



2023년 10월, 우리는 8,192 토큰까지 처리할 수 있는 최초의 오픈소스 임베딩 모델군인 jina-embeddings-v2를 소개했습니다. 이를 바탕으로 올해 우리는 동일한 광범위한 입력 지원과 함께 추가 개선 사항을 제공하는 jina-embeddings-v3를 출시했습니다.

이 포스트에서는 긴 컨텍스트 임베딩에 대해 자세히 살펴보고 몇 가지 질문에 답해보겠습니다: 이렇게 많은 양의 텍스트를 단일 벡터로 통합하는 것이 실용적인 경우는 언제일까요? 세그먼테이션이 검색을 향상시키나요? 만약 그렇다면 어떻게 향상시키나요? 텍스트를 세그먼트화하면서 문서의 다른 부분에서 컨텍스트를 어떻게 보존할 수 있을까요?
이러한 질문에 답하기 위해 여러 임베딩 생성 방법을 비교해보겠습니다:
- 긴 컨텍스트 임베딩(문서에서 최대 8,192 토큰까지 인코딩) vs 짧은 컨텍스트(즉, 192 토큰에서 잘라내기).
- 청킹 없음 vs. 단순 청킹 vs. 후기 청킹.
- 단순 청킹과 후기 청킹 모두에서의 다양한 청크 크기.
tag긴 컨텍스트는 정말 유용할까요?
최대 10페이지의 텍스트를 단일 임베딩으로 인코딩할 수 있는 능력으로, 긴 컨텍스트 임베딩 모델은 대규모 텍스트 표현의 가능성을 열어줍니다. 하지만 그것이 정말 유용할까요? 많은 사람들의 의견에 따르면...아니라고 합니다.




출처: How AI Is Built 팟캐스트의 Nils Reimer 인용, brainlag 트윗, egorfine Hacker News 댓글, andy99 Hacker News 댓글
우리는 긴 컨텍스트 기능에 대한 자세한 조사, 긴 컨텍스트가 도움이 되는 경우, 그리고 언제 사용해야 하고 (하지 말아야 하는지)에 대해 이러한 모든 우려 사항을 다룰 것입니다. 하지만 먼저, 이러한 회의론자들의 의견을 듣고 긴 컨텍스트 임베딩 모델이 직면한 몇 가지 문제를 살펴보겠습니다.
tag긴 컨텍스트 임베딩의 문제점
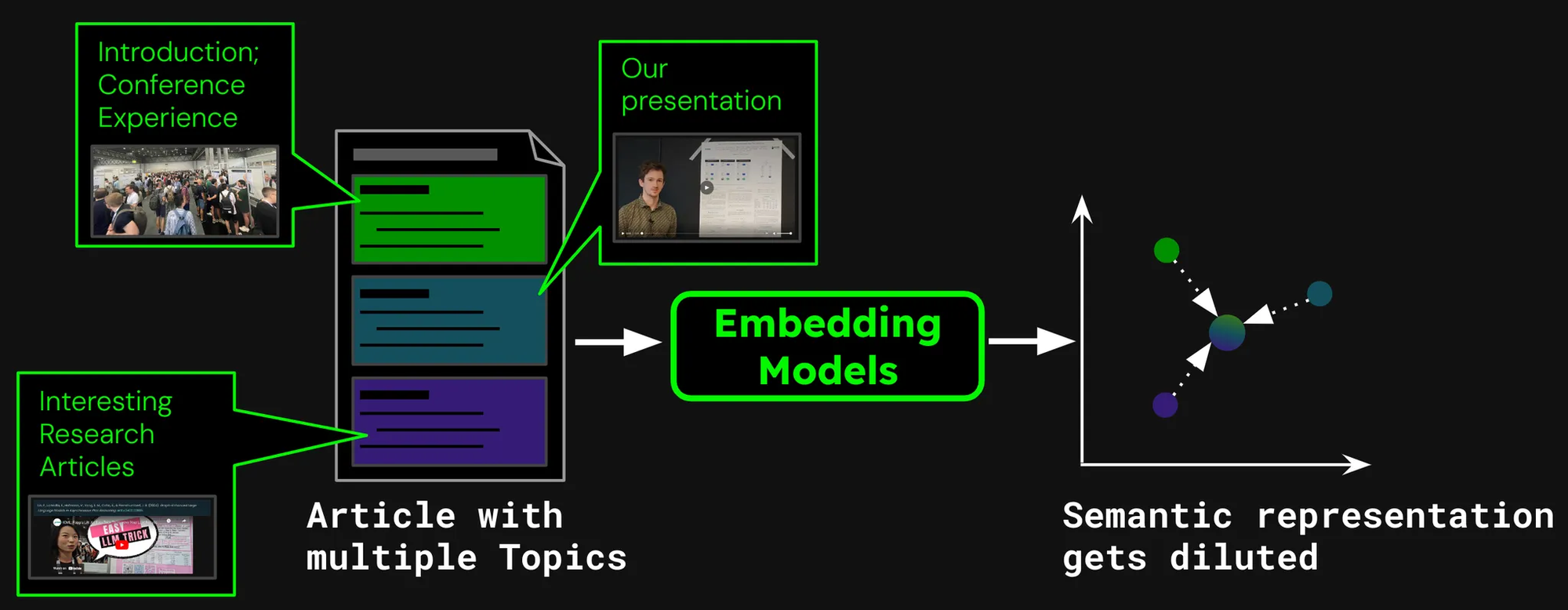
Jina AI 블로그와 같은 문서 검색 시스템을 구축한다고 상상해보세요. 때로는 하나의 글이 여러 주제를 다룰 수 있습니다. 예를 들어 ICML 2024 컨퍼런스 방문 보고서는 다음과 같은 내용을 포함합니다:
- ICML에 대한 일반적인 정보(참가자 수, 장소, 범위 등)를 담은 소개.
