



LAION AI の創設者である Christoph Schuhmann が最近、テキスト埋め込みモデルについて興味深い観察を共有しました:
文章内の単語をランダムに並び替えた場合でも、その文章の埋め込みの間のコサイン類似度は、元の文章と比べて驚くほど高い値を維持します。
例えば、2つの文章を見てみましょう:Berlin is the capital of Germany と the Germany Berlin is capital ofです。2番目の文章は意味を成しませんが、テキスト埋め込みモデルはこれらを区別することができません。jina-embeddings-v3を使用すると、これらの2つの文章のコサイン類似度は0.9295となります。
埋め込みが敏感ではないのは語順だけではありません。文法的な変換は文章の意味を大きく変えることがありますが、埋め込み距離にはほとんど影響を与えません。例えば、She ate dinner before watching the movieとShe watched the movie before eating dinnerは、行動の順序が逆であるにもかかわらず、コサイン類似度は0.9833です。
否定も、特別なトレーニングなしでは一貫して埋め込むことが難しいことで知られています。This is a useful modelとThis is not a useful modelは埋め込み空間ではほぼ同じように見えます。「today」を「yesterday」に変更するなど、同じクラスの単語に置き換えたり、動詞の時制を変更したりしても、期待するほど埋め込みは変化しません。
これには重大な影響があります。2つの検索クエリを考えてみましょう:Flight from Berlin to AmsterdamとFlight from Amsterdam to Berlinです。これらは、jina-embeddings-v3で0.9884というコサイン類似度を示すほど、ほぼ同一の埋め込みを持っています。旅行検索や物流などの実世界のアプリケーションにとって、この欠点は致命的です。
この記事では、埋め込みモデルが直面する課題を検討し、語順と単語選択に関する持続的な問題を調査します。方向性、時間性、因果関係、比較、否定などの言語カテゴリーにおける主要な失敗モードを分析しながら、モデルのパフォーマンスを向上させる戦略を探ります。
tagなぜ並び替えられた文章のコサイン類似度は驚くほど近いのか?
