



2023年10月、私たちは最長8,192トークンまでの入力を処理できる初のオープンソース埋め込みモデルファミリー「jina-embeddings-v2」を発表しました。これを基に、今年は同様の広範な入力サポートとさらなる機能を備えた「jina-embeddings-v3」をリリースしました。

この投稿では、長文コンテキスト埋め込みについて掘り下げ、いくつかの疑問に答えていきます:大量のテキストを1つのベクトルにまとめることは実用的なのか?セグメント化は検索を改善するのか、そしてどのように?ドキュメントの異なる部分のコンテキストをセグメント化しながら保持するにはどうすればよいのか?
これらの疑問に答えるため、以下のような埋め込み生成方法を比較します:
- 長文コンテキスト埋め込み(ドキュメントで最大8,192トークン)vs 短文コンテキスト(192トークンで切り捨て)
- チャンク分割なし vs 単純チャンク分割 vs 後期チャンク分割
- 単純チャンク分割と後期チャンク分割での異なるチャンクサイズ
tag長文コンテキストは本当に有用なのか?
1つの埋め込みで約10ページのテキストをエンコードできる機能により、長文コンテキスト埋め込みモデルは大規模なテキスト表現の可能性を開きます。しかし、それは本当に有用なのでしょうか?多くの人々によれば…そうではありません。




出典:How AI Is Built ポッドキャストでの Nils Reimer の発言、brainlag のツイート、egorfine の Hacker News コメント、andy99 の Hacker News コメント
これらの懸念に対して、長文コンテキスト機能の詳細な調査、長文コンテキストが有用な場合、そしていつ使用すべき(または使用すべきでない)かを見ていきます。まずは、これらの懐疑的な意見を聞き、長文コンテキスト埋め込みモデルが直面する問題を見てみましょう。
tag長文コンテキスト埋め込みの問題点
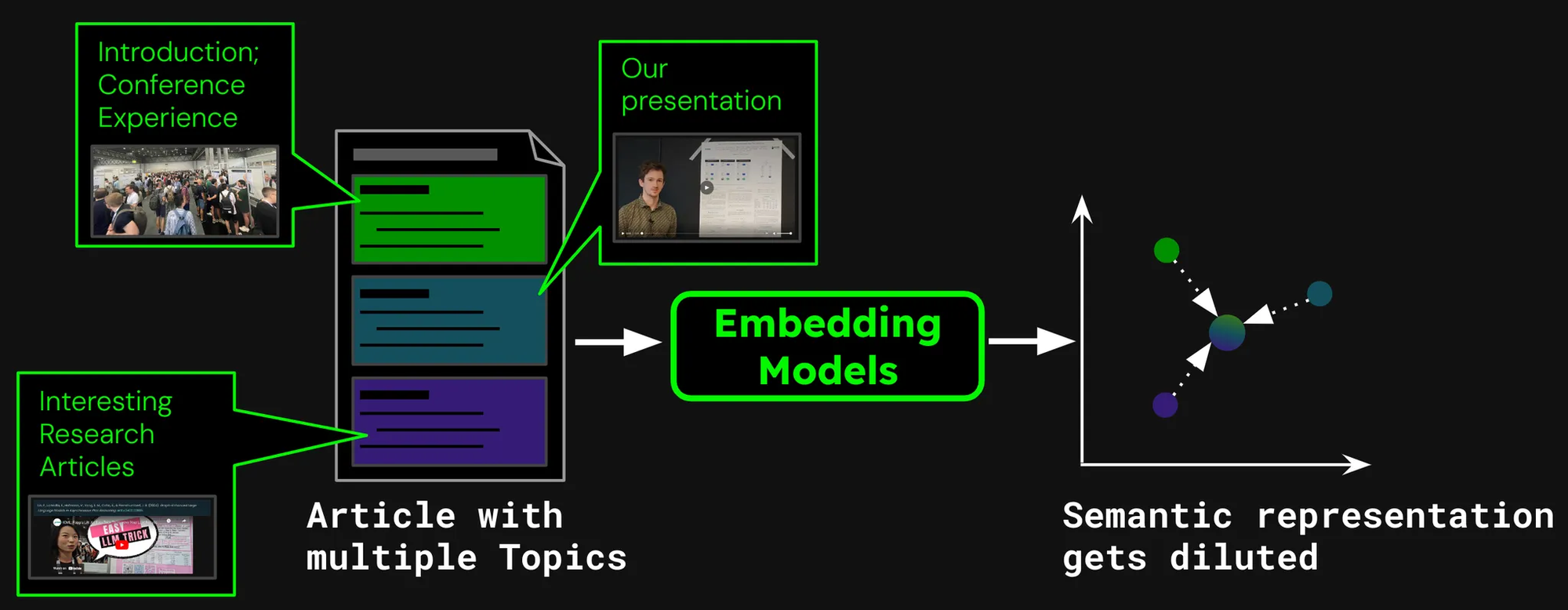
Jina AI ブログのような記事のドキュメント検索システムを構築しているとします。時には1つの記事が複数のトピックをカバーすることがあります。例えば、ICML 2024カンファレンスの参加レポートには以下が含まれています:
- ICML に関する一般的な情報(参加者数、場所、範囲など)を含む序文
- 私たちの研究発表(jina-clip-v1)
- ICML で発表された他の興味深い研究論文のまとめ
