





오늘 우리는 Jina Reranker v2 (jina-reranker-v2-base-multilingual)를 출시합니다. 이는 검색 기반 제품군에서 가장 최신이자 최고 성능을 자랑하는 신경망 재순위 모델입니다. Jina Reranker v2를 통해 RAG/검색 시스템 개발자들은 다음과 같은 이점을 누릴 수 있습니다:
- 다국어:
bge-reranker-v2-m3보다 우수한 성능으로 100개 이상의 언어에서 더 관련성 높은 검색 결과 제공 - 에이전트 지원: 에이전트 RAG를 위한 최첨단 함수 호출 및 텍스트-SQL 인식 문서 재순위화
- 코드 검색: 코드 검색 작업에서 최고 성능 발휘
- 초고속:
bge-reranker-v2-m3보다 15배 많은 문서 처리량, jina-reranker-v1-base-en보다 6배 더 많은 처리량 제공
Reranker API를 통해 Jina Reranker v2를 시작할 수 있으며, 모든 신규 사용자에게 100만 토큰을 무료로 제공합니다.

이 글에서는 Jina Reranker v2가 지원하는 새로운 기능들을 자세히 설명하고, 다른 최신 모델들(Jina Reranker v1 포함)과 비교한 성능을 보여주며, Jina Reranker v2가 작업 정확도와 문서 처리량에서 최고 성능을 달성하게 된 훈련 과정을 설명하겠습니다.
tag다시 보는 재순위화 모델이 필요한 이유
검색 기반에서 임베딩 모델이 가장 널리 사용되고 이해되는 구성 요소이지만, 이들은 종종 검색 속도를 위해 정확도를 희생합니다. 임베딩 기반 검색 모델은 일반적으로 이중 인코더 모델로, 각 문서가 임베딩되어 저장되고, 쿼리도 임베딩되어 쿼리의 임베딩과 문서의 임베딩 간의 유사도를 기반으로 검색이 이루어집니다. 이 모델에서는 사용자의 쿼리와 매칭된 문서 사이의 토큰 수준의 상호작용의 많은 뉘앙스가 손실됩니다 - 원본 쿼리와 문서는 서로를 "볼 수" 없고 오직 그들의 임베딩만이 가능하기 때문입니다. 이는 검색 정확도의 희생을 초래할 수 있습니다 - 교차 인코더 재순위화 모델이 뛰어난 영역입니다.

재순위화 모델은 쿼리-문서 쌍을 함께 인코딩하여 임베딩 대신 관련성 점수를 생성하는 교차 인코더 아키텍처를 사용하여 이러한 세밀한 의미론의 부족을 해결합니다. 연구들에 따르면, 대부분의 RAG 시스템에서 재순위화 모델의 사용은 의미적 근거를 개선하고 환각을 줄인다고 합니다.
tagJina Reranker v2의 다국어 지원
과거, Jina Reranker v1은 4개의 주요 영어 벤치마크에서 최고 수준의 성능을 달성하며 차별화되었습니다. 오늘날, 우리는 Jina Reranker v2에서 100개 이상의 언어에 대한 다국어 지원과 교차 언어 작업을 통해 재순위화 기능을 크게 확장하고 있습니다!
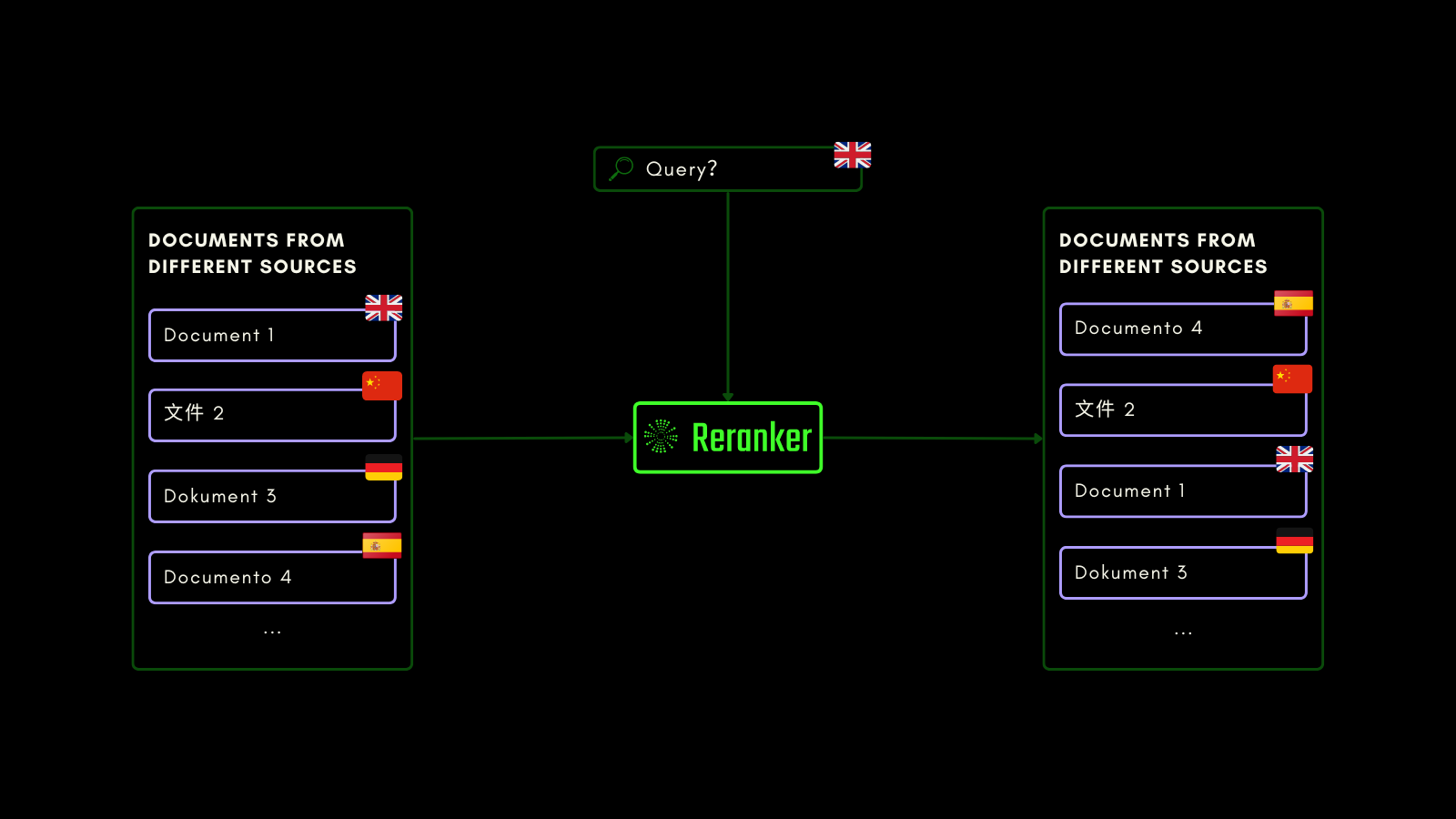
Jina Reranker v2의 교차 언어 및 영어 기능을 평가하기 위해, 아래 나열된 세 가지 벤치마크에서 유사한 재순위화 모델들과 성능을 비교했습니다:
MKQA: 다국어 지식 질문 및 답변
이 데이터셋은 실제 지식 베이스에서 도출된 26개 언어의 질문과 답변으로 구성되어 있으며, 질문-답변 시스템의 교차 언어 성능을 평가하도록 설계되었습니다. MKQA는 영어 쿼리와 이들의 비영어 언어로의 수동 번역, 그리고 영어를 포함한 여러 언어로 된 답변으로 구성되어 있습니다.
아래 그래프에서는 기존 임베딩 기반 검색을 수행하는 "dense retriever"를 기준선으로 포함하여 각 재순위화 모델의 recall@10 점수를 보고합니다:
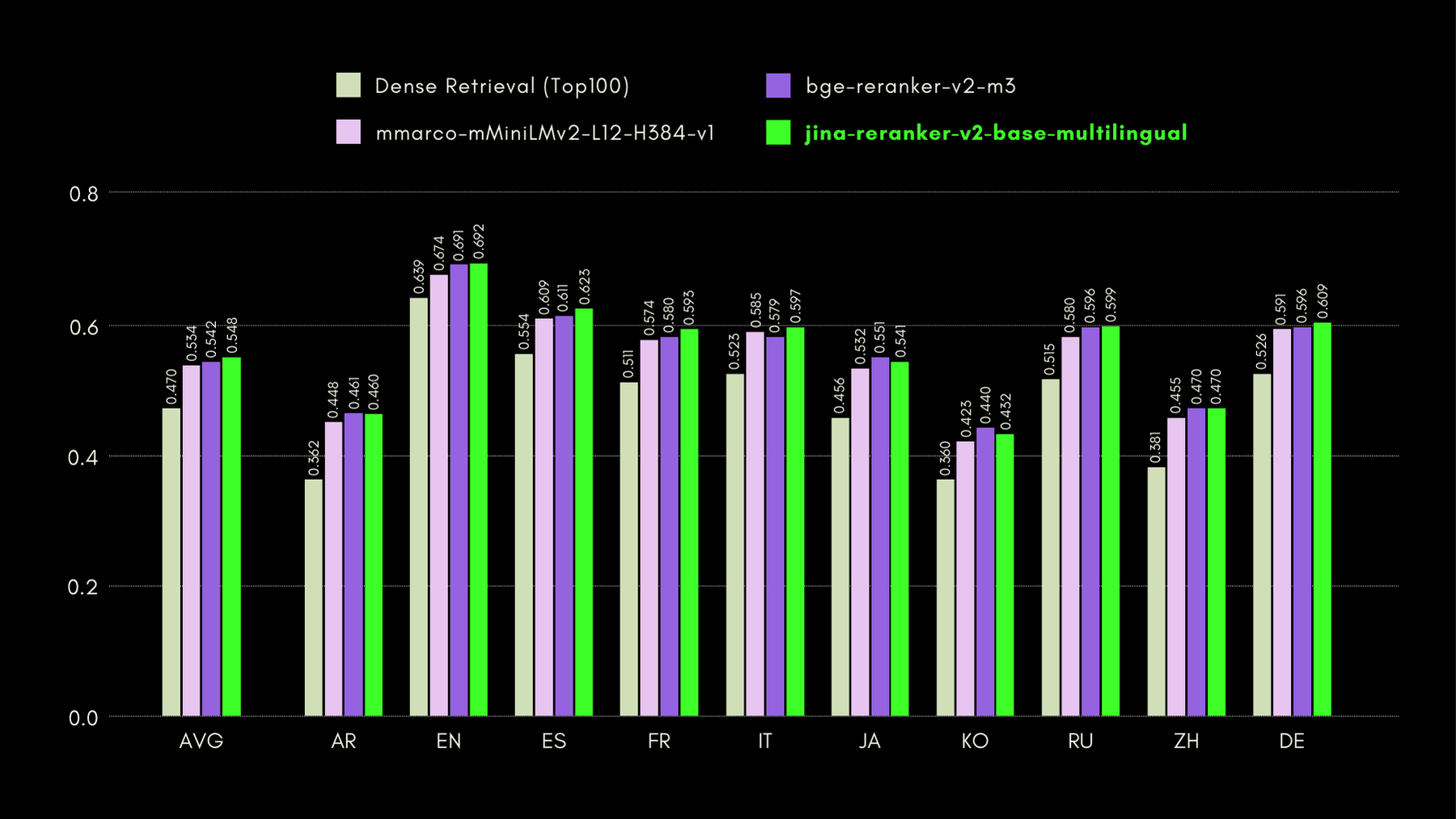
BEIR: 다양한 IR 작업에 대한 이질적 벤치마크
이 오픈소스 저장소는 많은 언어를 위한 검색 벤치마크를 포함하고 있지만, 우리는 영어 작업에만 초점을 맞췄습니다. 이는 훈련 데이터 없이 17개의 데이터셋으로 구성되어 있으며, 이 데이터셋들은 신경망 또는 어휘 검색기의 검색 정확도를 평가하는 데 중점을 둡니다.
아래 그래프에서는 각 재순위화 모델에 대한 BEIR의 NDCG@10을 보고합니다. BEIR의 결과는 새로 도입된 jina-reranker-v2-base-multilingual의 다국어 기능이 영어 검색 기능을 손상시키지 않음을 명확히 보여주며, 더욱이 jina-reranker-v1-base-en보다 크게 향상되었습니다.
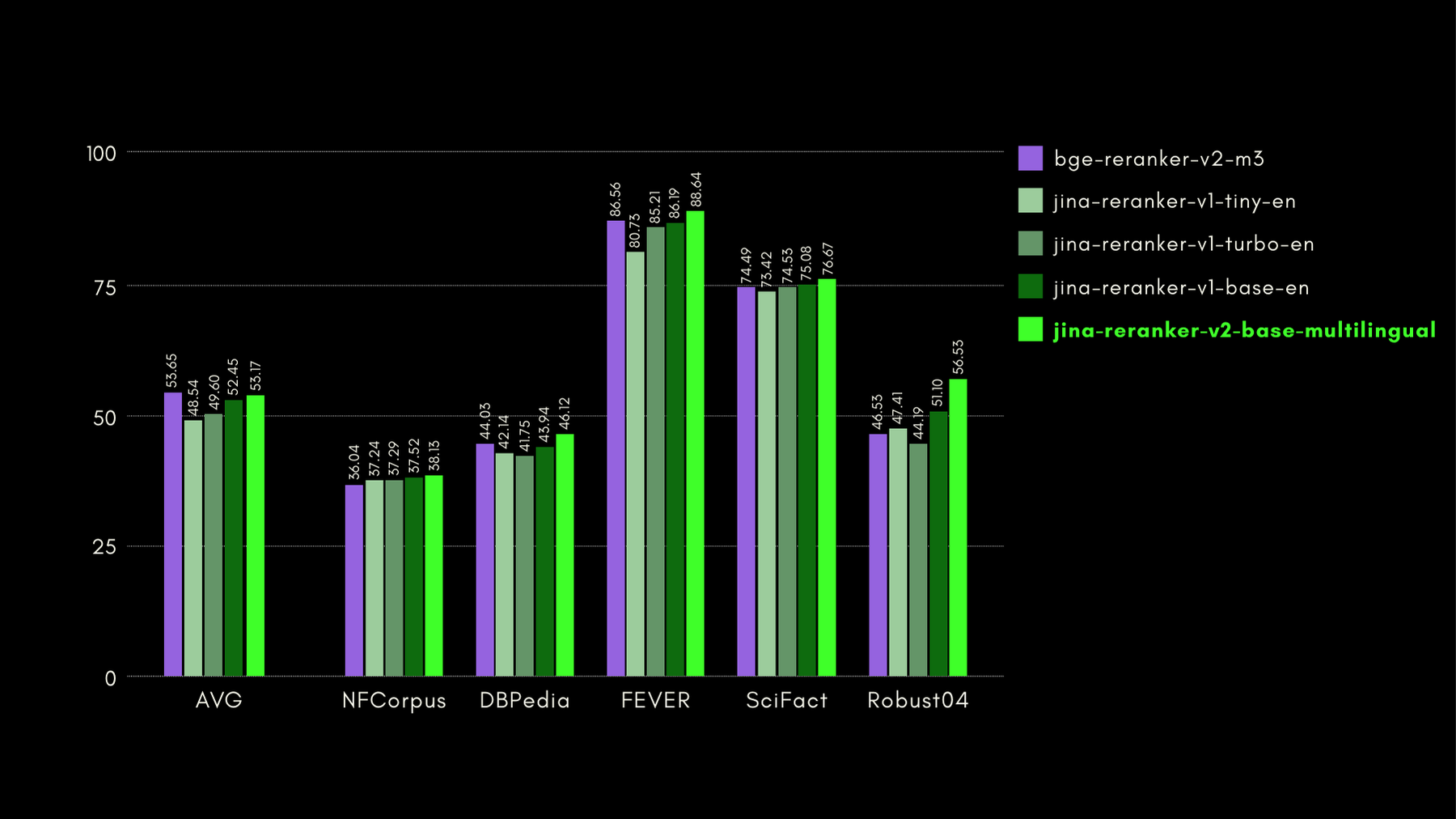
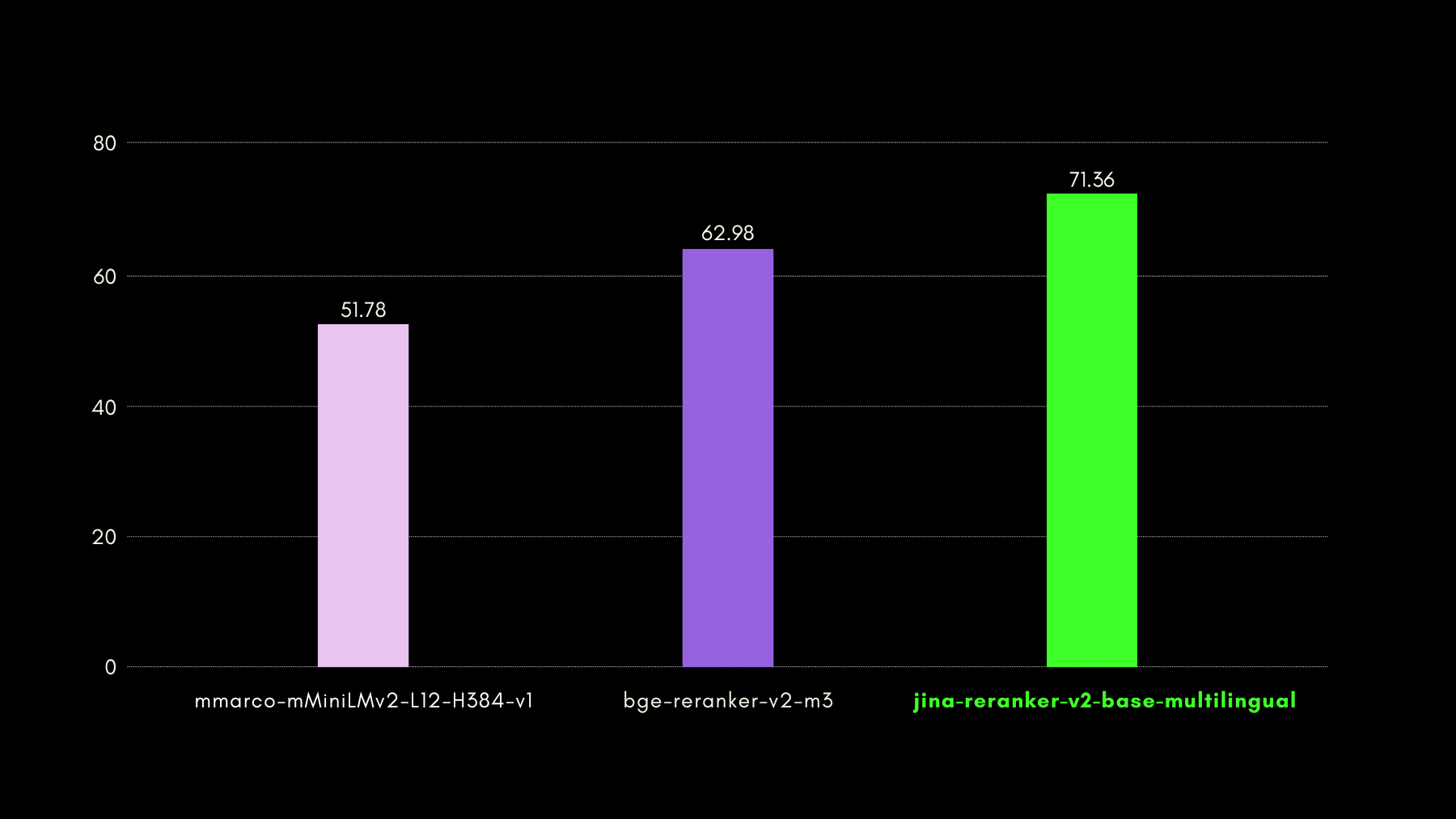
AirBench: 자동화된 이질적 IR 벤치마크
저희는 BAAI와 함께 RAG 시스템을 위한 AirBench 벤치마크를 공동 개발하고 발표했습니다. 이 벤치마크는 커스텀 도메인과 태스크를 위해 자동 생성된 합성 데이터를 사용하며, 벤치마크 대상 모델이 데이터셋에 과적합되는 것을 방지하기 위해 정답을 공개하지 않습니다.
현재 jina-reranker-v2-base-multilingual는 포함된 다른 모든 reranker 모델을 능가하며 리더보드에서 1위를 차지하고 있습니다.
tagTooling-Agents 요약: LLM에게 도구 사용법 가르치기
몇 년 전 AI 붐이 시작된 이후, 사람들은 AI 모델이 컴퓨터가 잘해야 할 일들을 제대로 수행하지 못하는 것을 보아왔습니다. 예를 들어, Mistral-7b-Instruct-v0.1과의 다음 대화를 살펴보세요:

얼핏 보기에는 맞아 보일 수 있지만, 실제로 203에 7724를 곱하면 1,567,972입니다.
그렇다면 LLM은 왜 10배 이상 차이나는 잘못된 답을 내놓을까요? LLM은 수학이나 다른 종류의 추론을 하도록 훈련되지 않았고, 내부 재귀가 없다는 것은 복잡한 수학 문제를 해결할 수 없다는 것을 거의 보장합니다. 이들은 정확성이 본질적으로 요구되지 않는 말하기나 다른 작업을 수행하도록 훈련되었습니다.
하지만 LLM은 답을 환각하는 것을 주저하지 않습니다. LLM의 관점에서 15,824,772는 204 × 7,724의 완벽하게 그럴듯한 답입니다. 단지 완전히 틀렸을 뿐이죠.
Agentic RAG는 생성형 LLM의 역할을 그들이 잘하지 못하는 것(생각하고 아는 것)에서 잘하는 것(읽기 이해와 정보를 자연어로 종합하는 것)으로 바꿉니다. 단순히 답을 생성하는 대신, RAG는 사용 가능한 데이터 소스에서 요청에 관련된 정보를 찾아 언어 모델에 제시합니다. 그것의 임무는 답을 만들어내는 것이 아니라, 다른 시스템이 찾은 답을 자연스럽고 반응적인 형태로 제시하는 것입니다.
저희는 Jina Reranker v2를 SQL 데이터베이스 스키마와 함수 호출에 민감하도록 훈련했습니다. 이는 기존 텍스트 검색과는 다른 종류의 의미론이 필요합니다. 태스크와 코드를 인식할 수 있어야 하며, 저희는 reranker를 이러한 기능에 맞게 특별히 훈련했습니다.
tag구조화된 데이터 쿼리에서의 Jina Reranker v2
임베딩과 reranker 모델이 이미 비구조화 데이터를 일급 시민으로 취급하는 반면, 대부분의 모델에서는 구조화된 테이블 데이터에 대한 지원이 여전히 부족합니다.
Jina Reranker v2는 MySQL이나 MongoDB와 같은 구조화된 데이터베이스를 쿼리하려는 downstream 의도를 이해하고, 입력 쿼리에 대해 구조화된 테이블 스키마에 올바른 관련성 점수를 할당합니다.
아래에서 볼 수 있듯이, reranker는 LLM이 자연어 쿼리로부터 SQL 쿼리를 생성하기 전에 가장 관련성 높은 테이블을 검색합니다:
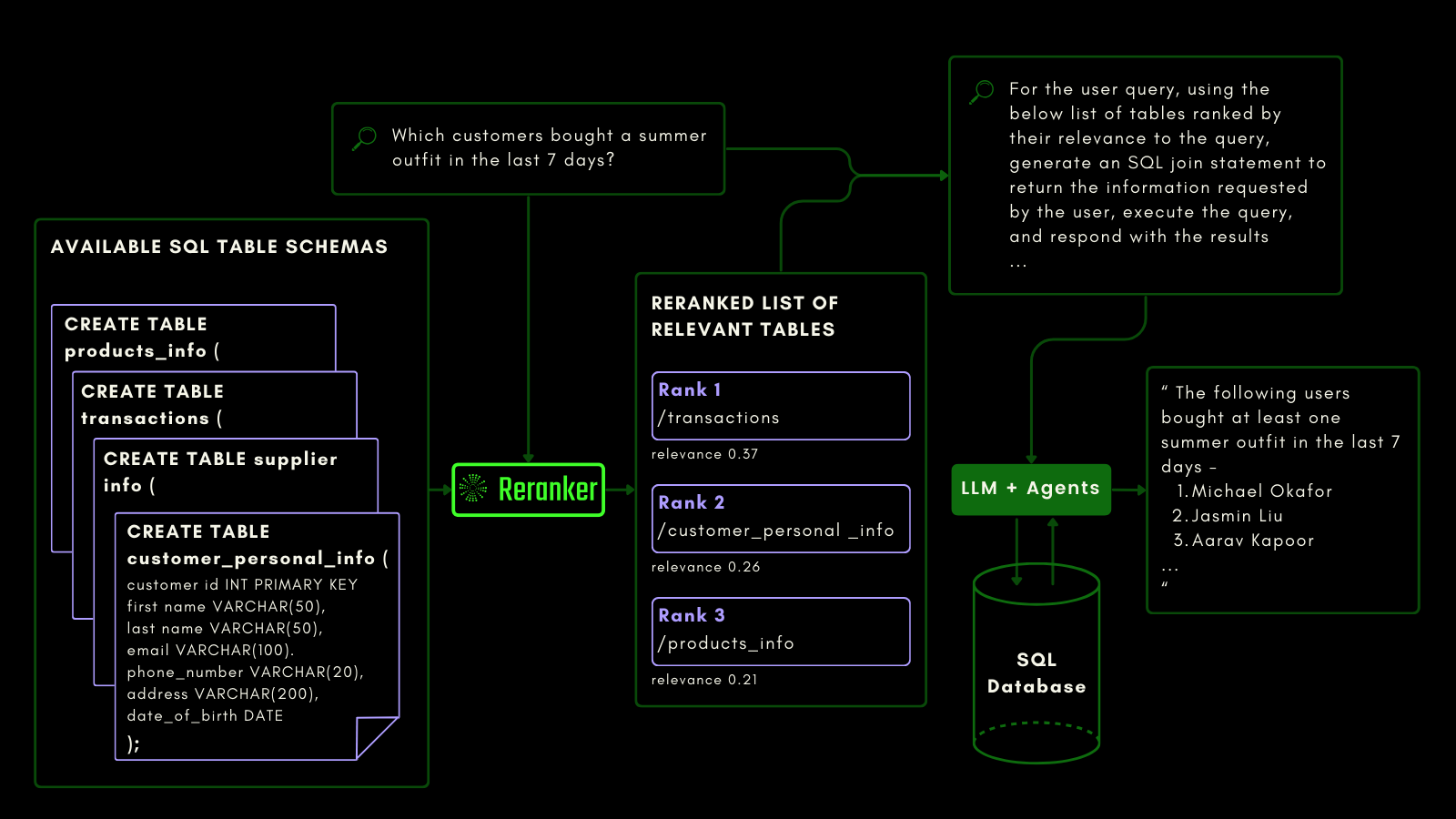
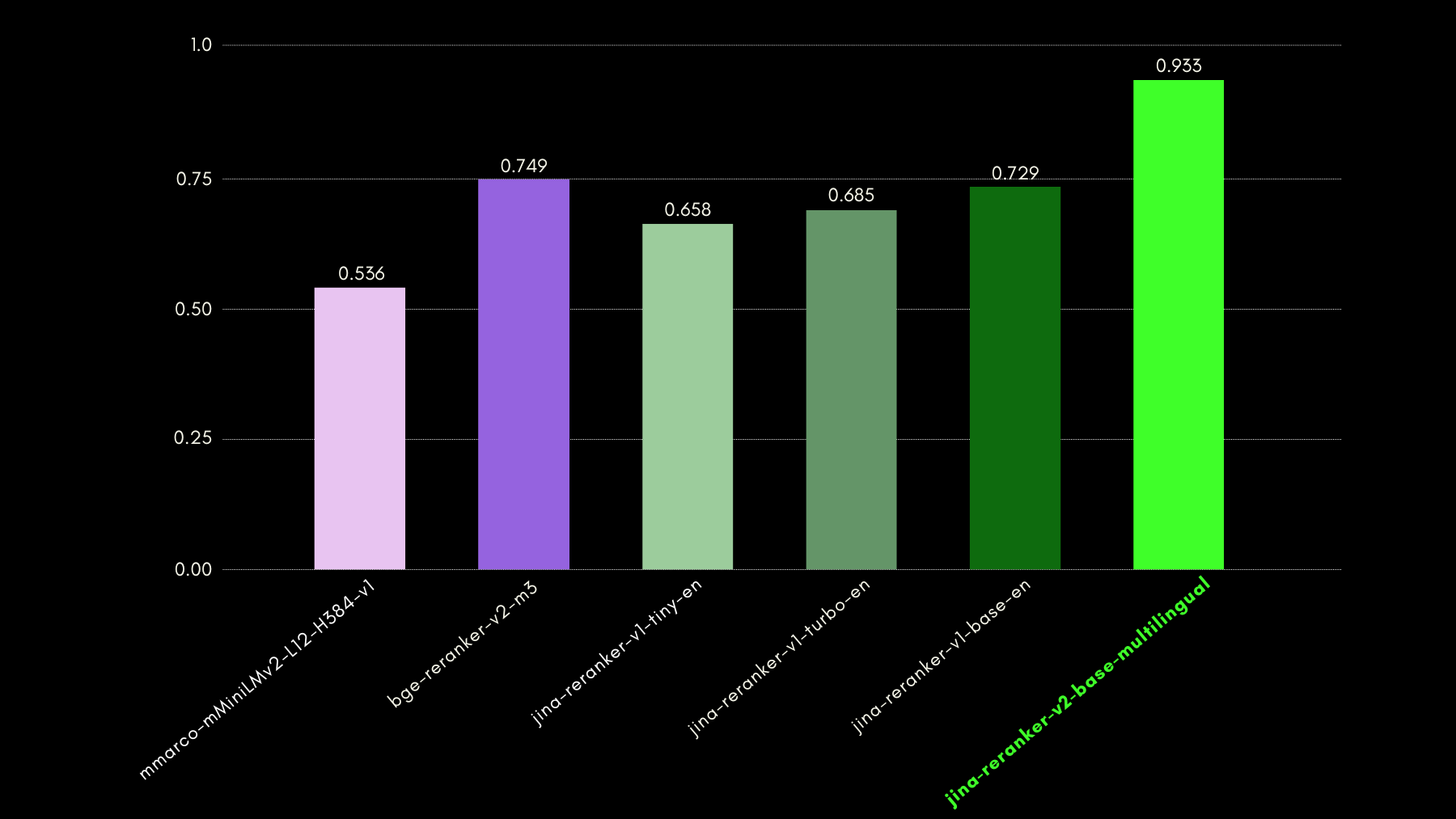
저희는 NSText2SQL 데이터셋 벤치마크를 사용하여 쿼리 인식 기능을 평가했습니다. 원본 데이터셋의 "instruction" 열에서 자연어로 작성된 지시사항과 해당하는 테이블 스키마를 추출했습니다.
아래 그래프는 recall@3를 사용하여 reranker 모델이 자연어 쿼리에 해당하는 올바른 테이블 스키마를 순위 매기는데 얼마나 성공적인지 비교합니다.
tag함수 호출에서의 Jina Reranker v2
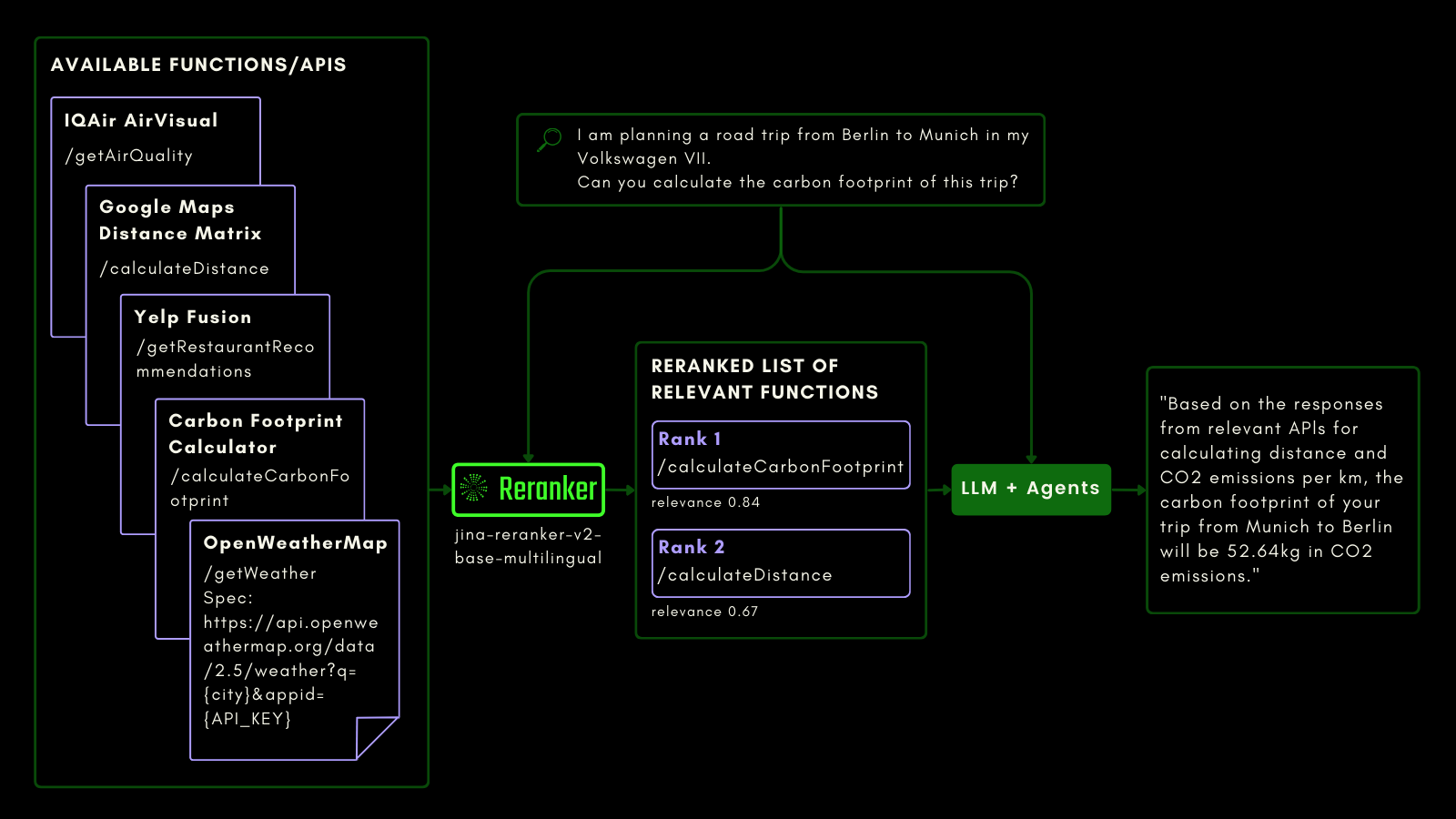
SQL 테이블을 쿼리하는 것처럼, agentic RAG를 사용하여 외부 도구를 호출할 수 있습니다. 이를 고려하여 Jina Reranker v2에 함수 호출을 통합했으며, 외부 함수에 대한 의도를 이해하고 그에 따라 함수 명세에 관련성 점수를 할당할 수 있습니다.
아래 도식은 LLM이 Reranker를 사용하여 함수 호출 기능을 개선하고, 궁극적으로 agentic AI 사용자 경험을 향상시키는 방법을 (예시와 함께) 설명합니다.
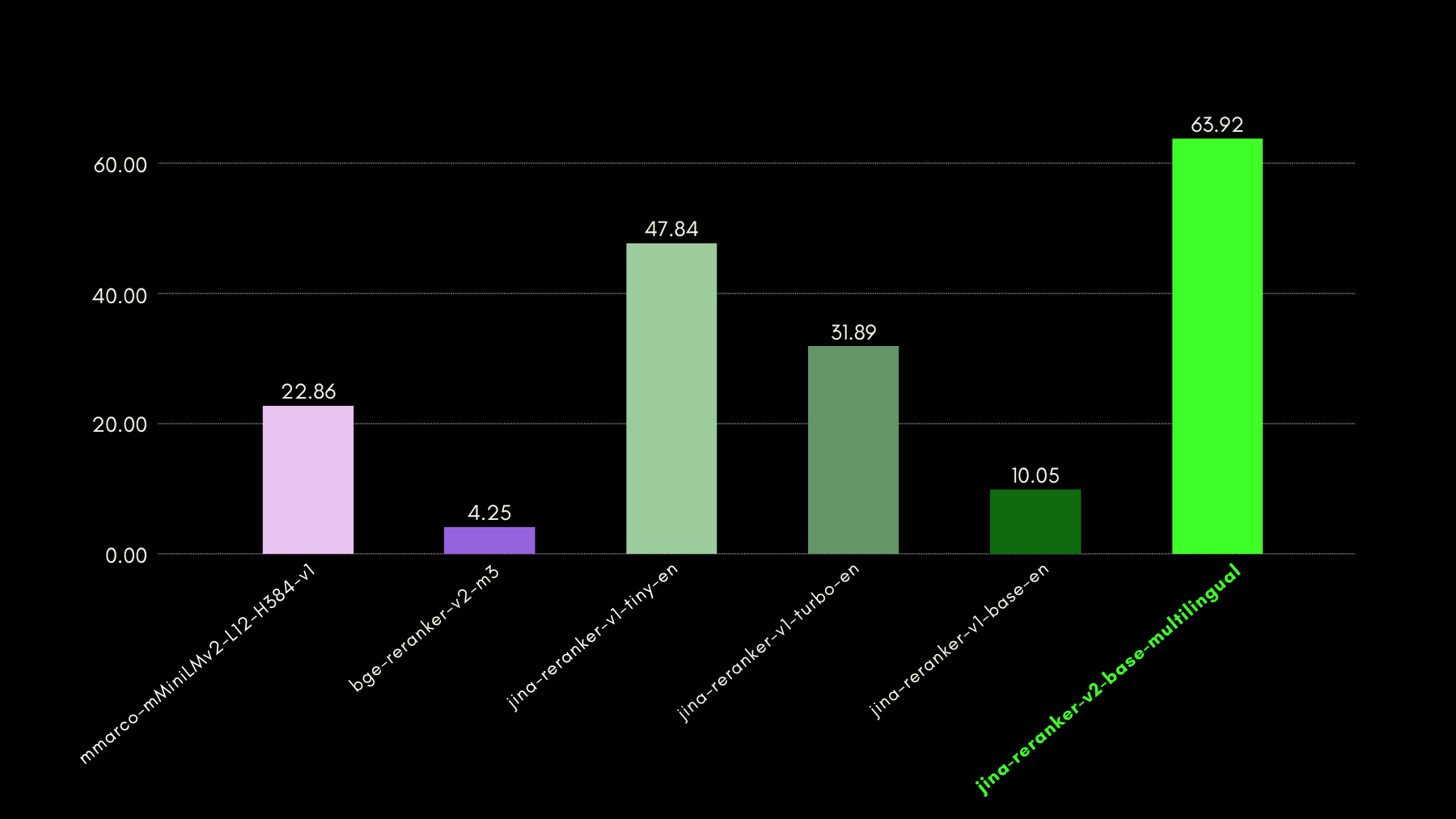
저희는 ToolBench 벤치마크로 함수 인식 기능을 평가했습니다. 이 벤치마크는 16,000개 이상의 공개 API와 단일 및 다중 API 설정에서 이를 사용하기 위한 합성 생성된 지시사항을 수집합니다.
다음은 다른 reranker 모델과 비교한 결과(recall@3 메트릭)입니다:
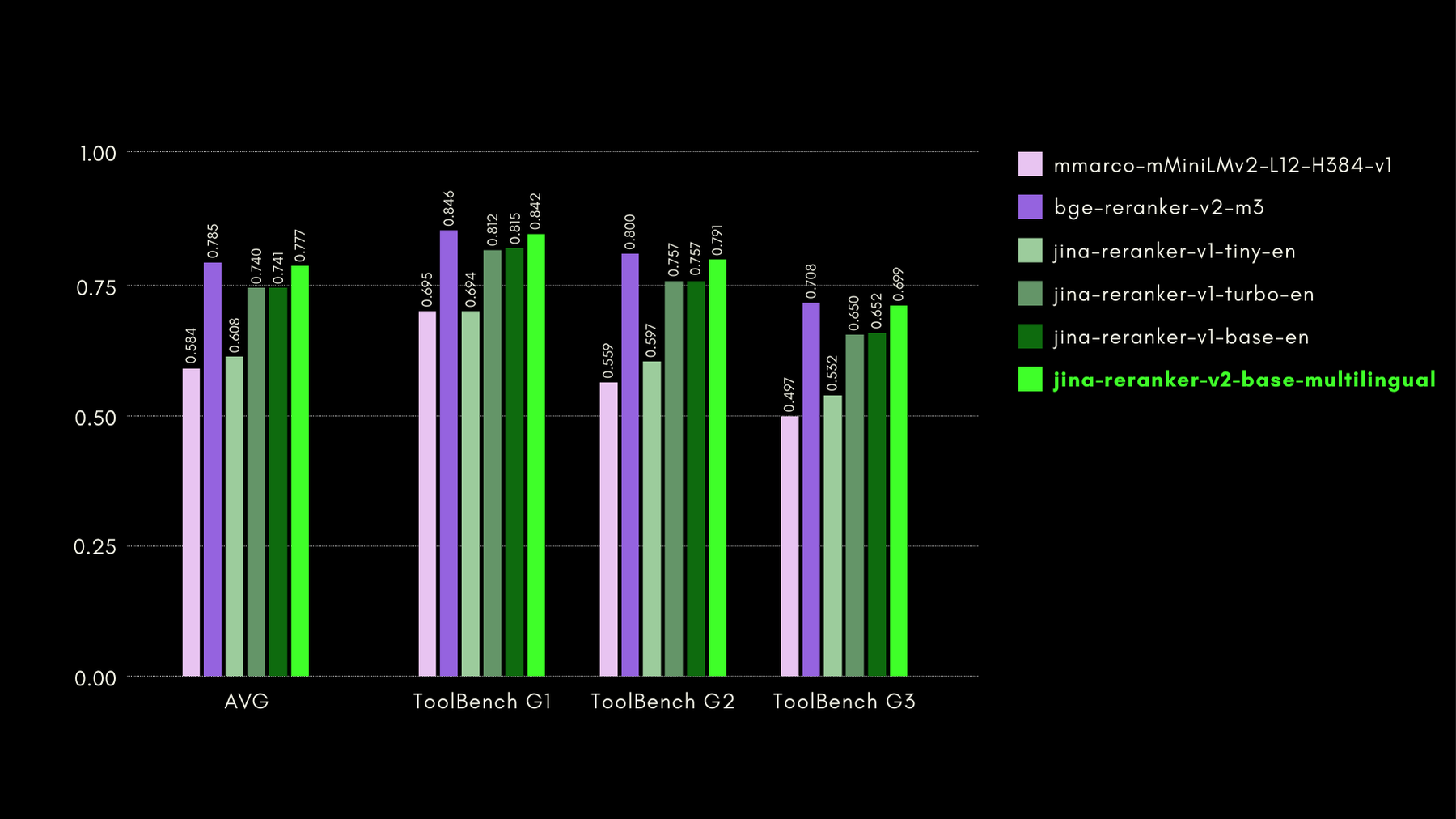
뒷부분에서도 보여드리겠지만, jina-reranker-v2-base-multilingual는 bge-reranker-v2-m3의 절반 크기이면서 거의 15배 빠른 속도로 거의 최신 수준의 성능을 보여줍니다.
tag코드 검색에서의 Jina Reranker v2
Jina Reranker v2는 함수 호출과 구조화된 데이터 쿼리에 대해 학습되었을 뿐만 아니라, 비슷한 크기의 경쟁 모델들과 비교해 코드 검색도 향상되었습니다. CodeSearchNet 벤치마크를 사용하여 코드 검색 능력을 평가했습니다. 이 벤치마크는 docstring 형식과 자연어 형식의 쿼리가 결합된 것으로, 쿼리와 관련된 코드 세그먼트가 레이블링되어 있습니다.
다음은 다른 리랭커 모델들과 비교한 MRR@10 결과입니다:
tagJina Reranker v2의 초고속 추론
교차 인코더 스타일의 신경망 리랭커는 검색된 문서의 관련성을 예측하는 데 뛰어나지만, 임베딩 모델보다 추론 속도가 느립니다. 즉, 쿼리를 n개의 문서와 일대일로 비교하는 것은 대부분의 벡터 데이터베이스에서 HNSW나 다른 빠른 검색 방법보다 훨씬 느립니다. Jina Reranker v2로 이러한 속도 문제를 해결했습니다.
- 우리의 독특한 학습 인사이트(다음 섹션에서 설명)로 278M 파라미터만으로 최신 수준의 정확도를 달성했습니다. 567M 파라미터를 가진
bge-reranker-v2-m3와 비교하면, Jina Reranker v2는 단지 절반의 크기입니다. 이러한 축소가 처리량(50ms당 처리되는 문서)이 개선된 첫 번째 이유입니다. - 비슷한 모델 크기에서도, Jina Reranker v2는 이전의 최신 Jina Reranker v1 영어 모델보다 6배 높은 처리량을 자랑합니다. 이는 트랜스포머 기반 모델의 어텐션 레이어에서 메모리와 연산 최적화를 도입한 Flash Attention 2를 구현했기 때문입니다.
위 단계들의 결과로 나타난 Jina Reranker v2의 처리량 성능을 보실 수 있습니다:
tagJina Reranker v2 학습 방법
jina-reranker-v2-base-multilingual를 4단계로 학습했습니다:
- 영어 데이터로 준비: 영어 데이터만을 사용하여 백본 모델의 첫 번째 버전을 학습했습니다. 여기에는 쌍(대조 학습) 또는 삼중항(쿼리, 올바른 응답, 잘못된 응답), 쿼리-함수 스키마 쌍, 쿼리-테이블 스키마 쌍이 포함됩니다.
- 교차 언어 데이터 추가: 다음 단계에서는 백본 모델의 검색 작업에 대한 다국어 능력을 향상시키기 위해 교차 언어 쌍과 삼중항 데이터셋을 추가했습니다.
- 모든 다국어 데이터 추가: 이 단계에서는 모델이 가능한 한 많은 데이터를 보도록 하는 데 중점을 두었습니다. 100개 이상의 저자원 및 고자원 언어로 된 모든 쌍과 삼중항 데이터셋으로 두 번째 단계의 모델 체크포인트를 미세 조정했습니다.
- 마이닝된 어려운 네거티브로 미세 조정: 세 번째 단계의 리랭킹 성능을 관찰한 후, 기존 쿼리에 대한 어려운 네거티브의 예시를 더 많이 포함한 삼중항 데이터를 추가하여 모델을 미세 조정했습니다 - 겉보기에는 쿼리와 관련이 있어 보이지만 실제로는 잘못된 응답들입니다.
이 4단계 학습 접근법은 가능한 한 일찍 학습 과정에 함수와 테이블 스키마를 포함시키면 모델이 이러한 사용 사례를 특별히 인식하고 언어 구조보다는 후보 문서의 의미론에 더 집중하는 것을 배울 수 있다는 인사이트를 바탕으로 했습니다.
tag실제 Jina Reranker v2 사용
tagReranker API를 통한 사용
Jina Reranker v2를 시작하는 가장 빠르고 쉬운 방법은 Jina Reranker의 API를 사용하는 것입니다.
이 페이지의 API 섹션으로 이동하여 원하는 프로그래밍 언어로 jina-reranker-v2-base-multilingual를 통합하세요.
예시 1: 함수 호출 랭킹
가장 관련성 높은 외부 함수/도구를 랭킹하려면 쿼리와 문서(함수 스키마)를 아래와 같이 포맷하세요:
curl -X 'POST' \
'https://api.jina.ai/v1/rerank' \
-H 'accept: application/json' \
-H 'Authorization: Bearer <YOUR JINA AI TOKEN HERE>' \
-H 'Content-Type: application/json' \
-d '{
"model": "jina-reranker-v2-base-multilingual",
"query": "I am planning a road trip from Berlin to Munich in my Volkswagen VII. Can you calculate the carbon footprint of this trip?",
"documents": [
"{'\''Name'\'': '\''getWeather'\'', '\''Specification'\'': '\''Provides current weather information for a specified city'\'', '\''spec'\'': '\''https://api.openweathermap.org/data/2.5/weather?q={city}&appid={API_KEY}'\'', '\''example'\'': '\''https://api.openweathermap.org/data/2.5/weather?q=Berlin&appid=YOUR_API_KEY'\''}",
"{'\''Name'\'': '\''calculateDistance'\'', '\''Specification'\'': '\''Calculates the driving distance and time between multiple locations'\'', '\''spec'\'': '\''https://maps.googleapis.com/maps/api/distancematrix/json?origins={startCity}&destinations={endCity}&key={API_KEY}'\'', '\''example'\'': '\''https://maps.googleapis.com/maps/api/distancematrix/json?origins=Berlin&destinations=Munich&key=YOUR_API_KEY'\''}",
"{'\''Name'\'': '\''calculateCarbonFootprint'\'', '\''Specification'\'': '\''Estimates the carbon footprint for various activities, including transportation'\'', '\''spec'\'': '\''https://www.carboninterface.com/api/v1/estimates'\'', '\''example'\'': '\''{type: vehicle, distance: distance, vehicle_model_id: car}'\''}"
]
}'<YOUR JINA AI TOKEN HERE>를 개인 Reranker API 토큰으로 교체하는 것을 잊지 마세요
다음과 같은 결과를 얻게 됩니다:
{
"model": "jina-reranker-v2-base-multilingual",
"usage": {
"total_tokens": 383,
"prompt_tokens": 383
},
"results": [
{
"index": 2,
"document": {
"text": "{'Name': 'calculateCarbonFootprint', 'Specification': 'Estimates the carbon footprint for various activities, including transportation', 'spec': 'https://www.carboninterface.com/api/v1/estimates', 'example': '{type: vehicle, distance: distance, vehicle_model_id: car}'}"
},
"relevance_score": 0.5422876477241516
},
{
"index": 1,
"document": {
"text": "{'Name': 'calculateDistance', 'Specification': 'Calculates the driving distance and time between multiple locations', 'spec': 'https://maps.googleapis.com/maps/api/distancematrix/json?origins={startCity}&destinations={endCity}&key={API_KEY}', 'example': 'https://maps.googleapis.com/maps/api/distancematrix/json?origins=Berlin&destinations=Munich&key=YOUR_API_KEY'}"
},
"relevance_score": 0.23283305764198303
},
{
"index": 0,
"document": {
"text": "{'Name': 'getWeather', 'Specification': 'Provides current weather information for a specified city', 'spec': 'https://api.openweathermap.org/data/2.5/weather?q={city}&appid={API_KEY}', 'example': 'https://api.openweathermap.org/data/2.5/weather?q=Berlin&appid=YOUR_API_KEY'}"
},
"relevance_score": 0.05033063143491745
}
]
}예제 2: SQL 쿼리 순위 매기기
마찬가지로 쿼리에 대한 구조화된 테이블 스키마의 관련성 점수를 검색하려면 다음 예제 API 호출을 사용할 수 있습니다:
curl -X 'POST' \
'https://api.jina.ai/v1/rerank' \
-H 'accept: application/json' \
-H 'Authorization: Bearer <YOUR JINA AI TOKEN HERE>' \
-H 'Content-Type: application/json' \
-d '{
"model": "jina-reranker-v2-base-multilingual",
"query": "which customers bought a summer outfit in the past 7 days?",
"documents": [
"CREATE TABLE customer_personal_info (customer_id INT PRIMARY KEY, first_name VARCHAR(50), last_name VARCHAR(50));",
"CREATE TABLE supplier_company_info (supplier_id INT PRIMARY KEY, company_name VARCHAR(100), contact_name VARCHAR(50));",
"CREATE TABLE transactions (transaction_id INT PRIMARY KEY, customer_id INT, purchase_date DATE, FOREIGN KEY (customer_id) REFERENCES customer_personal_info(customer_id), product_id INT, FOREIGN KEY (product_id) REFERENCES products(product_id));",
"CREATE TABLE products (product_id INT PRIMARY KEY, product_name VARCHAR(100), season VARCHAR(50), supplier_id INT, FOREIGN KEY (supplier_id) REFERENCES supplier_company_info(supplier_id));"
]
}'예상되는 응답은 다음과 같습니다:
{
"model": "jina-reranker-v2-base-multilingual",
"usage": {
"total_tokens": 253,
"prompt_tokens": 253
},
"results": [
{
"index": 2,
"document": {
"text": "CREATE TABLE transactions (transaction_id INT PRIMARY KEY, customer_id INT, purchase_date DATE, FOREIGN KEY (customer_id) REFERENCES customer_personal_info(customer_id), product_id INT, FOREIGN KEY (product_id) REFERENCES products(product_id));"
},
"relevance_score": 0.2789437472820282
},
{
"index": 0,
"document": {
"text": "CREATE TABLE customer_personal_info (customer_id INT PRIMARY KEY, first_name VARCHAR(50), last_name VARCHAR(50));"
},
"relevance_score": 0.06477169692516327
},
{
"index": 3,
"document": {
"text": "CREATE TABLE products (product_id INT PRIMARY KEY, product_name VARCHAR(100), season VARCHAR(50), supplier_id INT, FOREIGN KEY (supplier_id) REFERENCES supplier_company_info(supplier_id));"
},
"relevance_score": 0.027742892503738403
},
{
"index": 1,
"document": {
"text": "CREATE TABLE supplier_company_info (supplier_id INT PRIMARY KEY, company_name VARCHAR(100), contact_name VARCHAR(50));"
},
"relevance_score": 0.025516605004668236
}
]
}tagRAG/LLM 프레임워크를 통한 사용
Jina Reranker의 기존 LLM 및 RAG 오케스트레이션 프레임워크와의 통합은 모델명 jina-reranker-v2-base-multilingual을 사용하여 바로 작동해야 합니다. 애플리케이션에서 Jina Reranker v2를 통합하는 방법에 대해 자세히 알아보려면 각각의 문서 페이지를 참조하세요.
- Haystack by deepset: Jina Reranker v2는 Haystack의 JinaRanker 클래스와 함께 사용할 수 있습니다:
from haystack import Document
from haystack_integrations.components.rankers.jina import JinaRanker
docs = [Document(content="Paris"), Document(content="Berlin")]
ranker = JinaRanker(model="jina-reranker-v2-base-multilingual", api_key="<YOUR JINA AI API KEY HERE>")
ranker.run(query="City in France", documents=docs, top_k=1)
- LlamaIndex: Jina Reranker v2는 다음과 같이 초기화하여 JinaRerank 노드 후처리 모듈로 사용할 수 있습니다:
import os
from llama_index.postprocessor.jinaai_rerank import JinaRerank
jina_rerank = JinaRerank(model="jina-reranker-v2-base-multilingual", api_key="<YOUR JINA AI API KEY HERE>", top_n=1)
- Langchain: 기존 애플리케이션에서 Jina Reranker 2를 사용하려면 Jina Rerank 통합을 사용하세요. JinaRerank 모듈은 올바른 모델 이름으로 초기화해야 합니다:
from langchain_community.document_compressors import JinaRerank
reranker = JinaRerank(model="jina-reranker-v2-base-multilingual", jina_api_key="<YOUR JINA AI API KEY HERE>")
tagHuggingFace를 통한 사용
연구 및 평가 목적으로 jina-reranker-v2-base-multilingual 모델에 대한 접근을 Hugging Face에서 CC-BY-NC-4.0 라이선스로 공개하고 있습니다.

Hugging Face에서 모델을 다운로드하고 실행하려면 transformers와 einops 라이브러리를 설치하세요:
pip install transformers einops
pip install ninja
pip install flash-attn --no-build-isolation
Hugging Face 액세스 토큰을 사용하여 Hugging Face CLI 로그인을 통해 Hugging Face 계정에 로그인하세요:
huggingface-cli login --token <"HF-Access-Token">
사전 학습된 모델을 다운로드하세요:
from transformers import AutoModelForSequenceClassification
model = AutoModelForSequenceClassification.from_pretrained(
'jinaai/jina-reranker-v2-base-multilingual',
torch_dtype="auto",
trust_remote_code=True,
)
model.to('cuda') # GPU가 없는 경우 'cpu' 사용
model.eval()
쿼리와 재순위를 매길 문서를 정의하세요:
query = "Organic skincare products for sensitive skin"
documents = [
"Organic skincare for sensitive skin with aloe vera and chamomile.",
"New makeup trends focus on bold colors and innovative techniques",
"Bio-Hautpflege für empfindliche Haut mit Aloe Vera und Kamille",
"Neue Make-up-Trends setzen auf kräftige Farben und innovative Techniken",
"Cuidado de la piel orgánico para piel sensible con aloe vera y manzanilla",
"Las nuevas tendencias de maquillaje se centran en colores vivos y técnicas innovadoras",
"针对敏感肌专门设计的天然有机护肤产品",
"新的化妆趋势注重鲜艳的颜色和创新的技巧",
"敏感肌のために特別に設計された天然有機スキンケア製品",
"新しいメイクのトレンドは鮮やかな色と革新的な技術に焦点を当てています",
]
문장 쌍을 구성하고 관련성 점수를 계산하세요:
sentence_pairs = [[query, doc] for doc in documents]
scores = model.compute_score(sentence_pairs, max_length=1024)
점수는 부동 소수점 숫자의 리스트가 되며, 각 숫자는 해당 문서와 쿼리의 관련성 점수를 나타냅니다. 점수가 높을수록 관련성이 높습니다.
또는 rerank 함수를 사용하여 max_query_length를 기반으로 쿼리와 문서를 자동으로 청킹하여 큰 텍스트의 순위를 재조정할 수 있습니다
max_length를 사용하여 각 청크를 개별적으로 점수화합니다. 각 청크의 점수는 최종적인 재순위 결과를 생성하기 위해 결합됩니다:results = model.rerank(
query,
documents,
max_query_length=512,
max_length=1024,
top_n=3
)
이 함수는 각 문서의 관련성 점수뿐만 아니라 해당 문서의 내용과 원본 문서 목록에서의 위치도 반환합니다.
tag프라이빗 클라우드 배포를 통한 방법
Jina Reranker v2의 AWS 및 Azure 계정용 프라이빗 배포를 위한 사전 구축된 패키지는 곧 AWS Marketplace와 Azure Marketplace의 판매자 페이지에서 각각 찾아볼 수 있습니다.
tagJina Reranker v2의 주요 특징
Jina Reranker v2는 검색 기반의 중요한 기능 확장을 나타냅니다:
- 크로스 인코딩을 사용한 최신 검색 기술로 다양한 새로운 응용 분야를 개척합니다.
- 향상된 다국어 및 교차 언어 기능으로 사용 사례에서 언어 장벽을 제거합니다.
- 함수 호출에 대한 최고 수준의 지원과 구조화된 데이터 쿼리에 대한 인식으로 에이전트 RAG 기능을 한 단계 더 정밀하게 만듭니다.
- 컴퓨터 코드와 컴퓨터 형식 데이터의 향상된 검색으로 텍스트 정보 검색을 넘어설 수 있습니다.
- 훨씬 더 빠른 문서 처리량으로 검색 방법에 관계없이 이제 더 많은 검색된 문서를 더 빠르게 재순위화할 수 있으며, 세밀한 관련성 계산의 대부분을 jina-reranker-v2-base-multilingual에 맡길 수 있습니다.
RAG 시스템은 Reranker v2를 통해 훨씬 더 정밀해져, 기존 정보 관리 솔루션이 더 많고 더 나은 실행 가능한 결과를 생산하도록 돕습니다. 교차 언어 지원으로 다국적 및 다국어 기업에서 합리적인 가격에 사용하기 쉬운 API를 통해 이 모든 기능을 직접 사용할 수 있습니다.
실제 사용 사례에서 도출된 벤치마크로 테스트해보면, Jina Reranker v2가 실제 비즈니스 모델과 관련된 작업에서 최신 성능을 하나의 AI 모델로 유지하여 비용을 절감하고 기술 스택을 단순화하는 것을 직접 확인할 수 있습니다.
