
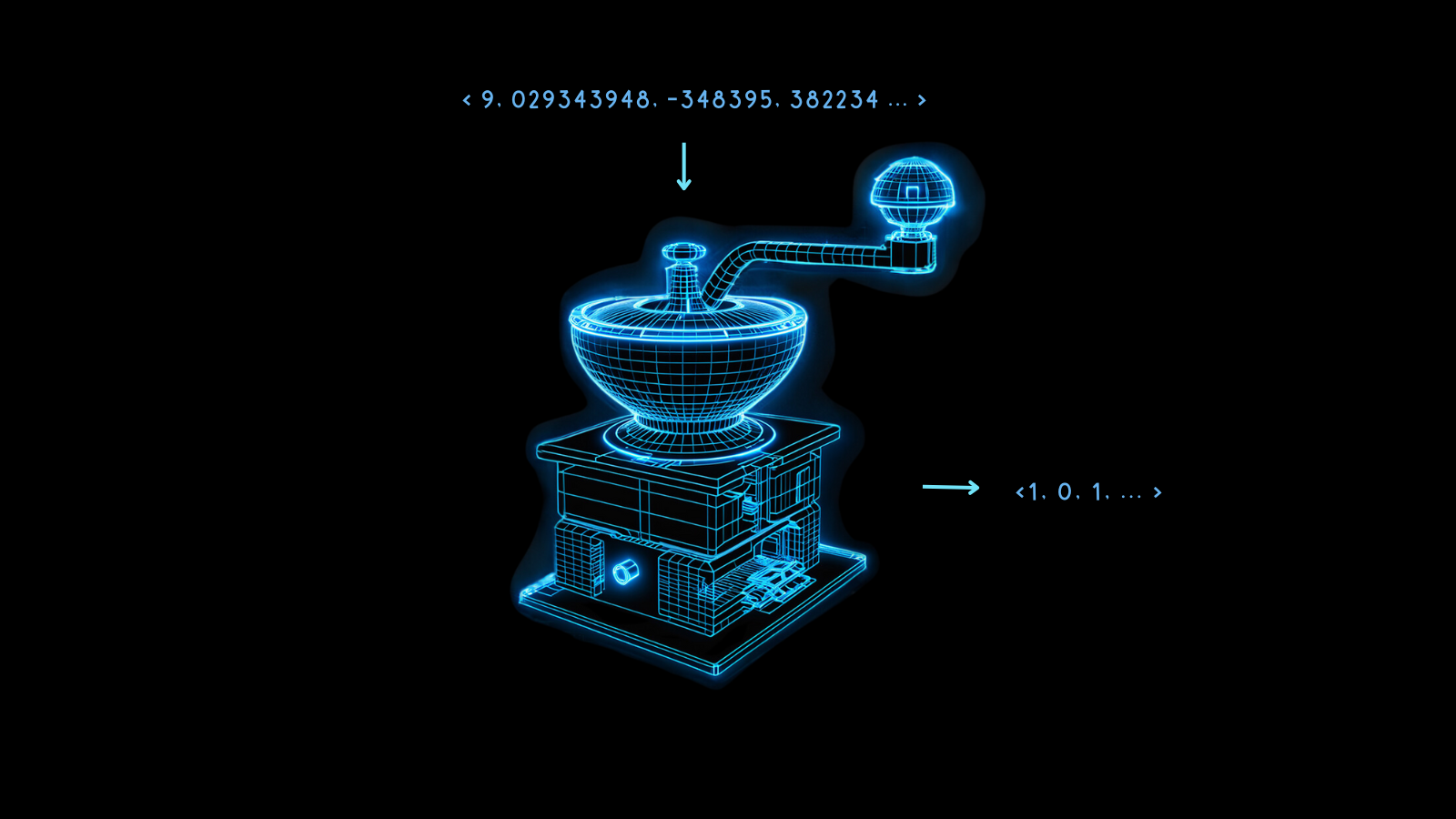


임베딩은 다양한 AI와 자연어 처리 애플리케이션의 핵심이 되었으며, 텍스트의 의미를 고차원 벡터로 표현하는 방법을 제공합니다. 하지만 모델의 크기가 커지고 AI 모델이 처리하는 데이터의 양이 증가함에 따라, 전통적인 임베딩의 계산 및 저장 요구사항이 급증했습니다. 바이너리 임베딩은 높은 성능을 유지하면서도 리소스 요구사항을 크게 줄이는 컴팩트하고 효율적인 대안으로 도입되었습니다.
