



다국어 모델에서 가장 큰 도전 과제 중 하나는 "언어 간극"입니다 — 서로 다른 언어로 된 동일한 의미의 구문이 제대로 정렬되거나 군집화되지 않는 현상을 말합니다. 이상적으로는 한 언어의 텍스트와 다른 언어로 된 그 등가물이 유사한 표현 — 즉, 서로 매우 가까운 임베딩 — 을 가져야 하며, 이를 통해 교차 언어 애플리케이션이 서로 다른 언어의 텍스트를 동일하게 처리할 수 있어야 합니다. 하지만 모델들은 종종 텍스트의 언어를 미묘하게 표현하여 "언어 간극"을 만들고, 이는 교차 언어 성능을 저하시킵니다.
이 글에서는 이러한 언어 간극과 그것이 텍스트 임베딩 모델의 성능에 미치는 영향에 대해 살펴보겠습니다. 우리는 jina-xlm-roberta 모델과 최신 jina-embeddings-v3를 사용하여 동일 언어 내의 패러프레이즈와 서로 다른 언어 쌍 간의 번역에 대한 의미적 정렬을 평가하는 실험을 수행했습니다. 이러한 실험들은 서로 다른 학습 조건에서 유사하거나 동일한 의미를 가진 구문들이 얼마나 잘 군집화되는지 보여줍니다.

또한 우리는 대조 학습 중 병렬 다국어 데이터의 도입과 같이 교차 언어 의미적 정렬을 개선하기 위한 학습 기법을 실험했습니다. 이 글에서 우리의 통찰과 결과를 공유하겠습니다.
tag다국어 모델 학습이 언어 간극을 만들고 줄이다
텍스트 임베딩 모델의 학습은 일반적으로 두 가지 주요 부분으로 구성된 다단계 프로세스를 포함합니다:
- 마스크 언어 모델링 (MLM): 사전 학습은 일반적으로 일부 토큰이 무작위로 마스킹된 매우 큰 양의 텍스트를 포함합니다. 모델은 이러한 마스킹된 토큰을 예측하도록 학습됩니다. 이 과정은 모델에게 구문, 어휘 의미론, 실제 세계의 제약에서 발생할 수 있는 토큰 간의 선택 의존성을 포함하여 학습 데이터의 언어 또는 언어들의 패턴을 가르칩니다.
- 대조 학습: 사전 학습 후, 모델은 의미적으로 유사한 텍스트의 임베딩을 더 가깝게 만들고 (선택적으로) 유사하지 않은 것들을 더 멀리 밀어내기 위해 큐레이트되거나 반-큐레이트된 데이터로 추가 학습됩니다. 이 학습은 의미적 유사성이 이미 알려져 있거나 적어도 신뢰할 수 있게 추정된 텍스트의 쌍, 삼중항, 또는 그룹을 사용할 수 있습니다. 여러 하위 단계가 있을 수 있으며 이 과정에 대한 다양한 학습 전략이 있는데, 새로운 연구가 자주 발표되고 있지만 최적의 접근 방식에 대한 명확한 합의는 없습니다.
언어 간극이 어떻게 발생하고 어떻게 해소될 수 있는지 이해하기 위해서는 두 단계의 역할을 모두 살펴볼 필요가 있습니다.
tag마스크 언어 사전 학습
텍스트 임베딩 모델의 교차 언어 능력 중 일부는 사전 학습 중에 획득됩니다.
동족어와 차용어를 통해 모델은 대량의 텍스트 데이터에서 일부 교차 언어 의미 정렬을 학습할 수 있습니다. 예를 들어, 영어 단어 banana와 프랑스어 단어 banane (그리고 독일어 Banane)는 철자가 충분히 비슷하고 자주 사용되어 임베딩 모델이 "banan-"과 비슷한 단어들이 언어 간에 유사한 분포 패턴을 가진다는 것을 학습할 수 있습니다. 이를 통해 다른 언어에서 같아 보이지 않는 단어들도 유사한 의미를 가질 수 있다는 것을 어느 정도 배울 수 있고, 심지어 문법 구조가 어떻게 번역되는지도 파악할 수 있습니다.
하지만 이는 명시적인 학습 없이 일어납니다.
