



Jina CLIP v1(jina-clip-v1)은 OpenAI의 원본 CLIP 모델의 기능을 확장한 새로운 멀티모달 임베딩 모델입니다. 이 새로운 모델로 사용자는 텍스트 전용 및 텍스트-이미지 크로스모달 검색에서 최신 성능을 제공하는 단일 임베딩 모델을 사용할 수 있습니다. Jina AI는 OpenAI CLIP의 성능을 텍스트 전용 검색에서 165%, 이미지 대 이미지 검색에서 12% 향상시켰으며, 텍스트-이미지 및 이미지-텍스트 작업에서는 동일하거나 약간 더 나은 성능을 보여줍니다. 이러한 향상된 성능으로 Jina CLIP v1은 멀티모달 입력 작업에 필수적입니다.
이 글에서는 먼저 원본 CLIP 모델의 단점과 독특한 공동 훈련 방법을 통해 이를 해결한 방법에 대해 논의하겠습니다. 그런 다음 다양한 검색 벤치마크에서 우리 모델의 효과를 입증할 것입니다. 마지막으로 사용자가 Embeddings API와 Hugging Face를 통해 Jina CLIP v1을 시작하는 방법에 대한 자세한 지침을 제공합니다.
tag멀티모달 AI를 위한 CLIP 아키텍처
2021년 1월, OpenAI는 CLIP(Contrastive Language–Image Pretraining) 모델을 발표했습니다. CLIP은 단순하면서도 독창적인 아키텍처를 가지고 있습니다: 텍스트용과 이미지용, 두 개의 임베딩 모델을 단일 출력 임베딩 공간을 가진 하나의 모델로 결합합니다. 텍스트와 이미지 임베딩은 서로 직접 비교할 수 있어, 텍스트 임베딩과 이미지 임베딩 사이의 거리가 해당 텍스트가 이미지를 얼마나 잘 설명하는지, 또는 그 반대의 경우와 비례합니다.
이는 멀티모달 정보 검색과 제로샷 이미지 분류에서 매우 유용한 것으로 입증되었습니다. 추가적인 특별 훈련 없이도 CLIP은 자연어 레이블이 있는 카테고리에 이미지를 배치하는 데 잘 수행했습니다.

원본 CLIP의 텍스트 임베딩 모델은 단 6,300만 개의 매개변수를 가진 커스텀 신경망이었습니다. 이미지 측면에서 OpenAI는 ResNet과 ViT 모델의 선택지와 함께 CLIP을 출시했습니다. 각 모델은 개별 모달리티에 대해 사전 훈련되었고, 그 후 준비된 이미지-텍스트 쌍에 대해 유사한 임베딩을 생성하도록 캡션이 있는 이미지로 훈련되었습니다.
