



텍스트와 이미지를 매끄럽게 결합한 멀티모달 검색은 OpenAI의 CLIP 같은 모델 덕분에 큰 발전을 이루었습니다. 이러한 모델들은 시각적 데이터와 텍스트 데이터 간의 간극을 효과적으로 연결하여 이미지와 관련 텍스트를 서로 연결할 수 있게 합니다.
CLIP과 유사한 모델들은 강력하지만, 특히 긴 텍스트를 처리하거나 복잡한 텍스트 관계를 다룰 때 주목할 만한 한계가 있습니다. 이러한 문제를 해결하기 위해 jina-clip-v1이 등장했습니다.
이러한 과제들을 해결하기 위해 설계된 jina-clip-v1은 강력한 텍스트-이미지 매칭 기능을 유지하면서 텍스트 이해력을 향상시켰습니다. 두 모달리티를 모두 사용하는 애플리케이션에 더 간소화된 솔루션을 제공하여, 검색 프로세스를 단순화하고 텍스트와 이미지를 위한 별도의 모델을 사용할 필요성을 없앴습니다.
이 글에서는 jina-clip-v1이 멀티모달 검색 애플리케이션에 가져오는 장점을 살펴보고, 통합된 텍스트와 이미지 임베딩을 통해 결과의 정확성과 다양성을 향상시키는 방법을 실험을 통해 보여드리겠습니다.
tagCLIP이란 무엇인가?
CLIP (Contrastive Language–Image Pretraining)은 OpenAI가 개발한 AI 모델 아키텍처로, 공동 표현을 학습하여 텍스트와 이미지를 연결합니다. CLIP은 본질적으로 텍스트 모델과 이미지 모델이 결합된 형태로, 두 종류의 입력을 공유 임베딩 공간으로 변환하여 유사한 텍스트와 이미지가 가깝게 위치하도록 합니다. CLIP은 방대한 이미지-텍스트 쌍 데이터셋으로 학습되어 시각적 콘텐츠와 텍스트 콘텐츠 간의 관계를 이해할 수 있게 되었습니다. 이를 통해 캡션 생성이나 이미지 검색과 같은 제로샷 학습 시나리오에서 높은 효과를 보여줍니다.
CLIP이 출시된 이후, SigLiP, LiT, EvaCLIP과 같은 다른 모델들이 CLIP의 기반을 확장하여 학습 효율성, 확장성, 멀티모달 이해력과 같은 측면을 개선했습니다. 이러한 모델들은 더 큰 데이터셋, 개선된 아키텍처, 더 정교한 학습 기술을 활용하여 이미지-언어 모델 분야를 더욱 발전시켰습니다.
CLIP은 텍스트만으로도 작동할 수 있지만, 상당한 한계가 있습니다. 첫째, 짧은 텍스트 캡션으로만 학습되어 최대 77단어 정도의 텍스트만 처리할 수 있습니다. 둘째, CLIP은 텍스트를 이미지와 연결하는 데는 탁월하지만 a crimson fruit와 a red apple가 같은 것을 지칭할 수 있다는 것과 같은 텍스트 간의 비교에는 어려움을 겪습니다. 이러한 부분에서는 jina-embeddings-v3와 같은 특화된 텍스트 모델이 더 뛰어납니다.
