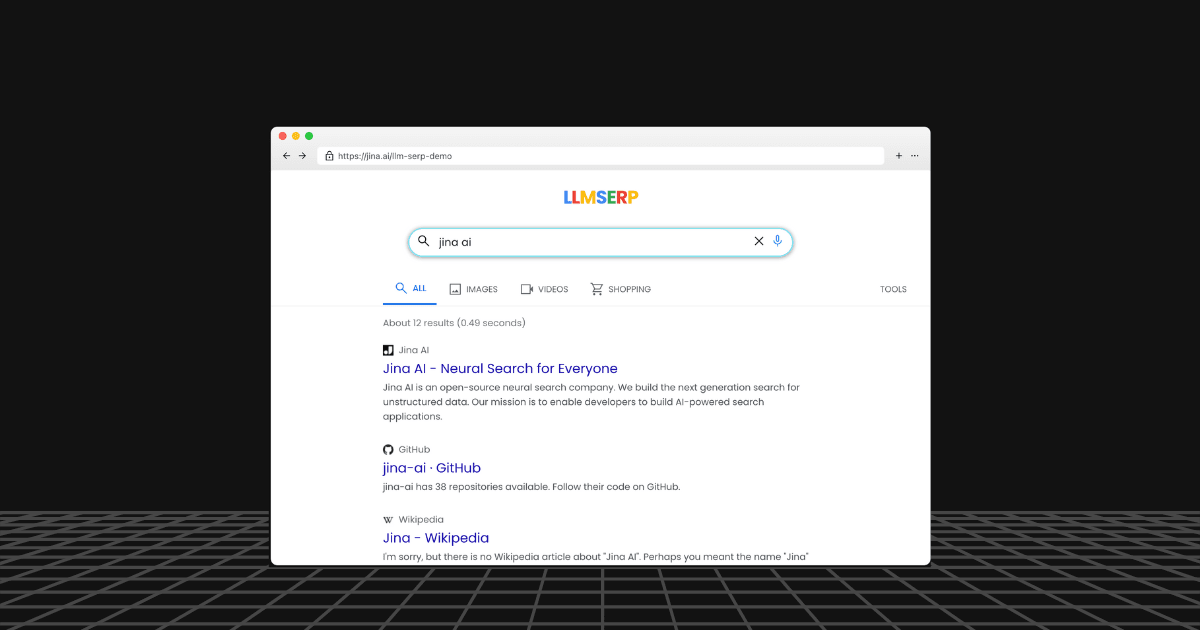


인터랙티브 데모를 통해 LLM SERP에서 여러분의 사이트가 어떻게 표시되는지 확인해보세요.
RAG 이후로, LLM을 사용하여 검색을 개선하는 것이 트렌드가 되었습니다. Perplexity에서 DeepSearch와 DeepResearch에 이르기까지, 검색 엔진 결과를 생성 프로세스에 주입하는 아이디어가 사실상 표준이 되었습니다. 많은 사용자들은 구글의 전통적인 페이지네이션 디자인이 시대에 뒤떨어지고, overwhelming하거나 지루하다고 느껴 예전만큼 자주 사용하지 않는다고 말합니다. 대신 채팅과 같은 검색 UI에서 나오는 QA 스타일 결과의 높은 정확도와 재현율에 익숙해졌으며, 이러한 디자인 철학이 앞으로의 방향이 될 수 있음을 시사합니다.
하지만 LLM 자체가 검색 엔진이라면 어떨까요?
마치 구글링을 하듯이 LLM에 내장된 지식을 탐색할 수 있다면 어떨까요? 페이지네이션, 링크 등 모든 것이 - 여러분이 익숙한 옛날 방식 그대로입니다. 무슨 말인지 잘 모르시겠다면, 아래 데모를 먼저 확인해보세요.
링크, 제목, 그리고 스니펫은 모두 LLM이 생성한 것입니다. https://jina.ai/llm-serp-demo에서 직접 쿼리를 시도해보세요!
환각 현상에 대한 우려를 제기하기 전에, 이 아이디어가 어느 정도 타당성이 있는 이유를 먼저 설명하겠습니다: LLM은 방대한 웹 지식 저장소로 학습되었습니다. DeepSeek-R1, GPT-4, Claude-3.7, Gemini-2.0과 같은 모델들은 공개된 인터넷에서 수조 개의 토큰으로 학습되었습니다. 대략적인 추정치로는 공개적으로 접근 가능한 고품질 웹 텍스트의 <1%에서 ~5%가 주요 모델 학습에 사용되었습니다.
이 수치가 너무 작다고 생각하신다면, 다음 비교를 고려해보세요: 구글의 인덱스를 기준(세계의 사용자 접근 가능 데이터의 100% 표현)으로 삼으면, Bing의 인덱스는 구글의 약 30-50%입니다. Baidu는 약 5-10%, Yandex는 3-5%를 커버합니다. Brave Search는 1% 미만을 인덱싱합니다. 따라서 LLM이 고품질 공개 데이터의 1-5%로 학습된다면, 이는 잠재적으로 적당한 소규모 검색 엔진이 제공할 수 있는 것과 동일한 양의 데이터와 맞먹을 수 있습니다.
이러한 모델들이 효과적으로 이 웹 데이터를 "기억"했기 때문에, 우리는 단순히 그들의 기억을 "활성화"하는 방식으로 프롬프트를 주어 검색 엔진처럼 기능하게 하고 검색 엔진 결과 페이지(SERP)와 유사한 결과를 생성하도록 할 수 있습니다.
네, 환각은 도전 과제이지만, 모델 기능이 각 반복마다 개선됨에 따라 이 문제가 완화될 것이라고 합리적으로 기대할 수 있습니다. X에서는 새로운 모델이 출시될 때마다 사람들이 처음부터 SVG를 생성하는 것에 집착하는 경향이 있는데, 각 버전이 이전보다 더 나은 일러스트레이션을 만들어내기를 바라는 것과 비슷합니다. 이 검색 엔진 아이디어도 LLM의 디지털 세계 이해도가 점진적으로 개선될 것이라는 비슷한 희망을 따릅니다.

