




2024年4月、私たちは Jina Reader をリリースしました。これは、単純なプレフィックス r.jina.ai を使用して、任意の URL を LLM フレンドリーな markdown に変換する簡単な API です。背後にある高度なネットワークプログラミングにもかかわらず、中核となる「読み取り」部分はかなり単純です。まず、ヘッドレスの Chrome ブラウザを使用してウェブページのソースを取得します。次に、Mozilla の Readability パッケージを活用して、ヘッダー、フッター、ナビゲーションバー、サイドバーなどの要素を削除しながらメインコンテンツを抽出します。最後に、regex と Turndown ライブラリを使用して、クリーンアップされた HTML を markdown に変換します。結果として、LLM による根拠付け、要約、推論に使用できる、よく構造化された markdown ファイルが得られます。
Jina Reader のリリース後の最初の数週間で、特にコンテンツの品質に関して多くのフィードバックを受け取りました。詳細すぎると感じるユーザーもいれば、十分に詳細でないと感じるユーザーもいました。また、Readability フィルターが間違ったコンテンツを削除したり、Turndown が HTML の特定の部分を markdown に変換するのに苦労したりするという報告もありました。幸いなことに、これらの問題の多くは、既存のパイプラインに新しい regex パターンやヒューリスティックを適用することで解決されました。
それ以来、私たちは一つの疑問を抱いてきました:より多くのヒューリスティックと regex でパッチを当てる代わりに(これは維持が increasingly 困難で多言語対応にも適していません)、言語モデルを使ってエンドツーエンドでこの問題を解決できないだろうか?
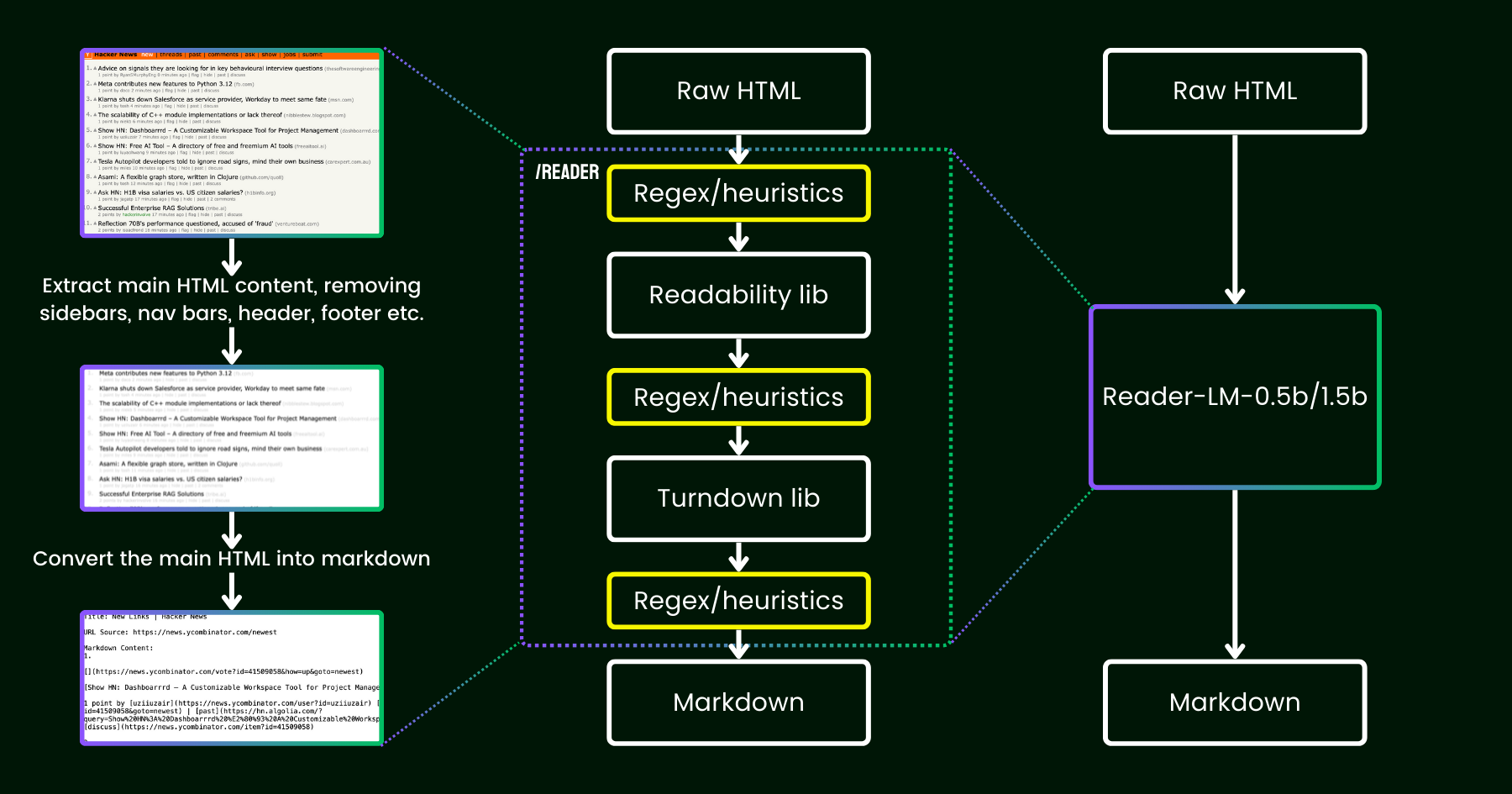
reader-lmの図解。小規模な言語モデルを使用して readability+turndown+regex ヒューリスティクスのパイプラインを置き換えています。一見すると、データクリーニングに LLM を使用することは、コスト効率が低く速度も遅いため過剰に思えるかもしれません。しかし、小規模言語モデル(SLM)、つまりパラメータ数が 10 億未満でエッジで効率的に実行できるモデルを考えた場合はどうでしょうか?それはずっと魅力的に聞こえますよね?しかし、これは本当に実現可能なのか、それとも単なる願望思考なのでしょうか?スケーリング則によると、パラメータが少なくなると一般的に推論や要約の能力は低下します。そのため、パラメータサイズが小さすぎる場合、SLM は意味のあるコンテンツを生成することすら困難かもしれません。これをさらに探るために、HTML から Markdown への変換タスクを詳しく見てみましょう:
- まず、私たちが考えているタスクは一般的な LLM タスクほど創造的で複雑ではありません。HTML から markdown への変換の場合、モデルは主に入力から出力への選択的コピー(つまり、HTML マークアップ、サイドバー、ヘッダー、フッターをスキップする)を行い、新しいコンテンツの生成(主に markdown 構文の挿入)に費やす労力は最小限です。これは、詩を生成したりコードを書いたりするような、出力がより多くの創造性を必要とし、入力からの単純なコピー&ペーストではない LLM の一般的なタスクとは大きく異なります。このことから、タスクが比較的シンプルに見えるため、SLM が機能する可能性があることが示唆されます。
- 第二に、長いコンテキストのサポートを優先する必要があります。現代の HTML には、単純な
