


OpenAI の O1 モデルのリリース以来、AI コミュニティで最も議論されているトピックの1つはテスト時の計算リソースのスケーリングです。これは、事前学習時ではなく、推論時(AI モデルが入力に対して出力を生成する段階)に追加の計算リソースを割り当てることを指します。よく知られている例として「思考の連鎖」による多段階推論があります。これにより、モデルは複数の潜在的な回答の評価、より深い計画、最終的な応答に至るまでの自己反省など、より広範な内部検討を行うことができます。この戦略は、特に複雑な推論タスクにおいて回答の品質を向上させます。最近 Alibaba がリリースした QwQ-32B-Preview モデルも、テスト時の計算リソースを増やすことで AI の推論を改善するというこのトレンドに従っています。
OpenAI の O1 モデルを使用する際、モデルが問題を解決するために推論の連鎖を構築する際に、多段階推論に追加の時間が必要となることが明確にわかります。
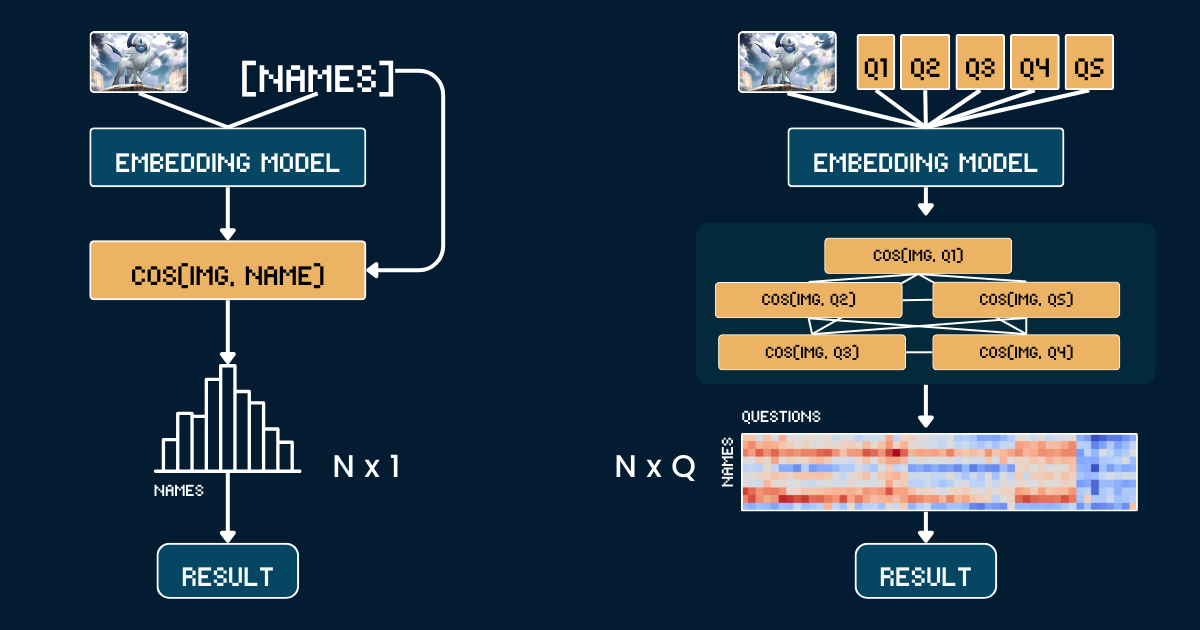
Jina AI では、LLM よりも埋め込みとリランカーに重点を置いているため、このコンテキストでテスト時の計算リソースのスケーリングを考えるのは自然なことです:「思考の連鎖」を埋め込みモデルにどのように適用できるのか?一見直感的ではないかもしれませんが、この記事では新しい視点を探り、テスト時の計算リソースのスケーリングを jina-clip に適用して、分布外(OOD)画像を分類する方法—そうでなければ不可能なタスクを解決する方法—を示します。

tagケーススタディ

TheFusion21/PokemonCards データセットを使用したポケモン分類に関する実験を行いました。このデータセットには何千もののポケモントレーディングカード画像が含まれています。このタスクは画像分類で、入力は切り取られたポケモンカードのアートワーク(すべてのテキスト/説明を削除)、出力は事前に定義されたポケモン名のセットから正しいポケモン名を選ぶというものです。このタスクは CLIP 埋め込みモデルにとって特に興味深い課題を提示します:
- ポケモンの名前と視覚的特徴はモデルにとってニッチな分布外の概念であり、直接的な分類が困難です
- 各ポケモンは CLIP がよりよく理解できる可能性のある基本的な要素(形状、色、ポーズ)に分解できる明確な視覚的特徴を持っています
- カードのアートワークは一貫した視覚フォーマットを提供しながら、背景、ポーズ、アーティスティックスタイルの変化を通じて複雑さを導入します
- このタスクは、言語モデルの複雑な推論の連鎖と同様に、複数の視覚的特徴を同時に統合する必要があります

Absol G、Aerodactyl、Weedle、Caterpie、Azumarill、Bulbasaur、Venusaur、Absol、Aggron、Beedrill δ、Alakazam、Ampharos、Dratini、Ampharos、Ampharos、Arcanine、Blaine's Moltres、Aerodactyl、Celebi & Venusaur-GX、Caterpie]tagベースライン
ベースラインのアプローチでは、ポケモンカードのアートワークと名前を単純に直接比較します。まず、各ポケモンカードの画像から、テキスト情報(ヘッダー、フッター、説明文)を切り取り、CLIP モデルがそれらのテキストに含まれるポケモンの名前から簡単に推測することを防ぎます。次に、jina-clip-v1 と jina-clip-v2 モデルを使用して、切り取った画像とポケモンの名前の両方をエンコードし、それぞれの埋め込みを取得します。分類は、これらの画像とテキストの埋め込みの間のコサイン類似度を計算することで行われ - 各画像は最も類似度スコアの高い名前とマッチングされます。これにより、追加のコンテキストや属性情報を使用せずに、カードアートワークとポケモンの名前の間で一対一のマッチングが作成されます。以下の擬似コードがベースラインの方法をまとめています。