우리는 jina-embeddings-v3의 사전 학습된 백본인 jina-xlm-roberta 모델이 마스크 언어 사전 학습에서 교차 언어 등가성을 얼마나 잘 학습했는지 테스트했습니다. 영어 문장들과 그것들의 독일어, 네덜란드어, 중국어 간체, 일본어 번역의 2차원 UMAP 문장 표현을 플롯했습니다. 결과는 아래 그림과 같습니다:
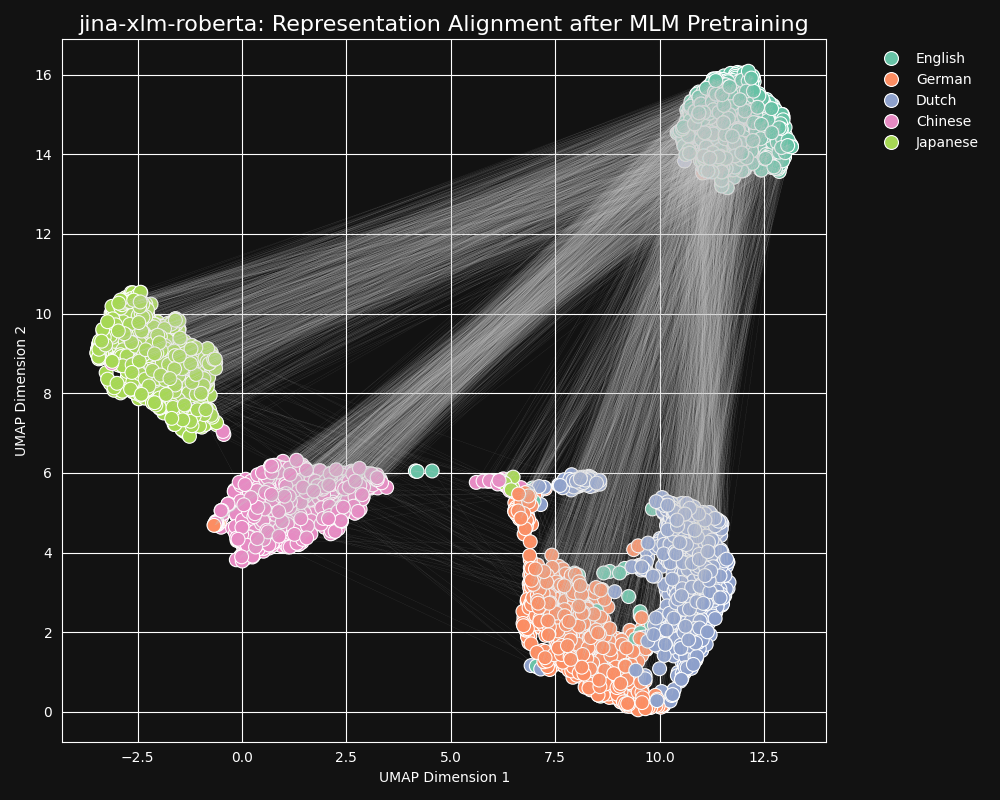
이러한 문장들은
jina-xlm-roberta 임베딩 공간에서 강하게 언어별 클러스터를 형성하는 경향이 있지만, 2차원 투영의 부작용일 수 있는 몇몇 이상치들을 볼 수 있습니다.사전 학습이 동일 언어의 문장 임베딩을 매우 강하게 클러스터링했음을 볼 수 있습니다. 이는 훨씬 더 높은 차원의 공간에서의 분포를 2차원으로 투영한 것이므로, 예를 들어 영어 문장의 좋은 번역인 독일어 문장이 여전히 해당 영어 소스에 가장 가까운 독일어 문장일 수 있습니다. 하지만 이는 영어 문장의 임베딩이 의미적으로 동일하거나 거의 동일한 독일어 문장보다 다른 영어 문장에 더 가까울 가능성이 높다는 것을 보여줍니다.
또한 독일어와 네덜란드어가 다른 언어 쌍들보다 훨씬 더 가까운 클러스터를 형성하는 것을 주목하세요. 이는 비교적 밀접하게 관련된 두 언어에서 놀라운 일이 아닙니다. 독일어와 네덜란드어는 때때로 부분적으로 상호 이해가 가능할 정도로 유사합니다.
일본어와 중국어도 다른 언어들보다 서로 더 가깝게 나타납니다. 같은 방식으로 관련되어 있지는 않지만, 일본어 쓰기에는 일반적으로 kanji (漢字), 중국어로는 hànzì를 사용합니다. 일본어는 이러한 문자의 대부분을 중국어와 공유하며, 두 언어는 하나 또는 여러 개의 한자를 함께 사용하여 쓰는 많은 단어를 공유합니다. MLM의 관점에서 이는 네덜란드어와 독일어 사이의 시각적 유사성과 같은 종류입니다.
각각 두 문장씩 있는 두 언어만 살펴보면 이 "언어 간극"을 더 간단하게 볼 수 있습니다:

MLM이 자연스럽게 텍스트를 언어별로 클러스터링하는 것처럼 보이므로, "my dog is blue"와 "my cat is red"는 독일어 상응어들과 멀리 떨어져 함께 클러스터링됩니다. 이전 블로그 포스트에서 논의된 "양식 간극"과 달리, 우리는 이것이 언어 간의 표면적 유사성과 차이점에서 발생한다고 생각합니다: 유사한 철자, 동일한 문자 시퀀스의 사용, 그리고 가능하게는 형태론과 구문 구조의 유사성 — 공통된 단어 순서와 단어를 구성하는 공통된 방식.
요약하면, 모델이 MLM 사전 학습에서 교차 언어 등가성을 어느 정도 학습하더라도, 이는 언어별로 텍스트를 클러스터링하려는 강한 편향을 극복하기에 충분하지 않습니다. 이는 큰 언어 간극을 남깁니다.
