

많은 사람들처럼 저도 많은 팟캐스트를 듣습니다. 일부는 공상 과학에 관한 것이고, 일부는 고생물학에 관한 것이며, 또 일부는 이상한 중세 사람들에 관한 것입니다. 제 취향이 가끔 좋지 않은 것을 제외하면 범죄 관련 콘텐츠는 없습니다.
하지만... 이 모든 팟캐스트를 듣는 것은 힘듭니다. 그런데 이것이 최악은 아닙니다. 저는 또한 많은 뉴스 피드를 구독하고 있습니다. 그리고 그것은 많은 읽을거리가 될 수 있습니다. 이 모든 뉴스 피드의 내용을 5분 요약으로 만들어서 아침에 이를 닦는 동안 휴대폰으로 들을 수 있다면 정말 좋을 것 같습니다.
이 글이 어디로 향하는지 아시겠죠. 저는 Python을 사용하여 (주로) Jina 기술 스택으로 개인화된 일일 뉴스 팟캐스트를 만드는 도구를 만들고 있습니다.
어떻게 들리는지 미리 들어보고 싶다면 아래에서 들어보실 수 있습니다:
tag뉴스 피드란 무엇인가요?
우선, 대부분의 사람들이 RSS나 Atom 피드라는 용어에 익숙하지 않기 때문에 저는 이것들을 "뉴스 피드"라고 부르고 있습니다. 간단히 말해서, 피드는 블로그나 뉴스 소스에서 발행한 글들의 구조화된 목록으로, 최신순으로 정렬되어 있습니다. 많은 사이트에서 이를 제공하고 있으며, 여러 앱과 웹사이트에서 모든 피드를 가져와서 Ars Technica, Taylor Swift 팬사이트, Washington Post와 같은 웹사이트를 직접 방문하지 않고도 한 앱에서 모든 뉴스를 읽을 수 있게 해줍니다:
이는 선사 시대 웹에서부터 이어져 온 오래된 기술이지만, Jina AI의 블로그를 포함한 많은 웹사이트에서 여전히 지원하고 있습니다(여기 우리의 피드가 있습니다).
간단히 말해서, 피드를 사용하면 사이드바의 불필요한 요소들과 광고를 건너뛰고 한 곳에서 모든 뉴스를 읽을 수 있습니다. 이 포스트에서는 뉴스 피드를 사용하여 우리가 팔로우하는 사이트들의 최신 게시물을 찾고 다운로드할 것입니다.
tag이 피딩 프렌지를 시작해봅시다
이 마법을 구현하기 위해, 우리는 여러 서비스와 Python 라이브러리를 사용할 것입니다:
- Feedparser: 뉴스 피드에서 콘텐츠를 다운로드하고 추출하는 Python 라이브러리입니다.
- Jina Reader: 헤더, 푸터, 사이드바와 같은 불필요한 요소를 제외하고 각 기사의 내용만 추출하는 Jina의 API입니다.
- PromptPerfect: Prompts-as-Services는 각 기사를 요약한 다음 NPR 뉴스리더 스타일로 하나의 문단으로 요약을 결합합니다.
- gTTS: 뉴스 리포트를 소리 내어 읽어주는 Google의 Text-to-Speech 라이브러리입니다.
이 포스트에서는 여기까지만 다룰 예정입니다. 개인화된 팟캐스트의 피드를 만들고 싶으시다면 다른 자료를 참고하시기 바랍니다.
tag피드 다운로드하기
이는 간단한 예제이므로, 기술 뉴스 웹사이트인 The Register와 OSNews의 뉴스 피드만 사용하겠습니다.
feed_urls = [
"https://www.osnews.com/feed/",
"https://www.theregister.com/headlines.atom"
]Feedparser를 사용하여 피드를 다운로드하고 각 피드에서 기사 링크를 다운로드할 수 있습니다:
import feedparser
for feed_url in feed_urls:
feed = feedparser.parse(feed_url)
for entry in feed["entries"]:
page_urls.append(entry["link"])tagJina Reader로 기사 텍스트 추출하기
각 피드는 해당 웹사이트의 각 기사 링크를 포함하고 있습니다. 그 웹페이지를 그냥 다운로드하면 사이드바, 헤더, 푸터 등 우리가 필요하지 않은 많은 HTML을 얻게 됩니다. 이것을 LLM에 제공하는 것은 마치 풀을 씹는 것과 같습니다. LLM이 이를 처리할 수는 있지만, 이는 자연스럽게 원하는 형태가 아닙니다.
