

最近の jina-reranker-v2-multilingual のリリース後、ICML 出張までの時間があったので、reranker モデルについての記事を書くことにしました。インターネットでアイデアを探していると、検索結果の上位に、reranker が SEO を改善できるという記事が出てきました。とても興味深そうですよね?私もそう思いました。Jina AI では reranker を扱っており、会社のウェブサイトの管理者として、SEO の改善には常に関心があるからです。
しかし、記事を全部読んでみると、完全に ChatGPT が生成したものだとわかりました。記事全体が「Reranking はあなたのビジネス/ウェブサイトにとって重要です」という考えを繰り返し言い換えるだけで、その方法や背後にある数学、実装方法については一切説明していませんでした。時間の無駄でした。
Reranker と SEO を結びつけることはできません。検索システムの開発者(一般的にコンテンツの消費者)は reranker に関心を持ち、コンテンツ作成者は SEO とそのシステムでのコンテンツのランク付けに関心を持ちます。彼らは基本的にテーブルの反対側に座っており、アイデアを交換することはほとんどありません。reranker に SEO の改善を求めるのは、鍛冶屋にファイアーボールの呪文のアップグレードを頼むようなもの、あるいは中華料理店で寿司を注文するようなものです。完全に無関係というわけではありませんが、明らかに間違った対象です。
Google が私をオフィスに招待して、彼らの reranker が jina.ai を十分に高くランク付けしているかどうかについて意見を求めるようなことを想像してみてください。あるいは、私が Google の reranking アルゴリズムを完全にコントロールして、誰かが "information retrieval" を検索するたびに jina.ai を最上位にハードコードするようなことを想像してみてください。どちらのシナリオも意味をなしません。では、なぜそのような記事が最初から存在するのでしょうか?ChatGPT に聞いてみると、このアイデアがもともとどこから来たのかが非常に明確になります。