最初、これはモデルが単語の意味を結合する方法に起因するのではないかと考えました - 各単語(上記の例文ではそれぞれ6-7単語)の埋め込みを作成し、平均プーリングでこれらの埋め込みを平均化します。これは、最終的な埋め込みには語順の情報がほとんど含まれないことを意味します。平均は値の順序に関係なく同じです。
しかし、CLS プーリング(文全体を理解するために特別な最初の単語を見て、語順により敏感であるはず)を使用するモデルでも同じ問題があります。例えば、bge-1.5-base-enでも、Berlin is the capital of Germanyとthe Germany Berlin is capital ofの文に対して0.9304のコサイン類似度を示します。
これは、埋め込みモデルのトレーニング方法の限界を示しています。言語モデルは事前学習中に文の構造を学習しますが、埋め込みモデルを作成する対照学習の過程でこの理解の一部を失うようです。
tagテキストの長さと語順は埋め込みの類似性にどのように影響するのか?
なぜモデルは語順の処理に苦労するのでしょうか?まず思い浮かぶのはテキストの長さ(トークン数)です。テキストがエンコーディング関数に送られると、モデルはまずトークン埋め込みのリスト(つまり、各トークン化された単語にその意味を表す専用のベクトルがある)を生成し、それらを平均化します。
テキストの長さと語順が埋め込みの類似性にどのように影響するかを確認するために、3、5、10、15、20、30トークンなど、さまざまな長さの180の合成文からなるデータセットを生成しました。また、各文のトークンをランダムに並び替えてバリエーションを作成しました:

以下にいくつかの例を示します:
| 長さ(トークン) | 元の文章 | 並び替えた文章 |
|---|---|---|
| 3 | The cat sleeps | cat The sleeps |
| 5 | He drives his car carefully | drives car his carefully He |
| 15 | The talented musicians performed beautiful classical music at the grand concert hall yesterday | in talented now grand classical yesterday The performed musicians at hall concert the music |