# Preprocessing
cropped_images = [crop_artwork(img) for img in pokemon_cards] # Remove text, keep only art
pokemon_names = ["Absol", "Aerodactyl", ...] # Raw Pokemon names
# Get embeddings using jina-clip-v1
image_embeddings = model.encode_image(cropped_images)
text_embeddings = model.encode_text(pokemon_names)
# Classification by cosine similarity
similarities = cosine_similarity(image_embeddings, text_embeddings)
predicted_names = [pokemon_names[argmax(sim)] for sim in similarities]
# Evaluate
accuracy = mean(predicted_names == ground_truth_names)tag分類のための「思考の連鎖」
画像を直接名前とマッチングする代わりに、ポケモンの認識を視覚的属性の構造化されたシステムに分解します。5つの主要な属性グループを定義します:主要な色(例:「白」、「青」)、主要な形態(例:「オオカミ」、「翼のある爬虫類」)、主要な特徴(例:「一本の白い角」、「大きな翼」)、体型(例:「四足のオオカミのような」、「翼があり細身の」)、背景シーン(例:「宇宙」、「緑の森」)。
各属性グループに対して、特定のテキストプロンプト(例:「このポケモンの体は主に{}色です」)と関連するオプションをペアにして作成します。そして、モデルを使用して画像と各属性オプションの間の類似度スコアを計算します。これらのスコアは、より較正された信頼度の測定値を得るために、softmax を使用して確率に変換されます。
思考の連鎖(CoT)の完全な構造は2つの部分から構成されています:プロンプトのグループを記述する classification_groups と、各ポケモンがどの属性オプションにマッチすべきかを定義する pokemon_rules です。例えば、Absol は色が「白」、形態が「オオカミのような」とマッチするはずです。完全な CoT は以下の通りです(これがどのように構築されるかは後で説明します):
pokemon_system = {
"classification_cot": {
"dominant_color": {
"prompt": "This Pokémon's body is mainly {} in color.",
"options": [
"white", # Absol, Absol G
"gray", # Aggron
"brown", # Aerodactyl, Weedle, Beedrill δ
"blue", # Azumarill
"green", # Bulbasaur, Venusaur, Celebi&Venu, Caterpie
"yellow", # Alakazam, Ampharos
"red", # Blaine's Moltres
"orange", # Arcanine
"light blue"# Dratini
]
},
"primary_form": {
"prompt": "It looks like {}.",
"options": [
"a wolf", # Absol, Absol G
"an armored dinosaur", # Aggron
"a winged reptile", # Aerodactyl
"a rabbit-like creature", # Azumarill
"a toad-like creature", # Bulbasaur, Venusaur, Celebi&Venu
"a caterpillar larva", # Weedle, Caterpie
"a wasp-like insect", # Beedrill δ
