
최근 Stanford NLP 그룹이 개발한 언어 모델(LM) 프롬프트를 알고리즘적으로 최적화하는 최신 프레임워크인 DSPy를 살펴보았습니다. 지난 3일 동안 DSPy에 대한 초기 인상과 귀중한 통찰을 얻었습니다. 제 관찰은 DSPy의 공식 문서를 대체하지 않습니다. 실제로 이 게시물을 자세히 살펴보기 전에 그들의 문서와 README를 한 번 읽어보시는 것을 강력히 권장합니다. 여기서의 논의는 DSPy의 기능을 며칠 동안 탐색한 초기 이해를 반영합니다. DSPy Assertions, Typed Predictor, LM 가중치 튜닝과 같은 여러 고급 기능은 아직 자세히 살펴보지 못했습니다.
 stanfordnlp
stanfordnlpJina AI에서 주로 검색 기반을 다루는 제 배경에도 불구하고, DSPy에 대한 제 관심은 Retrieval-Augmented Generation (RAG)의 잠재력에서 직접적으로 비롯된 것이 아닙니다. 대신 일부 생성 작업을 해결하기 위해 자동 프롬프트 튜닝에 DSPy를 활용할 수 있는 가능성에 관심이 있었습니다.
DSPy를 처음 접하시는 분이나, 프레임워크에 익숙하지만 공식 문서가 혼란스럽거나 부담스럽게 느껴지시는 분들을 위한 글입니다. 또한 초보자에게 부담스러울 수 있는 DSPy의 관용구를 엄격히 따르지 않기로 했습니다. 그럼 더 자세히 살펴보겠습니다.
tagDSPy에서 좋아하는 점
tagDSPy가 프롬프트 엔지니어링의 순환 고리를 닫다
DSPy에서 가장 흥미로운 점은 프롬프트 엔지니어링 주기의 순환 고리를 닫는 접근 방식입니다. 수동적이고 수작업인 프로세스를 데이터셋 준비, 모델 정의, 훈련, 평가, 테스트와 같은 구조화되고 잘 정의된 기계 학습 워크플로우로 변환합니다. 이것이 제가 생각하는 DSPy의 가장 혁신적인 측면입니다.
Bay Area를 여행하며 LLM 평가에 초점을 맞춘 많은 스타트업 창업자들과 이야기를 나누면서, 메트릭, 환각, 관찰 가능성, 규정 준수에 대한 논의를 자주 접했습니다. 하지만 이러한 대화는 종종 중요한 다음 단계로 나아가지 못합니다: 이러한 모든 메트릭을 가지고 우리는 다음에 무엇을 해야 할까요? 특정 마법의 단어들(예: "내 할머니가 돌아가시고 있어요")이 메트릭을 향상시킬 수 있다는 희망으로 프롬프트의 문구를 수정하는 것이 전략적 접근이라고 할 수 있을까요? 이 질문은 많은 LLM 평가 스타트업들이 답하지 못했고, DSPy를 발견하기 전까지는 저도 해결할 수 없었습니다. DSPy는 특정 메트릭을 기반으로 프롬프트를 최적화하거나, 프롬프트와 LLM 가중치를 모두 포함하는 전체 LLM 파이프라인을 최적화하는 명확하고 프로그래매틱한 방법을 소개합니다.
LangChain의 CEO인 Harrison과 전 OpenAI 개발자 관계 책임자인 Logan은 Unsupervised Learning Podcast에서 2024년이 LLM 평가의 중요한 전환점이 될 것이라고 말했습니다. 이러한 이유로 DSPy가 현재보다 더 많은 관심을 받아야 한다고 생각합니다. DSPy는 퍼즐의 중요한 누락된 조각을 제공하기 때문입니다.
tagDSPy가 로직을 텍스트 표현에서 분리하다
DSPy의 또 다른 인상적인 점은 프롬프트 엔지니어링을 재현 가능하고 LLM에 구애받지 않는 모듈로 공식화한다는 것입니다. 이를 위해 프롬프트에서 로직을 추출하여 로직과 텍스트 표현 사이의 명확한 관심사 분리를 만듭니다. 아래 그림과 같습니다.
