


신규! 파트 II: 경계 큐와 오해에 대한 심층 분석.
약 1년 전인 2023년 10월, 우리는 세계 최초의 8K 컨텍스트 길이를 가진 오픈소스 임베딩 모델인 jina-embeddings-v2-base-en을 출시했습니다. 그 이후로 임베딩 모델의 긴 컨텍스트 유용성에 대한 많은 논쟁이 있었습니다. 많은 애플리케이션에서 수천 단어에 달하는 문서를 하나의 임베딩 표현으로 인코딩하는 것은 이상적이지 않습니다. 많은 사용 사례에서는 텍스트의 더 작은 부분을 검색해야 하며, 밀집 벡터 기반 검색 시스템은 의미론이 임베딩 벡터에서 "과도하게 압축"될 가능성이 낮기 때문에 더 작은 텍스트 세그먼트로 더 잘 작동하는 경우가 많습니다.
Retrieval-Augmented Generation (RAG)는 문서를 더 작은 텍스트 청크(예: 512 토큰 이내)로 분할해야 하는 가장 잘 알려진 애플리케이션 중 하나입니다. 이러한 청크들은 일반적으로 텍스트 임베딩 모델이 생성한 벡터 표현과 함께 벡터 데이터베이스에 저장됩니다. 런타임 중에 동일한 임베딩 모델이 쿼리를 벡터 표현으로 인코딩하고, 이를 사용하여 관련된 저장된 텍스트 청크를 식별합니다. 이러한 청크들은 이후 대규모 언어 모델(LLM)에 전달되어 검색된 텍스트를 기반으로 쿼리에 대한 응답을 생성합니다.

간단히 말해서, 더 작은 청크를 임베딩하는 것이 더 선호되는 것 같습니다. 이는 부분적으로 다운스트림 LLM의 제한된 입력 크기 때문이기도 하지만, 긴 컨텍스트의 중요한 문맥 정보가 단일 벡터로 압축될 때 희석될 수 있다는 우려 때문이기도 합니다.
하지만 만약 업계가 512 컨텍스트 길이의 임베딩 모델만 필요로 한다면, 8192 컨텍스트 길이의 모델을 훈련시키는 의미가 무엇일까요?
이 글에서는 RAG에서 단순한 청킹-임베딩 파이프라인의 한계를 탐구하면서 이 중요하지만 불편한 질문을 다시 살펴봅니다. 우리는 "Late Chunking"이라는 새로운 접근 방식을 소개합니다. 이는 8192 길이 임베딩 모델이 제공하는 풍부한 문맥 정보를 활용하여 청크를 더 효과적으로 임베딩하는 방법입니다.
tag잃어버린 문맥 문제
단순한 청킹-임베딩-검색-생성 RAG 파이프라인에는 여러 과제가 있습니다. 특히 이 과정은 장거리 문맥 의존성을 파괴할 수 있습니다. 다시 말해, 관련 정보가 여러 청크에 걸쳐 있을 때 텍스트 세그먼트를 문맥에서 분리하면 효과가 없어질 수 있어 이 접근 방식이 특히 문제가 됩니다.
아래 이미지에서 위키피디아 기사가 문장 단위로 청크로 분할되어 있습니다. "its"와 "the city"와 같은 구문이 첫 문장에서만 언급된 "Berlin"을 참조하는 것을 볼 수 있습니다. 이로 인해 임베딩 모델이 이러한 참조를 올바른 엔터티에 연결하기 어려워져 더 낮은 품질의 벡터 표현이 생성됩니다.

