


최근 LAION AI의 설립자인 Christoph Schuhmann이 텍스트 임베딩 모델에 대한 흥미로운 관찰을 공유했습니다:
문장 내의 단어들이 무작위로 섞여도, 텍스트 임베딩 간의 코사인 유사도는 원래 문장과 비교했을 때 놀랍게도 높은 수준을 유지합니다.
예를 들어, 다음 두 문장을 살펴보겠습니다: Berlin is the capital of Germany와 the Germany Berlin is capital of. 두 번째 문장은 의미가 통하지 않지만, 텍스트 임베딩 모델은 이 둘을 구분하지 못합니다. jina-embeddings-v3를 사용하면, 이 두 문장의 코사인 유사도 점수는 0.9295입니다.
단어 순서만이 임베딩이 민감하지 않은 유일한 요소는 아닙니다. 문법적 변형은 문장의 의미를 크게 바꿀 수 있지만 임베딩 거리에는 거의 영향을 미치지 않습니다. 예를 들어, She ate dinner before watching the movie와 She watched the movie before eating dinner는 행동의 순서가 반대임에도 0.9833의 코사인 유사도를 가집니다.
부정도 특별한 훈련 없이는 일관되게 임베딩하기가 매우 어렵습니다 — This is a useful model과 This is not a useful model은 임베딩 공간에서 거의 동일하게 보입니다. 종종 "today"를 "yesterday"로 바꾸거나 동사 시제를 바꾸는 것과 같이 텍스트의 단어를 같은 부류의 다른 단어로 바꾸는 것은 예상만큼 임베딩을 크게 변화시키지 않습니다.
이는 심각한 의미를 가집니다. 두 검색 쿼리를 고려해보세요: Flight from Berlin to Amsterdam와 Flight from Amsterdam to Berlin. 이들은 거의 동일한 임베딩을 가지며, jina-embeddings-v3는 이들에게 0.9884의 코사인 유사도를 할당합니다. 여행 검색이나 물류와 같은 실제 애플리케이션에서 이러한 단점은 치명적입니다.
이 글에서는 임베딩 모델이 직면한 도전 과제들을 살펴보고, 단어 순서와 단어 선택에 대한 지속적인 어려움을 검토합니다. 우리는 방향, 시간, 인과관계, 비교, 부정 맥락을 포함한 언어적 카테고리 전반에 걸친 주요 실패 모드를 분석하면서 모델 성능을 향상시키기 위한 전략을 탐구합니다.
tag왜 섞인 문장들은 놀랍도록 비슷한 코사인 점수를 가질까요?
처음에는 이것이 모델이 단어의 의미를 결합하는 방식 때문일 것이라고 생각했습니다 - 각 단어에 대한 임베딩을 생성하고(위 예시 문장들에서 각각 6-7개 단어) 이를 평균 풀링으로 평균화합니다. 이는 최종 임베딩에 단어 순서 정보가 거의 없다는 것을 의미합니다. 평균은 값들의 순서와 관계없이 동일합니다.
하지만 CLS 풀링(전체 문장을 이해하기 위해 특별한 첫 단어를 보고 단어 순서에 더 민감해야 하는)을 사용하는 모델들도 같은 문제를 가지고 있습니다. 예를 들어, bge-1.5-base-en도 여전히 Berlin is the capital of Germany와 the Germany Berlin is capital of 문장에 대해 0.9304의 코사인 유사도 점수를 부여합니다.
이는 임베딩 모델의 훈련 방식의 한계를 보여줍니다. 언어 모델들이 사전 훈련 중에 문장 구조를 초기에 학습하지만, 임베딩 모델을 만들기 위한 대조 학습 과정에서 이러한 이해의 일부를 잃어버리는 것 같습니다.
tag텍스트 길이와 단어 순서는 임베딩 유사도에 어떤 영향을 미칠까요?
왜 모델들은 단어 순서에 어려움을 겪을까요? 가장 먼저 떠오르는 것은 텍스트의 길이(토큰 수)입니다. 텍스트가 인코딩 함수로 전송될 때, 모델은 먼저 토큰 임베딩 리스트를 생성하고(즉, 토큰화된 각 단어는 그 의미를 나타내는 전용 벡터를 가짐), 그 다음 이를 평균화합니다.