LLM이 진정으로 원하는 것은 일반 텍스트에 가까운 것입니다. Jina Reader는 기사를 Markdown으로 변환합니다.

이렇게 하면 다음과 같이 변환됩니다:
Title: Unintended acceleration leads to recall of every Cybertruck produced so far
URL Source: https://www.theregister.com/2024/04/19/tesla_recalls_all_3878_cybertrucks/?td=rt-3a
Published Time: 2024-04-19T13:55:08Z
Markdown Content:
Tesla has issued a recall notice for every single Cybertruck it has produced thus far, a sum of 3,878 vehicles.
Today's [recall notice](https://static.nhtsa.gov/odi/rcl/2024/RCLRPT-24V276-7026.PDF) \[PDF\] by the National Highway Traffic Safety Administration states that Cybertrucks have a defect on the accelerator pedal, which can get wedged against the interior of the car, keeping it pushed down. The pedal actually comes in two parts: the pedal itself and then a longer piece on top of it. That top piece can become partially detached and then slide off against the interior trim, making it impossible for the pedal to lift up. This defect [was already suspected](https://www.theregister.com/2024/04/15/tesla_lays_off_10_percent/) as Tesla paused production of the Cybertruck due to an "unexpected delay." Some Cybertruck owners also spoke on social media about their vehicles uncontrollably accelerating, with one crashing into a pole and another demonstrating [on film](https://www.tiktok.com/@el.chepito1985/video/7357758176504089898) how exactly the pedal breaks and gets stuck.
...전체 기사를 포함하는 것은 과도하므로 짧게 잘랐습니다. 하지만 이것이 명확하고 사람이 읽을 수 있는 (마크다운) 텍스트라는 것을 알 수 있습니다.
이러한 형태가 아닌:
<!doctype html>
<html lang="en">
<head>
<meta content="text/html; charset=utf-8" http-equiv="Content-Type">
<title>Unintended acceleration leads to recall of every Cybertruck • The Register</title>
<meta name="robots" content="max-snippet:-1, max-image-preview:standard, max-video-preview:0">
<meta name="viewport" content="initial-scale=1.0, width=device-width"/>
<meta property="og:image" content="https://regmedia.co.uk/2019/11/22/cybertruck.jpg"/>
<meta property="og:type" content="article" />
<meta property="og:url" content="https://www.theregister.com/2024/04/19/tesla_recalls_all_3878_cybertrucks/" />
<meta property="og:title" content="Unintended acceleration leads to recall of every Cybertruck" />
<meta property="og:description" content="That isn't what Tesla meant by Full Self-Driving" />
<meta name="twitter:card" content="summary_large_image">
<meta name="twitter:site" content="@TheRegister">
<script type="application/ld+json">
...실제 콘텐츠에 도달하기도 전에 잘라야 했습니다. 사람이 읽을 수 없는 불필요한 내용이 너무 많습니다.
LLM에 더 자연스럽게 소화할 수 있는 것(HTML보다는 마크다운)을 제공함으로써 더 나은 출력을 얻을 수 있습니다. 그렇지 않으면 사자에게 도리토스를 먹이는 것과 같습니다. 먹을 수는 있지만, 그런 식단을 유지한다면 최상의 사자가 될 수는 없습니다.
사람이 읽을 수 있는 방식으로 텍스트만 추출하기 위해 Jina Reader의 API를 사용할 것입니다:
import requests
articles = []
for url in page_urls:
reader_url = f"https://r.jina.ai/{url}"
article = requests.get(reader_url)
articles.append(article.text)https://r.jina.ai/<url>로 이동하면 됩니다. 예: https://r.jina.ai/https://www.theregister.com/2024/04/19/wing_commander_windows_95/tagPromptPerfect로 기사 요약하기
기사가 많을 수 있기 때문에, LLM을 사용하여 각 기사를 개별적으로 요약할 것입니다. 모든 기사를 한꺼번에 합쳐서 LLM에 요약을 요청하면 너무 많은 토큰으로 인해 처리가 어려울 수 있습니다.
이는 처리하고자 하는 기사의 수에 따라 달라질 것입니다. 몇 개의 기사만 다룰 경우에는 모두를 하나의 긴 문자열로 연결하여 한 번의 호출로 처리하는 것이 시간과 비용을 절약할 수 있습니다. 하지만 이 예제에서는 더 많은 수의 기사를 다룬다고 가정하겠습니다.
