



대형 언어 모델(LLMs) 및 검색 증강 생성(RAG)의 등장으로 기업들이 데이터를 활용할 수 있는 많은 기회가 열렸지만, 서로 다른 소스를 하나의 커뮤니케이션 인터페이스로 연결하는 문제도 제기되었습니다. HR 기술 혁신 기업 Springworks는 Jina AI와의 깊은 협력을 통해 이 문제를 해결하고자 했습니다.
이 사례 연구에서는 Springworks의 직장 생산성 도구인 Albus가 Jina Embeddings와 Reranker를 사용하여 다양한 앱의 데이터와 대화하는 방법을 살펴봅니다.




tag모든 앱을 하나의 도구로 연결하기
오늘날의 디지털화로 인해 직장 협업 도구가 폭발적으로 증가하면서 정보가 여러 개의 고립된 플랫폼에 분산되어 있는 환경이 만들어졌습니다. 직원들은 과거 브레인스토밍 세션의 결과나 지난주 스프린트 계획 회의록과 같이 어딘가에서 읽었던 정보를 기억하지만 다시 찾을 수 없어 끝없이 검색해야 하는 경우가 많습니다. 이러한 정보의 분산은 생산성을 저하시키고 좌절감을 가중시키는 장벽을 만듭니다. 생성형 AI는 다중 소스 데이터에 접근할 수 있는 질의응답 시스템을 만들어 직원들이 단일 소스에서 답변을 얻을 수 있도록 함으로써 이 문제를 해결하겠다고 약속합니다. 이를 위해서는 모든 정보 사일로에 접근하고 통합할 수 있는 AI 애플리케이션이 필요합니다.
tagSpringworks Albus의 해결책
Albus는 CRM, 티켓팅 시스템, 인사 관리 시스템 및 지식 관리 도구를 포함한 100개 이상의 일반적인 업무용 애플리케이션과 통합됩니다. Jina AI의 최첨단 Embedding 및 Reranker 모델을 LLM과 함께 활용하여 답변을 생성함으로써, Albus는 연결된 모든 소스를 분석하고 가장 관련성 있고 최신 정보를 사용하여 직원들의 질문에 답변합니다. 직원들은 더 이상 여러 앱에서 검색하거나 특정 파일 이름과 위치를 기억할 필요가 없습니다.
"우리는 자체 제작한 사내 벤치마크에서 거의 모든 최신 embeddings와 reranker 모델을 평가했으며, Jina의 모델들이 진정으로 돋보였습니다. 그들의 기술은 기대를 충족시킬 뿐만 아니라 그 이상을 제공합니다."
— Kartik Mandaville, Springworks의 창립자 겸 CEO
tagSpringworks 솔루션의 핵심
Springworks는 Jina AI와 협력하여 Albus의 고급 RAG 시스템을 개발하고 반복적으로 개선하고 있습니다. Albus는 구조화된 데이터와 비구조화된 데이터를 모두 검색합니다. AI 분류기는 사용자의 요청이 관계형 데이터베이스 쿼리로 해결되어야 하는지 또는 jina-colbert-v1-en을 사용하여 벡터 데이터베이스의 비구조화된 데이터를 쿼리해야 하는지 결정합니다. 소스에 관계없이 검색된 결과는 jina-reranker-v1-base-en을 사용하여 재순위화되어 모든 사용자 질문에 답변할 수 있는 가장 관련성 있는 정보를 찾습니다.
"Jina AI의 고객 성공 팀은 이러한 모델들의 최적화에 매우 중요한 역할을 했습니다. 신속한 응답과 철저한 설명을 통해 구현 과정을 단순화하고 결과를 크게 개선했습니다."
