





International Conference on Machine Learning は、機械学習および人工知能コミュニティにおける最も権威のある会議の一つで、今年は7月21日から27日までウィーンで2024年の会議が開催されました。

会議は7日間の集中的な学習経験で、口頭発表や他の研究者と直接意見交換する機会がありました。強化学習、ライフサイエンスのための AI、表現学習、マルチモーダルモデル、そしてもちろん AI モデル開発の中核要素において、多くの興味深い研究が行われています。特に重要だったのは、Physics of Large Language Models に関するチュートリアルで、LLM の内部動作を詳しく探り、LLM が情報を記憶しているのか、それとも発言時に推論を適用しているのかという疑問に説得力のある答えを提供しました。
tagJina-CLIP-v1 に関する私たちの研究
私たちは、ワークショップ「Multi-modal Foundation Models meet Embodied AI」の一環として、新しいマルチモーダルモデル jina-clip-v1 の研究についてポスター発表を行いました。
様々な分野で働く国際的な同僚たちと会い、議論することは非常に刺激的でした。私たちの発表は多くの好意的なフィードバックを得て、Jina CLIP がマルチモーダルとユニモーダルの対照学習パラダイムを統合する方法に多くの人々が興味を示しました。議論は CLIP アーキテクチャの限界から、追加のモダリティへの拡張、さらにはペプチドやタンパク質のマッチングへの応用まで及びました。
Michael Günther が Jina CLIP を発表
tag私たちのお気に入り
他の研究者のプロジェクトや発表について多くの議論を行う機会があり、以下がその中でのお気に入りです:
tagPlan Like a Graph (PLaG)
多くの人が「Few-Shot Prompting」や「Chain of Thought prompting」を知っています。Fangru Lin は ICML で新しい、より良い手法を発表しました:Plan Like a Graph (PLaG)。
彼女のアイデアはシンプルです:LLM に与えられたタスクを、LLM が並列または順次的に解決できるサブタスクに分解します。これらのサブタスクが実行グラフを形成します。グラフ全体を実行することで、高レベルのタスクが解決されます。
上の動画で、Fangru Lin は分かりやすい例を使ってその手法を説明しています。この改善は結果を向上させますが、タスクの複雑さが増すと LLM の性能は依然として大幅に低下することに注意してください。とはいえ、これは正しい方向への大きな一歩であり、即座に実用的なメリットをもたらします。
私たちにとって、彼女の研究が Jina AI でのプロンプトアプリケーションと類似していることは興味深いです。私たちはすでにグラフのようなプロンプト構造を実装していますが、彼女が行ったような実行グラフを動的に生成することは、これから探求する新しい方向性です。
tagXRM による環境の発見
この論文は、ラベルと相関する特徴に依存しながらも、正確な分類・関連性を導かない特徴にモデルが依存してしまう訓練環境を発見するためのシンプルなアルゴリズムを提案しています。有名な例として、waterbirds データセット(arXiv:1911.08731 参照)があります。これは、水鳥か陸鳥かに分類される、さまざまな背景の鳥の写真を含んでいます。トレーニング中、分類器は鳥自体の特徴ではなく、画像の背景に水があるかどうかを検出してしまいます。このようなモデルは、背景に水がない場合に水鳥を誤分類してしまいます。
この振る舞いを緩和するには、モデルが誤解を招く背景の特徴に依存しているサンプルを検出する必要があります。この論文は、それを行うための XRM アルゴリズムを提案しています。
このアルゴリズムは、トレーニングデータセットの異なる2つの部分で2つのモデルを訓練します。トレーニング中、一部のサンプルのラベルが反転します。具体的には、他のモデル(それぞれのサンプルでトレーニングされていないモデル)が異なる分類をした場合に発生します。この方法で、モデルは見かけの相関に依存することを促されます。その後、モデルの1つによって予測されたラベルが正解と異なるトレーニングデータからサンプルを抽出できます。これらの情報は後で、例えば Group DRO アルゴリズム を使用して、よりロバストな分類モデルを訓練するために使用できます。
tagLLM の評価コストを 140 分の 1 に削減!