tag대조 학습
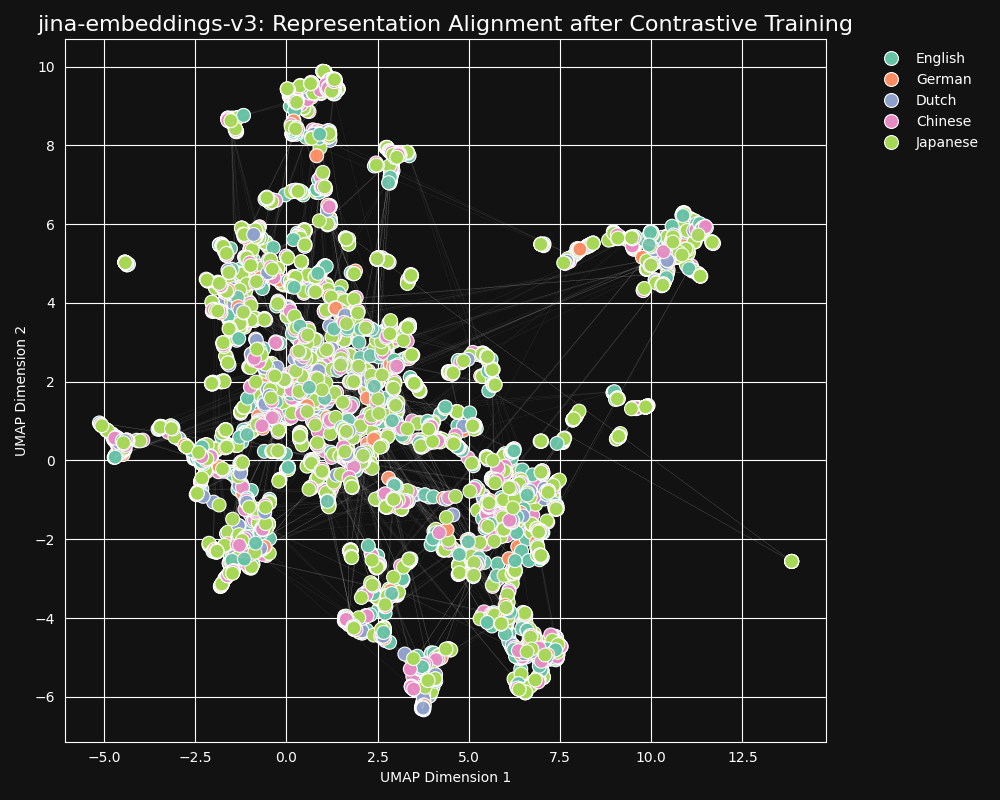
이상적으로, 우리는 임베딩 모델이 언어에 무관심하고 임베딩에서 일반적인 의미만 인코딩하기를 원합니다. 그러한 모델에서는 언어별 클러스터링이 보이지 않고 언어 간극이 없을 것입니다. 한 언어의 문장은 아래 그림과 같이 좋은 번역과 매우 가깝고 같은 언어라 하더라도 다른 의미를 가진 다른 문장과는 멀리 있어야 합니다:

MLM 사전 학습은 그것을 달성하지 못하므로, 우리는 임베딩에서 텍스트의 의미적 표현을 개선하기 위해 추가적인 대조 학습 기법을 사용합니다.
대조 학습은 의미가 유사하거나 다른 것으로 알려진 텍스트 쌍과, 한 쌍이 다른 쌍보다 더 유사한 것으로 알려진 삼중항을 사용합니다. 학습 중에 가중치는 텍스트 쌍과 삼중항 간의 이러한 알려진 관계를 반영하도록 조정됩니다.
우리의 대조 학습 데이터셋에는 30개 언어가 포함되어 있지만, 쌍과 삼중항의 97%는 단일 언어이며, 단 3%만이 교차 언어 쌍이나 삼중항을 포함합니다. 하지만 이 3%만으로도 극적인 결과를 만들어냅니다: jina-embeddings-v3의 임베딩 UMAP 투영에서 보여지듯이, 임베딩은 거의 언어 클러스터링을 보이지 않으며 의미적으로 유사한 텍스트는 언어에 관계없이 가까운 임베딩을 생성합니다.
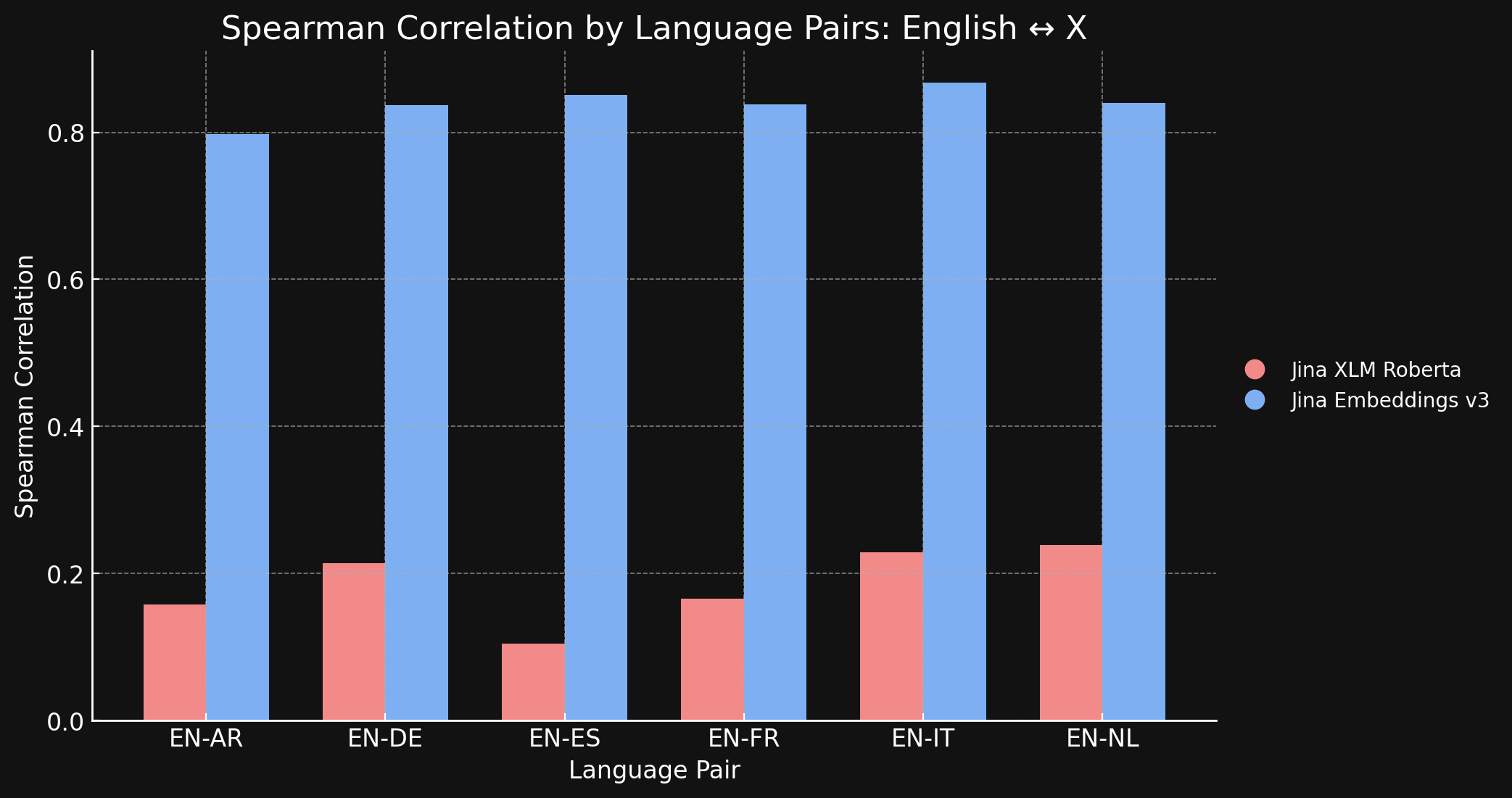
이를 확인하기 위해 STS17 데이터셋에서 jina-xlm-roberta와 jina-embeddings-v3가 생성한 표현의 스피어만 상관관계를 측정했습니다.
