまり、類似したトピック、内容、関連する意味)を示します。embedding は、近ければ近いほどユーザーが応答に満足する可能性が高いため、情報検索でよく使用されます。また、特定のドメインでのパフォーマンスを向上させるためのファインチューニングも比較的容易です。
テキスト reranker モデルは、同様の AI 原理を使用してテキストのコレクションをクエリと比較し、意味的な類似性によってソートします。embedding モデルだけに頼るのではなく、タスク固有の reranker モデルを使用することで、検索結果の精度が劇的に向上することがよくあります。RAG アプリケーションの reranker は、LLM のプロンプトに適切な情報が含まれる確率を最大化するために、情報検索の結果の一部を選択します。

tagSageMaker エンドポイントとしての Embedding モデルのパフォーマンスベンチマーク
g4dn.xlarge インスタンスで実行される SageMaker エンドポイントとしての Jina Embeddings v2 Base - English モデルのパフォーマンスと信頼性をテストしました。これらの実験では、1 秒ごとに新しいユーザーを 1 人ずつ生成し、各ユーザーはリクエストを送信し、応答を待ち、受信後に繰り返すようにしました。
- 100 トークン未満のリクエストの場合、最大 150 人の同時ユーザーまでは、リクエストあたりの応答時間は 100ms 未満でした。その後、同時ユーザー数の増加に伴い、応答時間は 100ms から 1500ms まで線形に増加しました。
- 約 300 人の同時ユーザーで、API から 5 件以上の失敗を受信し、テストを終了しました。
- 1K から 8K トークンのリクエストの場合、最大 20 人の同時ユーザーまでは、リクエストあたりの応答時間は 8s 未満でした。その後、同時ユーザー数の増加に伴い、応答時間は 8s から 60s まで線形に増加しました。
- 約 140 人の同時ユーザーで、API から 5 件以上の失敗を受信し、テストを終了しました。
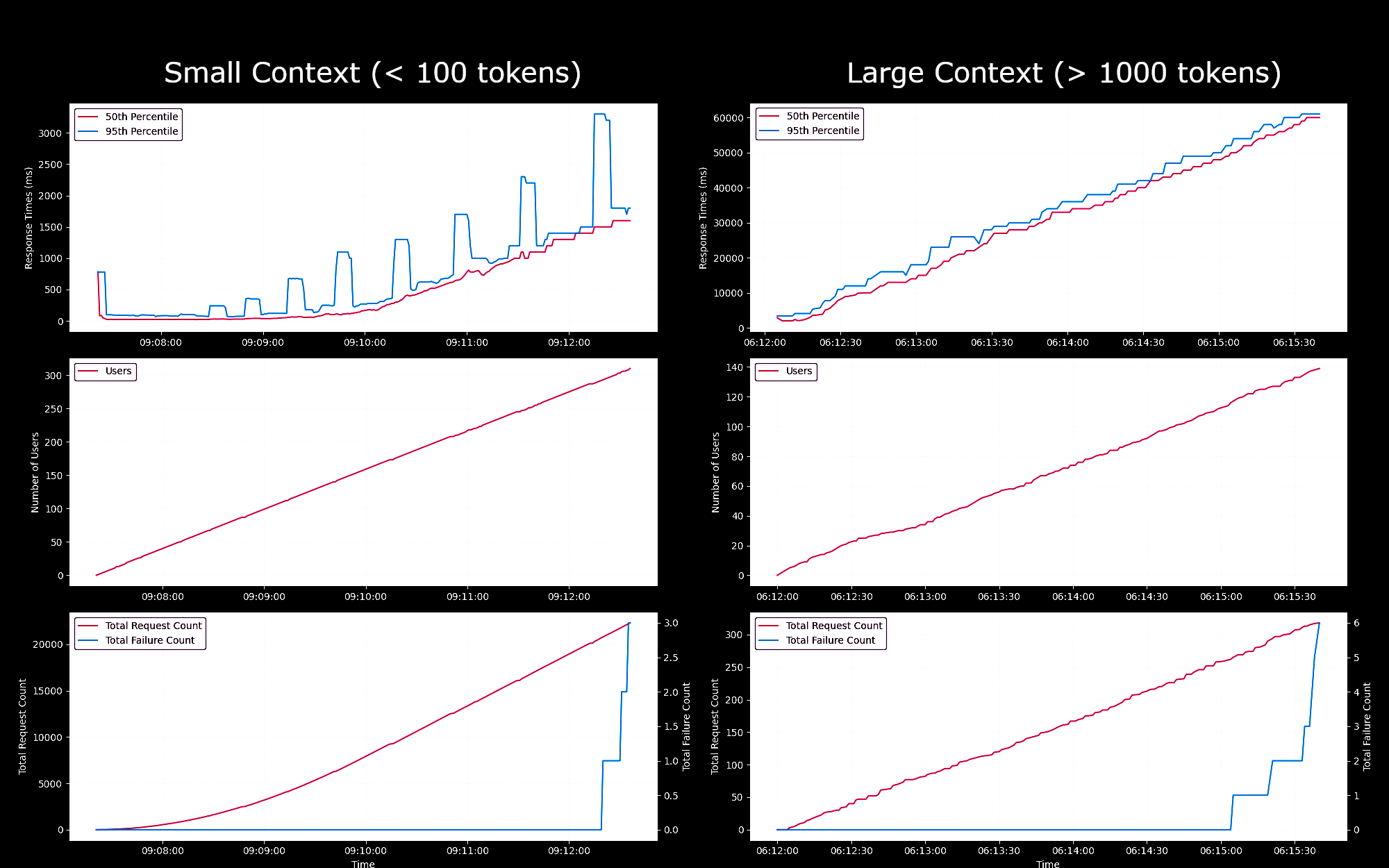
これらの結果から、通常の埋め込みワークロードを持つほとんどのユーザーにとって、g4dn.xlarge または g5.xlarge インスタンスが日常的なニーズを満たすことができると結論付けることができます。ただし、検索タスクよりもはるかに実行頻度の低い大規模なインデックス作成ジョブの場合、ユーザーはよりパフォーマンスの高いオプションを好む可能性があります。利用可能な Sagemaker インスタンスの一覧については、AWS の EC2 の概要をご参照ください。
tagAWS アカウントの設定
まず、AWS アカウントが必要です。まだ AWS ユーザーでない場合は、AWS のウェブサイトでアカウントにサインアップすることができます。

tagPython 環境での AWS ツールのセットアップ
このチュートリアルに必要な AWS ツールとライブラリを Python 環境にインストールします:
pip install awscli jina-sagemaker
AWS アカウントのアクセスキーとシークレットアクセスキーが必要になります。これらを取得するには、AWS ウェブサイトの手順に従ってください。


また、作業するAWS リージョンを選択する必要があります。
次に、環境変数に値を設定します。Python または Python ノートブックでは、以下のコードで設定できます:
import os
os.environ["AWS_ACCESS_KEY_ID"] = <YOUR_ACCESS_KEY_ID>
os.environ["AWS_SECRET_ACCESS_KEY"] = <YOUR_SECRET_ACCESS_KEY>