"a fox-like humanoid", # Alakazam
"a sheep-like biped", # Ampharos
"a dog-like beast", # Arcanine
"a flaming bird", # Blaine's Moltres
"a serpentine dragon" # Dratini
]
},
"key_trait": {
"prompt": "Its most notable feature is {}.",
"options": [
"a single white horn", # Absol, Absol G
"metal armor plates", # Aggron
"large wings", # Aerodactyl, Beedrill δ
"rabbit ears", # Azumarill
"a green plant bulb", # Bulbasaur, Venusaur, Celebi&Venu
"a small red spike", # Weedle
"big green eyes", # Caterpie
"a mustache and spoons", # Alakazam
"a glowing tail orb", # Ampharos
"a fiery mane", # Arcanine
"flaming wings", # Blaine's Moltres
"a tiny white horn on head" # Dratini
]
},
"body_shape": {
"prompt": "The body shape can be described as {}.",
"options": [
"wolf-like on four legs", # Absol, Absol G
"bulky and armored", # Aggron
"winged and slender", # Aerodactyl, Beedrill δ
"round and plump", # Azumarill
"sturdy and four-legged", # Bulbasaur, Venusaur, Celebi&Venu
"long and worm-like", # Weedle, Caterpie
"upright and humanoid", # Alakazam, Ampharos
"furry and canine", # Arcanine
"bird-like with flames", # Blaine's Moltres
"serpentine" # Dratini
]
},
"background_scene": {
"prompt": "The background looks like {}.",
"options": [
"outer space", # Absol G, Beedrill δ
"green forest", # Azumarill, Bulbasaur, Venusaur, Weedle, Caterpie, Celebi&Venu
"a rocky battlefield", # Absol, Aggron, Aerodactyl
"a purple psychic room", # Alakazam
"a sunny field", # Ampharos
"volcanic ground", # Arcanine
"a red sky with embers", # Blaine's Moltres
"a calm blue lake" # Dratini
]
}
},
"pokemon_rules": {
"Absol": {
"dominant_color": 0,
"primary_form": 0,
"key_trait": 0,
"body_shape": 0,
"background_scene": 2
},
"Absol G": {
"dominant_color": 0,
"primary_form": 0,
"key_trait": 0,
"body_shape": 0,
"background_scene": 0
},
// ...