아래 표는 번역된 텍스트의 의미적 유사성 순위 간의 스피어만 상관관계를 보여줍니다. 영어 문장 세트를 가져와서 특정 참조 문장의 임베딩과의 유사성을 측정하고 가장 유사한 것부터 가장 덜 유사한 순서로 정렬합니다. 그런 다음 이러한 모든 문장을 다른 언어로 번역하고 순위 매기기 과정을 반복합니다. 이상적인 교차 언어 임베딩 모델에서는 두 정렬된 목록이 동일하고 스피어만 상관관계가 1.0이 될 것입니다.
아래 차트와 표는 jina-xlm-roberta와 jina-embeddings-v3를 사용하여 영어와 STS17 벤치마크의 다른 6개 언어를 비교한 결과를 보여줍니다.
| Task | jina-xlm-roberta |
jina-embeddings-v3 |
|---|---|---|
| English ↔ Arabic | 0.1581 | 0.7977 |
| English ↔ German | 0.2136 | 0.8366 |
| English ↔ Spanish | 0.1049 | 0.8509 |
| English ↔ French | 0.1659 | 0.8378 |
| English ↔ Italian | 0.2293 | 0.8674 |
| English ↔ Dutch | 0.2387 | 0.8398 |
여기서 원래 사전 학습과 비교했을 때 대조 학습이 만드는 엄청난 차이를 볼 수 있습니다. 학습 데이터의 3%만이 교차 언어 데이터임에도 불구하고, jina-embeddings-v3 모델은 사전 학습에서 얻은 언어 격차를 거의 제거할 만큼 충분한 교차 언어 의미론을 학습했습니다.
tag영어 vs 세계: 다른 언어들이 정렬에서 따라잡을 수 있을까?
우리는 jina-embeddings-v3를 89개 언어로 학습시켰으며, 특히 30개의 매우 널리 사용되는 문자 언어에 중점을 두었습니다. 대규모 다국어 학습 코퍼스를 구축하기 위한 우리의 노력에도 불구하고, 영어는 여전히 우리가 대조 학습에 사용한 데이터의 거의 절반을 차지합니다. 충분한 텍스트 자료가 있는 널리 사용되는 글로벌 언어를 포함한 다른 언어들은 학습 세트의 방대한 영어 데이터에 비해 여전히 상대적으로 적게 대표됩니다.
이러한 영어의 우세함을 고려할 때, 영어 표현이 다른 언어들의 표현보다 더 잘 정렬되어 있을까요? 이를 탐구하기 위해 후속 실험을 진행했습니다.
우리는 "앵커"와 "긍정"이라는 1,000개의 영어 텍스트 쌍으로 구성된 parallel-sentences 데이터셋을 구축했습니다. 여기서 긍정 텍스트는 앵커 텍스트에 의해 논리적으로 함의됩니다.

예를 들어, 아래 표의 첫 번째 행을 보세요. 이 문장들은 의미가 완전히 동일하지는 않지만, 호환되는 의미를 가지고 있습니다. 이들은 동일한 상황을 정보적으로 설명합니다.
그런 다음 이 쌍들을 GPT-4를 사용하여 독일어, 네덜란드어, 중국어(간체), 중국어(번체), 일본어의 5개 언어로 번역했습니다. 마지막으로 품질을 보장하기 위해 수동으로 검사했습니다.