이는 위의 예시처럼 긴 기사를 문장 길이의 청크로 분할할 경우, RAG 시스템이 "베를린의 인구는 얼마입니까?"와 같은 쿼리에 답하는 데 어려움을 겪을 수 있다는 것을 의미합니다. 도시 이름과 인구가 단일 청크에 함께 나타나지 않고, 더 큰 문서 맥락이 없기 때문에 이러한 청크 중 하나를 제시받은 LLM은 "it"이나 "the city"와 같은 대용어를 해결할 수 없습니다.
슬라이딩 윈도우를 사용한 리샘플링, 여러 컨텍스트 윈도우 길이 사용, 다중 패스 문서 스캔 수행과 같은 이 문제를 완화하기 위한 휴리스틱이 있습니다. 하지만 모든 휴리스틱과 마찬가지로, 이러한 접근 방식은 성공할 수도 실패할 수도 있습니다. 일부 경우에는 작동할 수 있지만, 그 효과성에 대한 이론적 보장은 없습니다.
tag해결책: Late Chunking
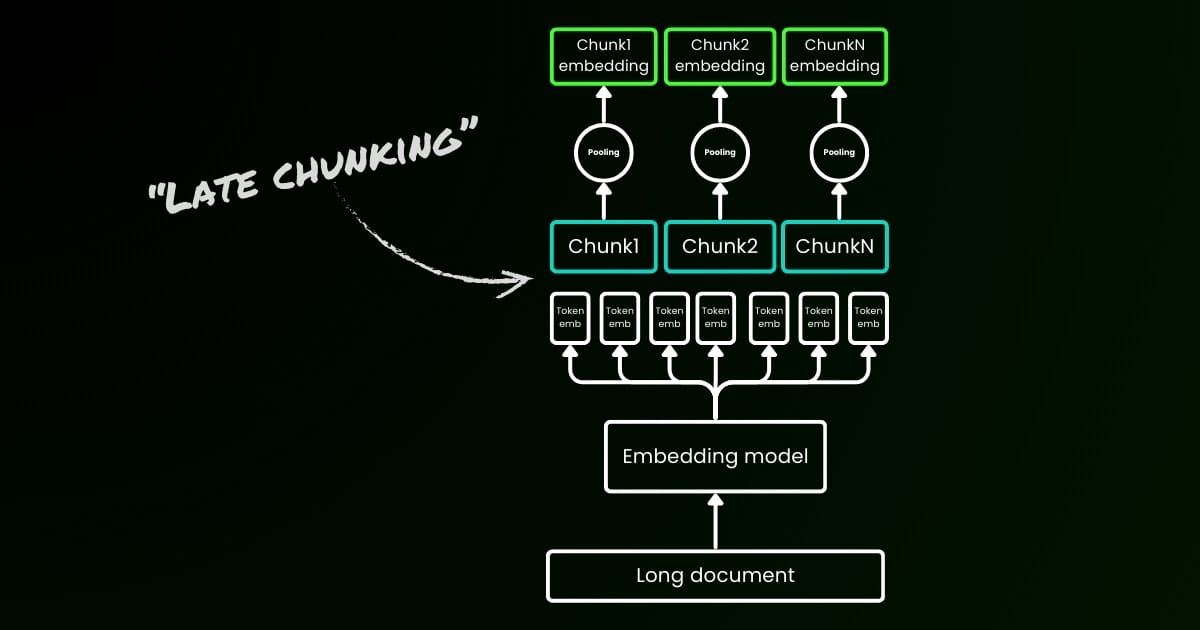
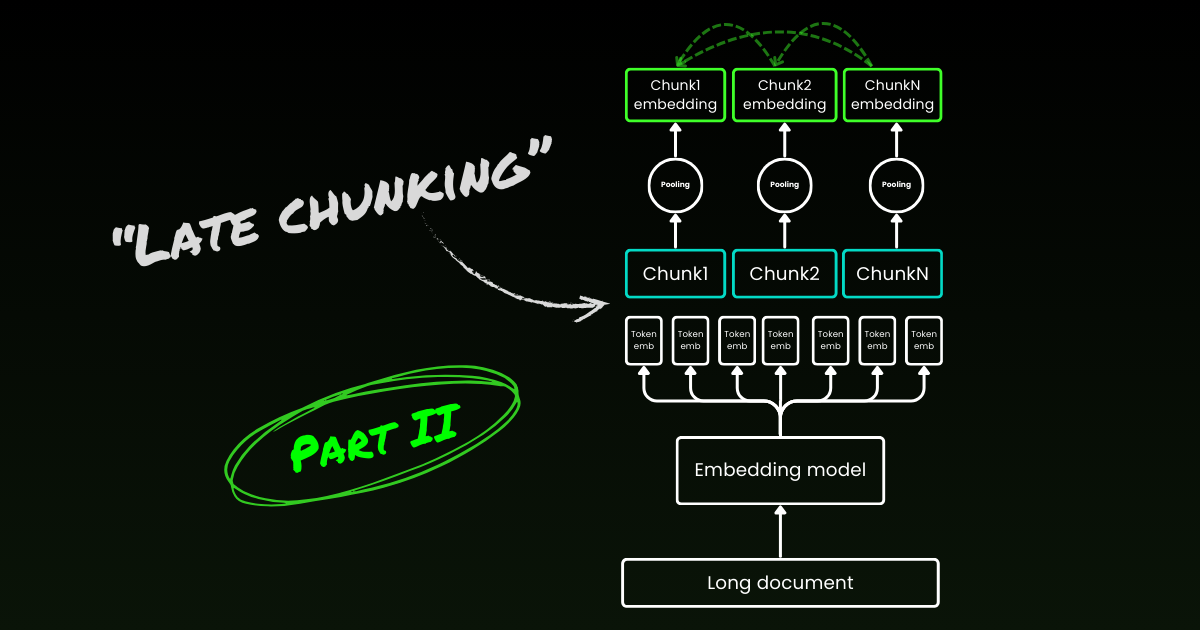
단순 인코딩 접근 방식(아래 이미지의 왼쪽)은 문장, 단락 또는 최대 길이 제한을 사용하여 텍스트를 선험적으로 분할합니다. 그 후 임베딩 모델이 이러한 결과 청크에 반복적으로 적용됩니다. 각 청크에 대한 단일 임베딩을 생성하기 위해 많은 임베딩 모델이 이러한 토큰 수준 임베딩에 평균 풀링을 사용하여 단일 임베딩 벡터를 출력합니다.