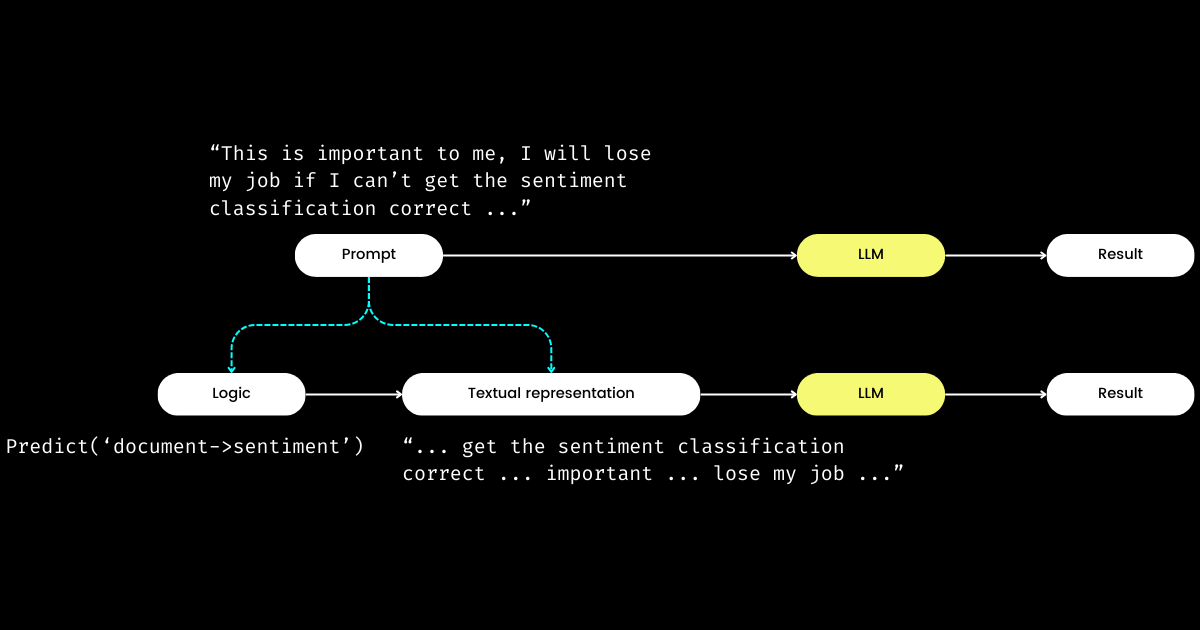
dspy.Module,)과 그것의 텍스트 표현으로 구성됩니다. 로직은 불변하고, 재현 가능하며, 테스트 가능하고 LLM에 구애받지 않습니다. 텍스트 표현은 단지 로직의 결과일 뿐입니다.로직을 불변하고, 테스트 가능하며, LLM에 구애받지 않는 "원인"으로, 텍스트 표현을 단순히 그것의 "결과"로 보는 DSPy의 개념은 처음에는 이해하기 어려울 수 있습니다. 특히 "프로그래밍 언어의 미래는 자연어"라는 널리 퍼진 믿음을 고려할 때 더욱 그렇습니다. "프롬프트 엔지니어링이 미래"라는 아이디어를 받아들이면, DSPy의 설계 철학을 마주했을 때 혼란스러울 수 있습니다. 단순화될 것이라는 기대와는 반대로, DSPy는 자연어 프롬프팅을 C 프로그래밍의 복잡성으로 되돌리는 것처럼 보이는 다양한 모듈과 시그니처 구문을 도입합니다!
