

Deepset の Haystack 2.0 への Jina Embeddings の統合とJina Reranker のリリースに続き、Jina Reranker が Jina Haystack 拡張機能を通じても利用可能になったことをお知らせできることを嬉しく思います。


Haystack は、GenAI プロジェクトのライフサイクルの各段階をサポートするエンドツーエンドのフレームワークです。ドキュメント検索、検索拡張生成(RAG)、質問応答、回答生成など、どのようなニーズにも対応し、最先端の埋め込みモデルと LLM をパイプラインに組み込んで、エンドツーエンドの NLP アプリケーションを構築し、ユースケースを解決することができます。
この記事では、これらを使用して独自の Jira チケット検索エンジンを作成し、運用を効率化して重複した課題を作成する時間を無駄にしないようにする方法を紹介します。
このチュートリアルを実行するには、Jina Reranker API キーが必要です。Jina Reranker のウェブサイトから、100 万トークンの無料トライアルクォータで作成できます。
tagJira サポートチケットの取得
複雑なプロジェクトに取り組むチームは誰でも、登録したい問題があるけれど、その問題のチケットがすでに存在するかどうかわからないというフラストレーションを経験したことがあるでしょう。
このチュートリアルでは、Jina Reranker と Haystack パイプラインを使用して、新規作成されるチケットに対して重複する可能性のあるチケットを提案するツールを簡単に作成する方法を紹介します。
- 既存のすべてのチケットと照合する必要のあるチケットを入力すると、パイプラインはまずデータベースから関連するすべての課題を取得します。
- その後、最初のチケット(データベースにすでに存在する場合)と子チケット(親 ID が元のチケットに対応するチケット)をリストから削除します。
- 最終的な選択には、元のチケットと同じトピックをカバーしている可能性があるものの、データベース内で ID を通じて関連付けられていない課題のみが含まれます。これらのチケットは最大限の関連性を確保するために再ランク付けされ、データベース内の重複エントリを特定できるようになります。
tagデータセットの取得
この解決策を実装するために、Apache Zookeeper プロジェクトの「進行中」のすべての Jira チケットを選びました。これは、分散アプリケーションのプロセスを調整するためのオープンソースサービスです。
チケットは扱いやすくするために JSON ファイルに配置しています。ファイルをワークスペースにダウンロードしてください。
tag前提条件の設定
必要なパッケージをインストールするには、次のコマンドを実行します:
pip install --q chromadb haystack-ai jina-haystack chroma-haystack
API キーを入力するには、環境変数として設定します:
import os
import getpass
os.environ["JINA_API_KEY"] = getpass.getpass()
getpass.getpass() は対応するコードブロックの下で API キーの入力を求めます。そこでキーを入力して Enter キーを押すと、チュートリアルを再開できます。お好みで、getpass.getpass() を API キー自体に置き換えることもできます。tagインデックスパイプラインの構築
インデックスパイプラインは、チケットを前処理し、ベクトルに変換して保存します。ベクトル埋め込みを保存するベクターデータベースとして、Chroma Document Store Haystack 統合を通じて Chroma DocumentStore を使用します。
from haystack_integrations.document_stores.chroma import ChromaDocumentStore
document_store = ChromaDocumentStore()
まず、関連するドキュメントフィールドのみを考慮し、空のエントリをすべて削除するカスタムデータ前処理プログラムを定義します:
import json
from typing import List
from haystack import Document, component
relevant_keys = ['Summary', 'Issue key', 'Issue id', 'Parent id', 'Issue type', 'Status', 'Project lead', 'Priority', 'Assignee', 'Reporter', 'Creator', 'Created', 'Updated', 'Last Viewed', 'Due Date', 'Labels',
'Description', 'Comment', 'Comment__1', 'Comment__2', 'Comment__3', 'Comment__4', 'Comment__5', 'Comment__6', 'Comment__7', 'Comment__8', 'Comment__9', 'Comment__10', 'Comment__11', 'Comment__12',
'Comment__13', 'Comment__14', 'Comment__15']
@component
class RemoveKeys:
@component.output_types(documents=List[Document])
def run(self, file_name: str):
with open(file_name, 'r') as file:
tickets = json.load(file)
cleaned_tickets = []
for t in tickets:
t = {k: v for k, v in t.items() if k in relevant_keys and v}
cleaned_tickets.append(t)
return {'documents': cleaned_tickets}
次に、チケットを Haystack が理解できる Document オブジェクトに変換するカスタム JSON コンバーターを作成する必要があります:
@component