텍스트 길이와 단어 순서가 임베딩 유사도에 미치는 영향을 보기 위해, 우리는 3, 5, 10, 15, 20, 30개의 토큰으로 구성된 180개의 합성 문장 데이터셋을 생성했습니다. 또한 각 문장의 토큰들을 무작위로 섞어 변형을 만들었습니다:

다음은 몇 가지 예시입니다:
| Length (tokens) | Original sentence | Shuffled sentence |
|---|---|---|
| 3 | The cat sleeps | cat The sleeps |
| 5 | He drives his car carefully | drives car his carefully He |
| 15 | The talented musicians performed beautiful classical music at the grand concert hall yesterday | in talented now grand classical yesterday The performed musicians at hall concert the music |
| 30 | The passionate group of educational experts collaboratively designed and implemented innovative teaching methodologies to improve learning outcomes in diverse classroom environments worldwide | group teaching through implemented collaboratively outcomes of methodologies across worldwide diverse with passionate and in experts educational classroom for environments now by learning to at improve from innovative The designed |
우리의 jina-embeddings-v3 모델과 오픈소스 모델 bge-base-en-v1.5를 사용하여 데이터셋을 인코딩한 다음, 원본 문장과 섞인 문장 사이의 코사인 유사도를 계산해 보겠습니다:
| Length (tokens) | Mean cosine similarity | Standard deviation in cosine similarity |
|---|---|---|
| 3 | 0.947 | 0.053 |
| 5 | 0.909 | 0.052 |
| 10 | 0.924 | 0.031 |
| 15 | 0.918 | 0.019 |
| 20 | 0.899 | 0.021 |
| 30 | 0.874 | 0.025 |
이제 코사인 유사도의 경향을 더 명확하게 보여주는 박스 플롯을 생성할 수 있습니다:
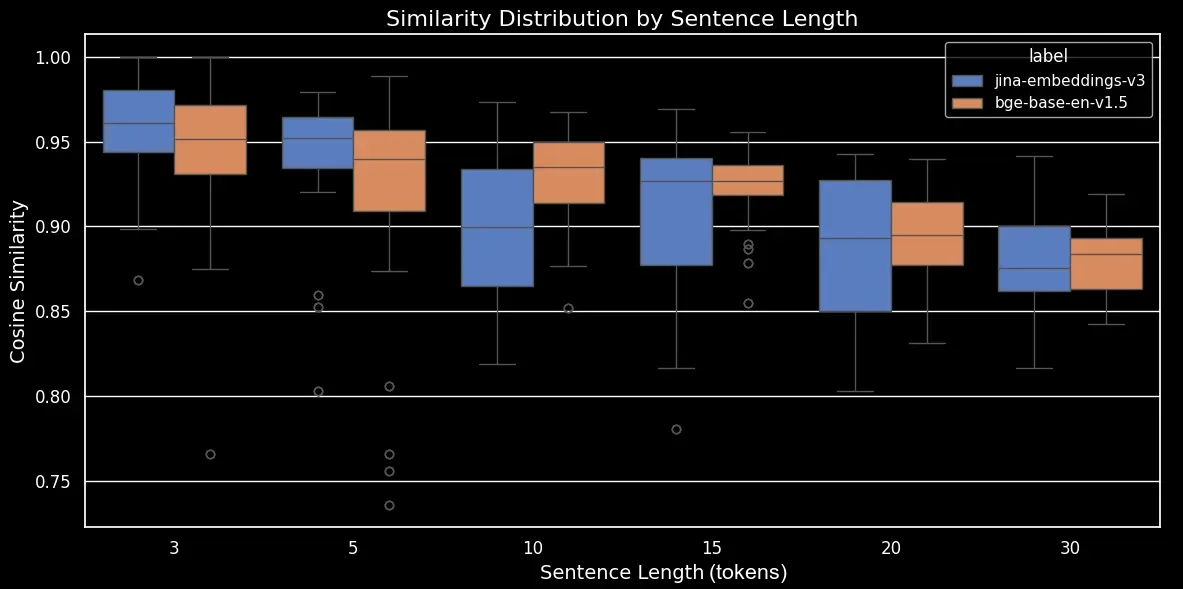
bge-base-en-1.5 (미세조정되지 않은)을 사용한 섞인 문장의 문장 길이별 유사도 분포보시다시피, 임베딩의 평균 코사인 유사도에는 명확한 선형 관계가 있습니다. 텍스트가 길수록 원본과 무작위로 섞인 문장 사이의 평균 코사인 유사도 점수가 낮아집니다. 이는 아마도 "단어 이동", 즉 무작위 섞기 후 단어들이 원래 위치에서 얼마나 멀리 이동했는지 때문일 것입니다. 짧은 텍스트에서는 토큰이 섞일 수 있는 "자리"가 단순히 더 적어서 멀리 이동할 수 없지만, 긴 텍스트는 더 많은 잠재적 순열을 가지고 있어 단어들이 더 멀리 이동할 수 있습니다.