os.environ["AWS_DEFAULT_REGION"] = <YOUR_AWS_REGION>
os.environ["AWS_DEFAULT_OUTPUT"] = "json"
デフォルトの出力を json に設定してください。
これは、AWS コマンドラインアプリケーションを使用するか、ローカルファイルシステムにAWS 設定ファイルをセットアップすることでも可能です。詳細については、AWS ウェブサイトのドキュメントをご覧ください。
tagロールの作成
このチュートリアルに必要なリソースを使用するために十分な権限を持つAWS ロールも必要です。
このロールは以下の条件を満たす必要があります:
- AmazonSageMakerFullAccess が有効になっていること。
- 以下のいずれかを満たすこと:
- AWS Marketplace サブスクリプションを作成する権限があり、以下の3つすべてが有効になっていること:
- aws-marketplace:ViewSubscriptions
- aws-marketplace:Unsubscribe
- aws-marketplace:Subscribe
- または、AWS アカウントがjina-embedding-modelのサブスクリプションを持っていること。
- AWS Marketplace サブスクリプションを作成する権限があり、以下の3つすべてが有効になっていること:
ロールの ARN(Amazon Resource Name)を変数名 role に保存してください:
role = <YOUR_ROLE_ARN>
詳細については、AWS ウェブサイトのロールに関するドキュメントをご覧ください。
tagAWS Marketplace での Jina AI モデルの購読
この記事では、Jina Embeddings v2 base English モデルを使用します。AWS Marketplace でこのモデルを購読してください。
ページを下にスクロールすると、価格情報が表示されます。AWS はマーケットプレイスのモデルを時間単位で課金するため、モデルエンドポイントを開始してから停止するまでの時間に対して課金されます。この記事では、その両方の方法をお示しします。
また、Jina Reranker v1 - English モデルも使用しますので、こちらも購読する必要があります。
サブスクリプションを購入したら、AWS リージョンのモデルの ARN を取得し、それぞれ embedding_package_arn と reranker_package_arn という変数名で保存してください。このチュートリアルのコードでは、これらの変数名を参照します。
ARN の取得方法がわからない場合は、Amazon リージョン名を変数 region に設定し、以下のコードを使用してください:
region = os.environ["AWS_DEFAULT_REGION"]
def get_arn_for_model(region_name, model_name):
model_package_map = {
"us-east-1": f"arn:aws:sagemaker:us-east-1:253352124568:model-package/{model_name}",
"us-east-2": f"arn:aws:sagemaker:us-east-2:057799348421:model-package/{model_name}",
"us-west-1": f"arn:aws:sagemaker:us-west-1:382657785993:model-package/{model_name}",
"us-west-2": f"arn:aws:sagemaker:us-west-2:594846645681:model-package/{model_name}",