class JsonConverter:
@component.output_types(documents=List[Document])
def run(self, tickets: List[Document]):
tickets_documents = []
for t in tickets:
if 'Parent id' in t:
t = Document(content=json.dumps(t), meta={'Issue key': t['Issue key'], 'Issue id': t['Issue id'], 'Parent id': t['Parent id']})
else:
t = Document(content=json.dumps(t), meta={'Issue key': t['Issue key'], 'Issue id': t['Issue id'], 'Parent id': ''})
tickets_documents.append(t)
return {'documents': tickets_documents}
最後に、Document を埋め込み、これらの埋め込みを ChromaDocumentStore に書き込みます:
from haystack import Pipeline
from haystack.components.writers import DocumentWriter
from haystack_integrations.components.retrievers.chroma import ChromaEmbeddingRetriever
from haystack.document_stores.types import DuplicatePolicy
from haystack_integrations.components.embedders.jina import JinaDocumentEmbedder
retriever = ChromaEmbeddingRetriever(document_store=document_store)
retriever_reranker = ChromaEmbeddingRetriever(document_store=document_store)
indexing_pipeline = Pipeline()
indexing_pipeline.add_component('cleaner', RemoveKeys())
indexing_pipeline.add_component('converter', JsonConverter())
indexing_pipeline.add_component('embedder', JinaDocumentEmbedder(model='jina-embeddings-v2-base-en'))
indexing_pipeline.add_component('writer', DocumentWriter(document_store=document_store, policy=DuplicatePolicy.SKIP))
indexing_pipeline.connect('cleaner', 'converter')
indexing_pipeline.connect('converter', 'embedder')
indexing_pipeline.connect('embedder', 'writer')
indexing_pipeline.run({'cleaner': {'file_name': 'tickets.json'}})
これにより、進行状況バーが表示され、保存された情報に関する簡単な JSON が出力されるはずです:
Calculating embeddings: 100%|██████████| 1/1 [00:01<00:00, 1.21s/it]
{'embedder': {'meta': {'model': 'jina-embeddings-v2-base-en',
'usage': {'total_tokens': 20067, 'prompt_tokens': 20067}}},
'writer': {'documents_written': 31}}tagクエリパイプラインの構築
チケットを比較できるようにクエリパイプラインを作成しましょう。Haystack 2.0 では、Retriever は DocumentStore と密接に結びついています。以前に初期化した Retriever に document store を渡すことで、このパイプラインは生成したドキュメントにアクセスし、それらを reranker に渡すことができます。reranker はこれらのドキュメントを質問と直接比較し、関連性に基づいてランク付けを行います。
まず、クエリとして渡された issue と同じ issue ID または parent ID を含むチケットを除外するカスタムクリーナーを定義します:
from typing import Optional
@component
class RemoveRelated:
@component.output_types(documents=List[Document])
def run(self, tickets: List[Document], query_id: Optional[str]):
retrieved_tickets = []
for t in tickets:
if not t.meta['Issue id'] == query_id and not t.meta['Parent id'] == query_id:
retrieved_tickets.append(t)
return {'documents': retrieved_tickets}
その後、クエリを埋め込み、関連ドキュメントを取得し、選択をクリーンアップし、最後に再ランク付けを行います:
from haystack_integrations.components.embedders.jina import JinaTextEmbedder
from haystack_integrations.components.rankers.jina import JinaRanker
query_pipeline_reranker = Pipeline()