바이너리 임베딩은 임베딩 벡터의 크기를 최대 96%(Jina Embeddings의 경우 96.875%)까지 줄여 이러한 리소스 요구사항을 완화하는 한 가지 방법입니다. 사용자는 정확도를 최소한으로 손실하면서 AI 애플리케이션에서 컴팩트한 바이너리 임베딩의 성능을 활용할 수 있습니다.
tag바이너리 임베딩이란 무엇인가?
바이너리 임베딩은 전통적인 고차원 부동소수점 벡터를 바이너리 벡터로 변환하는 특수한 형태의 데이터 표현입니다. 이는 임베딩을 압축할 뿐만 아니라 벡터의 무결성과 유용성을 거의 모두 유지합니다. 이 기법의 본질은 변환 후에도 데이터 포인트 간의 의미론적 관계와 거리를 유지하는 능력에 있습니다.
바이너리 임베딩의 마법은 양자화에 있습니다. 이는 고정밀 숫자를 저정밀 숫자로 변환하는 방법입니다. AI 모델링에서 이는 종종 임베딩의 32비트 부동소수점 숫자를 8비트 정수와 같은 더 적은 비트의 표현으로 변환하는 것을 의미합니다.

바이너리 임베딩은 이를 극한으로 가져가 각 값을 0 또는 1로 줄입니다. 32비트 부동소수점 숫자를 이진 숫자로 변환하면 임베딩 벡터의 크기가 32배 줄어들어 96.875%의 감소를 가져옵니다. 결과적으로 벡터 연산이 훨씬 더 빨라집니다. 일부 마이크로칩에서 사용 가능한 하드웨어 가속을 사용하면 벡터가 이진화될 때 벡터 비교 속도가 32배 이상 증가할 수 있습니다.
이 과정에서 일부 정보는 불가피하게 손실되지만, 모델이 매우 우수한 성능을 보일 때 이 손실은 최소화됩니다. 서로 다른 것들의 비양자화 임베딩이 최대한 다르다면, 이진화는 그 차이를 잘 보존할 가능성이 더 높습니다. 그렇지 않으면 임베딩을 정확하게 해석하기 어려울 수 있습니다.
Jina Embeddings 모델은 정확히 그런 방식으로 매우 강건하게 학습되어 이진화에 매우 적합합니다.
이러한 컴팩트한 임베딩은 특히 모바일과 시간에 민감한 사용과 같은 리소스 제약이 있는 환경에서 새로운 AI 애플리케이션을 가능하게 합니다.
아래 차트에서 보듯이 이러한 비용과 컴퓨팅 시간의 이점은 상대적으로 적은 성능 비용으로 얻을 수 있습니다.

jina-embeddings-v2-base-en의 경우, 이진 양자화는 검색 정확도를 47.13%에서 42.05%로 약 10% 감소시킵니다. jina-embeddings-v2-base-de의 경우, 이 손실은 44.39%에서 42.65%로 단 4%에 불과합니다.
Jina Embeddings 모델이 이진 벡터 생성에서 이렇게 우수한 성능을 보이는 이유는 더 균일한 임베딩 분포를 만들도록 학습되었기 때문입니다. 이는 두 개의 서로 다른 임베딩이 다른 모델의 임베딩보다 더 많은 차원에서 서로 더 멀리 떨어져 있을 가능성이 높다는 것을 의미합니다. 이러한 특성은 그 거리가 이진 형태에서도 더 잘 표현되도록 보장합니다.
tag바이너리 임베딩은 어떻게 작동하는가?