<div>マークアップよりもはるかに多くのノイズが含まれていることがよくあります。インライン CSS やスクリプトによって、コードは容易に数十万トークンまで膨らむ可能性があります。このシナリオで SLM を実用的にするためには、コンテキスト長が十分に大きくなければなりません。8K や 16K といったトークン長は全く役に立ちません。
私たちが必要としているのは、浅くて広い SLM のようです。「浅い」というのは、タスクが主に単純な「コピー&ペースト」であり、より少ないトランスフォーマーブロックで済むという意味です。そして「広い」というのは、実用的であるために長いコンテキストのサポートが必要で、アテンション機構に注意を払う必要があるという意味です。過去の研究では、コンテキスト長と推論能力は密接に関連していることが示されています。SLM にとって、パラメータサイズを小さく保ちながら両方の次元を最適化することは非常に困難です。
本日、私たちは reader-lm-0.5b と reader-lm-1.5b のリリースにより、この解決策の第一版を発表できることを嬉しく思います。これらは、ノイズの多い生の HTML からきれいな markdown を直接生成するように特別に訓練された 2 つの SLM です。両モデルは多言語対応で、最大 256K トークンのコンテキスト長をサポートします。コンパクトなサイズにもかかわらず、これらのモデルはこのタスクで最先端の性能を達成し、サイズが 1/50 でありながら、より大きな LLM を上回る性能を示しています。

以下が 2 つのモデルの仕様です:
| reader-lm-0.5b | reader-lm-1.5b | |
|---|---|---|
| パラメータ数 | 494M | 1.54B |
| コンテキスト長 | 256K | 256K |
| 隠れ層サイズ | 896 | 1536 |
| レイヤー数 | 24 | 28 |
| クエリヘッド数 | 14 | 12 |
| KV ヘッド数 | 2 | 2 |
| ヘッドサイズ | 64 | 128 |
| 中間サイズ | 4864 | 8960 |
| 多言語対応 | はい | はい |
| HuggingFace リポジトリ | リンク | リンク |
tagReader-LM を使い始める
tagGoogle Colab で
reader-lm を体験する最も簡単な方法は、Colab ノートブックを実行することです。このノートブックでは、reader-lm-1.5b を使用して Hacker News のウェブサイトを markdown に変換する方法を紹介しています。このノートブックは Google Colab の無料 T4 GPU tier でスムーズに実行できるように最適化されています。reader-lm-0.5b を読み込んだり、URL を任意のウェブサイトに変更して出力を探索したりすることもできます。モデルへの入力(つまりプロンプト)は生の HTML であり、プレフィックスの指示は必要ないことに注意してください。

無料版の T4 GPU には、モデル実行時の高度な最適化の使用を制限する制約があることにご注意ください。T4 では bfloat16 や flash attention などの機能が利用できないため、長い入力に対して VRAM 使用量が増加し、パフォーマンスが低下する可能性があります。本番環境では、大幅に優れたパフォーマンスを得るために、RTX 3090/4090 のような上位 GPU の使用をお勧めします。
tag本番環境:近日 Azure と AWS で利用可能
Reader-LM は Azure Marketplace と AWS SageMaker で利用できます。これらのプラットフォーム以外や社内でオンプレミスでこれらのモデルを使用する必要がある場合は、両モデルが CC BY-NC 4.0 ライセンスの下で提供されていることにご注意ください。商用利用についてのお問い合わせは、お気軽にご連絡ください。


tagベンチマーク