query_pipeline_reranker.add_component('query_embedder_reranker', JinaTextEmbedder(model='jina-embeddings-v2-base-en'))
query_pipeline_reranker.add_component('query_retriever_reranker', retriever_reranker)
query_pipeline_reranker.add_component('query_cleaner_reranker', RemoveRelated())
query_pipeline_reranker.add_component('query_ranker_reranker', JinaRanker())
query_pipeline_reranker.connect('query_embedder_reranker.embedding', 'query_retriever_reranker.query_embedding')
query_pipeline_reranker.connect('query_retriever_reranker', 'query_cleaner_reranker')
query_pipeline_reranker.connect('query_cleaner_reranker', 'query_ranker_reranker')
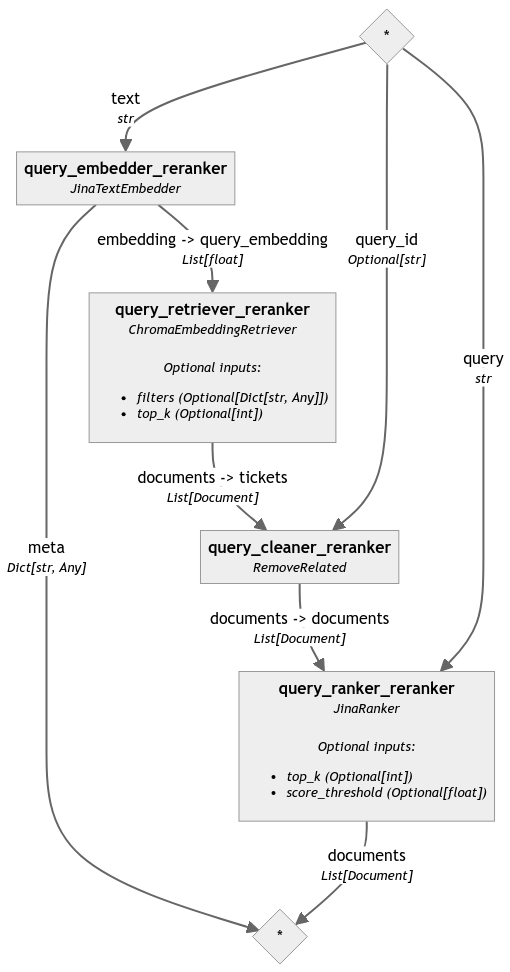
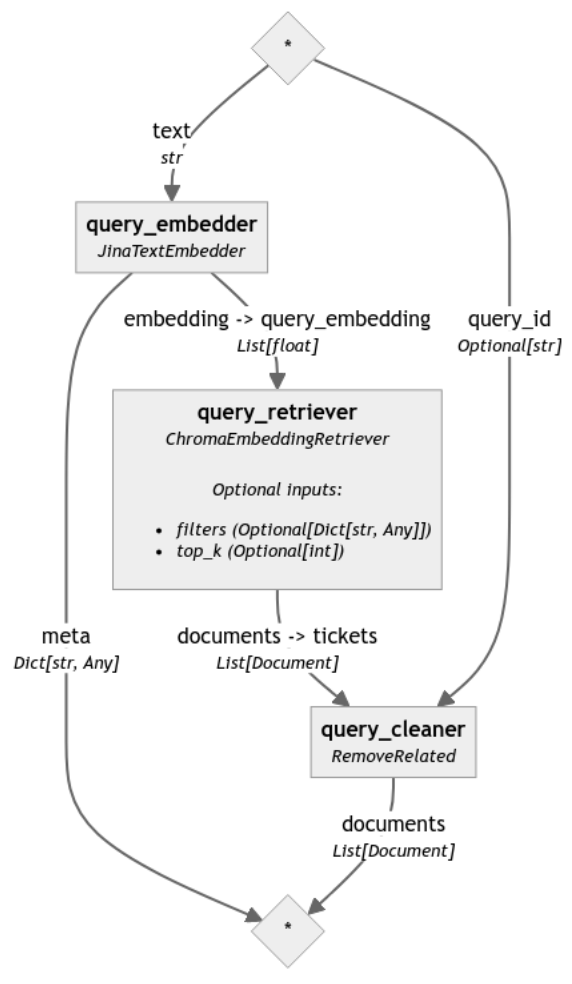
reranker による違いを強調するために、最終的な再ランク付けステップを含まない同じパイプラインを分析しました(対応するコードは読みやすさを考慮してこの投稿では省略していますが、ノートブックで確認できます):
これら 2 つのパイプラインの結果を比較するために、既存のチケット(ここでは "ZOOKEEPER-3282")の形式でクエリを定義します:
query_ticket_key = 'ZOOKEEPER-3282'
with open('tickets.json', 'r') as file:
tickets = json.load(file)
for ticket in tickets:
if ticket['Issue key'] == query_ticket_key:
query = str(ticket)
query_ticket_id = ticket['Issue id']
これは "documetations の大きなリファクタリング" に関するものです[sic]。スペルミスがあるにもかかわらず、Jina Reranker は正しく類似したチケットを取得することがわかります。
{
"Summary": "a big refactor for the documetations"
"Issue key": "ZOOKEEPER-3282"
"Issue id:: 13216608
"Parent id": ""
"Issue Type": "Task"
"Status": "In Progress"
"Project lead": "phunt"
"Priority": "Major"
"Assignee": "maoling"
"Reporter": "maoling"
"Creator": "maoling"
"Created": "19/Feb/19 11:50"
"Updated": "04/Aug/19 12:48"
"Last Viewed": "12/Mar/24 11:56"
"Description": "Hi guys: I'am working on doing a big refactor for the documetations.it aims to - 1.make a better reading experiences and help users know more about zookeeper quickly,as good as other projects' doc(e.g redis,hbase). - 2.have less changes to diff with the original docs as far as possible. - 3.solve the problem when we have some new features or improvements,but cannot find a good place to doc it. The new catalog may looks kile this: * is new one added. ** is the one to keep unchanged as far as possible. *** is the one modified. -------------------------------------------------------------- |---Overview |---Welcome ** [1.1] |---Overview ** [1.2] |---Getting Started ** [1.3] |---Release Notes ** [1.4] |---Developer |---API *** [2.1] |---Programmer's Guide ** [2.2] |---Recipes *** [2.3] |---Clients * [2.4] |---Use Cases * [2.5] |---Admin & Ops |---Administrator's Guide ** [3.1] |---Quota Guide ** [3.2] |---JMX ** [3.3] |---Observers Guide ** [3.4] |---Dynamic Reconfiguration ** [3.5] |---Zookeeper CLI * [3.6] |---Shell * [3.7] |---Configuration flags * [3.8] |---Troubleshooting & Tuning * [3.9] |---Contributor Guidelines |---General Guidelines * [4.1] |---ZooKeeper Internals ** [4.2] |---Miscellaneous |---Wiki ** [5.1] |---Mailing Lists ** [5.2] -------------------------------------------------------------- The Roadmap is: 1.