"ca-central-1": f"arn:aws:sagemaker:ca-central-1:470592106596:model-package/{model_name}",
"eu-central-1": f"arn:aws:sagemaker:eu-central-1:446921602837:model-package/{model_name}",
"eu-west-1": f"arn:aws:sagemaker:eu-west-1:985815980388:model-package/{model_name}",
"eu-west-2": f"arn:aws:sagemaker:eu-west-2:856760150666:model-package/{model_name}",
"eu-west-3": f"arn:aws:sagemaker:eu-west-3:843114510376:model-package/{model_name}",
"eu-north-1": f"arn:aws:sagemaker:eu-north-1:136758871317:model-package/{model_name}",
"ap-southeast-1": f"arn:aws:sagemaker:ap-southeast-1:192199979996:model-package/{model_name}",
"ap-southeast-2": f"arn:aws:sagemaker:ap-southeast-2:666831318237:model-package/{model_name}",
"ap-northeast-2": f"arn:aws:sagemaker:ap-northeast-2:745090734665:model-package/{model_name}",
"ap-northeast-1": f"arn:aws:sagemaker:ap-northeast-1:977537786026:model-package/{model_name}",
"ap-south-1": f"arn:aws:sagemaker:ap-south-1:077584701553:model-package/{model_name}",
"sa-east-1": f"arn:aws:sagemaker:sa-east-1:270155090741:model-package/{model_name}",
}
return model_package_map[region_name]
embedding_package_arn = get_arn_for_model(region, "jina-embeddings-v2-base-en")
reranker_package_arn = get_arn_for_model(region, "jina-reranker-v1-base-en")
tagデータセットの読み込み
このチュートリアルでは、YouTube チャンネル TU Delft Online Learning が提供する動画コレクションを使用します。このチャンネルは STEM 科目の様々な教育コンテンツを制作しています。そのプログラミングは CC-BY ライセンスで提供されています。


このチャンネルから 193 本の動画をダウンロードし、OpenAI のオープンソース Whisper 音声認識モデルで処理しました。動画を文字起こしするために、最小モデルの openai/whisper-tiny を使用しました。
文字起こしは CSV ファイルにまとめられており、こちらからダウンロードできます。
ファイルの各行には以下が含まれています:
- 動画のタイトル
- YouTube の動画 URL