하지만 왜 이런 접근 방식을 취할까요? 제가 이해하기로는 프롬프트 프로그래밍의 핵심에는 핵심 로직이 있고, 커뮤니케이션은 증폭기 역할을 하여 그 효과를 향상시키거나 감소시킬 수 있습니다. "감정 분류를 수행하라"는 지시는 핵심 로직을 나타내는 반면, "이 예시들을 따르지 않으면 해고하겠다"와 같은 문구는 그것을 전달하는 한 가지 방법입니다. 실제 상호작용과 마찬가지로, 일을 처리하는 데 어려움을 겪는 것은 종종 로직의 결함이 아닌 문제가 있는 커뮤니케이션에서 비롯됩니다. 이것이 많은 사람들, 특히 비원어민들이 프롬프트 엔지니어링을 어려워하는 이유를 설명합니다. 우리 회사의 매우 유능한 소프트웨어 엔지니어들이 로직의 부족이 아닌 "분위기를 말하지" 못하기 때문에 프롬프트 엔지니어링에 어려움을 겪는 것을 보았습니다. 로직을 프롬프트에서 분리함으로써, DSPy는 dspy.Module을 통해 로직의 결정론적 프로그래밍을 가능하게 하여, 개발자들이 사용하는 LLM에 관계없이 전통적인 엔지니어링에서처럼 로직에 집중할 수 있게 합니다.
그렇다면 개발자들이 로직에 집중한다면 누가 텍스트 표현을 관리할까요? DSPy가 이 역할을 맡아 여러분의 데이터와 평가 메트릭을 사용하여 텍스트 표현을 개선합니다—내러티브 초점 결정부터 힌트 최적화, 좋은 예시 선택까지 모든 것을 포함합니다. 놀랍게도 DSPy는 평가 메트릭을 사용하여 LLM 가중치도 미세 조정할 수 있습니다!
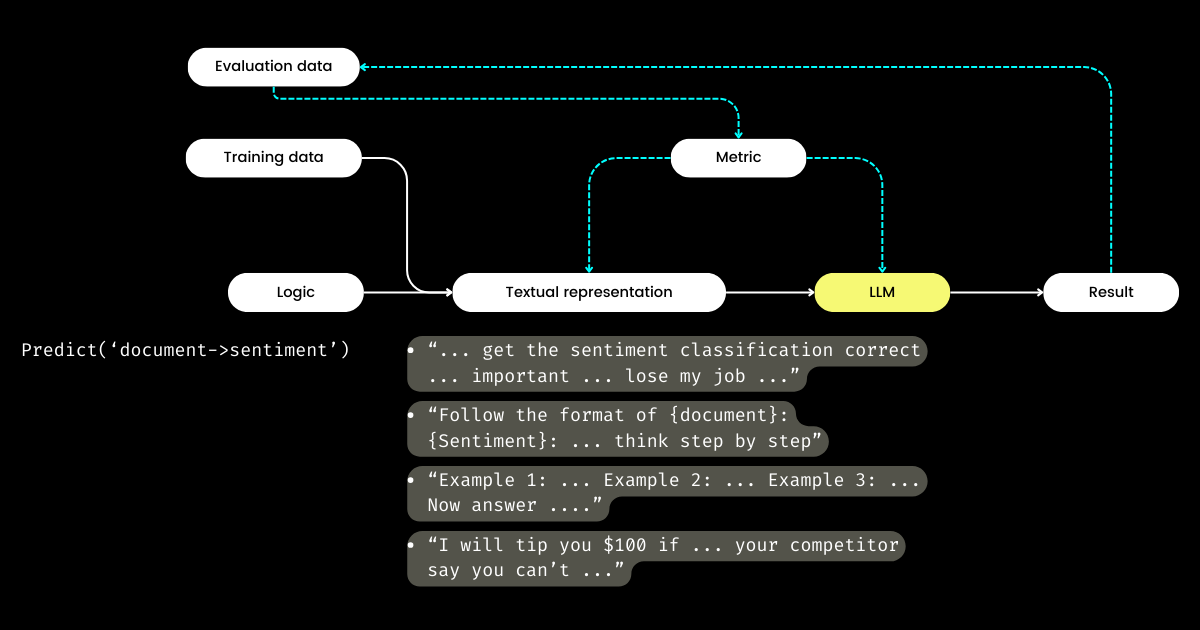
제게 DSPy의 주요 기여—프롬프트 엔지니어링에서 훈련과 평가의 순환 고리를 닫고 로직을 텍스트 표현에서 분리하는 것—는 LLM/Agent 시스템에 대한 잠재적 중요성을 강조합니다. 분명히 야심찬 비전이지만, 확실히 필요한 것입니다!
tagDSPy가 개선할 수 있다고 생각하는 점
첫째, DSPy는 관용구 때문에 초보자에게 가파른 학습 곡선을 제시합니다. signature, module, program, teleprompter, optimization, compile와 같은 용어들이 부담스러울 수 있습니다. 프롬프트 엔지니어링에 능숙한 사람들조차도 DSPy 내에서 이러한 개념들을 탐색하는 것이 어려운 미로가 될 수 있습니다.
