


Jina AI は、最先端のリランカーモデルファミリーの新モデルを発表し、AWS Sagemaker と Hugging Face で利用可能になりました:jina-reranker-v1-turbo-en と jina-reranker-v1-tiny-en。これらのモデルは、標準的なベンチマークで高性能を維持しながら速度とサイズを優先し、応答時間とリソース使用が重要な環境において、より高速でメモリ効率の良いリランキングプロセスを提供します。




Reranker Turbo と Tiny は、情報検索アプリケーションにおいて超高速な応答時間を実現するように最適化されています。私たちの埋め込みモデルと同様に、これらは JinaBERT アーキテクチャを使用しており、これは BERT アーキテクチャにALiBi の対称双方向バリアントを加えたものです。このアーキテクチャにより、最大 8,192 トークンまでの長いテキストシーケンスをサポートし、より大きな文書の深い分析や詳細な言語理解を必要とする複雑なクエリに理想的です。
Turbo と Tiny モデルは、Jina Reranker v1 から得られた知見を活用しています。リランキングは情報検索アプリケーションの主要なボトルネックとなる可能性があります。従来の検索アプリケーションは非常に成熟した技術であり、その性能は十分に理解されています。リランカーはテキストベースの検索に高い精度を加えますが、AI モデルは大きく、実行が遅く、コストがかかる可能性があります。
多くのユーザーは、精度が多少犠牲になっても、より小さく、より速く、より安価なモデルを好むでしょう。検索結果のリランキングという単一の目標があることで、モデルを効率化し、よりコンパクトなモデルで競争力のある性能を提供することが可能になります。隠れ層を減らすことで、処理を高速化しモデルサイズを削減します。これらのモデルは実行コストが低く、より高速なため、遅延を許容できないアプリケーションにより適しており、同時に大きなモデルの性能をほぼ完全に維持しています。
この記事では、Reranker Turbo と Reranker Tiny のアーキテクチャを紹介し、その性能を測定し、使い方を説明します。
tag効率化されたアーキテクチャ
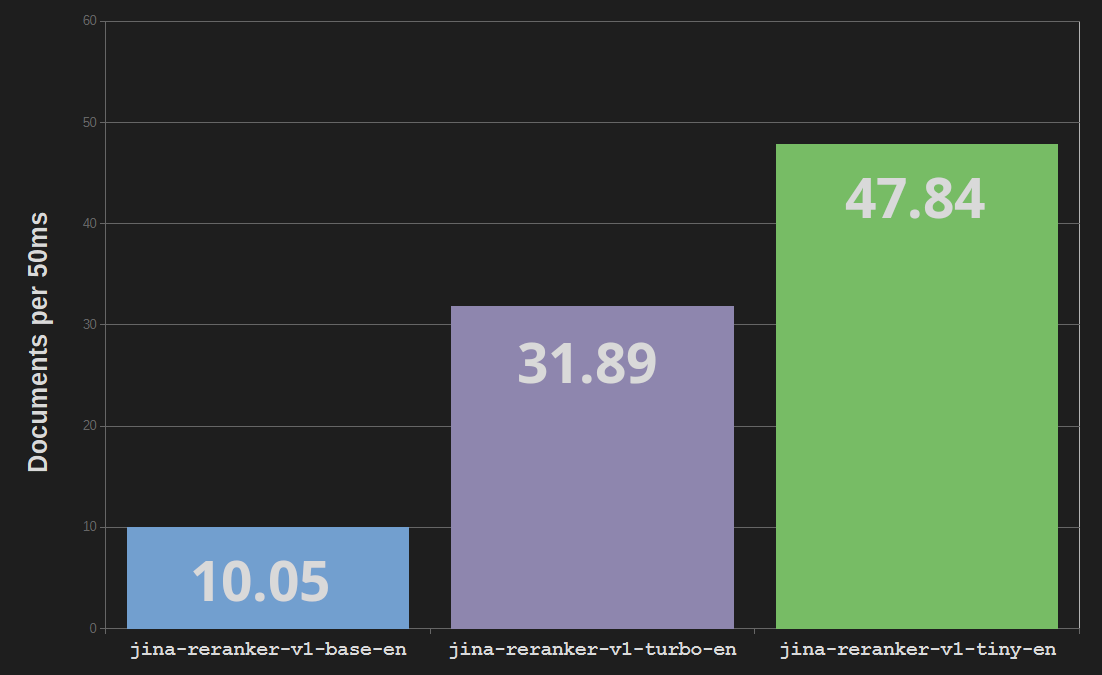