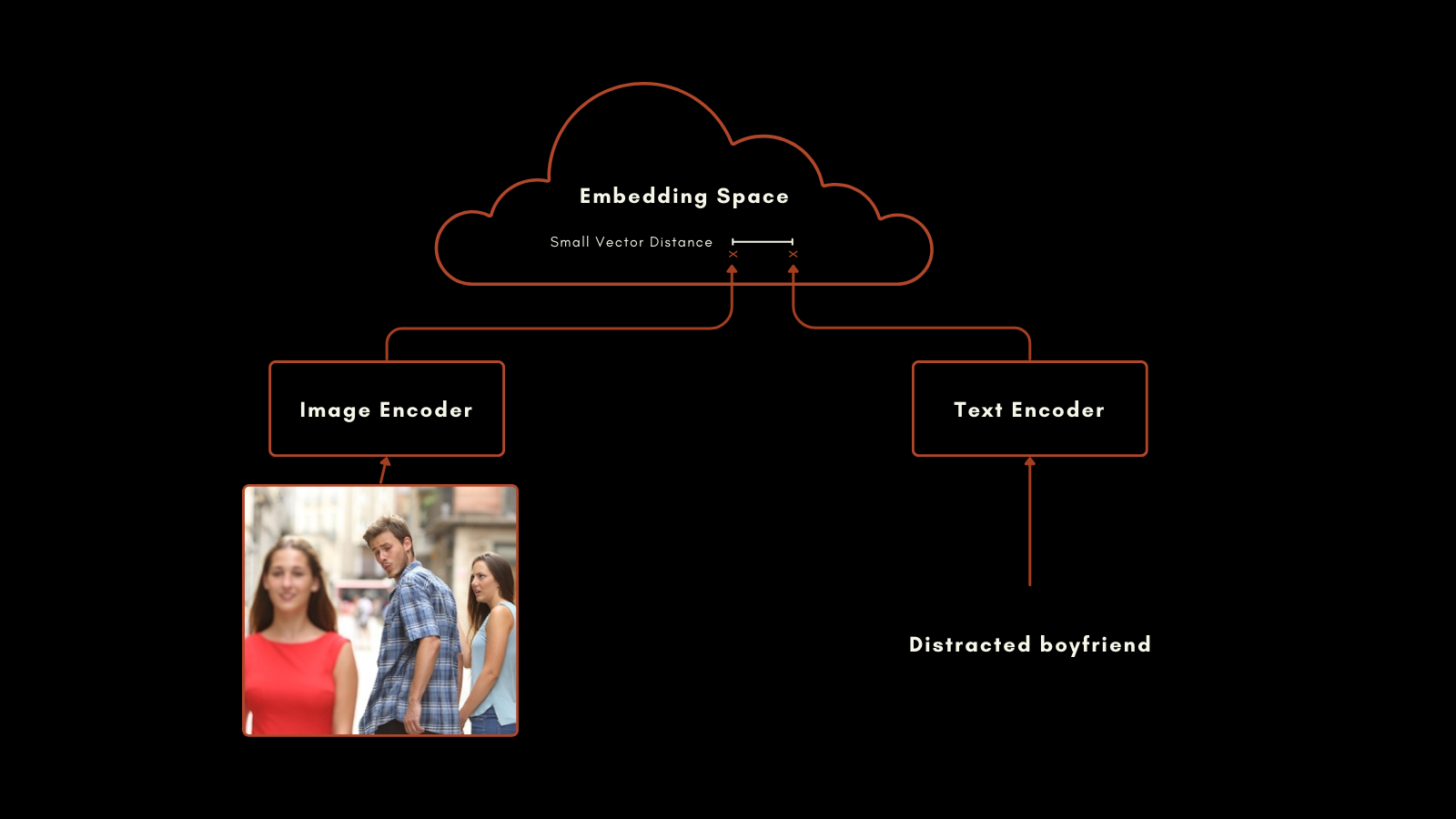
이 접근 방식은 인상적인 결과를 가져왔습니다. 특히 제로샷 분류 성능이 주목할 만합니다. 예를 들어, 훈련 데이터에 우주인의 레이블이 있는 이미지가 포함되어 있지 않았음에도 불구하고, CLIP은 텍스트와 이미지에서 관련 개념을 이해하여 우주인 사진을 정확하게 식별할 수 있었습니다.
그러나 OpenAI의 CLIP에는 두 가지 중요한 단점이 있습니다:
- 첫 번째는 매우 제한된 텍스트 입력 용량입니다. 최대 77개의 토큰 입력을 수용할 수 있지만, 실증적 분석에 따르면 실제로는 임베딩을 생성하는 데 20개 이상의 토큰을 사용하지 않습니다. 이는 CLIP이 이미지 캡션으로 훈련되었고, 캡션은 매우 짧은 경향이 있기 때문입니다. 이는 수천 개의 토큰을 지원하는 현재의 텍스트 임베딩 모델과는 대조적입니다.
