



개발자와 운영 엔지니어들은 쉽게 설정하고, 빠르게 시작하며, 나중에 추가적인 어려움 없이 확장된 프로덕션 환경에 효율적으로 배포할 수 있는 인프라를 높게 평가합니다. 이러한 이유로, 우리의 파트너 Milvus의 최신 경량 벡터 데이터베이스인 Milvus Lite는 Python 개발자들이 특히 고품질이고 사용하기 쉬운 검색 기반 모델과 함께 사용할 때 검색 애플리케이션을 빠르게 개발할 수 있는 중요한 도구입니다.
이 글에서는 가상의 회사 내부 공개 채널 채팅을 기반으로 구축된 Retrieval Augmented Generation (RAG) 애플리케이션의 예시를 통해 Milvus Lite가 Jina Embeddings v2와 Jina Reranker v1을 어떻게 통합하는지 설명하여, 직원들이 조직 관련 질문에 대한 정확하고 유용한 답변을 얻을 수 있도록 하겠습니다.
tagMilvus Lite, Jina Embeddings 및 Jina Reranker 개요
Milvus Lite는 선도적인 벡터 데이터베이스 Milvus의 새로운 경량 버전으로, 이제 Python 라이브러리로도 제공됩니다. Milvus Lite는 Docker나 Kubernetes에 배포된 Milvus와 동일한 API를 공유하지만 서버를 설정할 필요 없이 한 줄의 pip 명령으로 쉽게 설치할 수 있습니다.
Milvus의 Python SDK인 pymilvus에 Jina Embeddings v2와 Jina Reranker v1을 통합함으로써, 이제 Milvus Lite를 포함한 모든 Milvus 배포 모드에서 동일한 Python 클라이언트를 사용하여 문서를 직접 임베딩할 수 있는 옵션이 생겼습니다. Jina Embeddings와 Reranker 통합에 대한 자세한 내용은 pymilvus의 문서 페이지에서 찾을 수 있습니다.