この記事に対して1つの埋め込みを作成すると、その埋め込みは3つの異なるトピックの混合を表現することになります:
これにより以下の問題が生じます:
- 表現の希薄化:テキスト内のすべてのトピックは関連している可能性がありますが、ユーザーの検索クエリに関連するのは1つだけかもしれません。しかし、単一の埋め込み(この場合、ブログ投稿全体の埋め込み)はベクトル空間内の1点でしかありません。モデルの入力にテキストが追加されるにつれ、埋め込みは記事全体のトピックを捉えるようにシフトし、特定の段落のコンテンツを表現する効果が低下します。
- 容量の制限:埋め込みモデルは入力の長さに関係なく、固定サイズのベクトルを生成します。入力コンテンツが増えるほど、モデルがこれらの情報をベクトルで表現することが難しくなります。これは画像を16×16ピクセルにダウンスケールするようなものです — りんごのような単純なものの画像なら、スケールダウンしても意味を理解できます。しかし、ベルリンの街路地図をスケールダウンすると?そうはいきません。
- 情報の損失:場合によっては、長文コンテキスト埋め込みモデルでも限界に達します。多くのモデルは最大8,192トークンまでのテキストエンコードをサポートしています。より長いドキュメントは埋め込み前に切り捨てる必要があり、情報の損失につながります。ユーザーに関連する情報がドキュメントの末尾にある場合、それは埋め込みに全く捉えられません。
- テキストのセグメント化が必要な場合もある:一部のアプリケーションでは、ドキュメント全体ではなく、テキストの特定のセグメントの埋め込みが必要です。例えば、テキスト内の関連する段落を特定する場合などです。
tag長文コンテキスト vs 切り捨て
長文コンテキストが本当に価値があるかどうかを確認するため、2つの検索シナリオのパフォーマンスを見てみましょう:
- 最大8,192トークン(約10ページのテキスト)までのドキュメントのエンコード
- 192トークンでドキュメントを切り捨て、そこまでをエンコード
以下の結果を比較します:jina-embeddings-v3 の nDCG@10 検索メトリックでテストしました。以下のデータセットをテストしました:
| データセット | 説明 | クエリ例 | ドキュメント例 | 平均ドキュメント長(文字数) |
|---|---|---|---|---|
| NFCorpus | 主に PubMed からの 3,244 件のクエリとドキュメントを含む医療検索データセット。 | "Using Diet to Treat Asthma and Eczema" | "Statin Use and Breast Cancer Survival: A Nationwide Cohort Study from Finland Recent studies have suggested that [...]" | 326,753 |
