



오늘 우리는 5억 7천만 개의 매개변수를 가진 획기적인 텍스트 임베딩 모델인 jina-embeddings-v3를 발표하게 되어 기쁩니다. 이 모델은 **다국어** 데이터와 **긴 문맥** 검색 작업에서 최고 수준의 성능을 달성하며, 최대 8192 토큰의 입력 길이를 지원합니다. 이 모델은 작업별 Low-Rank Adaptation (LoRA) 어댑터를 특징으로 하여 **쿼리-문서 검색**, **클러스터링**, **분류**, **텍스트 매칭**과 같은 다양한 작업을 위한 고품질 임베딩을 생성할 수 있습니다.
MTEB 영어, 다국어 및 LongEmbed 평가에서 jina-embeddings-v3는 영어 작업에서 OpenAI와 Cohere의 최신 독점 임베딩을 능가하며, 모든 다국어 작업에서 multilingual-e5-large-instruct를 뛰어넘었습니다. 기본 출력 차원이 1024인 이 모델은 Matryoshka Representation Learning (MRL) 통합 덕분에 성능 저하 없이 임베딩 차원을 32까지 임의로 줄일 수 있습니다.


jina-embeddings-v2-(zh/es/de)는 우리의 이중언어 모델 스위트를 지칭하며, 중국어, 스페인어, 독일어의 단일 언어 및 교차 언어 작업에서만 테스트되었고 다른 모든 언어는 제외되었음을 참고해 주시기 바랍니다. 또한, openai-text-embedding-3-large와 cohere-embed-multilingual-v3.0의 점수는 전체 다국어 및 교차 언어 MTEB 작업에서 평가되지 않았기 때문에 보고하지 않습니다.
baai-bge-m3에서 사용된 고정 위치 임베딩과 jina-embeddings-v2에서 사용된 ALiBi 기반 접근 방식을 모두 능가합니다.2024년 9월 18일 출시 기준으로, jina-embeddings-v3는 **최고의** 다국어 모델이며 10억 개 미만의 매개변수를 가진 모델 중 MTEB 영어 리더보드에서 **2위**를 차지했습니다. v3는 총 89개 언어를 지원하며, 그 중 30개 언어에서 최고의 성능을 보입니다: 아랍어, 벵골어, 중국어, 덴마크어, 네덜란드어, 영어, 핀란드어, 프랑스어, 조지아어, 독일어, 그리스어, 힌디어, 인도네시아어, 이탈리아어, 일본어, 한국어, 라트비아어, 노르웨이어, 폴란드어, 포르투갈어, 루마니아어, 러시아어, 슬로바키아어, 스페인어, 스웨덴어, 태국어, 터키어, 우크라이나어, 우르두어, 베트남어.

jina-embeddings-v2에 비해 초선형적 개선을 보여주는 것을 확인할 수 있습니다. 이 그래프는 MTEB 리더보드에서 상위 100개 임베딩 모델을 선택하여 작성되었으며, 크기 정보가 없는 모델(일반적으로 폐쇄 소스 또는 독점 모델)은 제외되었습니다. 명백한 트롤링으로 확인된 제출물도 필터링되었습니다.또한, e5-mistral-7b-instruct와 같이 최근 주목받고 있는 LLM 기반 임베딩과 비교했을 때, jina-embeddings-v3는 훨씬 더 비용 효율적인 솔루션입니다. e5-mistral-7b-instruct는 71억 개의 매개변수(12배 더 큼)와 4096의 출력 차원(4배 더 큼)을 가지고 있지만 MTEB 영어 작업에서 단 1%의 개선만을 제공하여, 프로덕션과 엣지 컴퓨팅에 더 적합합니다.