}
}
最終的な分類は、これらの属性確率を組み合わせます - 単一の類似度比較の代わりに、複数の構造化された比較を行い、より情報に基づいた決定を行うためにそれらの確率を集約します。
# Classification process
def classify_pokemon(image):
# Generate all text prompts
all_prompts = []
for group in classification_cot:
for option in group["options"]:
prompt = group["prompt"].format(option)
all_prompts.append(prompt)
# Get embeddings and similarities
image_embedding = model.encode_image(image)
text_embeddings = model.encode_text(all_prompts)
similarities = cosine_similarity(image_embedding, text_embeddings)
# Convert to probabilities per attribute group
probabilities = {}
for group_name, group_sims in group_similarities:
probabilities[group_name] = softmax(group_sims)
# Score each Pokemon based on matching attributes
scores = {}
for pokemon, rules in pokemon_rules.items():
score = 0
for group, target_idx in rules.items():
score += probabilities[group][target_idx]
scores[pokemon] = score
return max(scores, key=scores.get)tag複雑さの分析
画像を N 個のポケモンの名前のいずれかに分類したいとします。ベースラインのアプローチでは、N 個のテキスト埋め込み(各ポケモンの名前に1つずつ)を計算する必要があります。対照的に、私たちのスケーリングされたテスト時の計算アプローチでは、Q 個のテキスト埋め込みを計算する必要があります。ここで、
Q は、すべての質問におけるオプションと質問の組み合わせの総数です。両方の手法では、1つの画像埋め込みの計算と最終的な分類ステップが必要ですが、これらの共通の処理は比較から除外しています。このケーススタディでは、N=13、Q=52 となっています。極端なケースで Q = N の場合、我々のアプローチはベースラインと本質的に同じになります。しかし、テスト時の計算をより効果的にスケールさせるためのポイントは:
Qを増やすように慎重に選ばれた質問を作成する- 各質問が最終的な答えについて異なる有益な手がかりを提供することを確認する
- 質問が可能な限り直交するように設計し、共同情報利得を最大化する
このアプローチは「20の質問」ゲームに似ており、各質問は可能な答えを効果的に絞り込むために戦略的に選ばれます。
tag評価
評価は13種類のポケモンクラスにわたる117のテスト画像で実施されました。結果は以下の通りです:
| Approach | jina-clip-v1 | jina-clip-v2 |
|---|---|---|
| Baseline | 31.36% | 16.10% |
| CoT | 46.61% | 38.14% |
| Improvement | +15.25% | +22.04% |
同じ CoT 分類が、この一般的ではない、もしくは OOD タスクにおいて、両モデルで大幅な改善(それぞれ +15.25% と +22.04%)をもたらしていることがわかります。これは pokemon_system が構築されれば、同じ CoT システムを異なるモデル間で効果的に転移できること、そしてファインチューニングやポストトレーニングが不要であることを示しています。