| QMSum | 関連する会議セグメントの要約を必要とするクエリベースの会議要約データセット。 | "The professor was the one to raise the issue and suggested that a knowledge engineering trick [...]" | "Project Manager: Is that alright now ? {vocalsound} Okay . Sorry ? Okay , everybody all set to start the meeting ? [...]" | 37,445 |
| NarrativeQA | 長い物語と特定の内容に関する質問を含む QA データセット。 | "What kind of business Sophia owned in Paris?" | "The Project Gutenberg EBook of The Old Wives' Tale, by Arnold Bennett\n\nThis eBook is for the use of anyone anywhere [...]" | 53,336 |
| 2WikiMultihopQA | ショートカットを避けるようテンプレートで設計された、最大 5 段階の推論ステップを持つマルチホップ QA データセット。 | "What is the award that the composer of song The Seeker (The Who Song) earned?" | "Passage 1:\nMargaret, Countess of Brienne\nMarguerite d'Enghien (born 1365 - d. after 1394), was the ruling suo jure [...]" | 30,854 |
| SummScreenFD | 分散したプロットの統合を必要とする TV シリーズの台本とあらすじを含む脚本要約データセット。 | "Penny gets a new chair, which Sheldon enjoys until he finds out that she picked it up from [...]" | "[EXT. LAS VEGAS CITY (STOCK) - NIGHT]\n[EXT. ABERNATHY RESIDENCE - DRIVEWAY -- NIGHT]\n(The lamp post light over the [...]" | 1,613 |