Reader-LM のパフォーマンスを定量的に評価するため、以下の大規模言語モデルと比較しました:GPT-4o、Gemini-1.5-Flash、Gemini-1.5-Pro、LLaMA-3.1-70B、Qwen2-7B-Instruct。
モデルは以下の指標で評価されました:
- ROUGE-L(高いほど良い):要約や質問応答タスクで広く使用されるこの指標は、予測出力と参照との n-gram レベルでの重なりを測定します。
- Token Error Rate(TER、低いほど良い):この指標は、生成された markdown トークンが元の HTML コンテンツに現れない割合を計算します。この指標は、モデルのハルシネーション率を評価し、モデルが HTML に基づかないコンテンツを生成するケースを特定するために設計されました。ケーススタディに基づいてさらなる改善が行われる予定です。
- Word Error Rate(WER、低いほど良い):OCR や ASR タスクで一般的に使用される WER は、単語シーケンスを考慮し、挿入(ADD)、置換(SUB)、削除(DEL)などのエラーを計算します。この指標は、生成された markdown と期待される出力との間のミスマッチを詳細に評価します。
このタスクで LLM を活用するため、以下の統一された指示をプレフィックスプロンプトとして使用しました:
Your task is to convert the content of the provided HTML file into the corresponding markdown file. You need to convert the structure, elements, and attributes of the HTML into equivalent representations in markdown format, ensuring that no important information is lost. The output should strictly be in markdown format, without any additional explanations.結果は以下の表の通りです。
| ROUGE-L | WER | TER | |
|---|---|---|---|
| reader-lm-0.5b | 0.56 | 3.28 | 0.34 |
| reader-lm-1.5b | 0.72 | 1.87 | 0.19 |
| gpt-4o | 0.43 | 5.88 | 0.50 |
| gemini-1.5-flash | 0.40 | 21.70 | 0.55 |
| gemini-1.5-pro | 0.42 | 3.16 | 0.48 |
| llama-3.1-70b | 0.40 | 9.87 | 0.50 |
| Qwen2-7B-Instruct | 0.23 | 2.45 | 0.70 |
tag定性的研究
出力された markdown を視覚的に検査することで定性的研究を実施しました。英語、ドイツ語、日本語、中国語の複数言語による、ニュース記事、ブログ投稿、ランディングページ、E コマースページ、フォーラム投稿を含む 22 の HTML ソースを選択しました。また、正規表現、ヒューリスティクス、事前定義ルールに依存する Jina Reader API をベースラインとして含めました。
評価は出力の 4 つの重要な側面に焦点を当て、各モデルを 1(最低)から 5(最高)のスケールで評価しました:
- ヘッダー抽出:各モデルが h1、h2、...、h6 ヘッダーを正しい markdown 構文を使用して識別し、フォーマットする能力を評価。
- メインコンテンツ抽出:段落、リストのフォーマット、プレゼンテーションの一貫性を維持しながら、本文を正確に変換するモデルの能力を評価。