이것이 어떻게 작동하는지 보기 위해 세 개의 임베딩 A, B, C를 고려해 보겠습니다. 이 세 개는 모두 이진화되지 않은 완전한 부동소수점 벡터입니다. 이제 A에서 B까지의 거리가 B에서 C까지의 거리보다 크다고 가정해 봅시다. 임베딩에서는 일반적으로 코사인 거리를 사용합니다. 따라서:
A, B, C를 이진화하면 해밍 거리를 사용하여 거리를 더 효율적으로 측정할 수 있습니다.
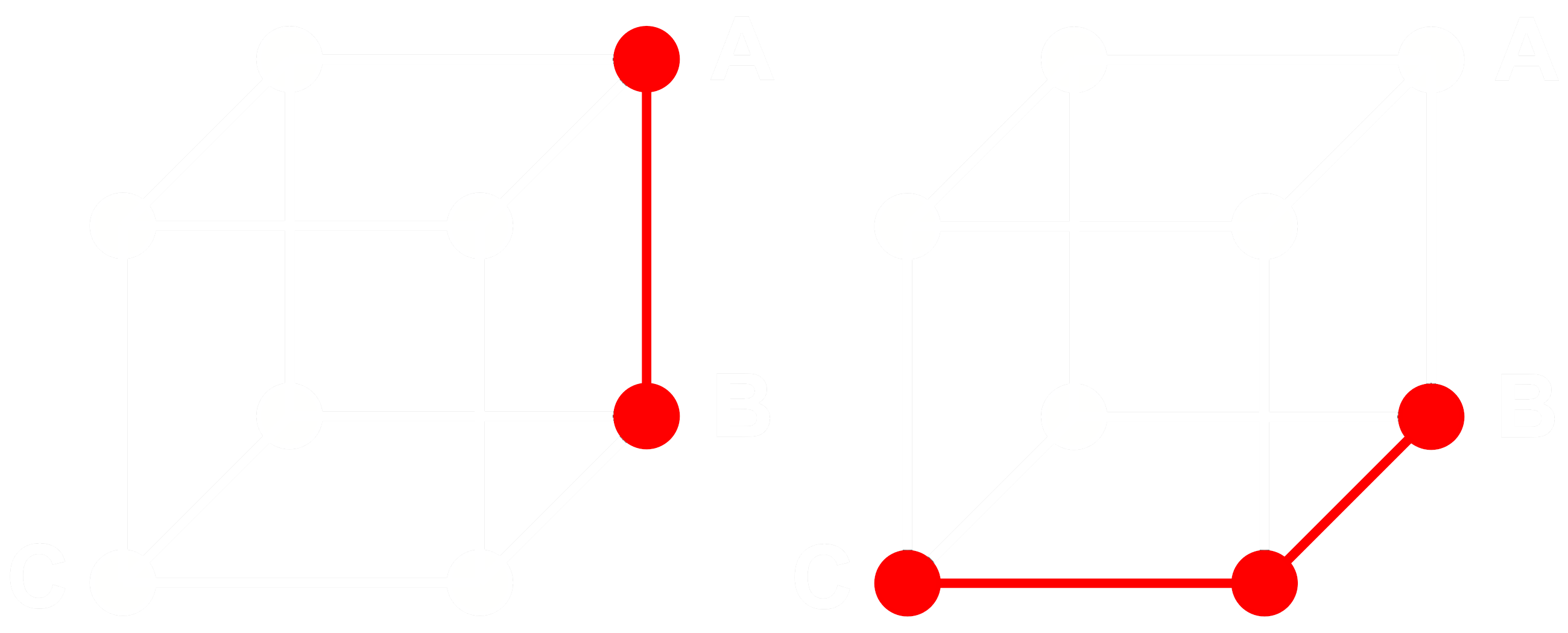
A, B, C의 이진화된 버전을 각각 Abin, Bbin, Cbin이라고 부릅시다.
이진 벡터의 경우, Abin과 Bbin 사이의 코사인 거리가 Bbin과 Cbin 사이의 거리보다 크다면, Abin과 Bbin 사이의 해밍 거리는 Bbin과 Cbin 사이의 해밍 거리보다 크거나 같습니다.