見て分かる通り、192 トークン以上をエンコードすることで顕著な性能向上が得られます:
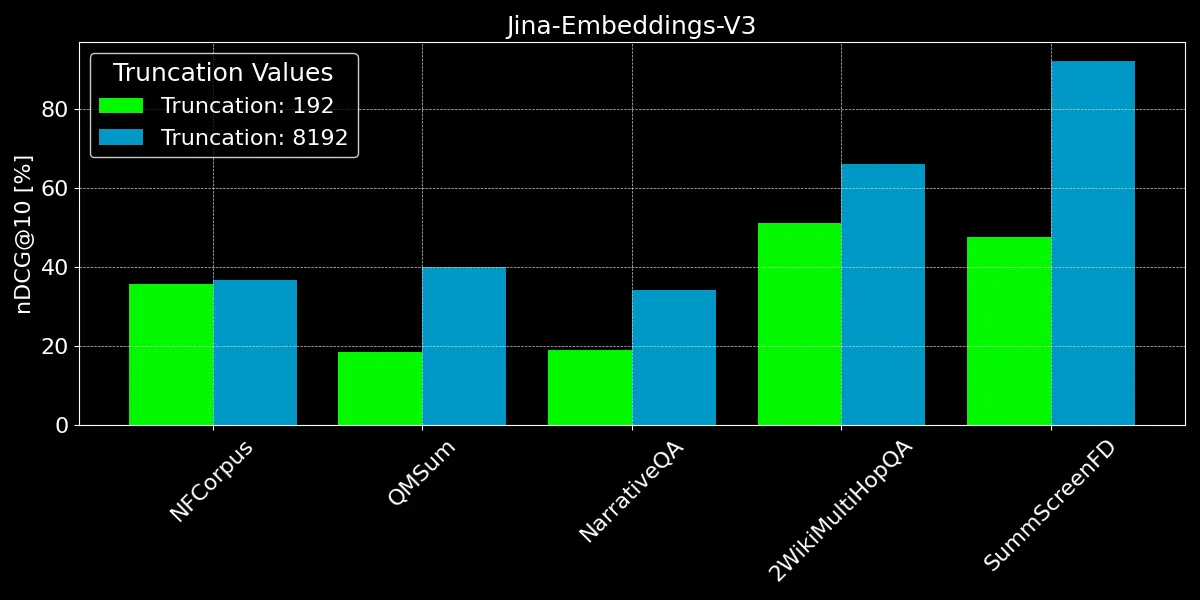
ただし、データセットによって改善の度合いは異なります:
- NFCorpus では、切り捨てはほとんど影響を与えません。これは、タイトルと要約がドキュメントの先頭にあり、一般的なユーザーの検索語に非常に関連性が高いためです。切り捨てられているかどうかに関わらず、最も関連性の高いデータはトークン制限内に収まっています。
- QMSum と NarrativeQA は、ユーザーが通常テキスト内の特定の事実を検索する「読解」タスクとみなされます。これらの事実は、しばしばドキュメント全体に散らばった詳細の中に埋め込まれており、192 トークンの制限を超えることがあります。例えば、NarrativeQA のドキュメント『Percival Keene』では、「Percival の昼食を盗むいじめっ子は誰?」という質問の答えはこの制限をはるかに超えた位置にあります。同様に、2WikiMultiHopQA では、関連情報がドキュメント全体に分散しており、クエリに効果的に答えるためにモデルは複数のセクションから知識を収集して統合する必要があります。
- SummScreenFD は、与えられた要約に対応する脚本を特定することを目的としたタスクです。要約は脚本全体に分散した情報を含むため、より多くのテキストをエンコードすることで、要約と正しい脚本のマッチング精度が向上します。
tagより良い検索性能のためのテキストセグメント化
• セグメント化:入力テキストの境界キューを検出すること。例えば、文や固定数のトークンなど。
• ナイーブチャンキング:セグメント化のキューに基づいてテキストをチャンクに分割すること(エンコード前)。
• レイトチャンキング:まずドキュメントをエンコードしてから、セグメント化すること(チャンク間のコンテキストを保持)。
ドキュメント全体を 1 つのベクトルに埋め込む代わりに、境界キューを割り当てることでドキュメントを最初にセグメント化するさまざまな方法があります:

一般的な方法には以下があります:
- 固定サイズによるセグメント化: ドキュメントを埋め込みモデルのトークナイザーによって決定された固定数のトークンに分割します。これにより、セグメントのトークン化が全体のドキュメントのトークン化と対応することを保証します(特定の文字数でセグメント化すると異なるトークン化につながる可能性があります)。
- 文によるセグメント化: ドキュメントを文に分割し、各チャンクは n 個の文で構成されます。
- 意味によるセグメント化: 各セグメントは複数の文に対応し、埋め込みモデルが連続する文の類似性を判断します。埋め込みの類似性が高い文は同じチャンクに割り当てられます。
簡単のため、この記事では固定サイズのセグメント化を使用します。
tagナイーブチャンキングを使用したドキュメント検索
固定サイズのセグメント化を実行した後、それらのセグメントに従ってナイーブにドキュメントをチャンク化できます:
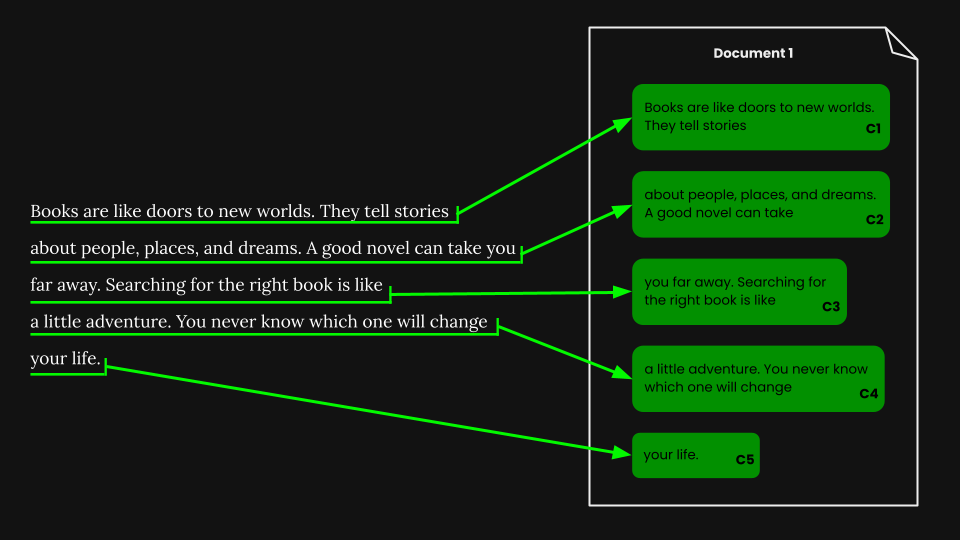
jina-embeddings-v3 を使用して、各チャンクをその意味を正確に捉えた埋め込みにエンコードし、それらの埋め込みをベクターデータベースに保存します。
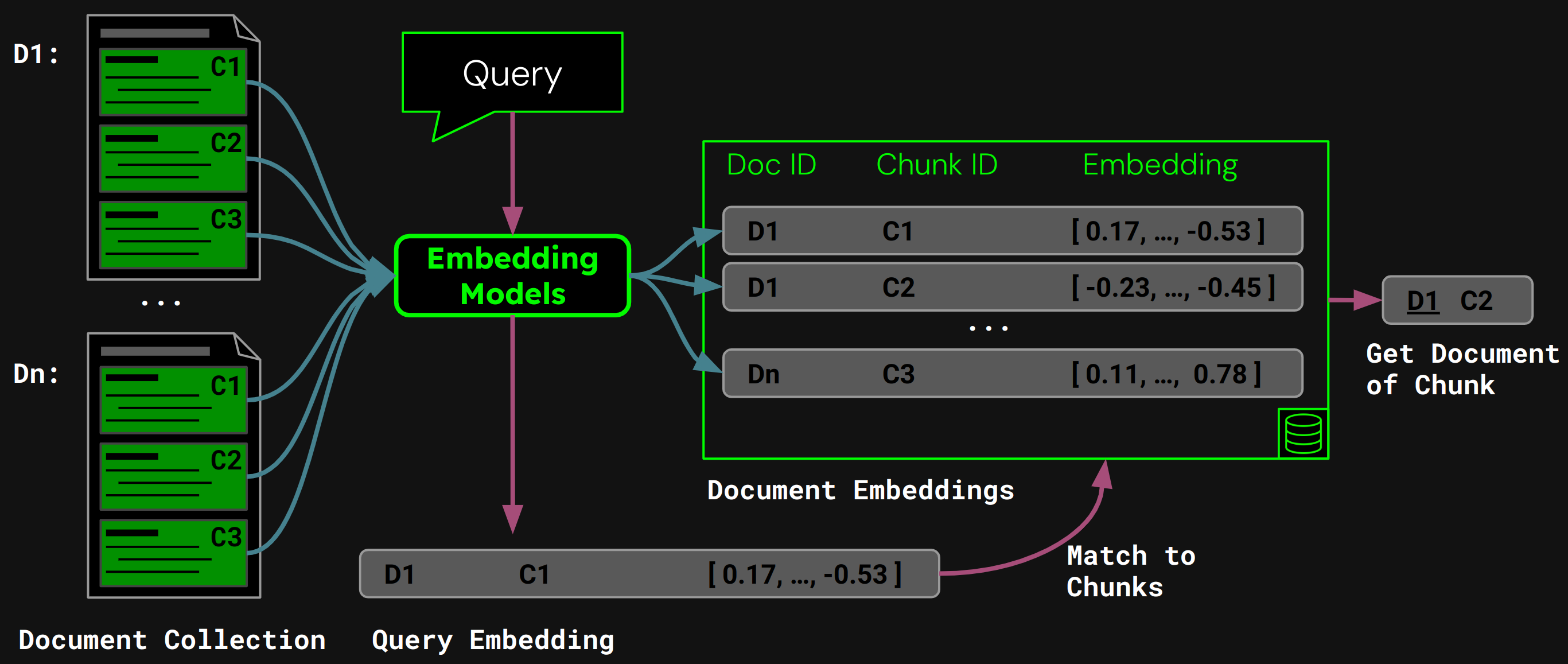
実行時には、モデルがユーザーのクエリをクエリベクトルにエンコードします。これをチャンク埋め込みのベクターデータベースと比較して、コサイン類似度が最も高いチャンクを見つけ、対応するドキュメントをユーザーに返します:
tagナイーブチャンキングの問題点

ナイーブチャンキングは長文脈埋め込みモデルの制限の一部に対処しますが、以下のような欠点もあります:
- 全体像の欠如:文書検索において、小さなチャンクの複数の埋め込みでは文書全体のトピックを捉えきれない可能性があります。木を見て森を見ない状態と考えてください。
- コンテキスト欠如の問題:図6に示すように、文脈情報が欠けているためチャンクを正確に解釈できません。
- 効率性:チャンクが増えるほど、ストレージが必要になり検索時間も増加します。
tagレイトチャンキングによるコンテキスト問題の解決
レイトチャンキングは主に2つのステップで動作します:
- まず、モデルの長文脈処理能力を使って文書全体をトークン埋め込みにエンコードします。これにより文書の完全なコンテキストが保持されます。
- 次に、セグメンテーション時に特定された境界キューに対応するトークン埋め込みのシーケンスに平均プーリングを適用して、チャンク埋め込みを作成します。
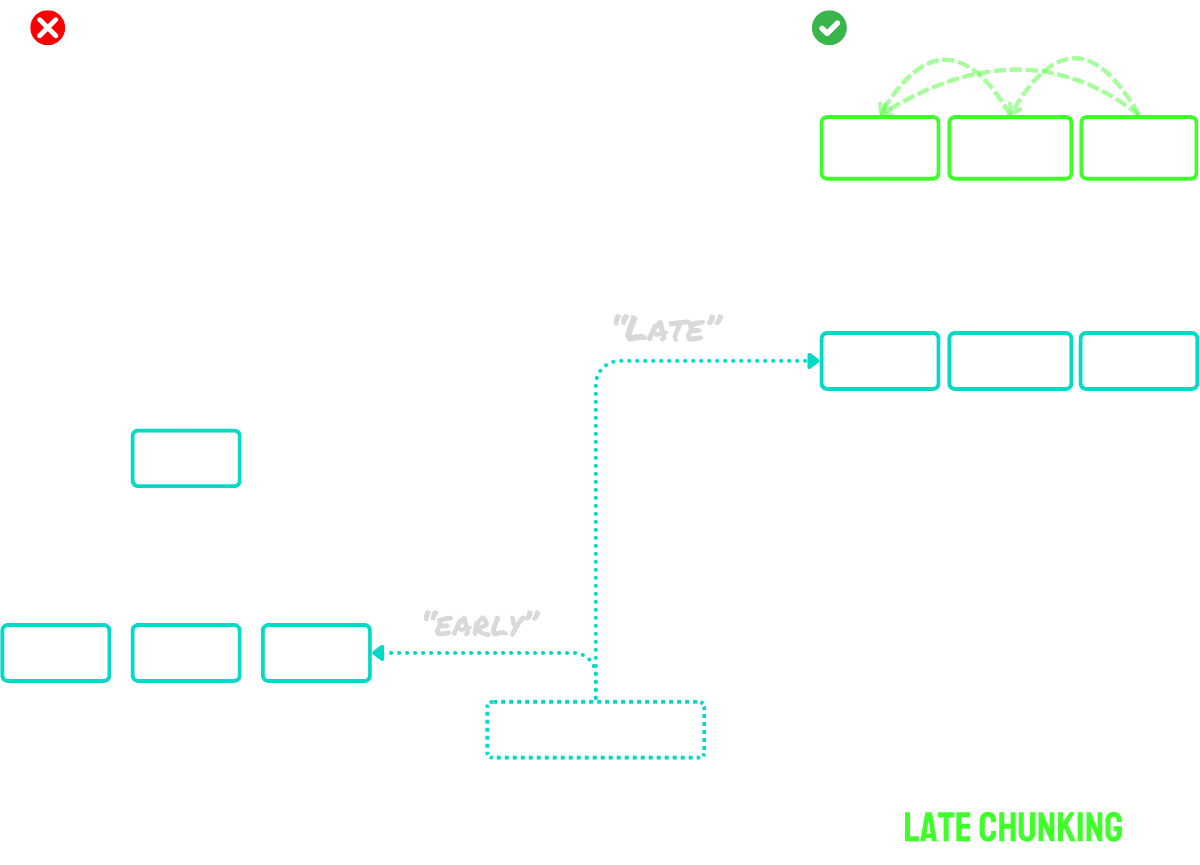