- 우리의 연구 발표(jina-clip-v1).
- ICML에서 발표된 다른 흥미로운 연구 논문들의 요약.
이 글에 대해 하나의 임베딩만 생성한다면, 그 임베딩은 세 가지 서로 다른 주제의 혼합을 나타내게 됩니다:
이는 여러 문제를 야기합니다:
- 표현 희석: 주어진 텍스트의 모든 주제가 관련될 수 있지만, 사용자의 검색 쿼리와 관련된 것은 하나일 수 있습니다. 하지만 단일 임베딩(이 경우 전체 블로그 포스트의 임베딩)은 벡터 공간에서 단 하나의 점입니다. 모델 입력에 더 많은 텍스트가 추가될수록, 임베딩은 글의 전반적인 주제를 캡처하도록 이동하여 특정 단락에서 다루는 내용을 효과적으로 표현하지 못하게 됩니다.
- 제한된 용량: 임베딩 모델은 입력 길이와 관계없이 고정된 크기의 벡터를 생성합니다. 입력에 더 많은 내용이 추가될수록, 모델이 이 모든 정보를 벡터로 표현하기가 어려워집니다. 이는 이미지를 16×16 픽셀로 축소하는 것과 같습니다 - 사과와 같이 단순한 이미지는 축소해도 의미를 파악할 수 있지만, 베를린의 거리 지도는 그렇지 않습니다.
- 정보 손실: 어떤 경우에는 긴 컨텍스트 임베딩 모델도 한계에 부딪힙니다. 많은 모델이 최대 8,192 토큰까지의 텍스트 인코딩을 지원합니다. 더 긴 문서는 임베딩 전에 잘라내야 하므로 정보 손실이 발생합니다. 사용자와 관련된 정보가 문서 끝에 있다면, 그 정보는 임베딩에 전혀 캡처되지 않을 것입니다.
- 텍스트 세그먼테이션이 필요할 수 있음: 일부 애플리케이션은 전체 문서가 아닌 텍스트의 특정 세그먼트에 대한 임베딩이 필요합니다. 예를 들어 텍스트에서 관련 구절을 식별하는 경우가 있습니다.
tag긴 컨텍스트 vs. 잘라내기
긴 컨텍스트가 전혀 가치가 있는지 알아보기 위해, 두 가지 검색 시나리오의 성능을 살펴보겠습니다:
- 최대 8,192 토큰(약 10페이지의 텍스트)까지 문서 인코딩.
- 192 토큰에서 문서를 잘라내고 거기까지만 인코딩.
다음을 사용하여 결과를 비교해보겠습니다jina-embeddings-v3의 nDCG@10 검색 메트릭으로 평가했습니다. 다음 데이터셋들을 테스트했습니다:
| 데이터셋 | 설명 | 쿼리 예시 | 문서 예시 | 평균 문서 길이(문자) |
|---|---|---|---|---|
| NFCorpus | PubMed에서 가져온 3,244개의 쿼리와 문서로 구성된 전체 텍스트 의료 검색 데이터셋입니다. | "Using Diet to Treat Asthma and Eczema" | "Statin Use and Breast Cancer Survival: A Nationwide Cohort Study from Finland Recent studies have suggested that [...]" | 326,753 |
| QMSum | 관련 회의 세그먼트의 요약이 필요한 쿼리 기반 회의 요약 데이터셋입니다. | "The professor was the one to raise the issue and suggested that a knowledge engineering trick [...]" | "Project Manager: Is that alright now ? {vocalsound} Okay . Sorry ? Okay , everybody all set to start the meeting ? [...]" | 37,445 |
| NarrativeQA | 긴 이야기와 특정 내용에 대한 질문이 포함된 QA 데이터셋입니다. | "What kind of business Sophia owned in Paris?" | "The Project Gutenberg EBook of The Old Wives' Tale, by Arnold Bennett\n\nThis eBook is for the use of anyone anywhere [...]" | 53,336 |