qwen-2.5-max의 원샷 SVG 돼지 그리기 능력을 보여주고 있습니다.지식 컷오프 날짜는 또 다른 제한 사항입니다. 검색 엔진은 실시간에 가까운 정보를 반환해야 하지만, LLM 가중치는 학습 후 고정되므로 컷오프 날짜 이후의 정확한 정보를 제공할 수 없습니다. 일반적으로 쿼리가 이 컷오프 날짜에 가까울수록 환각이 발생할 가능성이 높아집니다. 오래된 정보는 더 자주 인용되고 다시 표현되었을 가능성이 높아 학습 데이터에서 가중치가 증가했을 수 있기 때문입니다. (이는 정보가 균일하게 가중치가 부여된다고 가정합니다; 속보는 최신성과 관계없이 불균형적인 주목을 받을 수 있습니다.) 하지만 이러한 제한은 실제로 이 접근 방식이 가장 유용할 수 있는 영역을 정확히 정의합니다—모델의 지식 시간대 내에 있는 정보에 대해서입니다.
tagLLM-as-SERP는 어디에서 유용할 수 있을까요?
DeepSearch/RAG 또는 다른 검색 그라운딩 시스템에서 핵심 과제는 질문이 외부 정보가 필요한지 아니면 모델의 지식으로 답변할 수 있는지 판단하는 것입니다. 현재 시스템들은 일반적으로 다음과 같은 지시사항으로 프롬프트 기반 라우팅을 사용합니다:
- For greetings, casual conversation, or general knowledge questions, answer directly without references.
- For all other questions, provide a verified answer with external knowledge. Each reference must include exactQuote and url.이 접근 방식은 양쪽 방향 모두에서 실패합니다 - 때로는 불필요한 검색을 트리거하고, 때로는 중요한 정보 요구를 놓칩니다. 특히 최신 추론 모델의 경우, 외부 데이터가 필요한지 여부는 생성 중간까지 명확하지 않은 경우가 많습니다.
만약 검색을 그냥 실행하면 어떨까요? 실제 검색 API 호출 한 번과 LLM-as-search 시스템 호출 한 번을 할 수 있습니다. 이렇게 하면 사전 라우팅 결정이 필요 없어지고, 실제 검색의 최신 데이터, 모델의 학습 컷오프 내의 지식, 그리고 잠재적으로 일부 잘못된 정보를 비교할 수 있는 다운스트림으로 이동시킬 수 있습니다.

최종 추론 단계에서는 불일치를 식별하고 최신성, 신뢰성, 결과 간의 합의를 기반으로 출처의 가중치를 평가할 수 있습니다. 이는 우리가 명시적으로 코딩할 필요가 없는데, LLM이 이미 잘하는 부분이기 때문입니다. 또한 검색 결과의 각 URL을 방문하여(예: Jina Reader 사용) 출처를 추가로 검증할 수 있습니다. 실제 구현에서는 이러한 검증 단계가 항상 필요합니다. 실제 검색 엔진이든 가짜 검색 엔진이든 검색 엔진의 발췌문에만 의존해서는 안 됩니다.
tag결론
LLM-as-SERP를 사용함으로써, 우리는 "이것이 모델의 지식 범위 내에 있는가 아닌가?"라는 이진적 질문을 더 강력한 증거 평가 프로세스로 전환합니다.
실험해 볼 수 있는 플레이그라운드와 우리가 호스팅하는 API 엔드포인트를 제공합니다. 또한 자유롭게 여러분의 DeepSearch/DeepResearch 구현에 통합하여 직접 개선 사항을 확인해보세요.

이 API는 결과 수, 페이지네이션, 국가, 언어 등을 정의할 수 있는 완전한 SERP 엔드포인트를 모방합니다. GitHub에서 구현 내용을 확인할 수 있습니다. 이 흥미로운 접근 방식에 대한 여러분의 피드백을 기다립니다.