— Kartik Mandaville, Springworks의 창립자 겸 CEO
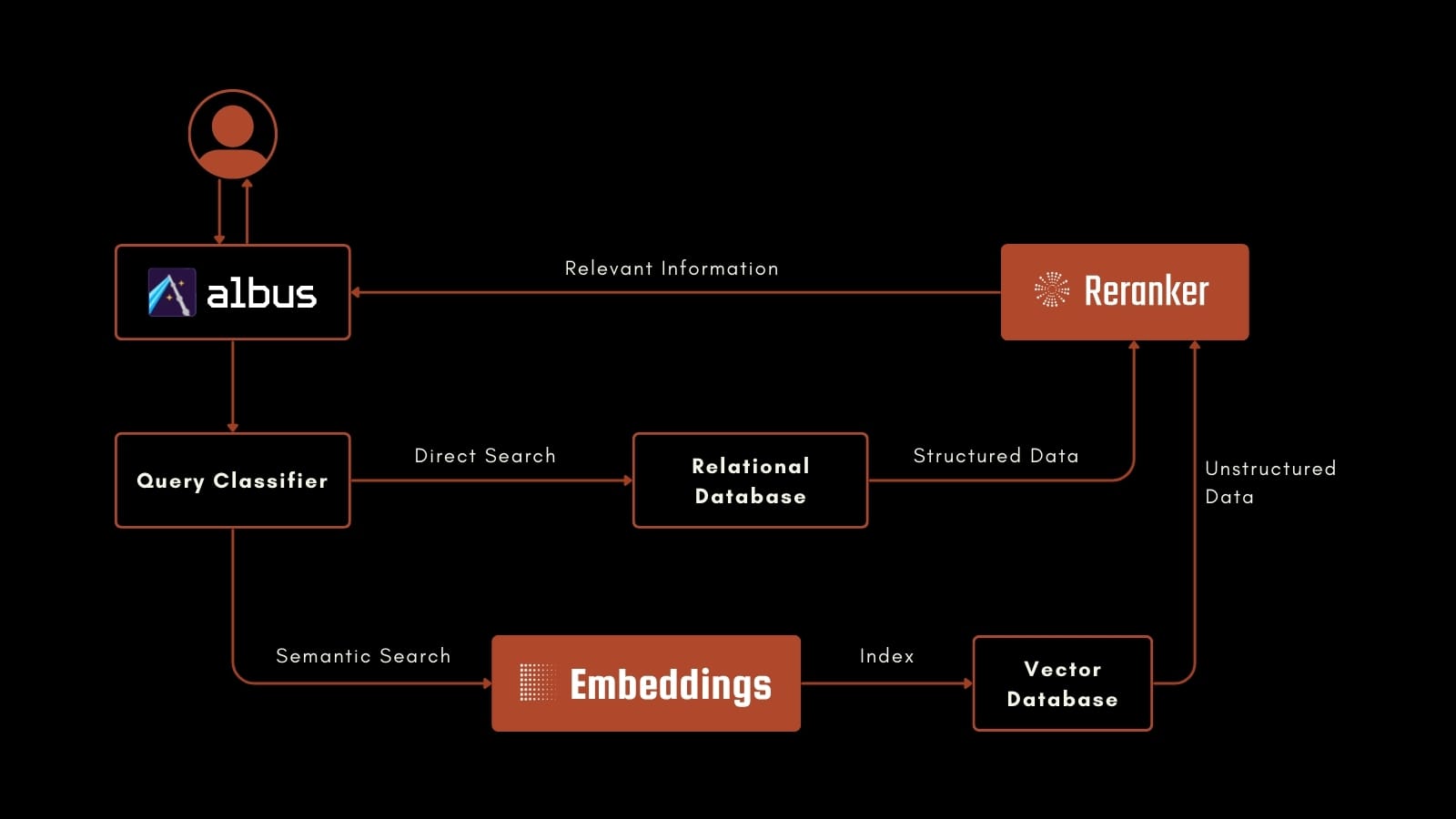
예를 들어, 사용자가 Albus를 사용하여 Jira 티켓 데이터베이스를 쿼리하고자 하며 다음과 같이 질문한다고 가정해 보겠습니다:
Which tickets were created since March about updating the Dockerfile
to use the latest Ubuntu version?Query Classifier는 이 쿼리가 구조화된 검색에 가장 적합하다고 판단하고 ("since March"는 전통적인 필터 쿼리를 의미함), Jira Query Language로 동등한 쿼리를 생성합니다(Jira에서 사용되는 SQL 변형):
project = "BACKEND_API"
AND created >= "2023-03-01"
AND text ~ "dockerfile"
AND text ~ "Ubuntu"이는 일련의 티켓을 반환하고, 그들의 텍스트 내용은 원래의 자연어 쿼리와 함께 jina-reranker-v1-base-en으로 전송됩니다. Jina Reranker가 이들을 재정렬하고, 상위 순위 티켓의 텍스트는 템플릿과 함께 LLM용 프롬프트로 컴파일됩니다. 이를 통해 사용자에게 전달되는 자연어 텍스트 응답이 생성됩니다.