| 2WikiMultihopQA | 지름길을 피하기 위해 템플릿으로 설계된 최대 5단계의 추론 단계가 있는 멀티홉 QA 데이터셋입니다. | "What is the award that the composer of song The Seeker (The Who Song) earned?" | "Passage 1:\nMargaret, Countess of Brienne\nMarguerite d'Enghien (born 1365 - d. after 1394), was the ruling suo jure [...]" | 30,854 |
| SummScreenFD | 분산된 플롯 통합이 필요한 TV 시리즈 대본과 요약으로 구성된 대본 요약 데이터셋입니다. | "Penny gets a new chair, which Sheldon enjoys until he finds out that she picked it up from [...]" | "[EXT. LAS VEGAS CITY (STOCK) - NIGHT]\n[EXT. ABERNATHY RESIDENCE - DRIVEWAY -- NIGHT]\n(The lamp post light over the [...]" | 1,613 |
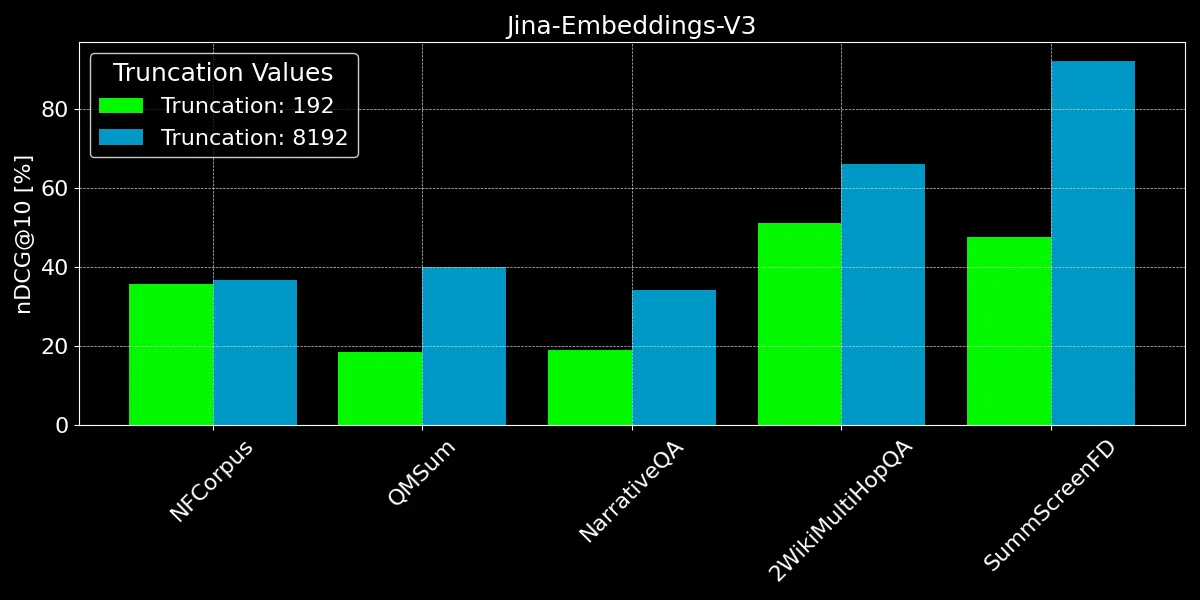
보시다시피 192개 토큰 이상을 인코딩하면 주목할 만한 성능 향상을 얻을 수 있습니다:
하지만 일부 데이터셋에서는 다른 데이터셋보다 더 큰 개선이 있었습니다:
- NFCorpus의 경우, 잘라내기가 거의 차이를 만들지 않습니다. 이는 제목과 초록이 문서의 시작 부분에 있고, 이것들이 일반적인 사용자 검색어와 매우 관련이 있기 때문입니다. 잘라내기 여부와 관계없이 가장 관련성 높은 데이터는 토큰 제한 내에 유지됩니다.
- QMSum과 NarrativeQA는 사용자가 일반적으로 텍스트 내의 특정 사실을 검색하는 "독해" 작업으로 간주됩니다. 이러한 사실들은 종종 문서 전체에 흩어져 있는 세부 사항에 포함되어 있으며, 192 토큰 제한을 벗어날 수 있습니다. 예를 들어, NarrativeQA 문서 Percival Keene에서 "Percival의 점심을 훔치는 불량배는 누구인가?"라는 질문의 답은 이 제한을 훨씬 넘어서 있습니다. 마찬가지로 2WikiMultiHopQA에서는 쿼리에 효과적으로 답하기 위해 여러 섹션의 지식을 탐색하고 종합해야 하므로 관련 정보가 전체 문서에 분산되어 있습니다.
- SummScreenFD는 주어진 요약과 일치하는 대본을 식별하는 작업입니다. 요약이 대본 전체에 분산된 정보를 포함하고 있기 때문에 더 많은 텍스트를 인코딩하면 요약을 올바른 대본과 매칭하는 정확도가 향상됩니다.
tag더 나은 검색 성능을 위한 텍스트 분할
• 분할(Segmentation): 입력 텍스트에서 문장이나 고정된 수의 토큰과 같은 경계 신호를 감지하는 것
• 단순 청킹(Naive chunking): 인코딩하기 전에 분할 신호를 기반으로 텍스트를 청크로 나누는 것
• 후기 청킹(Late chunking): 문서를 먼저 인코딩한 다음 분할하는 것(청크 간의 문맥을 보존)
전체 문서를 하나의 벡터로 임베딩하는 대신, 경계 신호를 할당하여 문서를 먼저 분할하는 다양한 방법을 사용할 수 있습니다:

일반적인 방법은 다음과 같습니다:
- 고정 크기로 분할: 임베딩 모델의 토크나이저에 의해 결정된 고정된 수의 토큰으로 문서를 분할합니다. 이는 세그먼트의 토큰화가 전체 문서의 토큰화와 일치하도록 보장합니다(특정 문자 수로 분할하면 다른 토큰화가 될 수 있음).