| 30 | The passionate group of educational experts collaboratively designed and implemented innovative teaching methodologies to improve learning outcomes in diverse classroom environments worldwide | group teaching through implemented collaboratively outcomes of methodologies across worldwide diverse with passionate and in experts educational classroom for environments now by learning to at improve from innovative The designed |
私たちのjina-embeddings-v3モデルとオープンソースモデルのbge-base-en-v1.5を使用してデータセットをエンコードし、元の文章と並び替えた文章の間のコサイン類似度を計算します:
| 長さ(トークン) | コサイン類似度の平均 | コサイン類似度の標準偏差 |
|---|---|---|
| 3 | 0.947 | 0.053 |
| 5 | 0.909 | 0.052 |
| 10 | 0.924 | 0.031 |
| 15 | 0.918 | 0.019 |
| 20 | 0.899 | 0.021 |
| 30 | 0.874 | 0.025 |
コサイン類似度の傾向をより明確に示すボックスプロットを生成できます:
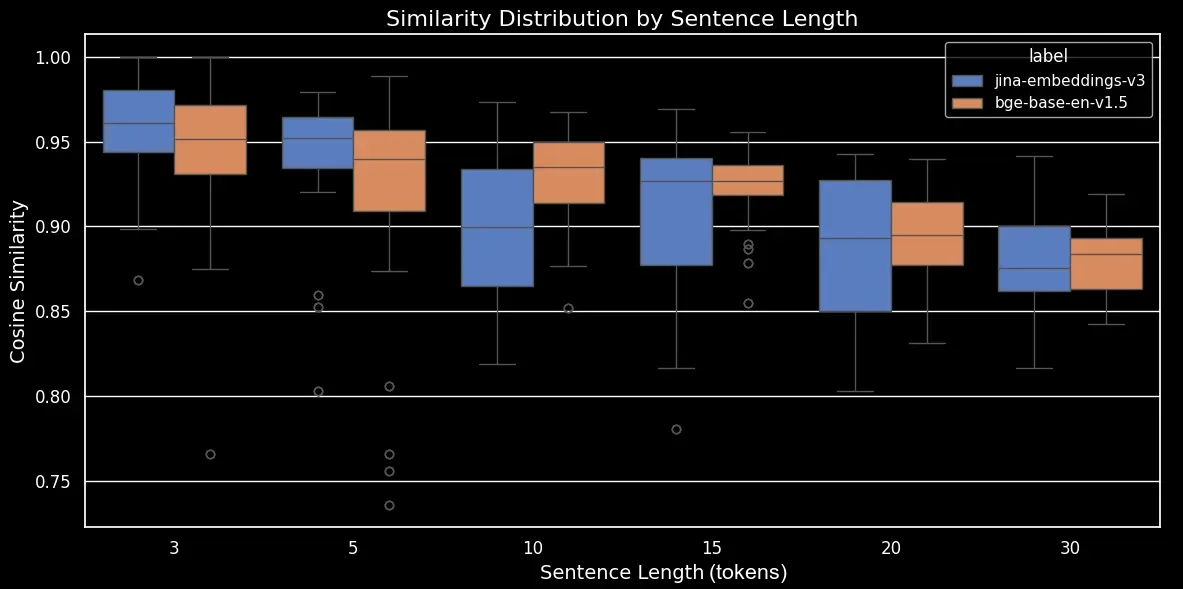
bge-base-en-1.5(ファインチューニングなし)を使用した並び替え文の文長別類似度分布見て分かるように、埋め込みの平均コサイン類似度には明確な線形関係があります。テキストが長くなるほど、元の文とランダムに並び替えた文の間の平均コサイン類似度スコアは低くなります。これは「単語の移動」、つまりランダムな並び替え後に単語が元の位置からどれだけ移動したかによると考えられます。短いテキストでは、トークンが移動できる「スロット」が少ないため、大きく移動できませんが、長いテキストでは潜在的な順列の数が多く、単語はより遠くまで移動することができます。
下図(コサイン類似度 vs 平均単語変位)に示すように、テキストが長くなるほど、単語の変位は大きくなります:
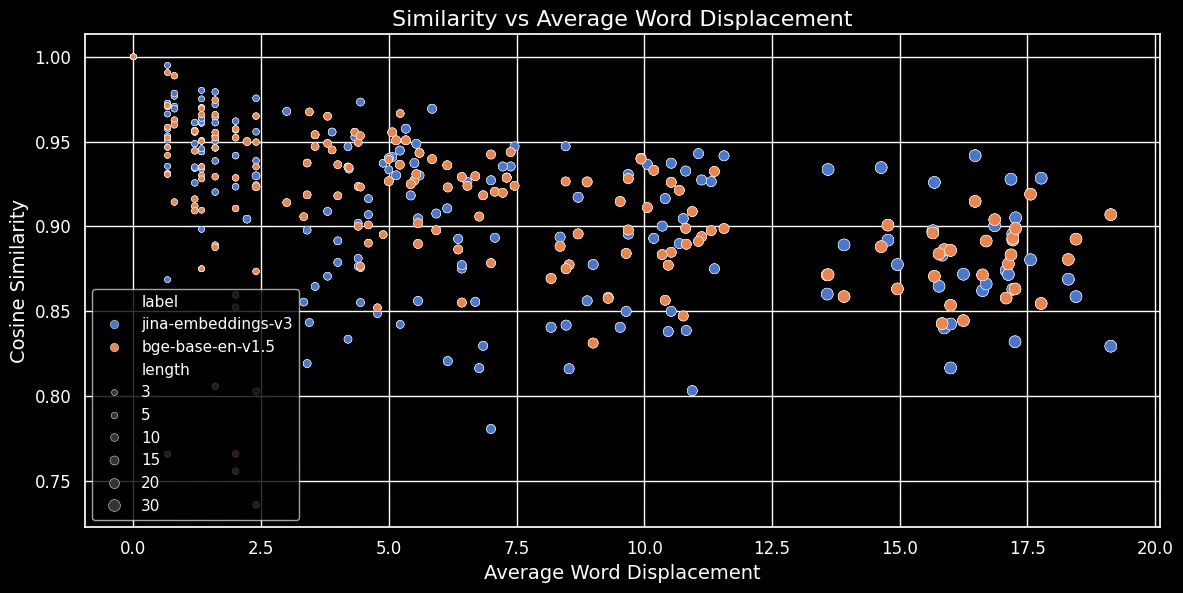