(I pick up it : D) 1.1 write API[2.1], which includes the: 1.1.1 original API Docs which is a Auto-generated java doc,just give a link. 1.1.2. Restful-api (the apis under the /zookeeper-contrib-rest/src/main/java/org/apache/zookeeper/server/jersey/resources) 1.2 write Clients[2.4], which includes the: 1.2.1 C client 1.2.2 zk-python, kazoo 1.2.3 Curator etc....... look at an example from: https://redis.io/clients # write Recipes[2.3], which includes the: - integrate "Java Example" and "Barrier and Queue Tutorial"(Since some bugs in the examples and they are obsolete,we may delete something) into it. - suggest users to use the recipes implements of Curator and link to the Curator's recipes doc. # write Zookeeper CLI[3.6], which includes the: - about how to use the zk command line interface [./zkCli.sh] e.g ls /; get ; rmr;create -e -p etc....... - look at an example from redis: https://redis.io/topics/rediscli # write shell[3.7], which includes the: - list all usages of the shells under the zookeeper/bin. (e.g zkTxnLogToolkit.sh,zkCleanup.sh) # write Configuration flags[3.8], which includes the: - list all usages of configurations properties(e.g zookeeper.snapCount): - move the original Advanced Configuration part of zookeeperAdmin.md into it. look at an example from:https://coreos.com/etcd/docs/latest/op-guide/configuration.html # write Troubleshooting & Tuning[3.9], which includes the: - move the original "Gotchas: Common Problems and Troubleshooting" part of Administrator's Guide.md into it. - move the original "FAQ" into into it. - add some new contents (e.g https://www.yumpu.com/en/document/read/29574266/building-an-impenetrable-zookeeper-pdf-github). look at an example from:https://redis.io/topics/problems https://coreos.com/etcd/docs/latest/tuning.html # write General Guidelines[4.1], which includes the: - move the original "Logging" part of ZooKeeper Internals into it as the logger specification. - write specifications about code, git commit messages,github PR etc ... look at an example from: http://hbase.apache.org/book.html#hbase.commit.msg.format # write Use Cases[2.5], which includes the: - just move the context from: https://cwiki.apache.org/confluence/display/ZOOKEEPER/PoweredBy into it. - add some new contents.(e.g Apache Projects:Spark;Companies:twitter,fb) -------------------------------------------------------------- BTW: - Any insights or suggestions are very welcomed.After the dicussions,I will create a series of tickets(An umbrella) - Since these works can be done parallelly, if you are interested in them, please don't hesitate,just assign to yourself, pick it up. (Notice: give me a ping to avoid the duplicated work)."