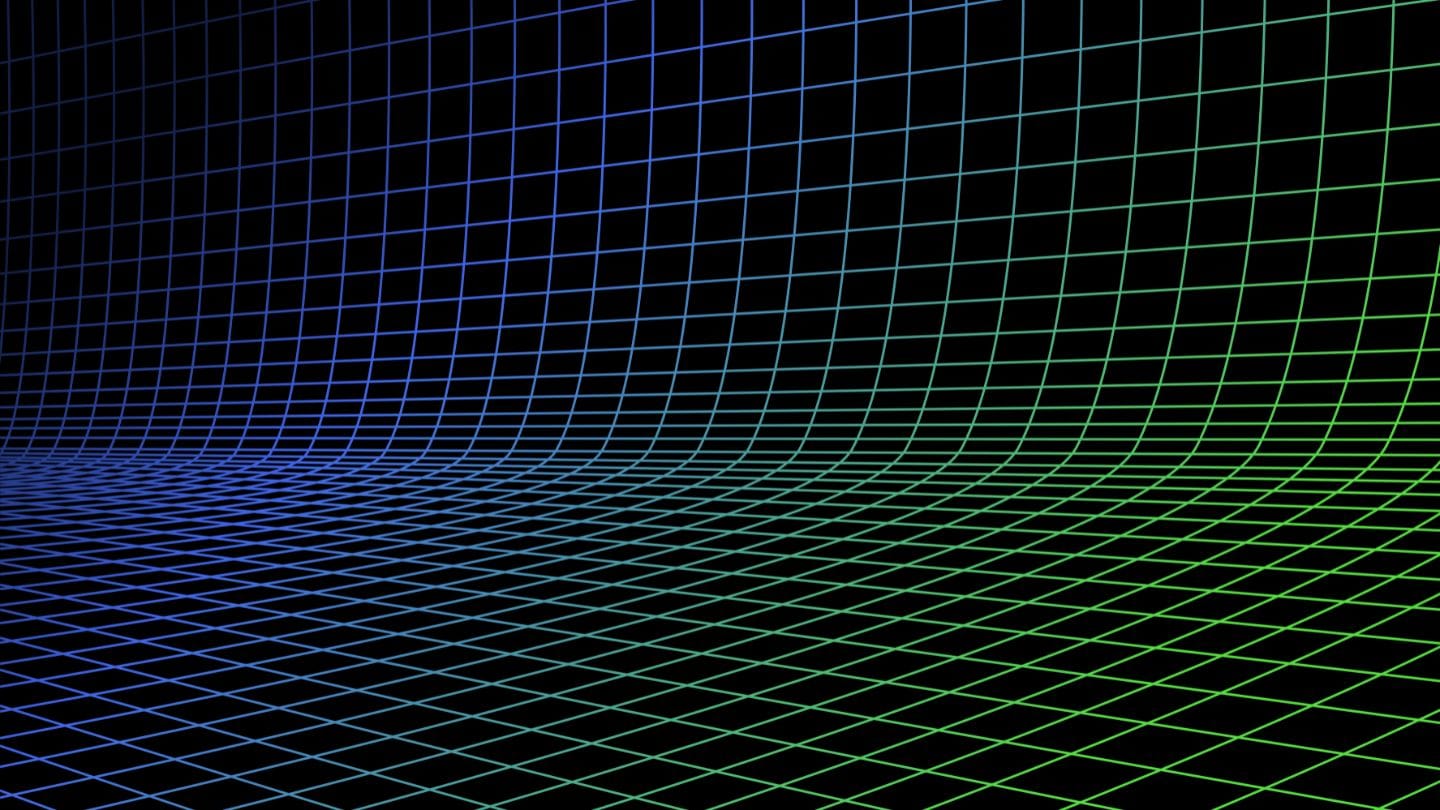
이러한 한계는 텍스트와 이미지를 모두 다루는 검색 작업을 복잡하게 만듭니다. 예를 들어, 사용자가 텍스트 문자열이나 이미지로 패션 제품을 검색할 수 있는 "룩 쇼핑" 온라인 스토어에서는 각 제품을 여러 번 처리해야 합니다 - 이미지용으로 한 번, 텍스트용으로 한 번, 그리고 텍스트 특화 모델용으로 한 번 더. 마찬가지로 사용자가 제품을 검색할 때도 텍스트와 이미지 대상을 모두 찾기 위해 최소 두 번의 검색이 필요합니다:
tagjina-clip-v1이 CLIP의 한계를 해결하는 방법
CLIP의 한계를 극복하기 위해, 우리는 jina-clip-v1을 만들어 더 긴 텍스트를 이해하고 텍스트 쿼리를 텍스트와 이미지 모두에 더 효과적으로 매칭할 수 있게 했습니다. jina-clip-v1이 특별한 이유는 무엇일까요? 첫째, 더 스마트한 텍스트 이해 모델(JinaBERT)을 사용하여 짧은 캡션(제품명)뿐만 아니라 더 길고 복잡한 텍스트(제품 설명)도 이해할 수 있습니다. 둘째, jina-clip-v1은 텍스트와 이미지의 매칭, 그리고 텍스트와 다른 텍스트의 매칭 두 가지 모두를 잘 수행하도록 학습되었습니다.