はい、その通りです。このトリックで、LLM の評価コストを極めて小さな割合にまで削減できます。
コアとなるアイデアはシンプルです:同じモデル機能をテストする評価サンプルをすべて削除するのです。背後にある数学はそれほど単純ではありませんが、ポスターセッションで発表した Felipe Maia Polo が分かりやすく説明しています。140 分の 1 への削減は、人気のある MMLU データセット(Massive Multitask Language Understanding)に適用された場合の結果であることに注意してください。あなた独自の評価データセットでは、サンプルの評価結果がどの程度相関しているかによって異なります。多くのサンプルをスキップできる場合もあれば、ほんの少しだけの場合もあります。
とにかく試してみてください。Jina AI で評価サンプルをどの程度削減できたか、追ってお知らせします。
tagMulti-Marginal Matching Gap による複数表現の対比
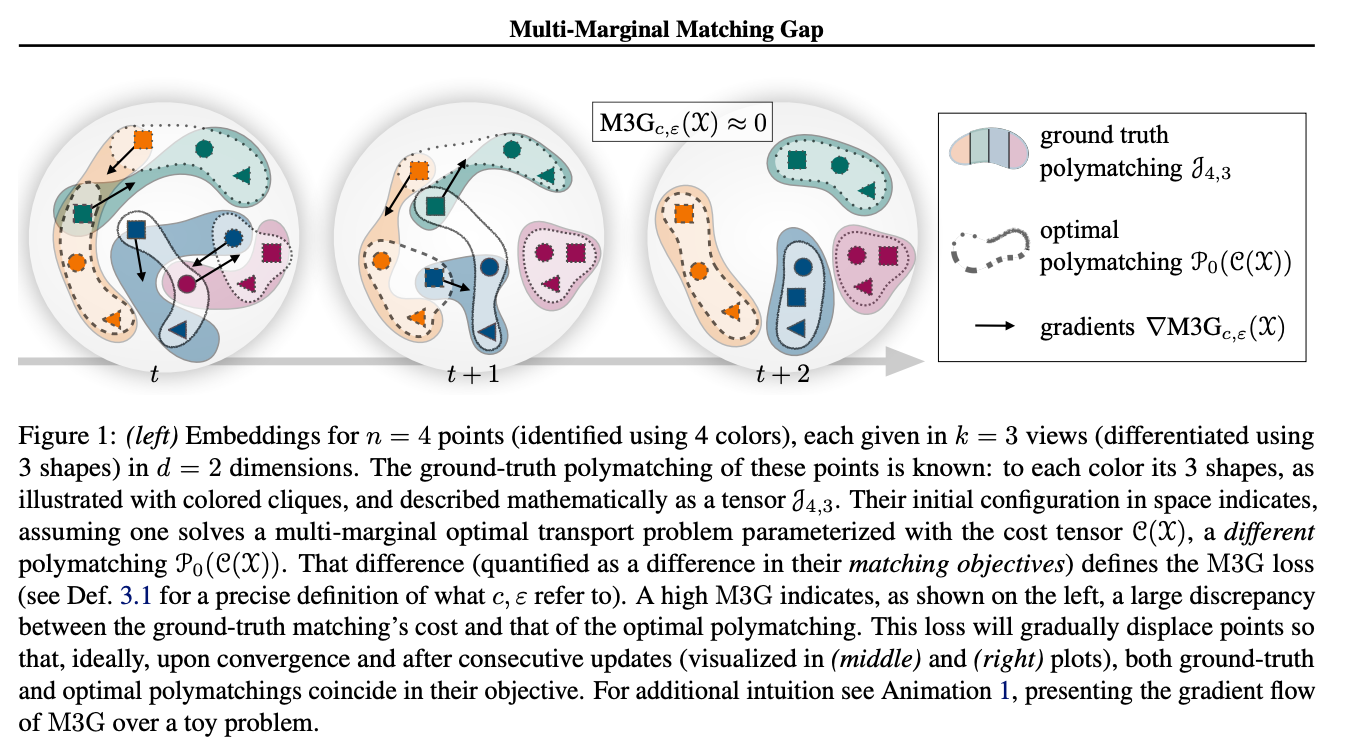
この研究は対照学習における一般的な課題に取り組んでいます:InfoNCE 損失のような多くの対照損失関数は、データポイントのペアで動作し、正のペア間の距離を測定します。サイズ k > 2 の正のタプルに拡張するために、対照学習は通常、問題を複数のペアに縮小し、すべての正のペアについてペアごとの損失を累積しようとします。著者らは、Multi-Marginal Optimal Transport 問題を解決する Sinkhorn アルゴリズムの修正版である M3G(Multi-Marginal Matching Gap)損失を提案しています。この損失関数は、サイズ k > 2 の正のタプルからなるデータセット(例えば、同じオブジェクトの >2 枚の画像、3つ以上のモダリティを持つマルチモーダル問題、あるいは同じ画像の3つ以上の拡張を持つ SimCLR 拡張)のシナリオで使用できます。実験結果は、この手法がペアへの単純な縮小よりも優れていることを示しています。
tagGround Truth は必要なし!