このアプローチの主な利点は、トークン埋め込みがコンテキスト化されていることです。つまり、文書の他の部分への参照や関係性を自然に捉えることができます。埋め込み処理がチャンキングの前に行われるため、各チャンクは文書の広範なコンテキストを保持し、ナイーブチャンキングが抱えるコンテキスト欠如の問題を解決します。
モデルの最大入力サイズを超える文書には、「ロングレイトチャンキング」を使用できます:
- まず、文書を重複する「マクロチャンク」に分割します。各マクロチャンクはモデルの最大コンテキスト長(例:8,192トークン)に収まるサイズにします。
- モデルがこれらのマクロチャンクを処理してトークン埋め込みを作成します。
- トークン埋め込みができたら、標準のレイトチャンキングを進め、平均プーリングを適用して最終的なチャンク埋め込みを作成します。
このアプローチにより、レイトチャンキングの利点を保ちながら、任意の長さの文書を処理できます。モデルが処理できる形に文書を変換し、その後に通常のレイトチャンキング手順を適用する2段階のプロセスと考えてください。
まとめると:
- ナイーブチャンキング:文書を小さなチャンクに分割し、各チャンクを個別にエンコードします。
- レイトチャンキング:文書全体を一度にエンコードしてトークン埋め込みを作成し、その後、セグメント境界に基づいてトークン埋め込みをプーリングしてチャンク埋め込みを作成します。
- ロングレイトチャンキング:大きな文書をモデルのコンテキストウィンドウに収まる重複マクロチャンクに分割し、それらをエンコードしてトークン埋め込みを取得し、通常通りレイトチャンキングを適用します。
アイデアの詳細な説明については、私たちの論文や上記のブログ記事をご覧ください。
tagチャンキングすべきか否か
長文脈埋め込みが一般的に短いテキスト埋め込みよりも優れていることを既に見てきました。また、ナイーブチャンキングとレイトチャンキングの両方の戦略の概要も見てきました。ここで疑問となるのは:チャンキングは長文脈埋め込みより優れているのでしょうか?
公平な比較を行うため、セグメント化を開始する前にテキスト値をモデルの最大シーケンス長(8,192トークン)に切り詰めます。セグメントあたり64トークンの固定サイズセグメンテーションを使用します(ナイーブセグメンテーションとレイトチャンキングの両方で)。3つのシナリオを比較してみましょう:
- セグメンテーションなし:各テキストを1つの埋め込みにエンコードします。これは前回の実験(図2参照)と同じスコアになりますが、比較のためにここに含めています。
- ナイーブチャンキング:テキストをセグメント化し、境界キューに基づいてナイーブチャンキングを適用します。