OpenAI CLIP의 경우 그렇지 않습니다: 인덱싱과 쿼리 모두에서 두 개의 모델(이미지와 짧은 텍스트용 CLIP, 긴 텍스트용 다른 텍스트 임베딩)이 필요합니다. 이는 오버헤드를 추가할 뿐만 아니라 매우 빨라야 할 검색 작업을 느리게 만듭니다. jina-clip-v1은 속도의 희생 없이 이 모든 것을 하나의 모델로 처리합니다:

이러한 통합된 접근 방식은 이전 모델들로는 어려웠던 새로운 가능성을 열어주어 검색에 대한 우리의 접근 방식을 재형성할 수 있습니다. 이 글에서는 두 가지 실험을 진행했습니다:
- 텍스트와 이미지 검색을 결합하여 검색 결과 개선: jina-clip-v1이 텍스트와 이미지에서 이해한 내용을 결합할 수 있을까요? 이 두 가지 이해를 혼합하면 어떤 일이 발생할까요? 시각적 정보를 추가하면 검색 결과가 바뀔까요? 간단히 말해, 텍스트와 이미지를 동시에 사용하여 검색하면 더 나은 결과를 얻을 수 있을까요?
- 이미지를 사용한 검색 결과 다양화: 대부분의 검색 엔진은 텍스트 매칭을 최대화합니다. 하지만 jina-clip-v1의 이미지 이해를 "시각적 셔플"로 사용할 수 있을까요? 가장 관련성 높은 결과만 보여주는 대신, 시각적으로 다양한 결과를 포함할 수 있습니다. 이는 더 많은 관련 결과를 찾는 것이 아니라 덜 관련되어 있더라도 더 넓은 범위의 관점을 보여주는 것입니다. 이를 통해 이전에 고려하지 못했던 주제의 측면을 발견할 수 있습니다. 예를 들어, 패션 검색에서 사용자가 "멀티컬러 칵테일 드레스"를 검색할 때, 상위 목록이 모두 같아 보이는 것(즉, 매우 유사한 매칭)을 원할까요, 아니면 선택할 수 있는 더 넓은 다양성(시각적 셔플을 통해)을 원할까요?
두 접근 방식 모두 전자상거래, 미디어, 예술과 디자인, 의료 이미징 등 사용자가 텍스트나 이미지로 검색할 수 있는 다양한 사용 사례에서 가치가 있습니다.