v1 のポケモン分類におけるベースラインのパフォーマンス(31.36%)が比較的高いことは注目に値します。このモデルはポケモン関連のコンテンツを含む LAION-400M で訓練されました。一方、v2 は DFN-2B(400M インスタンスをサブサンプリング)で訓練され、より質の高いがフィルタリングされたデータセットであり、ポケモン関連のコンテンツが除外されていた可能性があり、このタスクにおける v2 の低いベースラインパフォーマンス(16.10%)を説明しています。
tag効果的な pokemon_system の構築
スケールされたテスト時の計算アプローチの効果は、pokemon_system をどれだけうまく構築できるかに大きく依存します。このシステムを構築するには、手動から完全自動化まで、さまざまなアプローチがあります。
手動構築
最も直接的なアプローチは、ポケモンデータセットを手動で分析し、属性グループ、プロンプト、ルールを作成することです。ドメインエキスパートは、色、形状、特徴的な要素などの主要な視覚的属性を特定する必要があります。その後、各属性に対する自然言語プロンプトを作成し、各属性グループの可能なオプションを列挙し、各ポケモンを正しい属性オプションにマッピングします。これは高品質なルールを提供しますが、時間がかかり、より大きな N へのスケーリングが難しくなります。
LLM 支援による構築
分類システムを生成するようLLMにプロンプトを与えることで、このプロセスを加速できます。適切に構造化されたプロンプトは、視覚的特徴に基づく属性グループ、自然言語プロンプトテンプレート、包括的で相互排他的なオプション、そして各ポケモンのマッピングルールを要求します。LLM は素早く最初の草案を生成できますが、その出力は検証が必要かもしれません。
I need help creating a structured system for Pokemon classification. For each Pokemon in this list: [Absol, Aerodactyl, Weedle, Caterpie, Azumarill, ...], create a classification system with:
1. Classification groups that cover these visual attributes:
- Dominant color of the Pokemon
- What type of creature it appears to be (primary form)
- Its most distinctive visual feature
- Overall body shape
- What kind of background/environment it's typically shown in
2. For each group:
- Create a natural language prompt template using "{}" for the option
- List all possible options that could apply to these Pokemon
- Make sure options are mutually exclusive and comprehensive
3. Create rules that map each Pokemon to exactly one option per attribute group, using indices to reference the options
Please output this as a Python dictionary with two main components:
- "classification_groups": containing prompts and options for each attribute
- "pokemon_rules": mapping each Pokemon to its correct attribute indices
Example format:
{
"classification_groups": {
"dominant_color": {
"prompt": "This Pokemon's body is mainly {} in color",
"options": ["white", "gray", ...]
},
...
},
"pokemon_rules": {
"Absol": {
"dominant_color": 0, # index for "white"