이제 구조화된 검색에 적합하지 않은 요청을 상상해 보겠습니다:
How does the company's ESOP policy differ between senior management
and associate-level employees?Query Classifier는 이것이 embeddings 기반 벡터 검색에 더 적합하다고 인식하고 jina-colbert-v1-base-en을 사용하여 임베딩을 생성하며, 이는 벡터 데이터베이스가 티켓과 매칭합니다. 이 결과들은 구조화된 검색 사례와 마찬가지로 원래 쿼리와 함께 jina-reranker-v1-base-en에 전달되어 동일한 절차를 통해 자연어 응답을 생성합니다.
tag즉각적인 배포와 원클릭 통합
Albus는 가능한 한 사용자 친화적이 되도록 설계되었습니다. 한 번의 클릭으로 업무용 앱을 통합할 수 있습니다:
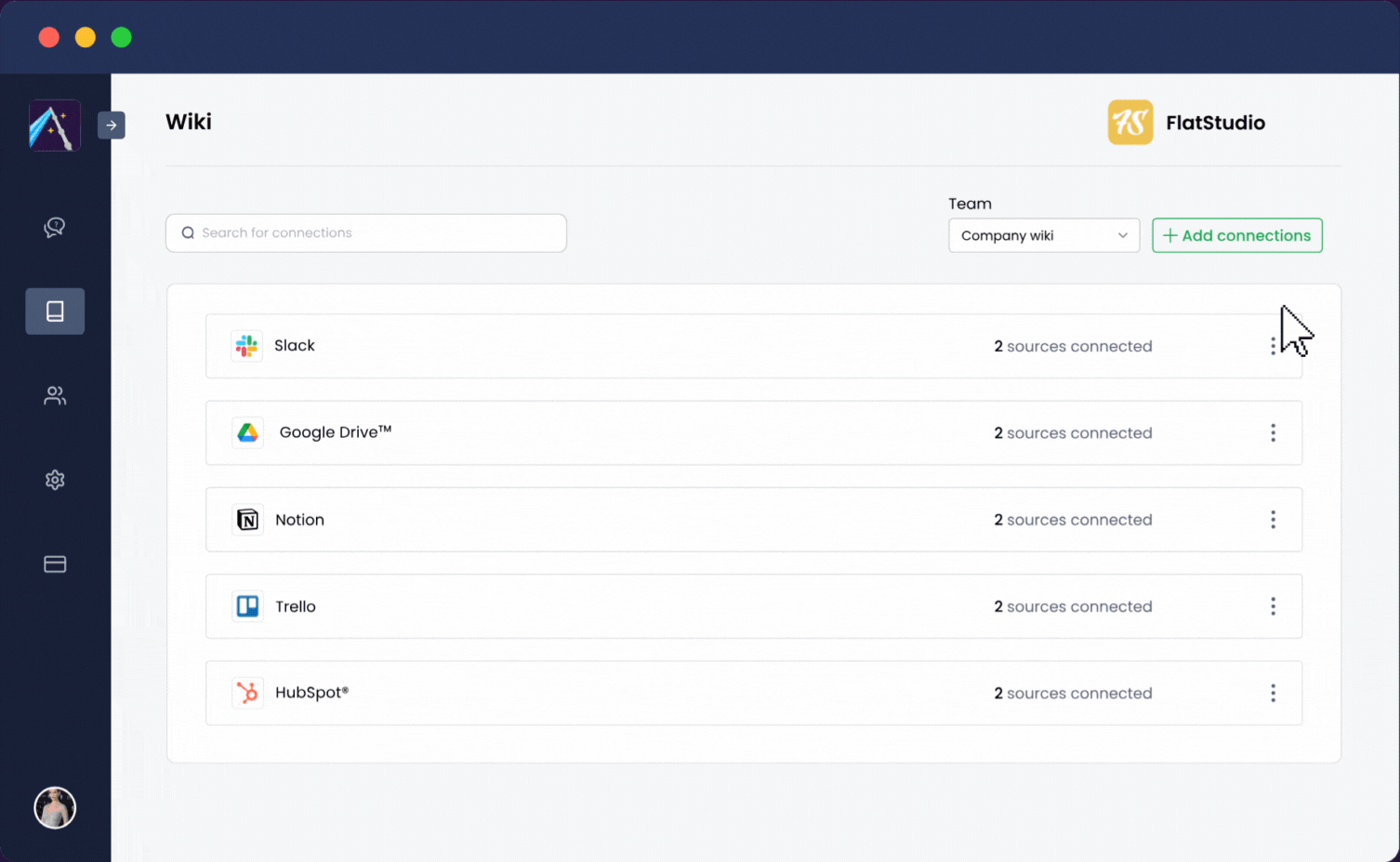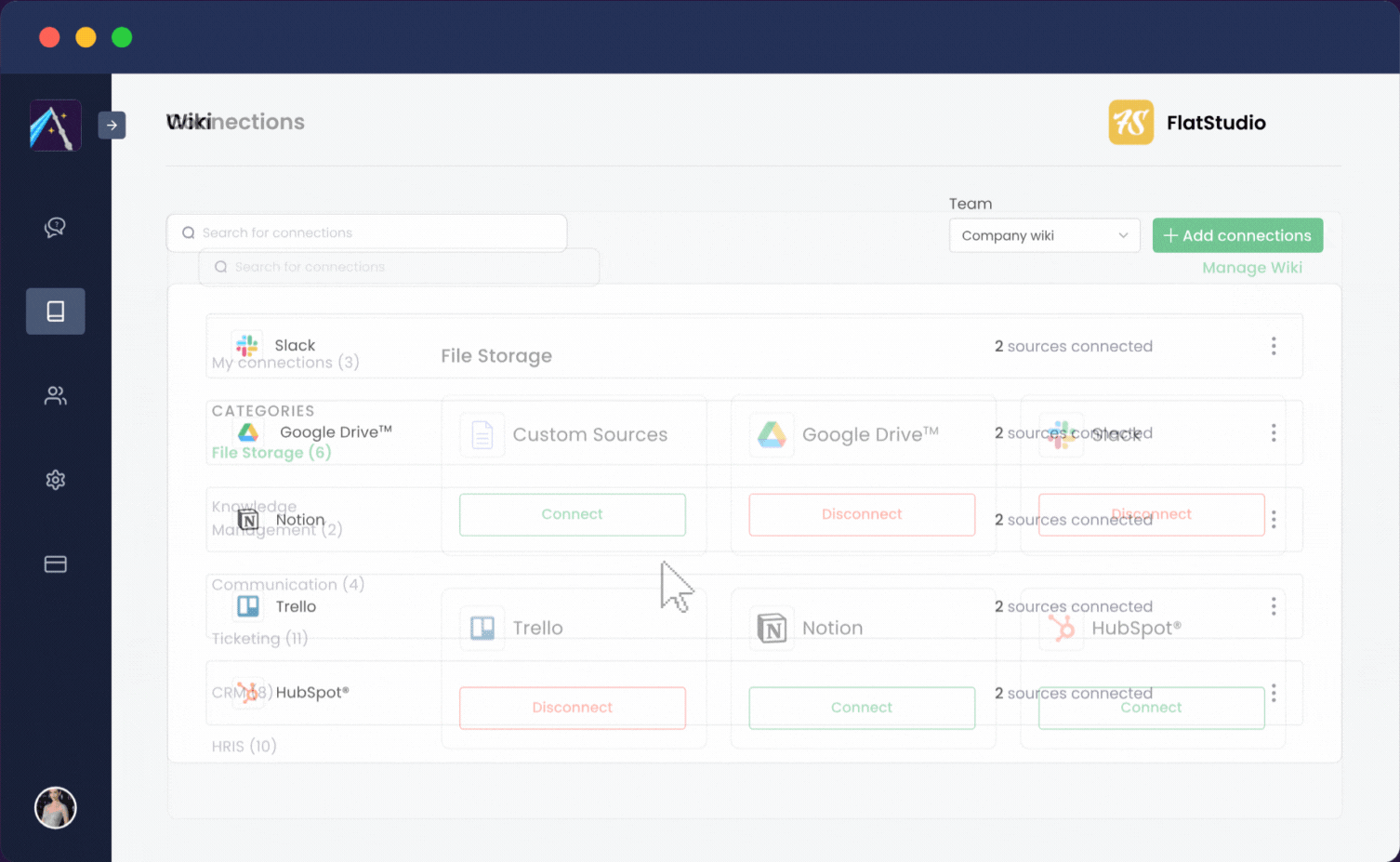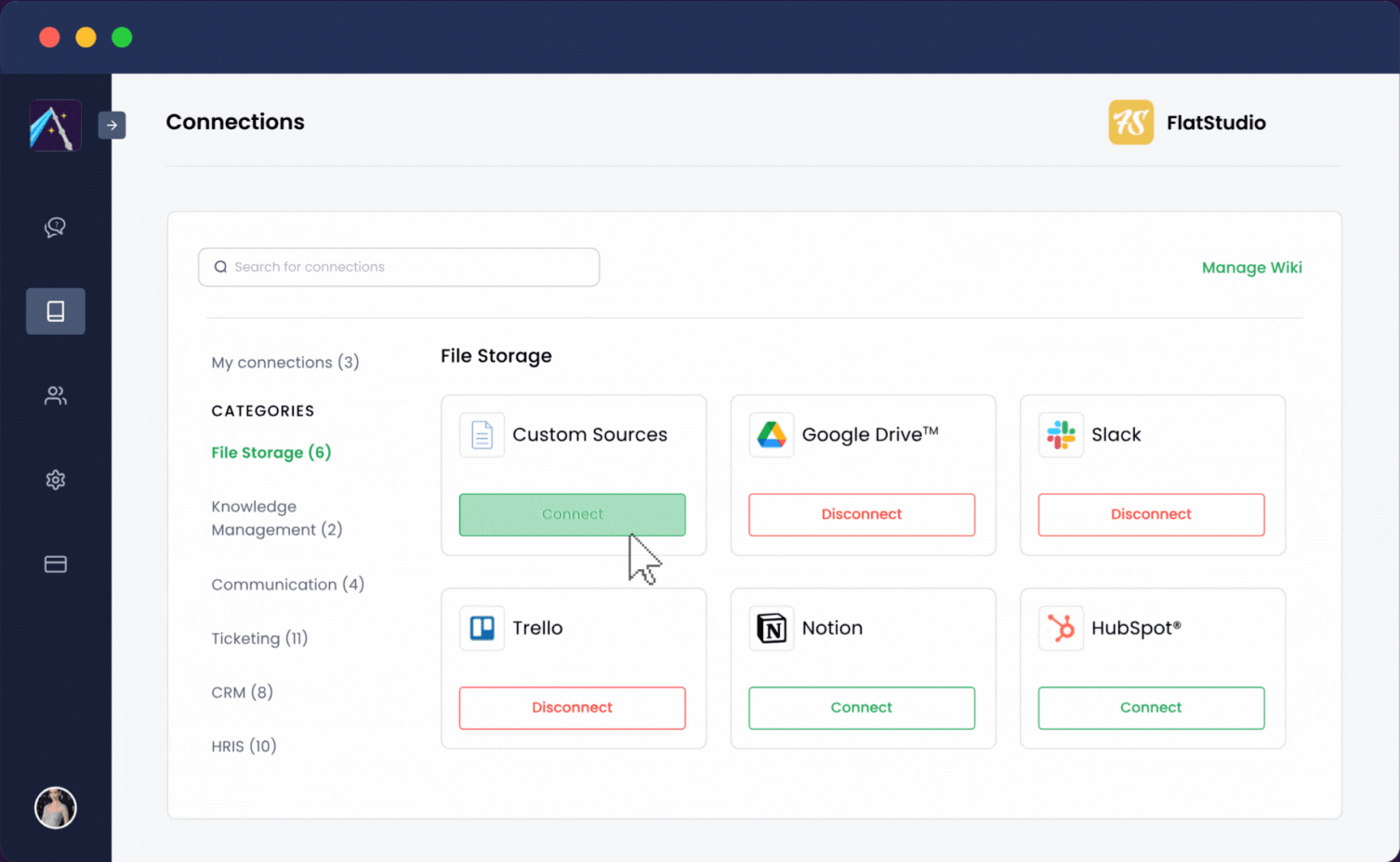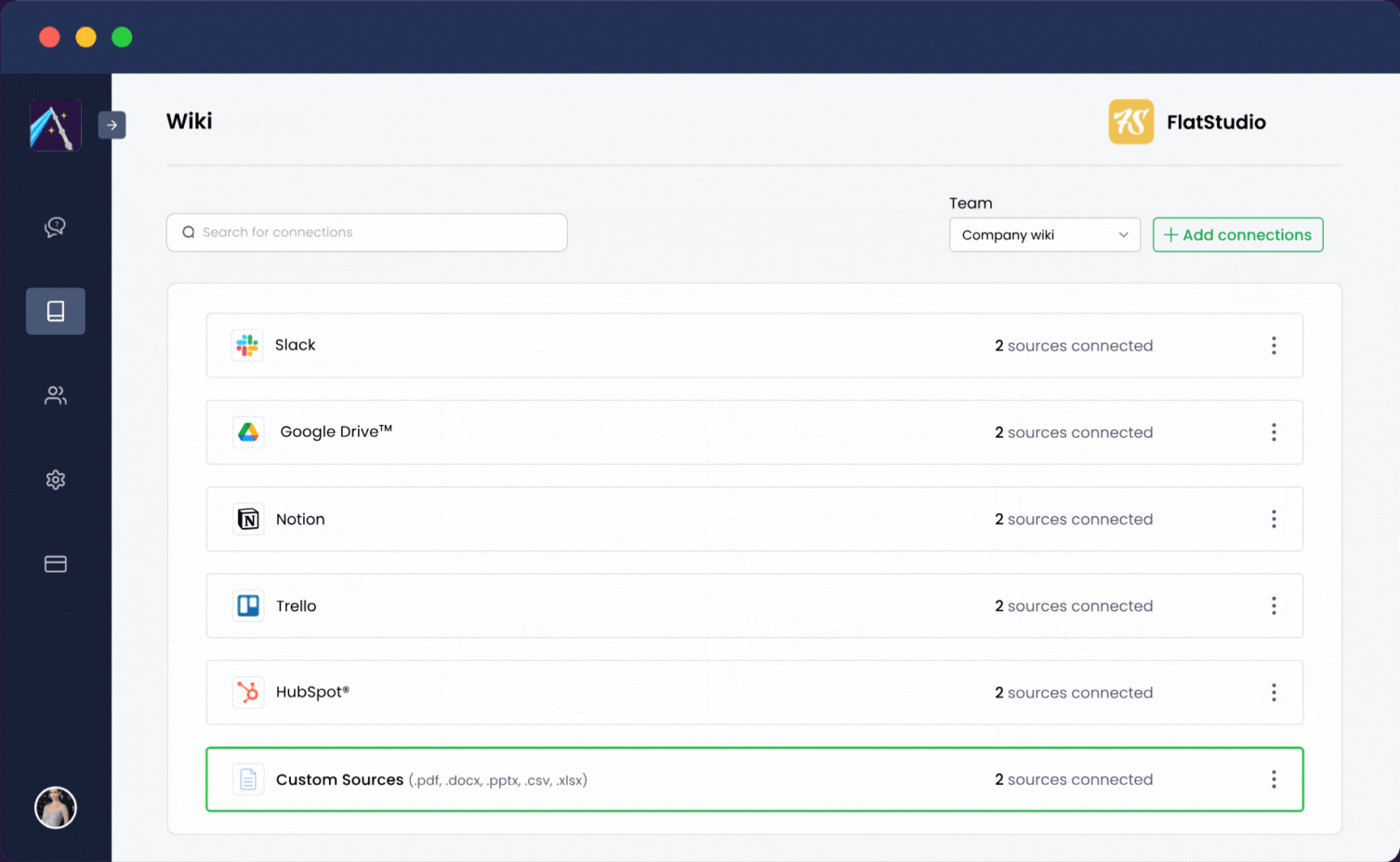