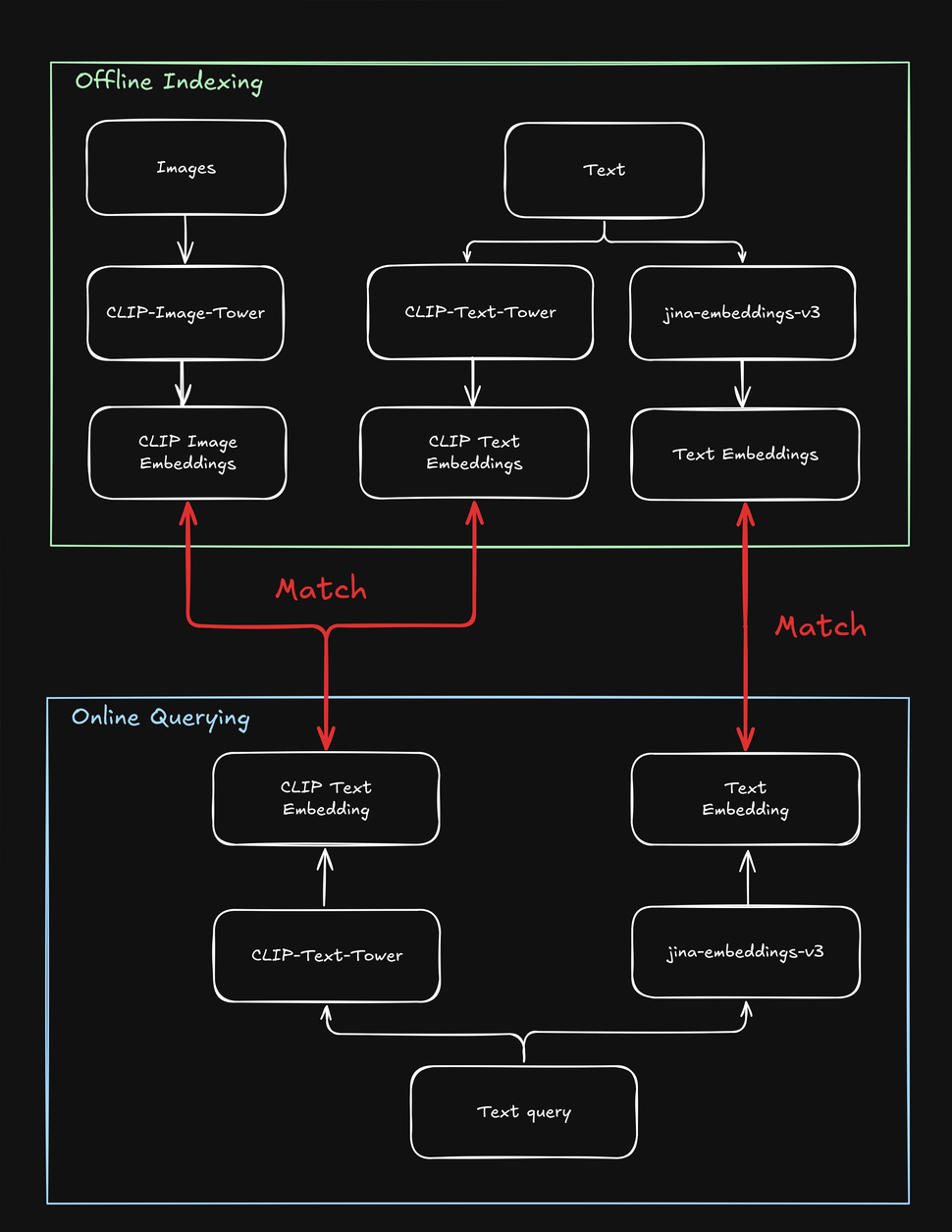
tag평균 이상의 성능을 위한 텍스트와 이미지 임베딩 평균화
사용자가 쿼리를 제출할 때(주로 텍스트 문자열로), jina-clip-v1 텍스트 타워를 사용하여 쿼리를 텍스트 임베딩으로 인코딩할 수 있습니다. jina-clip-v1의 강점은 같은 의미 공간에서 텍스트-텍스트와 텍스트-이미지 신호를 정렬함으로써 텍스트와 이미지를 모두 이해하는 능력에 있습니다.
각 제품의 사전 인덱싱된 텍스트와 이미지 임베딩을 평균화하여 결합하면 검색 결과를 개선할 수 있을까요?
이는 텍스트 정보(예: 제품 설명)와 시각적 정보(예: 제품 이미지)를 모두 포함하는 단일 표현을 생성합니다. 그런 다음 텍스트 쿼리 임베딩을 사용하여 이러한 혼합된 표현을 검색할 수 있습니다. 이것이 검색 결과에 어떤 영향을 미칠까요?
이를 알아보기 위해, 우리는 Fashion200k 데이터셋을 사용했습니다. 이는 패션 이미지 검색과 크로스 모달 이해와 관련된 작업을 위해 특별히 만들어진 대규모 데이터셋입니다. 여기에는 의류, 신발, 액세서리와 같은 20만 개 이상의 패션 아이템 이미지와 해당하는 제품 설명 및 메타데이터가 포함되어 있습니다.
 xthan
xthan각 항목을 광범위한 카테고리(예: dress)와 세부 카테고리(예: knit midi dress)로 분류했습니다.
tag세 가지 검색 방법 분석
텍스트와 이미지 임베딩의 평균이 더 나은 검색 결과를 도출하는지 알아보기 위해, 텍스트 문자열(예: red dress)을 쿼리로 사용하는 세 가지 유형의 검색을 실험했습니다:
- 텍스트 임베딩을 사용한 쿼리-설명 검색: 텍스트 임베딩을 기반으로 제품 설명을 검색합니다.
- 크로스 모달 검색을 사용한 쿼리-이미지 검색: 이미지 임베딩을 기반으로 제품 이미지를 검색합니다.
- 평균 임베딩을 사용한 쿼리: 제품 설명과 제품 이미지의 평균 임베딩을 검색합니다.