8k-토큰 컨텍스트 윈도우와 다국어 기능을 갖춘 Jina Embeddings v2는 텍스트의 광범위한 의미를 인코딩하고 정확한 검색을 보장합니다. Jina Reranker v1을 파이프라인에 추가함으로써, 더 깊은 문맥적 이해를 위해 검색된 결과를 쿼리와 직접 크로스 인코딩하여 결과를 더욱 정제할 수 있습니다.
tag실전에서의 Milvus와 Jina AI 모델
이 튜토리얼은 실제 사용 사례에 초점을 맞출 것입니다: 회사의 Slack 채팅 기록을 쿼리하여 과거 대화를 기반으로 다양한 질문에 답변하는 것입니다.
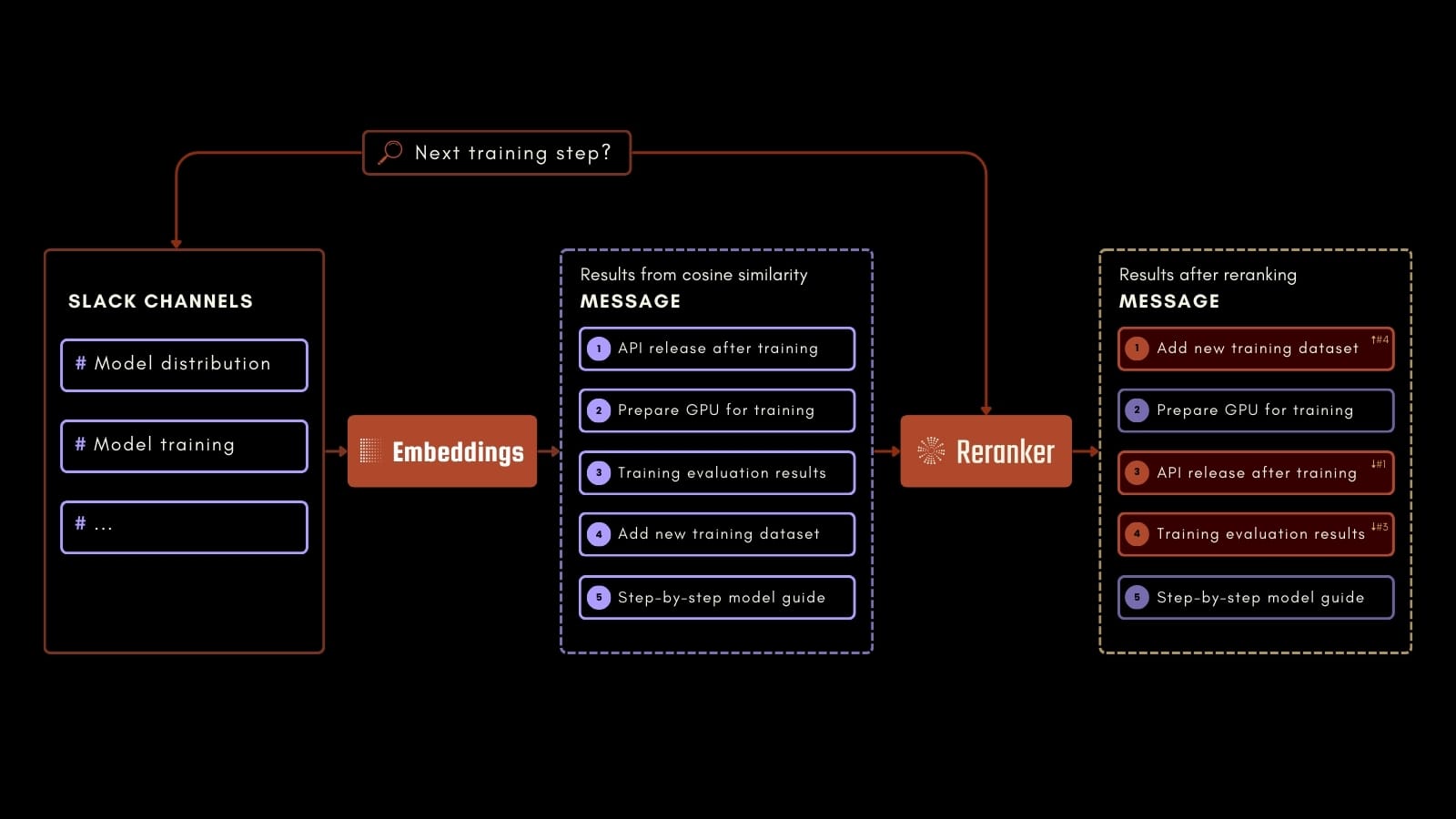
예를 들어, 직원이 위의 프로세스 스키마에서와 같이 AI 트레이닝의 다음 단계에 대해 물어볼 수 있습니다. Jina Embeddings, Jina Reranker, Milvus를 사용하여 기록된 Slack 메시지에서 관련 정보를 정확하게 식별할 수 있습니다. 이 애플리케이션은 과거 커뮤니케이션에서 가치 있는 정보에 쉽게 접근할 수 있게 함으로써 직장 생산성을 향상시킬 수 있습니다.
답변을 생성하기 위해, Langchain의 HuggingFace 통합을 통해 Mixtral 7B Instruct를 사용할 것입니다. 모델을 사용하려면 여기에 설명된 대로 생성할 수 있는 HuggingFace 액세스 토큰이 필요합니다.
Colab에서 따라하거나 노트북을 다운로드하여 진행할 수 있습니다.


tag데이터셋에 대하여
이 튜토리얼에서 사용된 데이터셋은 GPT-4를 사용하여 생성되었으며, Blueprint AI의 Slack 채널 채팅 기록을 재현하도록 설계되었습니다. Blueprint는 자체 기반 모델을 개발하는 가상의 AI 스타트업입니다. 데이터셋은 여기에서 다운로드할 수 있습니다.