- レイトチャンキング:テキストをセグメント化し、レイトチャンキングを使用して埋め込みを決定します。
レイトチャンキングとナイーブセグメンテーションの両方で、関連文書を決定するためにチャンク検索を使用します(この投稿の前半の図5に示したように)。
結果は明確な勝者を示していません:
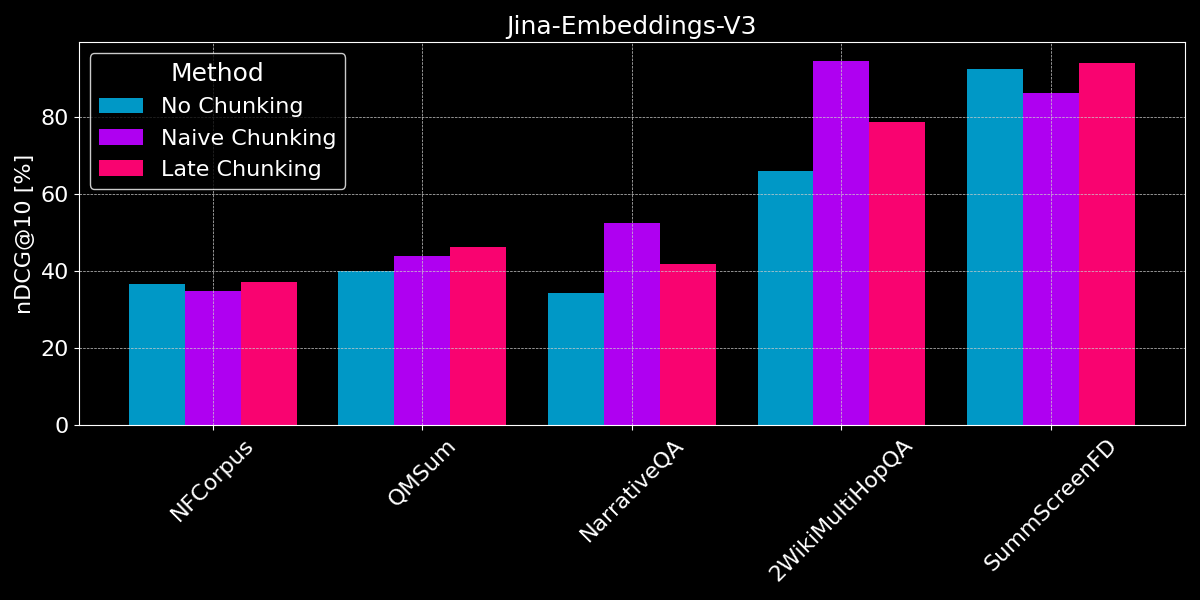
- 事実検索では、ナイーブチャンキングの方が優れています: QMSum、NarrativeQA、2WikiMultiHopQA データセットでは、モデルは文書内の関連する段落を特定する必要があります。ここでは、関連情報が含まれているのは少数のチャンクだけで、それらのチャンクが文書全体の単一の埋め込みよりもはるかに良く情報を捉えているため、ナイーブチャンキングが明らかに優れています。
- 後期チャンキングは一貫性のある文書と関連コンテキストで最も効果的です:ユーザーが特定の事実ではなくテーマ全体を検索する一貫性のあるトピックを扱う文書(NFCorpusのような)では、後期チャンキングはチャンキングなしよりもわずかに優れた性能を示します。これは文書全体のコンテキストとローカルな詳細のバランスを取るためです。しかし、後期チャンキングは一般的にコンテキストを保持することでナイーブチャンキングよりも優れていますが、この利点は、ほとんどが無関係な情報を含む文書内で孤立した事実を検索する場合には欠点となる可能性があります - NarrativeQAと2WikiMultiHopQAでの性能低下に見られるように、追加されたコンテキストが役立つよりも混乱を招くことになります。
tagチャンクサイズは違いを生むか?
チャンキング手法の有効性は実際にデータセットに依存し、コンテンツ構造が重要な役割を果たすことを示しています:
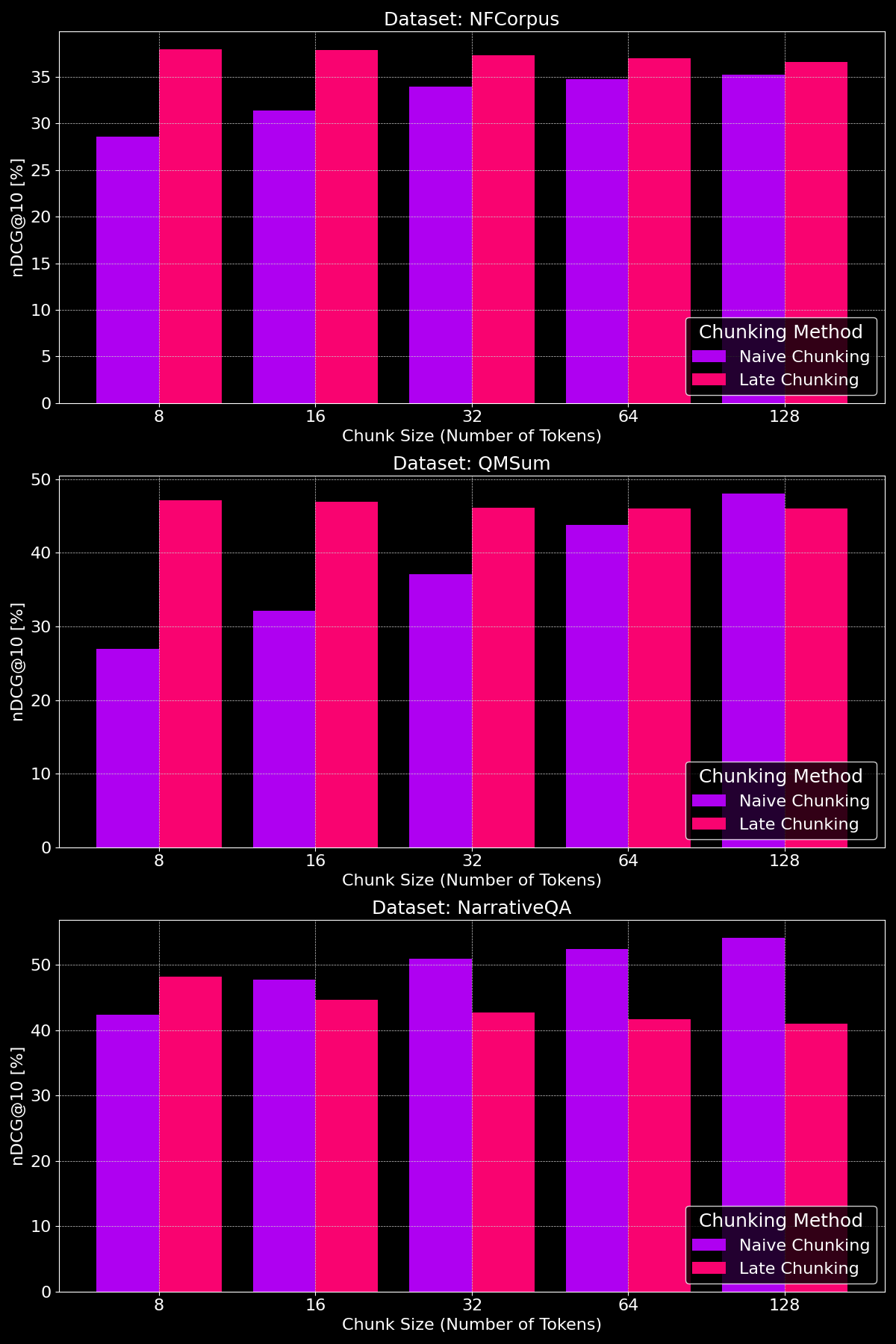
見てわかるように、後期チャンキングは一般的に小さいチャンクサイズでナイーブチャンキングを上回ります。これは、小さいナイーブチャンクはコンテキストを多く含められないのに対し、小さい後期チャンクは文書全体のコンテキストを保持し、より意味的に有意義になるためです。例外はNarrativeQAデータセットで、無関係なコンテキストが多すぎて後期チャンキングが劣ります。大きいチャンクサイズでは、ナイーブチャンキングはコンテキストが増えるため著しい改善を示し(時には後期チャンキングを上回る)、一方で後期チャンキングの性能は徐々に低下します。
tag要点:どの場合に何を使うべきか?
