

長文書のチャンキングには2つの問題があります。1つ目は、分割点の決定、つまり文書をどのように分割するかということです。固定トークン長、固定文数、あるいは正規表現や意味的分割モデルのようなより高度な技術を考慮することができます。正確なチャンク境界は、検索結果の可読性を向上させるだけでなく、RAG システムで LLM に供給されるチャンクが正確で十分なものであることを保証します。
2つ目の問題は、各チャンクにおける文脈の喪失です。文書が分割されると、ほとんどの人が次の論理的なステップとして、各チャンクを個別にバッチ処理で埋め込みます。しかし、これは元の文書からグローバルな文脈が失われることにつながります。多くの先行研究は最初の問題に取り組み、より良い境界検出が意味的表現を改善すると主張してきました。例えば、「意味的チャンキング」は、埋め込み空間で余弦類似度の高い文をグループ化して、意味的単位の分断を最小限に抑えます。
私たちの観点から、これら2つの問題はほぼ独立しており、別々に取り組むことができます。優先順位をつけるとすれば、2番目の問題がより重要だと考えます。
| 問題2:文脈情報 | |||
|---|---|---|---|
| 保持 | 喪失 | ||
| 問題1:分割点 | 良好 | 理想的なシナリオ | 貧弱な検索結果 |
| 不良 | 良好な検索結果だが、結果が人間に読みやすくないか LLM の推論に適していない可能性がある | 最悪のシナリオ |
tag文脈喪失に対する Late Chunking
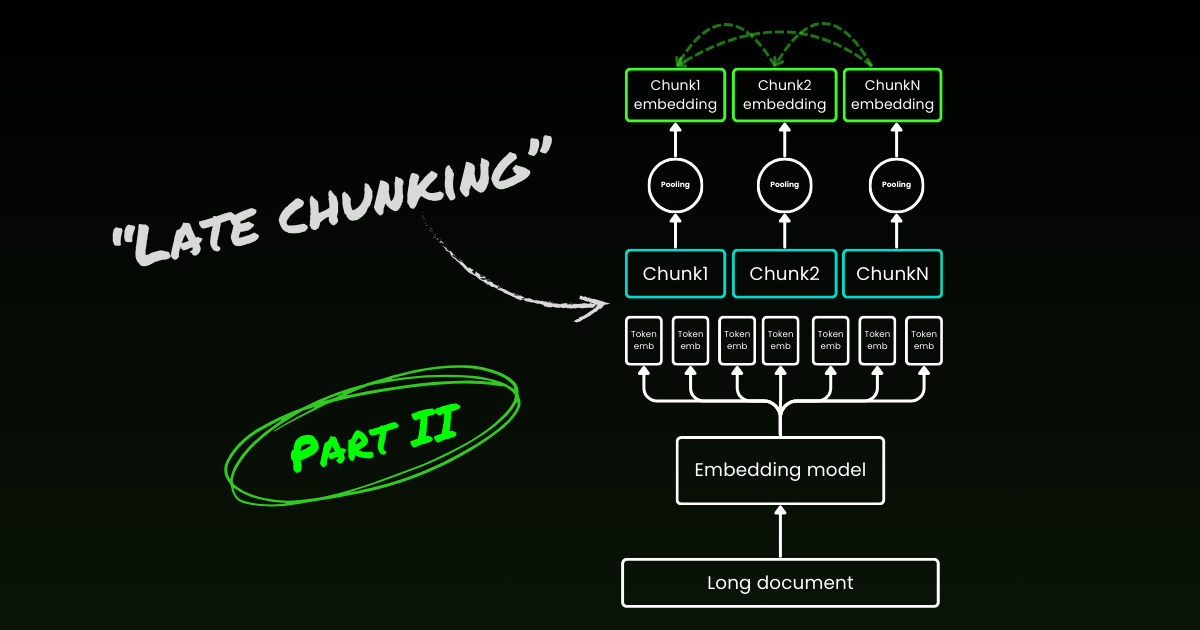
Late chunking は2番目の問題、つまり文脈の喪失から取り組みます。これは理想的な分割点や意味的境界を見つけることについてのものではありません。長文書を小さなチャンクに分割するには、依然として正規表現、ヒューリスティクス、その他の技術を使用する必要があります。しかし、分割されたら直ちに各チャンクを埋め込むのではなく、late chunking ではまず文書全体を1つのコンテキストウィンドウで符号化します(jina-embeddings-v3 の場合は8192トークン)。その後、境界の手がかりに従って各チャンクの平均プーリングを適用します—これが late chunking の「late」という名前の由来です。

tagLate Chunking は不完全な境界手がかりに対して頑健
興味深いことに、実験によると late chunking は完璧な意味的境界の必要性を排除し、これは上述の最初の問題を部分的に解決します。実際、固定トークン境界に適用された late chunking は、意味的境界手がかりを用いたナイブなチャンキングよりも優れた性能を示します。固定長境界を使用する単純な分割モデルは、late chunking と組み合わせると、高度な境界検出アルゴリズムと同等の性能を発揮します。私たちは3つの異なるサイズの埋め込みモデルをテストし、結果はすべてのテストデータセットにおいて、それらすべてが一貫して late chunking の恩恵を受けることを示しています。そうは言っても、埋め込みモデル自体が性能に最も大きな影響を与える要因であり続けます—late chunking を使用した弱いモデルが、使用しない強いモデルを上回る例は一つもありません。

jina-embeddings-v2-small)に対する相対的な検索性能の改善。アブレーション研究の一環として、異なる境界手がかり(固定トークン長、文境界、意味的境界)と異なるモデル(jina-embeddings-v2-small、nomic-v1、jina-embeddings-v3)で late chunking をテストしました。MTEB での性能に基づくと、これら3つの埋め込みモデルのランキングは:jina-embeddings-v2-small < nomic-v1 < jina-embeddings-v3。ただし、この実験の焦点は埋め込みモデル自体のパフォーマンスを評価することではなく、より優れた埋め込みモデルが後期チャンキングと境界の手がかりとどのように相互作用するかを理解することにあります。実験の詳細については、研究論文をご確認ください。| Combo | SciFact | NFCorpus | FiQA | TRECCOVID |
|---|---|---|---|---|
| Baseline | 64.2 | 23.5 | 33.3 | 63.4 |