- 두 번째로, 텍스트 전용 검색 시나리오에서 텍스트 임베딩의 성능이 매우 낮습니다. 이미지 캡션은 매우 제한된 종류의 텍스트이며, 텍스트 임베딩 모델이 지원해야 할 것으로 예상되는 광범위한 사용 사례를 반영하지 않습니다.
대부분의 실제 사용 사례에서는 텍스트 전용과 이미지-텍스트 검색이 결합되거나 적어도 작업에 모두 사용 가능합니다. 텍스트 전용 작업을 위해 두 번째 임베딩 모델을 유지하는 것은 AI 프레임워크의 크기와 복잡성을 사실상 두 배로 증가시킵니다.
Jina AI의 새로운 모델은 이러한 문제들을 직접적으로 해결하며, jina-clip-v1은 텍스트와 이미지 모달리티의 모든 조합을 포함하는 작업에서 최신 성능을 제공하기 위해 지난 몇 년간 이루어진 발전을 활용합니다.
tagJina CLIP v1 소개
Jina CLIP v1은 OpenAI의 원본 CLIP 스키마를 유지합니다: 동일한 임베딩 공간에서 출력을 생성하도록 공동 훈련된 두 개의 모델입니다.
텍스트 인코딩을 위해, 우리는 Jina BERT v2 아키텍처를 적용했는데, 이는 Jina Embeddings v2 모델에서 사용됩니다. 이 아키텍처는 최신의 8k 토큰 입력 윈도우를 지원하고 768차원 벡터를 출력하여, 더 긴 텍스트에서 더 정확한 임베딩을 생성합니다. 이는 원본 CLIP 모델에서 지원하는 77 토큰 입력의 100배 이상입니다.
이미지 임베딩의 경우, 우리는 베이징 인공지능 아카데미의 최신 모델인 EVA-02 모델을 사용하고 있습니다. 우리는 여러 이미지 AI 모델을 실증적으로 비교하여, 유사한 사전 훈련으로 크로스모달 컨텍스트에서 테스트했고, EVA-02가 다른 모델들을 명확하게 능가했습니다. 또한 모델 크기가 Jina BERT 아키텍처와 비슷하여, 이미지와 텍스트 처리 작업의 계산 부하가 대략적으로 동일합니다.
이러한 선택은 사용자에게 중요한 이점을 제공합니다:
- 모든 벤치마크와 모든 모달 조합에서 더 나은 성능을 보이며, 특히 텍스트 전용 임베딩 성능이 크게 향상되었습니다.
EVA-02의 이미지-텍스트 및 이미지 전용 작업에서의 실증적으로 우수한 성능에, Jina AI의 추가 훈련으로 이미지 전용 성능이 향상되는 이점이 더해졌습니다.- 더 긴 텍스트 입력을 지원합니다. Jina Embeddings의 8k 토큰 입력 지원으로 상세한 텍스트 정보를 처리하고 이미지와 상관관계를 분석할 수 있습니다.
- 이 멀티모달 모델이 비멀티모달 시나리오에서도 매우 높은 성능을 보이기 때문에 공간, 컴퓨팅, 코드 유지보수, 복잡성 측면에서 큰 순 절감 효과가 있습니다.
tag훈련
고성능 멀티모달 AI를 위한 우리의 방법 중 일부는 훈련 데이터와 절차입니다. 우리는 이미지 캡션에 사용된 매우 짧은 텍스트 길이가 CLIP 스타일 모델에서 낮은 텍스트 전용 성능의 주요 원인이라는 것을 발견했으며, 우리의 훈련은 이를 명시적으로 해결하도록 설계되었습니다.