- 문장으로 분할: 문서를 문장으로 분할하고, 각 청크는 n개의 문장으로 구성됩니다.
- 의미로 분할: 각 세그먼트는 여러 문장에 해당하며 임베딩 모델이 연속된 문장들의 유사성을 결정합니다. 임베딩 유사도가 높은 문장들은 같은 청크에 할당됩니다.
단순화를 위해 이 글에서는 고정 크기 분할을 사용합니다.
tag단순 청킹을 사용한 문서 검색
고정 크기 분할을 수행한 후에는 해당 세그먼트에 따라 문서를 단순하게 청킹할 수 있습니다:
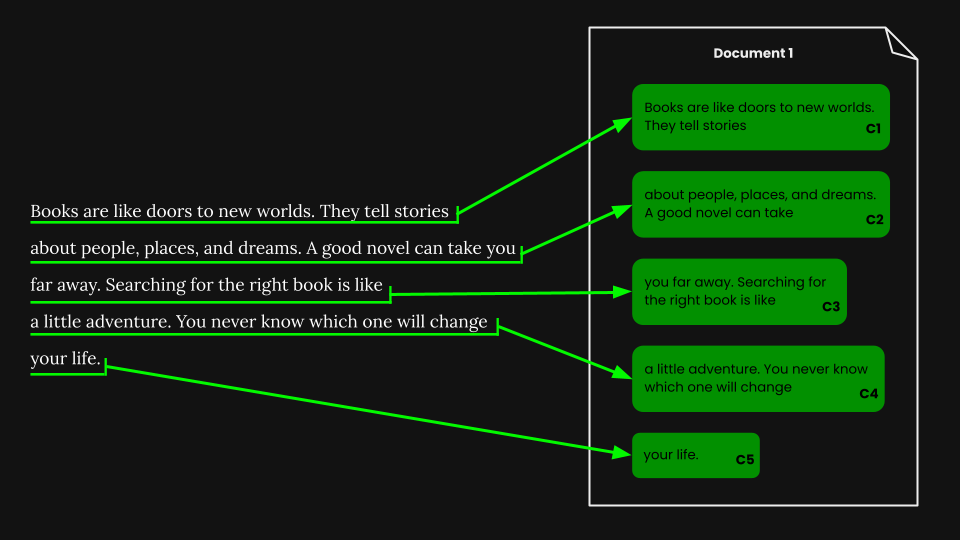
jina-embeddings-v3를 사용하여 각 청크를 의미를 정확하게 포착하는 임베딩으로 인코딩한 다음, 이러한 임베딩들을 벡터 데이터베이스에 저장합니다.
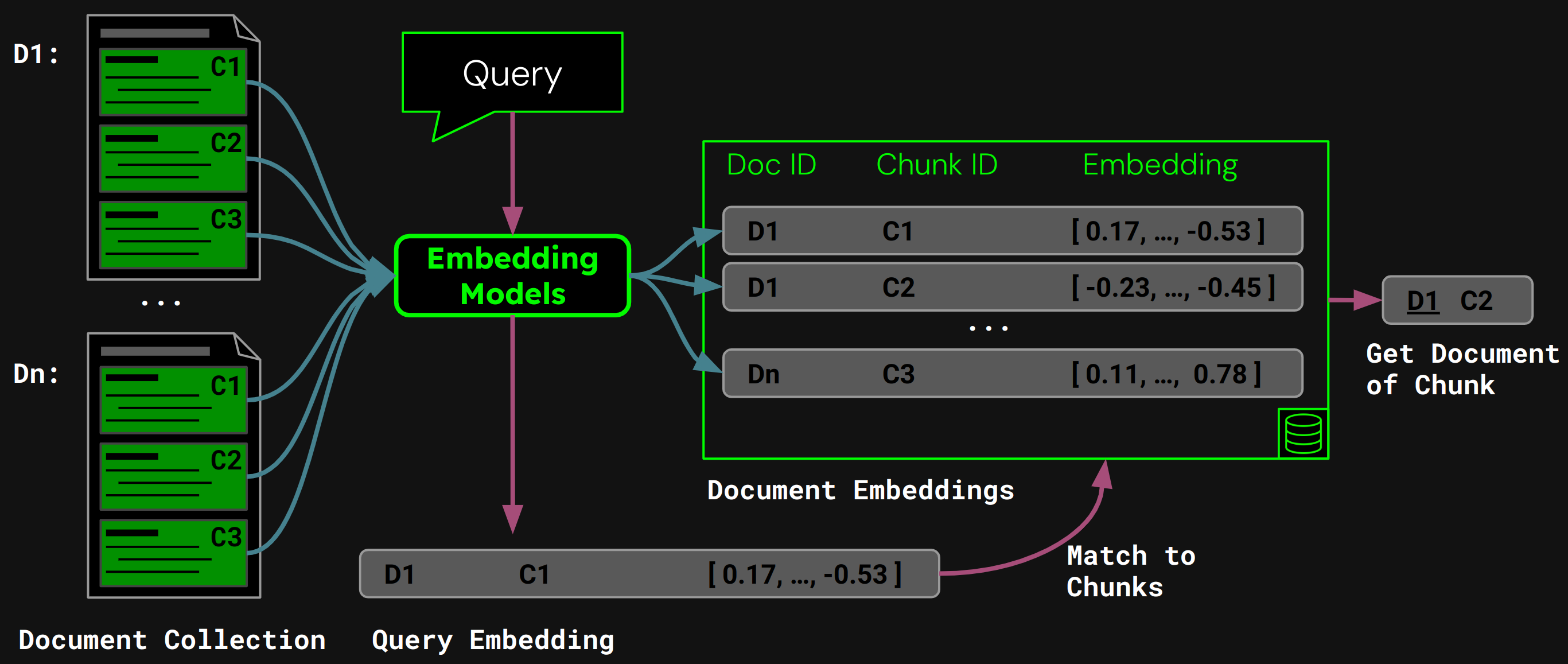
런타임에서 모델은 사용자의 쿼리를 쿼리 벡터로 인코딩합니다. 이를 청크 임베딩의 벡터 데이터베이스와 비교하여 코사인 유사도가 가장 높은 청크를 찾은 다음, 해당하는 문서를 사용자에게 반환합니다:
tag단순 청킹의 문제점

단순 청킹이 긴 컨텍스트 임베딩 모델의 일부 제한사항을 해결하긴 하지만, 다음과 같은 단점도 있습니다:
- 큰 그림을 놓침: 문서 검색에서 작은 청크들의 여러 임베딩은 문서의 전체적인 주제를 포착하지 못할 수 있습니다. 나무만 보고 숲을 보지 못하는 것과 같습니다.
- 컨텍스트 누락 문제: 그림 6에서 보듯이 컨텍스트 정보가 누락되어 청크를 정확하게 해석할 수 없습니다.
- 효율성: 더 많은 청크는 더 많은 저장 공간을 필요로 하고 검색 시간을 증가시킵니다.
tag후기 청킹이 컨텍스트 문제를 해결합니다
후기 청킹은 두 가지 주요 단계로 작동합니다:
- 먼저, 모델의 긴 컨텍스트 기능을 사용하여 전체 문서를 토큰 임베딩으로 인코딩합니다. 이는 문서의 전체 컨텍스트를 보존합니다.
- 그런 다음, 분할 과정에서 식별된 경계 신호에 해당하는 특정 토큰 임베딩 시퀀스에 평균 풀링을 적용하여 청크 임베딩을 생성합니다.
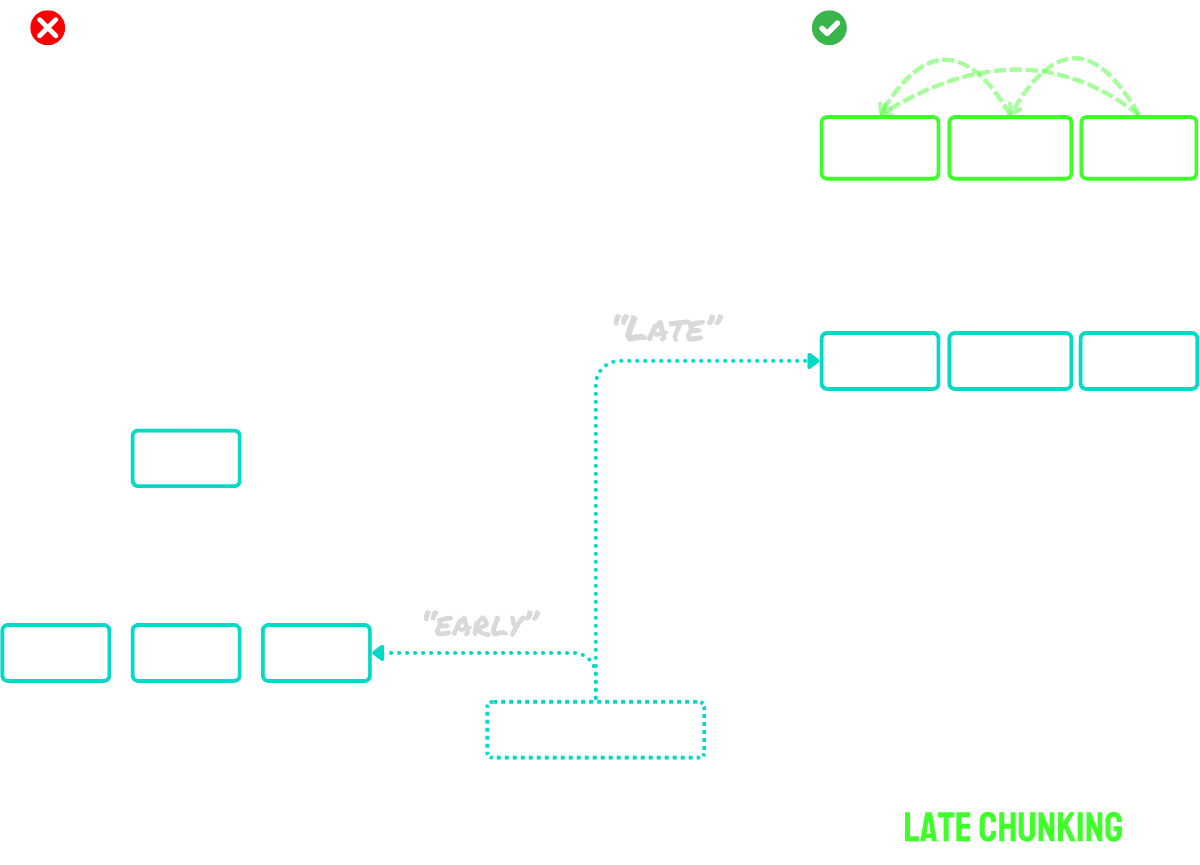
이 접근 방식의 주요 장점은 토큰 임베딩이 문맥화되어 있다는 것입니다 - 즉, 문서의 다른 부분에 대한 참조와 관계를 자연스럽게 포착합니다. 임베딩 과정이 청킹 전에 이루어지기 때문에, 각 청크는 단순 청킹 접근 방식에서 발생하는 컨텍스트 누락 문제를 해결하면서 더 넓은 문서 컨텍스트에 대한 인식을 유지합니다.