| Language | Anchor | Positive |
|---|---|---|
| English | Two young girls are playing outside in a non-urban environment. | Two girls are playing outside. |
| German | Zwei junge Mädchen spielen draußen in einer nicht urbanen Umgebung. | Zwei Mädchen spielen draußen. |
| Dutch | Twee jonge meisjes spelen buiten in een niet-stedelijke omgeving. | Twee meisjes spelen buiten. |
| Chinese (Simplified) | 两个年轻女孩在非城市环境中玩耍。 | 两个女孩在外面玩。 |
| Chinese (Traditional) | 兩個年輕女孩在非城市環境中玩耍。 | 兩個女孩在外面玩。 |
| Japanese | 2人の若い女の子が都市環境ではない場所で遊んでいます。 | 二人の少女が外で遊んでいます。 |
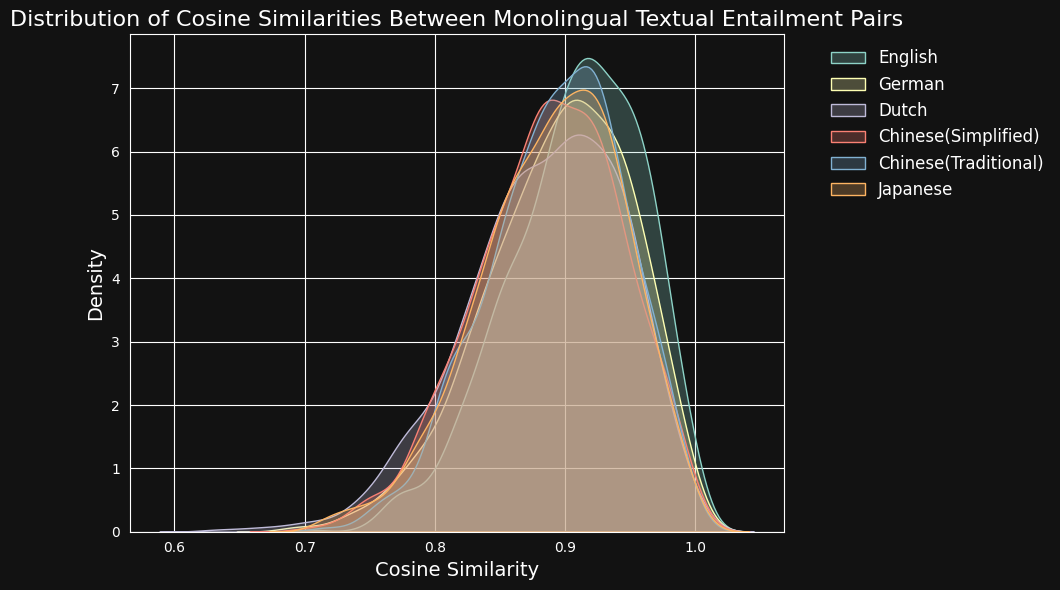
그런 다음 jina-embeddings-v3로 각 텍스트 쌍을 인코딩하고 그들 사이의 코사인 유사도를 계산했습니다. 아래 그림과 표는 각 언어의 코사인 유사도 점수 분포와 평균 유사도를 보여줍니다:
| Language | Average Cosine Similarity |
|---|---|
| English | 0.9078 |
| German | 0.8949 |
| Dutch | 0.8844 |
| Chinese (Simplified) | 0.8876 |
| Chinese (Traditional) | 0.8933 |
| Japanese | 0.8895 |
학습 데이터에서 영어가 우세함에도 불구하고, jina-embeddings-v3는 독일어, 네덜란드어, 일본어, 그리고 두 형태의 중국어에서 영어만큼 잘 의미적 유사성을 인식합니다.
tag언어 장벽 허물기: 영어를 넘어선 교차 언어 정렬
일반적으로 교차 언어 표현 정렬 연구는 영어를 포함하는 언어 쌍을 연구합니다. 이러한 초점은 이론상 실제 상황을 가리킬 수 있습니다. 모델이 다른 언어 쌍이 제대로 지원되는지 검토하지 않고, 단순히 모든 것을 영어에 최대한 가깝게 표현하도록 최적화할 수 있습니다.
이를 탐구하기 위해 parallel-sentences 데이터셋을 사용하여 영어 이외의 이중 언어 쌍에 대한 교차 언어 정렬을 연구하는 실험을 수행했습니다.
아래 표는 서로 다른 언어 쌍 간의 동등한 텍스트 - 공통된 영어 원문의 번역본 - 사이의 코사인 유사도 분포를 보여줍니다. 이상적으로는 모든 쌍이 코사인 1을 가져야 합니다 - 즉, 동일한 의미 임베딩을 갖습니다. 실제로는 이런 일이 일어날 수 없지만, 좋은 모델이라면 번역 쌍에 대해 매우 높은 코사인 값을 가질 것으로 예상됩니다.
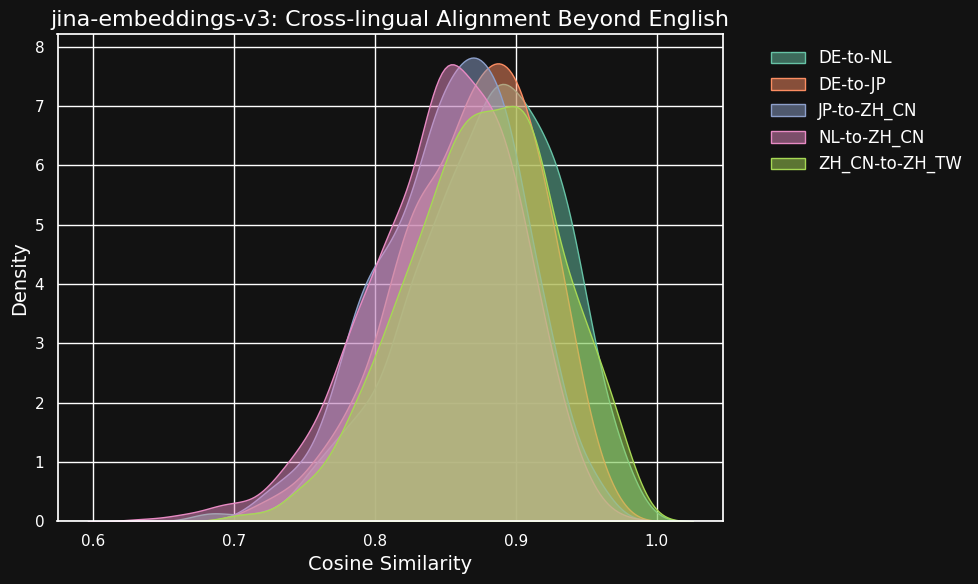
| Language Pair | Average Cosine Similarity |
|---|---|
| German ↔ Dutch | 0.8779 |
| German ↔ Japanese | 0.8664 |
| Chinese (Simplified) ↔ Japanese | 0.8534 |
| Dutch ↔ Chinese (Simplified) | 0.8479 |
| Chinese (Simplified) ↔ Chinese (Traditional) | 0.8758 |
서로 다른 언어 간의 유사도 점수가 동일 언어의 호환 가능한 텍스트보다 약간 낮지만, 여전히 매우 높습니다. 네덜란드어/독일어 번역의 코사인 유사도는 독일어의 호환 가능한 텍스트 간의 유사도에 거의 근접합니다.