- 動画の文字起こしテキスト
Python でこのデータを読み込むには、まず pandas と requests をインストールしてください:
pip install requests pandas
CSV データを直接 tu_delft_dataframe という名前の Pandas DataFrame に読み込みます:
import pandas
# Load the CSV file
tu_delft_dataframe = pandas.read_csv("https://raw.githubusercontent.com/jina-ai/workshops/feat-sagemaker-post/notebooks/embeddings/sagemaker/tu_delft.csv")
DataFrame の head() メソッドを使用して内容を確認できます。ノートブックでは以下のように表示されるはずです:
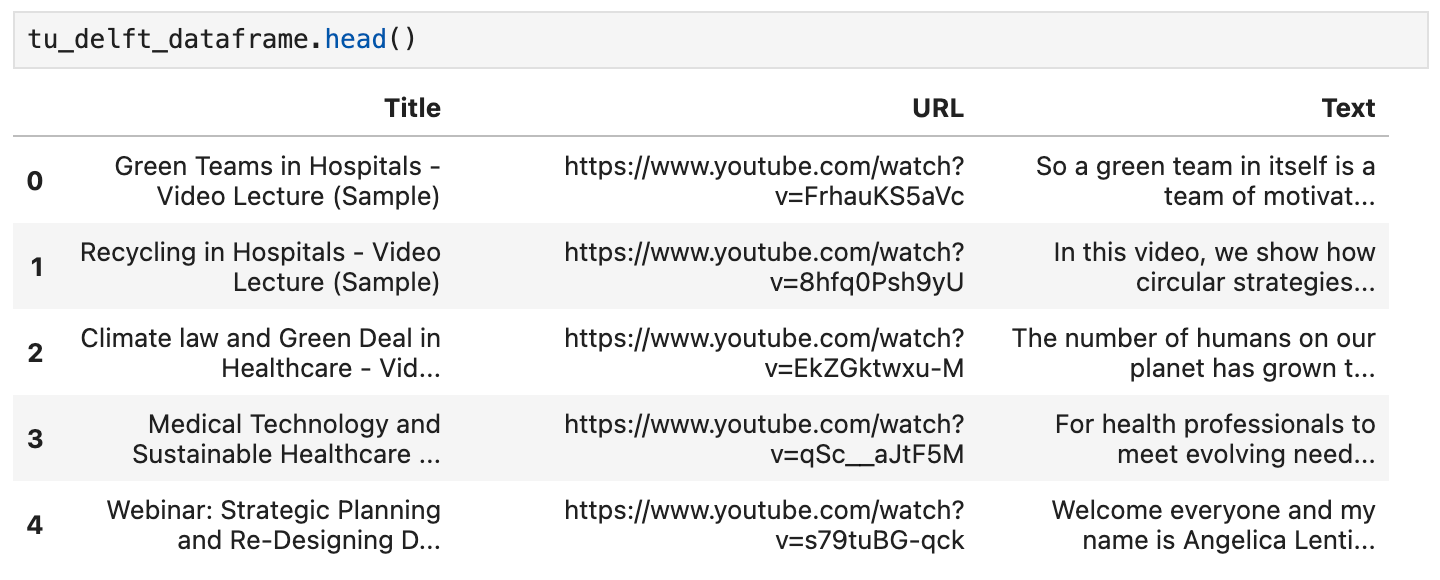
このデータセットに記載されている URL を使用して動画を視聴し、音声認識が完璧ではありませんが、基本的に正確であることを確認することもできます。
tagJina Embeddings v2 エンドポイントの起動
以下のコードは、埋め込みモデルを実行するために AWS 上で ml.g4dn.xlarge インスタンスを起動します。これが完了するまでに数分かかる場合があります。
import boto3
from jina_sagemaker import Client
# 埋め込みエンドポイントの名前を選択してください。便利な名前なら何でも構いません。
embeddings_endpoint_name = "jina_embedding"
embedding_client = Client(region_name=boto3.Session().region_name)
embedding_client.create_endpoint(
arn=embedding_package_arn,
role=role,
endpoint_name=embeddings_endpoint_name,
instance_type="ml.g4dn.xlarge",
n_instances=1,
)
embedding_client.connect_to_endpoint(endpoint_name=embeddings_endpoint_name)
必要に応じて instance_type を変更して、別の AWS クラウドインスタンスタイプを選択してください。
tagデータセットの構築とインデックス作成
データを読み込み、Jina Embeddings v2 モデルを実行している状態で、データの準備とインデックス作成を行うことができます。データは FAISS ベクトルストア(AI アプリケーション向けに特別に設計されたオープンソースのベクトルデータベース)に保存します。
まず、RAG アプリケーションの残りの前提条件をインストールしてください:
pip install tdqm numpy faiss-cpu
tagチャンキング
LLM のプロンプトに複数のテキストを収めるために、個々の文字起こしをより小さな部分(「チャンク」)に分割する必要があります。以下のコードは、デフォルトで各チャンクが 128 語を超えないように、文の境界で個々の文字起こしを分割します。
def chunk_text(text, max_words=128):
"""
Divide text into chunks where each chunk contains the maximum number
of full sentences with fewer words than `max_words`.
