




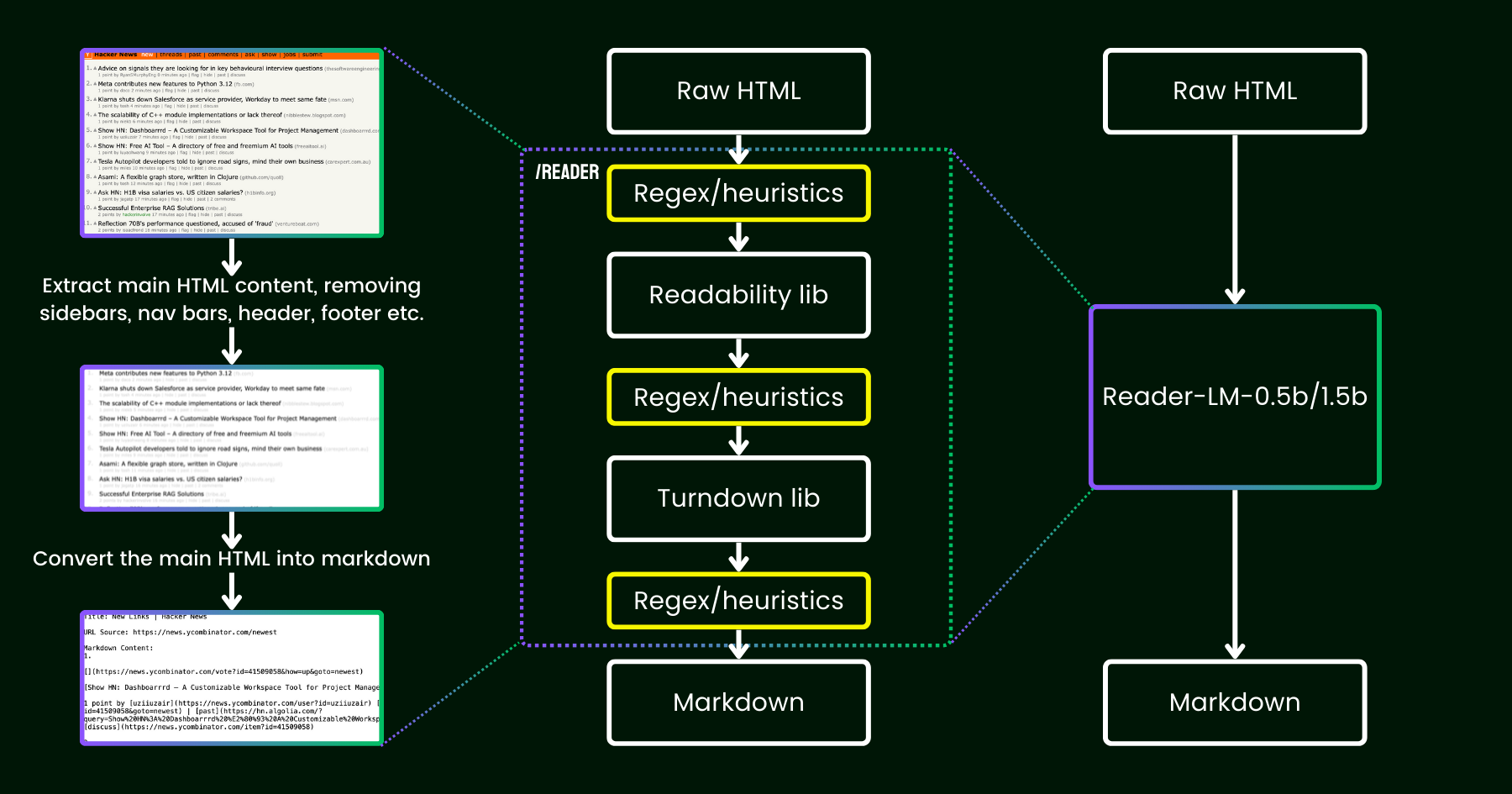
2024년 4월, 우리는 Jina Reader를 출시했습니다. 이는 단순히 r.jina.ai 접두사를 추가하는 것만으로 모든 URL을 LLM 친화적인 markdown으로 변환하는 간단한 API입니다. 백그라운드에서 이루어지는 복잡한 네트워크 프로그래밍에도 불구하고, 핵심 "읽기" 부분은 매우 간단합니다. 먼저, 헤드리스 Chrome 브라우저를 사용하여 웹페이지의 소스를 가져옵니다. 그런 다음 Mozilla의 Readability 패키지를 활용하여 헤더, 푸터, 내비게이션 바, 사이드바와 같은 요소들을 제거하고 주요 콘텐츠를 추출합니다. 마지막으로, regex와 Turndown 라이브러리를 사용하여 정리된 HTML을 markdown으로 변환합니다. 결과물은 LLM이 그라운딩, 요약, 추론에 사용할 수 있는 잘 구조화된 markdown 파일입니다.
