

독일 베를린 - 2023년 1월 15일 – Jina AI에서는 JFK의 상징적인 'Ich bin ein Berliner'를 떠올리며 우리만의 방식으로 언어를 연결하게 되어 기쁩니다. 오늘 우리는 최신 혁신인 jina-embeddings-v2-base-de, 독일어/영어 임베딩 모델을 발표하게 되어 자랑스럽습니다. 이 최첨단 이중 언어 모델은 8,192 토큰의 컨텍스트 길이를 자랑하며 언어 표현에서 큰 진전을 이루었습니다. 이 모델의 특별한 점은 비교 가능한 모델의 1/7 크기로도 최고 수준의 성능을 달성한다는 점입니다.
임베딩은 미국 시장 진출을 노리는 독일 기업들에게 매우 중요합니다. German American Business Outlook (GABO) 2022에 따르면, 독일 기업의 약 1/3이 글로벌 매출과 이익의 20% 이상을 미국에서 창출하고 있으며, 93%는 미국 매출 증가를 예상하고 있습니다. 이러한 추세는 계속되어 93%가 향후 3년간 미국 투자를 늘릴 계획이며, 85%는 순매출 성장을 예상하고 디지털 전환에 큰 중점을 두고 있습니다. 우수한 임베딩은 고객 선호도에 대한 이해를 높이고, 보다 효과적인 소통을 가능하게 하며, 문화적으로 적합한 제품을 포지셔닝함으로써 이러한 확장에 중요한 역할을 할 수 있습니다.
우리의 혁신은 영어권 국가에서 이중 언어 애플리케이션을 구현하고자 하는 독일 기업들에게 특히 유익합니다. jina-embeddings-v2-base-de와 함께 독일 기업들이 점점 더 연결되는 세상에서 어떻게 혁신하고 성장할지 기대됩니다.
tag모델 주요 특징
- 최첨단 성능: jina-embeddings-v2-base-de는 관련 벤치마크에서 지속적으로 상위권을 차지하며 비슷한 크기의 오픈소스 모델들 중 선두를 달리고 있습니다.
- 이중 언어 모델: 이 모델은 독일어와 영어 텍스트를 모두 인코딩하여 검색 애플리케이션에서 두 언어 중 어느 것이든 쿼리나 대상 문서로 사용할 수 있습니다. 두 언어로 된 동일한 의미의 텍스트는 같은 임베딩 공간에 매핑되어 다국어 애플리케이션의 기반이 됩니다.
- 확장된 컨텍스트: 8192 토큰 길이로 jina-embeddings-v2-base-de는 수백 토큰만 지원하는 모델들을 훨씬 뛰어넘어 더 긴 텍스트와 문서 조각을 지원할 수 있습니다.
- 컴팩트한 크기: jina-embeddings-v2-base-de는 표준 컴퓨터 하드웨어에서 높은 성능을 발휘하도록 설계되었습니다. 1억 6,100만 개의 파라미터만으로 전체 모델은 322MB이며 일반 컴퓨터의 메모리에 적합합니다. 임베딩 자체는 768차원으로, 많은 모델들에 비해 상대적으로 작은 벡터 크기를 가져 애플리케이션의 공간과 실행 시간을 절약합니다.
- 편향 최소화: 최근 연구에 따르면 특정 언어 훈련 없는 다국어 모델들은 임베딩에서 영어 문법 구조에 대한 강한 편향을 보입니다. 임베딩 모델은 의미를 포착하는 것이 중요하며 단순히 표면적으로 유사한 문장 쌍을 선호해서는 안 됩니다.