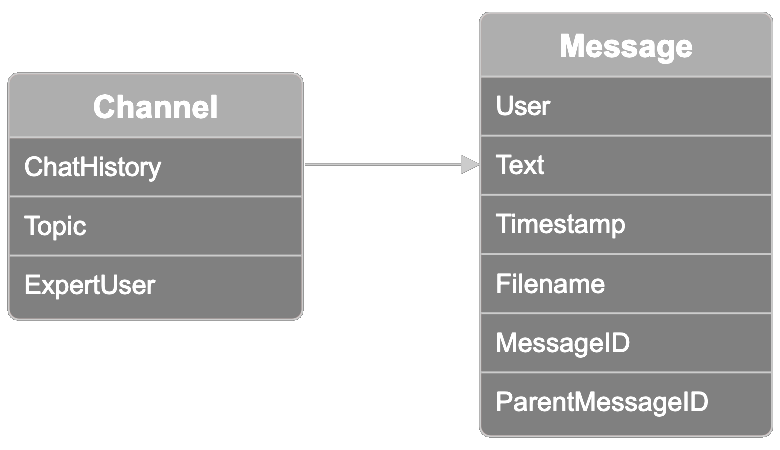
데이터는 관련된 Slack 스레드 모음을 나타내는 채널로 구성되어 있습니다. 각 채널에는 10가지 주제 옵션 중 하나의 주제 레이블이 있습니다: model distribution, model training, model fine-tuning, ethics and bias mitigation, user feedback, sales, marketing, model onboarding, creative design, product management. 한 참가자는 "전문가 사용자"로 알려져 있습니다. 이 필드를 사용하여 아래에서 보여드릴 주제의 가장 전문적인 사용자를 쿼리한 결과를 검증할 수 있습니다.
각 채널에는 채널당 최대 100개의 메시지를 포함하는 대화 스레드가 있는 채팅 기록이 포함되어 있습니다. 데이터셋의 각 메시지에는 다음 정보가 포함되어 있습니다:
- 메시지를 보낸 사용자
- 사용자가 보낸 메시지 텍스트
- 메시지의 타임스탬프
- 사용자가 메시지에 첨부했을 수 있는 파일 이름
- 메시지 ID
- 메시지가 다른 메시지에서 시작된 스레드 내에 있는 경우 부모 메시지 ID
tag환경 설정
먼저, 필요한 모든 구성 요소를 설치하세요:
pip install -U pymilvus
pip install -U "pymilvus[model]"
pip install langchain
pip install langchain-community
데이터셋을 다운로드하세요:
import os
if not os.path.exists("chat_history.json"):
!wget https://raw.githubusercontent.com/jina-ai/workshops/main/notebooks/embeddings/milvus/chat_history.json환경 변수에 Jina AI API Key를 설정하세요. 여기에서 생성할 수 있습니다.
import os
import getpass
os.environ["JINAAI_API_KEY"] = getpass.getpass(prompt="Jina AI API Key: ")Hugging Face Token도 동일하게 설정하세요. 여기에서 생성하는 방법을 확인할 수 있습니다. Hugging Face Hub에 접근하기 위해 READ로 설정되어 있는지 확인하세요.
os.environ["HUGGINGFACEHUB_API_TOKEN"] = getpass.getpass(prompt="Hugging Face Token: ")tagMilvus Collection 생성
데이터를 인덱싱하기 위한 Milvus Collection을 생성하세요:
from pymilvus import MilvusClient, DataType
# Specify a local file name as uri parameter of MilvusClient to use Milvus Lite
client = MilvusClient("milvus_jina.db")
schema = MilvusClient.create_schema(
auto_id=True,
enable_dynamic_field=True,
)
schema.add_field(field_name="id", datatype=DataType.INT64, description="The Primary Key", is_primary=True)
schema.add_field(field_name="embedding", datatype=DataType.FLOAT_VECTOR, description="The Embedding Vector", dim=768)
index_params = client.prepare_index_params()
index_params.add_index(field_name="embedding", metric_type="COSINE", index_type="AUTOINDEX")
client.create_collection(collection_name="milvus_jina", schema=schema, index_params=index_params)tag데이터 준비
채팅 기록을 파싱하고 메타데이터를 추출합니다:
import json
with open("chat_history.json", "r", encoding="utf-8") as file:
chat_data = json.load(file)
messages = []
metadatas = []
for channel in chat_data:
chat_history = channel["chat_history"]
chat_topic = channel["topic"]
chat_expert = channel["expert_user"]
for message in chat_history:
text = f"""{message["user"]}: {message["message"]}"""
messages.append(text)
meta = {
"time_stamp": message["time_stamp"],
"file_name": message["file_name"],
"parent_message_nr": message["parent_message_nr"],
"channel": chat_topic,
"expert": True if message["user"] == chat_expert else False
}
metadatas.append(meta)
tag채팅 데이터 임베딩
관련 채팅 정보를 검색하기 위해 Jina Embeddings v2를 사용하여 각 메시지의 임베딩을 생성합니다:
from pymilvus.model.dense import JinaEmbeddingFunction
jina_ef = JinaEmbeddingFunction("jina-embeddings-v2-base-en")
embeddings = jina_ef.encode_documents(messages)tag채팅 데이터 인덱싱