이는 Jina 1.0에서 겪었던 경험과 유사합니다. 당시 우리는 chunk, document, driver, executor, pea, pod, querylang, flow와 같은 다양한 용어들을 도입했습니다(심지어 사용자들이 기억하기 쉽도록 귀여운 스티커도 만들었죠!).






이러한 초기 개념들 대부분은 이후 Jina 리팩토링에서 제거되었습니다. 오늘날에는 "대대적인 정리" 이후 Executor, Document, Flow만이 살아남았습니다. Jina 3.0에서 새로운 개념인 Deployment를 추가했으니 균형이 맞춰졌다고 할 수 있겠네요. 🤷
이 문제는 DSPy나 Jina에만 국한된 것이 아닙니다. TensorFlow의 0.x에서 1.x 버전으로 넘어가면서 도입된 수많은 개념과 추상화를 떠올려보세요. 이는 소프트웨어 프레임워크의 초기 단계에서 자주 발생하는 문제라고 생각합니다. 학술적 표기법을 최대한의 정확성과 재현성을 보장하기 위해 코드베이스에 직접 반영하려는 시도가 있기 때문입니다. 하지만 모든 사용자가 이러한 세부적인 추상화를 원하는 것은 아닙니다. 간단한 원라이너를 선호하는 사람부터 더 많은 유연성을 요구하는 사람까지 다양합니다. 소프트웨어 프레임워크의 추상화에 대한 이 주제는 2020년 블로그 포스트에서 자세히 다룬 바 있으니, 관심 있는 독자들은 참고하시기 바랍니다.


둘째로, DSPy의 문서는 일관성 측면에서 때때로 부족함을 보입니다. module과 program, teleprompter와 optimizer, 또는 optimize와 compile(때로는 training이나 bootstrapping으로도 언급됨)과 같은 용어들이 혼용되어 혼란을 가중시킵니다. 결과적으로 저는 DSPy를 처음 접했을 때 정확히 무엇을 optimize하는지, bootstrapping 과정이 무엇인지 이해하는 데 많은 시간을 보냈습니다.
이러한 어려움에도 불구하고, DSPy를 더 깊이 파고들고 문서를 다시 검토하다 보면 모든 것이 명확해지는 순간이 올 것입니다. DSPy만의 독특한 용어와 PyTorch와 같은 프레임워크에서 보던 친숙한 구조들 간의 연관성이 보이기 시작할 것입니다. 하지만 DSPy는 분명히 향후 버전에서 개선의 여지가 있습니다. 특히 PyTorch 배경이 없는 프롬프트 엔지니어들이 더 쉽게 접근할 수 있도록 만드는 것이 중요합니다.
tagDSPy 초보자들이 겪는 일반적인 어려움
아래 섹션에서는 제가 DSPy를 처음 시작할 때 막혔던 질문들을 모아보았습니다. 다른 학습자들이 비슷한 어려움을 겪을 때 도움이 되기를 바라면서 이러한 인사이트를 공유합니다.
tagteleprompter, optimization, compile이 무엇인가요? DSPy에서 정확히 무엇이 최적화되나요?
DSPy에서 "Teleprompters"는 optimizer입니다(그리고 @lateinteraction이 이를 명확히 하기 위해 문서와 코드를 개선하고 있는 것 같습니다). compile 함수는 이 optimizer의 핵심으로, optimizer.optimize()를 호출하는 것과 유사합니다. DSPy에서의 트레이닝이라고 생각하면 됩니다. 이 compile() 프로세스는 다음을 튜닝하는 것을 목표로 합니다:
- few-shot 데모
- instructions
- LLM의 가중치
하지만 대부분의 DSPy 초급 튜토리얼에서는 가중치와 instruction 튜닝까지 다루지 않습니다. 이는 다음 질문으로 이어집니다.
tagDSPy의 bootstrap은 무엇인가요?