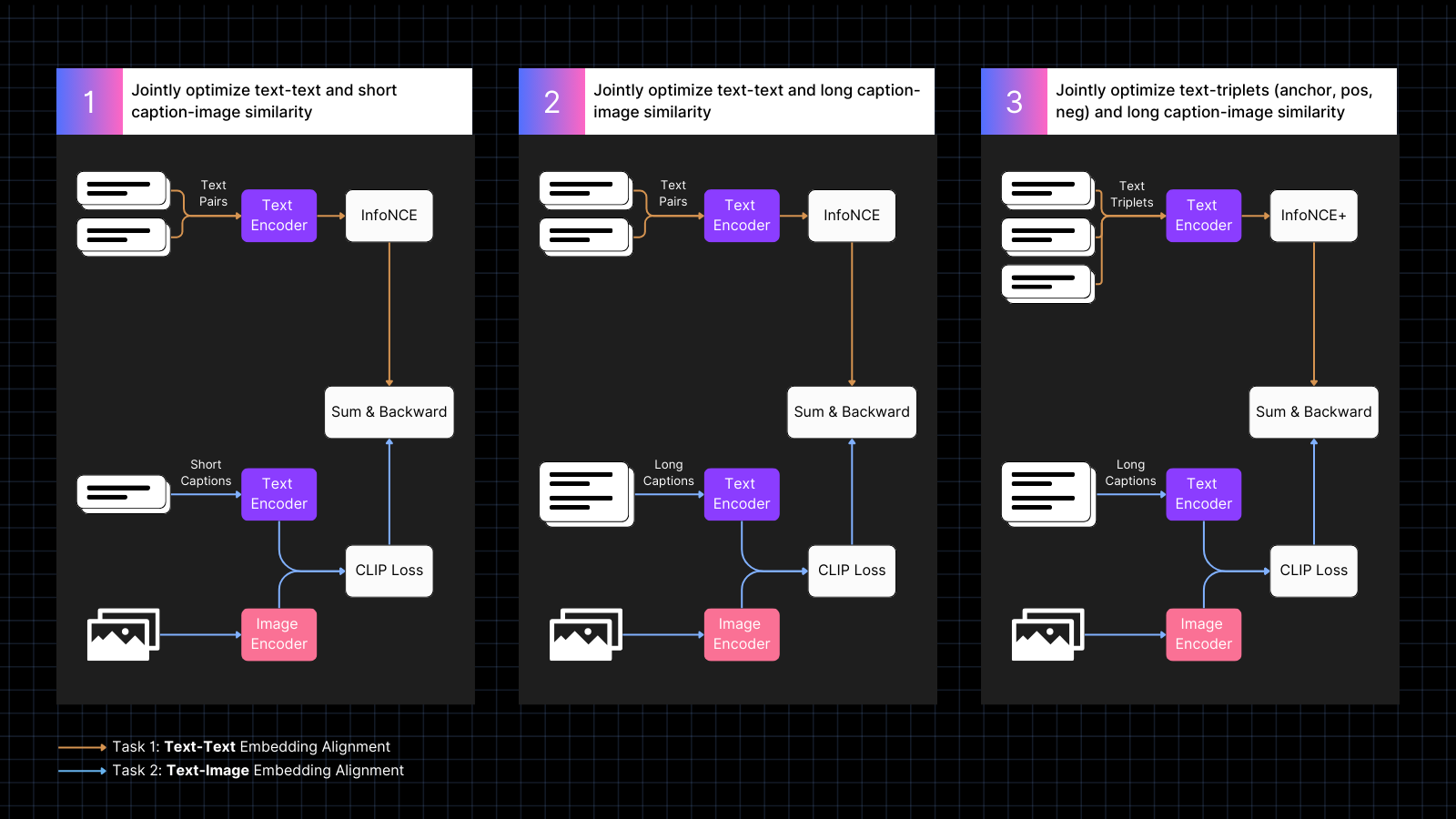
훈련은 세 단계로 진행됩니다:
- 캡션이 있는 이미지 데이터를 사용하여 이미지와 텍스트 임베딩을 정렬하는 것을 배우며, 유사한 의미를 가진 텍스트 쌍을 중간에 삽입합니다. 이 공동 훈련은 두 가지 유형의 작업을 동시에 최적화합니다. 이 단계에서 모델의 텍스트 전용 성능은 감소하지만, 이미지-텍스트 쌍만으로 훈련했을 때보다는 덜 감소합니다.