この投稿では、いつセグメンテーションを使用し、いつ後期チャンキングが役立つかをより理解するために、さまざまな種類の文書検索タスクを見てきました。では、何を学んだのでしょうか?
tag長文コンテキスト埋め込みはいつ使うべきか?
一般的に、埋め込みモデルの入力に文書のテキストをできるだけ多く含めても検索精度を損なうことはありません。ただし、長文コンテキスト埋め込みモデルは、関連性を判断するのに重要なタイトルや導入部などを含む文書の冒頭に焦点を当てることが多く、文書の中間部分を見落とす可能性があります。
tagナイーブチャンキングはいつ使うべきか?
文書が複数の側面をカバーしている場合や、ユーザーのクエリが文書内の特定の情報を対象としている場合、チャンキングは一般的に検索性能を向上させます。
最終的に、セグメンテーションの決定は、ユーザーへの部分テキストの表示の必要性(例:Googleが検索結果のプレビューで関連する段落を表示するように)やコンピューティングとメモリの制約など、検索オーバーヘッドとリソース使用量の増加によりセグメンテーションが好ましくない場合などの要因に依存します。
tag後期チャンキングはいつ使うべきか?
チャンクを作成する前に文書全体をエンコードすることで、後期チャンキングはコンテキストの欠如によってテキストセグメントが意味を失う問題を解決します。これは特に、各部分が全体と関連する一貫性のある文書で効果的です。私たちの実験では、論文で示されているように、後期チャンキングはテキストを小さなチャンクに分割する場合に特に効果的です。ただし、一つ注意点があります:文書の部分が互いに無関係な場合、このより広いコンテキストを含めることは、埋め込みにノイズを加えることで、実際に検索性能を低下させる可能性があります。
tag結論
長文コンテキスト埋め込み、ナイーブチャンキング、後期チャンキングの選択は、検索タスクの具体的な要件によって異なります。長文コンテキスト埋め込みは一般的なクエリを持つ一貫性のある文書に有用で、チャンキングはユーザーが文書内の特定の事実や情報を求める場合に優れています。後期チャンキングは、小さなセグメント内のコンテキストの一貫性を保持することで、さらに検索を強化します。最終的に、データと検索目標を理解することで、精度、効率性、コンテキストの関連性のバランスを取る最適なアプローチが決まります。
これらの戦略を検討している場合は、jina-embeddings-v3を試してみることをお勧めします。その高度な長文コンテキスト機能、後期チャンキング、柔軟性は、多様な検索シナリオに最適な選択肢となります。