トークン埋め込みは局所的なコンテキスト(最も近い単語)に依存します。短いテキストでは、単語を並べ替えてもそのコンテキストはあまり変化しません。しかし、長いテキストでは、単語が元のコンテキストから大きく離れる可能性があり、それによってトークン埋め込みが大きく変化する可能性があります。その結果、長いテキストの単語をシャッフルすると、短いテキストよりも埋め込みの距離が大きくなります。上図は、平均プーリングを使用する jina-embeddings-v3 と CLS プーリングを使用する bge-base-en-v1.5 の両方で、同じ関係が成り立つことを示しています:長いテキストをシャッフルして単語をより遠くに移動させると、類似度スコアが小さくなります。
tagより大きなモデルで問題は解決するか?
通常、このような問題に直面した場合、よくある対処法は単により大きなモデルを投入することです。しかし、より大きなテキスト埋め込みモデルが本当に単語の順序情報をより効果的に捉えることができるのでしょうか?テキスト埋め込みモデルのスケーリング則(私たちの jina-embeddings-v3 リリース記事で参照)によると、より大きなモデルは一般的により良いパフォーマンスを提供します:
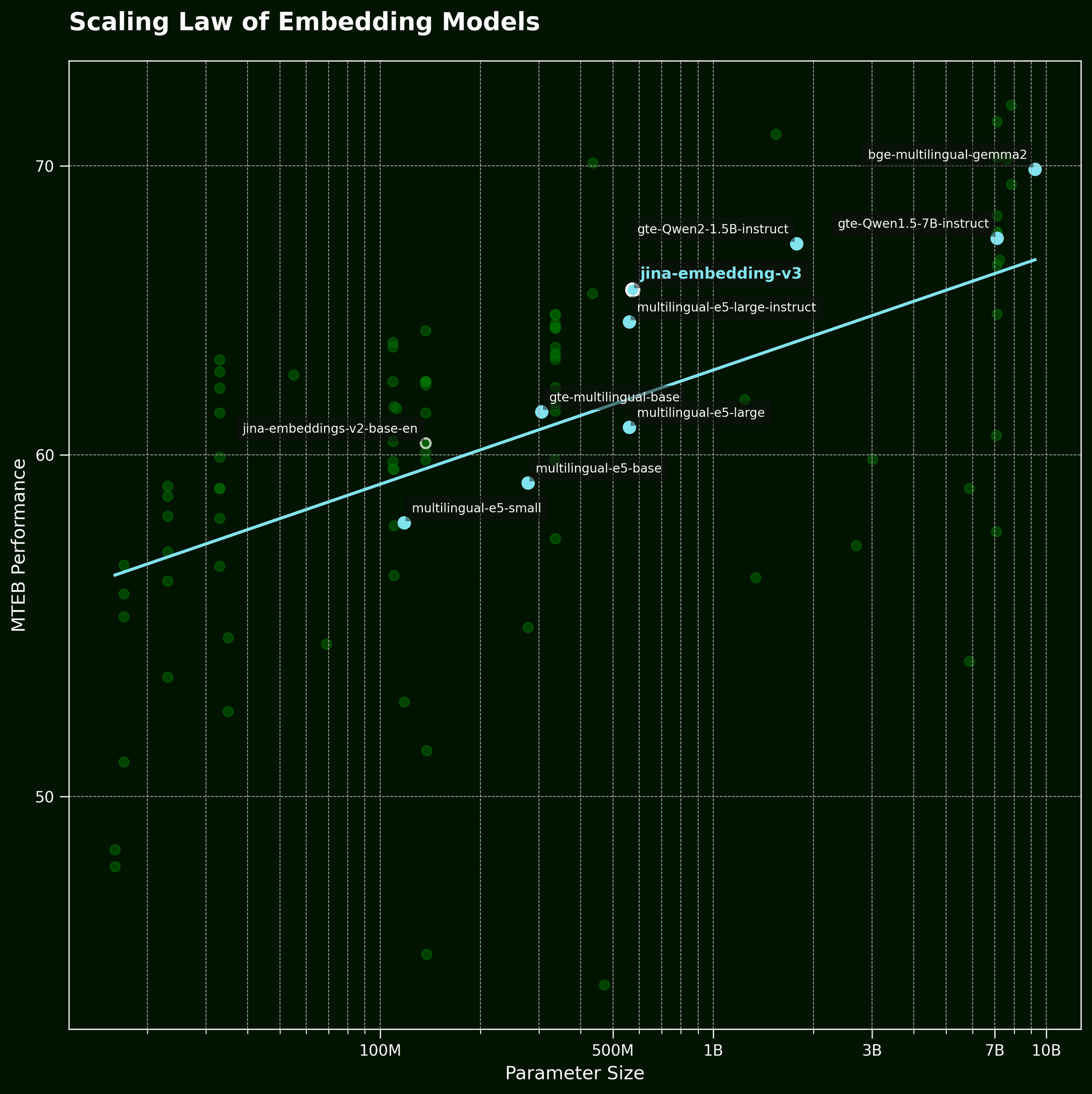
しかし、より大きなモデルが単語の順序情報をより効果的に捉えることができるのでしょうか?私たちは BGE モデルの3つのバリエーション:bge-small-en-v1.5、bge-base-en-v1.5、bge-large-en-v1.5をテストしました。それぞれのパラメータサイズは3,300万、1億1,000万、3億3,500万です。
先ほどと同じ180文を使用しますが、長さの情報は無視します。3つのモデルバリエーションを使用して、元の文とそのランダムシャッフルの両方をエンコードし、平均コサイン類似度をプロットします:
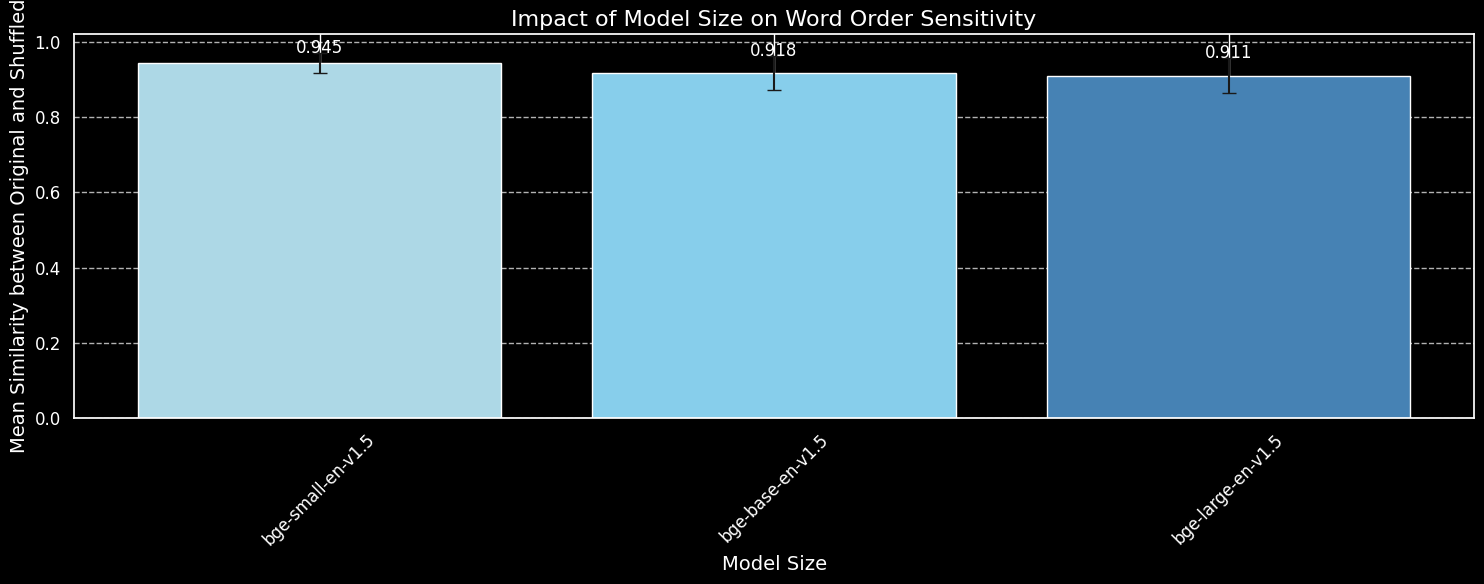
bge-small-en-v1.5、bge-base-en-v1.5、bge-large-en-v1.5を使用。より大きなモデルの方が単語の順序の変化に対してより敏感であることが分かりますが、その差は小さいものです。はるかに大きな bge-large-en-v1.5 でさえ、シャッフルされた文とシャッフルされていない文を区別する能力はわずかに優れている程度です。埋め込みモデルが単語の並べ替えにどの程度敏感であるかを決定する要因には、特に訓練方法の違いなど、他の要因が関係しています。さらに、コサイン類似度はモデルの区別能力を測定するための非常に限られたツールです。しかし、モデルサイズは主要な考慮事項ではないことが分かります。単純にモデルを大きくするだけではこの問題を解決できません。