독일어와 네덜란드어가 매우 유사한 언어이기 때문에 이는 놀랍지 않을 수 있습니다. 마찬가지로, 여기서 테스트된 두 가지 중국어 변형은 실제로 두 개의 다른 언어가 아니라 같은 언어의 스타일이 다른 형태일 뿐입니다. 하지만 네덜란드어와 중국어 또는 독일어와 일본어와 같이 매우 다른 언어 쌍에서도 의미적으로 동등한 텍스트 간에 매우 강한 유사성을 보이는 것을 알 수 있습니다.
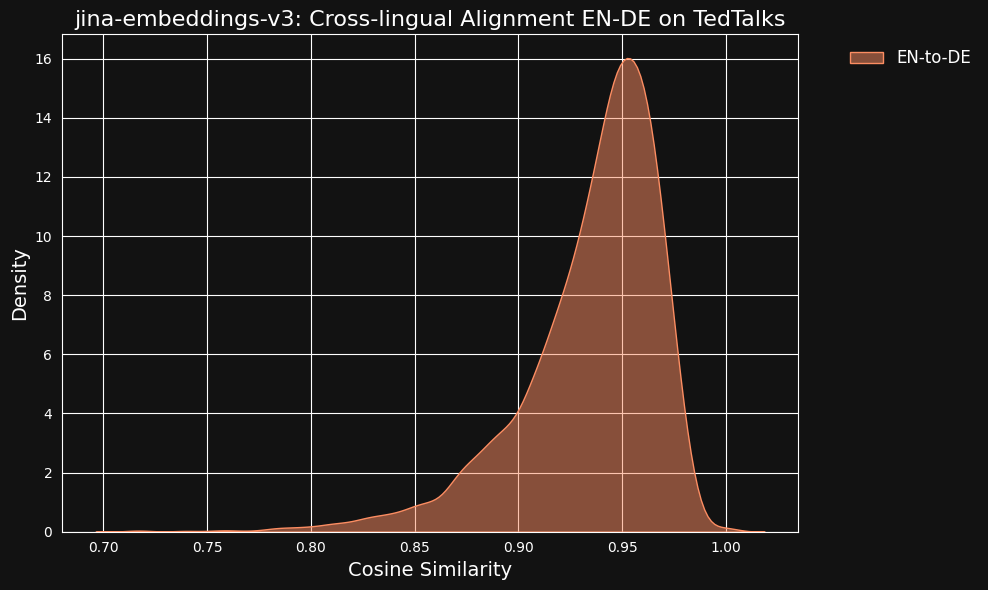
이런 매우 높은 유사도 값이 ChatGPT를 번역기로 사용한 부작용일 수 있다고 생각했습니다. 이를 테스트하기 위해 TED Talks의 영어와 독일어 인간 번역 대본을 다운로드하여 정렬된 번역 문장들이 같은 높은 상관관계를 가지는지 확인했습니다.
아래 그림에서 볼 수 있듯이 결과는 기계 번역된 데이터보다 더 강력했습니다.
tag교차 언어 데이터가 교차 언어 정렬에 얼마나 기여하나요?
사라지는 언어 격차와 높은 수준의 교차 언어 성능은 명시적으로 교차 언어인 훈련 데이터의 매우 작은 부분에 비해 불균형해 보입니다. 대조 훈련 데이터의 단 3%만이 모델에게 언어 간 정렬 방법을 구체적으로 가르칩니다.
그래서 우리는 교차 언어가 실제로 어떤 기여를 하고 있는지 테스트해보았습니다.
작은 실험을 위해 교차 언어 데이터 없이 jina-embeddings-v3를 완전히 재훈련하는 것은 비용이 너무 많이 들기 때문에, Hugging Face에서 xlm-roberta-base 모델을 다운로드하여 jina-embeddings-v3 훈련에 사용한 데이터의 일부를 사용하여 대조 학습을 추가로 진행했습니다. 우리는 구체적으로 교차 언어 데이터의 양을 조정하여 두 가지 경우를 테스트했습니다: 하나는 교차 언어 데이터가 없는 경우이고, 다른 하나는 쌍의 20%가 교차 언어인 경우입니다. 아래 표에서 훈련 메타 파라미터를 확인할 수 있습니다:
| Backbone | % Cross-Language | Learning Rate | Loss Function | Temperature |
xlm-roberta-base without X-language data | 0% | 5e-4 | InfoNCE | 0.05 |
