



새로운 정보 검색 기술의 발전을 따라가는 것도 중요하지만, 이미 비즈니스 가치를 입증하고 신뢰할 수 있는 구성 요소를 깨뜨리지 않는 것도 똑같이 중요합니다.
AI 기반 벡터 검색의 성장에도 불구하고, 대부분의 기업들은 여전히 BM25 알고리즘의 변형을 사용하는 전통적인 검색 기술에 의존하고 있습니다. 이는 신뢰할 수 있고 검증된 기술입니다. 완전히 새로운 시스템으로 전환하는 것은 큰 변화일 뿐만 아니라, 상당한 리소스와 운영의 전면적인 개편이 필요하기 때문에 현실적으로 어려운 경우가 많습니다. 또한, BM25는 Elasticsearch와 Solr 같은 널리 사용되는 검색 엔진 플랫폼에서 사용되는 어휘 검색 엔진의 핵심이며, 많은 사용 사례에서 이미 좋은 결과를 보여주고 있습니다.
따라서 많은 기업들은 AI 기반 검색이 사용자 만족도와 결과 품질을 크게 향상시킨다는 설득력 있는 증거에도 불구하고 신경망 검색으로의 완전한 전환을 주저하고 있습니다.
tag검색 방식에 구애받지 않는 신경망 재순위화
Reranker는 검색 시스템 환경에 혁신적인 추가 기능입니다. Elasticsearch와 같은 기존 검색 엔진의 가치를 높이기 위해 설계되었으며, 검색 품질을 개선하는 애드온처럼 작동하는 추가 계층으로 기능합니다. 어떤 검색 기술과 연결되어 있는지 알 필요 없이, 단순히 매치 리스트를 받아 더 나은 순서로 재정렬합니다.
Jina Reranker는 전통적인 검색 기술에 더 깊은 이해도를 추가합니다. BM25와 같은 알고리즘은 용어 빈도를 기반으로 문서를 검색하는 데는 좋지만, 사용자의 의도를 고려하여 검색된 텍스트의 의미를 평가하는 데는 어려움을 겪습니다. 이것이 AI가 뛰어난 부분입니다: Reranker는 사용자가 찾고자 하는 것에 더 잘 부합하는 결과를 만들어내는 데 도움을 줍니다.
따라서 AI 모델의 강력한 장점을 검색 프레임워크에 도입하고자 하는 기업에게 Jina Reranker를 추가하는 것은 현명한 선택이 될 수 있으며, 기존 검색 인프라를 교체하는 부담을 지지 않아도 됩니다. 이는 검색 결과를 단순히 수용 가능한 수준이 아닌, 더 관련성 있고 정확한 탁월한 수준으로 개선하는 것에 관한 것입니다.
tagJina Reranker를 선택하는 이유
재순위화 모델들 중에서 Jina Reranker 모델은 선두주자로서 성능 벤치마크에서 최신 점수를 기록하며 돋보입니다.

이 글에서는 e-commerce 플랫폼을 위한 추천 시스템을 구현하는 방법을 보여드리겠습니다. 먼저 BM25 검색기 자체의 성능을 분석한 다음, 검색 파이프라인에 Jina Reranker를 추가하여 결과가 어떻게 더 관련성 있고 효과적이 되는지 살펴보겠습니다.