- AI 모델이 생성한 이미지를 더 큰 텍스트와 정렬하는 합성 데이터를 사용하여 훈련합니다. 동시에 텍스트 전용 쌍으로 훈련을 계속합니다. 이 단계에서 모델은 이미지와 함께 더 큰 텍스트에 주목하는 것을 배웁니다.
- 하드 네거티브가 있는 텍스트 트리플을 사용하여 더 미세한 의미적 구별을 학습함으로써 텍스트 전용 성능을 더욱 향상시킵니다. 동시에 이미지와 긴 텍스트의 합성 쌍을 사용한 훈련을 계속합니다. 이 단계에서는 모델이 이미지-텍스트 능력을 잃지 않으면서 텍스트 전용 성능이 극적으로 향상됩니다.
훈련과 모델 아키텍처의 자세한 내용은 우리의 최근 논문을 참조하세요:
tag멀티모달 임베딩의 새로운 최첨단 기술
우리는 Jina CLIP v1의 성능을 텍스트 전용, 이미지 전용, 그리고 두 입력 모달리티를 모두 포함하는 크로스 모달 작업에서 평가했습니다. 텍스트 전용 성능을 평가하기 위해 MTEB 검색 벤치마크를 사용했습니다. 이미지 전용 작업의 경우 CIFAR-100 벤치마크를 사용했습니다. 크로스 모델 작업의 경우 CLIP 벤치마크에 포함된 Flickr8k, Flickr30K, 그리고 MSCOCO Captions에서 평가했습니다.
결과는 아래 표에 요약되어 있습니다:
| Model | Text-Text | Text-to-Image | Image-to-Text | Image-Image |
|---|---|---|---|---|
| jina-clip-v1 | 0.429 | 0.899 | 0.803 | 0.916 |
| openai-clip-vit-b16 | 0.162 | 0.881 | 0.756 | 0.816 |
| % increase vs OpenAI CLIP |
165% | 2% | 6% | 12% |
이 결과에서 볼 수 있듯이 jina-clip-v1은 모든 카테고리에서 OpenAI의 기존 CLIP을 능가하며, 특히 텍스트 전용 및 이미지 전용 검색에서 현저히 우수한 성능을 보입니다. 모든 카테고리에서 평균 46%의 성능 향상을 보여줍니다.
더 자세한 평가는 최근 발표된 논문에서 확인할 수 있습니다.
tag임베딩 API 시작하기
Jina 임베딩 API를 사용하여 Jina CLIP v1을 애플리케이션에 쉽게 통합할 수 있습니다.
아래 코드는 Python의 requests 패키지를 사용하여 텍스트와 이미지의 임베딩을 얻기 위해 API를 호출하는 방법을 보여줍니다. 텍스트 문자열과 이미지 URL을 Jina AI 서버에 전달하여 두 인코딩을 반환받습니다.
<YOUR_JINA_AI_API_KEY>를 활성화된 Jina API 키로 교체하는 것을 잊지 마세요. Jina Embeddings 웹페이지에서 백만 개의 무료 토큰이 포함된 체험판 키를 받을 수 있습니다.import requests
import numpy as np
from numpy.linalg import norm
cos_sim = lambda a,b: (a @ b.T) / (norm(a)*norm(b))
url = 'https://api.jina.ai/v1/embeddings'
headers = {
'Content-Type': 'application/json',
'Authorization': 'Bearer <YOUR_JINA_AI_API_KEY>'
}
data = {
'input': [
{"text": "Bridge close-shot"},
{"url": "https://fastly.picsum.photos/id/84/1280/848.jpg?hmac=YFRYDI4UsfbeTzI8ZakNOR98wVU7a-9a2tGF542539s"}],
'model': 'jina-clip-v1',
'encoding_type': 'float'
}
response = requests.post(url, headers=headers, json=data)
sim = cos_sim(np.array(response.json()['data'][0]['embedding']), np.array(response.json()['data'][1]['embedding']))
print(f"Cosine text<->image: {sim}")
tag주요 LLM 프레임워크와의 통합
Jina CLIP v1은 이미 LlamaIndex와 LangChain에서 사용할 수 있습니다:
- LlamaIndex:
MultimodalEmbedding기본 클래스와 함께JinaEmbedding을 사용하고,get_image_embeddings또는get_text_embeddings를 호출하세요. - LangChain:
JinaEmbeddings를 사용하고,embed_images또는embed_documents를 호출하세요.