"""
sentences = text.split(".")
chunk = []
word_count = 0
for sentence in sentences:
sentence = sentence.strip(".")
if not sentence:
continue
words_in_sentence = len(sentence.split())
if word_count + words_in_sentence <= max_words:
chunk.append(sentence)
word_count += words_in_sentence
else:
# Yield the current chunk and start a new one
if chunk:
yield ". ".join(chunk).strip() + "."
chunk = [sentence]
word_count = words_in_sentence
# Yield the last chunk if it's not empty
if chunk:
yield " ".join(chunk).strip() + "."tag各チャンクの Embeddings を取得する
FAISS データベースに保存するため、各チャンクの embedding が必要です。テキストチャンクを Jina AI の embedding モデルエンドポイントに渡し、embedding_client.embed()メソッドを使用して取得します。そして、テキストチャンクと embedding ベクトルを pandas データフレーム tu_delft_dataframe に新しい列 chunks と embeddings として追加します:
import numpy as np
from tqdm import tqdm
tqdm.pandas()
def generate_embeddings(text_df):
chunks = list(chunk_text(text_df["Text"]))
embeddings = []
for i, chunk in enumerate(chunks):
response = embedding_client.embed(texts=[chunk])
chunk_embedding = response[0]["embedding"]
embeddings.append(np.array(chunk_embedding))
text_df["chunks"] = chunks
text_df["embeddings"] = embeddings
return text_df
print("Embedding text chunks ...")
tu_delft_dataframe = generate_embeddings(tu_delft_dataframe)
## Google Colab や Python ノートブックを使用している場合、
## 上の行を削除して、以下の行のコメントを解除してください:
# tu_delft_dataframe = tu_delft_dataframe.progress_apply(generate_embeddings, axis=1)
tagFaiss を使用したセマンティック検索のセットアップ
以下のコードは FAISS データベースを作成し、tu_delft_pandasを反復処理してチャンクと embedding ベクトルを挿入します:
import faiss
dim = 768 # Jina v2 embeddings の次元
index_with_ids = faiss.IndexIDMap(faiss.IndexFlatIP(dim))
k = 0
doc_ref = dict()
for idx, row in tu_delft_dataframe.iterrows():
embeddings = row["embeddings"]
for i, embedding in enumerate(embeddings):
normalized_embedding = np.ascontiguousarray(np.array(embedding, dtype="float32").reshape(1, -1))
faiss.normalize_L2(normalized_embedding)
index_with_ids.add_with_ids(normalized_embedding, k)
doc_ref[k] = (row["chunks"][i], idx)
k += 1
tagJina Reranker v1 エンドポイントの起動
上記の Jina Embedding v2 モデルと同様に、このコードは AWS 上で ml.g4dn.xlarge インスタンスを起動して reranker モデルを実行します。同様に、実行には数分かかる場合があります。
import boto3
from jina_sagemaker import Client
# reranker エンドポイントの名前を選択します。便利な名前を使用できます。
reranker_endpoint_name = "jina_reranker"
reranker_client = Client(region_name=boto3.Session().region_name)
reranker_client.create_endpoint(
arn=reranker_package_arn,
role=role,
endpoint_name=reranker_endpoint_name,
instance_type="ml.g4dn.xlarge",
n_instances=1,
)
reranker_client.connect_to_endpoint(endpoint_name=reranker_endpoint_name)
tagクエリ関数の定義
次に、テキストクエリに最も類似した転写チャンクを特定する関数を定義します。
これは 2 段階のプロセスです:
- データ準備段階で行ったように、
embedding_client.embed()メソッドを使用してユーザー入力を embedding ベクトルに変換します。 - embedding を FAISS インデックスに渡して最適な一致を取得します。以下の関数では、デフォルトで上位 20 件の一致を返しますが、
nパラメータで制御できます。
find_most_similar_transcript_segment関数は、保存された embedding とクエリ embedding のコサインを比較して、最適な一致を返します。
def find_most_similar_transcript_segment(query, n=20):
query_embedding = embedding_client.embed(texts=[query])[0]["embedding"] # クエリが十分に短いと仮定してチャンク分割は不要
query_embedding = np.ascontiguousarray(np.array(query_embedding, dtype="float32").reshape(1, -1))
faiss.normalize_L2(query_embedding)