반면, 이 글에서 제안하는 "Late Chunking" 접근 방식은 먼저 임베딩 모델의 트랜스포머 레이어를 전체 텍스트 또는 가능한 한 많은 부분에 적용합니다. 이는 전체 텍스트의 정보를 포함하는 각 토큰에 대한 벡터 표현 시퀀스를 생성합니다. 이후 이 토큰 벡터 시퀀스의 각 청크에 평균 풀링이 적용되어 전체 텍스트의 문맥을 고려한 각 청크의 임베딩이 생성됩니다. 독립적이고 동일하게 분포된(i.i.d.) 청크 임베딩을 생성하는 단순 인코딩 접근 방식과 달리, late 청킹은 각 임베딩이 이전 임베딩에 "조건화된" 청크 임베딩 세트를 생성하여 각 청크에 대해 더 많은 문맥 정보를 인코딩합니다.
명백하게 late 청킹을 효과적으로 적용하려면 약 10페이지 분량의 텍스트인 8192 토큰까지 지원하는 jina-embeddings-v2-base-en과 같은 긴 컨텍스트 임베딩 모델이 필요합니다. 이 크기의 텍스트 세그먼트는 더 긴 컨텍스트로 해결해야 하는 문맥 의존성이 있을 가능성이 훨씬 낮습니다.
late 청킹에도 여전히 경계 큐가 필요하다는 점을 강조하는 것이 중요합니다. 하지만 이러한 큐는 토큰 수준 임베딩을 얻은 후에만 사용됩니다—이것이 이름에 "late"가 들어간 이유입니다.
| 단순 청킹 | Late 청킹 | |
|---|---|---|
| 경계 큐의 필요성 | 예 | 예 |
| 경계 큐의 사용 | 전처리에서 직접 | 트랜스포머 레이어에서 토큰 수준 임베딩을 얻은 후 |
| 결과 청크 임베딩 | i.i.d. | 조건부 |
| 근처 청크의 문맥 정보 | 손실. 일부 휴리스틱(중첩 샘플링 등)으로 완화 | 긴 컨텍스트 임베딩 모델로 잘 보존됨 |
tag구현 및 정성적 평가


late 청킹의 구현은 위의 Google Colab에서 찾을 수 있습니다. 여기서는 긴 문서를 의미 있는 청크로 분할하기 위해 가능한 모든 경계 큐를 활용하는 Tokenizer API의 최근 기능 릴리스를 활용합니다. 이 기능 뒤의 알고리즘에 대한 자세한 논의는 X에서 찾을 수 있습니다.