tag動機
もしその AI 生成記事が Google で上位にランクされているなら、より良質な記事を書いてその位置を奪いたいと思います。人間や ChatGPT を誤解させたくないので、この記事での私の主張は明確です:
具体的に、この記事では、Google Search Console からエクスポートした実際の検索クエリを見て、それらと記事との意味的な関係が Google 検索でのインプレッションやクリック数に何らかの示唆を与えるかどうかを検討します。意味的な関係を評価する 3 つの方法を検討します:単語頻度、embedding モデル(jina-embeddings-v2-base-en)、そしてreranker モデル(jina-reranker-v2-multilingual)です。学術研究と同様に、まず研究したい問題を概説しましょう:
- 意味的スコア(クエリ、ドキュメント)は記事のインプレッションやクリック数と関係があるか?
- より深いモデルはそのような関係をより良く予測できるのか?それとも単語頻度で十分なのか?
tag実験セットアップ
この実験では、Google Search Console(GSC)からエクスポートしたjina.ai/newsウェブサイトの実データを使用します。GSC は、Google ユーザーからのオーガニック検索トラフィックを分析できるウェブマスターツールです。Google 検索を通じて何人がブログ投稿を開いたか、検索クエリは何かなどを分析できます。GSC から抽出できる指標は多数ありますが、この実験では3つに焦点を当てます:クエリ、インプレッション、クリック数です。クエリは、ユーザーが Google の検索ボックスに入力したものです。インプレッションは、Google が検索結果であなたのリンクを表示し、ユーザーがそれを見る機会を得た回数を測定します。クリック数は、ユーザーが実際にそれを開いた回数を測定します。Google の「検索モデル」がユーザークエリに対して your 記事に高い関連性スコアを割り当てた場合、多くのインプレッションを得る可能性があることに注意してください。ただし、ユーザーが結果リスト内の他のアイテムをより興味深いと感じた場合、あなたのページはクリック数がゼロになる可能性もあります。
jina.ai/news から最も検索された 7 つのブログ投稿について、過去 4 ヶ月間の GSC 指標をエクスポートしました。各記事には約 1,000 から 5,000 のクリック数と 10,000 から 90,000 のインプレッションがあります。各検索クエリと対応する記事間のクエリ-記事の意味論を調べたいので、GSC で各記事をクリックし、右上の Export ボタンをクリックしてデータをエクスポートする必要があります。zip ファイルが提供され、解凍すると Queries.csv ファイルが見つかります。これが必要なファイルです。
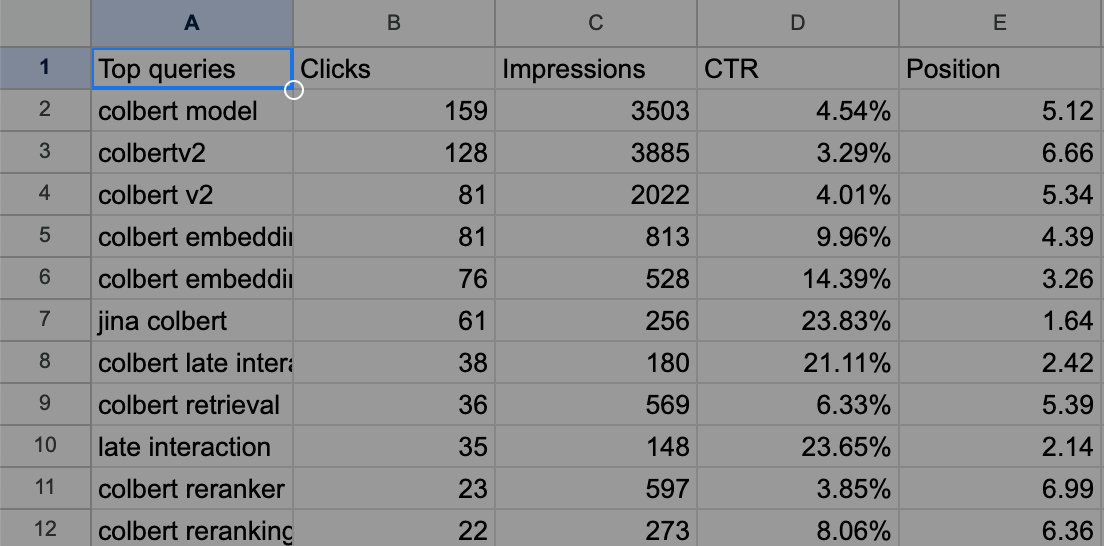
例として、ColBERT ブログ投稿についてエクスポートされた Queries.csv は以下のようになっています。
tag方法論
さて、データは全て準備できました。では、何をしたいのでしょうか?
私たちは、クエリと記事間の意味的関係( と表記)がインプレッションとクリック数と相関があるかどうかを確認したいのです。インプレッションは Google の秘密の検索モデル と考えることができます。つまり、単語頻度、embedding モデル、reranker モデルなどの公開手法を使用して をモデル化し、それが非公開の を近似できるかどうかを確認したいのです。
クリック数についてはどうでしょうか?クリック数も Google の秘密の検索モデルの一部と考えることができますが、不確定な人的要因の影響を受けます。直感的に、クリック数はモデル化がより困難です。
Let me help translate this technical content to Japanese:いずれにせよ、 を に整合させることが目標です。つまり、私たちの は、 が高い時に高いスコアを、 が低い時に低いスコアを示すべきです。これは散布図で視覚化すると分かりやすく、X 軸に 、Y 軸に をプロットします。各クエリの 値と 値をプロットすることで、私たちの検索モデルが Google の検索モデルとどの程度整合しているかを直感的に把握できます。トレンドラインを重ねることで、信頼できるパターンを確認できます。
結果を示す前に、手法をまとめてみましょう:
- クエリと記事の意味的関係が、Google 検索でのインプレッション数とクリック数と相関するかを確認したい。
- Google がドキュメントのクエリへの関連性を判断するアルゴリズム () やクリックの要因は不明です。しかし、これらの の数値は GSC から、つまり各クエリのインプレッション数とクリック数として観察できます。
- 単語頻度、埋め込みモデル、リランカーモデルなどのパブリックな検索手法()が、それぞれ独自の方法でクエリ-ドキュメント関連性をスコア化していますが、これらが の良い近似となっているかを確認したいと考えています。ある意味では、これらが良い近似でないことは既に分かっています。そうでなければ、誰もが Google になれるはずですから。しかし、どの程度かけ離れているのかを理解したいのです。
- 結果を散布図で視覚化して定性的な分析を行います。
tag実装
完全な実装は以下の Google Colab で確認できます。


まず、Jina Reader API を使用してブログ投稿の内容をクロールします。クエリの単語頻度は、基本的な大文字・小文字を区別しないカウントで決定されます。埋め込みモデルについては、ブログ投稿の内容とすべての検索クエリを 1 つの大きなリクエストにまとめて:[[blog1_content], [q1], [q2], [q3], ..., [q481]]、Embedding API に送信します。レスポンスを受け取った後、最初の埋め込みと他のすべての埋め込みとのコサイン類似度を計算して、クエリごとの意味的スコアを取得します。
リランカーモデルの場合、リクエストを少し工夫して構築します:{query: [blog1_content], documents: [[q1], [q2], [q3], ..., [q481]]} としてこの大きなリクエストを Reranker API に送信します。返されたスコアを直接意味的関連性として使用できます。これを工夫的と呼ぶのは、通常、リランカーはクエリに対してドキュメントをランク付けするために使用されるからです。この場合、ドキュメントとクエリの役割を反転させ、リランカーを使用してドキュメントに対してクエリをランク付けします。
Embedding API と Reranker API の両方で、記事の長さを気にする必要がないことに注意してください(クエリは常に短いので問題ありません)。両方の API は最大 8K の入力長をサポートしています(実際、Reranker API は「無限」の長さをサポートしています)。すべてが数秒で迅速に実行でき、この実験用に 私たちのウェブサイト から無料の 1M トークン API キーを取得できます。
tag結果
最後に結果です。しかし結果を示す前に、まずベースラインのプロットがどのように見えるかを示したいと思います。散布図と Y 軸の対数スケールを使用するため、完全に良好な とひどく悪い がどのように見えるかを想像するのは難しい場合があります。2 つの単純なベースラインを構築しました:1 つは が (Ground Truth)の場合、もう 1 つは (ランダム)の場合です。それらの可視化を見てみましょう。
tagベースライン