Jina Reranker Turbo(jina-reranker-v1-turbo-en)は、6 層のアーキテクチャを使用し、パラメータ総数は 3,780 万で、ベースリランカーモデル jina-reranker-v1-base-en の 1 億 3,700 万パラメータと 12 層と比較して、モデルサイズを 4 分の 1 に削減し、処理速度を最大 3 倍に向上させています。
Reranker Tiny(jina-reranker-v1-tiny-en)は、4 層で 3,300 万パラメータを使用し、さらに並列処理を強化し高速化を実現しています – ベース Reranker モデルの約 5 倍の速さを実現し、Turbo モデルと比べてメモリコストを 13% 削減しています。
tag知識蒸留
Reranker Turbo と Tiny は、知識蒸留を使用して訓練されています。これは、既存の AI モデルを使用して、別のモデルを同じような動作をするように訓練する技術です。外部データソースを使用する代わりに、既存のモデルを使用して訓練用のデータを生成します。私たちは Jina Reranker ベースモデルを使用して文書コレクションをランク付けし、その結果を使用して Turbo と Tiny の両方を訓練しました。このように、実世界のデータに制限されないため、より多くのデータを訓練プロセスに取り入れることができます。
これは、生徒が教師から学ぶようなものです:すでに訓練された高性能モデル – Jina Reranker Base モデル – が「教師」として、未訓練の Jina Turbo と Jina Tiny モデルに新しい訓練データを生成することで「教える」のです。この技術は、大きなモデルから小さなモデルを作成するために広く使用されています。最良の場合、「教師」モデルと「生徒」モデルのタスク性能の差は非常に小さくなります。
tagBEIR での評価
効率化と知識蒸留の利点は、性能品質をほとんど犠牲にすることなく得られます。情報検索のための BEIR ベンチマークにおいて、jina-reranker-v1-turbo-en は jina-reranker-v1-base-en の精度の 95% 近くをスコアし、jina-reranker-v1-tiny-en はベースモデルのスコアの 92.5% をスコアしています。