기사를 요약하기 위해 PromptPerfect의 Prompt-as-a-Service를 사용할 것입니다.
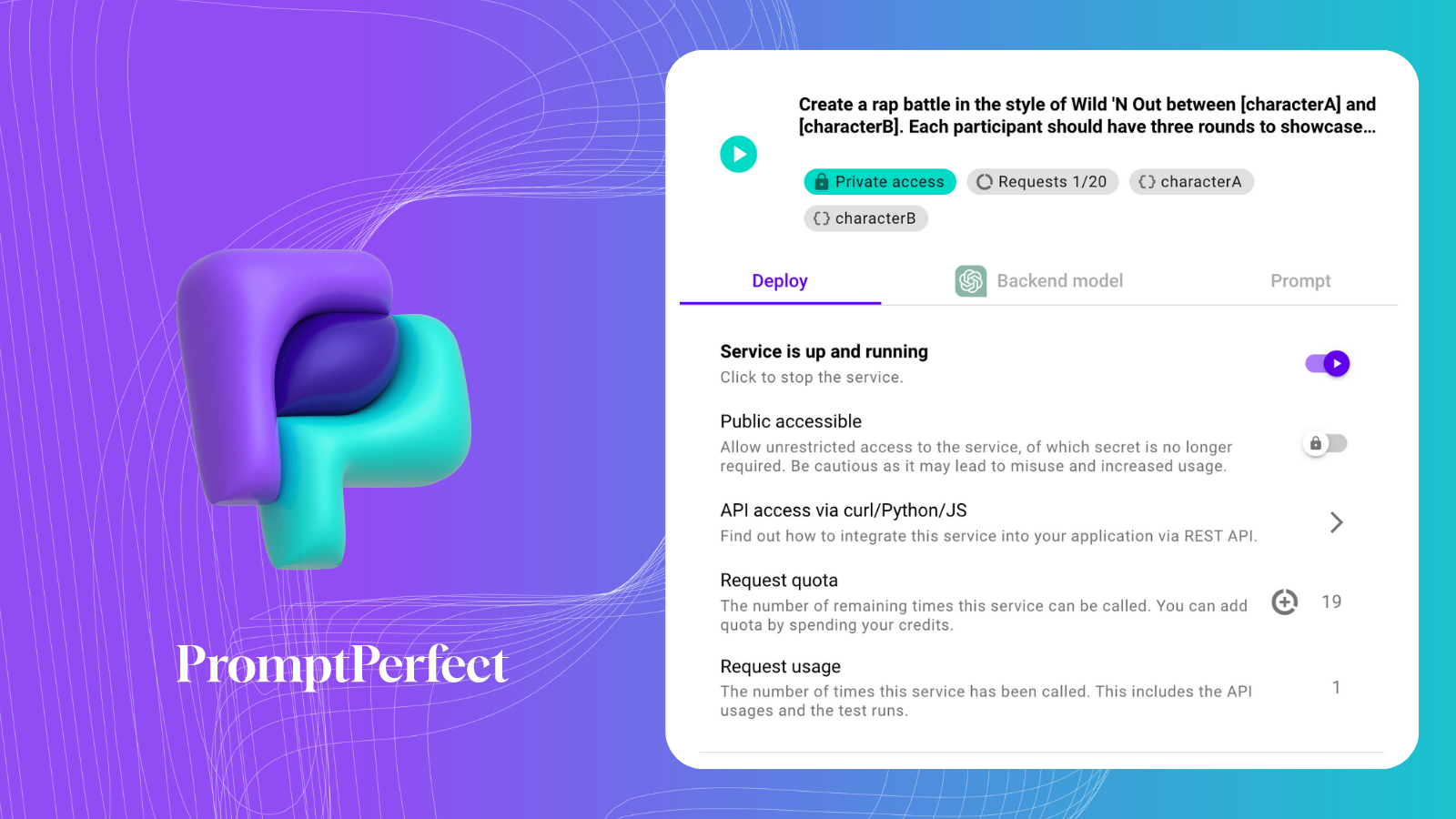
여기 우리의 Prompt-as-Service입니다:

이 글 뒷부분에서 다른 Prompt-as-Service를 호출할 것이므로, 이를 위한 함수를 작성하겠습니다:
def get_paas_response(id, template_dict):
url = f"https://api.promptperfect.jina.ai/{id}"
headers = {
"x-api-key": f"token {PROMPTPERFECT_KEY}",
"Content-Type": "application/json"
}
response = requests.post(url, headers=headers, json={"parameters": template_dict})
if response.status_code == 200:
text = response.json()["data"]
return text
else:
return response.text각 요약을 리스트에 추가한 다음, 최종적으로 글머리 기호가 있는 마크다운 리스트로 연결하겠습니다:
summaries = []
for article in articles:
summary = get_paas_response(
prompt_id="mkuMXLdx1kMU0Xa8l19A",
template_prompt={"article": article}
)
summaries.append(summary)
concat_summaries = "\n- ".join(summaries)tagPromptPerfect로 뉴스 리포트 생성하기
이제 글머리 기호 리스트가 있으니, 이를 다른 Prompt-as-a-Service에 전송하여 자연스러운 뉴스 진행자의 말투로 된 뉴스 속보를 생성할 수 있습니다:

전체 프롬프트는 다음과 같습니다:
당신은 NPR 기술 뉴스 편집자입니다. 다음과 같은 뉴스 요약을 받았습니다:
[summaries]
당신의 임무는 각 항목을 자연스럽게 다루면서 다음 항목으로 이어지는 한 단락의 개요를 제공하는 것입니다. 필요한 경우 항목의 순서를 변경할 수 있으며, 중복된 내용은 병합할 수 있습니다.