아래 그림(코사인 유사도 vs 평균 단어 이동)에서 볼 수 있듯이, 텍스트가 길수록 단어 이동이 더 커집니다:
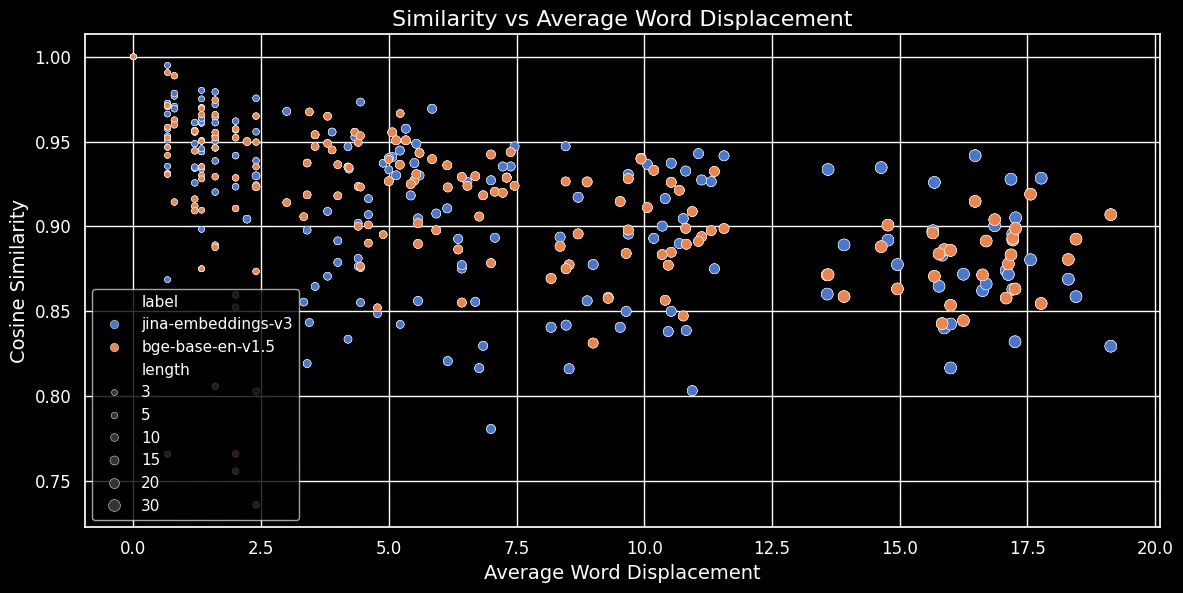
토큰 임베딩은 가장 가까운 단어와 같은 지역적 문맥에 의존합니다. 짧은 텍스트에서는 단어를 재배열해도 그 문맥을 크게 바꿀 수 없습니다. 하지만 긴 텍스트의 경우, 단어가 원래 문맥에서 매우 멀리 이동할 수 있고 이는 토큰 임베딩을 크게 변화시킬 수 있습니다. 결과적으로, 긴 텍스트에서 단어를 섞으면 짧은 텍스트보다 더 먼 임베딩이 생성됩니다. 위 그림은 mean pooling을 사용하는 jina-embeddings-v3와 CLS pooling을 사용하는 bge-base-en-v1.5 모두에서 동일한 관계가 성립함을 보여줍니다: 더 긴 텍스트를 섞고 단어를 더 멀리 이동시키면 유사도 점수가 낮아집니다.
tag더 큰 모델이 문제를 해결할까요?
보통 이런 종류의 문제에 직면하면, 더 큰 모델을 적용하는 것이 일반적인 전략입니다. 하지만 더 큰 텍스트 임베딩 모델이 정말로 단어 순서 정보를 더 효과적으로 포착할 수 있을까요? 텍스트 임베딩 모델의 스케일링 법칙에 따르면(jina-embeddings-v3 출시 포스트에서 언급), 더 큰 모델이 일반적으로 더 나은 성능을 제공합니다:
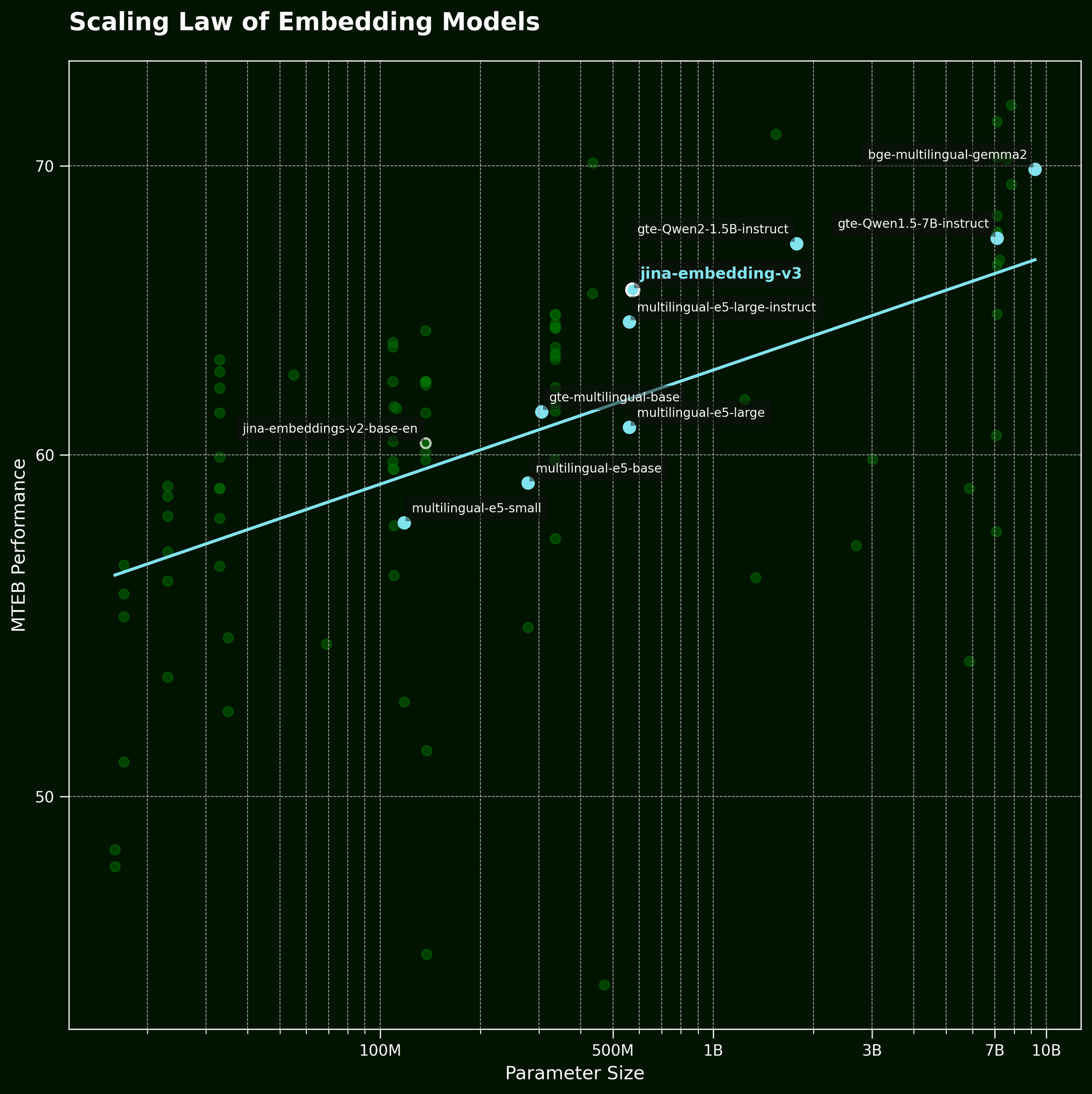