Zachary Robertson(Stanford University)が、ラベル付きデータなしで LLM を評価する研究を発表しました。これは理論的な研究ですが、高度な AI システムのスケーラブルな監視に大きな可能性を持っています。カジュアルな LLM ユーザーのためのものではありませんが、LLM の評価に取り組んでいる場合は、必ず検討すべきものです。私たちは、Jina AI のエージェントをこの方法で評価できることをすでに認識しています。最初の実験結果が出たら共有する予定です。
tagモデル崩壊は避けられないのか?実データと合成データの蓄積による再帰の呪いの打破
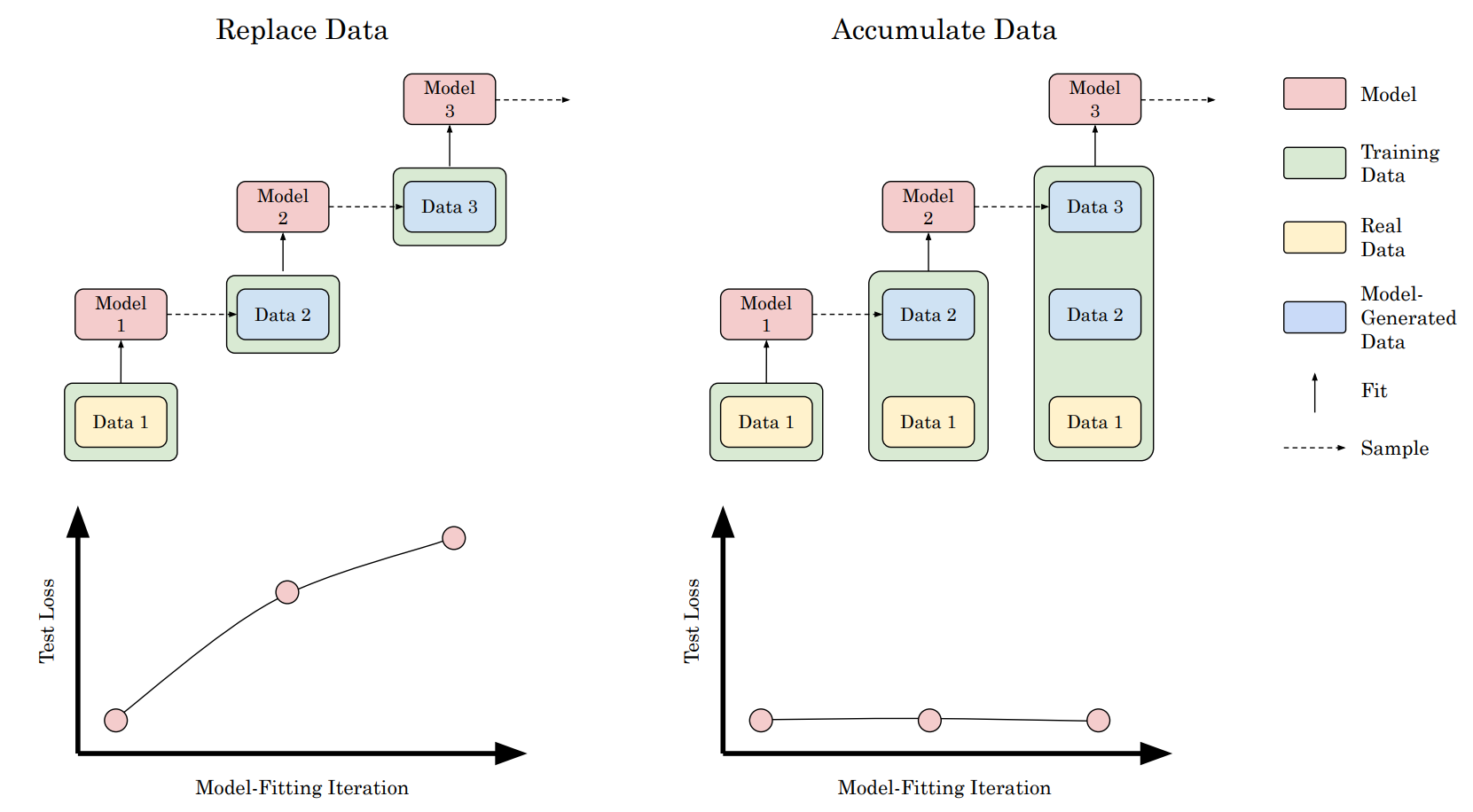
最近、複数の記事(このNatureの論文など)が、Web からクロールされたトレーニングデータに合成データが増加しているため、新しく訓練されたモデルのパフォーマンスが時間とともに悪化する可能性があると予測しています。
我々の同僚の Scott Martens もモデル崩壊に関する記事を公開し、合成データがモデルトレーニングに有用なケースについて議論しています。

モデルのトレーニングは、トレーニングデータが同じデータで訓練された以前のバージョンのモデルまたはモデルによって生成された場合に崩壊する可能性があります。この論文では、実験を通じて少し異なる見方を示しています:崩壊が起こるのは、以前の実験で行われたように実データを合成データで置き換える場合のみです。しかし、実データに合成データを追加する場合、結果として得られるモデルのパフォーマンスに測定可能な変化はありません。これらの結果は、モデル崩壊は起こらないことを示唆しています。ただし、追加の合成データを使用しても、その合成データポイントを作成するために使用されたモデルよりも一般的に優れたモデルを訓練することはできないことが再度証明されました。
tagAI の脳外科手術が可能に
誰かの職業を予測したいが、性別は予測したくない場合を考えてみましょう。Google Research、ETH Zürich、International Institute of Information Technology Hyderabad (IIITH)、Bar-Ilan University によるこの研究は、ステアリングベクトルと共分散マッチングを使用してバイアスを制御する方法を示しています。
tagMagicLens - オープンエンド指示による自己教師あり画像検索

この論文は、クエリ画像 + 指示 + ターゲット画像の三つ組みで訓練された自己教師あり画像検索モデルである MagicLens モデルを紹介しています。
著者らは、Web から画像ペアを収集し、LLM を使用して単なる視覚的類似性を超えた多様な意味的関係で画像をリンクするオープンエンドなテキスト指示を合成するデータ収集/キュレーションパイプラインを導入しています。このパイプラインは、広範な分布にわたって 36.7M の高品質な三つ組みを生成するために使用されます。このデータセットは、共有パラメータを持つシンプルなデュアルエンコーダアーキテクチャを訓練するために使用されます。バックボーンのビジョンおよび言語エンコーダは、CoCa または CLIP base および large バリアントで初期化されます。2 つのマルチモーダル入力を単一の埋め込みに圧縮するために、単一のマルチヘッド注意プーラーが導入されます。トレーニング目的は、単純な InfoNCE 損失を用いて MagicLens を訓練するために、クエリ画像と指示のペアをターゲット画像と空の文字列指示と対比させます。著者らは指示ベースの画像検索に関する評価結果を提示しています。