...
},
...
}
}より堅牢なアプローチは、LLM による生成と人間による検証を組み合わせることです。まず、LLM が初期システムを生成します。次に、人間の専門家が属性グループ、オプションの完全性、ルールの正確性を確認して修正します。LLM はこのフィードバックに基づいてシステムを改良し、満足のいく品質が得られるまでこのプロセスを繰り返します。このアプローチは効率性と正確性のバランスを取ります。
DSPy を使用した自動構築
完全に自動化されたアプローチとして、DSPy を使用して pokemon_system を反復的に最適化することができます。このプロセスは、手動または LLM で書かれた単純な pokemon_system を初期プロンプトとして始まります。各バージョンはホールドアウトセットで評価され、精度を DSPy へのフィードバック信号として使用します。このパフォーマンスに基づいて、最適化されたプロンプト(つまり、pokemon_system の新バージョン)が生成されます。このサイクルは収束するまで繰り返され、この全プロセスの間、埋め込みモデルは完全に固定されたままです。
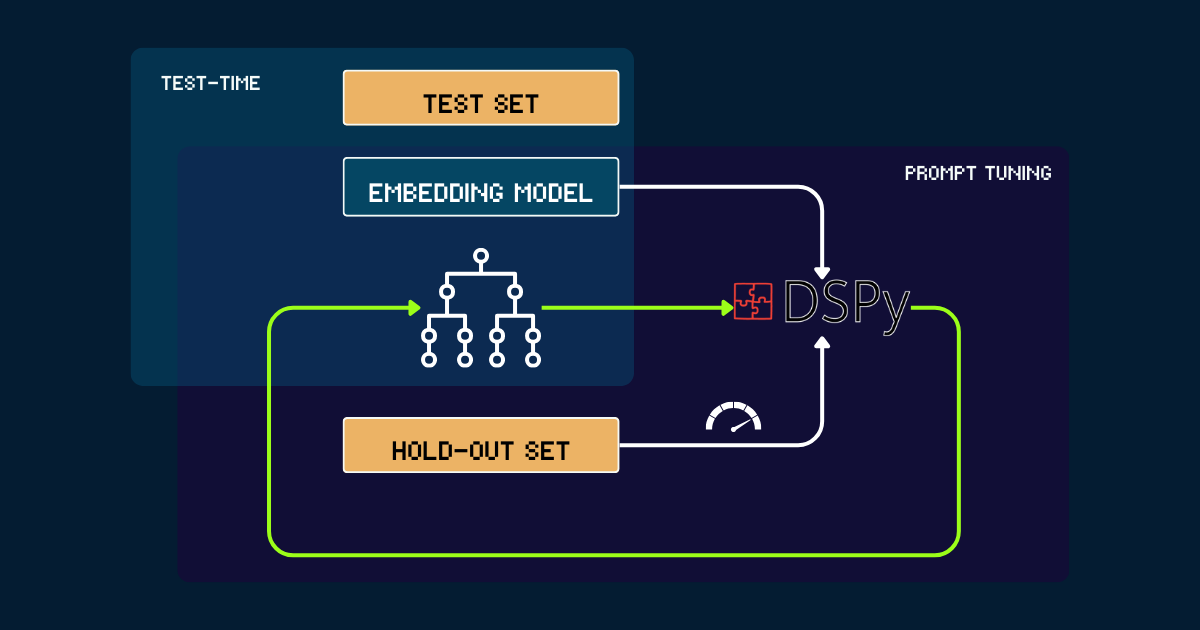
pokemon_system CoT デザインを見つける;チューニングプロセスは各タスクに対して1回だけ行えばよい。tag埋め込みモデルのテスト時計算をスケールする理由
事前学習のスケーリングが最終的に経済的に実現不可能になるためです。
Jina 埋め込みスイート(jina-embeddings-v1、v2、v3、jina-clip-v1、v2、jina-ColBERT-v1、v2 を含む)のリリース以来、スケールされた事前学習を通じた各モデルのアップグレードにはより多くのコストがかかっています。例えば、2023年6月にリリースされた最初のモデル jina-embeddings-v1 は110Mパラメータでした。当時の訓練コストは、測定方法によって5,000ドルから10,000ドルの間でした。jina-embeddings-v3 では改善は顕著ですが、それは主に投入された資源の増加によるものです。フロンティアモデルのコスト軌道は、数千ドルから数万ドル、そして大手AI企業では今日では数億ドルにまで上っています。事前学習により多くのお金、リソース、データを投入することで、より良いモデルが得られますが、限界収益は最終的に更なるスケーリングを経済的に持続不可能にします。

一方で、現代の埋め込みモデルはますますパワフルになっています:多言語、マルチタスク、マルチモーダル、そしてゼロショットや指示に従う強力な性能を備えています。この汎用性は、アルゴリズムの改善とテスト時計算のスケーリングに大きな余地を残しています。
そこで問題となるのは、ユーザーが深く気にかけるクエリに対してどの程度のコストを払う意思があるかということです。固定された事前学習モデルで推論時間が長くなることを許容することで結果の質が大幅に向上するのであれば、多くの人々はそれを価値があると考えるでしょう。我々の見解では、埋め込みモデルのテスト時計算のスケーリングには大きな未開拓の可能性があります。これは、単にトレーニング時のモデルサイズを増やすことから、より良いパフォーマンスを達成するために推論フェーズでの計算努力を強化することへのシフトを表しています。
tag結論
jina-clip-v1/v2 のテスト時計算に関するケーススタディから、以下の主要な発見が得られました:
- 埋め込みのファインチューニングやポストトレーニングを行わずに、一般的でないデータや分布外(OOD)データでより良いパフォーマンスを達成しました。
- 類似度検索と分類基準を反復的に改善することで、システムはより微妙な区別を行えるようになりました。
- 動的なプロンプト調整と反復的な推論を組み込むことで、埋め込みモデルの推論プロセスを単一のクエリから、より洗練された思考の連鎖へと変換しました。
このケーススタディは、テスト時計算で可能なことの表面をかすっただけです。アルゴリズム的なスケーリングにはまだ大きな余地があります。例えば、「20の質問」ゲームの最適な戦略のように、解答空間を最も効率的に絞り込む質問を反復的に選択する方法を開発できます。テスト時計算をスケールすることで、埋め込みモデルを現在の限界を超えて押し進め、かつては手の届かないと思われた、より複雑で微妙なタスクに取り組めるようにすることができます。