Albus는 몇 분 내에 가동되어 귀사의 전체 직장을 단일 채팅 환경으로 변환하여 팀원들이 질문만으로도 모든 정보를 찾을 수 있게 합니다.
tag지식 공유의 새로운 지평
Springworks는 기업이 데이터에 접근하는 새로운 방법을 만들었으며 신뢰할 수 있는 사무용 도구가 될 것입니다. 중앙 집중식 AI 기반 정보 검색 솔루션을 제공함으로써 Albus는 직원들이 필요한 정보를 찾는 데 소요되는 시간과 노력을 줄입니다. Jina AI와 기존 시스템과의 통합 능력, 그리고 정확하고 맥락을 이해하는 답변을 제공하는 능력 덕분에 Albus는 기업 지식을 그 어느 때보다 접근하기 쉽게 만듭니다.
Jina AI는 최고 품질의 모델을 경쟁력 있는 가격으로 기업에 제공하기 위해 최선을 다하고 있습니다. 당사의 구현 전문성과 엔터프라이즈 서비스의 혜택을 받고 싶으시다면 저희 웹사이트를 통해 문의해 주시기 바랍니다. Discord 채널을 통해 직접 소통하며 피드백을 공유하고 최신 모델 소식을 받아보세요. 저희는 매일 제품을 개선하고 있으며, 여러분의 의견은 저희 개발 과정에 매우 중요합니다.