tagPrompt Sketching - プロンプトの新しい方法
LLM へのプロンプトの方法が変化しています。Prompt Sketching は、生成モデルに固定の制約を与えることを可能にします。単に指示を提供してモデルが望む通りに動作することを期待するのではなく、完全なテンプレートを定義し、モデルに望む内容を生成させることができます。
これを構造化された JSON 形式を提供するように微調整された LLM と混同しないでください。微調整アプローチでは、モデルは依然として望むものを自由に生成できます。Prompt Sketching ではそうではありません。これはプロンプトエンジニアに完全に新しいツールボックスを提供し、探求が必要な研究分野を開拓します。上記の動画で、Mark Müller がこの新しいパラダイムについて詳しく説明しています。
彼らのオープンソースプロジェクト LMQL もチェックできます。
tagRepoformer - リポジトリレベルのコード補完のための選択的検索
多くのクエリにおいて、クエリが簡単すぎるか、検索システムが関連文書を見つけられない(おそらく存在しないため)場合、RAG は実際にはモデルの助けになりません。これは、モデルが誤解を招くまたは存在しないソースに依存する場合、生成時間が長くなりパフォーマンスが低下することにつながります。
この論文は、LLM が検索が有用かどうかを自己評価できるようにすることでこの問題に対処しています。コードテンプレートのギャップを埋めるように訓練されたコード補完モデルでこのアプローチを実証しています。与えられたテンプレートに対して、システムはまず検索結果が有用かどうかを判断し、有用な場合は検索を呼び出します。最後に、コード LLM は検索結果がそのプロンプトに追加されているかどうかにかかわらず、欠けているコンテキストを生成します。
tagプラトン的表現仮説

プラトン的表現仮説は、ニューラルネットワークモデルが世界の共通の表現に収束する傾向があると主張しています。プラトンのイデア論から、私たちが間接的にしか観察できない歪んだ形で現れる「理想」の領域が存在するという考えを借用し、著者らは AI モデルが、トレーニングアーキテクチャ、トレーニングデータ、さらには入力モダリティに関係なく、単一の現実表現に収束するように見えると主張しています。データスケールとモデルサイズが大きくなるほど、それらの表現はより類似してくるように見えます。
著者たちはベクトル表現を考察し、カーネルアラインメント指標を用いて表現の整列を測定しています。具体的には、2つのカーネル K1 と K2 によって誘導される k-近傍集合の平均交差を k で正規化した相互最近傍指標を使用しています。本研究では、モデルとデータセットのサイズが大きくなり性能が向上するにつれて、カーネル間の整列がより強くなることを実証的に示しています。この整列は、テキストモデルと画像モデルのような異なるモダリティのモデルを比較する場合でも観察することができます。
tagまとめ
スケーリング則に対する当初の熱狂は少し落ち着きを見せ始めていますが、ICML 2024 では、多くの新しい、多様で創造的な人材が私たちの分野に参入していることが示され、進歩がまだまだ続くことを確信できます。
ICML 2024 は素晴らしい経験となり、2025年にはまた戻ってくることを約束します 🇨🇦。