| Late | 66.1 | 30.0 | 33.8 | 64.7 |
| Nomic | 70.7 | 35.3 | 37.0 | 72.9 |
| Jv3 | 71.8 | 35.6 | 46.3 | 73.0 |
| Late + Nomic | 70.6 | 35.3 | 38.3 | 75.0 |
| Late + Jv3 | 73.2 | 36.7 | 47.6 | 77.2 |
| SentBound | 64.7 | 28.3 | 30.4 | 66.5 |
| Late + SentBound | 65.2 | 30.0 | 33.9 | 66.6 |
| Nomic + SentBound | 70.4 | 35.3 | 34.8 | 74.3 |
| Jv3 + SentBound | 71.4 | 35.8 | 43.7 | 72.4 |
| Late + Nomic + SentBound | 70.5 | 35.3 | 36.9 | 76.1 |
| Late + Jv3 + SentBound | 72.4 | 36.6 | 47.6 | 76.2 |
| SemanticBound | 64.3 | 27.4 | 30.3 | 66.2 |
| Late + SemanticBound | 65.0 | 29.3 | 33.7 | 66.3 |
| Nomic + SemanticBound | 70.4 | 35.3 | 34.8 | 74.3 |
| Jv3 + SemanticBound | 71.2 | 36.1 | 44.0 | 74.7 |
| Late + Nomic + SemanticBound | 70.5 | 36.9 | 36.9 | 76.1 |
| Late + Jv3 + SemanticBound | 72.4 | 36.6 | 47.6 | 76.2 |
不適切な境界に対して耐性があるからといって、境界を無視できるというわけではありません—人間と LLM の可読性の両方にとって依然として重要です。私たちの見方は次の通りです:セグメンテーションの最適化(前述の第1の問題)において、意味やコンテキストの損失を心配することなく、可読性に完全に焦点を当てることができます。後期チャンキングは良い境界点も悪い境界点も処理できるので、考慮すべきは可読性だけです。
tag後期チャンキングは双方向
後期チャンキングに関するもう1つの一般的な誤解は、条件付きチャンク埋め込みが「先を見ない」前のチャンクのみに依存しているということです。これは間違いです。後期チャンキングの条件付き依存関係は実際に双方向であり、一方向ではありません。これは、埋め込みモデル(エンコーダーのみのトランスフォーマー)の注意行列が、自己回帰モデルで使用される三角マスク行列とは異なり、完全に接続されているためです。形式的には、チャンク の埋め込み であり、 ではありません。ここで は言語モデルの因数分解を表します。これは後期チャンキングが正確な境界配置に依存しない理由も説明しています。

tag後期チャンキングは訓練可能
後期チャンキングは埋め込みモデルの追加訓練を必要としません。平均プーリングを使用する長いコンテキストの埋め込みモデルであれば適用可能で、実務者にとって非常に魅力的です。ただし、質問応答やクエリ-ドキュメント検索などのタスクに取り組んでいる場合は、ファインチューニングによってパフォーマンスをさらに向上させることができます。具体的には、訓練データは以下の要素からなるタプルで構成されます:
- クエリ(質問や検索語など)
- クエリに関連する情報を含むドキュメント
- ドキュメント内の関連スパン(クエリに直接対応するテキストの特定のチャンク)
モデルは、InfoNCE のような対照損失関数を使用して、クエリをその関連スパンとペアリングすることで訓練されます。これにより、関連スパンがクエリと埋め込み空間で密接に整列し、無関係なスパンはより遠くに押しやられます。その結果、モデルはチャンク埋め込みを生成する際に、ドキュメントの最も関連性の高い部分に焦点を当てることを学習します。詳細については、研究論文をご参照ください。
tag後期チャンキング vs コンテキスト検索
後期チャンキングが導入された直後、Anthropic はコンテキスト検索と呼ばれる別の戦略を導入しました。Anthropic の手法は、失われたコンテキストの問題に対する総当たり的なアプローチで、以下のように機能します:
- 各チャンクは完全なドキュメントと共に LLM に送信されます
- LLM は各チャンクに関連するコンテキストを追加します
- これにより、より豊かで情報量の多い埋め込みが得られます
私たちの見解では、これは本質的にコンテキスト強化であり、グローバルコンテキストが LLM を使用して各チャンクに明示的にハードコードされます。これはコスト、時間、ストレージの面で高価です。さらに、LLM がコンテキストを効果的に強化するために正確で読みやすいチャンクに依存するため、このアプローチがチャンク境界に対して耐性があるかどうかは不明確です。対照的に、後期チャンキングは上記で示したように境界の手がかりに対して高い耐性を持っています。埋め込みサイズは同じままなので、追加のストレージは必要ありません。埋め込みモデルの完全なコンテキスト長を活用しているにもかかわらず、強化を生成するために LLM を使用するよりもはるかに高速です。研究論文の定性的研究では、Anthropic のコンテキスト検索が後期チャンキングと同様のパフォーマンスを示すことを示しています。しかし、後期チャンキングは、エンコーダーのみのトランスフォーマーの本来のメカニズムを活用することで、よりローレベルで汎用的で自然なソリューションを提供します。
tagどの埋め込みモデルが後期チャンキングをサポートしているか
後期チャンキングは jina-embeddings-v3 や v2 に限定されたものではありません。平均プーリングを使用する長いコンテキストの埋め込みモデルに適用できる、かなり汎用的なアプローチです。例えば、この投稿では nomic-v1 もサポートしていることを示しています。すべての埋め込みプロバイダーが自社のソリューションで後期チャンキングのサポートを実装することを心から歓迎します。
モデルユーザーとして、新しい埋め込みモデルや API を評価する際に、後期チャンキングをサポートしているかどうかを確認するには、以下の手順に従ってください:
- シングル出力:モデル/API は文章ごとに単一の最終埋め込みのみを提供し、トークンレベルの埋め込みは提供しませんか?もしそうなら、後期チャンク分割をサポートできない可能性が高いです(特に Web API の場合)。
- 長文脈サポート:モデル/API は少なくとも 8192 トークンの文脈を処理できますか?できない場合、後期チャンク分割は適用できません—より正確には、短い文脈のモデルに後期チャンク分割を適用する意味がありません。サポートしている場合は、単にサポートを謳っているだけでなく、実際に長い文脈で良好なパフォーマンスを発揮することを確認してください。これらの情報は通常、LongMTEB やその他の長文脈ベンチマークでの評価など、モデルの技術レポートで確認できます。
- 平均プーリング:プーリング前にトークンレベルの埋め込みを提供する自己ホスト型モデルや API の場合、デフォルトのプーリング方法が平均プーリングであるかを確認してください。CLS や最大プーリングを使用するモデルは後期チャンク分割と互換性がありません。
まとめると、埋め込みモデルが長文脈をサポートし、デフォルトで平均プーリングを使用している場合、後期チャンク分割を容易にサポートできます。GitHub リポジトリで実装の詳細と更なる議論をご確認ください。
tag結論
では、後期チャンク分割とは何でしょうか?後期チャンク分割は、長文脈埋め込みモデルを使用してチャンク埋め込みを生成する簡単な方法です。高速で、境界手がかりに対して強靭で、非常に効果的です。これはヒューリスティックや過剰なエンジニアリングではなく、Transformer のメカニズムに対する深い理解に基づいた思慮深い設計です。
今日、LLM を取り巻くハイプ(誇大宣伝)は否定できません。多くの場合、BERT のような小規模なモデルで効率的に対処できる問題が、より大規模で複雑なソリューションの魅力に導かれて LLM に委ねられています。大手 LLM プロバイダーがモデルの採用を推進し、埋め込みプロバイダーが埋め込みを提唱するのは、双方が自社の商業的強みを活かそうとしているため、当然のことです。しかし最終的には、ハイプではなく、実際に機能するものが重要です。コミュニティ、業界、そして最も重要な時間が、どのアプローチが本当にリーンで効率的で持続可能なのかを明らかにするでしょう。
私たちの研究論文を必ずお読みください。また、様々なシナリオで後期チャンク分割のベンチマークを実施し、フィードバックを共有していただければ幸いです。