하지만 더 큰 모델이 단어 순서 정보를 더 효과적으로 포착할 수 있을까요? 우리는 BGE 모델의 세 가지 변형을 테스트했습니다: bge-small-en-v1.5, bge-base-en-v1.5, 그리고 bge-large-en-v1.5로, 각각 3천3백만, 1억1천만, 3억3천5백만 개의 파라미터를 가지고 있습니다.
이전과 동일한 180개의 문장을 사용하되, 길이 정보는 무시하겠습니다. 세 가지 모델 변형을 사용하여 원본 문장과 무작위로 섞은 문장을 인코딩하고 평균 코사인 유사도를 그래프로 나타내겠습니다:
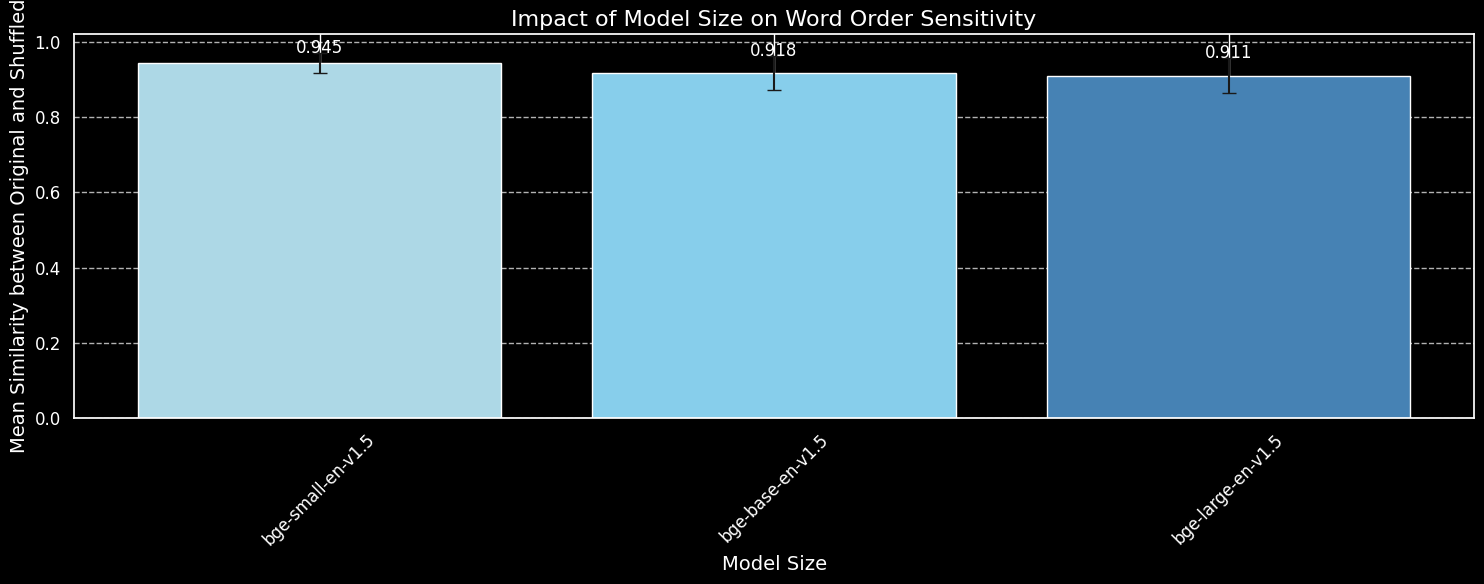
bge-small-en-v1.5, bge-base-en-v1.5, bge-large-en-v1.5를 사용한 섞인 문장 데이터셋에서 모델 크기가 단어 순서 민감도에 미치는 영향.더 큰 모델이 단어 순서 변화에 더 민감하다는 것을 볼 수 있지만, 그 차이는 작습니다. 훨씬 더 큰 bge-large-en-v1.5조차도 섞인 문장과 섞이지 않은 문장을 구별하는 데 있어서 미세하게 더 나을 뿐입니다. 임베딩 모델이 단어 재배열에 얼마나 민감한지를 결정하는 데는 다른 요소들, 특히 훈련 방식의 차이가 작용합니다. 또한, 코사인 유사도는 모델의 구별 능력을 측정하는 데 매우 제한적인 도구입니다. 그러나 모델 크기가 주요 고려사항이 아니라는 것을 알 수 있습니다. 단순히 모델을 더 크게 만드는 것으로는 이 문제를 해결할 수 없습니다.