모델의 최대 입력 크기를 초과하는 문서의 경우, "긴 후기 청킹"을 사용할 수 있습니다:
- 먼저, 문서를 겹치는 "매크로 청크"로 나눕니다. 각 매크로 청크는 모델의 최대 컨텍스트 길이(예: 8,192 토큰) 내에 맞도록 크기가 조정됩니다.
- 모델이 이러한 매크로 청크를 처리하여 토큰 임베딩을 생성합니다.
- 토큰 임베딩을 얻은 후, 표준 후기 청킹을 진행합니다 - 평균 풀링을 적용하여 최종 청크 임베딩을 생성합니다.
이 접근 방식을 통해 후기 청킹의 이점을 유지하면서 모든 길이의 문서를 처리할 수 있습니다. 이를 두 단계 프로세스로 생각하면 됩니다: 먼저 문서를 모델이 처리할 수 있게 만든 다음, 일반적인 후기 청킹 절차를 적용합니다.
요약하면:
- 단순 청킹: 문서를 작은 청크로 분할한 다음, 각 청크를 별도로 인코딩합니다.
- 후기 청킹: 전체 문서를 한 번에 인코딩하여 토큰 임베딩을 생성한 다음, 세그먼트 경계를 기반으로 토큰 임베딩을 풀링하여 청크 임베딩을 생성합니다.
- 긴 후기 청킹: 큰 문서를 모델의 컨텍스트 윈도우에 맞는 겹치는 매크로 청크로 분할하고, 이를 인코딩하여 토큰 임베딩을 얻은 다음, 일반적인 후기 청킹을 적용합니다.
아이디어에 대한 더 자세한 설명은 우리의 논문이나 위에서 언급한 블로그 포스트를 참고하세요.
tag청킹을 할 것인가 말 것인가?
우리는 이미 긴 컨텍스트 임베딩이 일반적으로 짧은 텍스트 임베딩보다 성능이 좋다는 것을 보았고, 단순 청킹과 후기 청킹 전략에 대해 개요를 살펴보았습니다. 이제 질문은: 청킹이 긴 컨텍스트 임베딩보다 더 나은가요?
공정한 비교를 위해, 우리는 텍스트 값을 분할하기 전에 모델의 최대 시퀀스 길이(8,192 토큰)로 자릅니다. 분할 크기를 64 토큰으로 고정하여 사용합니다(단순 분할과 후기 청킹 모두). 세 가지 시나리오를 비교해 보겠습니다:
- 분할 없음: 각 텍스트를 하나의 임베딩으로 인코딩합니다. 이는 이전 실험(그림 2 참조)과 동일한 점수를 보여주지만, 더 나은 비교를 위해 여기에 포함시킵니다.
- 단순 청킹: 텍스트를 분할한 다음, 경계 신호를 기반으로 단순 청킹을 적용합니다.
- 후기 청킹: 텍스트를 분할한 다음, 후기 청킹을 사용하여 임베딩을 결정합니다.
후기 청킹과 단순 분할 모두에서, 관련 문서를 결정하기 위해 청크 검색을 사용합니다(이전 포스트의 그림 5에서 보여진 것처럼).