먼저 전체 데이터셋을 인덱싱한 후, 성능 평가를 위해 1,000개의 쿼리를 무작위로 생성했습니다. 각 쿼리를 텍스트 임베딩으로 인코딩하고, 위에서 설명한 방법들을 기반으로 각각 매칭했습니다. 반환된 제품의 카테고리가 입력 쿼리와 얼마나 일치하는지를 측정하여 정확도를 평가했습니다.
multicolor henley t-shirt dress 쿼리를 사용했을 때, 쿼리-설명 검색이 상위 5개 정밀도에서 가장 높은 성능을 보였지만, 상위 랭크된 마지막 세 개의 드레스는 시각적으로 동일했습니다. 효과적인 검색은 사용자의 관심을 더 잘 끌기 위해 관련성과 다양성의 균형을 맞춰야 하므로 이는 이상적이지 않습니다.
쿼리-이미지 크로스 모달 검색은 동일한 쿼리를 사용했지만 반대 접근 방식을 취해 매우 다양한 드레스 컬렉션을 보여주었습니다. 5개 중 2개의 결과가 올바른 광범위 카테고리와 일치했지만, 세부 카테고리와는 일치하는 것이 없었습니다.
텍스트와 이미지 임베딩 평균 검색이 가장 좋은 결과를 보여주었습니다: 5개 결과 모두 광범위 카테고리와 일치했고, 5개 중 2개는 세부 카테고리와도 일치했습니다. 또한 시각적으로 중복된 항목들이 제거되어 더 다양한 선택을 제공했습니다. 평균화된 텍스트와 이미지 임베딩을 검색하기 위해 텍스트 임베딩을 사용하는 것은 검색 품질을 유지하면서 시각적 요소를 통합하여 더 다양하고 균형 잡힌 결과를 도출하는 것으로 보입니다.
tag확장: 더 많은 쿼리로 평가하기
이것이 더 큰 규모에서도 작동하는지 확인하기 위해, 추가적인 광범위 및 세부 카테고리에 대해 실험을 계속 진행했습니다. 매번 다른 수의 결과("k-값")를 검색하면서 여러 번의 반복 실험을 수행했습니다.
광범위 및 세부 카테고리 모두에서, 쿼리-평균 임베딩이 모든 k-값(10, 20, 50, 100)에서 일관되게 가장 높은 정밀도를 달성했습니다. 이는 텍스트와 이미지 임베딩을 결합하는 것이 카테고리가 광범위하든 구체적이든 관련 항목을 검색하는 데 가장 정확한 결과를 제공한다는 것을 보여줍니다:
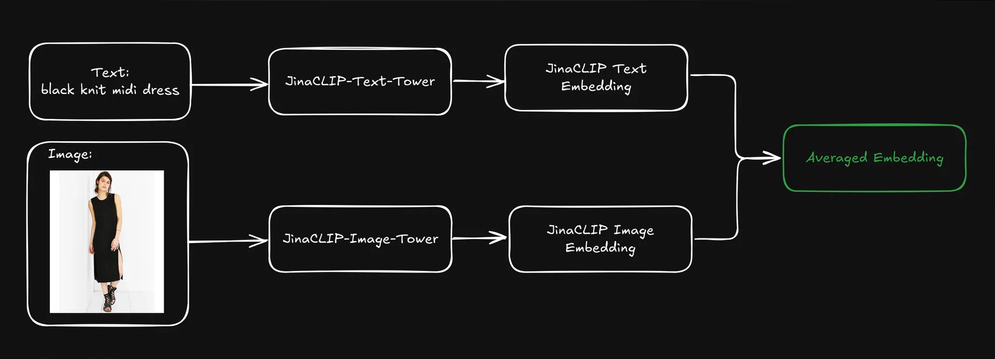
[나머지 번역 계속...]black jacket - 이들이 블랙 바이커 재킷, 봄버 재킷, 블레이저, 또는 다른 종류의 재킷을 의미하는지?).이제 jina-clip-v1의 크로스 모달 기능을 활용하는 대신, 텍스트 타워의 텍스트 임베딩을 초기 텍스트 검색에 사용한 다음, 이미지 타워의 이미지 임베딩을 "시각적 재순위화" 도구로 활용하여 검색 결과를 다양화해 보겠습니다. 이는 아래 다이어그램에서 설명됩니다:
- 먼저 텍스트 임베딩을 기반으로 상위 k개의 검색 결과를 가져옵니다.