- 豊かな構造の保持:見出し、小見出し、箇条書き、順序付きリストを含む文書の全体的な構造を効果的に維持する各モデルの能力を分析。
- Markdown 構文の使用:
<a>(リンク)、<strong>(太字)、<em>(イタリック)などの HTML 要素を適切な markdown 相当に正しく変換する各モデルの能力を評価。
結果は以下の通りです。

Reader-LM-1.5B は全ての側面で一貫して良好なパフォーマンスを示し、特に構造の保持と markdown 構文の使用で優れています。Jina Reader API を常に上回るわけではありませんが、そのパフォーマンスは Gemini 1.5 Pro のような大規模モデルと競合しており、より大きな LLM に対する非常に効率的な代替手段となっています。Reader-LM-0.5B は小規模ながら、特に構造の保持において solid なパフォーマンスを提供します。
tagReader-LM の学習方法
tagデータ準備
Jina Reader API を使用して、生の HTML とそれに対応する markdown のトレーニングペアを生成しました。実験中、SLM がトレーニングデータの品質に特に敏感であることがわかりました。そのため、高品質な markdown エントリーのみをトレーニングセットに含めるデータパイプラインを構築しました。
さらに、GPT-4o によって生成された合成 HTML とその markdown 対応を追加しました。実世界の HTML と比較して、合成データは一般的にはるかに短く、よりシンプルで予測可能な構造を持ち、ノイズレベルが大幅に低くなっています。
最後に、チャットテンプレートを使用して HTML と markdown を連結しました。最終的なトレーニングデータは以下のようにフォーマットされています:
<|im_start|>system
You are a helpful assistant.<|im_end|>
<|im_start|>user
{{RAW_HTML}}<|im_end|>
<|im_start|>assistant
{{MARKDOWN}}<|im_end|>
トレーニングデータの総量は 25 億トークンです。
tag2 段階のトレーニング
私たちは 65M から 135M、そして 3B パラメータまでの様々なモデルサイズで実験を行いました。各モデルの仕様は以下の表の通りです。
| reader-lm-65m | reader-lm-135m | reader-lm-360m | reader-lm-0.5b | reader-lm-1.5b | reader-lm-1.7b | reader-lm-3b | |
|---|---|---|---|---|---|---|---|
| Hidden Size | 512 | 576 | 960 | 896 | 1536 | 2048 | 3072 |
| # Layers | 8 | 30 | 32 | 24 | 28 | 24 | 32 |
| # Query Heads | 16 | 9 | 15 | 14 | 12 | 32 | 32 |
| # KV Heads | 8 | 3 | 5 | 2 | 2 | 32 | 32 |
| Head Size | 32 | 64 | 64 | 64 | 128 | 64 | 96 |
| Intermediate Size | 2048 | 1536 | 2560 | 4864 | 8960 | 8192 | 8192 |
| Attention Bias | False | False | False | True | True | False | False |
| Embedding Tying | False | True | True | True | True | True | False |