결과는 명확한 승자를 보여주지 않습니다:
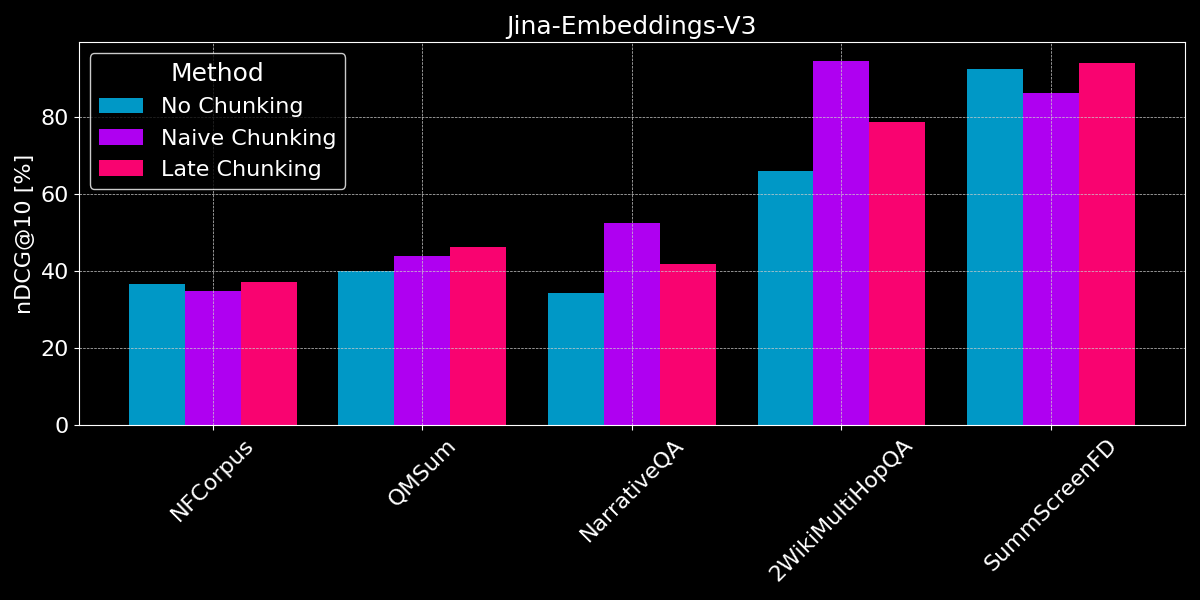
- 사실 검색의 경우, 단순 청킹이 더 나은 성능을 보입니다: QMSum, NarrativeQA, 2WikiMultiHopQA 데이터셋에서 모델은 문서에서 관련 구절을 식별해야 합니다. 여기서는 단순 청킹이 모든 것을 하나의 임베딩으로 인코딩하는 것보다 확실히 더 나은데, 이는 아마도 몇 개의 청크만이 관련 정보를 포함하고 있고, 해당 청크들이 전체 문서의 단일 임베딩보다 그 정보를 훨씬 더 잘 포착하기 때문입니다.
tag청크 크기가 차이를 만드나요?
분할 방법의 효과는 데이터셋에 따라 크게 달라지며, 이는 콘텐츠 구조가 중요한 역할을 한다는 것을 보여줍니다:
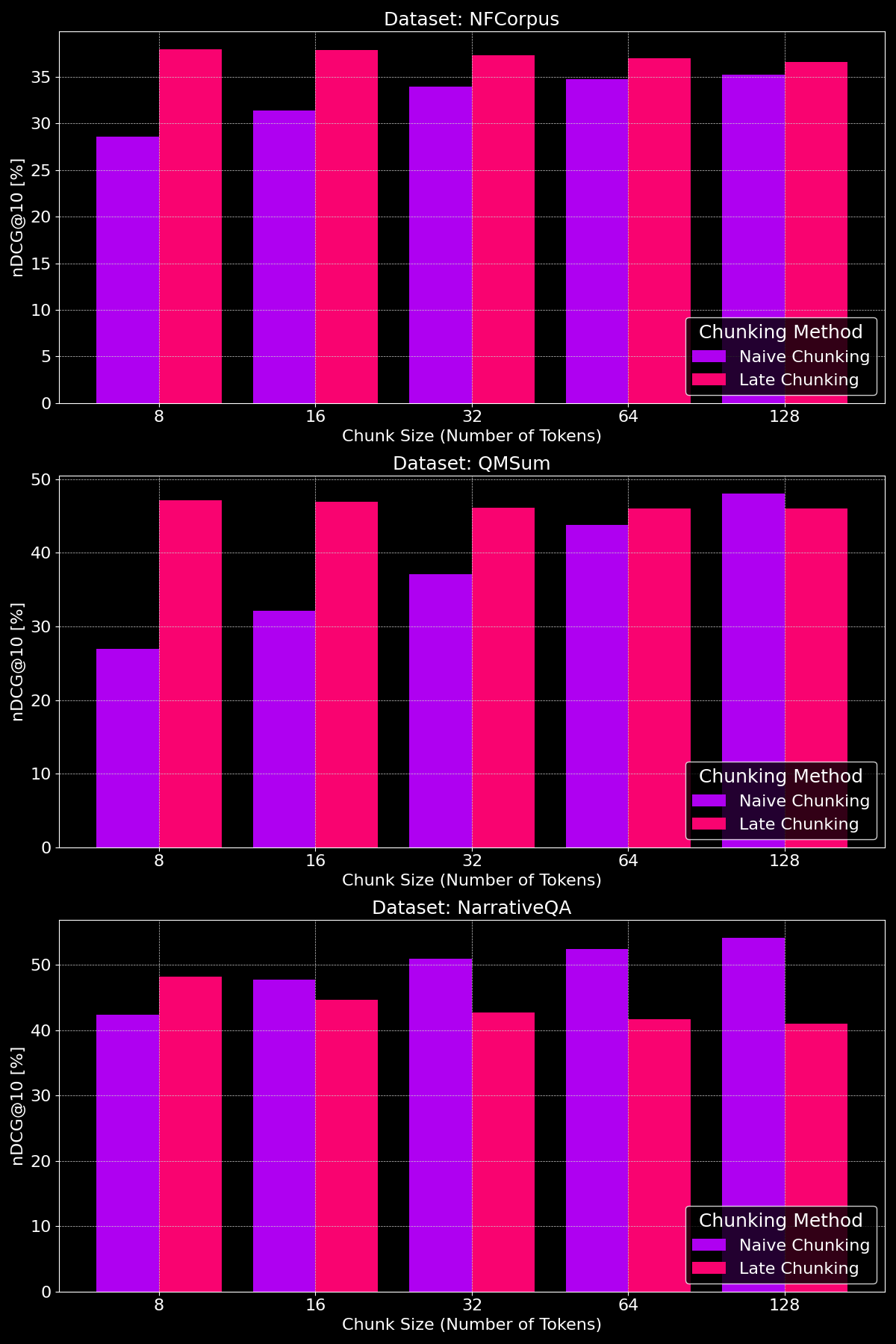
보시다시피, 후기 분할은 일반적으로 작은 청크 크기에서 단순 분할보다 더 나은 성능을 보입니다. 작은 단순 분할 청크는 컨텍스트를 거의 포함하지 못하는 반면, 작은 후기 분할 청크는 전체 문서의 컨텍스트를 유지하여 의미적으로 더 유의미하기 때문입니다. NarrativeQA 데이터셋은 예외인데, 너무 많은 관련 없는 컨텍스트가 있어서 후기 분할이 뒤처집니다. 더 큰 청크 크기에서는 단순 분할이 현저한 개선을 보이며(때로는 후기 분할을 능가함) 컨텍스트가 증가하는 반면, 후기 분할의 성능은 점차 감소합니다.
tag핵심 포인트: 어떤 상황에서 무엇을 사용할까요?
이 글에서는 다양한 유형의 문서 검색 작업을 살펴보며 언제 분할을 사용하고 언제 후기 분할이 도움이 되는지 더 잘 이해하고자 했습니다. 그래서, 우리가 배운 것은 무엇일까요?
tag긴 컨텍스트 임베딩은 언제 사용해야 할까요?
일반적으로 임베딩 모델의 입력에 문서의 텍스트를 최대한 많이 포함시키는 것은 검색 정확도에 해를 끼치지 않습니다. 하지만 긴 컨텍스트 임베딩 모델은 주로 문서의 시작 부분에 집중하는 경향이 있습니다. 제목과 소개와 같이 관련성을 판단하는 데 더 중요한 내용이 포함되어 있지만, 모델이 문서 중간의 내용을 놓칠 수 있기 때문입니다.