D, I = index_with_ids.search(query_embedding, n) # 上位 n 件の一致を取得
results = []
for i in range(n):
distance = D[0][i]
index_id = I[0][i]
transcript_segment, doc_idx = doc_ref[index_id]
results.append((transcript_segment, doc_idx, distance))
# 結果を距離でソート
results.sort(key=lambda x: x[2])
return [(tu_delft_dataframe.iloc[r[1]]["Title"].strip(), r[0]) for r in results]
また、reranker エンドポイント reranker_clientにアクセスし、find_most_similar_transcript_segmentの結果を渡して、最も関連性の高い 3 つの結果のみを返す関数を定義します。これは、reranker_client.rerank()メソッドを使用して reranker エンドポイントを呼び出します。
def rerank_results(query_found, query, n=3):
ret = reranker_client.rerank(
documents=[f[1] for f in query_found],
query=query,
top_n=n,
)
return [query_found[r['index']] for r in ret[0]['results']]
tagJumpStart を使用して Mistral-Instruct をロード
このチュートリアルでは、RAG システムの LLM 部分として、Amazon SageMaker JumpStart で利用可能な mistral-7b-instruct モデルを使用します。

以下のコードを実行して、Mistral-Instruct をロードおよびデプロイします:
from sagemaker.jumpstart.model import JumpStartModel
jumpstart_model = JumpStartModel(model_id="huggingface-llm-mistral-7b-instruct", role=role)
model_predictor = jumpstart_model.deploy()
このLLMにアクセスするエンドポイントは変数 model_predictor に格納されます。
tagJumpStart での Mistral-Instruct の使用
以下は、Python の組み込み string テンプレートクラスを使用して、このアプリケーション用の Mistral-Instruct のプロンプトテンプレートを作成するコードです。各クエリに対して、モデルに提示される 3 つの一致する転写チャンクがあることを前提としています。
このテンプレートを自分で試して、このアプリケーションを修正したり、より良い結果が得られるかどうかを確認したりすることができます。
from string import Template
prompt_template = Template("""
<s>[INST] 与えられたコンテキストのみを使用して、以下の質問に答えてください。
ユーザーからの質問は、YouTube チャンネルの動画の書き起こしに基づいています。
コンテキストは、ユーザーの質問に関連する情報として、(動画タイトル、書き起こしセグメント)
の形式でランク付けされたリストとして提示されています。
回答は提示されたコンテキストのみを使用する必要があります。コンテキストに基づいて
質問に答えられない場合は、その旨を述べてください。
コンテキスト:
1. 動画タイトル:$title_1、書き起こしセグメント:$segment_1
2. 動画タイトル:$title_2、書き起こしセグメント:$segment_2
3. 動画タイトル:$title_3、書き起こしセグメント:$segment_3
質問:$question
回答:[/INST]
""")
このコンポーネントを配置したことで、完全な RAG アプリケーションのすべての部分が揃いました。
tagモデルへのクエリ
モデルへのクエリは 3 段階のプロセスです。
- クエリに基づいて関連するチャンクを検索します。
- プロンプトを組み立てます。
- プロンプトを Mistral-Instruct モデルに送信し、その回答を返します。
関連するチャンクを検索するには、上で定義した find_most_similar_transcript_segment 関数を使用します。
question = "最初の洋上風力発電所はいつ稼働しましたか?"
search_results = find_most_similar_transcript_segment(question)
reranked_results = rerank_results(search_results, question)
検索結果を再ランク付けされた順序で確認できます:
for title, text, _ in reranked_results:
print(title + "\n" + text + "\n")
結果:
Offshore Wind Farm Technology - Course Introduction
Since the first offshore wind farm commissioned in 1991 in Denmark, scientists and engineers have adapted and improved the technology of wind energy to offshore conditions. This is a rapidly evolving field with installation of increasingly larger wind turbines in deeper waters. At sea, the challenges are indeed numerous, with combined wind and wave loads, reduced accessibility and uncertain-solid conditions. My name is Axel Vire, I'm an assistant professor in Wind Energy at U-Delf and specializing in offshore wind energy. This course will touch upon the critical aspect of wind energy, how to integrate the various engineering disciplines involved in offshore wind energy. Each week we will focus on a particular discipline and use it to design and operate a wind farm.
