


日曜の夜。週末かけて魂を込めて書き上げた記事に「投稿」をクリック。一言一句、アイデアの全てがあなた独自のもの。いくつかの「いいね」が少しずつ集まっていく。バイラルとまではいかないが、これはあなたの作品だ。
3日後、フィードをスクロールしていると、そこにあった - あなたの記事の魂が他人の体に宿っているのを! 言葉は並び替えられているが、自分の創作だとすぐにわかる。最悪なのは、その盗作バージョンが拡散され、あなたの創造性を盗んだ上で大成功を収めていること。これは私たちが望んだクリエイティブ・エコノミーではない。
明白な解決策は作品に自分の名前を付けることだ。しかし正直に言えば、それは最も簡単に削除できるものでもある。もっと良い方法はないだろうか?この記事では、embedding モデルを使用して、オリジナルコンテンツに署名と検出の両方が可能な透かし技術を紹介する。これは単なる検索/RAG の決まり文句ではない - jina-embeddings-v3 の長文コンテキストや多言語アラインメントなどのユニークな機能を活用して堅牢な認証システムを作り出し、LLM による言い換えや翻訳などの変換を経ても信頼性の高いコンテンツ検証を維持することができる。
tagテキスト透かしの理解
デジタル透かしは長年にわたりコンテンツ保護の要となってきた。半透明のロゴが重ねられたミームを見かけたことがあるだろう - これが画像透かしの最も基本的な形式だ。現代の透かし技術は単純な視覚的オーバーレイをはるかに超えて進化しており、人間の目には気付かれないが機械で読み取り可能なものが多い。
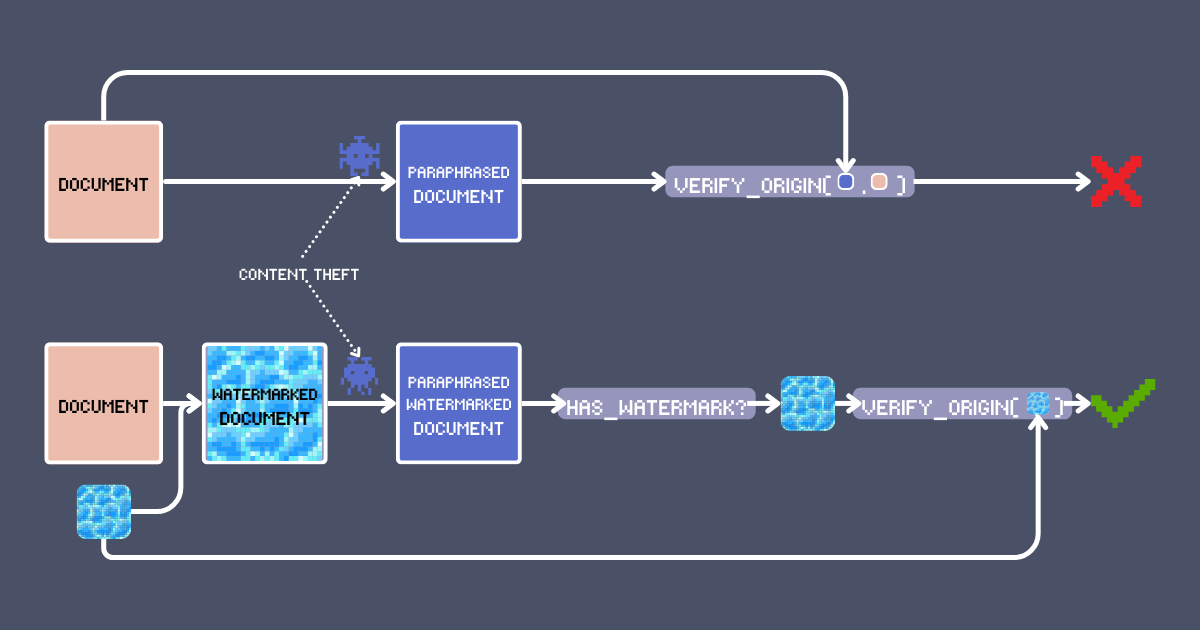
テキスト透かしも同様の原則に従いますが、意味空間で動作します。ピクセルを変更する代わりに、テキスト透かしは、元の意味を保持しながら検出可能な署名を埋め込む方法でコンテンツを微妙に修正します。そのため、効果的なテキスト透かしに必要な主要な要件は:
- 意味の保持:視覚的な透かしが画像の重要な要素を覆い隠すべきでないように、透かしを入れたテキストは元の意味と可読性を維持する必要があります。
- 不可知性:人間の読者には気付かれない透かしにすることで、コンテンツ変換時に意図的に保持したり削除したりできないようにする必要があります。
- 機械検出可能:人間の読者には微妙な透かしであっても、アルゴリズムが確実に識別できる明確で測定可能なパターンを作成する必要があります。
- 変換不変性:意図的なものであれ透かしの存在を知らないものであれ、あらゆるコンテンツ変換(言い換えや翻訳など)は、透かしを保持するか、元のコンテンツの構造や意味を根本的に変更するような大幅な変更を必要とする必要があります。
tagテキスト透かしに Embeddings を使用する
embeddings を使ってテキスト透かしシステムを構築してみましょう。まず、このシステムの主要なコンポーネントを定義します:
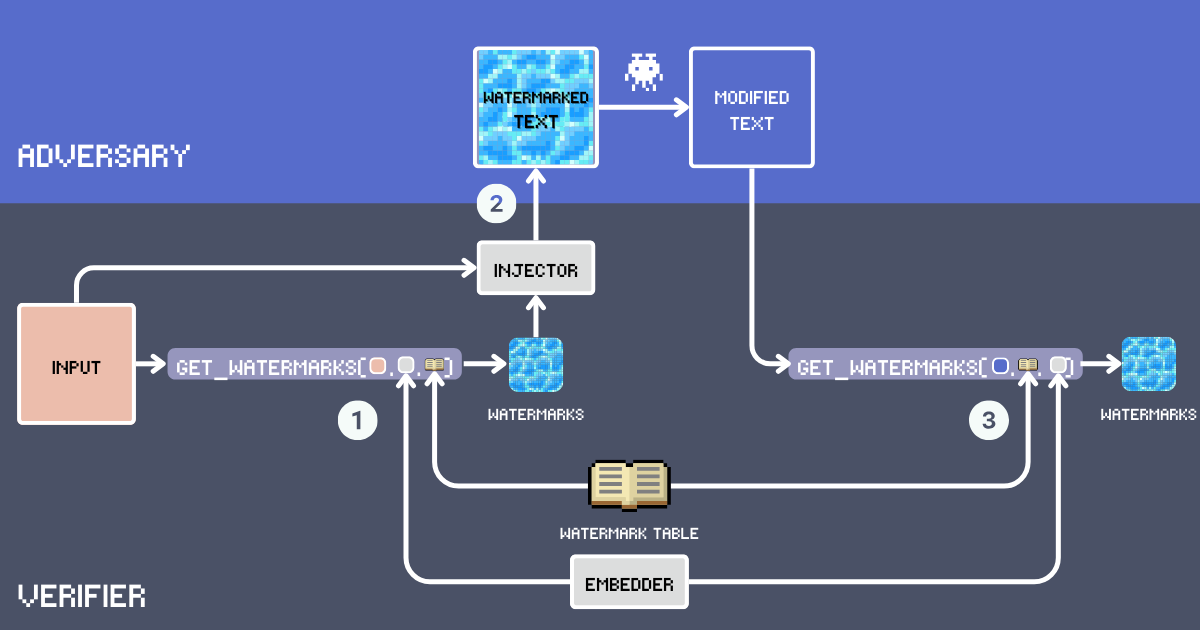
- 入力:透かしを入れる元のテキスト。
- 透かしテーブル:透かし候補の単語を含む秘密の語彙集。透かしの効果を最適にするため、単語は様々な文脈で自然に適合するほど一般的である必要があります。機能語、固有名詞、不自然に見える珍しい単語は除外されます。例えば
delve into、embarkは良い候補ですが、goodは一般的すぎます。以下では、上級英語語彙を使用して WatermarkTable を構築します。 - Embedder:2つの目的を持つ embedding モデル:
inputテキストに基づいてWatermarkTableから意味的に適切な単語を選択し、言い換えられた可能性のあるテキストで透かしを検出することを支援します。私たちは jina-embeddings-v3 を使用しています。これは非常に長いテキストと異なる言語の両方を上手く処理できるためです。これにより、長文の文書に透かしを入れ、翻訳された場合でも盗作を検出することができます。 - 透かし:入力テキストの embedding と テーブル内の embedding とのコサイン類似度を計算することで WatermarkTable から選択された単語。単語数は挿入率によって決定され、通常は入力単語数の 12% です。
- インジェクター:一貫性、事実の正確性、自然な流れ、透かし単語の均一な分布を維持しながら、透かし単語を入力テキストに統合する指示に従う LLM。
- 透かし入りテキスト:インジェクターが
inputに透かし単語を挿入した後の出力。 - 攻撃者(コンテンツ盗用):帰属表示なしに透かし入りテキストを流用しようとする存在で、通常は言い換え、翻訳、または軽微な編集を通じて行います。今日では、単に
Paraphrase [text]というプロンプトで LLM を使用して自動的に書き換えることを意味します。 - 変更されたテキスト:攻撃者による透かし入りテキストへの変更後の結果。これが透かしをチェックする必要のあるテキストです。
tagアルゴリズム


tag結論
これらの例から、この基本的なセットアップでも、埋め込みベースの電子透かしがかなり堅牢であることがわかります。特に注目すべきは、翻訳後でも透かしが検出可能なままだということです。この言語間での堅牢性は、jina-embeddings-v3 モデルの強力な多言語機能によって実現されています。強力な多言語および言語間機能がなければ、このような翻訳を通じた持続性は達成できなかったでしょう。
この透かしシステムの精度と堅牢性を向上させる方法はいくつかあります。まず、透かしテーブルを拡張し、多様性を確保するように慎重に構築することができます。これは重要です。なぜなら、より大きく多様な語彙は意味空間をより広くカバーし、任意のテキストに対して文脈的に適切な透かしを見つけやすくなり、同時に反復的または明白なパターンのリスクを減らすことができるからです。
Injector コンポーネントは、より洗練された挿入戦略を実装することで改善できます。例えば、不可視性を維持するために透かしを均一にテキスト全体に分散させるように指示することができます。さらに、late chunking 技術を使用して個々のセグメントや文に対して透かしを生成し、Injector が透かしの配置についてより細かい判断を下せるようにすることができます。これにより、最終的なテキストにおける全体的な不可視性と意味的な一貫性の両方を維持することができます。
より深く探求したい読者のために、「POSTMARK: A Robust Blackbox Watermark for Large Language Models」(Chang ら、EMNLP 2024)は、数学的な定式化と広範な実験を含む包括的なフレームワークを提示しています。著者らは、透かし語彙の構築、最適な挿入戦略、そして様々な攻撃に対する堅牢性を体系的に探求しています。また、自動評価と人間による評価の両方を通じて、透かしの検出とテキストの品質のトレードオフを徹底的に分析しています。