tag실제 세계에서의 단어 순서와 단어 선택
jina-embeddings-v2를 사용하고 있습니다 (최신 모델인 jina-embeddings-v3가 아님). v2가 훨씬 작아서 로컬 GPU에서 실험하기가 더 빠르기 때문입니다. v3의 5억8천만 파라미터에 비해 1억3천7백만 파라미터를 가지고 있습니다.서론에서 언급했듯이, 단어 순서는 임베딩 모델의 유일한 과제가 아닙니다. 더 현실적인 실제 과제는 단어 선택에 관한 것입니다. 문장의 단어를 바꾸는 방법은 여러 가지가 있으며, 이러한 변화가 임베딩에 잘 반영되지 않습니다. "She flew from Paris to Tokyo"를 "She drove from Tokyo to Paris"로 변경할 수 있으며, 임베딩은 유사하게 유지됩니다. 우리는 이를 여러 변경 카테고리로 매핑했습니다:
| 카테고리 | 예시 - 좌 | 예시 - 우 | 코사인 유사도 (jina) |
|---|---|---|---|
| 방향 | She flew from Paris to Tokyo | She drove from Tokyo to Paris | 0.9439 |
| 시간 | She ate dinner before watching the movie | She watched the movie before eating dinner | 0.9833 |
| 인과 | The rising temperature melted the snow | The melting snow cooled the temperature | 0.8998 |
| 비교 | Coffee tastes better than tea | Tea tastes better than coffee | 0.9457 |
| 부정 | He is standing by the table | He is standing far from the table | 0.9116 |
위 표는 텍스트 임베딩 모델이 미묘한 단어 변화를 잡아내는 데 실패하는 "실패 사례" 목록을 보여줍니다. 이는 우리의 예상과 일치합니다: 텍스트 임베딩 모델은 추론 능력이 부족합니다. 예를 들어, 모델은 "from"과 "to" 사이의 관계를 이해하지 못합니다. 텍스트 임베딩 모델은 의미적 매칭을 수행하며, 의미는 일반적으로 토큰 수준에서 캡처되어 풀링 후 단일 밀집 벡터로 압축됩니다. 반면에, 조 단위 토큰 규모의 더 큰 데이터셋에서 훈련된 LLM(자기회귀 모델)은 추론을 위한 창발적 능력을 보이기 시작하고 있습니다.
이로 인해 우리는 대조 학습을 사용하여 쿼리와 긍정 사례를 더 가깝게 당기고 쿼리와 부정 사례를 더 멀리 밀어내는 삼중항을 사용하여 임베딩 모델을 미세 조정할 수 있을지 궁금해졌습니다.

예를 들어, "암스테르담에서 베를린으로 가는 항공편"은 "베를린에서 암스테르담으로 가는 항공편"의 부정 쌍으로 간주될 수 있습니다. 실제로 jina-embeddings-v1 기술 보고서(Michael Guenther 외)에서 우리는 이 문제를 작은 규모로 다루었습니다: 대규모 언어 모델에서 생성된 10,000개의 예제로 구성된 부정 데이터셋에서 jina-embeddings-v1 모델을 미세 조정했습니다.

위 보고서 링크에 보고된 결과는 유망했습니다:
모든 모델 크기에서 삼중항 데이터(우리의 부정 훈련 데이터셋 포함)로 미세 조정하면 성능이 크게 향상되었으며, 특히 HardNegation 태스크에서 두드러졌습니다.
