


ColPali スタイルのモデルを実験している中で、私たちのエンジニアの1人が最近リリースした jina-clip-v2 モデルを使用して可視化を作成しました。画像とテキストのペアに対して、トークンの埋め込みとパッチの埋め込み間の類似度をマッピングし、興味深い視覚的洞察を生み出すヒートマップオーバーレイを作成しました。

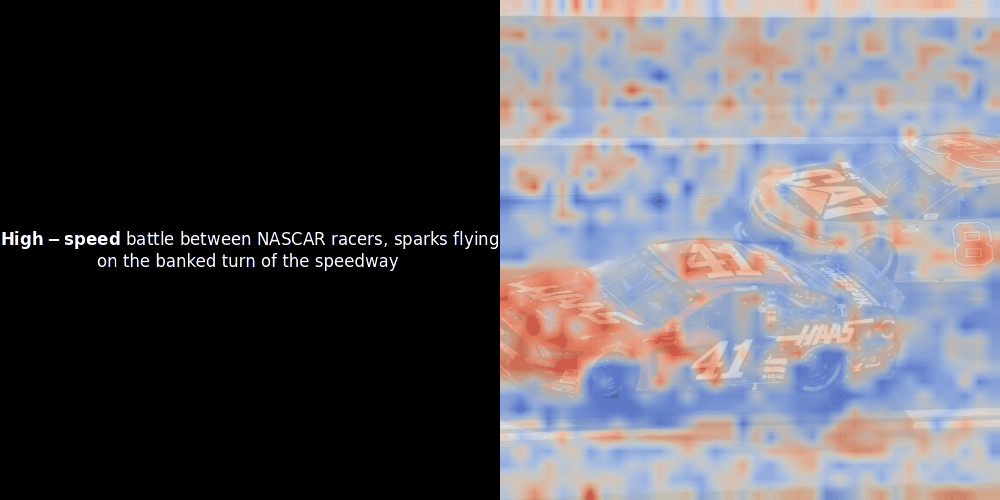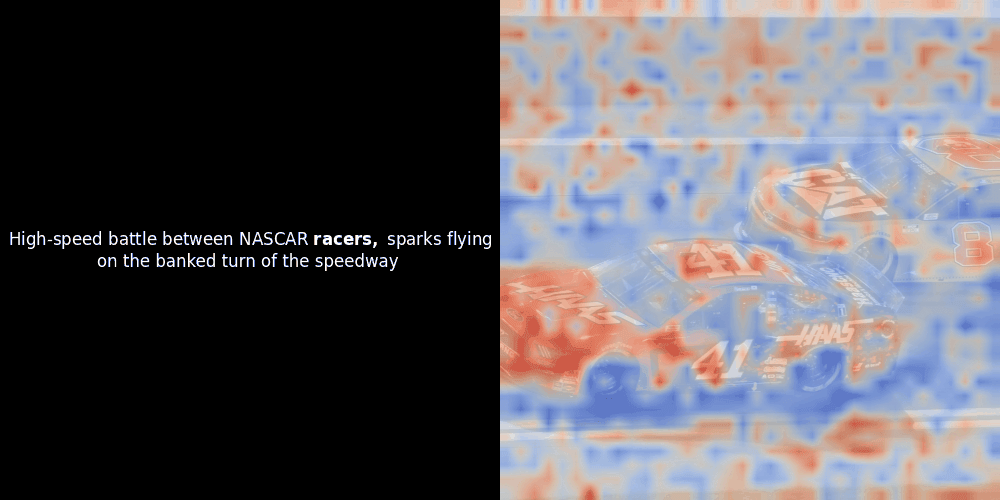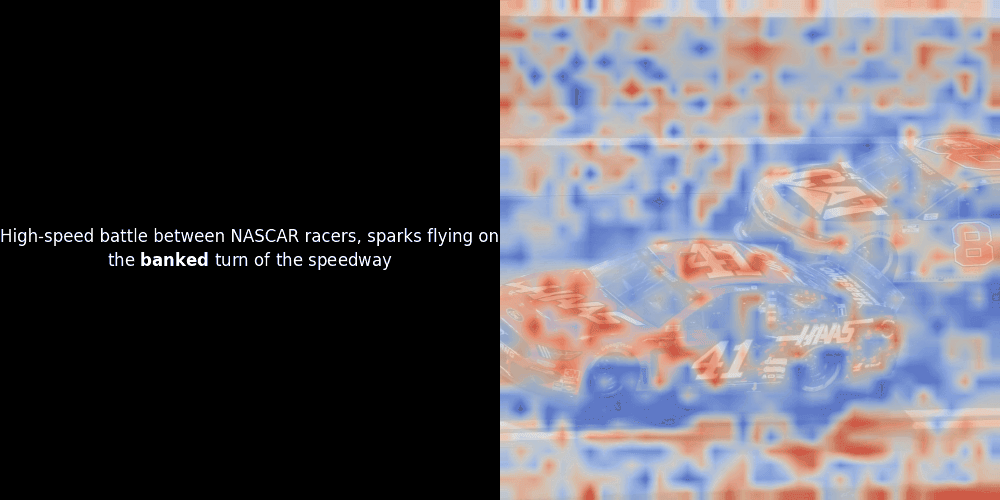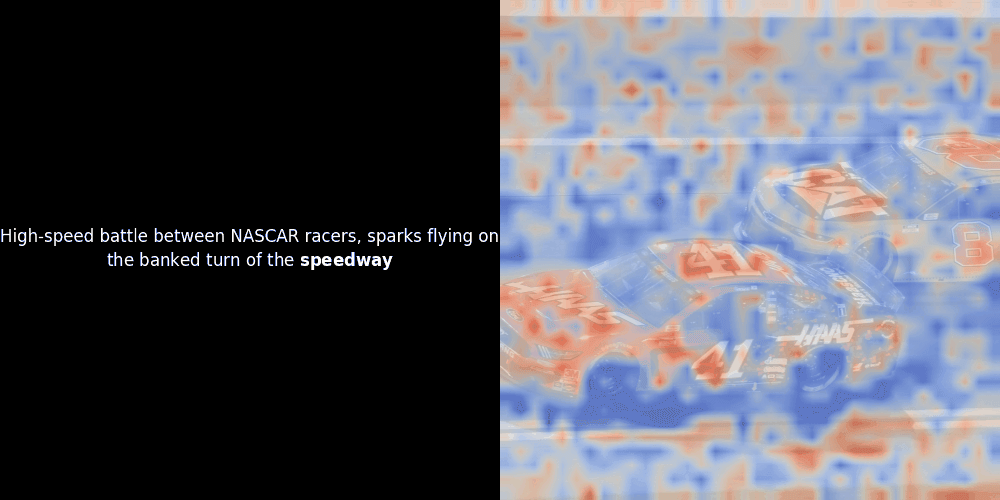
残念ながら、これは単なるヒューリスティックな可視化であり、明示的または保証された仕組みではありません。CLIP のようなグローバルな対照的アラインメントは、パッチとトークン間の大まかなローカルアラインメントを偶然的に生成することはありますが、これはモデルの意図的な目的ではなく、意図しない副作用です。その理由を説明しましょう。
tagコードを理解する

コードが行っていることを高レベルで見ていきましょう。注意点として、jina-clip-v2 はデフォルトではトークンレベルやパッチレベルの埋め込みにアクセスする API を公開していません - この可視化を実現するには事後的なパッチが必要でした。
単語レベルの埋め込みを計算する
model.text_model.output_tokens = True を設定すると、text_model(x=...,)[1] を呼び出すことでトークン埋め込みの (batch_size, seq_len, embed_dim) 形式の2番目の要素が返されます。入力文を Jina CLIP トークナイザーでトークン化し、対応するトークン埋め込みを平均化することで、サブワードトークンを「単語」に戻しグループ化します。トークン文字列が _ 文字で始まるかどうかをチェックして(SentencePiece ベースのトークナイザーの典型的な特徴)、新しい単語の開始を検出します。これにより、単語レベルの埋め込みのリストと単語のリストが生成されます(「Dog」が1つの埋め込み、「and」が1つの埋め込みなど)。
パッチレベルの埋め込みを計算する
画像タワーについては、vision_model(..., return_all_features=True) が (batch_size, n_patches+1, embed_dim) を返します。ここで最初のトークンは [CLS] トークンです。そこから、各パッチの埋め込み(つまり、ビジョントランスフォーマーのパッチトークン)を抽出します。次に、これらのパッチ埋め込みを patch_side × patch_side の2次元グリッドに整形し、元の画像解像度に合わせてアップサンプリングします。
単語とパッチの類似度を可視化する
類似度の計算と、それに続くヒートマップの生成は標準的な「事後的」解釈手法です:テキスト埋め込みを1つ選び、すべてのパッチ埋め込みとのコサイン類似度を計算し、その特定のトークン埋め込みに対して最も類似度の高いパッチを示すヒートマップを生成します。最後に、文中の各トークンを順に処理し、左側でそのトークンを太字でハイライトし、右側の元の画像に類似度ベースのヒートマップをオーバーレイします。すべてのフレームがアニメーション GIF にまとめられます。
tag意味のある説明可能性なのか?
純粋なコードの観点からは、はい、ロジックは一貫しており、各トークンのヒートマップを生成します。パッチの類似度をハイライトする一連のフレームが得られるため、スクリプトは「うたい文句通りの動作」をします。
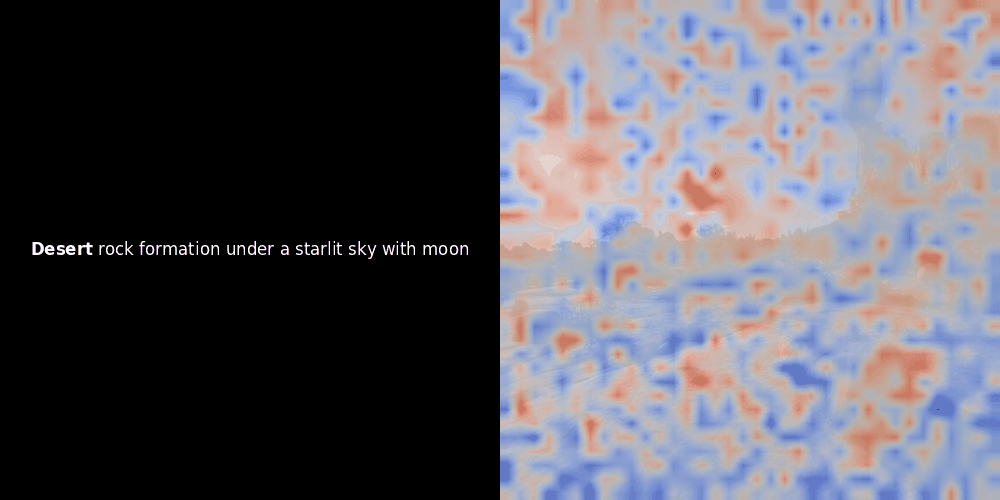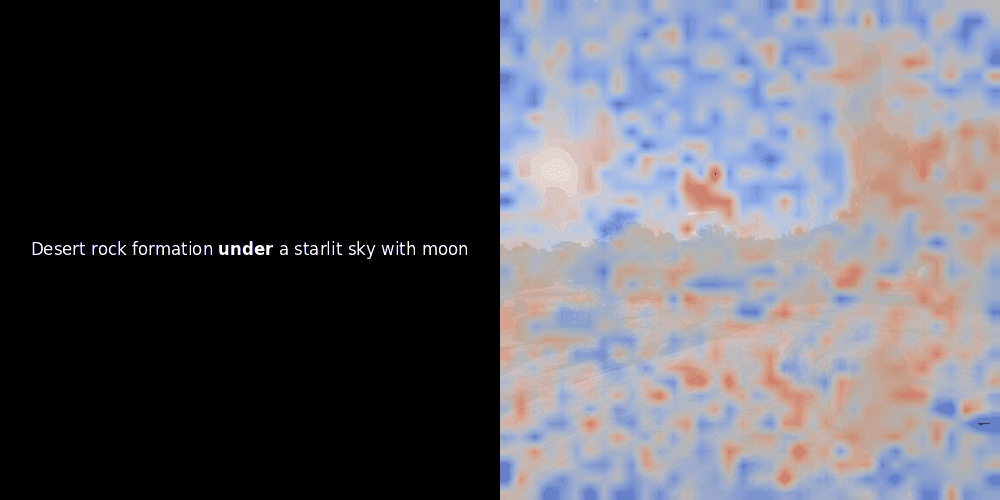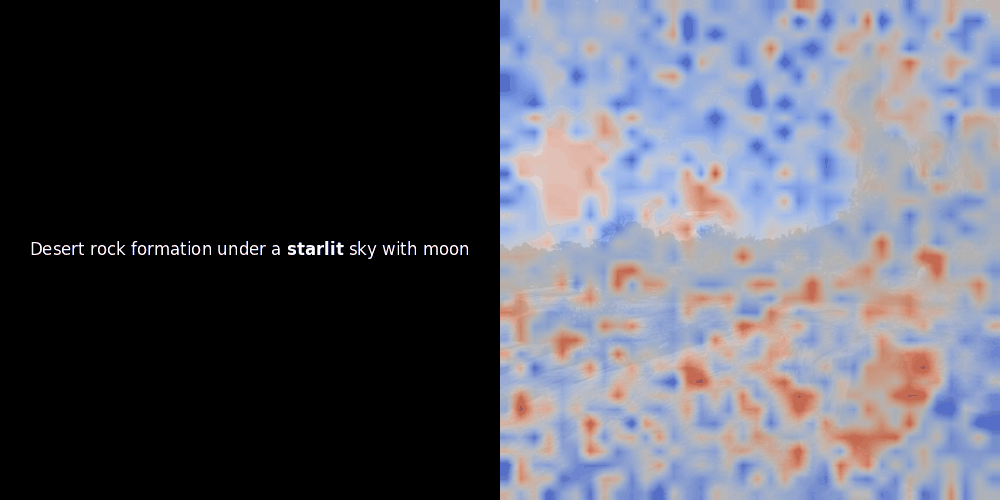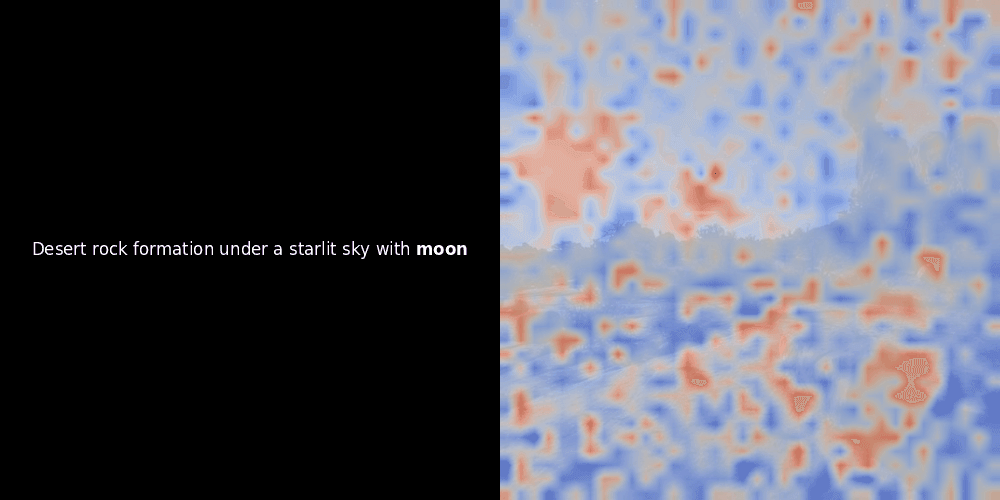

上の例を見ると、moon や branches のような単語が、元の画像の対応する視覚的パッチとよく整列しているように見えます。しかし、ここで重要な質問があります:これは意味のある整列なのか、それとも単なる偶然の一致なのでしょうか?
これはより深い問題です。注意点を理解するために、CLIP がどのように訓練されるのかを思い出してください:

- CLIP は画像全体とテキスト全体の間のグローバルな対照的アラインメントを使用します。訓練時、画像エンコーダーは単一のベクトル(プールされた表現)を生成し、テキストエンコーダーは別の単一のベクトルを生成します。CLIP は、これらが一致するテキスト-画像ペアでは一致し、それ以外では不一致になるように訓練されます。
- 「パッチ X がトークン Y に対応する」というレベルでの明示的な教師あり学習はありません。モデルは「この領域が犬で、あの領域が猫」などを直接的にハイライトするようには訓練されていません。代わりに、画像全体の表現がテキスト全体の表現と一致するように教えられます。
- CLIP のアーキテクチャは画像側に Vision Transformer、テキスト側にテキストトランスフォーマーを使用し - それぞれ別個のエンコーダーを形成しているため - パッチをトークンに自然にアラインメントするクロスアテンションモジュールはありません。代わりに、各タワーでのセルフアテンションと、グローバルな画像またはテキスト埋め込みのための最終的な投影を得ます。
簡単に言えば、これはヒューリスティックな可視化です。特定のパッチ埋め込みが特定のトークン埋め込みに近いか遠いかは、ある程度創発的なものです。これは、モデルの堅牢な、または公式な「アテンション」というよりも、事後的な解釈可能性のトリックです。
tagなぜローカルアラインメントが現れるのか?
では、なぜ時々単語-パッチレベルのローカルアラインメントが見られるのでしょうか?ここで重要なのは:CLIP はグローバルな画像-テキスト対照的な目的で訓練されますが、それでも(ViT ベースの画像エンコーダーでは)セルフアテンションと(テキストでは)トランスフォーマー層を使用します。これらのセルフアテンション層の中で、画像表現の異なる部分は、テキスト表現内の単語が相互作用するのと同じように、相互に作用することができます。大規模な画像-テキストデータセットでの訓練を通じて、モデルは自然に、全体的な画像を対応するテキスト記述と一致させるのに役立つ内部の潜在構造を発達させます。

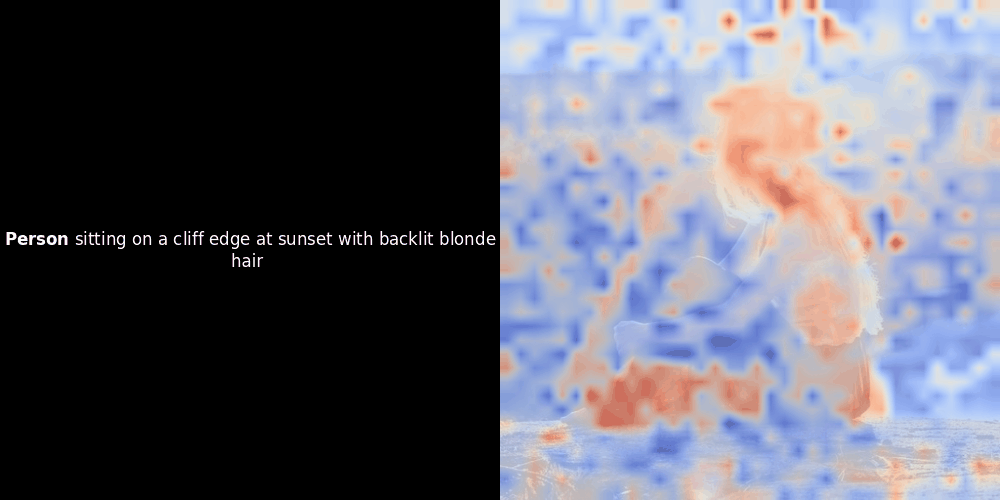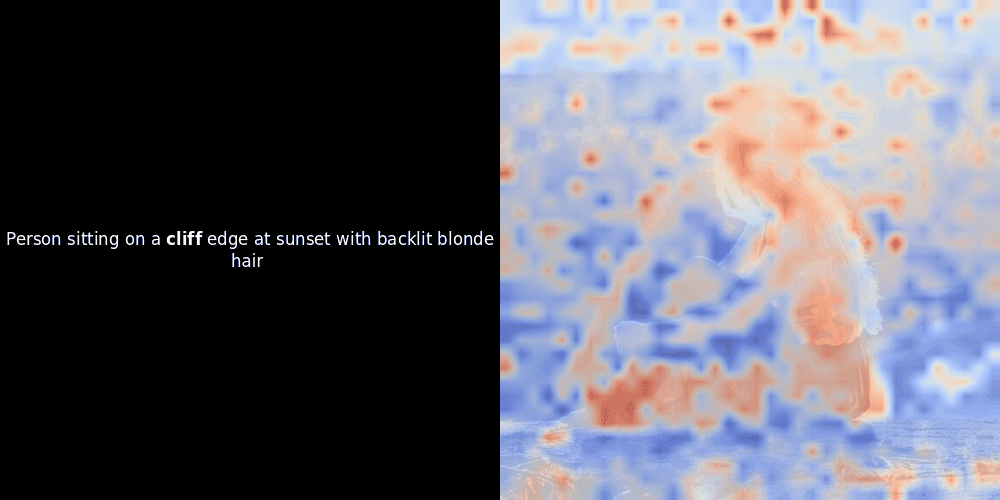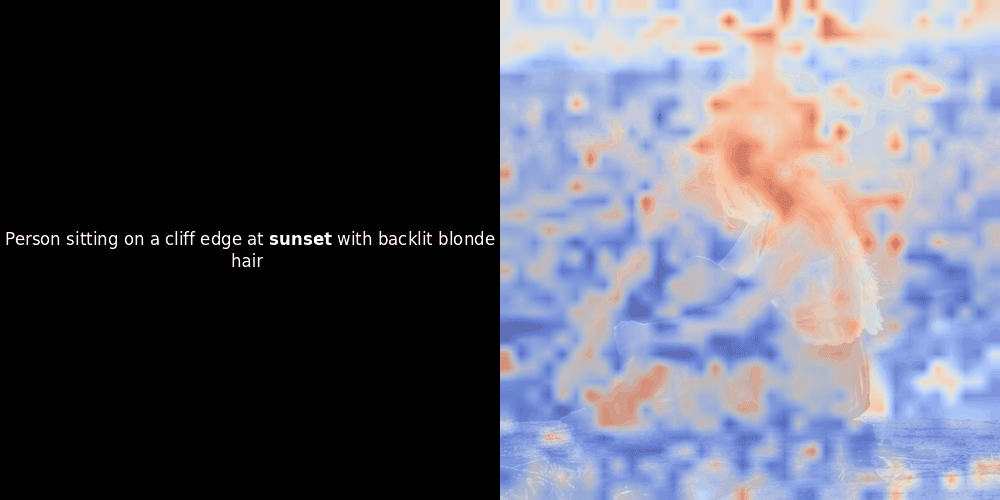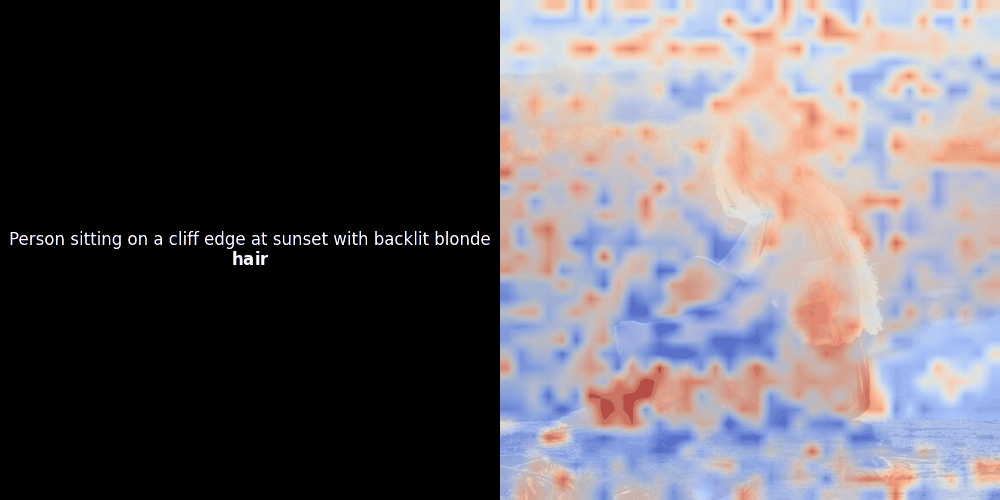
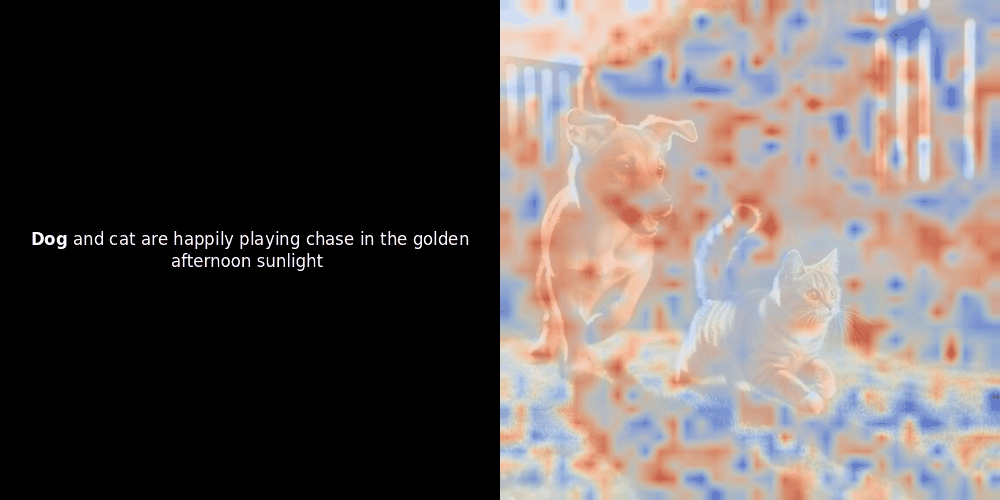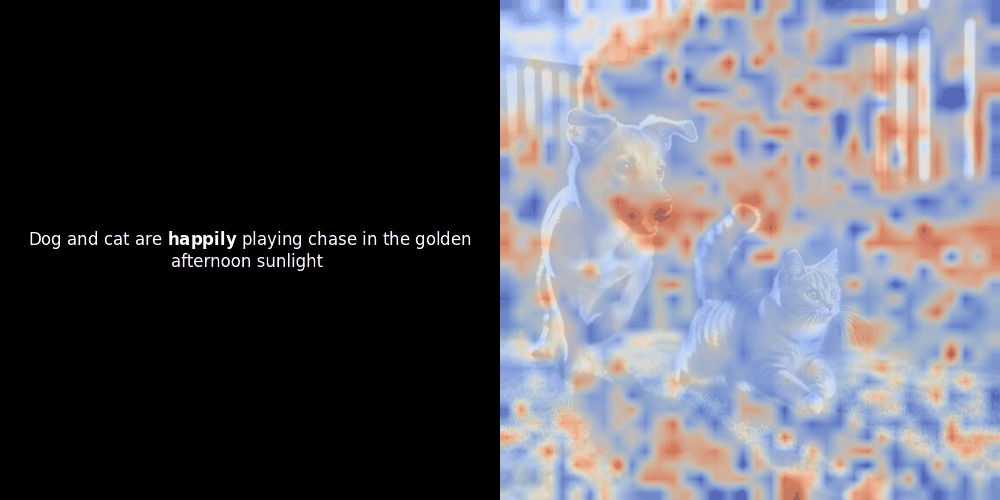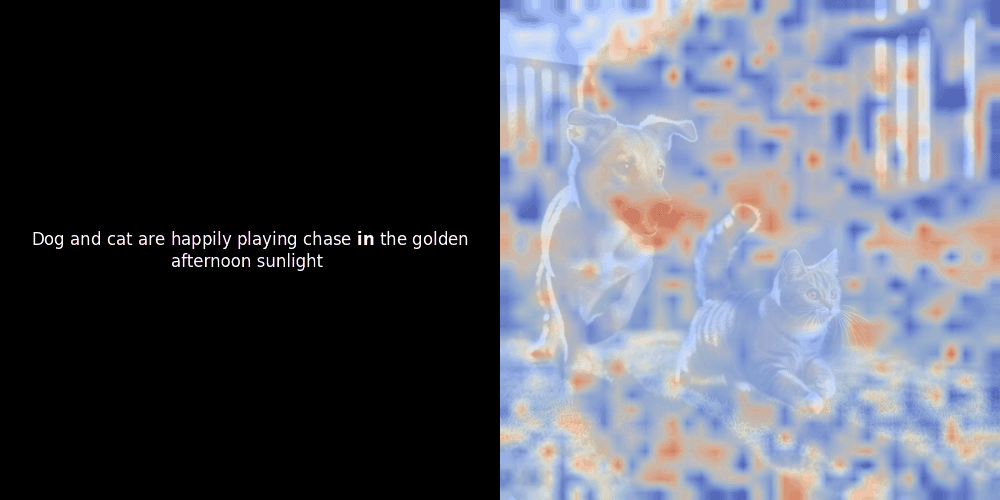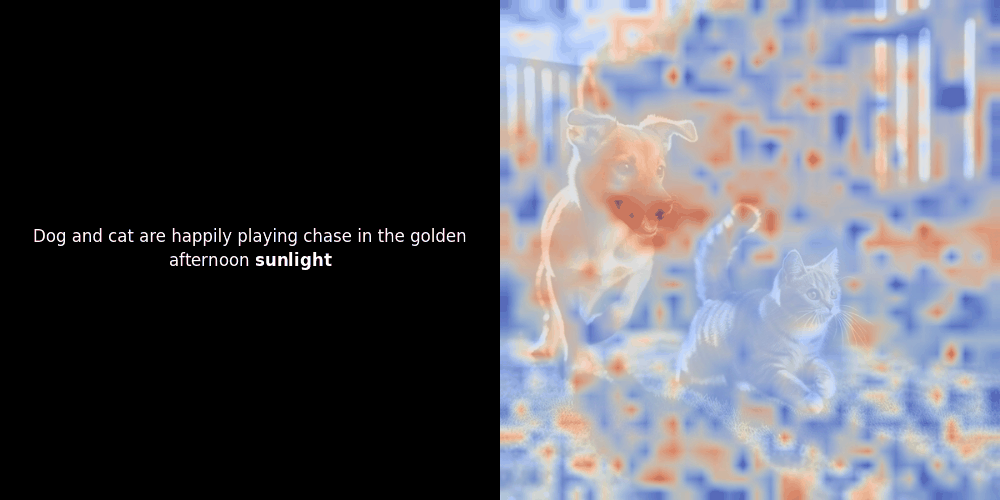
これらの潜在表現においてローカルアラインメントが現れる理由は、少なくとも2つあります:
- 共起パターン:モデルが多くの「犬」の画像を「猫」の画像の隣で見る場合(しばしばそれらの単語でラベル付けまたは記述される)、これらの概念に大まかに対応する潜在特徴を学習することができます。そのため、「犬」の埋め込みは、犬のような形状やテクスチャを描写するローカルパッチに近くなる可能性があります。これはパッチレベルで明示的に教師あり学習されているわけではありませんが、犬の画像/テキストペアの繰り返しの関連付けから創発的に生まれます。
- Self-attention:Vision Transformer において、パッチは互いに attend します。モデルは全体的に正確なシーン表現を生成しようとするため、特徴的なパッチ(犬の顔など)は一貫した潜在的な「シグネチャー」を持つことになります。それが全体的な対比損失を最小化するのに役立つ場合、それは強化されます。
tag理論的分析
CLIP の対比学習の目的は、マッチする画像とテキストのペアのコサイン類似度を最大化し、マッチしないペアの類似度を最小化することです。テキストエンコーダーと画像エンコーダーがそれぞれトークンとパッチの埋め込みを生成すると仮定します:
グローバルな類似度はローカルな類似度の集約として表現できます:
特定のトークンとパッチのペアが学習データ全体で頻繁に共起する場合、モデルは累積的な勾配更新を通じてそれらの類似度を強化します:
ここで は共起回数です。これにより は大きく増加し、これらのペアのローカルな整列がより強化されます。しかし、対比損失は全てのトークンとパッチのペアに勾配更新を分散させるため、特定のペアへの更新の強さは制限されます:
これにより、個々のトークンとパッチの類似度の大幅な強化が防がれます。
tag結論
CLIP のトークンとパッチの可視化は、テキストと画像の表現間の付随的な、創発的な整列を活用しています。この整列は興味深いものの、CLIP のグローバルな対比学習に起因し、正確で信頼性のある説明可能性に必要な構造的な堅牢性を欠いています。結果として得られる可視化は、しばしばノイズと不一貫性を示し、詳細な解釈的応用における有用性が制限されます。

ColBERT や ColPali のような後期相互作用モデルは、テキストトークンと画像パッチ間の明示的で細粒度の整列を構造的に組み込むことで、これらの制限に対処しています。モダリティを独立して処理し、後段階で対象を絞った類似度計算を実行することで、これらのモデルは各テキストトークンが関連する画像領域と意味のある関連付けを持つことを保証します。