これで「完全に良好」と「ひどく悪い」予測子がどのように見えるかについての直感が得られました。以下の視覚的検査に非常に役立つ要点とともに、これら 2 つのプロットを覚えておいてください:
- 良好な予測子の散布図は、左下から右上へと対数トレンドラインに従うべきです。
- 良好な予測子のトレンドラインは、X 軸と Y 軸を完全にカバーするべきです(後で見るように、一部の予測子はこのように反応しません)。
- 良好な予測子の分散領域(トレンドライン周りの不透明な領域として描画)は小さくあるべきです。
次に、すべてのプロットを一緒に示します。各予測子について 2 つのプロットを示します:1 つはインプレッションをどの程度予測できるかを示し、もう 1 つはクリックをどの程度予測できるかを示します。なお、7 つのブログ投稿すべてのデータを集約したため、合計で 3620 のクエリ、つまり各散布図に 3620 のデータポイントがあります。
これらのグラフを上下にスクロールして詳しく調べ、比較し、細部に注目してください。しっかりと理解した上で、次のセクションで結論を述べたいと思います。
tag単語頻度を予測子として


tag埋め込みモデルを予測子として


tagリランカーモデルを予測子として


tag発見事項
比較しやすいように、すべてのグラフを一か所にまとめてみましょう。以下のような観察と説明があります:



インプレッションに対する異なる予測子。各点はクエリを表し、X 軸はクエリ-記事の意味的スコア、Y 軸は GSC からエクスポートされたインプレッション数を表します。



クリック数に対する異なる予測指標。各点はクエリを表し、X軸はクエリと記事の意味的スコア、Y軸は GSC からエクスポートされたクリック数を示します。
- 一般的に、クリックの散布図はすべて、インプレッション図に比べてよりまばらです。これは同じデータに基づいているにもかかわらず見られる現象です。前述のように、高いインプレッション数が必ずしもクリックを保証するわけではないためです。
- 用語頻度の散布図は他に比べてよりまばらです。 これは、Google からの実際の検索クエリのほとんどが記事に正確には出現しないため、X値がゼロとなるためです。それでもインプレッションとクリックは発生します。そのため、用語頻度の傾向線の開始点がY軸のゼロ点から始まっていないのが分かります。特定のクエリが記事に複数回出現する場合、インプレッションとクリックが増加すると予想されます。傾向線はこれを確認していますが、傾向線の分散も大きくなっており、サポートデータが不足していることを示唆しています。全般的に、用語頻度は良い予測指標とは言えません。
- 用語頻度予測指標とエンベディングモデルおよびリランカーモデルの散布図を比較すると、後者の方がはるかに良好です:データポイントの分布が良く、傾向線の分散も妥当に見えます。しかし、上記の真値の傾向線と比較すると、大きな違いが1つあります - どちらの傾向線もX軸のゼロ点から始まっていないのです。これは、モデルから非常に高い意味的類似性を得たとしても、Google はゼロのインプレッション/クリックを割り当てる可能性が高いことを意味します。これはクリックの散布図でより顕著になり、開始点はインプレッションの場合よりもさらに右に押し出されています。つまり、Google は私たちのエンベディングモデルとリランカーモデルを使用していないということです—驚きですね!
- 最後に、これら3つの中で最良の予測指標を選ぶとすれば、リランカーモデルを選びます。理由は2つあります:
- リランカーモデルの傾向線は、インプレッションとクリックの両方において、エンベディングモデルの傾向線と比べてX軸上でより広く分布しており、より大きな「ダイナミックレンジ」を持っています。これは真値の傾向線により近いものとなっています。
- スコアが0から1の間でうまく分布しています。これは主に、最新の Reranker v2 モデルがキャリブレーションされているためですが、2023年10月にリリースされた初期の jina-embeddings-v2-base-en はそうではなく、その値が0.60から0.90の範囲に広がっているのが分かります。とはいえ、この2つ目の理由は への近似とは関係ありません。0から1の間でキャリブレーションされた意味的スコアの方が、理解と比較が直感的になるというだけです。
tag最終的な考察
では、SEOにおける教訓は何でしょうか?これはあなたのSEO戦略にどのような影響を与えるのでしょうか?正直なところ、そう大きくはありません。
上記の洗練された図が示唆しているのは、おそらくあなたがすでに知っている基本的なSEOの原則です:ユーザーが検索している内容を書き、人気のあるクエリに関連するコンテンツを確実に提供することです。Reranker V2のような良い予測指標があれば、それを一種の「SEOコパイロット」として執筆のガイドに使うことができるかもしれません。
あるいはそうでないかもしれません。 むしろ、Google や誰かを喜ばせるためではなく、知識のため、自己向上のために書くべきかもしれません。なぜなら、書かずに考えるだけでは、考えていると思い込んでいるだけだからです。