}
最後に、クエリパイプラインを実行します。この場合、20 件のチケットを取得し、ID 関連のエントリを除外し、再ランク付けを行い、最も関連性の高い 10 件の issue を最終選択として出力します。
再ランク付け処理の前には、17 件のチケットが出力されました:
| Rank | Issue ID | Issue Key | Summary |
|---|---|---|---|
| 1 | 13191544 | ZOOKEEPER-3170 | Umbrella for eliminating ZooKeeper flaky tests |
| 2 | 13400622 | ZOOKEEPER-4375 | Quota cannot limit the specify value when multiply clients create/set znodes |
| 3 | 13249579 | ZOOKEEPER-3499 | [admin server way] Add a complete backup mechanism for zookeeper internal |
| 4 | 13295073 | ZOOKEEPER-3775 | Wrong message in IOException |
| 5 | 13268474 | ZOOKEEPER-3617 | ZK digest ACL permissions gets overridden |
| 6 | 13296971 | ZOOKEEPER-3787 | Apply modernizer-maven-plugin to build |
| 7 | 13265507 | ZOOKEEPER-3600 | support the complete linearizable read and multiply read consistency level |
| 8 | 13222060 | ZOOKEEPER-3318 | [CLI way]Add a complete backup mechanism for zookeeper internal |
| 9 | 13262989 | ZOOKEEPER-3587 | Add a documentation about docker |
| 10 | 13262130 | ZOOKEEPER-3578 | Add a new CLI: multi |
| 11 | 13262828 | ZOOKEEPER-3585 | Add a documentation about RequestProcessors |
| 12 | 13262494 | ZOOKEEPER-3583 | Add new apis to get node type and ttl time info |
| 13 | 12998876 | ZOOKEEPER-2519 | zh->state should not be 0 while handle is active |
| 14 | 13536435 | ZOOKEEPER-4696 | Update for Zookeeper latest version |
| 15 | 13297249 | ZOOKEEPER-3789 | fix the build warnings about @see,@link,@return found by IDEA |
| 16 | 12728973 | ZOOKEEPER-1983 | Append to zookeeper.out (not overwrite) to support logrotation |
| 17 | 12478629 | ZOOKEEPER-915 | Errors that happen during sync() processing at the leader do not get propagated back to the client. |
再ランカーを含めた後、クエリパイプラインを実行します:
result = query_pipeline_reranker.run(data={'query_embedder_reranker':{'text': query},
'query_retriever_reranker': {'top_k': 20},
'query_cleaner_reranker': {'query_id': query_ticket_id},
'query_ranker_reranker': {'query': query, 'top_k': 10}
}
)
for idx, res in enumerate(result['query_ranker_reranker']['documents']):
print('Doc {}:'.format(idx + 1), res)
最終出力は関連性の高い上位 10 件のチケットです:
| Rank | Issue ID | Issue Key | Summary |
|---|---|---|---|
| 1 | 13262989 | ZOOKEEPER-3587 | Add a documentation about docker |
| 2 | 13265507 | ZOOKEEPER-3600 | support the complete linearizable read and multiply read consistency level |
| 3 | 13249579 | ZOOKEEPER-3499 | [admin server way] Add a complete backup mechanism for zookeeper internal |
| 4 | 12478629 | ZOOKEEPER-915 | Errors that happen during sync() processing at the leader do not get propagated back to the client. |
| 5 | 13262828 | ZOOKEEPER-3585 | Add a documentation about RequestProcessors |
| 6 | 13297249 | ZOOKEEPER-3789 | fix the build warnings about @see,@link,@return found by IDEA |
| 7 | 12998876 | ZOOKEEPER-2519 | zh->state should not be 0 while handle is active |
| 8 | 13536435 | ZOOKEEPER-4696 | Update for Zookeeper latest version |
| 9 | 12728973 | ZOOKEEPER-1983 | Append to zookeeper.out (not overwrite) to support logrotation |
| 10 | 13222060 | ZOOKEEPER-3318 | [CLI way]Add a complete backup mechanism for zookeeper internal |
tagJina Embeddings と Reranker の利点
このチュートリアルをまとめると、Jina Embeddings、Jina Reranker、Haystack 2.0 に基づいて重複チケット特定ツールを構築しました。上記の結果は、ベクトル検索で関連文書を取得するための Jina Embeddings と、最も関連性の高いコンテンツを最終的に取得するための Jina Reranker の両方の必要性を明確に示しています。
例えば、ドキュメント追加に関する 2 つの課題「ZOOKEEPER-3585」と「ZOOKEEPER-3587」を見てみると、検索ステップ後にそれぞれ 11 位と 9 位に正しく含まれていることがわかります。文書の再ランク付け後、両方とも最も関連性の高い文書の上位 5 位以内(それぞれ 5 位と 1 位)に入り、大幅な改善が見られます。
両方のモデルを Haystack のパイプラインに統合することで、ツール全体が使用可能な状態になります。この組み合わせにより、Jina Haystack 拡張機能はアプリケーションに最適なソリューションとなります。