Jina Reader 출시 후 첫 몇 주 동안, 우리는 특히 콘텐츠 품질에 관한 많은 피드백을 받았습니다. 일부 사용자들은 너무 상세하다고 느꼈고, 다른 사용자들은 충분히 상세하지 않다고 느꼈습니다. 또한 Readability 필터가 잘못된 콘텐츠를 제거하거나 Turndown이 HTML의 특정 부분을 markdown으로 변환하는 데 어려움을 겪었다는 보고도 있었습니다. 다행히도 이러한 문제들의 대부분은 새로운 regex 패턴이나 휴리스틱으로 기존 파이프라인을 패치하여 성공적으로 해결되었습니다.
그 이후로 우리는 한 가지 질문을 고민해왔습니다: 더 많은 휴리스틱과 regex로 패치하는 대신(이는 유지보수가 점점 어려워지고 다국어 지원에 친화적이지 않음), 언어 모델을 사용하여 이 문제를 end-to-end 방식으로 해결할 수 있을까요?
reader-lm의 도식화.첫 눈에 보기에는 낮은 비용 효율성과 느린 속도 때문에 데이터 정제에 LLM을 사용하는 것이 과도해 보일 수 있습니다. 하지만 만약 우리가 작은 언어 모델(SLM) - 10억 개 미만의 파라미터를 가지고 edge에서 효율적으로 실행될 수 있는 모델을 고려한다면 어떨까요? 그것은 훨씬 더 매력적으로 들리지 않나요? 하지만 이것이 정말 실현 가능한 것일까요, 아니면 단순한 희망 사항일까요? 스케일링 법칙에 따르면, 파라미터가 적을수록 일반적으로 추론과 요약 능력이 감소합니다. 따라서 SLM은 파라미터 크기가 너무 작으면 의미 있는 콘텐츠를 생성하는 데도 어려움을 겪을 수 있습니다. 이를 더 자세히 살펴보기 위해 HTML-to-Markdown 작업을 살펴보겠습니다:
- 첫째, 우리가 고려하고 있는 작업은 일반적인 LLM 작업만큼 창의적이거나 복잡하지 않습니다. HTML을 markdown으로 변환하는 경우, 모델은 주로 입력에서 출력으로 선택적 복사를 수행해야 하며(즉, HTML 마크업, 사이드바, 헤더, 푸터를 건너뛰기), 새로운 콘텐츠를 생성하는 데는 최소한의 노력만 필요합니다(주로 markdown 구문 삽입). 이는 시나 코드를 작성하는 것과 같이 출력이 훨씬 더 창의적이고 입력에서 직접적인 복사-붙여넣기가 아닌 더 넓은 LLM 작업과는 크게 대조됩니다. 이러한 관찰은 작업이 더 일반적인 텍스트 생성보다 단순해 보이기 때문에 SLM이 작동할 수 있다는 것을 시사합니다.