- 각 상위 검색 결과에 대해 시각적 특징을 추출하고 이미지 임베딩을 사용하여 클러스터링합니다.
- 각 클러스터에서 하나의 항목을 선택하여 검색 결과를 재정렬하고 다양화된 목록을 사용자에게 제시합니다.
상위 50개의 결과를 가져온 후, 이미지 임베딩에 경량 k-means 클러스터링(k=5)을 적용하고 각 클러스터에서 항목을 선택했습니다. 쿼리-제품 카테고리를 측정 지표로 사용했기 때문에 카테고리 정확도는 Query-to-Description 성능과 일관성을 유지했습니다. 하지만 이미지 기반 다양화를 통해 순위가 매겨진 결과가 더 많은 다양한 측면(원단, 재단, 패턴 등)을 포함하기 시작했습니다. 참고로, 이전의 멀티컬러 헨리 티셔츠 드레스 예시입니다:

이제 텍스트 임베딩 검색과 이미지 임베딩을 다양화 재순위화 도구로 결합하여 다양화가 검색 결과에 어떤 영향을 미치는지 살펴보겠습니다:

순위가 매겨진 결과는 텍스트 기반 검색에서 시작되지만 상위 5개 예시에서 더 다양한 "측면"을 다루기 시작합니다. 이는 실제로 임베딩을 평균화하지 않고도 평균화와 유사한 효과를 얻습니다.
하지만 이는 비용이 발생합니다: 상위 k개 결과를 검색한 후 추가적인 클러스터링 단계를 적용해야 하며, 이는 초기 순위의 크기에 따라 몇 밀리초가 추가됩니다. 또한 k-means 클러스터링의 k 값을 결정하는 것은 어느 정도 휴리스틱한 추측이 필요합니다. 이것이 결과 다양화를 개선하기 위해 우리가 지불해야 하는 대가입니다!
tag결론
jina-clip-v1은 단일의 효율적인 모델에서 두 모달리티를 통합하여 텍스트와 이미지 검색 간의 격차를 효과적으로 해소합니다. 우리의 실험은 이미지와 함께 더 길고 복잡한 텍스트 입력을 처리하는 능력이 기존 CLIP과 같은 모델들보다 우수한 검색 성능을 제공한다는 것을 보여주었습니다.
우리의 테스트는 텍스트와 설명 매칭, 이미지 매칭, 평균 임베딩 등 다양한 방법을 다루었습니다. 결과는 일관되게 텍스트와 이미지 임베딩을 결합하는 것이 가장 좋은 결과를 산출하여 정확도와 검색 결과의 다양성을 모두 개선한다는 것을 보여주었습니다. 또한 이미지 임베딩을 "시각적 재순위화" 도구로 사용하면 관련성을 유지하면서 결과의 다양성을 향상시킨다는 것을 발견했습니다.
이러한 발전은 사용자가 텍스트 설명과 이미지를 모두 사용하여 검색하는 실제 응용 프로그램에 중요한 의미를 갖습니다. jina-clip-v1은 두 유형의 데이터를 동시에 이해함으로써 검색 프로세스를 간소화하고, 더 관련성 있는 결과를 제공하며, 더 다양한 제품 추천을 가능하게 합니다. 이 통합된 검색 기능은 전자상거래를 넘어 미디어 자산 관리, 디지털 도서관, 시각적 콘텐츠 큐레이션에도 도움이 되어 다양한 형식의 관련 콘텐츠를 더 쉽게 발견할 수 있게 합니다.
jina-clip-v1이 현재 영어만 지원하지만, 우리는 현재 jina-clip-v2를 개발 중입니다. jina-embeddings-v3와 jina-colbert-v2의 뒤를 이어, 이 새로운 버전은 89개 언어를 지원하는 최첨단 다국어 멀티모달 검색기가 될 것입니다. 이 업그레이드는 전자상거래, 미디어 등 전 세계 응용 프로그램을 위한 더 강력한 임베딩 모델로서, 다양한 시장과 산업 전반에 걸쳐 검색 및 검색 작업에 새로운 가능성을 열어줄 것입니다.