tag기존 워크플로우에 Jina Reranker 추가하기:
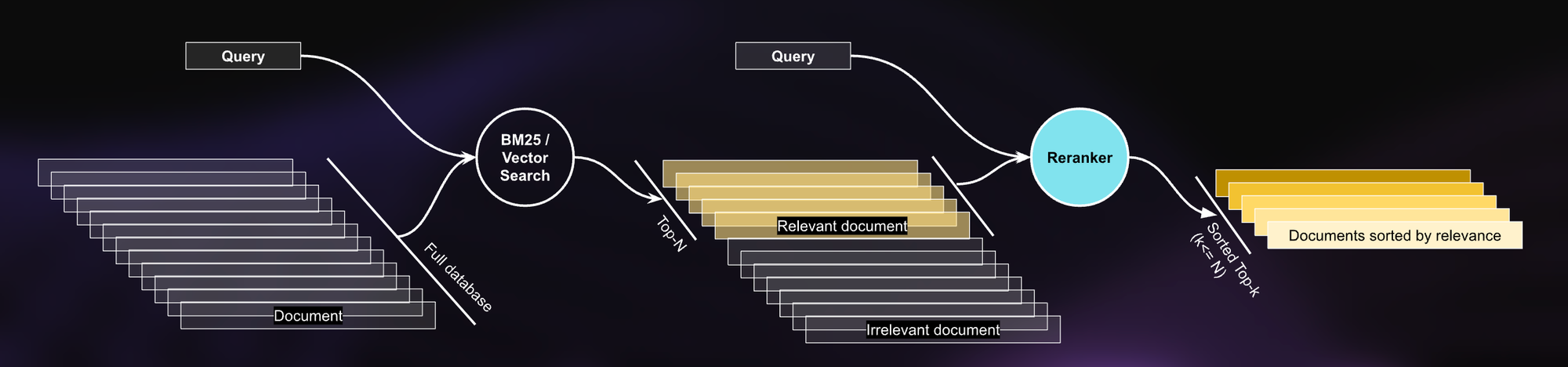
Jina Reranker를 통합한 업데이트된 워크플로우 내용입니다:
- 초기 검색: 쿼리가 입력되면 BM25 검색 엔진이 쿼리 용어와 문서를 매칭하여 관련 문서를 검색합니다.
- 재순위화: jina-reranker-v1-base-en이 이러한 초기 결과를 가져와 최신 AI를 사용하여 사용자의 쿼리에 비추어 각 검색된 문서의 관련성을 평가합니다.
- 결과 반환: Jina Reranker는 검색 결과의 순서를 재배열하여 가장 관련성 높은 문서가 상위에 표시되도록 합니다.
우리의 사용하기 쉬운 API와 포괄적인 문서는 시스템에 최소한의 변경만으로도 전체 프로세스를 안내해드립니다.

tag실제 작동 확인하기: Jina Reranker로 E-Commerce 검색 개선하기
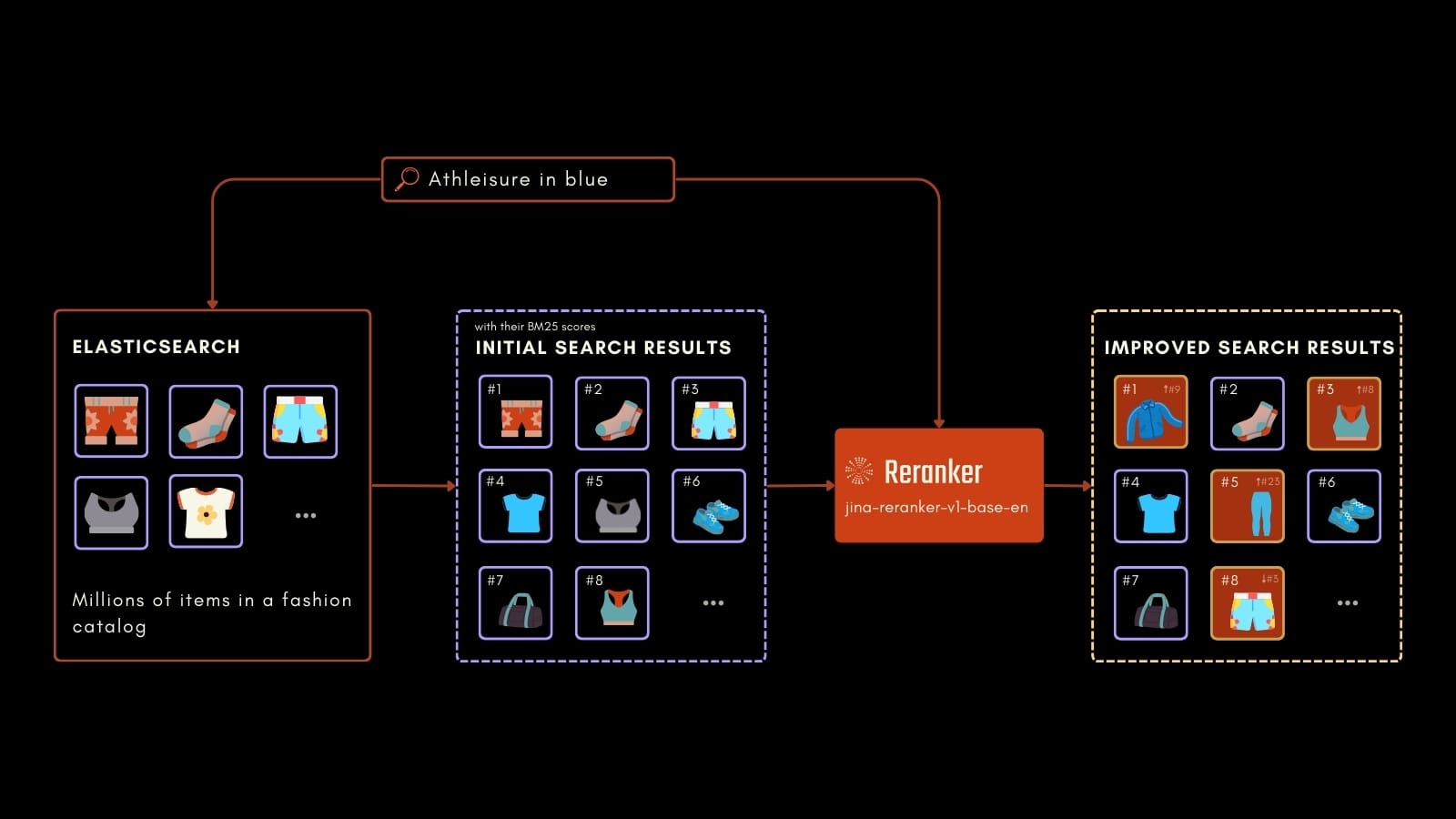
실제 애플리케이션에서 Jina Reranker의 영향을 보여주기 위해 실용적인 e-commerce 예제를 살펴보겠습니다. 여기서의 목표는 사용자의 쿼리를 기반으로 제품 목록을 검색하는 것입니다.
이를 설명하기 위해, 인기 있는 AI 검색 및 오케스트레이션 프레임워크인 deepset의 Haystack을 사용하여 두 개의 검색 파이프라인을 설정하겠습니다. 첫 번째 파이프라인은 BM25만 사용합니다. 두 번째는 BM25 시스템에 jina-reranker-v1-base-en을 통합합니다. 기존 Elasticsearch 클러스터가 있다면 Haystack의 InMemoryDocumentStore 구성 요소를 ElasticsearchDocumentStore로 쉽게 교체하여 동일한 실험을 수행할 수 있습니다.
Kaggle의 샘플 데이터셋을 사용할 것입니다. CSV를 여기서 직접 다운로드할 수 있습니다. 이 나란한 비교는 검색 워크플로우에 Jina Reranker를 통합함으로써 가져오는 향상을 보여줍니다.
시작하려면 필요한 모든 구성 요소를 설치하세요:
pip install --q haystack-ai jina-haystack
Jina API Key를 환경 변수로 설정하세요. 여기서 생성할 수 있습니다.