- 원활한 통합: Jina Embeddings v2 모델은 MongoDB, Qdrant, Weaviate를 포함한 주요 벡터 데이터베이스와 Haystack과 LlamaIndex와 같은 RAG 및 LLM 프레임워크와 기본적으로 통합됩니다.
tag독일어 NLP에서의 선도적 성능
우리는 jina-embeddings-v2-base-de를 독일어와 영어를 모두 지원하는 4개의 유명한 기준 모델과 비교 테스트했습니다. 이들은 다음과 같습니다:
- 마이크로소프트의 Multilingual-E5-large와 Multilingual-E5-base
- T-Systems의 Cross English & German RoBERTa for Sentence Embeddings
- Sentence-BERT (
distiluse-base-multilingual-cased-v2)
우리의 벤치마크에는 영어를 위한 MTEB 태스크와 자체 커스텀 벤치마크가 포함됩니다. 독일어 임베딩을 위한 포괄적인 벤치마크 스위트가 부족하여, 우리는 MTEB에서 영감을 받아 자체 벤치마크를 개발했습니다. 여기에서 우리의 발견과 혁신을 여러분과 공유하게 되어 자랑스럽습니다.
 jina-ai
jina-ai
tag컴팩트한 크기, 우수한 결과
jina-embeddings-v2-base-de는 특히 독일어 작업에서 탁월한 성능을 보여줍니다. E5 base 모델보다 크기가 1/3 미만임에도 더 나은 성능을 보이며, 7배 더 큰 E5 large 모델과 대등한 성능을 보여 그 효율성과 파워를 입증합니다. 이러한 효율성은 다른 인기 있는 이중 및 다국어 임베딩 모델들과 비교할 때 jina-embeddings-v2-base-de를 게임 체인저로 만듭니다.
tag독일어-영어 교차 언어 검색에서의 탁월한 성능
우리의 모델은 단순히 크기와 효율성에 관한 것이 아닙니다. 영어-독일어 교차 언어 검색 작업에서도 최고의 성능을 보입니다. 이는 다양한 주요 벤치마크에서 입증되었습니다:
- 영어에서 독일어 검색을 위한 WikiCLIR
- 영어에서 독일어 검색을 위한 MTEB 평가의 일부인 STS17