tag모델 아키텍처
| 특징 | 설명 |
|---|---|
| 기반 | jina-XLM-RoBERTa |
| 기본 매개변수 | 559M |
| LoRA 포함 매개변수 | 572M |
| 최대 입력 토큰 | 8192 |
| 최대 출력 차원 | 1024 |
| 레이어 | 24 |
| 어휘 | 250K |
| 지원 언어 | 89 |
| 어텐션 | FlashAttention2, 없이도 작동 |
| 풀링 | Mean pooling |
jina-embeddings-v3의 아키텍처는 아래 그림과 같습니다. 백본 아키텍처를 구현하기 위해 우리는 XLM-RoBERTa 모델을 다음과 같은 주요 수정사항과 함께 채택했습니다: (1) 긴 텍스트 시퀀스의 효과적인 인코딩 가능, (2) 태스크별 임베딩 인코딩 허용, (3) 최신 기술로 전반적인 모델 효율성 개선. 우리는 기존 XLM-RoBERTa 토크나이저를 계속 사용합니다. jina-embeddings-v3는 5억 7천만 개의 매개변수로 1억 3천 7백만 개의 매개변수를 가진 jina-embeddings-v2보다 크지만, 여전히 LLM에서 미세 조정된 임베딩 모델들보다는 훨씬 작습니다.

jina-XLM-RoBERTa 모델을 기반으로 하며, 4가지 다른 태스크를 위한 5개의 LoRA 어댑터를 포함합니다.jina-embeddings-v3의 핵심 혁신은 LoRA 어댑터의 사용입니다. 4가지 태스크를 최적화하기 위해 5개의 태스크별 LoRA 어댑터가 도입되었습니다. 모델의 입력은 텍스트(임베딩될 긴 문서)와 태스크 두 부분으로 구성됩니다. jina-embeddings-v3는 4가지 태스크를 지원하며 5개의 어댑터를 구현합니다: 비대칭 검색 태스크에서의 쿼리와 문서 임베딩을 위한 retrieval.query와 retrieval.passage, 클러스터링 태스크를 위한 separation, 분류 태스크를 위한 classification, STS나 대칭 검색과 같은 의미적 유사도 태스크를 위한 text-matching. LoRA 어댑터는 전체 매개변수의 3% 미만을 차지하여 계산에 매우 미미한 오버헤드만 추가합니다.
성능을 더욱 향상시키고 메모리 소비를 줄이기 위해, 우리는 FlashAttention 2를 통합하고, 활성화 체크포인팅을 지원하며, 효율적인 분산 학습을 위해 DeepSpeed 프레임워크를 사용합니다.
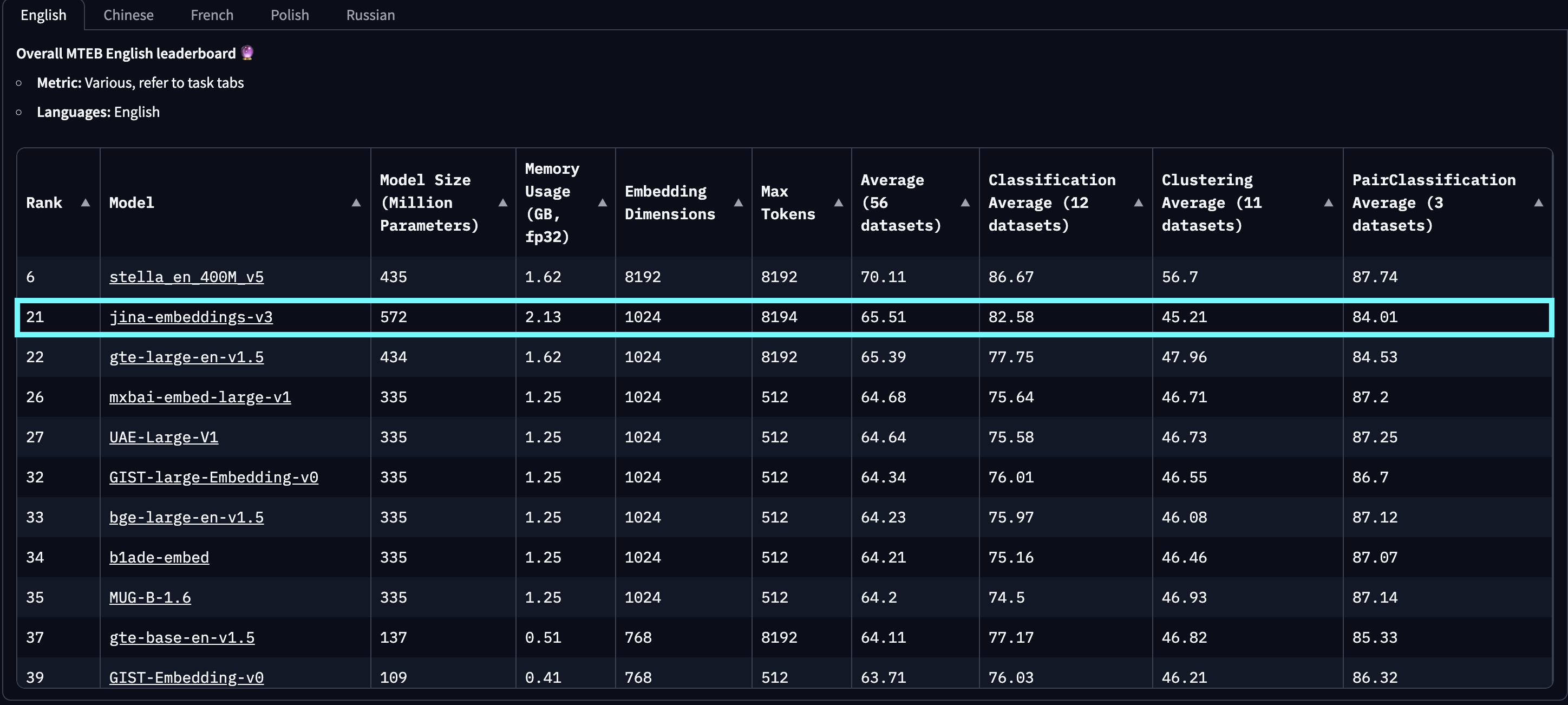
tag시작하기
tagJina AI Search Foundation API를 통해
jina-embeddings-v3를 사용하는 가장 쉬운 방법은 Jina AI 홈페이지를 방문하여 Search Foundation API 섹션으로 이동하는 것입니다. 오늘부터 이 모델은 모든 새로운 사용자를 위한 기본값으로 설정됩니다. 거기에서 직접 다양한 매개변수와 기능을 탐색할 수 있습니다.
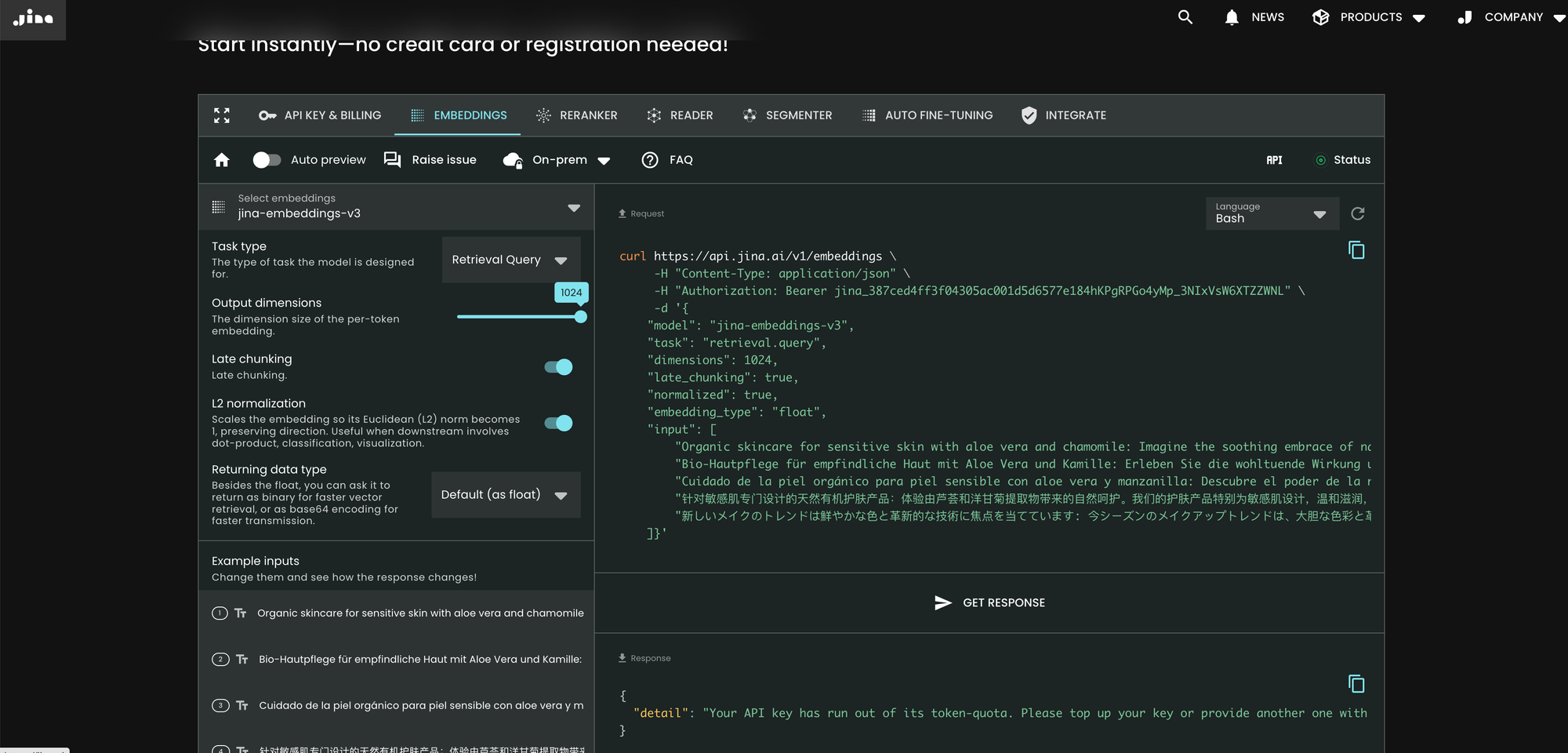
curl https://api.jina.ai/v1/embeddings \
-H "Content-Type: application/json" \
-H "Authorization: Bearer jina_387ced4ff3f04305ac001d5d6577e184hKPgRPGo4yMp_3NIxVsW6XTZZWNL" \
-d '{
"model": "jina-embeddings-v3",
"task": "text-matching",
"dimensions": 1024,
"late_chunking": true,
"input": [
"Organic skincare for sensitive skin with aloe vera and chamomile: ...",
"Bio-Hautpflege für empfindliche Haut mit Aloe Vera und Kamille: Erleben Sie die wohltuende Wirkung...",
"Cuidado de la piel orgánico para piel sensible con aloe vera y manzanilla: Descubre el poder ...",
"针对敏感肌专门设计的天然有机护肤产品:体验由芦荟和洋甘菊提取物带来的自然呵护。我们的护肤产品特别为敏感肌设计,...",
"新しいメイクのトレンドは鮮やかな色と革新的な技術に焦点を当てています: 今シーズンのメイクアップトレンドは、大胆な色彩と革新的な技術に注目しています。..."
]}'v2와 비교하여 v3는 API에서 task, dimensions, late_chunking이라는 세 가지 새로운 매개변수를 도입했습니다.
매개변수 task
task 매개변수는 중요하며 다운스트림 태스크에 따라 설정되어야 합니다. 결과적인 임베딩은 해당 특정 태스크에 최적화될 것입니다. 자세한 내용은 아래 목록을 참조하세요.
task 값 |
태스크 설명 |
|---|---|
retrieval.passage |
쿼리-문서 검색 태스크에서 문서 임베딩 |
retrieval.query |
쿼리-문서 검색 태스크에서 쿼리 임베딩 |
separation |
문서 클러스터링, 코퍼스 시각화 |
classification |
텍스트 분류 |
text-matching |
(기본값) 의미적 텍스트 유사도, 일반 대칭 검색, 추천, 유사 항목 찾기, 중복 제거 |
API는 먼저 일반적인 메타 임베딩을 생성한 다음 추가적인 미세 조정된 MLP로 조정하는 것이 아닙니다. 대신, 태스크별 LoRA 어댑터를 모든 트랜스포머 레이어(총 24개 레이어)에 삽입하고 한 번에 인코딩을 수행합니다. 자세한 내용은 우리의 arXiv 논문에서 확인할 수 있습니다.
매개변수 dimensions
dimensions 매개변수를 통해 사용자는 최저 비용으로 공간 효율성과 성능 사이의 균형을 선택할 수 있습니다. jina-embeddings-v3에서 사용된 MRL 기술 덕분에 임베딩의 차원을 원하는 만큼(심지어 단일 차원까지도!) 줄일 수 있습니다. 작은 임베딩은 벡터 데이터베이스에 더 저장 친화적이며, 그 성능 비용은 아래 그림에서 추정할 수 있습니다.

매개변수 late_chunking
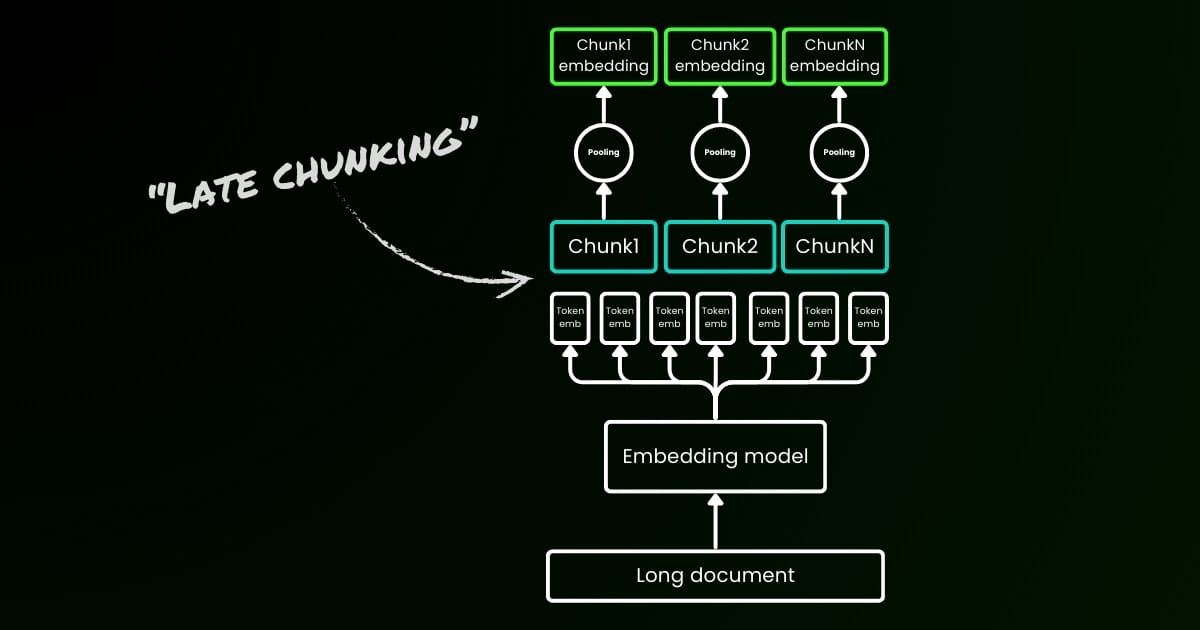
마지막으로, late_chunking 매개변수는 지난달 우리가 소개한 새로운 청킹 방법을 문장 배치를 인코딩하는 데 사용할지 여부를 제어합니다. true로 설정하면, 우리의 API는 input 필드의 모든 문장을 연결하여 단일 문자열로 모델에 공급합니다. 다시 말해, 입력의 문장들을 마치 동일한 섹션, 단락 또는 문서에서 원래 나온 것처럼 취급합니다. 내부적으로, 모델은 이 긴 연결된 문자열을 임베딩하고 나중에 청킹을 수행하여 입력 리스트의 크기와 일치하는 임베딩 리스트를 반환합니다. 따라서 리스트의 각 임베딩은 이전 임베딩들의 조건부가 됩니다.
사용자 관점에서, late_chunking을 설정하는 것은 입력이나 출력 형식을 변경하지 않습니다. 임베딩 값의 변화만 볼 수 있는데, 이는 이제 독립적으로가 아닌 전체 이전 컨텍스트를 기반으로 계산되기 때문입니다. late_chunking 사용 시 알아야 할 중요한 점은late_chunking=True에서는 input의 모든 토큰을 합한 총 토큰 수가 jina-embeddings-v3에서 허용되는 최대 컨텍스트 길이인 8192로 제한됩니다. late_chunking=False일 때는 이러한 제한이 없으며, 총 토큰 수는 Embedding API의 비율 제한에만 영향을 받습니다.
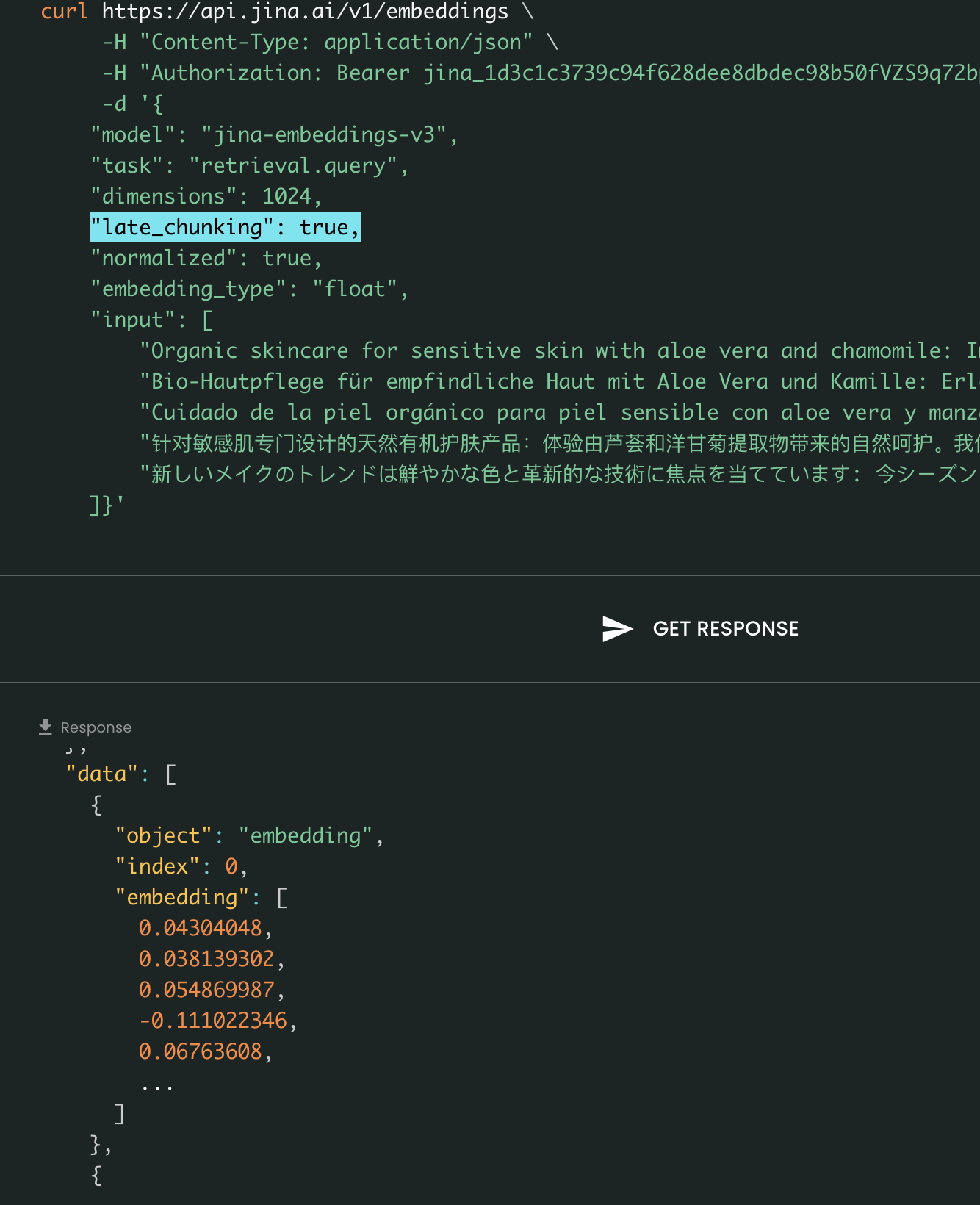
Late Chunking On vs Off: 입력과 출력 형식은 동일하며 임베딩 값만 차이가 있습니다. late_chunking이 활성화되면 임베딩은 input의 전체 이전 컨텍스트의 영향을 받지만, 비활성화되면 임베딩은 독립적으로 계산됩니다.
tagAzure 및 AWS를 통해
jina-embeddings-v3는 이제 AWS SageMaker와 Azure Marketplace에서 사용할 수 있습니다.


해당 플랫폼 외에서 사용하거나 기업 내 온프레미스에서 사용해야 하는 경우, 이 모델은 CC BY-NC 4.0 라이선스로 제공됩니다. 상업적 사용 문의는 저희에게 연락 주시기 바랍니다.
tag벡터 데이터베이스 및 파트너사를 통해
우리는 Pinecone, Qdrant, Milvus와 같은 벡터 데이터베이스 제공업체들과 LlamaIndex, Haystack, Dify와 같은 LLM 오케스트레이션 프레임워크와 긴밀히 협력하고 있습니다. 출시 시점에 Pinecone, Qdrant, Milvus, Haystack이 이미 jina-embeddings-v3에 대한 지원을 통합했으며, 여기에는 task, dimensions, late_chunking의 세 가지 새로운 매개변수가 포함됩니다. v2 API와 이미 통합된 다른 파트너들도 모델 이름을 jina-embeddings-v3로 변경하는 것만으로 v3를 지원할 수 있습니다. 다만, v3에서 새로 도입된 매개변수들은 아직 지원하지 않을 수 있습니다.
Pinecone을 통해

Qdrant를 통해

Milvus를 통해

Haystack을 통해

tag결론
2023년 10월, 우리는 jina-embeddings-v2-base-en을 출시했으며, 이는 8K 컨텍스트 길이를 지원하는 세계 최초의 오픈소스 임베딩 모델이었습니다. 이는 긴 컨텍스트를 지원하고 OpenAI의 text-embedding-ada-002와 대등한 성능을 보이는 유일한 텍스트 임베딩 모델이었습니다. 오늘날, 1년간의 학습과 실험, 그리고 소중한 교훈을 바탕으로, 우리는 텍스트 임베딩 모델의 새로운 지평을 여는 jina-embeddings-v3를 자랑스럽게 출시하며, 이는 우리 회사의 중요한 이정표가 되었습니다.
이번 출시를 통해 우리는 우리가 잘 알려진 분야인 긴 컨텍스트 임베딩에서 계속해서 뛰어난 성과를 보이면서, 동시에 산업계와 커뮤니티로부터 가장 많이 요청받았던 기능인 다국어 임베딩도 구현했습니다. 동시에 성능도 새로운 수준으로 끌어올렸습니다. Task-specific LoRA, MRL, late chunking과 같은 새로운 기능들과 함께, 우리는 jina-embeddings-v3가 RAG, 에이전트 등 다양한 애플리케이션을 위한 진정한 기반 임베딩 모델이 될 것이라고 믿습니다. NV-embed-v1/v2와 같은 최근의 LLM 기반 임베딩과 비교했을 때, 우리 모델은 매개변수 효율성이 매우 높아 프로덕션과 엣지 디바이스에 더욱 적합합니다.
앞으로 우리는 저자원 언어에서의 jina-embeddings-v3 성능을 평가하고 개선하는 것과 제한된 데이터 가용성으로 인한 체계적 실패를 분석하는 데 초점을 맞출 계획입니다. 또한, jina-embeddings-v3의 모델 가중치와 혁신적인 기능들, 그리고 새로운 관점들은 jina-clip-v2를 포함한 향후 모델들의 기반이 될 것입니다.
jina-reranker-v3, 그리고 reader-lm-v2.