| Vocabulary Size | 32768 | 49152 | 49152 | 151646 | 151646 | 49152 | 32064 |
| Base Model | Lite-Oute-1-65M-Instruct | SmolLM-135M | SmolLM-360M-Instruct | Qwen2-0.5B-Instruct | Qwen2-1.5B-Instruct | SmolLM-1.7B | Phi-3-mini-128k-instruct |
モデルのトレーニングは2段階で行われました:
- 短くて単純な HTML:この段階では、最大シーケンス長(HTML + markdown)を 32K トークンに設定し、合計 15 億トレーニングトークンを使用しました。
- 長くて複雑な HTML:シーケンス長を 128K トークンまで拡張し、12 億トレーニングトークンを使用しました。この段階では、Zilin Zhu の "Ring Flash Attention"(2024)からジグザグリングアテンション機構を実装しました。
トレーニングデータには 128K トークンまでのシーケンスが含まれていたため、モデルは 256K トークンまでは問題なく対応できると考えています。ただし、512K トークンの処理は困難かもしれません。なぜなら、RoPE 位置エンベッディングをトレーニングシーケンス長の4倍まで拡張すると、性能が低下する可能性があるためです。
65M と 135M パラメータのモデルでは、短いシーケンス(1K トークン未満)に対して妥当な「コピー」動作を達成できることがわかりましたが、入力長が増加すると、これらのモデルは合理的な出力を生成することが困難になりました。現代の HTML ソースコードは簡単に 100K トークンを超えることがあるため、1K トークンの制限では全く不十分です。
tag劣化と単調なループ
私たちが直面した主な課題の1つは、特に繰り返しやループの形での劣化でした。トークンを生成した後、モデルは同じトークンを繰り返し生成したり、短いトークン列を最大出力長に達するまで連続して繰り返すループに陥ったりしていました。

この問題に対処するため:
- デコード方法として対照的探索(contrastive search)を適用し、トレーニング中に対照的損失を組み込みました。実験の結果、この方法は実際に繰り返し生成を効果的に削減しました。
- transformer パイプライン内に単純な繰り返し停止基準を実装しました。この基準は、モデルがトークンの繰り返しを始めた時点を自動的に検出し、単調なループを避けるために早期にデコードを停止します。このアイデアは、この議論からインスピレーションを得ました。
tag長い入力に対するトレーニング効率
長い入力を処理する際のメモリ不足(OOM)エラーのリスクを軽減するため、チャンク単位のモデル転送を実装しました。このアプローチでは、長い入力を小さなチャンクでエンコードし、VRAM の使用量を削減します。
Transformers Trainer をベースにしたトレーニングフレームワークでデータパッキングの実装を改善しました。トレーニング効率を最適化するために、複数の短いテキスト(例:2K トークン)を1つの長いシーケンス(例:30K トークン)に連結し、パディングのないトレーニングを実現します。しかし、元の実装では、一部の短い例が2つのサブテキストに分割され、異なる長いトレーニングシーケンスに含まれていました。このような場合、2番目のサブテキストはコンテキスト(この場合は生の HTML コンテンツ)を失い、トレーニングデータが破損します。これにより、モデルは入力コンテキストではなくパラメータに依存せざるを得なくなり、これが幻覚の主要な原因になると考えています。
最終的に、私たちは 0.5B と 1.5B のモデルを公開用に選択しました。0.5B モデルは、長いコンテキスト入力に対して望ましい「選択的コピー」動作を達成できる最小のモデルであり、1.5B モデルはパラメータサイズに対して収穫逓減に達することなく、性能を大幅に向上させる最小の大型モデルです。