Offshore Wind Farm Technology - Course Introduction
I'm a researcher and lecturer at the Wind Energy and Economics Department and I will be your moderator throughout this course. That means I will answer any questions you may have. I'll strengthen the interactions between the participants and also I'll get you in touch with the lecturers when needed. The course is mainly developed for professionals in the field of offshore wind energy. We want to broaden their knowledge of the relevant technical disciplines and their integration. Professionals with a scientific background who are new to the field of offshore wind energy will benefit from a high-level insight into the engineering aspects of wind energy. Overall, the course will help you make the right choices during the development and operation of offshore wind farms.
Offshore Wind Farm Technology - Course Introduction
Designed wind turbines that better withstand wind, wave and current loads Identify great integration strategies for offshore wind turbines and gain understanding of the operational and maintenance of offshore wind turbines and farms We also hope that you will benefit from the course and from interaction with other learners who share your interest in wind energy And therefore we look forward to meeting you online.
この情報を直接プロンプトテンプレートで使用できます:
prompt_for_llm = prompt_template.substitute(
question = question,
title_1 = search_results[0][0],
segment_1 = search_results[0][1],
title_2 = search_results[1][0],
segment_2 = search_results[1][1],
title_3 = search_results[2][0],
segment_3 = search_results[2][1],
)
実際に LLM に送信されるプロンプトを確認するために文字列を出力します:
print(prompt_for_llm)
<s>[INST] Answer the question below only using the given context.
The question from the user is based on transcripts of videos from a YouTube
channel.
The context is presented as a ranked list of information in the form of
(video-title, transcript-segment), that is relevant for answering the
user's question.
The answer should only use the presented context. If the question cannot be
answered based on the context, say so.
Context:
1. Video-title: Offshore Wind Farm Technology - Course Introduction, transcript-segment: Since the first offshore wind farm commissioned in 1991 in Denmark, scientists and engineers have adapted and improved the technology of wind energy to offshore conditions. This is a rapidly evolving field with installation of increasingly larger wind turbines in deeper waters. At sea, the challenges are indeed numerous, with combined wind and wave loads, reduced accessibility and uncertain-solid conditions. My name is Axel Vire, I'm an assistant professor in Wind Energy at U-Delf and specializing in offshore wind energy. This course will touch upon the critical aspect of wind energy, how to integrate the various engineering disciplines involved in offshore wind energy. Each week we will focus on a particular discipline and use it to design and operate a wind farm.
2. Video-title: Offshore Wind Farm Technology - Course Introduction, transcript-segment: For example, we look at how to characterize the wind and wave conditions at a given location. How to best place the wind turbines in a farm and also how to retrieve the electricity back to shore. We look at the main design drivers for offshore wind turbines and their components. We'll see how these aspects influence one another and the best choices to reduce the cost of energy. This course is organized by the two-delfd wind energy institute, an interfaculty research organization focusing specifically on wind energy. You will therefore benefit from the expertise of the lecturers in three different faculties of the university. Aerospace engineering, civil engineering and electrical engineering. Hi, my name is Ricardo Pareda.
3. Video-title: Systems Analysis for Problem Structuring part 1B the mono actor perspective example, transcript-segment: So let's assume the demarcation of the problem and the analysis of objectives has led to the identification of three criteria. The security of supply, the percentage of offshore power generation and the costs of energy provision. We now reason backwards to explore what factors have an influence on these system outcomes. Really, the offshore percentage is positively influenced by the installed Wind Power capacity at sea, a key system factor. Capacity at sea in turn is determined by both the size and the number of wind farms at sea. The Ministry of Economic Affairs cannot itself invest in new wind farms but hopes to simulate investors and energy companies by providing subsidies and by expediting the granting process of licenses as needed.
Question: When was the first offshore wind farm commissioned?
Answer: [/INST]
このプロンプトを LLM エンドポイント —model_predictor— に model_predictor.predict() メソッドを通して渡します:
answer = model_predictor.predict({"inputs": prompt_for_llm})
これはリストを返しますが、1つのプロンプトのみを渡したため、1つのエントリを持つリストになります。各エントリはキー generated_text の下に応答テキストを持つ dict です:
answer = answer[0]['generated_text']
print(answer)
結果:
The first offshore wind farm was commissioned in 1991. (Context: Video-title: Offshore Wind Farm Technology - Course Introduction, transcript-segment: Since the first offshore wind farm commissioned in 1991 in Denmark, ...)