- 둘째, 우리는 긴 컨텍스트 지원을 우선시해야 합니다. 현대의 HTML은 종종 단순한
<div>마크업보다 훨씬 더 많은 노이즈를 포함합니다. 인라인 CSS와 스크립트는 쉽게 코드를 수십만 토큰으로 부풀릴 수 있습니다. SLM이 이러한 시나리오에서 실용적이려면 컨텍스트 길이가 충분히 커야 합니다. 8K나 16K와 같은 토큰 길이는 전혀 유용하지 않습니다.
우리에게 필요한 것은 얕지만 넓은 SLM인 것 같습니다. "얕다"는 것은 작업이 주로 단순한 "복사-붙여넣기"이므로 더 적은 트랜스포머 블록이 필요하다는 의미이고, "넓다"는 것은 실용적이기 위해 긴 컨텍스트 지원이 필요하므로 어텐션 메커니즘에 신경 써야 한다는 의미입니다. 이전 연구에 따르면 컨텍스트 길이와 추론 능력은 밀접하게 연관되어 있습니다. SLM의 경우, 파라미터 크기를 작게 유지하면서 두 차원을 모두 최적화하는 것은 매우 어려운 과제입니다.
오늘 우리는 reader-lm-0.5b와 reader-lm-1.5b의 첫 번째 버전을 발표하게 되어 기쁩니다. 이 두 SLM은 노이즈가 많은 raw HTML에서 직접 깔끔한 markdown을 생성하도록 특별히 훈련된 모델입니다. 두 모델 모두 다국어를 지원하고 최대 256K 토큰의 컨텍스트 길이를 지원합니다. 작은 크기에도 불구하고, 이 모델들은 이 작업에서 최고의 성능을 달성하여, 크기가 1/50에 불과함에도 더 큰 LLM들을 능가합니다.

다음은 두 모델의 사양입니다:
| reader-lm-0.5b | reader-lm-1.5b | |
|---|---|---|
| # Parameters | 494M | 1.54B |
| Context length | 256K | 256K |
| Hidden Size | 896 | 1536 |
| # Layers | 24 | 28 |
| # Query Heads | 14 | 12 |
| # KV Heads | 2 | 2 |
| Head Size | 64 | 128 |
| Intermediate Size | 4864 | 8960 |
| Multilingual | Yes | Yes |
| HuggingFace Repo | Link | Link |
tagReader-LM 시작하기
tagGoogle Colab에서
reader-lm을 경험하는 가장 쉬운 방법은 우리의 Colab 노트북을 실행하는 것입니다. 여기서는 reader-lm-1.5b를 사용하여 Hacker News 웹사이트를 markdown으로 변환하는 방법을 보여줍니다. 이 노트북은 Google Colab의 무료 T4 GPU 환경에서 원활하게 실행되도록 최적화되어 있습니다. reader-lm-0.5b를 로드하거나 URL을 다른 웹사이트로 변경하여 출력을 탐색할 수도 있습니다. 모델에 대한 입력(즉, 프롬프트)은 raw HTML이며 - 접두 지시사항이 필요하지 않다는 점에 유의하세요.

무료 T4 GPU에는 모델 실행 중 고급 최적화 사용을 제한할 수 있는 한계가 있음을 유의하시기 바랍니다. T4에서는 bfloat16 및 flash attention과 같은 기능을 사용할 수 없어, 더 긴 입력에 대해 더 높은 VRAM 사용량과 성능 저하가 발생할 수 있습니다. 프로덕션 환경에서는 상당히 향상된 성능을 위해 RTX 3090/4090와 같은 고성능 GPU 사용을 권장합니다.
tag프로덕션에서: 곧 Azure & AWS에서 사용 가능
Reader-LM은 Azure Marketplace와 AWS SageMaker에서 사용할 수 있습니다. 이러한 플랫폼 이외의 환경이나 사내에서 이 모델들을 사용해야 하는 경우, 두 모델 모두 CC BY-NC 4.0 라이선스로 제공됨을 참고하시기 바랍니다. 상업적 사용 문의는 언제든 연락 주시기 바랍니다.