Bootstrap은 few-shot in-context learning을 위한 자체 생성 데모를 만드는 것을 의미하며, 이는 compile() 프로세스(즉, 위에서 언급한 최적화/트레이닝)의 중요한 부분입니다. 이러한 few-shot 데모들은 사용자가 제공한 레이블된 데이터로부터 생성됩니다. 하나의 데모는 보통 입력, 출력, 근거(예: Chain of Thought에서), 그리고 중간 입력 및 출력(다단계 프롬프트용)으로 구성됩니다. 물론 질 좋은 few-shot 데모는 출력의 우수성을 위해 핵심입니다. 이를 위해 DSPy는 사용자 정의 메트릭 함수를 통해 특정 기준을 충족하는 데모만 선택되도록 합니다. 이는 다음 질문으로 이어집니다.
tagDSPy 메트릭 함수란 무엇인가요?
DSPy를 직접 사용해본 후, 저는 메트릭 함수가 현재 문서에서 다루는 것보다 훨씬 더 강조되어야 한다고 생각하게 되었습니다. DSPy의 메트릭 함수는 평가와 트레이닝 단계 모두에서 중요한 역할을 합니다. 암시적 특성(trace=None으로 제어됨) 덕분에 "손실" 함수로도 작동합니다:
def keywords_match_jaccard_metric(example, pred, trace=None):
# Jaccard similarity between example keywords and predicted keywords
A = set(normalize_text(example.keywords).split())
B = set(normalize_text(pred.keywords).split())
j = len(A & B) / len(A | B)
if trace is not None:
# act as a "loss" function
return j
return j > 0.8 # act as evaluation이 접근 방식은 전통적인 기계 학습과는 매우 다릅니다. 전통적인 방식에서는 손실 함수가 보통 연속적이고 미분 가능한 형태(예: hinge/MSE)이며, 평가 메트릭은 완전히 다르고 이산적(예: NDCG)일 수 있습니다. DSPy에서는 평가와 손실 함수가 메트릭 함수로 통합되어 있으며, 이는 이산적일 수 있고 대부분 부울 값을 반환합니다. 메트릭 함수는 LLM도 통합할 수 있습니다! 아래 예시에서는 LLM을 사용한 퍼지 매치를 구현하여 예측값과 정답이 크기 면에서 유사한지 판단합니다. 예를 들어 "1 million dollars"와 "$1M"은 true를 반환할 것입니다.
class Assess(dspy.Signature):
"""Assess the if the prediction is in the same magnitude to the gold answer."""
gold_answer = dspy.InputField(desc='number, could be in natural language')
prediction = dspy.InputField(desc='number, could be in natural language')
assessment = dspy.OutputField(desc='yes or no, focus on the number magnitude, not the unit or exact value or wording')
def same_magnitude_correct(example, pred, trace=None):
return dspy.Predict(Assess)(gold_answer=example.answer, prediction=pred.answer).assessment.lower() == 'yes'메트릭 함수는 강력하지만 최종 품질 평가뿐만 아니라 최적화 결과에도 영향을 미치며 DSPy 사용자 경험을 크게 좌우합니다. 잘 설계된 메트릭 함수는 최적화된 프롬프트로 이어질 수 있지만, 잘못 작성된 경우 최적화가 실패할 수 있습니다. DSPy로 새로운 문제를 해결할 때, 로직(즉, DSPy.Module)을 설계하는 데 쓰는 시간만큼 메트릭 함수에도 시간을 투자해야 할 수 있습니다. 이렇게 로직과 메트릭에 동시에 중점을 두는 것은 초보자들에게 부담이 될 수 있습니다.
tag"Bootstrapped 0 full traces after 20 examples in round 0"는 무슨 의미인가요?