따라서:
해밍 거리의 경우:
이상적으로, 임베딩을 이진화할 때 전체 임베딩의 관계가 이진 임베딩에서도 동일하게 유지되기를 원합니다. 이는 부동소수점 코사인에서 한 거리가 다른 거리보다 크다면, 이진화된 등가물 사이의 해밍 거리에서도 더 커야 한다는 것을 의미합니다:
모든 임베딩 삼중항에 대해 이것을 참으로 만들 수는 없지만, 거의 모든 경우에 대해 참이 되도록 할 수 있습니다.
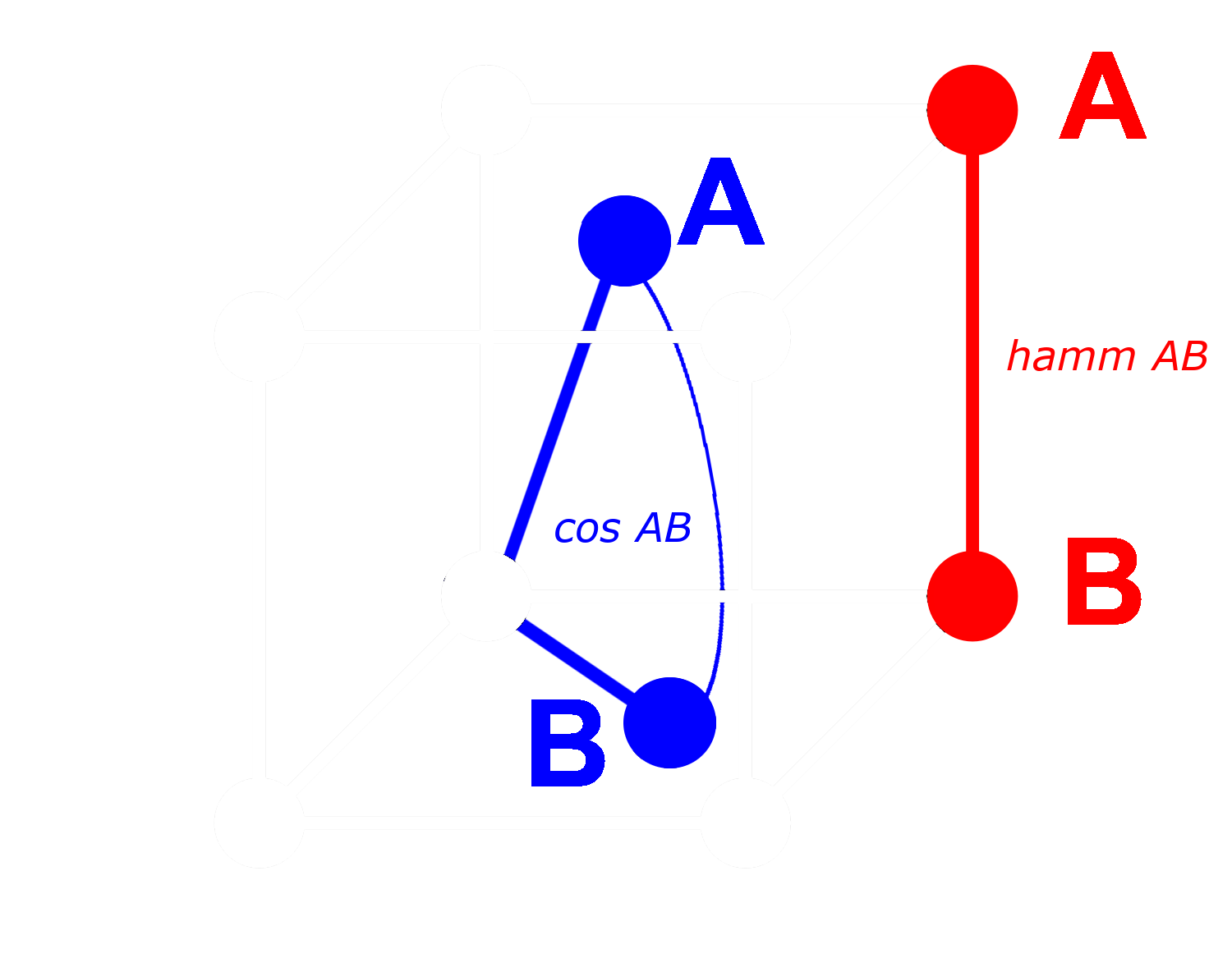
이진 벡터에서는 모든 차원을 존재(1) 또는 부재(0)로 처리할 수 있습니다. 두 벡터가 비이진 형태에서 서로 멀수록, 하나의 차원에서 하나는 양수 값을 가지고 다른 하나는 음수 값을 가질 확률이 높아집니다. 이는 이진 형태에서 하나는 0을 가지고 다른 하나는 1을 가지는 차원이 더 많을 가능성이 높다는 것을 의미합니다. 이로 인해 해밍 거리로 측정했을 때 더 멀리 떨어지게 됩니다.