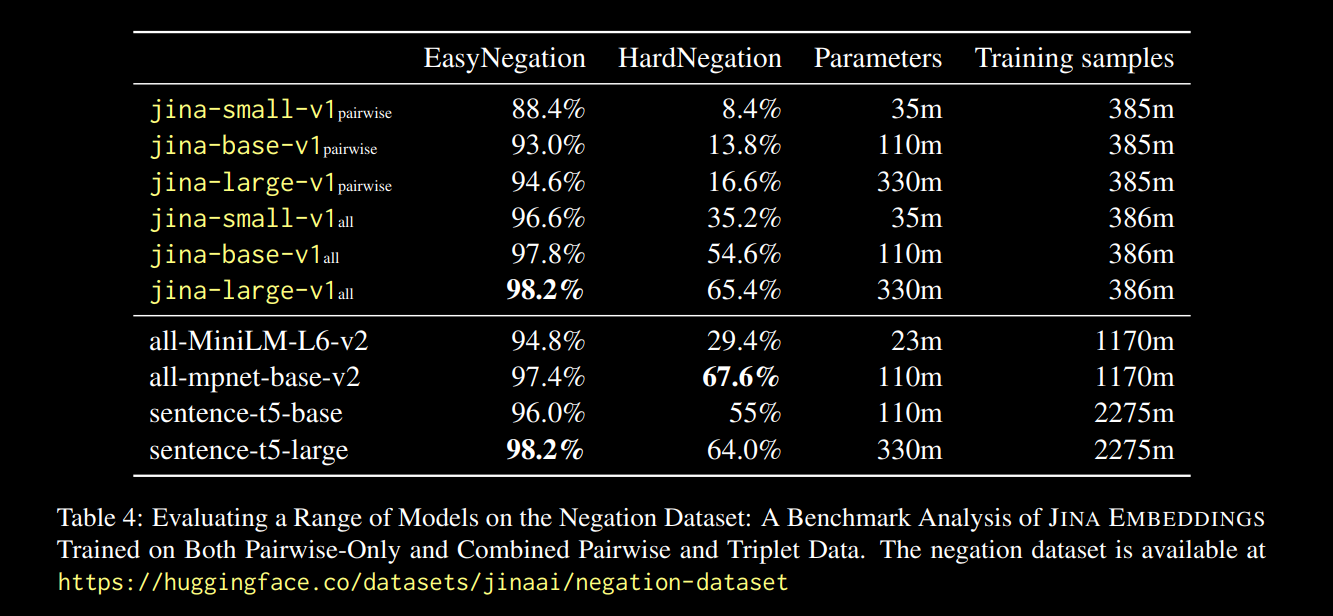
jina-embeddings 모델의 EasyNegation 및 HardNegation 점수를 보여주는 표.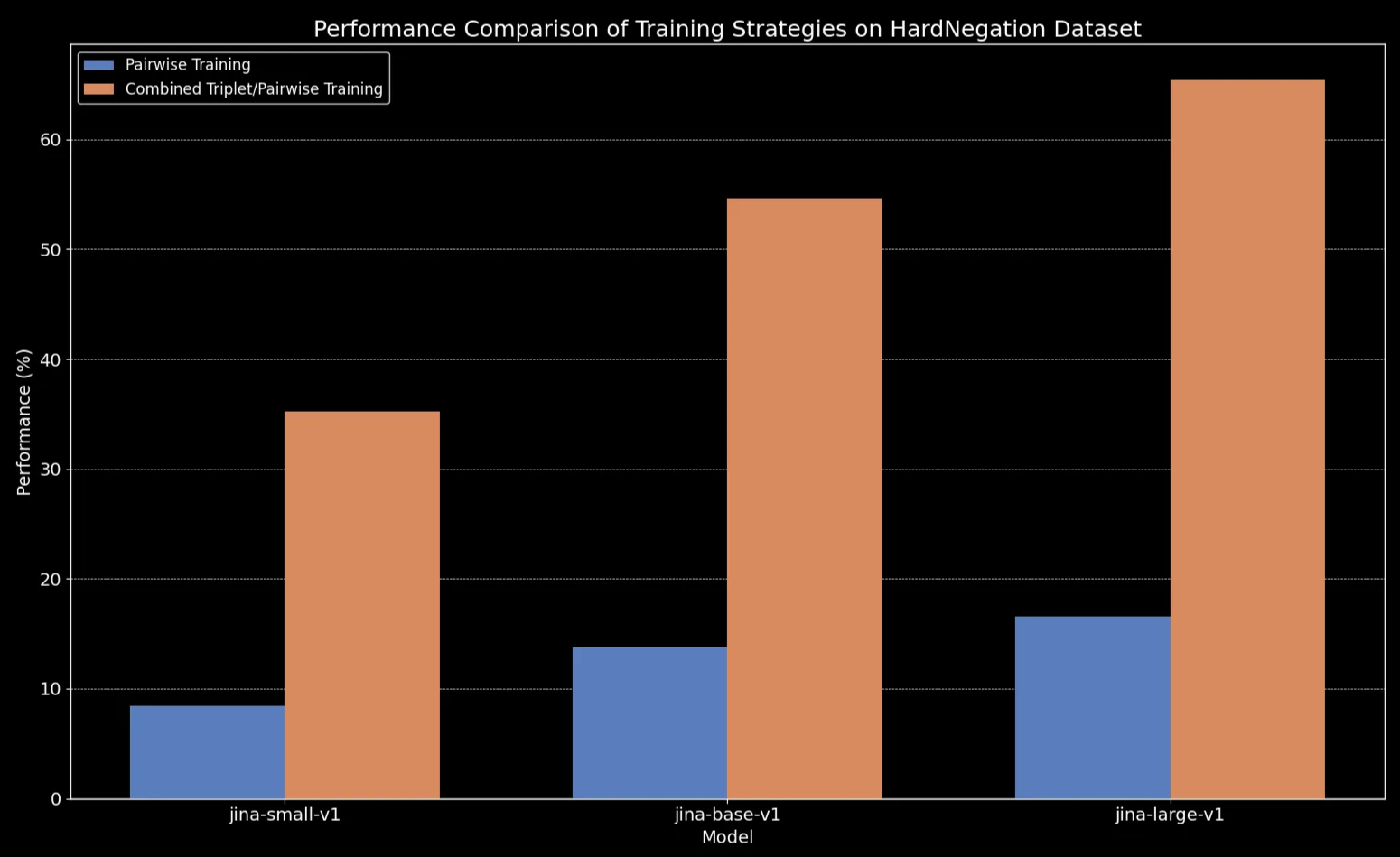
jina-embeddings 간 훈련 전략의 성능 비교.tag큐레이트된 데이터셋으로 텍스트 임베딩 모델 미세 조정하기
앞 섹션에서 우리는 텍스트 임베딩에 관한 몇 가지 주요 관찰 사항을 살펴보았습니다:
- 짧은 텍스트는 단어 순서를 포착하는 데 오류가 더 발생하기 쉽습니다.
- 텍스트 임베딩 모델의 크기를 늘린다고 해서 반드시 단어 순서 이해가 개선되지는 않습니다.
- 대조 학습이 이러한 문제에 대한 잠재적 해결책이 될 수 있습니다.
이를 염두에 두고, 우리는 jina-embeddings-v2-base-en과 bge-base-en-1.5를 부정 및 단어 순서 데이터셋(총 약 11,000개의 훈련 샘플)에서 미세 조정했습니다:


미세 조정을 평가하기 위해 우리는 쿼리, 긍정(pos), 부정(neg) 케이스로 구성된 1,000개의 삼중항 데이터셋을 생성했습니다:

다음은 예시 행입니다:
| Anchor | The river flows from the mountains to the sea |
| Positive | Water travels from mountain peaks to ocean |
| Negative | The river flows from the sea to the mountains |
이러한 삼중항은 단어 순서 변경으로 인한 방향, 시간, 인과 의미 변화를 포함한 다양한 실패 사례를 다루도록 설계되었습니다.
이제 세 가지 다른 평가 세트로 모델을 평가할 수 있습니다:
- 180개의 합성 문장 세트(이 게시물의 앞부분에서), 무작위로 섞음.
- 수동으로 확인한 5개의 예시(위의 방향/인과 등 표에서).
- 방금 생성한 삼중항 데이터셋에서 94개의 큐레이트된 삼중항.