메시지, 임베딩 및 관련 메타데이터를 인덱싱합니다:
collection_data = [{
"message": message,
"embedding": embedding,
"metadata": metadata
} for message, embedding, metadata in zip(messages, embeddings, metadatas)]
data = client.insert(
collection_name="milvus_jina",
data=collection_data
)tag채팅 기록 쿼리
질문을 해봅시다:
query = "Who knows the most about encryption protocols in my team?"이제 쿼리를 임베딩하고 관련 메시지를 검색합니다. 여기서는 가장 관련성이 높은 5개의 메시지를 검색하고 Jina Reranker v1을 사용하여 순위를 재조정합니다:
from pymilvus.model.reranker import JinaRerankFunction
query_vectors = jina_ef.encode_queries([query])
results = client.search(
collection_name="milvus_jina",
data=query_vectors,
limit=5,
)
results = results[0]
ids = [results[i]["id"] for i in range(len(results))]
results = client.get(
collection_name="milvus_jina",
ids=ids,
output_fields=["id", "message", "metadata"]
)
jina_rf = JinaRerankFunction("jina-reranker-v1-base-en")
documents = [results[i]["message"] for i in range(len(results))]
reranked_documents = jina_rf(query, documents)
reranked_messages = []
for reranked_document in reranked_documents:
idx = reranked_document.index
reranked_messages.append(results[idx])마지막으로, Mixtral 7B Instruct를 사용하여 쿼리에 대한 답변을 생성하고 재순위가 매겨진 메시지를 컨텍스트로 사용합니다:
from langchain.prompts import PromptTemplate
from langchain_community.llms import HuggingFaceEndpoint
llm = HuggingFaceEndpoint(repo_id="mistralai/Mixtral-8x7B-Instruct-v0.1")
prompt = """<s>[INST] Context information is below.\\n
It includes the five most relevant messages to the query, sorted based on their relevance to the query.\\n
---------------------\\n
{context_str}\\\\n
---------------------\\n
Given the context information and not prior knowledge,
answer the query. Please be brief, concise, and complete.\\n
If the context information does not contain an answer to the query,
respond with \\"No information\\".\\n
Query: {query_str}[/INST] </s>"""
prompt = PromptTemplate(template=prompt, input_variables=["query_str", "context_str"])
llm_chain = prompt | llm
answer = llm_chain.invoke({"query_str":query, "context_str":reranked_messages})
print(f"\n\nANSWER:\n\n{answer}")우리의 질문에 대한 답변은:
"컨텍스트 정보를 바탕으로, User5가 팀에서 암호화 프로토콜에 대해 가장 잘 알고 있는 것 같습니다. 그들은 새로운 프로토콜이 특히 클라우드 배포에서 데이터 보안을 크게 향상시킨다고 언급했습니다."
chat_history.json의 메시지를 읽어보시면 User5가 가장 전문적인 사용자인지 직접 확인해볼 수 있습니다.
tag요약
우리는 Milvus Lite를 설정하고, Jina Embeddings v2를 사용하여 채팅 데이터를 임베딩하고, Jina Reranker v1로 검색 결과를 개선하는 방법을 Slack 채팅 기록 검색이라는 실용적인 사용 사례를 통해 살펴보았습니다. Milvus Lite는 복잡한 서버 설정 없이 Python 기반 애플리케이션 개발을 단순화합니다. Jina Embeddings 및 Reranker와의 통합은 직장에서 가치 있는 정보에 더 쉽게 접근할 수 있게 함으로써 생산성을 향상시키는 것을 목표로 합니다.
tag지금 Jina AI 모델과 Milvus 사용하기
Milvus Lite와 통합된 Jina Embeddings 및 Reranker는 몇 줄의 코드만으로 사용할 수 있는 완벽한 처리 파이프라인을 제공합니다.
여러분의 사용 사례에 대해 듣고 Jina AI Milvus 확장이 여러분의 비즈니스 요구 사항에 어떻게 부합하는지 이야기하고 싶습니다. 웹사이트나 Discord 채널을 통해 피드백을 공유하고 최신 모델에 대한 정보를 받아보세요. Milvus와 Jina AI의 통합에 대한 질문이 있으시다면 Milvus 커뮤니티에 참여하세요.