- 독일어에서 영어 검색을 위한 MTEB의 STS22
- MTEB에 포함된 독일어에서 영어 검색을 위한 BUCC
이러한 벤치마크, 특히 MTEB 평가 테스트(WikiCLIR 제외)에서의 성능은 jina-embeddings-v2-base-de가 복잡한 이중 언어 작업을 처리하는 데 얼마나 효과적인지를 보여줍니다.
tagAPI 액세스 받기
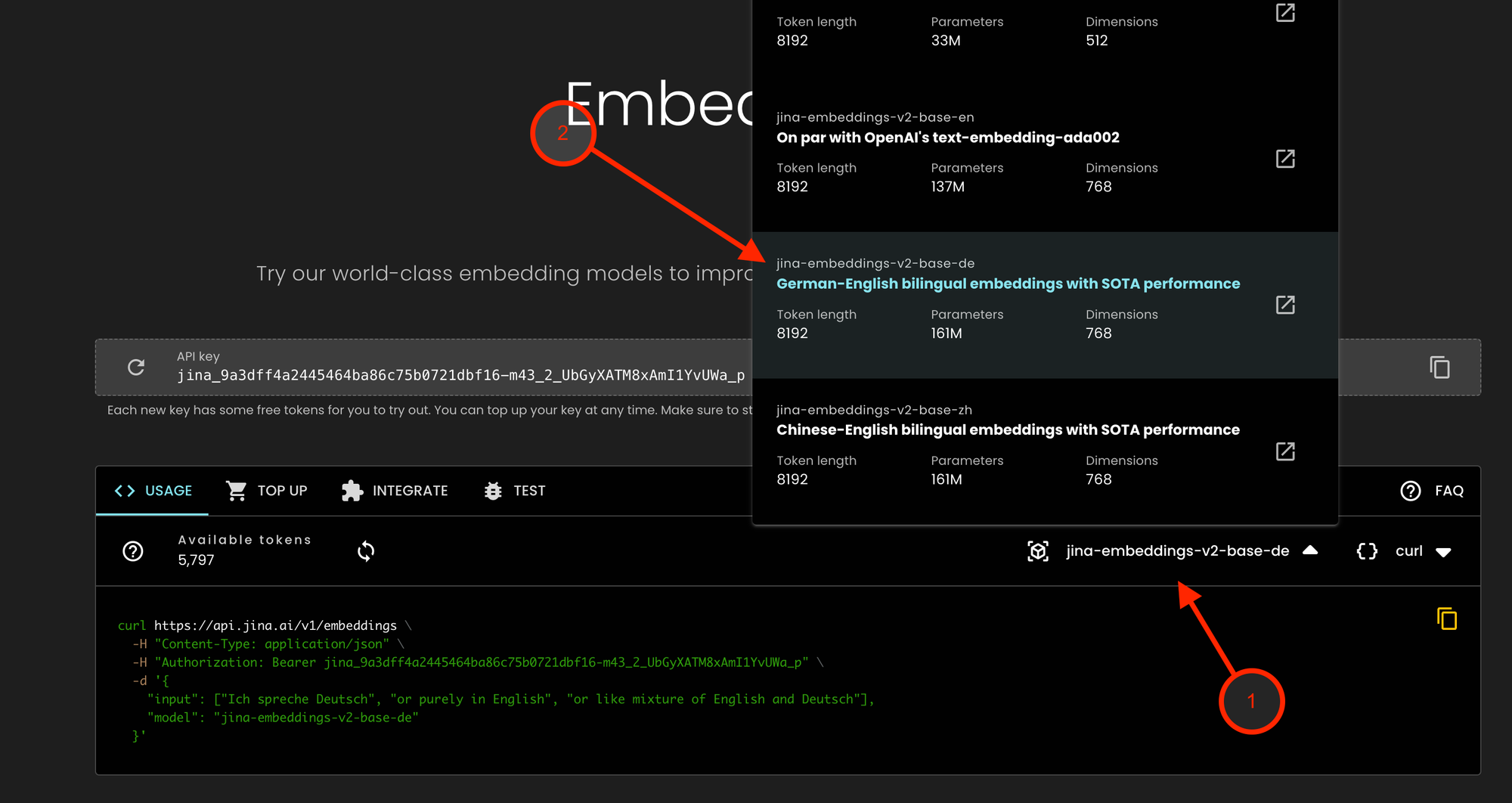
jina-embeddings-v2-base-de를 포함하여 프라이버시와 데이터 규정 준수를 중요시하는 기업 사용자를 위한 제품은 Jina Embeddings API를 통해 접근할 수 있습니다:
- Jina Embeddings API를 방문하여 모델 드롭다운을 클릭하세요
- jina-embeddings-v2-base-de를 선택하세요

곧 Amazon 클라우드 사용자를 위한 AWS Sagemaker 마켓플레이스와 HuggingFace에서 이 모델을 다운로드할 수 있게 될 것입니다.
tagJina 8K Embeddings: 다양한 AI 애플리케이션의 초석
임베딩은 정보 검색, 데이터 품질 관리, 분류, 추천 등 광범위한 AI 애플리케이션에 매우 중요합니다. 이는 수많은 AI 작업을 향상시키는 데 기본이 됩니다.
Jina AI는 프라이버시와 데이터 규정 준수를 중요시하는 모든 유형과 규모의 기업들이 핵심 AI 구성 요소를 투명하고 접근 가능하며 저렴하게 이용할 수 있도록 임베딩 기술의 최신 발전을 추구하고 있습니다. jina-embeddings-v2-base-de 외에도, Jina AI는 중국어를 위한 최첨단 임베딩 모델과 고성능 영어 단일어 모델을 출시했습니다. 이는 AI 기술을 더욱 포용적이고 전 세계적으로 적용 가능하게 만들고자 하는 우리의 사명의 일환입니다.
여러분의 피드백을 소중히 여깁니다. 우리의 커뮤니티 채널에 참여하여 피드백을 제공하고 우리의 발전 사항을 계속 확인하세요. 우리는 함께 더 강력하고 포용적인 AI의 미래를 만들어가고 있습니다.