다음은 미세 조정 전후의 섞인 문장에 대한 차이입니다:
| 문장 길이(토큰) | 평균 코사인 유사도 (jina) |
평균 코사인 유사도 (jina-ft) |
평균 코사인 유사도 (bge) |
평균 코사인 유사도 (bge-ft) |
|---|---|---|---|---|
| 3 | 0.970 | 0.927 | 0.929 | 0.899 |
| 5 | 0.958 | 0.910 | 0.940 | 0.916 |
| 10 | 0.953 | 0.890 | 0.934 | 0.910 |
| 15 | 0.930 | 0.830 | 0.912 | 0.875 |
| 20 | 0.916 | 0.815 | 0.901 | 0.879 |
| 30 | 0.927 | 0.819 | 0.877 | 0.852 |
결과는 분명해 보입니다: 파인튜닝 과정이 단 5분밖에 걸리지 않았음에도 불구하고, 무작위로 섞은 문장 데이터셋에서 성능이 극적으로 향상된 것을 볼 수 있습니다:
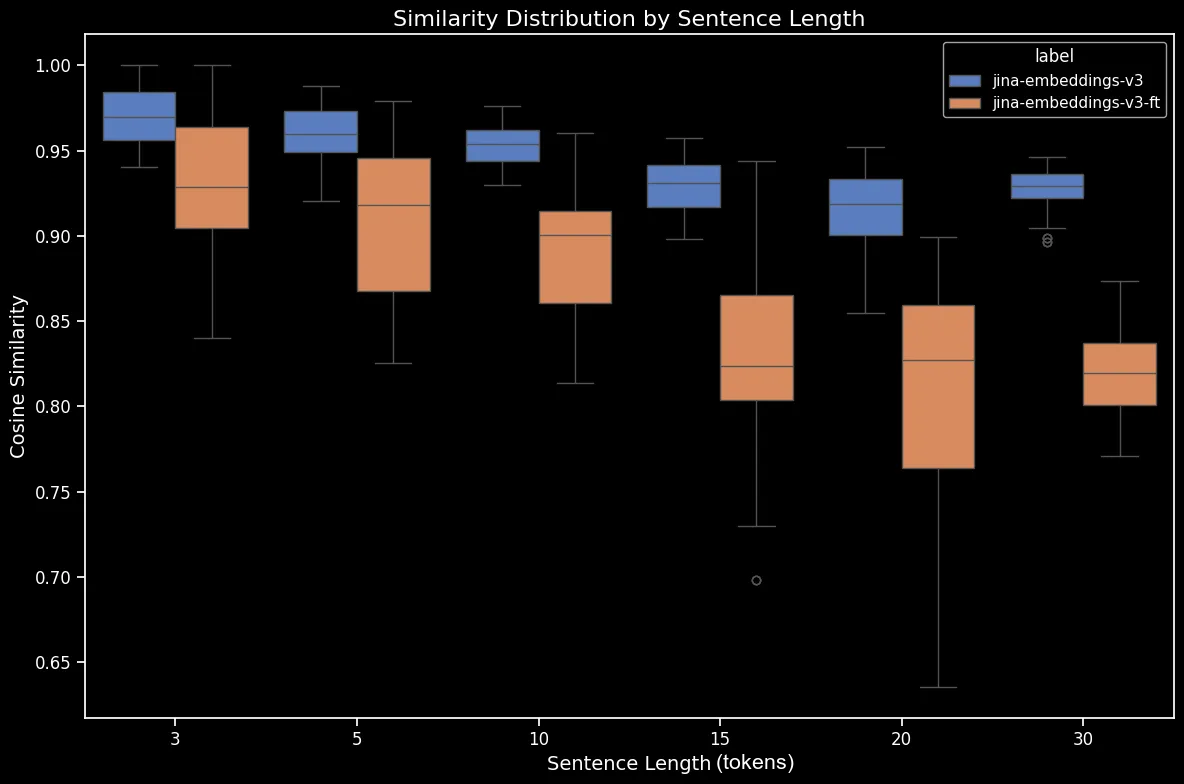
bge-base-en-1.5 (파인튜닝됨)의 섞인 문장에 대한 문장 길이별 유사도 분포.방향성, 시간적, 인과관계 및 비교 케이스에서도 향상을 볼 수 있습니다. 모델은 평균 코사인 유사도의 하락으로 반영되는 상당한 성능 향상을 보여줍니다. 가장 큰 성능 향상은 부정 케이스에서 나타났는데, 이는 파인튜닝 데이터셋에 10,000개의 부정 학습 예제가 포함되어 있기 때문입니다.
| 카테고리 | 예시 - 왼쪽 | 예시 - 오른쪽 | 평균 코사인 유사도 (jina) |
평균 코사인 유사도 (jina-ft) |
평균 코사인 유사도 (bge) |
평균 코사인 유사도 (bge-ft) |
|---|---|---|---|---|---|---|
| 방향성 | She flew from Paris to Tokyo. | She drove from Tokyo to Paris | 0.9439 | 0.8650 | 0.9319 | 0.8674 |