import os
import getpass
os.environ["JINA_API_KEY"] = getpass.getpass()
제품명을 기반으로 제품을 검색하세요. 예를 들어:
short_query = "Nightwear for Women"
각 CSV 행을 Document로 변환합니다:
import csv
from haystack import Document
documents = []
with open("fashion_data.csv") as f:
data = csv.reader(f, delimiter=";")
for row in data:
row_text = ''.join(row)
row_doc = Document(content=row_text, meta={"prod_id": row[0], "prod_image": row[1]})
documents.append(row_doc)
tag파이프라인 #1: BM25만 사용
from haystack import Pipeline
from haystack.document_stores.types import DuplicatePolicy
from haystack.document_stores.in_memory import InMemoryDocumentStore
from haystack.components.retrievers.in_memory import InMemoryBM25Retriever
document_store=InMemoryDocumentStore()
document_store.write_documents(documents=documents, policy=DuplicatePolicy.OVERWRITE)
retriever = InMemoryBM25Retriever(document_store=document_store)
rag_pipeline = Pipeline()
rag_pipeline.add_component("retriever", retriever)
result = rag_pipeline.run(
{
"retriever": {"query": query, "top_k": 50},
}
)
for doc in result["retriever"]["documents"]:
print("Product ID:", doc.meta["prod_id"])
print("Product Image:", doc.meta["prod_image"])
print("Score:", doc.score)
print("-"*100)
BM25가 반환한 50개 결과의 썸네일입니다:

결과가 잠옷과 관련되어 쿼리와 부분적으로 일치하는 것을 볼 수 있지만, 가장 관련성 높은 매칭(격자에서 굵게 표시된 이미지)이 BM25가 검색한 수많은 제품 사이에서 묻혀버리는 것 같습니다. 실제로 BM25만 사용하면 사용자는 페이지 상단에 주로 관련 없는 결과를 받게 됩니다.
tag파이프라인 #2: BM25 + Jina Reranker
아래 스크립트는 이 파이프라인을 단계별로 구성하는 방법을 보여줍니다:
from haystack_integrations.components.rankers.jina import JinaRanker
ranker_retriever = InMemoryBM25Retriever(document_store=document_store)
ranker = JinaRanker()
ranker_pipeline = Pipeline()
ranker_pipeline.add_component("ranker_retriever", ranker_retriever)
ranker_pipeline.add_component("ranker", ranker)
ranker_pipeline.connect("ranker_retriever.documents", "ranker.documents")
result = ranker_pipeline.run(
{
"ranker_retriever": {"query": query, "top_k": 50},
"ranker": {"query": query, "top_k": 10},
}
)
for doc in result["ranker"]["documents"]:
print("Product ID:", doc.meta["prod_id"])
print("Product Image:", doc.meta["prod_image"])
print("Score:", doc.score)
print("-"*100)
Jina Reranker가 반환한 상위 10개 결과입니다:

BM25와 비교하면, Jina Reranker는 훨씬 더 관련성 높은 답변 모음을 반환합니다. 이커머스 환경에서 이는 더 나은 사용자 경험과 구매 가능성 증가로 이어집니다.
tagBM25와 Jina Reranker 통합의 영향
이커머스 도메인에서의 사례 연구를 통해, Jina Reranker와 Elasticsearch 같은 전통적인 검색 엔진의 통합이 검색 기술에서 중요한 도약임이 분명해졌습니다. 이 통합이 검색 경험을 개선하는 방법을 살펴보겠습니다:
- 향상된 적중률: Jina Reranker와 전통적인 검색의 결합으로 관련 결과의 빈도가 눈에 띄게 증가했습니다. 이는 검색 프로세스를 더 정확하게 만들어 사용자 쿼리와 긴밀하게 연결됩니다.
- 개선된 사용자 경험: 검색 결과의 품질이 눈에 띄게 향상되었습니다. 이는 Jina Reranker와 BM25의 결합된 기능이 사용자의 특정 요구사항과 더 잘 부합하여 전반적인 검색 경험을 향상시킨다는 것을 보여줍니다.
- 복잡한 쿼리에 대한 높은 정확도: 어려운 검색의 경우, 이러한 시너지는 쿼리와 관련 콘텐츠에 대한 더 상세한 이해를 보장합니다. 이는 더 정확하고 선명한 결과로 이어집니다.
tag검색 경험을 향상시킬 준비가 되셨나요?
Jina Reranker는 검색 결과의 관련성을 높이기 위한 이상적인 솔루션입니다. 기존 검색 시스템과 원활하게 통합되며 최소한의 코딩으로 신속하게 구현할 수 있습니다.
지금까지 읽은 내용이 흥미롭고 Jina Reranker가 만들어낼 수 있는 차이를 직접 확인하고 싶으시다면 한번 시도해보세요. Jina AI의 Search Foundation 모델이 여러분의 환경에서 가져올 변혁적인 힘을 직접 경험해보세요.