文字列の質問をパラメータとして受け取り、文字列として答えを返す関数を書いて、クエリを単純化しましょう:
def ask_rag(question):
search_results = find_most_similar_transcript_segment(question)
reranked_results = rerank_results(search_results, question)
prompt_for_llm = prompt_template.substitute(
question = question,
title_1 = search_results[0][0],
segment_1 = search_results[0][1],
title_2 = search_results[1][0],
segment_2 = search_results[1][1],
title_3 = search_results[2][0],
segment_3 = search_results[2][1],
)
answer = model_predictor.predict({"inputs": prompt_for_llm})
return answer[0]["generated_text"]
これで、さらにいくつかの質問をすることができます。答えは動画のトランスクリプトの内容に依存します。例えば、データに答えがある場合は詳細な質問をして回答を得ることができます:
ask_rag("What is a Kaplan Meyer estimator?")
The Kaplan Meyer estimator is a non-parametric estimator for the survival
function, defined for both censored and not censored data. It is represented
as a series of declining horizontal steps that approaches the truths of the
survival function if the sample size is sufficiently large enough. The value
of the empirical survival function obtained is assumed to be constant between
two successive distinct observations.
ask_rag("Who is Reneville Solingen?")
Reneville Solingen is a professor at Delft University of Technology in Global
Software Engineering. She is also a co-author of the book "The Power of Scrum."
answer = ask_rag("What is the European Green Deal?")
print(answer)
The European Green Deal is a policy initiative by the European Union to combat
climate change and decarbonize the economy, with a goal to make Europe carbon
neutral by 2050. It involves the use of green procurement strategies in various
sectors, including healthcare, to reduce carbon emissions and promote corporate
social responsibility.
また、利用可能な情報の範囲外の質問をすることもできます:
ask_rag("What countries export the most coffee?")
Based on the context provided, there is no clear answer to the user's
question about which countries export the most coffee as the context
only discusses the Delft University's cafeteria discounts and sustainable
coffee options, as well as lithium production and alternatives for use in
electric car batteries.
ask_rag("How much wood could a woodchuck chuck if a woodchuck could chuck wood?")
The context does not provide sufficient information to answer the question.
The context is about thermit welding of rails, stress concentration factors,
and a lyrics video. There is no mention of woodchucks or the ability of
woodchuck to chuck wood in the context.
自分のクエリを試してみてください。また、結果を改善するために LLM へのプロンプトの方法を変更することもできます。
tagシャットダウン
使用するモデルと AWS インフラストラクチャの料金は時間単位で請求されるため、このチュートリアルを終了する際には、3つの AI モデルすべてを停止することが非常に重要です:
- 埋め込みモデルエンドポイント
embedding_client - 再ランカーモデルエンドポイント
reranker_client - 大規模言語モデルエンドポイント
model_predictor
3つのモデルエンドポイントすべてをシャットダウンするには、次のコードを実行します:
# shut down the embedding endpoint
embedding_client.delete_endpoint()
embedding_client.close()
# shut down the reranker endpoint
reranker_client.delete_endpoint()
reranker_client.close()
# shut down the LLM endpoint
model_predictor.delete_model()
model_predictor.delete_endpoint()
tagAWS Marketplace で Jina AI モデルを今すぐ始めましょう
SageMaker 上の当社の埋め込みモデルと再ランキングモデルにより、AWS 上のエンタープライズ AI ユーザーは、既存のクラウド運用のメリットを損なうことなく、Jina AI の優れた価値提案に即座にアクセスできるようになりました。AWS のセキュリティ、信頼性、一貫性、予測可能な価格設定がすべて組み込まれています。
Jina AI では、既存のプロセスに AI を取り入れることで恩恵を受けられるビジネスに最先端技術をもたらすために懸命に取り組んでいます。私たちは、使いやすく実用的なインターフェースを通じて、手頃な価格で信頼性の高い高性能なモデルを提供することを目指し、AI への投資を最小限に抑えながら、リターンを最大化します。
当社が提供するすべての埋め込みモデルと再ランカーモデルのリストを確認し、7日間無料で試すには、Jina AI の AWS Marketplace のページをご覧ください。
Jina AI の製品があなたのビジネスニーズにどのように適合するか、ユースケースについてお聞かせください。当社のウェブサイトまたはDiscord チャンネルからご連絡いただき、フィードバックを共有したり、最新モデルの情報を入手したりすることができます。