| 시간적 | She ate dinner before watching the movie | She watched the movie before eating dinner | 0.9833 | 0.9263 | 0.9683 | 0.9331 |
| 인과관계 | The rising temperature melted the snow | The melting snow cooled the temperature | 0.8998 | 0.7937 | 0.8874 | 0.8371 |
| 비교 | Coffee tastes better than tea | Tea tastes better than coffee | 0.9457 | 0.8759 | 0.9723 | 0.9030 |
| 부정 | He is standing by the table | He is standing far from the table | 0.9116 | 0.4478 | 0.8329 | 0.4329 |
tag결론
이 포스트에서는 텍스트 임베딩 모델이 직면한 과제들, 특히 단어 순서를 효과적으로 처리하는 데 어려움을 겪는 문제에 대해 살펴보았습니다. 이를 분석하기 위해, 우리는 5가지 주요 실패 유형을 확인했습니다: 방향성, 시간적, 인과관계, 비교, 부정. 이들은 단어 순서가 정말 중요한 종류의 쿼리들이며, 만약 여러분의 사용 사례가 이들 중 하나를 포함한다면 이러한 모델의 한계를 알고 있는 것이 좋습니다.
또한 우리는 부정에 초점을 맞춘 데이터셋을 5가지 실패 카테고리 모두를 포함하도록 확장하는 빠른 실험을 진행했습니다. 결과는 희망적이었습니다: 신중하게 선택된 "하드 네거티브"로 파인튜닝을 하니 모델이 어떤 항목들이 함께 속하고 어떤 것들이 속하지 않는지를 더 잘 인식하게 되었습니다. 하지만 아직 할 일이 더 있습니다. 향후 단계에는 데이터셋의 크기와 품질이 성능에 미치는 영향을 더 깊이 연구하는 것이 포함됩니다.