반대로 더 가까운 벡터들에게는 반대가 적용됩니다: 비이진 벡터들이 가까울수록, 모든 차원에서 둘 다 0을 가지거나 둘 다 1을 가질 확률이 높아집니다. 이는 해밍 거리로 측정했을 때 더 가깝게 만듭니다.
Jina Embeddings 모델이 이진화에 매우 적합한 이유는 네거티브 마이닝과 다른 미세 조정 방법을 사용하여 특히 유사하지 않은 것들 사이의 거리를 늘리고 유사한 것들 사이의 거리를 줄이도록 학습되었기 때문입니다. 이는 임베딩을 더 강건하게 만들고, 유사성과 차이점에 더 민감하게 만들며, 이진 임베딩 간의 해밍 거리를 비이진 임베딩 간의 코사인 거리에 더 비례하게 만듭니다.
tagJina AI의 바이너리 임베딩으로 얼마나 절약할 수 있는가?
Jina AI의 바이너리 임베딩 모델을 채택하면 시간에 민감한 애플리케이션의 지연 시간을 낮출 뿐만 아니라, 아래 표에서 볼 수 있듯이 상당한 비용 이점도 얻을 수 있습니다:
| Model | Memory per 250 million embeddings |
Retrieval benchmark average |
Estimated price on AWS ($3.8 per GB/month with x2gb instances) |
|---|---|---|---|
| 32-bit floating point embeddings | 715 GB | 47.13 | $35,021 |
| Binary embeddings | 22.3 GB | 42.05 | $1,095 |
이러한 95% 이상의 절감은 검색 정확도의 ~10% 감소만을 동반합니다.
이는 OpenAI의 Ada 2 모델이나 Cohere의 Embed v3의 이진화된 벡터를 사용하는 것보다 더 큰 절감 효과입니다. 두 모델 모두 1024차원 이상의 출력 임베딩을 생성합니다. Jina AI의 임베딩은 768차원만을 가지면서도 다른 모델들과 비슷한 성능을 보이며, 동일한 정확도에서도 양자화 이전에 더 작은 크기를 가집니다.
이러한 절감은 희소 자원과 에너지 사용을 줄여 환경적으로도 도움이 됩니다.
tag시작하기
Jina Embeddings API를 사용하여 이진 임베딩을 얻으려면, API 호출에 encoding_type 파라미터를 추가하고 부호가 있는 정수로 인코딩된 이진화 임베딩을 얻으려면 binary 값을, 부호 없는 정수의 경우 ubinary 값을 사용하면 됩니다.