NPR 일일 뉴스에서 읽을 수 있는 한 단락의 대본을 출력하세요. 대본은 소리 내어 읽을 때 5분을 넘지 않아야 합니다.
다음 코드로 뉴스 대본을 얻을 수 있습니다:
news_script = get_paas_response(
prompt_id="tmW07mipzJ14HgAjOcfD",
template_prompt={"summaries": concat_summaries}
)최종 텍스트는 다음과 같습니다:
오늘의 기술 뉴스에서는 다양한 업데이트와 발전 사항을 다루겠습니다. 먼저, Tiny11 Builder 도구는 사용자가 Windows 11을 디블로트하여 자신의 선호도에 맞는 맞춤형 이미지를 생성할 수 있게 해줍니다. 게임 분야로 넘어가서, 90년대 게이머들을 매료시켰던 슈퍼 닌텐도 카트리지 내부의 숨겨진 구성 요소들을 살펴보겠습니다. 소프트웨어 분야에서는 Wayland용 Niri 타일링 윈도우 매니저가 무한 스크롤링과 개선된 애니메이션과 같은 새로운 기능을 제공하는 주요 업데이트를 발표했습니다. AI 영역에서는 Microsoft의 Copilot 기능이 Windows Insider 배포 과정에서 버그와 침해적인 동작으로 인해 배포가 중단되는 등의 문제에 직면했습니다. 한편, 영국 정보위원회(ICO)는 Google의 Privacy Sandbox에 대해 프라이버시 영향과 경쟁에 미치는 영향에 대한 우려를 제기했습니다. 마지막으로, 미국 연방항공국(FAA)은 Varda Space Industries 관련 사건 이후, 재진입 차량이 발사 전 라이선스를 취득하도록 발사 라이선스 요건을 업데이트했습니다. 이러한 다양한 기술 이야기들은 기술 세계의 지속적인 발전과 도전을 보여줍니다.
tag뉴스 소리내어 읽기
텍스트를 소리내어 읽기 위해 Google의 TTS 라이브러리를 사용하겠습니다.


from gtts import gTTS
tts = gTTS(news_script, tld="us")
tts.save("output.mp3")이렇게 하면 최종 오디오 파일이 생성됩니다:
tag다음 단계
이 글에서는 나머지 팟캐스트 제작 경험에 대해서는 다루지 않을 것입니다. 그것은 우리의 전문 분야가 아니며, 의학적 조언과 마찬가지로 팟캐스트 피드 설정, Spotify나 Apple Podcasts 등에 업로드하는 세부사항에 대해서는 우리의 조언을 듣지 않는 것이 좋습니다. 의학이나 팟캐스트에 관한 조언은 각각 의사나 Joe Rogan과 상담하시기 바랍니다.
Jina Reader가 할 수 있는 다른 기능에 대해서는, 웹 페이지의 읽기 가능한 버전을 다운로드하여 만들 수 있는 모든 RAG 애플리케이션을 생각해보세요. PromptPerfect의 경우, YouTuber(또는 관심이 있다면 마케터)를 어떻게 도울 수 있는지 살펴보세요.