tag가격 책정
텍스트와 이미지 입력 모두 토큰 소비량으로 과금됩니다.
영어 텍스트의 경우, 경험적으로 계산한 결과 평균적으로 단어당 1.1개의 토큰이 필요합니다.
이미지의 경우, 이미지를 커버하는 데 필요한 224x224 픽셀 타일의 수를 계산합니다. 이러한 타일 중 일부는 부분적으로 비어 있을 수 있지만 동일하게 계산됩니다. 각 타일을 처리하는 데 1,000 토큰이 소요됩니다.
예시
750x500 픽셀 크기의 이미지의 경우:
- 이미지는 224x224 픽셀 타일로 나뉩니다.
- 타일 수를 계산하기 위해 픽셀 너비를 224로 나누고 가장 가까운 정수로 올림합니다.
750/224 ≈ 3.35 → 4 - 높이에 대해서도 반복:
500/224 ≈ 2.23 → 3
- 타일 수를 계산하기 위해 픽셀 너비를 224로 나누고 가장 가까운 정수로 올림합니다.
- 이 예시에서 필요한 총 타일 수는:
4 (가로) x 3 (세로) = 12 타일 - 비용은 12 x 1,000 = 12,000 토큰이 됩니다
tag기업 지원
110억 토큰이 포함된 프로덕션 배포 계획을 구매하는 사용자를 위한 새로운 혜택을 도입합니다. 여기에는 다음이 포함됩니다:
- 귀사의 특정 사용 사례와 요구사항을 논의하기 위한 제품 및 엔지니어링 팀과의 3시간 상담.
- Jina AI의 모델을 애플리케이션에 통합하는 방법을 보여주는, RAG(Retrieval-Augmented Generation) 또는 벡터 검색 사용 사례에 맞춤화된 Python 노트북.
- 귀사의 요구사항을 신속하고 효율적으로 충족시키기 위한 전담 계정 관리자 배정 및 우선순위 이메일 지원.
tagHugging Face의 오픈소스 Jina CLIP v1
Jina AI는 오픈소스 검색 기반에 전념하고 있으며, 이를 위해 이 모델을 Apache 2.0 라이선스 하에 Hugging Face에서 무료로 제공하고 있습니다.
자체 시스템이나 클라우드 설치에서 이 모델을 다운로드하고 실행하는 예제 코드는 jina-clip-v1의 Hugging Face 모델 페이지에서 찾을 수 있습니다.

tag요약
Jina AI의 최신 모델인 jina-clip-v1은 OpenAI의 CLIP보다 상당한 성능 향상을 제공하는 멀티모달 임베딩 모델의 중요한 진보를 나타냅니다. 텍스트 전용 및 이미지 전용 검색 작업에서 현저한 개선과 함께 텍스트-이미지 및 이미지-텍스트 작업에서 경쟁력 있는 성능을 보여주며, 복잡한 임베딩 사용 사례를 위한 유망한 솔루션으로 자리잡고 있습니다.
현재 리소스 제약으로 인해 이 모델은 영어 텍스트만 지원합니다. 더 많은 언어를 지원할 수 있도록 기능을 확장하기 위해 노력하고 있습니다.