tagJina Embedding API 직접 접근하기
curl 사용:
curl https://api.jina.ai/v1/embeddings \
-H "Content-Type: application/json" \
-H "Authorization: Bearer <YOUR API KEY>" \
-d '{
"input": ["Your text string goes here", "You can send multiple texts"],
"model": "jina-embeddings-v2-base-en",
"encoding_type": "binary"
}'
또는 Python requests API를 통해:
import requests
headers = {
"Content-Type": "application/json",
"Authorization": "Bearer <YOUR API KEY>"
}
data = {
"input": ["Your text string goes here", "You can send multiple texts"],
"model": "jina-embeddings-v2-base-en",
"encoding_type": "binary",
}
response = requests.post(
"https://api.jina.ai/v1/embeddings",
headers=headers,
json=data,
)
위의 Python request로 response.json()을 검사하면 다음과 같은 응답을 받게 됩니다:
{
"model": "jina-embeddings-v2-base-en",
"object": "list",
"usage": {
"total_tokens": 14,
"prompt_tokens": 14
},
"data": [
{
"object": "embedding",
"index": 0,
"embedding": [
-0.14528547,
-1.0152762,
...
]
},
{
"object": "embedding",
"index": 1,
"embedding": [
-0.109809875,
-0.76077706,
...
]
}
]
}
이는 96개의 8비트 부호 있는 정수로 저장된 두 개의 이진 임베딩 벡터입니다. 이를 768개의 0과 1로 풀어내려면 numpy 라이브러리를 사용해야 합니다:
import numpy as np
# assign the first vector to embedding0
embedding0 = response.json()['data'][0]['embedding']
# convert embedding0 to a numpy array of unsigned 8-bit ints
uint8_embedding = np.array(embedding0).astype(numpy.uint8)
# unpack to binary
np.unpackbits(uint8_embedding)
결과는 0과 1로만 이루어진 768차원 벡터입니다:
array([0, 0, 1, 1, 0, 1, 1, 0, 1, 1, 0, 0, 0, 1, 0, 1, 1, 1, 1, 1, 0, 0,
0, 0, 1, 1, 1, 1, 1, 1, 0, 0, 1, 1, 0, 0, 0, 1, 1, 1, 0, 1, 0, 1,
0, 0, 0, 0, 0, 0, 1, 0, 1, 0, 0, 1, 1, 0, 0, 0, 0, 1, 0, 1, 1, 1,
0, 0, 0, 0, 1, 1, 1, 0, 0, 1, 0, 0, 0, 0, 1, 1, 1, 1, 0, 1, 0, 1,
1, 1, 0, 1, 1, 1, 1, 0, 0, 0, 1, 1, 1, 1, 1, 0, 1, 0, 1, 0, 0, 0,
0, 0, 1, 0, 0, 0, 1, 0, 1, 1, 0, 0, 1, 0, 1, 1, 1, 1, 0, 0, 1, 0,
1, 0, 0, 1, 1, 0, 0, 1, 0, 1, 1, 0, 0, 0, 0, 1, 0, 0, 1, 0, 0, 1,
1, 0, 1, 0, 1, 1, 0, 0, 0, 1, 0, 1, 1, 1, 0, 0, 1, 1, 0, 0, 0, 1,
1, 1, 0, 1, 0, 1, 1, 1, 1, 0, 1, 0, 0, 1, 0, 0, 1, 0, 1, 0, 1, 1,