すべての Jina Reranker モデルは、その多くがはるかに大きなサイズを持つ他の一般的なリランカーモデルと競争力があります。
| モデル | BEIR スコア (NDCC@10) | パラメータ |
|---|---|---|
| Jina Reranker モデル | ||
| jina-reranker-v1-base-en | 52.45 | 137M |
| jina-reranker-v1-turbo-en | 49.60 | 38M |
| jina-reranker-v1-tiny-en | 48.54 | 33M |
| その他のリランキングモデル | ||
mxbai-rerank-base-v1 |
49.19 | 184M |
mxbai-rerank-xsmall-v1 |
48.80 | 71M |
ms-marco-MiniLM-L-6-v2 |
48.64 | 23M |
bge-reranker-base |
47.89 | 278M |
ms-marco-MiniLM-L-4-v2 |
47.81 | 19M |
NDCC@10: 上位 10 件の結果に対する正規化割引累積利得を使用して計算されたスコア。
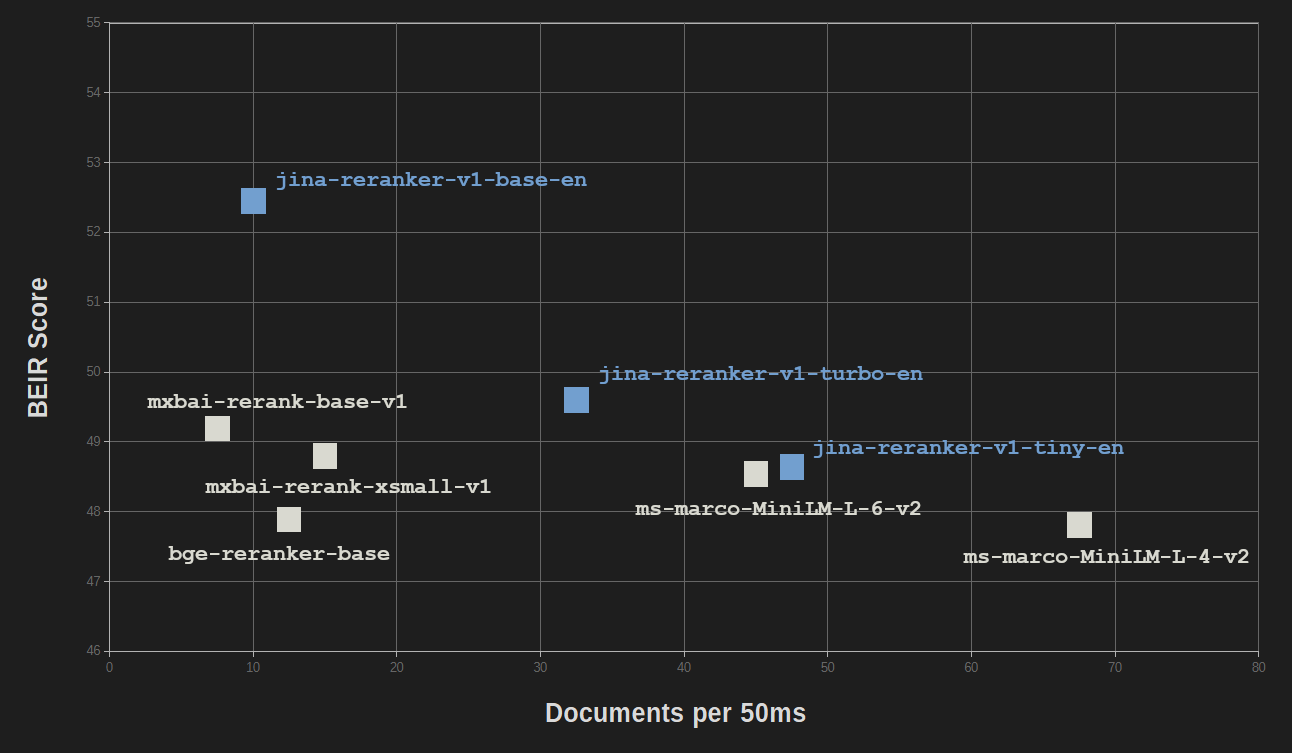
MiniLM-L6(ms-marco-MiniLM-L-6-v2)とMiniLM-L4(ms-marco-MiniLM-L-4-v2)のみが同程度のサイズと速度を持ち、jina-reranker-v1-turbo-enとjina-reranker-v1-tiny-enは同等かそれ以上のパフォーマンスを示しています。
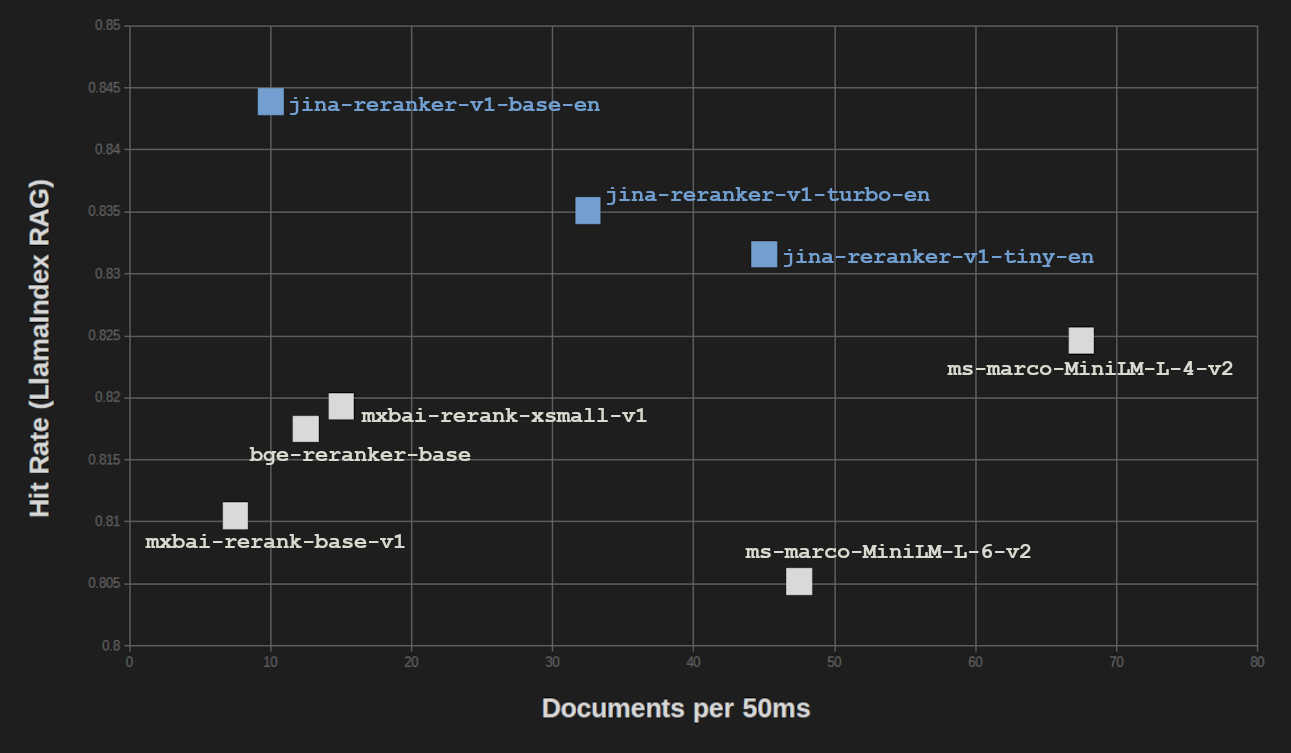
LlamaIndex RAG ベンチマークでも同様の結果が得られています。ベクトル検索用の3つの埋め込みモデル(jina-embeddings-v2-base-en、bge-base-en-v1.5、Cohere-embed-english-v3.0)を使用して RAG セットアップで3つの Jina Reranker すべてをテストし、スコアを平均化しました。
| Reranker Model | Avg. Hit Rate | Avg. MRR |
|---|---|---|
| Jina Reranker models | ||
| jina-reranker-v1-base-en | 0.8439 | 0.7006 |