tag벤치마크
Reader-LM의 성능을 정량적으로 평가하기 위해 GPT-4o, Gemini-1.5-Flash, Gemini-1.5-Pro, LLaMA-3.1-70B, Qwen2-7B-Instruct를 포함한 여러 대형 언어 모델과 비교했습니다.
모델들은 다음과 같은 메트릭으로 평가되었습니다:
- ROUGE-L (높을수록 좋음): 요약 및 질의응답 작업에 널리 사용되는 이 메트릭은 예측된 출력과 참조 간의 n-gram 수준에서의 중복을 측정합니다.
- Token Error Rate (TER, 낮을수록 좋음): 이 메트릭은 생성된 마크다운 토큰이 원본 HTML 콘텐츠에 나타나지 않는 비율을 계산합니다. 이 메트릭은 모델이 HTML에 근거하지 않은 내용을 생성하는 경우를 식별하는 데 도움이 되도록 설계되었으며, 사례 연구를 바탕으로 추가 개선이 이루어질 예정입니다.
- Word Error Rate (WER, 낮을수록 좋음): OCR과 ASR 작업에서 일반적으로 사용되는 WER은 단어 시퀀스를 고려하고 삽입(ADD), 대체(SUB), 삭제(DEL)와 같은 오류를 계산합니다. 이 메트릭은 생성된 마크다운과 예상 출력 간의 불일치를 상세하게 평가합니다.
이 작업에 LLM을 활용하기 위해 다음과 같은 통일된 지시문을 프롬프트 접두사로 사용했습니다:
Your task is to convert the content of the provided HTML file into the corresponding markdown file. You need to convert the structure, elements, and attributes of the HTML into equivalent representations in markdown format, ensuring that no important information is lost. The output should strictly be in markdown format, without any additional explanations.결과는 아래 표에서 확인할 수 있습니다.
| ROUGE-L | WER | TER | |
|---|---|---|---|
| reader-lm-0.5b | 0.56 | 3.28 | 0.34 |
| reader-lm-1.5b | 0.72 | 1.87 | 0.19 |
| gpt-4o | 0.43 | 5.88 | 0.50 |
| gemini-1.5-flash | 0.40 | 21.70 | 0.55 |
| gemini-1.5-pro | 0.42 | 3.16 | 0.48 |
| llama-3.1-70b | 0.40 | 9.87 | 0.50 |
| Qwen2-7B-Instruct | 0.23 | 2.45 | 0.70 |
tag정성적 연구
출력된 마크다운을 시각적으로 검사하여 정성적 연구를 수행했습니다. 영어, 독일어, 일본어, 중국어로 된 뉴스 기사, 블로그 포스트, 랜딩 페이지, 이커머스 페이지, 포럼 게시물을 포함한 22개의 HTML 소스를 선택했습니다. 또한 정규식, 휴리스틱, 사전 정의된 규칙에 의존하는 Jina Reader API를 기준선으로 포함했습니다.
평가는 출력의 네 가지 주요 차원에 중점을 두었으며, 각 모델은 1(최저)에서 5(최고) 척도로 평가되었습니다:
- 헤더 추출: 각 모델이 문서의 h1, h2,..., h6 헤더를 식별하고 올바른 마크다운 구문을 사용하여 포맷팅하는 정도를 평가했습니다.
- 주요 콘텐츠 추출: 모델이 본문 텍스트를 정확하게 변환하고, 단락을 보존하며, 목록을 포맷팅하고, 프레젠테이션의 일관성을 유지하는 능력을 평가했습니다.
- 풍부한 구조 보존: 각 모델이 제목, 부제목, 글머리 기호, 순서가 있는 목록을 포함한 문서의 전체 구조를 효과적으로 유지하는 방법을 분석했습니다.
- 마크다운 구문 사용: 각 모델이
<a>(링크),<strong>(굵은 텍스트),<em>(이탤릭체)과 같은 HTML 요소를 적절한 마크다운 등가물로 올바르게 변환하는 능력을 평가했습니다.