0, 0, 0, 1, 1, 1, 0, 0, 0, 0, 0, 0, 1, 1, 0, 1, 0, 0, 0, 1, 1, 1,
1, 0, 0, 1, 0, 0, 0, 1, 0, 1, 0, 0, 1, 0, 1, 0, 1, 0, 0, 1, 0, 0,
0, 0, 0, 0, 1, 0, 0, 0, 1, 1, 1, 0, 1, 1, 0, 1, 1, 0, 1, 0, 0, 0,
1, 0, 0, 1, 0, 0, 1, 0, 0, 0, 1, 1, 0, 1, 1, 0, 0, 0, 1, 0, 0, 1,
0, 0, 0, 0, 0, 1, 1, 0, 0, 1, 1, 1, 1, 0, 1, 0, 1, 0, 1, 1, 1, 1,
1, 0, 1, 0, 0, 0, 1, 0, 0, 1, 0, 1, 1, 1, 0, 1, 1, 1, 1, 1, 1, 0,
0, 0, 0, 0, 1, 0, 1, 1, 1, 0, 1, 1, 1, 1, 0, 0, 0, 0, 0, 1, 1, 1,
1, 1, 1, 1, 0, 1, 0, 0, 0, 0, 0, 0, 1, 0, 0, 1, 0, 1, 0, 1, 0, 1,
1, 0, 1, 1, 1, 0, 0, 1, 0, 1, 1, 0, 1, 0, 0, 1, 1, 0, 0, 0, 1, 1,
0, 0, 0, 1, 1, 1, 1, 1, 0, 1, 1, 0, 1, 0, 0, 0, 1, 1, 0, 1, 1, 0,
1, 0, 1, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 1, 1, 1, 1, 0, 1, 1, 1, 0,
0, 0, 0, 0, 0, 1, 1, 1, 1, 0, 1, 0, 1, 1, 0, 1, 0, 1, 1, 1, 0, 0,
0, 0, 1, 1, 1, 0, 1, 0, 1, 0, 0, 1, 0, 1, 0, 0, 0, 1, 1, 1, 0, 1,
0, 1, 1, 1, 0, 1, 1, 0, 1, 0, 1, 1, 1, 1, 1, 0, 1, 0, 0, 0, 1, 0,
0, 1, 1, 1, 0, 1, 1, 0, 0, 1, 1, 0, 1, 1, 0, 1, 1, 1, 0, 1, 1, 0,
1, 1, 0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 1, 1, 1, 1, 0, 1, 1, 0,
0, 1, 0, 0, 1, 1, 0, 1, 0, 0, 1, 0, 0, 1, 0, 1, 0, 1, 1, 1, 0, 0,
0, 0, 1, 1, 0, 1, 0, 0, 1, 1, 1, 1, 1, 0, 1, 0, 1, 1, 1, 1, 0, 1,
1, 0, 1, 1, 0, 1, 1, 0, 1, 0, 0, 1, 0, 0, 0, 1, 0, 1, 0, 1, 1, 0,
1, 1, 1, 0, 0, 0, 1, 0, 0, 1, 0, 0, 0, 1, 0, 0, 1, 0, 1, 1, 0, 0,
1, 0, 1, 1, 1, 1, 1, 1, 1, 0, 1, 0, 0, 0, 1, 0, 0, 1, 1, 1, 0, 1,
1, 1, 0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 1, 1, 0, 1, 1, 0, 0, 1, 1, 0,
1, 0, 1, 0, 0, 0, 0, 0, 0, 0, 1, 1, 0, 0, 0, 1, 0, 0, 1, 1, 0, 1,
1, 1, 1, 0, 0, 1, 1, 1, 0, 1, 0, 0, 1, 1, 0, 1, 1, 1, 1, 1, 1, 0,
1, 1, 1, 0, 0, 1, 1, 0, 0, 1, 0, 0, 1, 1, 0, 0, 0, 1, 0, 1, 1, 1,
0, 0, 1, 1, 0, 0, 1, 0, 1, 1, 1, 1, 1, 0, 1, 0, 0, 1, 0, 0],
dtype=uint8)
tagQdrant에서 이진 양자화 사용하기
Qdrant의 통합 라이브러리를 사용하여 이진 임베딩을 Qdrant 벡터 저장소에 직접 저장할 수 있습니다. Qdrant는 내부적으로 BinaryQuantization을 구현했기 때문에, 전체 벡터 컬렉션에 대한 사전 설정 구성으로 사용할 수 있어 코드를 다르게 수정하지 않고도 이진 벡터를 검색하고 저장할 수 있습니다.