tag実世界における単語の順序と単語の選択
jina-embeddings-v2(最新モデルの jina-embeddings-v3 ではありません)を使用しています。これは v2 の方がはるかに小さく、ローカルGPUでの実験が速いためです。パラメータ数は v3 の5億8,000万に対して1億3,700万です。序論で述べたように、単語の順序は埋め込みモデルにとって唯一の課題ではありません。より現実的な実世界の課題は単語の選択についてです。文の中で単語を入れ替える方法は多くあり、それらは埋め込みにうまく反映されません。「She flew from Paris to Tokyo」を「She drove from Tokyo to Paris」に変更しても、埋め込みは類似したままです。私たちはこれをいくつかのカテゴリーに分けて調査しました:
| カテゴリー | 例 - 左 | 例 - 右 | コサイン類似度(jina) |
|---|---|---|---|
| 方向性 | She flew from Paris to Tokyo | She drove from Tokyo to Paris | 0.9439 |
| 時間的 | She ate dinner before watching the movie | She watched the movie before eating dinner | 0.9833 |
| 因果関係 | The rising temperature melted the snow | The melting snow cooled the temperature | 0.8998 |
| 比較 | Coffee tastes better than tea | Tea tastes better than coffee | 0.9457 |
| 否定 | He is standing by the table | He is standing far from the table | 0.9116 |
上の表は、テキスト埋め込みモデルが微妙な単語の変更を捉えられない「失敗ケース」のリストを示しています。これは私たちの予想通りです: テキスト埋め込みモデルには推論する能力が欠けています。例えば、モデルは"from"と"to"の関係を理解できません。テキスト埋め込みモデルは意味的なマッチングを行いますが、その意味は通常トークンレベルで捉えられ、プーリング後に単一の密なベクトルに圧縮されます。一方、より大規模なデータセット(兆トークン規模)で訓練された LLM(自己回帰モデル)は、推論のための新たな能力を示し始めています。
これにより私たちは、クエリとポジティブを近づけ、クエリとネガティブを遠ざけるように、トリプレットを使用した対照学習で埋め込みモデルを微調整できるのではないかと考えました。

例えば、「Flight from Amsterdam to Berlin」は「Flight from Berlin to Amsterdam」のネガティブペアと考えられます。実際、jina-embeddings-v1 の技術レポート(Michael Guenther ら)では、この問題に小規模に取り組みました:大規模言語モデルで生成した 10,000 例の否定データセットで jina-embeddings-v1 モデルを微調整しました。

上記のレポートに記載された結果は有望でした:
全てのモデルサイズで、トリプレットデータ(否定訓練データセットを含む)による微調整が、特に HardNegation タスクにおいてパフォーマンスを劇的に向上させることが分かりました。
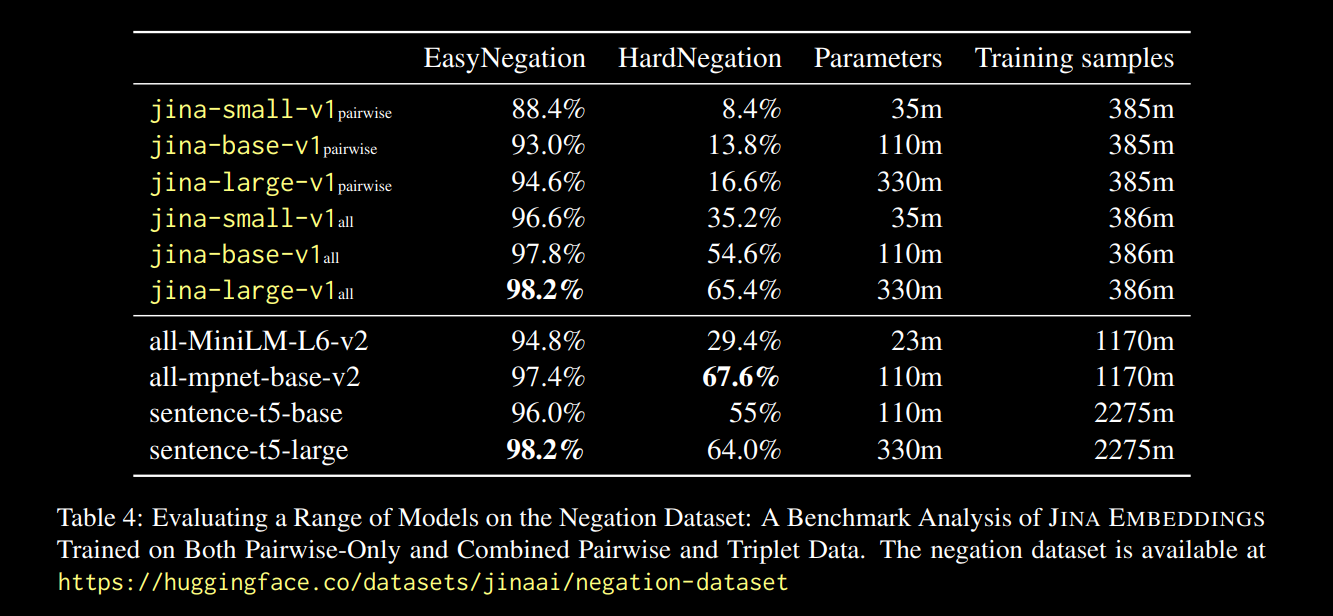
jina-embeddings の各サイズモデルにおける、ペアワイズ学習とトリプレット/ペアワイズ組み合わせ学習の EasyNegation および HardNegation スコアを示す表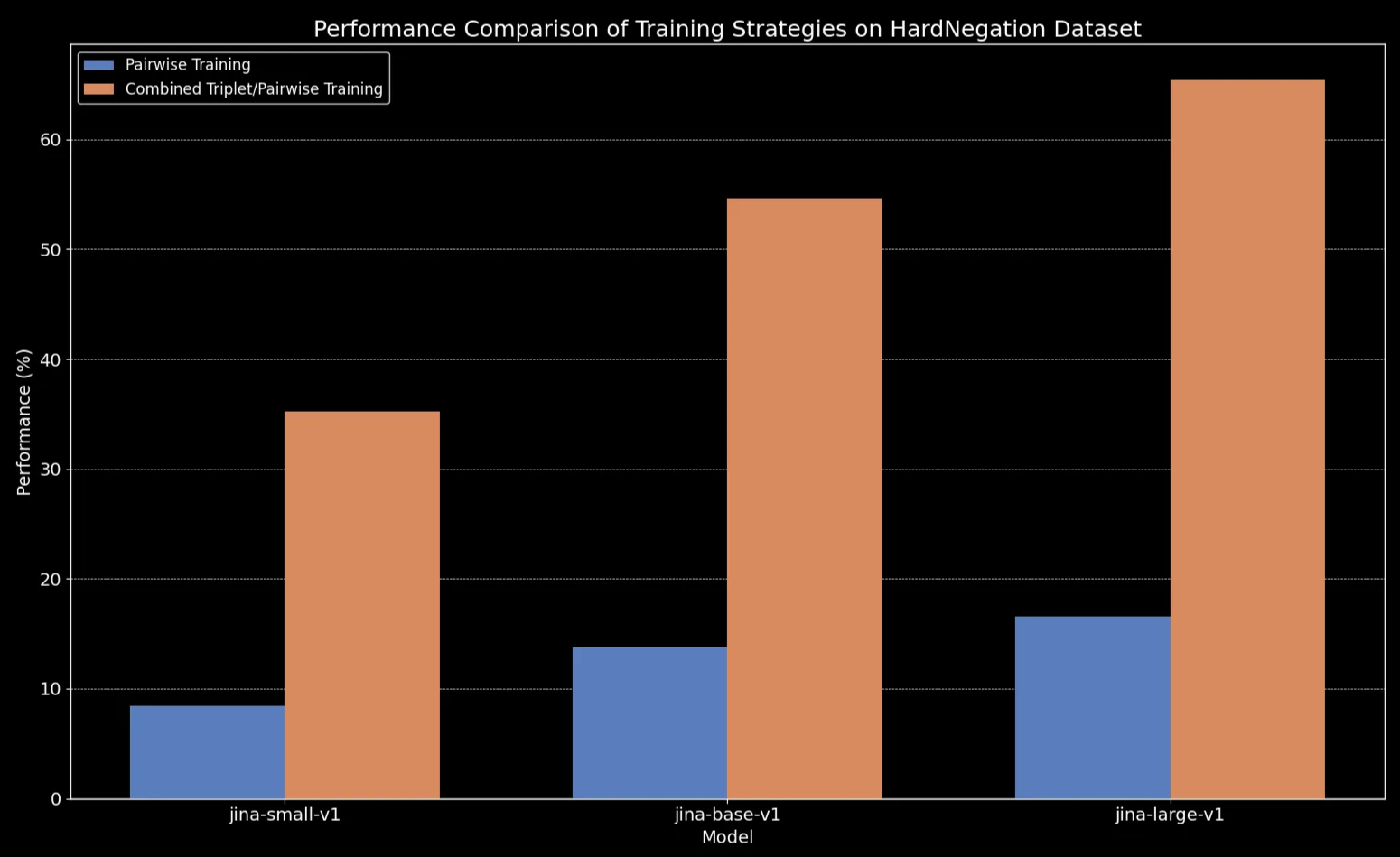
jina-embeddings の異なるバージョン間における訓練戦略のパフォーマンス比較tagキュレーションされたデータセットによるテキスト埋め込みモデルの微調整
前のセクションでは、テキスト埋め込みに関するいくつかの重要な観察を探りました:
- 短いテキストは単語の順序を捉えるのに失敗しやすい
- テキスト埋め込みモデルのサイズを大きくしても、単語の順序の理解は必ずしも改善されない
- 対照学習がこれらの問題に対する潜在的な解決策となりうる
これを踏まえて、否定と語順のデータセット(合計約 11,000 の訓練サンプル)で jina-embeddings-v2-base-en と bge-base-en-1.5 を微調整しました:


微調整の評価を助けるため、query、positive (pos)、negative (neg) からなる 1,000 のトリプレットのデータセットを生成しました:

以下は例の行です:
| Anchor | The river flows from the mountains to the sea |
| Positive | Water travels from mountain peaks to ocean |
| Negative | The river flows from the sea to the mountains |
これらのトリプレットは、単語の順序の変更による方向、時間、因果の意味の変化を含む、様々な失敗ケースをカバーするように設計されています。
これで、3 つの異なる評価セットでモデルを評価できます:
- 180 の合成文(この投稿の前半から)をランダムにシャッフルしたセット
- 手動でチェックした 5 つの例(上の方向/因果関係などの表から)
- 先ほど生成したトリプレットデータセットから選んだ 94 のキュレーションされたトリプレット
以下は、微調整前後でのシャッフルされた文の違いです:
| 文の長さ(トークン数) | 平均コサイン類似度(jina) |
平均コサイン類似度(jina-ft) |
平均コサイン類似度(bge) |
平均コサイン類似度(bge-ft) |
|---|---|---|---|---|
| 3 | 0.970 | 0.927 | 0.929 | 0.899 |
| 5 | 0.958 | 0.910 | 0.940 | 0.916 |
| 10 | 0.953 | 0.890 | 0.934 | 0.910 |
| 15 | 0.930 | 0.830 | 0.912 | 0.875 |
| 20 | 0.916 | 0.815 | 0.901 | 0.879 |
| 30 | 0.927 | 0.819 | 0.877 | 0.852 |
結果は明確です:ファインチューニングのプロセスはわずか5分しかかかりませんでしたが、ランダムにシャッフルされた文のデータセットにおいて劇的なパフォーマンスの向上が見られました:
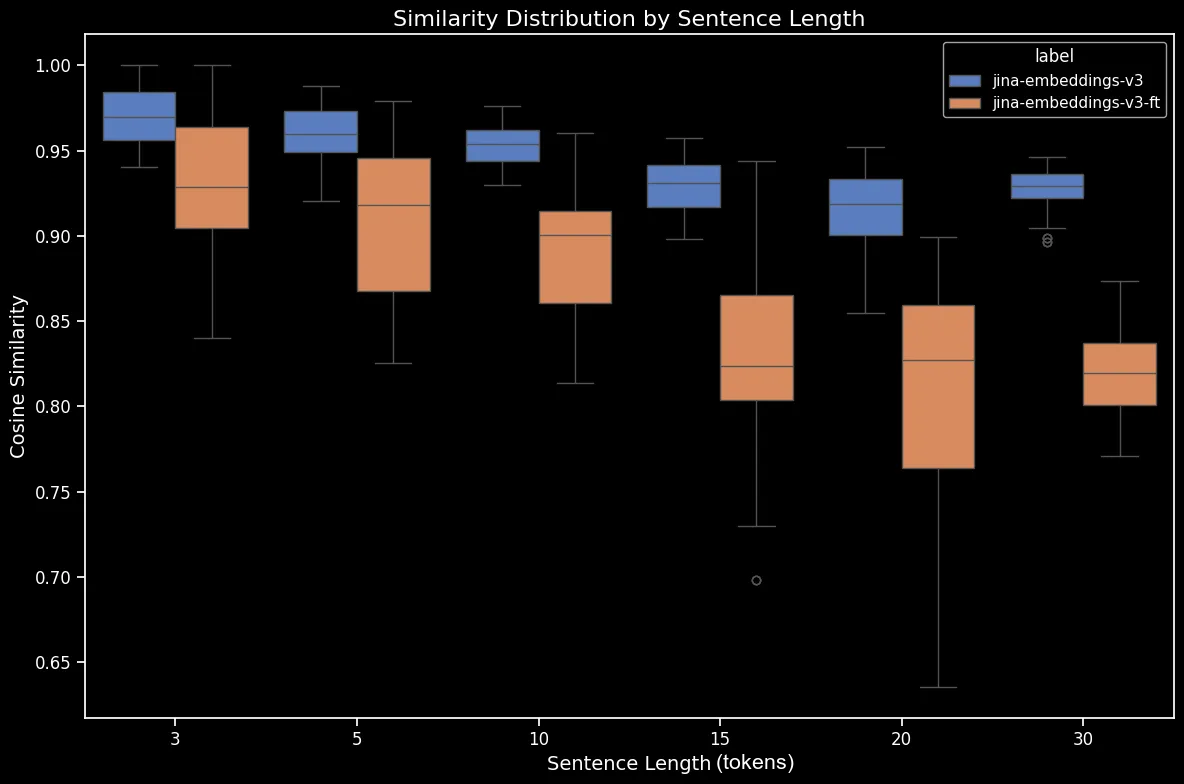
bge-base-en-1.5(ファインチューニング済み)の比較)。また、方向性、時間的、因果関係、比較のケースでも改善が見られました。モデルは平均コサイン類似度の低下に反映されるように、大幅なパフォーマンスの向上を示しています。最大のパフォーマンス向上は否定のケースで見られ、これはファインチューニングのデータセットに10,000の否定訓練例が含まれていたためです。
| カテゴリー | 例 - 左 | 例 - 右 | 平均コサイン類似度(jina) |
平均コサイン類似度(jina-ft) |
平均コサイン類似度(bge) |
平均コサイン類似度(bge-ft) |
|---|---|---|---|---|---|---|
| 方向性 | She flew from Paris to Tokyo. | She drove from Tokyo to Paris | 0.9439 | 0.8650 | 0.9319 | 0.8674 |
| 時間的 | She ate dinner before watching the movie | She watched the movie before eating dinner | 0.9833 | 0.9263 | 0.9683 | 0.9331 |
| 因果関係 | The rising temperature melted the snow | The melting snow cooled the temperature | 0.8998 | 0.7937 | 0.8874 | 0.8371 |
| 比較 | Coffee tastes better than tea | Tea tastes better than coffee | 0.9457 | 0.8759 | 0.9723 | 0.9030 |
| 否定 | He is standing by the table | He is standing far from the table | 0.9116 | 0.4478 | 0.8329 | 0.4329 |
tag結論
この記事では、テキスト埋め込みモデルが直面する課題、特に語順を効果的に処理することの困難さについて詳しく説明しました。具体的には、5つの主要な失敗タイプを特定しました:方向性、時間的、因果関係、比較、そして否定です。これらは語順が本当に重要なクエリのタイプであり、もしあなたのユースケースにこれらが含まれている場合、これらのモデルの限界を知っておく価値があります。
また、否定に焦点を当てたデータセットを5つの失敗カテゴリーすべてをカバーするように拡張する簡単な実験も行いました。結果は有望でした:慎重に選択された「ハードネガティブ」でファインチューニングを行うことで、モデルはどのアイテムが関連しているか、していないかをより適切に認識できるようになりました。とはいえ、まだやるべきことは残っています。今後のステップには、データセットのサイズと品質がパフォーマンスにどのように影響するかをより深く調査することが含まれます。