위의 Wikipedia 예시에 후기 청킹을 적용하면,의미적 유사성이 즉시 개선되는 것을 볼 수 있습니다. 예를 들어,Wikipedia 기사에서 "the city"와 "Berlin"의 경우,"the city"를 나타내는 벡터에는 이전에 언급된 "Berlin"과 연결하는 정보가 포함되어 있어,해당 도시 이름과 관련된 쿼리에 대해 훨씬 더 나은 매칭을 제공합니다.
| Query | Chunk | Sim. on naive chunking | Sim. on late chunking |
|---|---|---|---|
| Berlin | Berlin is the capital and largest city of Germany, both by area and by population. | 0.849 | 0.850 |
| Berlin | Its more than 3.85 million inhabitants make it the European Union's most populous city, as measured by population within city limits. | 0.708 | 0.825 |
| Berlin | The city is also one of the states of Germany, and is the third smallest state in the country in terms of area. | 0.753 | 0.850 |
위의 수치 결과에서 이를 관찰할 수 있는데,코사인 유사도를 사용하여 "Berlin"이라는 용어의 임베딩을 Berlin에 관한 기사의 다양한 문장과 비교한 것입니다. "Sim. on IID chunk embeddings" 열은 a priori 청킹을 사용한 "Berlin" 쿼리 임베딩과 임베딩 간의 유사도 값을 보여주며,"Sim. under contextual chunk embedding"은 후기 청킹 방법의 결과를 나타냅니다.
tagBEIR에 대한 정량적 평가
간단한 예시를 넘어 후기 청킹의 효과를 검증하기 위해,BeIR의 일부 검색 벤치마크를 사용하여 테스트했습니다. 이러한 검색 작업은 쿼리 세트,텍스트 문서 코퍼스,그리고 각 쿼리와 관련된 문서의 ID 정보를 저장하는 QRels 파일로 구성됩니다.
쿼리와 관련된 문서를 식별하기 위해,문서들은 청크로 나뉘고 임베딩 인덱스로 인코딩되며,k-최근접 이웃(kNN)을 사용하여 각 쿼리 임베딩에 대해 가장 유사한 청크가 결정됩니다. 각 청크가 문서에 해당하므로,청크의 kNN 순위는 문서의 kNN 순위로 변환될 수 있습니다(순위에서 여러 번 나타나는 문서의 경우 첫 번째 출현만 유지). 이 결과 순위는 그라운드 트루스 QRels 파일이 제공하는 순위와 비교되며,nDCG@10과 같은 검색 메트릭이 계산됩니다. 이 절차는 아래에 설명되어 있으며,재현성을 위한 평가 스크립트는 이 리포지토리에서 찾을 수 있습니다.
 jina-ai
jina-ai우리는 다양한 BeIR 데이터셋에서 이 평가를 실행하여 단순 청킹과 우리의 후기 청킹 방법을 비교했습니다. 경계 단서를 얻기 위해,텍스트를 대략 256 토큰의 문자열로 나누는 정규식을 사용했습니다. 단순 청킹과 후기 청킹 평가 모두 임베딩 모델로 jina-embeddings-v2-small-en을 사용했습니다; 이는 8192 토큰 길이를 지원하는 v2-base-en 모델의 더 작은 버전입니다. 결과는 아래 표에서 확인할 수 있습니다.
| Dataset | Avg. Document Length (characters) | Naive Chunking (nDCG@10) | Late Chunking (nDCG@10) | No Chunking (nDCG@10) |
|---|---|---|---|---|
| SciFact | 1498.4 | 64.20% | 66.10% | 63.89% |
| TRECCOVID | 1116.7 | 63.36% | 64.70% | 65.18% |
| FiQA2018 | 767.2 | 33.25% | 33.84% | 33.43% |
| NFCorpus | 1589.8 | 23.46% | 29.98% | 30.40% |
| Quora | 62.2 | 87.19% | 87.19% | 87.19% |
모든 경우에서 후기 청킹은 단순한 접근 방식에 비해 점수를 향상시켰습니다. 일부 경우에는 전체 문서를 단일 임베딩으로 인코딩하는 것보다 더 나은 성능을 보였으며,다른 데이터셋에서는 청킹을 전혀 하지 않는 것이 가장 좋은 결과를 냈습니다(물론,청크 순위를 매길 필요가 없는 경우에만 청킹을 하지 않는 것이 의미가 있으며,이는 실제로는 드문 경우입니다). 단순 접근 방식과 후기 청킹 간의 성능 차이를 문서 길이에 대해 플롯하면,문서의 평균 길이가 후기 청킹을 통한 nDCG 점수의 더 큰 개선과 상관관계가 있다는 것이 분명해집니다. 다시 말해,문서가 길수록 후기 청킹 전략이 더 효과적이 됩니다.

tag결론
이 글에서는 긴 컨텍스트 임베딩 모델의 능력을 활용하여 짧은 청크를 임베딩하는 "후기 청킹"이라는 간단한 접근 방식을 소개했습니다. 우리는 전통적인 i.i.d. 청크 임베딩이 컨텍스트 정보를 보존하지 못해 최적화되지 않은 검색으로 이어지는 방식을 보여주었고,후기 청킹이 각 청크 내의 컨텍스트 정보를 유지하고 조건화하는 간단하면서도 매우 효과적인 솔루션을 제공한다는 것을 보여주었습니다. 후기 청킹의 효과는 긴 문서에서 더욱 두드러지며,이는 jina-embeddings-v2-base-en과 같은 고급 긴 컨텍스트 임베딩 모델에 의해서만 가능한 기능입니다. 이 연구가 긴 컨텍스트 임베딩 모델의 중요성을 입증할 뿐만 아니라 이 주제에 대한 추가 연구도 촉진하기를 바랍니다.
파트 II 계속 읽기: 경계 단서와 오해에 대한 심층 분석.