tag代替アーキテクチャ:エンコーダーのみのモデル
このプロジェクトの初期段階では、この課題に取り組むためにエンコーダーのみのアーキテクチャも検討しました。前述のように、HTML から Markdown への変換タスクは主に「選択的コピー」タスクのように見えます。トレーニングペア(生の HTML と markdown)が与えられた場合、入力と出力の両方に存在するトークンを 1、それ以外を 0 としてラベル付けすることができます。これにより、問題を Named Entity Recognition(NER)で使用されるようなトークン分類タスクに変換できます。
このアプローチは論理的に見えましたが、実践では重大な課題がありました。まず、実世界のソースからの生の HTML は非常にノイジーで長く、1 のラベルが極めて疎になるため、モデルが学習するのが困難でした。次に、## title、*bold*、| table | のような特殊な markdown 構文を 0-1 スキーマでエンコードすることが問題となりました。これらの記号は生の HTML 入力には存在しないためです。第三に、出力トークンは必ずしも入力の順序に厳密に従わないことです。特にテーブルやリンクでは、マイナーな順序の変更がしばしば発生し、このような順序変更の動作を単純な 0-1 スキーマで表現することが困難でした。短距離の順序変更は、動的プログラミングやアライメント・ワーピングアルゴリズムを用いて、距離のオフセットを表す -1, -2, +1, +2 のようなラベルを導入することで、バイナリ分類問題をマルチクラストークン分類タスクに変換することで、潜在的に処理できたかもしれません。
要約すると、エンコーダーのみのアーキテクチャで問題を解決し、トークン分類タスクとして扱うことには魅力があります。特に、デコーダーのみのモデルと比較してトレーニングシーケンスがはるかに短くなり、VRAM の使用がより効率的になります。しかし、主な課題は良質なトレーニングデータの準備にあります。動的プログラミングやヒューリスティックを使用して完璧なトークンレベルのラベリングシーケンスを作成するためのデータ前処理に費やす時間と労力が膨大であることに気付いた時点で、このアプローチを中止することを決定しました。
tag結論
Reader-LM は、オープンウェブ上のデータ抽出とクリーニングのために設計された革新的な小規模言語モデル(SLM)です。Jina Reader にインスパイアされ、生の雑多な HTML をクリーンなマークダウンに変換できる、エンドツーエンドの言語モデルソリューションを作ることを目指しました。同時に、コスト効率を重視し、モデルサイズを小さく保つことで、Reader-LM の実用性と使いやすさを確保しています。これは Jina AI で初めて訓練されたデコーダーオンリーの長文コンテキストモデルでもあります。
一見すると単純な「選択的コピー」の問題に見えるかもしれませんが、HTML をマークダウンに変換してクリーニングすることは決して容易ではありません。具体的には、モデルが位置を意識したコンテキストベースの推論に優れている必要があり、これには特に隠れ層において大きなパラメータサイズが求められます。それに比べて、マークダウン構文の学習は比較的単純です。
実験の過程で、SLM を一からトレーニングすることは特に困難であることも判明しました。事前訓練済みモデルから開始し、タスク固有のトレーニングを継続することで、トレーニングの効率が大幅に向上しました。効率性と品質の両面でまだ改善の余地があります:コンテキスト長の拡張、デコードの高速化、入力における指示のサポート追加(これにより Reader-LM がウェブページの特定の部分をマークダウンに抽出できるようになります)などです。