xlm-roberta-base with X-language data | 20% | 5e-4 | InfoNCE | 0.05 |
그런 다음 MTEB의 STS17과 STS22 벤치마크와 스피어만 상관계수를 사용하여 두 모델의 교차 언어 성능을 평가했습니다. 결과는 다음과 같습니다:
tagSTS17
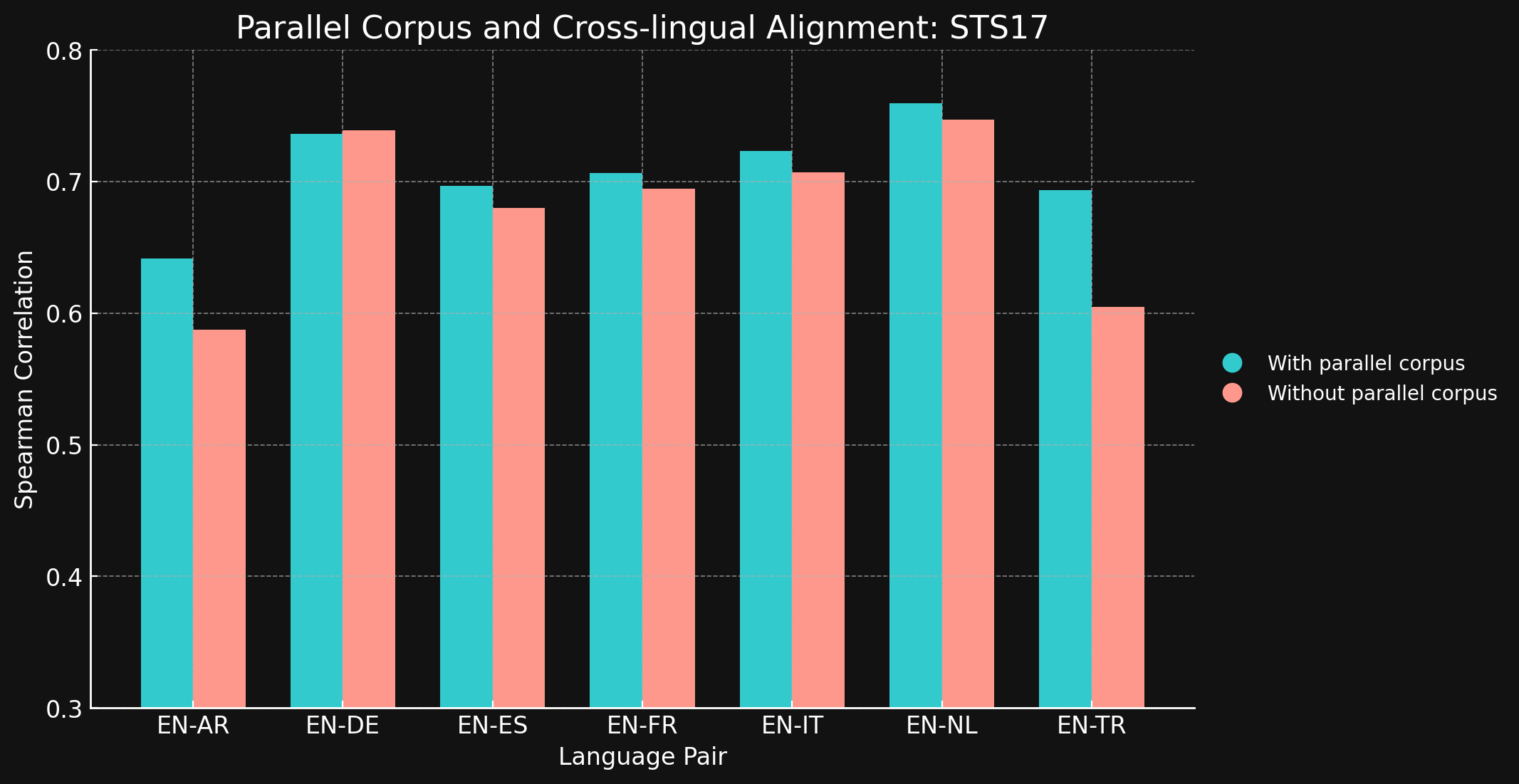
| Language Pair | With parallel corpora | Without parallel corpora |
| English ↔ Arabic | 0.6418 | 0.5875 |
| English ↔ German | 0.7364 | 0.7390 |
| English ↔ Spanish | 0.6968 | 0.6799 |
| English ↔ French | 0.7066 | 0.6944 |
| English ↔ Italian | 0.7232 | 0.7070 |
| English ↔ Dutch | 0.7597 | 0.7468 |
| English ↔ Turkish | 0.6933 | 0.6050 |
tagSTS22
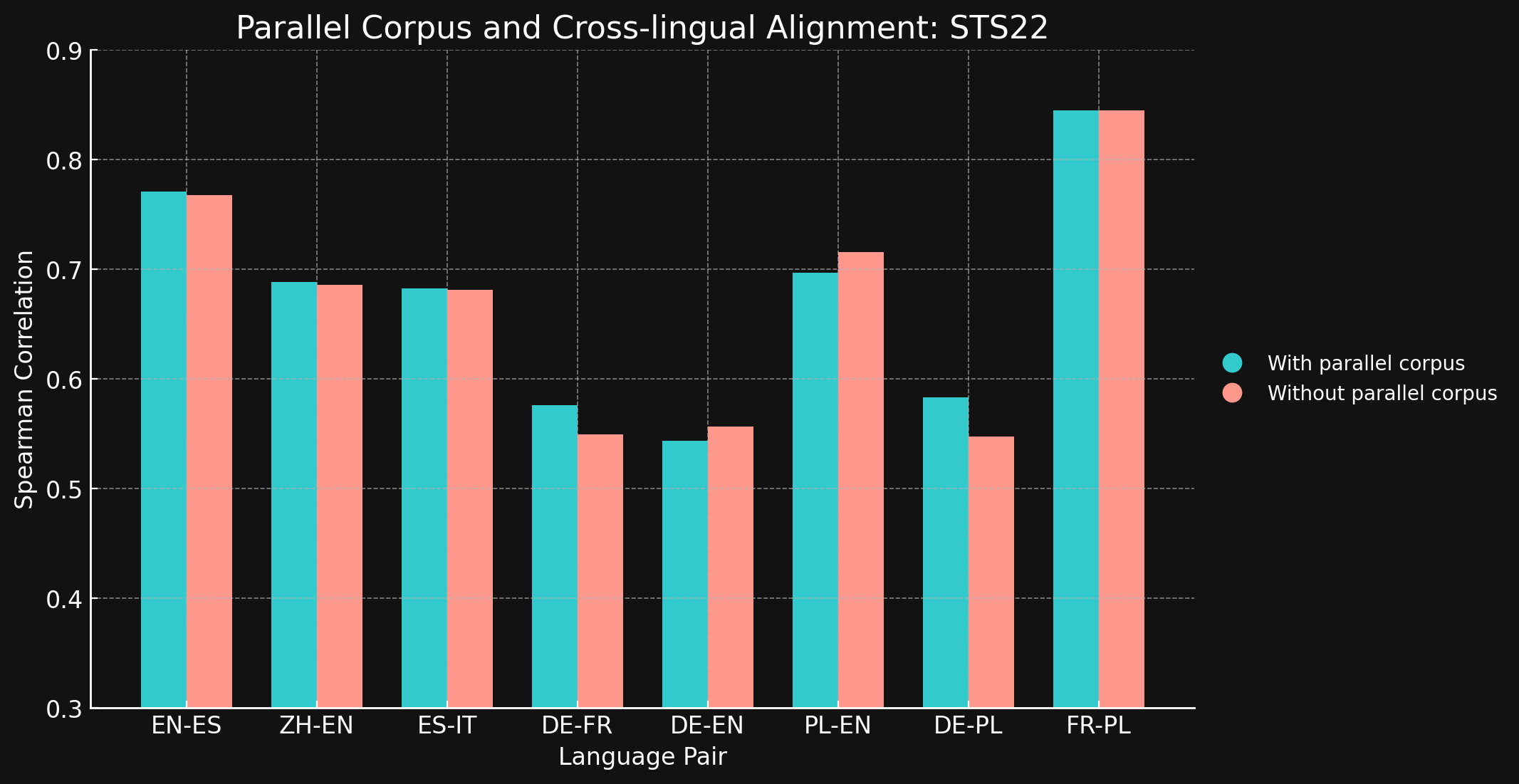
| 언어 쌍 | 병렬 코퍼스 사용 | 병렬 코퍼스 미사용 |
| English ↔ Spanish | 0.7710 | 0.7675 |
| Simplified Chinese ↔ English | 0.6885 | 0.6860 |
| Spanish ↔ Italian | 0.6829 | 0.6814 |
| German ↔ French | 0.5763 | 0.5496 |
| German ↔ English | 0.5439 | 0.5566 |
| Polish ↔ English | 0.6966 | 0.7156 |
| German ↔ English | 0.5832 | 0.5478 |
| French ↔ Polish | 0.8451 | 0.8451 |
테스트한 대부분의 언어 쌍에서 교차 언어 학습 데이터가 거의 또는 전혀 개선을 가져오지 않는다는 것을 보고 놀랐습니다. 더 큰 데이터셋으로 완전히 학습된 모델에서도 이러한 결과가 유지될지는 확실히 알 수 없지만, 명시적인 교차 언어 학습이 큰 도움이 되지 않는다는 증거를 제공합니다.