compile() 중에 조용히 출력되는 이 메시지는 매우 중요한 의미를 담고 있습니다. 이는 본질적으로 최적화/컴파일이 실패했으며, 얻은 프롬프트가 단순한 few-shot보다 나아지지 않았다는 것을 의미합니다. 무엇이 잘못된 걸까요? 이런 메시지를 만났을 때 DSPy 프로그램을 디버깅하는 데 도움이 되는 몇 가지 팁을 정리했습니다:
메트릭 함수가 잘못되었을 때
BootstrapFewShot(metric=your_metric)에서 사용되는 your_metric 함수가 올바르게 구현되었나요? 단위 테스트를 수행해보세요. your_metric이 True를 반환하나요, 아니면 항상 False를 반환하나요? True를 반환하는 것이 중요한데, 이는 DSPy가 부트스트랩된 예제를 "성공"으로 간주하는 기준이기 때문입니다. 모든 평가를 True로 반환하면 모든 예제가 부트스트래핑에서 "성공"으로 간주됩니다! 물론 이상적이지는 않지만, 이는 메트릭 함수의 엄격성을 조정하여 "Bootstrapped 0 full traces" 결과를 변경하는 방법입니다. DSPy 문서에는 메트릭이 스칼라 값도 반환할 수 있다고 나와있지만, 기본 코드를 살펴본 결과 초보자에게는 권장하지 않습니다.
로직(DSPy.Module)이 잘못되었을 때
메트릭 함수가 올바르다면, dspy.Module 로직이 올바르게 구현되었는지 확인해야 합니다. 먼저, 각 단계에 대한 DSPy 시그니처가 올바르게 할당되었는지 확인하세요. dspy.Predict('question->answer')와 같은 인라인 시그니처는 사용하기 쉽지만, 품질을 위해서는 클래스 기반 시그니처를 구현하는 것을 강력히 권장합니다. 특히 클래스에 설명적인 문서 문자열을 추가하고, InputField와 OutputField의 desc 필드를 채우세요—이 모든 것이 LM에게 각 필드에 대한 힌트를 제공합니다. 아래에서는 페르미 문제를 해결하기 위한 두 개의 다단계 DSPy.Module을 구현했는데, 하나는 인라인 시그니처를 사용하고 다른 하나는 클래스 기반 시그니처를 사용합니다.
class FermiSolver(dspy.Module):
def __init__(self):
super().__init__()
self.step1 = dspy.Predict('question -> initial_guess')
self.step2 = dspy.Predict('question, initial_guess -> calculated_estimation')
self.step3 = dspy.Predict('question, initial_guess, calculated_estimation -> variables_and_formulae')
self.step4 = dspy.ReAct('question, initial_guess, calculated_estimation, variables_and_formulae -> gathering_data')
self.step5 = dspy.Predict('question, initial_guess, calculated_estimation, variables_and_formulae, gathering_data -> answer')
def forward(self, q):
step1 = self.step1(question=q)
step2 = self.step2(question=q, initial_guess=step1.initial_guess)
step3 = self.step3(question=q, initial_guess=step1.initial_guess, calculated_estimation=step2.calculated_estimation)
step4 = self.step4(question=q, initial_guess=step1.initial_guess, calculated_estimation=step2.calculated_estimation, variables_and_formulae=step3.variables_and_formulae)
step5 = self.step5(question=q, initial_guess=step1.initial_guess, calculated_estimation=step2.calculated_estimation, variables_and_formulae=step3.variables_and_formulae, gathering_data=step4.gathering_data)
return step5인라인 시그니처만 사용한 페르미 문제 해결기
class FermiStep1(dspy.Signature):
question = dspy.InputField(desc='Fermi problems involve the use of estimation and reasoning')
initial_guess = dspy.OutputField(desc='Have a guess – don't do any calculations yet')
class FermiStep2(FermiStep1):
initial_guess = dspy.InputField(desc='Have a guess – don't do any calculations yet')
calculated_estimation = dspy.OutputField(desc='List the information you'll need to solve the problem and make some estimations of the values')
class FermiStep3(FermiStep2):
calculated_estimation = dspy.InputField(desc='List the information you'll need to solve the problem and make some estimations of the values')