tag단순 분할은 언제 사용해야 할까요?
문서가 여러 측면을 다루거나 사용자 쿼리가 문서 내의 특정 정보를 대상으로 할 때, 분할은 일반적으로 검색 성능을 향상시킵니다.
결국 분할 결정은 사용자에게 부분 텍스트를 표시해야 하는 필요성(예: Google이 검색 결과 미리보기에서 관련 구절을 표시하는 것처럼)이나 계산 및 메모리 제약과 같은 요소에 따라 달라집니다. 분할은 검색 오버헤드와 자원 사용이 증가하기 때문에 덜 선호될 수 있습니다.
tag후기 분할은 언제 사용해야 할까요?
전체 문서를 인코딩한 후 청크를 생성함으로써, 후기 분할은 텍스트 세그먼트가 컨텍스트 부족으로 의미를 잃는 문제를 해결합니다. 이는 각 부분이 전체와 연관되는 일관성 있는 문서에서 특히 잘 작동합니다. 우리의 실험은 후기 분할이 텍스트를 더 작은 청크로 나눌 때 특히 효과적이라는 것을 보여주며, 이는 우리의 논문에서 입증되었습니다. 하지만 한 가지 주의할 점이 있습니다: 문서의 일부가 서로 관련이 없는 경우, 이러한 더 넓은 컨텍스트를 포함하면 임베딩에 노이즈를 추가하여 실제로 검색 성능이 저하될 수 있습니다.
tag결론
긴 컨텍스트 임베딩, 단순 분할, 후기 분할 중 선택은 검색 작업의 특정 요구 사항에 따라 달라집니다. 긴 컨텍스트 임베딩은 일반적인 쿼리가 있는 일관성 있는 문서에 유용하며, 분할은 사용자가 문서 내에서 특정 사실이나 정보를 찾는 경우에 뛰어납니다. 후기 분할은 더 작은 세그먼트 내에서 문맥적 일관성을 유지함으로써 검색을 더욱 향상시킵니다. 결국 데이터와 검색 목표를 이해하는 것이 정확성, 효율성, 문맥적 관련성의 균형을 맞추는 최적의 접근 방식을 결정하는 데 도움이 될 것입니다.
이러한 전략들을 탐색하고 있다면 jina-embeddings-v3를 시도해 보세요—고급 긴 컨텍스트 기능, 후기 분할, 유연성을 갖춘 이 모델은 다양한 검색 시나리오에 탁월한 선택이 될 것입니다.