하지만 STS17에는 영어/아랍어와 영어/터키어 쌍이 포함되어 있다는 점에 주목해야 합니다. 이 두 언어는 우리의 학습 데이터에서 상대적으로 적게 대표되는 언어입니다. 우리가 사용한 XML-RoBERTa 모델은 아랍어가 2.25%, 터키어가 2.32%로, 우리가 테스트한 다른 언어들에 비해 훨씬 적은 비중으로 사전 학습되었습니다. 이 실험에서 사용한 작은 대조 학습 데이터셋에서는 아랍어가 1.7%, 터키어가 1.8%에 불과했습니다.
이 두 언어 쌍만이 교차 언어 데이터로 학습했을 때 명확한 차이를 보인 유일한 경우입니다. 우리는 명시적인 교차 언어 데이터가 학습 데이터에서 덜 대표되는 언어들에 대해 더 효과적이라고 생각하지만, 결론을 내리기 전에 이 영역을 더 탐구할 필요가 있습니다. 대조 학습에서 교차 언어 데이터의 역할과 효과는 Jina AI가 활발히 연구하고 있는 분야입니다.
tag결론
마스크드 언어 모델링과 같은 기존의 언어 사전 학습 방법은 "언어 간격"을 남깁니다. 이는 서로 다른 언어의 의미적으로 유사한 텍스트들이 원래 있어야 할 만큼 가깝게 정렬되지 않는다는 것을 의미합니다. Jina Embeddings의 대조 학습 방식이 이러한 간격을 줄이거나 심지어 제거하는 데 매우 효과적이라는 것을 보여드렸습니다.
이것이 작동하는 이유는 완전히 명확하지 않습니다. 우리는 대조 학습에서 명시적인 교차 언어 텍스트 쌍을 사용하지만, 매우 적은 양으로만 사용하며, 이것들이 실제로 양질의 교차 언어 결과를 보장하는 데 얼마나 큰 역할을 하는지는 불분명합니다. 더 통제된 조건에서 명확한 효과를 보여주려는 우리의 시도는 명확한 결과를 도출하지 못했습니다.
하지만 jina-embeddings-v3가 사전 학습 언어 간격을 극복했다는 것은 분명하며, 이는 다국어 애플리케이션을 위한 강력한 도구가 되었습니다. 여러 언어에 걸쳐 동일한 강력한 성능이 필요한 모든 작업에 바로 사용할 수 있습니다.
jina-embeddings-v3는 우리의 Embeddings API(백만 토큰 무료)를 통해 또는 AWS나 Azure를 통해 사용할 수 있습니다. 이러한 플랫폼 외부에서 또는 회사 내부에서 사용하고 싶으시다면, CC BY-NC 4.0 라이선스 하에 있다는 점을 기억해 주세요. 상업적 사용에 관심이 있으시다면 저희에게 연락해 주시기 바랍니다.