variables_and_formulae = dspy.OutputField(desc='Write a formula or procedure to solve your problem')
class FermiStep4(FermiStep3):
variables_and_formulae = dspy.InputField(desc='Write a formula or procedure to solve your problem')
gathering_data = dspy.OutputField(desc='Research, measure, collect data and use your formula. Find the smallest and greatest values possible')
class FermiStep5(FermiStep4):
gathering_data = dspy.InputField(desc='Research, measure, collect data and use your formula. Find the smallest and greatest values possible')
answer = dspy.OutputField(desc='the final answer, must be a numerical value')
class FermiSolver2(dspy.Module):
def __init__(self):
super().__init__()
self.step1 = dspy.Predict(FermiStep1)
self.step2 = dspy.Predict(FermiStep2)
self.step3 = dspy.Predict(FermiStep3)
self.step4 = dspy.Predict(FermiStep4)
self.step5 = dspy.Predict(FermiStep5)
def forward(self, q):
step1 = self.step1(question=q)
step2 = self.step2(question=q, initial_guess=step1.initial_guess)
step3 = self.step3(question=q, initial_guess=step1.initial_guess, calculated_estimation=step2.calculated_estimation)
step4 = self.step4(question=q, initial_guess=step1.initial_guess, calculated_estimation=step2.calculated_estimation, variables_and_formulae=step3.variables_and_formulae)
step5 = self.step5(question=q, initial_guess=step1.initial_guess, calculated_estimation=step2.calculated_estimation, variables_and_formulae=step3.variables_and_formulae, gathering_data=step4.gathering_data)
return step5각 필드에 대한 더 포괄적인 설명이 포함된 클래스 기반 시그니처를 사용한 페르미 문제 해결기
또한 def forward(self, ) 부분도 확인하세요. 다단계 모듈의 경우, 마지막 단계의 출력(또는 FermiSolver에서처럼 모든 출력)이 다음 단계의 입력으로 제대로 전달되는지 확인하세요.
문제가 너무 어려운 경우
메트릭과 모듈이 모두 올바른 것 같다면, 문제 자체가 너무 어렵고 구현한 로직으로는 해결하기에 충분하지 않을 수 있습니다. 따라서 DSPy는 주어진 로직과 메트릭 함수로는 어떤 데모도 부트스트랩하는 것이 불가능하다고 판단합니다. 이 시점에서 고려할 수 있는 몇 가지 옵션이 있습니다:
- 더 강력한 LM 사용. 예를 들어, 학생 LM으로
gpt-35-turbo-instruct대신gpt-4-turbo를 사용하거나, 교사로 더 강력한 LM을 사용하세요. 이는 종종 매우 효과적일 수 있습니다. 결국 더 강력한 모델은 프롬프트에 대한 이해도가 더 높습니다. - 로직 개선.
dspy.Module의 일부 단계를 더 복잡한 것으로 추가하거나 교체하세요. 예를 들어,Predict를ChainOfThoughtProgramOfThought로 교체하거나,Retrieval단계를 추가하세요. - 더 많은 학습 예제 추가. 20개의 예제가 충분하지 않다면, 100개를 목표로 하세요! 그러면 하나의 예제가 메트릭 검사를 통과하고
BootstrapFewShot에 의해 선택될 수 있습니다. - 문제 재구성. 종종 문제는 잘못된 방식으로 구성되었을 때 해결할 수 없게 됩니다. 하지만 다른 각도에서 바라보면 훨씬 더 쉽고 명확해질 수 있습니다.
실제로는 시행착오의 과정이 필요합니다. 예를 들어, 저는 특히 어려운 문제를 다뤘습니다: 두세 개의 키워드를 기반으로 Google Material Design 아이콘과 유사한 SVG 아이콘을 생성하는 것이었습니다. 처음에는 dspy.ChainOfThought('keywords -> svg')를 사용하는 단순한 DSPy.Module과 pHash 알고리즘과 유사하게 생성된 SVG와 실제 Material Design SVG 간의 시각적 유사도를 평가하는 메트릭 함수를 사용했습니다. 20개의 학습 예제로 시작했지만, 첫 번째 라운드 후에 "Bootstrapped 0 full traces after 20 examples in round 0"가 나왔고, 이는 최적화가 실패했음을 나타냅니다. 데이터셋을 100개로 늘리고, 모듈을 여러 단계로 수정하고, 메트릭 함수의 임계값을 조정한 결과, 결국 2개의 부트스트랩된 데모를 얻고 최적화된 프롬프트를 얻을 수 있었습니다.