결과는 아래에서 확인할 수 있습니다.

Reader-LM-1.5B는 모든 차원에서 일관되게 좋은 성능을 보이며, 특히 구조 보존과 마크다운 구문 사용에서 뛰어났습니다. Jina Reader API를 항상 능가하지는 않지만, Gemini 1.5 Pro와 같은 더 큰 모델들과 경쟁력 있는 성능을 보여 더 큰 LLM의 매우 효율적인 대안이 됩니다. Reader-LM-0.5B는 더 작지만, 특히 구조 보존에서 견실한 성능을 제공합니다.
tagReader-LM을 훈련시킨 방법
tag데이터 준비
Jina Reader API를 사용하여 원시 HTML과 해당하는 마크다운의 훈련 쌍을 생성했습니다. 실험 중에 SLM이 훈련 데이터의 품질에 특히 민감하다는 것을 발견했습니다. 따라서 고품질 마크다운 항목만 훈련 세트에 포함되도록 하는 데이터 파이프라인을 구축했습니다.
또한 GPT-4o로 생성된 일부 합성 HTML과 그에 상응하는 마크다운을 추가했습니다. 실제 HTML과 비교하여 합성 데이터는 일반적으로 훨씬 짧고, 더 단순하고 예측 가능한 구조를 가지며, 노이즈 수준이 현저히 낮습니다.
마지막으로 채팅 템플릿을 사용하여 HTML과 마크다운을 연결했습니다. 최종 훈련 데이터는 다음과 같이 포맷됩니다:
<|im_start|>system
You are a helpful assistant.<|im_end|>
<|im_start|>user
{{RAW_HTML}}<|im_end|>
<|im_start|>assistant
{{MARKDOWN}}<|im_end|>
전체 훈련 데이터는 25억 토큰에 달합니다.
tag2단계 훈련
65M부터 135M, 최대 3B 파라미터까지 다양한 모델 크기로 실험을 진행했습니다. 각 모델의 세부 사양은 아래 표에서 확인할 수 있습니다.
| reader-lm-65m | reader-lm-135m | reader-lm-360m | reader-lm-0.5b | reader-lm-1.5b | reader-lm-1.7b | reader-lm-3b | |
|---|---|---|---|---|---|---|---|
| Hidden Size | 512 | 576 | 960 | 896 | 1536 | 2048 | 3072 |
| # Layers | 8 | 30 | 32 | 24 | 28 | 24 | 32 |
| # Query Heads | 16 | 9 | 15 | 14 | 12 | 32 | 32 |
| # KV Heads | 8 | 3 | 5 | 2 | 2 | 32 | 32 |
| Head Size | 32 | 64 | 64 | 64 | 128 | 64 | 96 |
| Intermediate Size | 2048 | 1536 | 2560 | 4864 | 8960 | 8192 | 8192 |
| Attention Bias | False | False | False | True | True | False | False |
| Embedding Tying | False | True | True | True | True | True | False |
| Vocabulary Size | 32768 | 49152 | 49152 | 151646 | 151646 | 49152 | 32064 |
| Base Model | Lite-Oute-1-65M-Instruct | SmolLM-135M | SmolLM-360M-Instruct | Qwen2-0.5B-Instruct | Qwen2-1.5B-Instruct | SmolLM-1.7B | Phi-3-mini-128k-instruct |
모델 훈련은 두 단계로 진행되었습니다:
- 단순하고 짧은 HTML: 이 단계에서는 최대 시퀀스 길이(HTML + markdown)를 32K 토큰으로 설정했으며, 총 15억 개의 훈련 토큰을 사용했습니다.
- 길고 복잡한 HTML: 시퀀스 길이를 128K 토큰으로 확장했으며, 12억 개의 훈련 토큰을 사용했습니다. 이 단계에서는 Zilin Zhu의 "Ring Flash Attention" (2024)에서 제안된 지그재그-링-어텐션 메커니즘을 구현했습니다.