| jina-reranker-v1-turbo-en | 0.8351 | 0.6498 |
| jina-reranker-v1-tiny-en | 0.8316 | 0.6761 |
| Other reranking models | ||
mxbai-rerank-base-v1 |
0.8105 | 0.6583 |
mxbai-rerank-xsmall-v1 |
0.8193 | 0.6673 |
ms-marco-MiniLM-L-6-v2 |
0.8052 | 0.6121 |
bge-reranker-base |
0.8175 | 0.6480 |
ms-marco-MiniLM-L-4-v2 |
0.8246 | 0.6354 |
MRR:平均逆順位
検索拡張生成(RAG)タスクにおいては、BEIR の純粋な情報検索ベンチマークと比べて、結果の品質の低下はさらに少なくなっています。そして RAG のパフォーマンスを処理速度と比較すると、ms-marco-MiniLM-L-4-v2のみが大幅に高いスループットを提供していますが、それは結果の品質を大きく犠牲にしています。
tagAWS でのコスト削減
Reranker Turbo と Reranker Tiny を使用することで、メモリ使用量と CPU 時間に課金される AWS と Azure のユーザーは大幅なコスト削減を実現できます。使用ケースによって節約の程度は異なりますが、メモリ使用量の約75%削減だけでも、メモリに課金するクラウドシステムでは75%のコスト削減に直接つながります。
さらに、スループットが速いため、より安価な AWS インスタンスでより多くのクエリを実行できます。
tagはじめに
Jina Reranker モデルは使いやすく、アプリケーションやワークフローに簡単に統合できます。Reranker API ページにアクセスして、サービスの使用方法を確認し、100万トークンの無料アクセスを利用して試すことができます。

私たちのモデルはAWS SageMaker でも利用可能です。詳細については、AWS で検索拡張生成システムを設定する方法に関するチュートリアルをご覧ください。

Jina Reranker モデルは、Apache 2.0 ライセンスの下で Hugging Face からダウンロードすることもできます:
