



セマンティック埋め込みは、チャットボットや AI アート モデルを含む最新の AI モデルの中核です。ユーザーからは見えないことがありますが、表面のすぐ下に潜んでいます。
埋め込みの理論は 2 つの部分から成り立っています:
- 物事 — AI モデルの外部にあるテキストや画像などの物事は、それらの物事に関するデータから AI モデルによって作成されたベクトルによって表現されます。
- AI モデルの外部にある物事の関係性は、それらのベクトル間の空間的な関係によって表現されます。私たちは、そのように機能するベクトルを作成するように AI モデルを特別にトレーニングします。
画像とテキストのマルチモーダルモデルを作成する場合、画像の埋め込みとそれらの画像を説明または関連するテキストの埋め込みが比較的近くなるようにモデルをトレーニングします。これら 2 つのベクトルが表す物事(画像とテキスト)の間の意味的な類似性は、2 つのベクトル間の空間的な関係に反映されます。
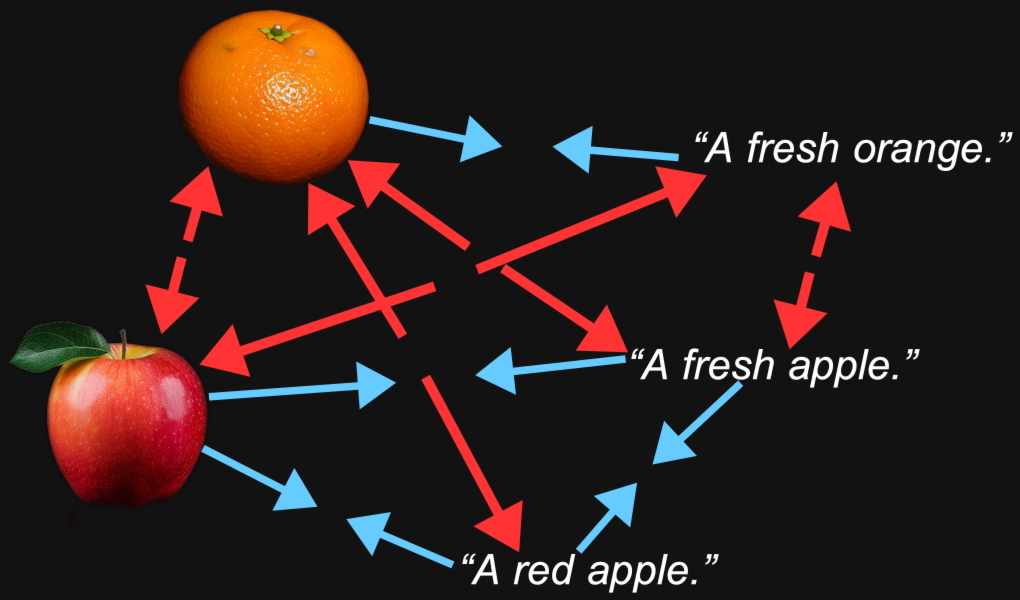
例えば、オレンジの画像の埋め込みベクトルと「新鮮なオレンジ」というテキストのベクトルは、同じ画像と「新鮮なりんご」というテキストよりも近くなることが合理的に予想されます。
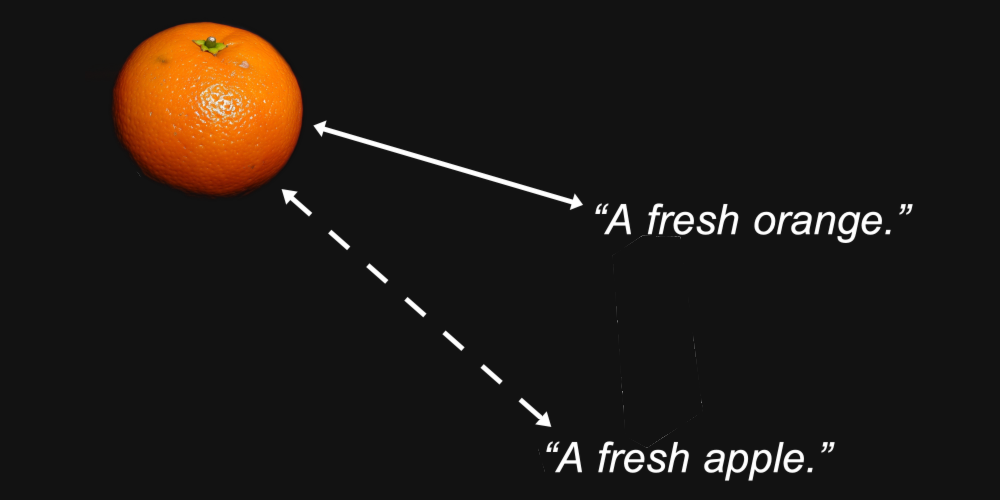
これが埋め込みモデルの目的です:私たちが気にする特徴(画像に描かれている果物の種類やテキストで名付けられている果物など)が、それらの間の距離に保持される表現を生成することです。
しかしマルチモーダリティは別の要素をもたらします。オレンジの写真は「新鮮なオレンジ」というテキストよりもりんごの写真に近く、「新鮮なりんご」というテキストはりんごの画像よりも別のテキストに近いことがわかるかもしれません。
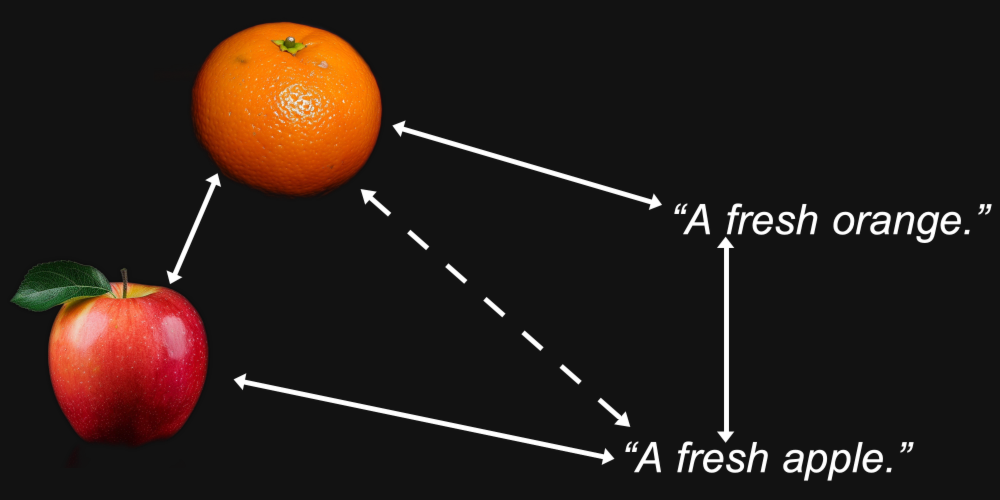
これは、Jina AI の Jina CLIP モデル(jina-clip-v1)を含むマルチモーダルモデルで実際に起こることです。
これを検証するために、Flickr8k テストセットから 1,000 のテキスト-画像ペアをサンプリングしました。各ペアには 5 つのキャプションテキスト(technically にはペアではありません)と 1 つの画像が含まれており、5 つのテキストはすべて同じ画像を説明しています。
例えば、以下の画像(Flickr8k データセットの 1245022983_fb329886dd.jpg):

その 5 つのキャプション:
A child in all pink is posing nearby a stroller with buildings in the distance.
A little girl in pink dances with her hands on her hips.
A small girl wearing pink dances on the sidewalk.
The girl in a bright pink skirt dances near a stroller.
The little girl in pink has her hands on her hips.
Jina CLIP を使用して画像とテキストを埋め込み、次のことを行いました:
- 画像埋め込みとそのキャプションテキストの埋め込みのコサイン類似度を比較。
- 同じ画像を説明する 5 つのキャプションテキストの埋め込みを取り、それらのコサイン類似度を相互に比較。
結果は図 1 に示すように、驚くほど大きな差が見られました:
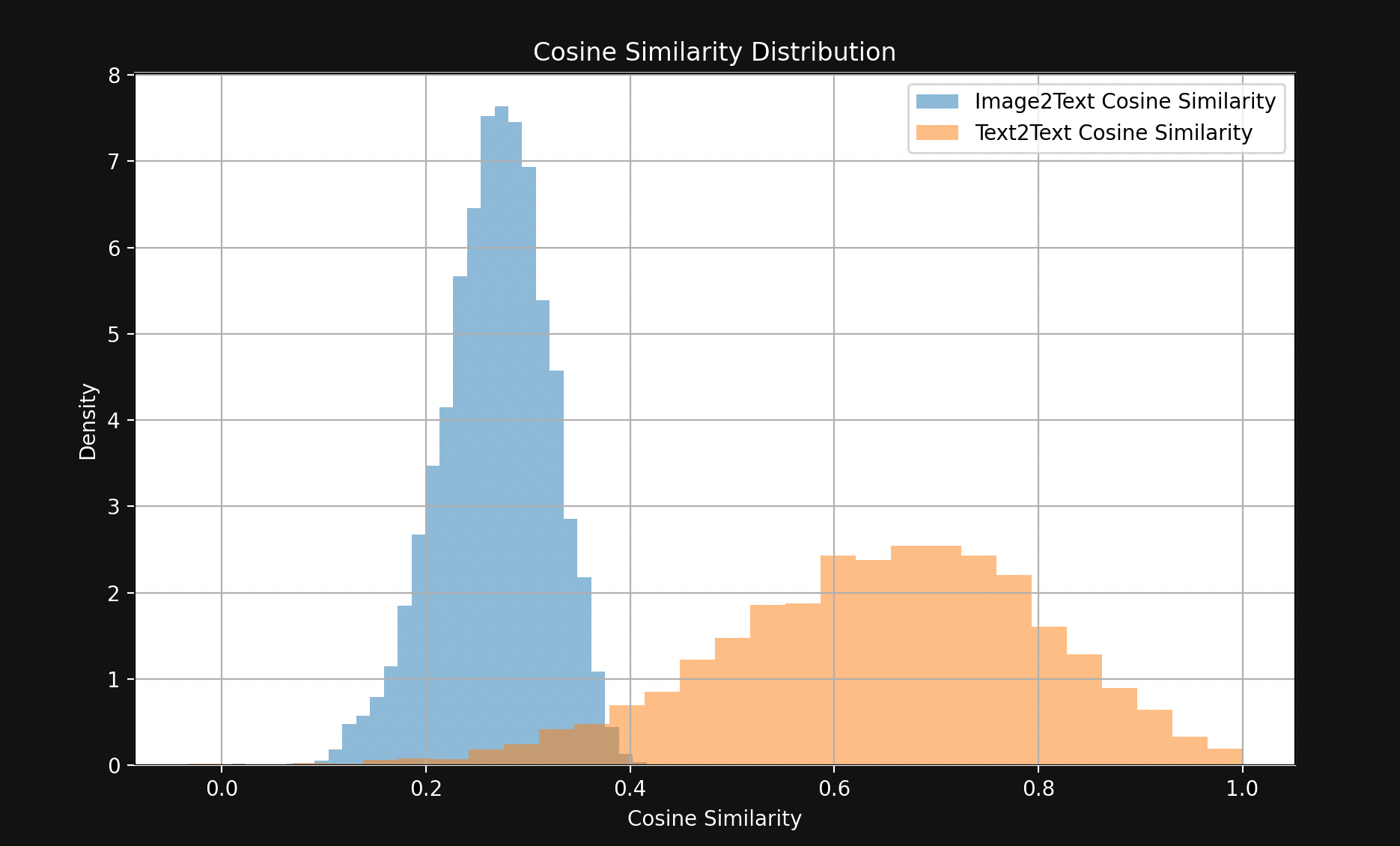
わずかな例外を除いて、一致するテキストペアは一致する画像-テキストペアよりもはるかに近接しています。これは、Jina CLIP が埋め込み空間の一部にテキストをエンコードし、画像を比較的遠い別の部分にエンコードしていることを強く示しています。このテキストと画像の間の空間がマルチモーダルギャップです。

マルチモーダル埋め込みモデルは、私たちが気にする意味的な情報以上のものをエンコードしています:入力の媒体をエンコードしているのです。Jina CLIP によると、「一枚の絵は千の言葉に値する」という諺は当てはまりません。どれだけ言葉を重ねても完全には等価にならない内容を持っているのです。誰もトレーニングしていないのに、入力の媒体をその埋め込みの意味にエンコードしています。
この現象は、論文『Mind the Gap: Understanding the Modality Gap in Multi-modal Contrastive Representation Learning』[Liang et al., 2022]で「モダリティギャップ」として研究されています。モダリティギャップとは、埋め込み空間における、ある媒体の入力と別の媒体の入力との間の空間的な分離のことです。モデルはそのようなギャップを意図的にトレーニングされているわけではありませんが、マルチモーダルモデルに広く見られます。
Jina CLIP におけるモダリティギャップに関する私たちの調査は、Liang et al. [2022]に大きく基づいています。
tagモダリティギャップはどこから来るのか?
Liang et al. [2022]は、モダリティギャップの主要な 3 つの源を特定しています:
- 「コーン効果」と呼ばれる初期化バイアス。
- トレーニング中の温度(ランダム性)の低下により、このバイアスを「アンラーン」することが非常に困難になる。
- マルチモーダルモデルで広く使用される対照学習手順が、意図せずにギャップを強化する。
これらを順番に見ていきましょう。
tagコーン効果
CLIP または CLIP スタイルのアーキテクチャで構築されたモデルは、実際には2つの独立した埋め込みモデルが連携したものです。画像-テキストのマルチモーダルモデルの場合、以下のスキーマのように、テキストをエンコードするモデルと、画像をエンコードする完全に別個のモデルがあります。
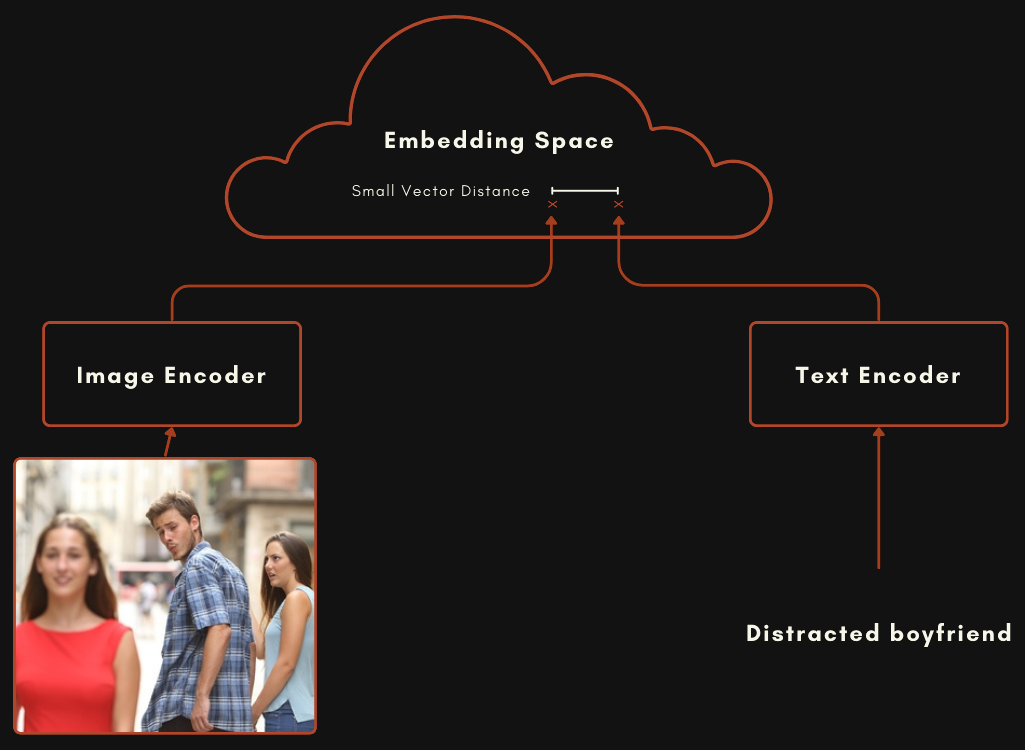
これら2つのモデルは、テキストが画像を適切に説明している場合、画像の埋め込みとテキストの埋め込みが比較的近くなるように訓練されます。
このようなモデルは、両方のモデルの重みをランダム化し、画像とテキストのペアを同時に提示して、2つの出力間の距離を最小化するようにゼロから訓練することで構築できます。オリジナルの OpenAI CLIP モデルはこの方法で訓練されました。ただし、これには多くの画像-テキストペアと計算コストの高い訓練が必要です。最初の CLIP モデルでは、OpenAI はインターネット上のキャプション付き素材から4億組の画像-テキストペアを収集しました。
より最近の CLIP スタイルのモデルは事前訓練されたコンポーネントを使用します。これは、テキスト用と画像用それぞれの良好な単一モード埋め込みモデルとして、各コンポーネントを個別に訓練することを意味します。その後、これら2つのモデルは画像-テキストペアを使用して一緒に訓練され、この過程は対照チューニングと呼ばれます。一致する画像-テキストペアを使用して、一致するテキストと画像の埋め込みをより近づけ、一致しないものをより遠ざけるように重みを徐々に「調整」します。
この手法は一般的に、取得が困難で高コストな画像-テキストペアのデータを少なくて済み、より入手が容易なキャプションのない単純なテキストと画像を大量に使用します。Jina CLIP(jina-clip-v1)はこの後者の方法で訓練されました。一般的なテキストデータを使用してJinaBERT v2 モデルをテキストエンコーディング用に事前訓練し、事前訓練されたEVA-02 画像エンコーダーを使用し、Koukounas et al. [2024]で概説されているように、様々な対照訓練技術を用いてさらに訓練しました。
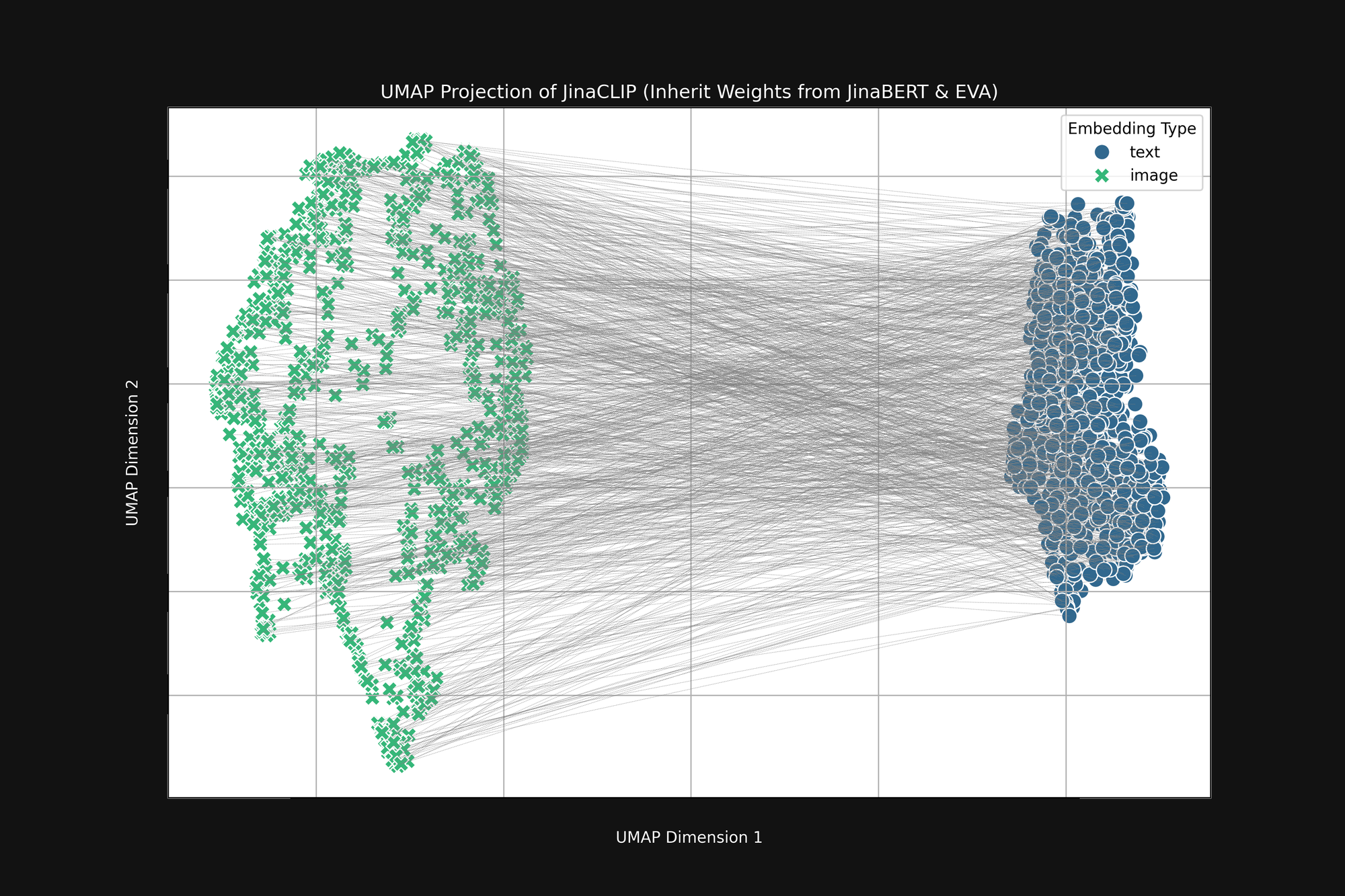
これらの2つの事前訓練されたモデルを取り、画像-テキストペアで訓練する前の出力を見ると、重要なことに気付きます。図2(上)は、事前訓練された EVA-02 エンコーダーが生成した画像埋め込みと事前訓練された JinaBERT v2 が生成したテキスト埋め込みをUMAPで2次元に投影したもので、灰色の線は一致する画像-テキストペアを示しています。これはクロスモーダル訓練の前の状態です。
結果は、一方の端に画像埋め込み、もう一方の端にテキスト埋め込みがある、一種の切断された「円錐」形状になります。この円錐形状は2次元投影では十分に表現できませんが、上の画像でおおよその形を見ることができます。すべてのテキストは埋め込み空間の一部に、すべての画像は別の部分にクラスター化されています。訓練後も、テキストが一致する画像よりも他のテキストに類似している場合、この初期状態がその大きな理由です。画像と最もマッチするテキスト、テキストとテキスト、画像と画像のマッチングという目的は、この円錐形状と完全に両立します。
モデルは生まれた時から偏見を持っており、学習してもそれは変わりません。図3(下)は、画像-テキストペアを使用して完全に訓練された後のリリースされた Jina CLIP モデルの同じ分析です。マルチモーダルのギャップは、むしろさらに顕著になっています。
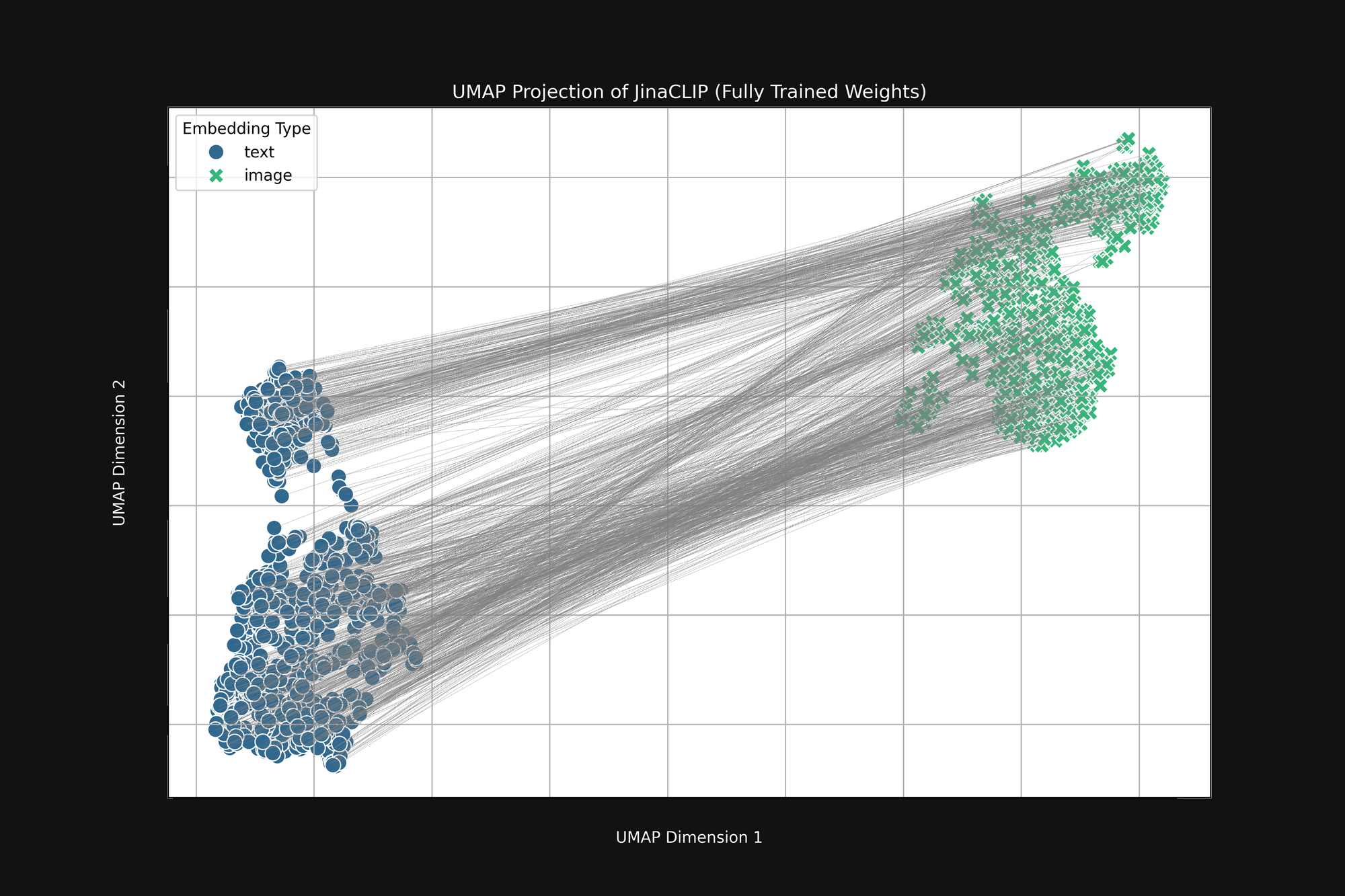
広範な訓練の後でも、Jina CLIP はメディアをメッセージの一部としてエンコードし続けています。
完全にランダムな初期化を使用する、より計算コストの高い OpenAI のアプローチを使用しても、このバイアスは取り除けません。オリジナルの OpenAI CLIP アーキテクチャを取り、すべての重みを完全にランダム化して、上記と同じ分析を行いました。結果は図4に示すように、依然として切断された円錐形状になります:
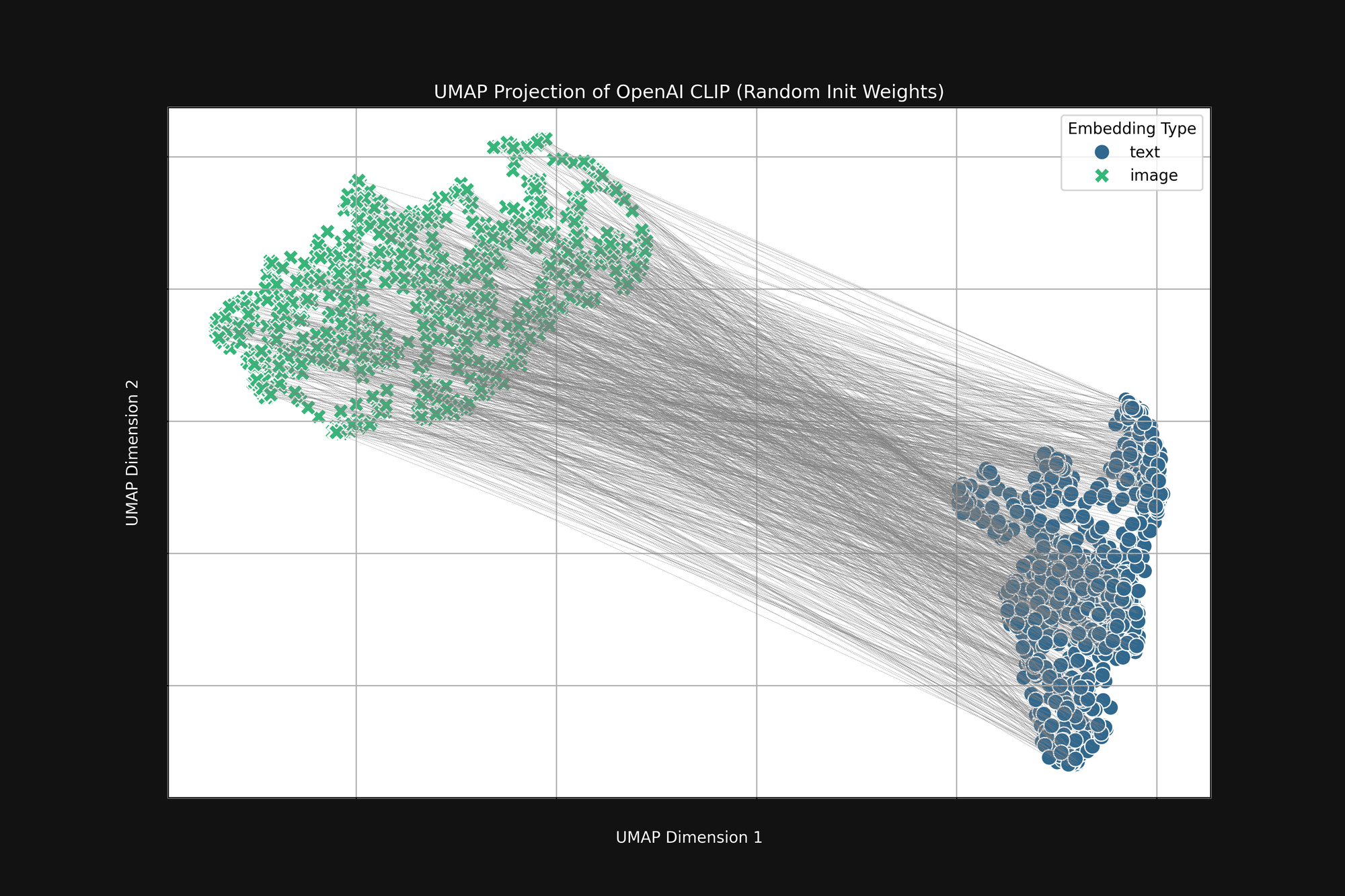
このバイアスは構造的な問題であり、解決策がない可能性があります。もしそうであれば、訓練中にこれを補正するか軽減する方法を探すしかありません。
tag訓練温度
AI モデルの訓練中、通常はプロセスにランダム性を加えます。訓練サンプルのバッチがモデルの重みをどれだけ変更すべきかを計算し、実際に重みを変更する前にそれらの変更に小さなランダム要因を加えます。このランダム性の量を、熱力学での使用方法にちなんで温度と呼びます。
高い温度はモデルに非常に速い大きな変化を生み出し、低い温度はモデルが訓練データを見るたびに変更できる量を減少させます。結果として、高い温度では個々の埋め込みが訓練中に埋め込み空間内で大きく移動することが予想され、低い温度では移動が非常にゆっくりになります。
AI モデルの訓練のベストプラクティスは、高い温度から始めて徐々に下げることです。これにより、重みがランダムか目標から遠い初期段階で大きな学習の飛躍を可能にし、その後より安定的に詳細を学習できるようになります。
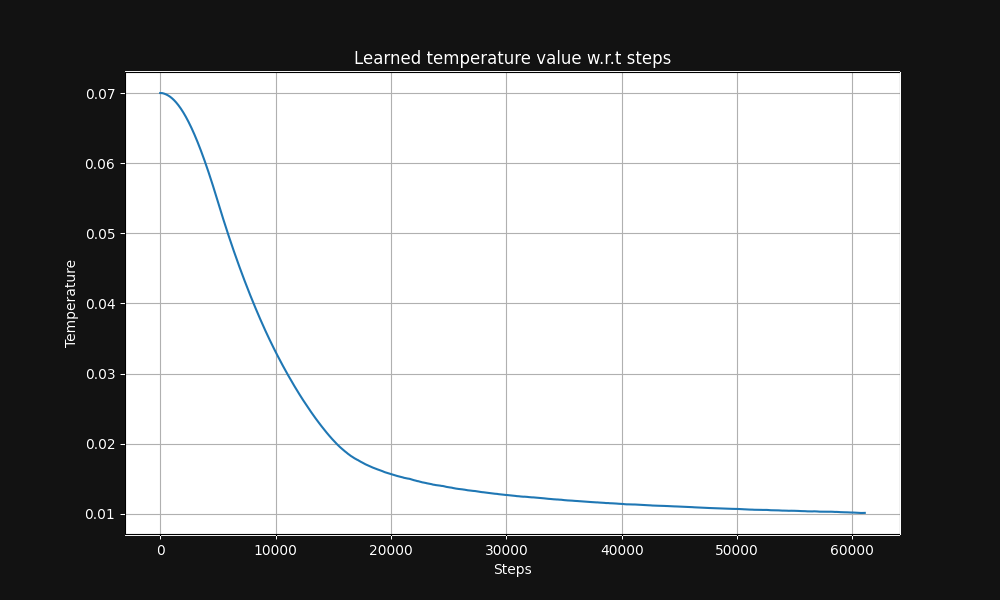
Jina CLIP の画像-テキストペア訓練は、0.07の温度(これは比較的高い温度です)から始まり、図5に示すように、訓練ステップに応じて指数関数的に0.01まで低下させます:
私たちは、温度を上げる — ランダム性を増やす — ことで円錐効果が減少し、画像埋め込みとテキスト埋め込みが全体的により近づくかどうかを知りたいと考えました。そこで、固定温度0.1(非常に高い値)で Jina CLIP を再訓練しました。各訓練エポックの後、図1のように、画像-テキストペアとテキスト-テキストペア間の距離の分布を確認しました。結果は以下の図6に示されています:
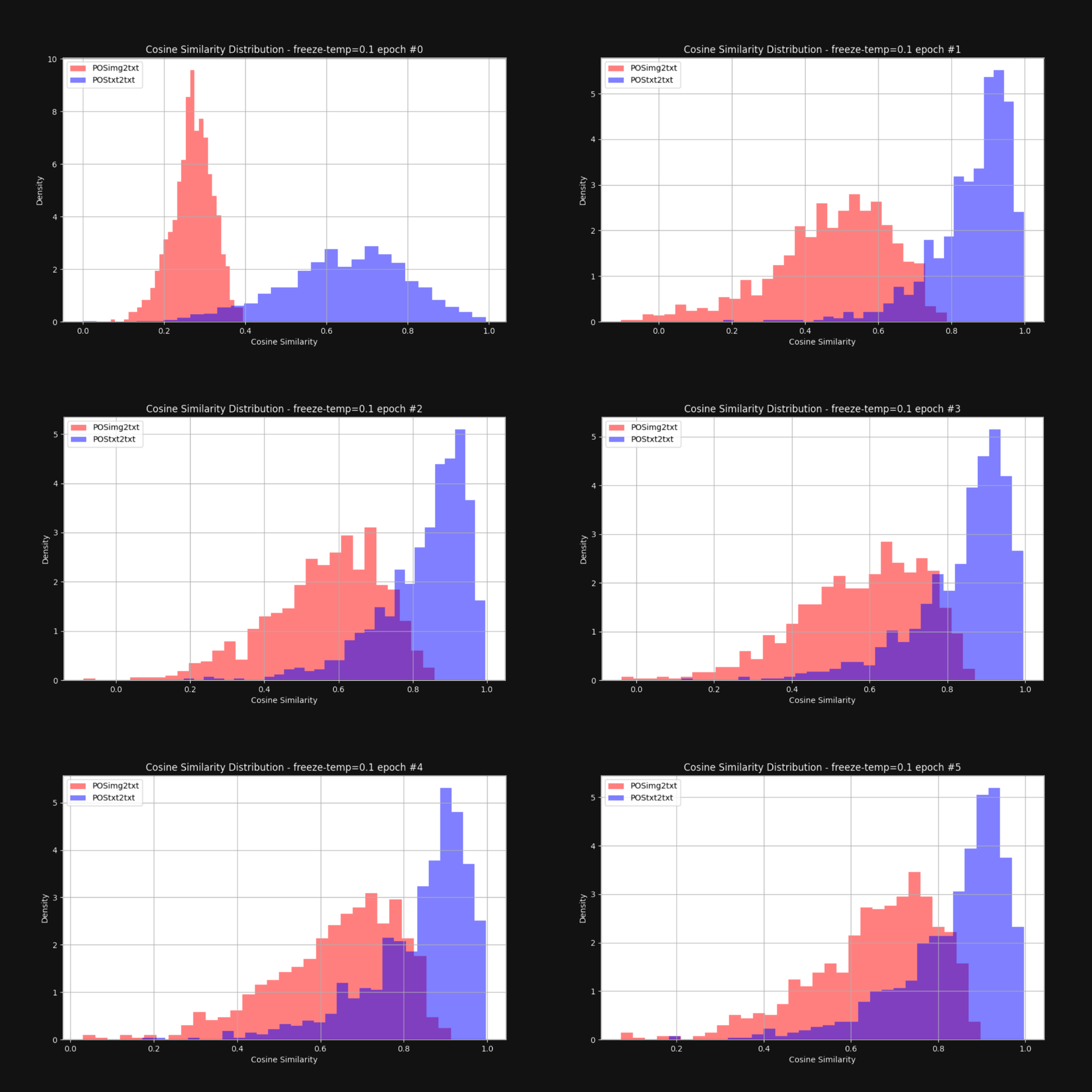
ご覧の通り、高い温度を維持することでモダリティ間のギャップは劇的に縮小します。訓練中に埋め込みが大きく動くことを許容することで、埋め込み分布の初期バイアスを克服する大きな助けとなります。
しかし、これにはコストが伴います。私たちは6つの異なる検索テストでモデルのパフォーマンスをテストしました:MS-COCO、Flickr8k、Flickr30kのデータセットから、3つのテキスト-テキスト検索テストと3つのテキスト-画像検索テストを行いました。図7に示すように、すべてのテストで訓練初期にパフォーマンスが急落し、その後非常にゆっくりと上昇することが分かります:
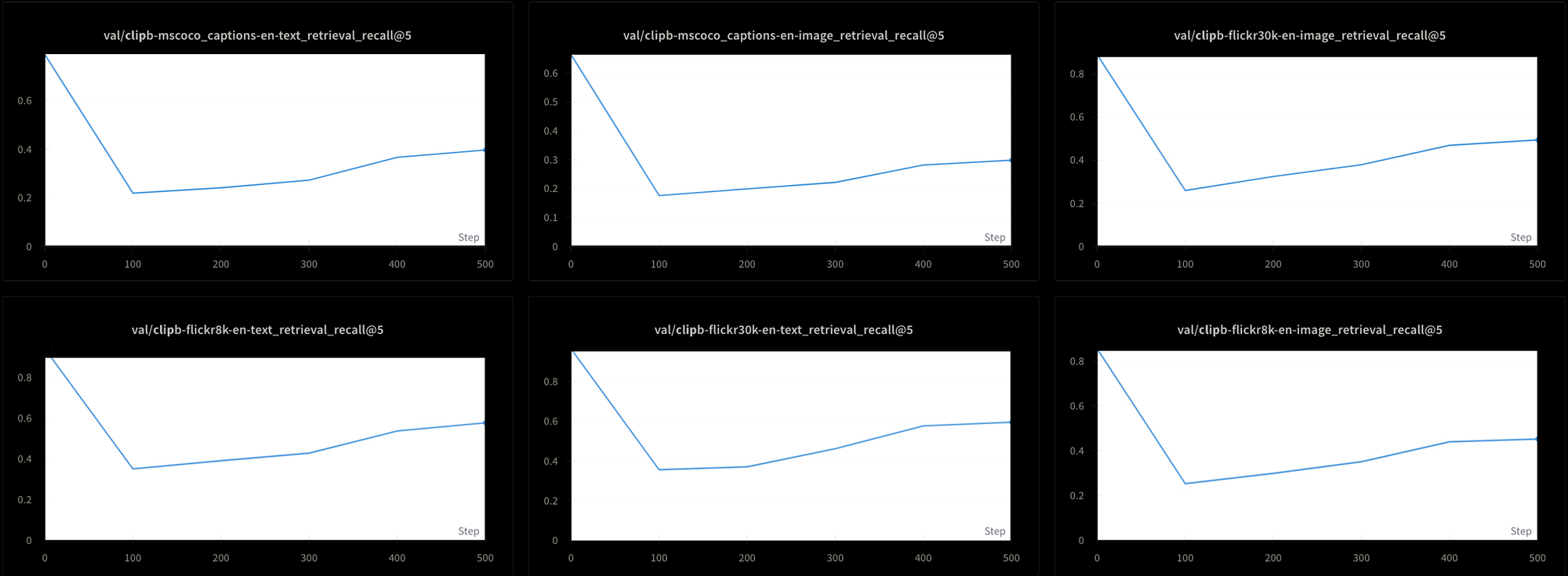
この一定の高温度を使用して Jina CLIP のようなモデルを訓練するには、極めて時間がかかり、コストがかかるでしょう。理論的には可能ですが、これは実用的な解決策ではありません。
tag対照学習と誤った負例の問題
Liang et al. [2022] はまた、標準的な対照学習の実践—CLIP スタイルのマルチモーダルモデルを訓練するために使用するメカニズム—がマルチモーダルギャップを強化する傾向があることを発見しました。
対照学習は基本的に単純な概念です。画像埋め込みとテキスト埋め込みがあり、それらがより近くにあるべきことを知っているので、訓練中にモデルの重みを調整してそうなるようにします。ゆっくりと進め、重みを少しずつ調整し、2つの埋め込みがどれだけ離れているかに比例して調整します:近ければ近いほど、変更は小さくなります。
この技術は、一致する場合に埋め込みを近づけるだけでなく、一致しない場合にそれらを遠ざける場合の方がはるかに効果的です。一緒になるべき画像-テキストのペアだけでなく、離れているべきペアも必要です。
これには以下の問題があります:
- データソースは完全に一致するペアのみで構成されています。人間が無関係であると確認したテキストと画像のデータベースを作成する人はいませんし、ウェブのスクレイピングやその他の教師なしまたは半教師あり手法で容易に構築することもできません。
- 表面的には完全に無関係に見える画像とテキストのペアであっても、必ずしもそうとは限りません。そのような否定的な判断を客観的に下すことができる意味論の理論は持ち合わせていません。例えば、ポーチで横たわる猫の画像は、「ソファで眠る人」というテキストと完全な不一致とは言えません。どちらも何かの上で横たわっているという共通点があります。
理想的には、確実に関連がある AND 関連がない画像-テキストのペアで訓練したいところですが、関連がないことが分かっているペアを得る明確な方法はありません。人々に「このテキストはこの画像を説明していますか?」と尋ねて一貫した回答を期待することは可能です。しかし「このテキストはこの画像と全く関係がありませんか?」と尋ねて一貫した回答を得ることは、はるかに困難です。
その代わりに、訓練データからランダムに画像とテキストを選択して、関連のないペアを作成し、実質的に常に不適切なマッチングになることを期待します。実際の仕組みとしては、訓練データをバッチに分割します。Jina CLIP の訓練では、32,000個の一致する画像-テキストペアを含むバッチを使用しましたが、この実験ではバッチサイズは16のみでした。
以下の表は Flickr8k からランダムにサンプリングした16個の画像-テキストペアです:
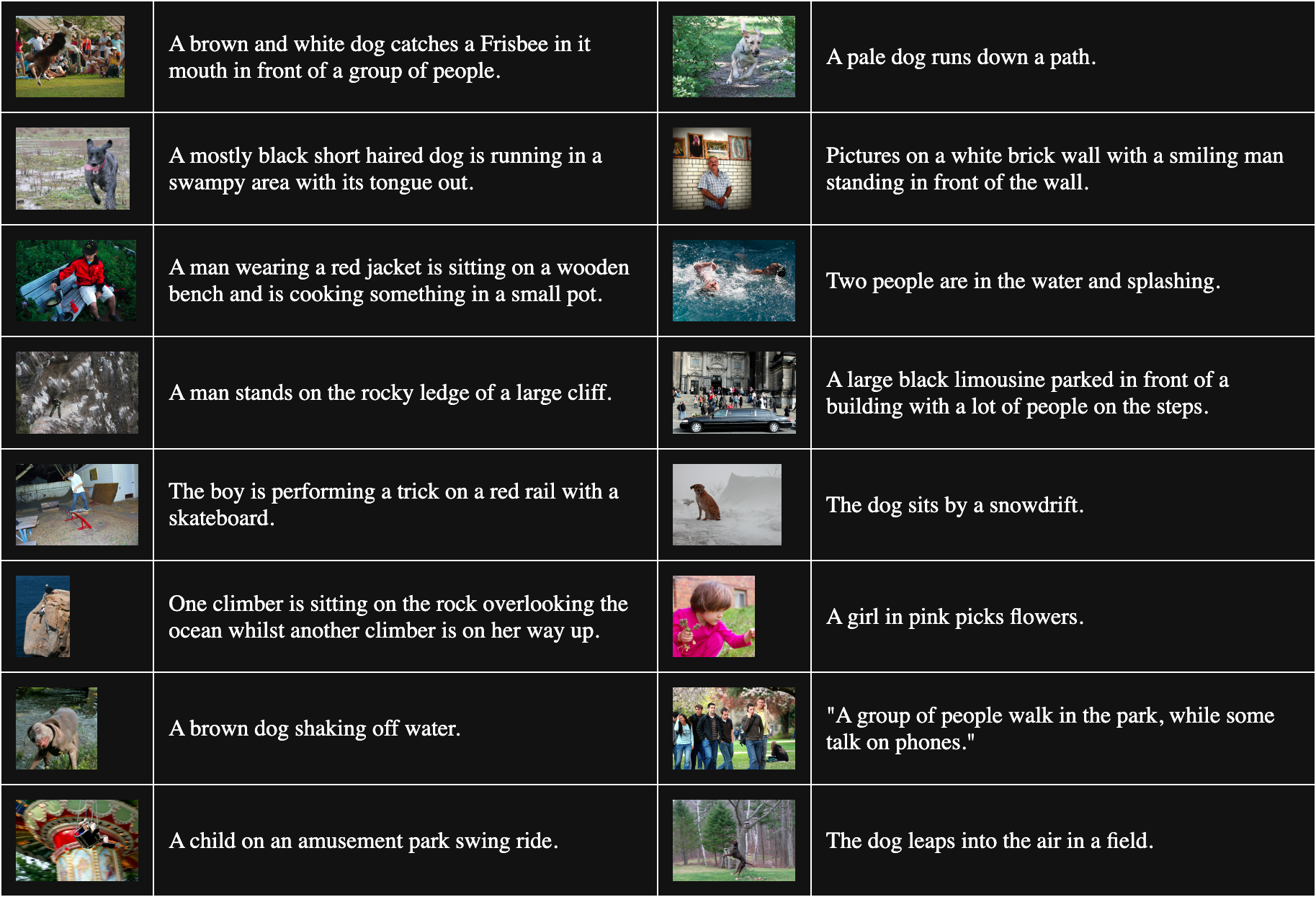
一致しないペアを得るために、バッチ内のすべての画像を、それに一致するもの以外のすべてのテキストと組み合わせます。例えば、以下のペアは一致しない画像とテキストです:

キャプション:ピンク色の服を着た少女が花を摘んでいます。
しかし、この手順は、他の画像に一致するすべてのテキストが等しく不適切なマッチであると仮定しています。これは必ずしも真実ではありません。例えば:

キャプション:犬が雪の吹きだまりの横に座っています。
このテキストはこの画像を説明してはいませんが、犬という共通点があります。このペアを不一致として扱うと、「犬」という単語をどの犬の画像からも遠ざける傾向が生まれます。
Liang et al. [2022] は、これらの不完全な不一致ペアがすべての画像とテキストを互いに遠ざけることを示しています。
私たちは、完全にランダムに初期化された vit-b-32 画像モデルと同様にランダム化された JinaBERT v2 テキストモデルを使用して、訓練温度を一定の0.02(やや低い温度)に設定して、彼らの主張を検証することにしました。2つの訓練データセットを構築しました:
- Flickr8k からランダムに抽出したバッチで、上記のように構築された不一致ペアを含むもの。
- 同じ画像の複数のコピーに異なるテキストを付けたものを各バッチに意図的に含むように構築したもの。これにより、「不一致」ペアの相当数が実際には互いに正しい一致であることが保証されます。
その後、それぞれのデータセットで2つのモデルを1エポック訓練し、各モデルについて Flickr8k データセットの1,000のテキスト-画像ペア間の平均コサイン距離を測定しました。ランダムバッチで訓練されたモデルの平均コサイン距離は0.7521で、意図的に一致する「不一致」ペアを多く含むモデルの平均コサイン距離は0.7840でした。不正確な「不一致」ペアの影響はかなり大きいことが分かります。実際のモデル訓練ははるかに長く、はるかに多くのデータを使用することを考えると、この効果が成長し、画像とテキスト全体の間のギャップを拡大することが分かります。
tagメディアがメッセージである
カナダのコミュニケーション理論家マーシャル・マクルーハンは、1964年の著書『メディア論—人間の拡張の諸相』で「メディアがメッセージである」という言葉を生み出し、メッセージは自律的ではないことを強調しました。メッセージは意味に大きく影響を与える文脈の中で私たちに届き、彼は有名に、その文脈の最も重要な部分の1つがコミュニケーションメディアの性質であると主張しました。
マルチモーダリティ・ギャップは、AI モデルにおける創発的な意味現象のクラスを研究する独特の機会を提供してくれます。Jina CLIP に対して、学習データの媒体をエンコードするように誰も指示していませんでした — それなのに、そうしてしまったのです。マルチモーダルモデルの問題を解決できていないとしても、少なくとも問題の発生源については理論的によく理解できています。
同じような偏りにより、私たちのモデルは、まだ探していない他の要素もエンコードしているはずだと考えるべきです。例えば、多言語埋め込みモデルでも同様の問題が存在する可能性が高いです。特に類似の学習手法が広く使用されているため、2つ以上の言語での共同学習は、おそらく言語間で同じようなギャップを生み出しています。このギャップ問題の解決策は、非常に広範な影響を持つ可能性があります。
より広範なモデルにおける初期化バイアスの調査も、新たな洞察につながるでしょう。埋め込みモデルにとってメディアがメッセージであるならば、私たちの気付かないうちに、他にどのような情報がモデルにエンコードされているのでしょうか?