훈련 데이터에 최대 128K 토큰의 시퀀스가 포함되어 있었기 때문에, 모델이 256K 토큰까지는 문제없이 처리할 수 있을 것으로 생각됩니다. 하지만 512K 토큰을 처리하는 것은 어려울 수 있는데, 이는 RoPE 위치 임베딩을 훈련 시퀀스 길이의 4배로 확장하면 성능이 저하될 수 있기 때문입니다.
65M과 135M 파라미터 모델의 경우, 짧은 시퀀스(1K 토큰 미만)에서는 합리적인 "복사" 동작을 달성할 수 있었습니다. 하지만 입력 길이가 증가함에 따라 이러한 모델들은 합리적인 출력을 생성하는 데 어려움을 겪었습니다. 현대의 HTML 소스 코드가 쉽게 100K 토큰을 초과할 수 있다는 점을 고려할 때, 1K 토큰 제한은 매우 불충분합니다.
tag퇴화와 단조로운 반복
우리가 직면한 주요 과제 중 하나는 퇴화였으며, 특히 반복과 순환의 형태로 나타났습니다. 일부 토큰을 생성한 후, 모델은 동일한 토큰을 반복적으로 생성하거나 짧은 토큰 시퀀스를 최대 허용 출력 길이에 도달할 때까지 계속해서 반복하는 순환에 빠지곤 했습니다.

이 문제를 해결하기 위해:
- 디코딩 방법으로 contrastive search를 적용하고 훈련 중에 contrastive loss를 포함시켰습니다. 실험 결과, 이 방법은 반복적인 생성을 효과적으로 줄였습니다.
- transformer 파이프라인 내에 간단한 반복 중지 기준을 구현했습니다. 이 기준은 모델이 토큰을 반복하기 시작할 때 자동으로 감지하고 단조로운 반복을 피하기 위해 디코딩을 조기에 중단합니다. 이 아이디어는 이 토론에서 영감을 받았습니다.
tag긴 입력에 대한 훈련 효율성
긴 입력을 처리할 때 메모리 부족(OOM) 오류의 위험을 줄이기 위해 청크 단위 모델 포워딩을 구현했습니다. 이 접근 방식은 긴 입력을 더 작은 청크로 인코딩하여 VRAM 사용량을 줄입니다.
Transformers Trainer를 기반으로 한 훈련 프레임워크에서 데이터 패킹 구현을 개선했습니다. 훈련 효율성을 최적화하기 위해 여러 개의 짧은 텍스트(예: 2K 토큰)를 하나의 긴 시퀀스(예: 30K 토큰)로 연결하여 패딩이 없는 훈련을 가능하게 했습니다. 그러나 원래 구현에서는 일부 짧은 예제들이 두 개의 하위 텍스트로 분할되어 서로 다른 긴 훈련 시퀀스에 포함되었습니다. 이런 경우 두 번째 하위 텍스트는 컨텍스트(예: 우리의 경우 원시 HTML 내용)를 잃게 되어 훈련 데이터가 손상됩니다. 이는 모델이 입력 컨텍스트가 아닌 파라미터에만 의존하도록 만들며, 이것이 환각의 주요 원인이라고 생각합니다.
최종적으로 우리는 0.5B와 1.5B 모델을 공개용으로 선택했습니다. 0.5B 모델은 긴 컨텍스트 입력에서 원하는 "선택적 복사" 동작을 달성할 수 있는 가장 작은 모델이며, 1.5B 모델은 파라미터 크기 대비 수익 체감 없이 성능을 크게 향상시킬 수 있는 가장 작은 대형 모델입니다.
tag대체 아키텍처: 인코더 전용 모델
이 프로젝트 초기에는 이 작업을 해결하기 위해 인코더 전용 아키텍처를 사용하는 방법도 탐색했습니다. 앞서 언급했듯이 HTML-to-Markdown 변환 작업은 주로 "선택적 복사" 작업으로 보입니다. 훈련 쌍(원시 HTML과 markdown)이 주어졌을 때, 입력과 출력 모두에 존재하는 토큰을 1로, 나머지는 0으로 레이블링할 수 있습니다. 이는 문제를 Named Entity Recognition (NER)에서 사용되는 것과 유사한 토큰 분류 작업으로 변환합니다.