아래 예시 코드를 참조하세요:
import qdrant_client
import requests
from qdrant_client.models import Distance, VectorParams, Batch, BinaryQuantization, BinaryQuantizationConfig
# Jina API 키를 제공하고 사용 가능한 모델 중 하나를 선택하세요.
# 여기에서 무료 평가판 키를 받을 수 있습니다: https://jina.ai/embeddings/
JINA_API_KEY = "jina_xxx"
MODEL = "jina-embeddings-v2-base-en" # 또는 "jina-embeddings-v2-base-en"
EMBEDDING_SIZE = 768 # small 변형의 경우 512
# API에서 임베딩 가져오기
url = "https://api.jina.ai/v1/embeddings"
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {JINA_API_KEY}",
}
text_to_encode = ["Your text string goes here", "You can send multiple texts"]
data = {
"input": text_to_encode,
"model": MODEL,
}
response = requests.post(url, headers=headers, json=data)
embeddings = [d["embedding"] for d in response.json()["data"]]
# Qdrant에 임베딩 인덱싱하기
client = qdrant_client.QdrantClient(":memory:")
client.create_collection(
collection_name="MyCollection",
vectors_config=VectorParams(size=EMBEDDING_SIZE, distance=Distance.DOT, on_disk=True),
quantization_config=BinaryQuantization(binary=BinaryQuantizationConfig(always_ram=True)),
)
client.upload_collection(
collection_name="MyCollection",
ids=list(range(len(embeddings))),
vectors=embeddings,
payload=[
{"text": x} for x in text_to_encode
],
)검색을 구성하려면 oversampling과 rescore 매개변수를 사용해야 합니다:
from qdrant_client.models import SearchParams, QuantizationSearchParams
results = client.search(
collection_name="MyCollection",
query_vector=embeddings[0],
search_params=SearchParams(
quantization=QuantizationSearchParams(
ignore=False,
rescore=True,
oversampling=2.0,
)
)
)tagLlamaIndex 사용하기
LlamaIndex에서 Jina 바이너리 임베딩을 사용하려면 JinaEmbedding 객체를 인스턴스화할 때 encoding_queries 매개변수를 binary로 설정하세요:
from llama_index.embeddings.jinaai import JinaEmbedding
# https://jina.ai/embeddings/에서 무료 평가판 키를 받을 수 있습니다
JINA_API_KEY = ""
jina_embedding_model = JinaEmbedding(
api_key=jina_ai_api_key,
model="jina-embeddings-v2-base-en",
encoding_queries='binary',
encoding_documents='float'
)
jina_embedding_model.get_query_embedding('Query text here')
jina_embedding_model.get_text_embedding_batch(['X', 'Y', 'Z'])
tag바이너리 임베딩을 지원하는 다른 벡터 데이터베이스
다음 벡터 데이터베이스들이 바이너리 벡터를 기본적으로 지원합니다:
tag예시
바이너리 임베딩의 실제 사용을 보여드리기 위해 arXiv.org에서 초록들을 선택하여 jina-embeddings-v2-base-en을 사용해 32비트 부동소수점과 바이너리 벡터를 모두 생성했습니다. 그런 다음 "3D segmentation"이라는 예시 쿼리의 임베딩과 비교했습니다.
아래 표에서 볼 수 있듯이 상위 3개 답변은 동일하고 상위 5개 중 4개가 일치합니다. 바이너리 벡터를 사용하면 거의 동일한 상위 매치를 생성합니다.
| 바이너리 | 32비트 부동소수점 | |||
|---|---|---|---|---|
| 순위 | 해밍 거리 |
일치하는 텍스트 | 코사인 | 일치하는 텍스트 |
| 1 | 0.1862 | SEGMENT3D: A Web-based Application for Collaboration... |
0.2340 | SEGMENT3D: A Web-based Application for Collaboration... |
| 2 | 0.2148 | Segmentation-by-Detection: A Cascade Network for... |
0.2857 | Segmentation-by-Detection: A Cascade Network for... |
| 3 | 0.2174 | Vox2Vox: 3D-GAN for Brain Tumour Segmentation... |
0.2973 | Vox2Vox: 3D-GAN for Brain Tumour Segmentation... |
| 4 | 0.2318 | DiNTS: Differentiable Neural Network Topology Search... |
0.2983 | Anisotropic Mesh Adaptation for Image Segmentation... |
| 5 | 0.2331 | Data-Driven Segmentation of Post-mortem Iris Image... |
0.3019 | DiNTS: Differentiable Neural Network Topology... |