이 접근 방식이 논리적으로 보였지만 실제로는 상당한 어려움이 있었습니다. 첫째, 실제 소스에서 가져온 원시 HTML은 매우 노이즈가 많고 길어서 1 레이블이 매우 드물게 나타나므로 모델이 학습하기 어렵습니다. 둘째, ## title, *bold*, | table |와 같은 특수 markdown 구문을 0-1 스키마로 인코딩하는 것이 문제가 되었는데, 이는 이러한 기호들이 원시 HTML 입력에 존재하지 않기 때문입니다. 셋째, 출력 토큰이 항상 입력의 순서를 엄격히 따르지는 않습니다. 특히 테이블과 링크에서는 약간의 재정렬이 자주 발생하는데, 이러한 재정렬 동작을 간단한 0-1 스키마로 표현하기 어렵습니다. 단거리 재정렬은 거리 오프셋을 나타내는 -1, -2, +1, +2와 같은 레이블을 도입하여 이진 분류 문제를 다중 클래스 토큰 분류 작업으로 변환함으로써 동적 프로그래밍이나 정렬-왜곡 알고리즘으로 처리할 수 있습니다.
요약하면, 인코더 전용 아키텍처를 사용하고 이를 토큰 분류 작업으로 취급하는 것은 특히 훈련 시퀀스가 디코더 전용 모델에 비해 훨씬 짧아 VRAM 사용이 더 효율적이라는 점에서 매력적입니다. 하지만 주요 과제는 좋은 훈련 데이터를 준비하는 데 있습니다. 완벽한 토큰 수준 레이블링 시퀀스를 만들기 위해 동적 프로그래밍과 휴리스틱을 사용하는 데 들이는 시간과 노력이 압도적이라는 것을 깨달았을 때, 우리는 이 접근 방식을 중단하기로 결정했습니다.
tag결론
Reader-LM은 오픈 웹에서의 데이터 추출 및 정제를 위해 설계된 새로운 소형 언어 모델(SLM)입니다. Jina Reader에서 영감을 받아, 저희는 원시의 노이즈가 있는 HTML을 깔끔한 markdown으로 변환할 수 있는 엔드투엔드 언어 모델 솔루션을 만들고자 했습니다. 동시에 Reader-LM이 실용적이고 사용 가능한 상태를 유지할 수 있도록 모델 크기를 작게 유지하며 비용 효율성에 중점을 두었습니다. 이는 또한 Jina AI에서 훈련된 최초의 긴 컨텍스트를 지원하는 디코더 전용 모델입니다.
이 작업이 처음에는 단순한 "선택적 복사" 문제로 보일 수 있지만, HTML을 markdown으로 변환하고 정제하는 것은 결코 쉽지 않습니다. 특히 모델이 위치 인식 및 컨텍스트 기반 추론에서 뛰어난 성능을 발휘해야 하며, 이는 특히 은닉층에서 더 큰 파라미터 크기를 필요로 합니다. 이에 비해 markdown 문법을 학습하는 것은 상대적으로 간단합니다.
실험 과정에서 처음부터 SLM을 훈련시키는 것이 특히 어렵다는 것도 발견했습니다. 사전 훈련된 모델로 시작하여 작업별 훈련을 계속하는 것이 훈련 효율성을 크게 향상시켰습니다. 효율성과 품질 면에서 여전히 개선의 여지가 많이 있습니다: 컨텍스트 길이 확장, 디코딩 속도 향상, 그리고 입력에서 지시사항 지원 추가 등이 있으며, 이를 통해 Reader-LM이 웹페이지의 특정 부분을 markdown으로 추출할 수 있게 될 것입니다.
